 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
FisheyeMultiNet: Real-time Multi-task Learning Architecture for Surround-view Automated Parking System
Dec 23, 2019
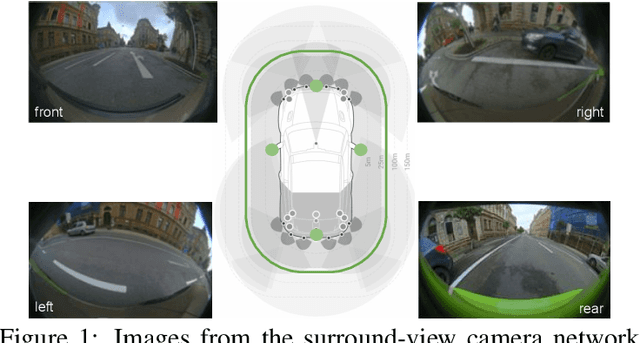
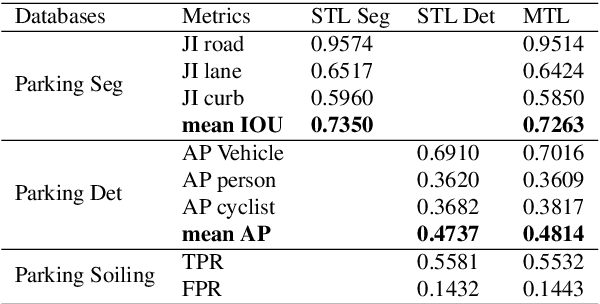
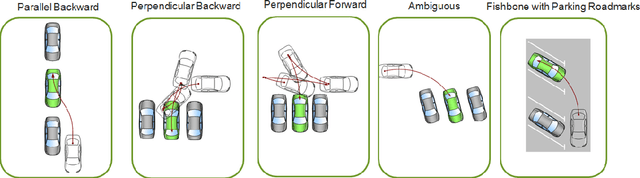
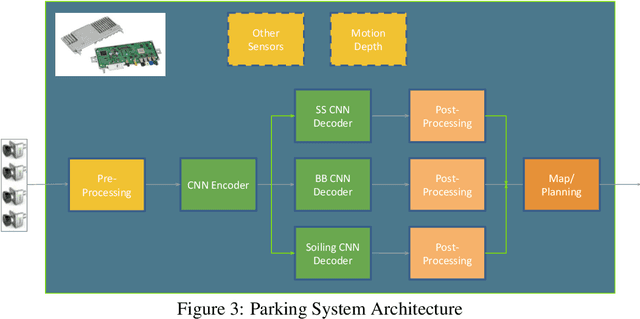
Automated Parking is a low speed manoeuvring scenario which is quite unstructured and complex, requiring full 360{\deg} near-field sensing around the vehicle. In this paper, we discuss the design and implementation of an automated parking system from the perspective of camera based deep learning algorithms. We provide a holistic overview of an industrial system covering the embedded system, use cases and the deep learning architecture. We demonstrate a real-time multi-task deep learning network called FisheyeMultiNet, which detects all the necessary objects for parking on a low-power embedded system. FisheyeMultiNet runs at 15 fps for 4 cameras and it has three tasks namely object detection, semantic segmentation and soiling detection. To encourage further research, we release a partial dataset of 5,000 images containing semantic segmentation and bounding box detection ground truth via WoodScape project \cite{yogamani2019woodscape}.
RTM3D: Real-time Monocular 3D Detection from Object Keypoints for Autonomous Driving
Jan 10, 2020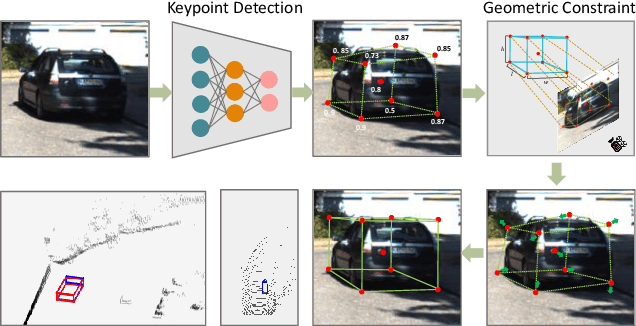
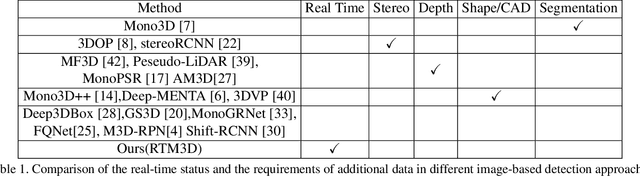
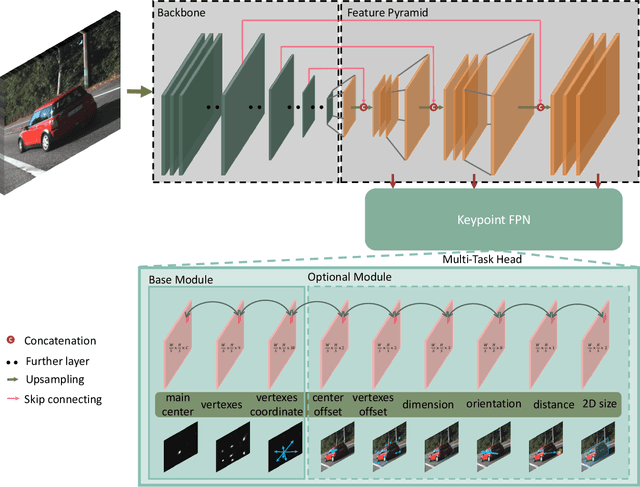
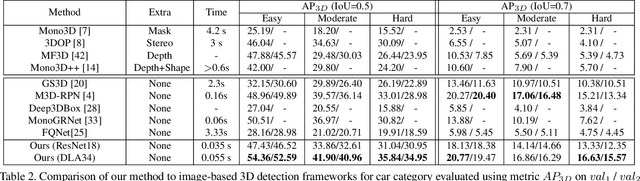
In this work, we propose an efficient and accurate monocular 3D detection framework in single shot. Most successful 3D detectors take the projection constraint from the 3D bounding box to the 2D box as an important component. Four edges of a 2D box provide only four constraints and the performance deteriorates dramatically with the small error of the 2D detector. Different from these approaches, our method predicts the nine perspective keypoints of a 3D bounding box in image space, and then utilize the geometric relationship of 3D and 2D perspectives to recover the dimension, location, and orientation in 3D space. In this method, the properties of the object can be predicted stably even when the estimation of keypoints is very noisy, which enables us to obtain fast detection speed with a small architecture. Training our method only uses the 3D properties of the object without the need for external networks or supervision data. Our method is the first real-time system for monocular image 3D detection while achieves state-of-the-art performance on the KITTI benchmark. Code will be released at https://github.com/Banconxuan/RTM3D.
Dynamic Event Camera Calibration
Jul 20, 2021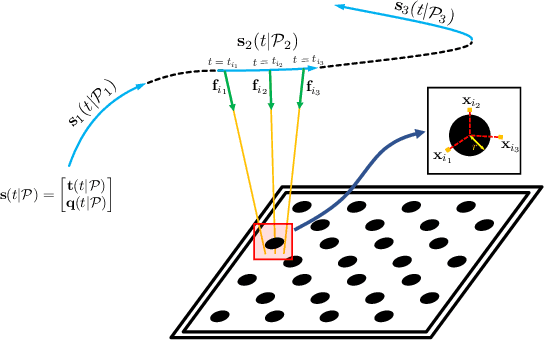
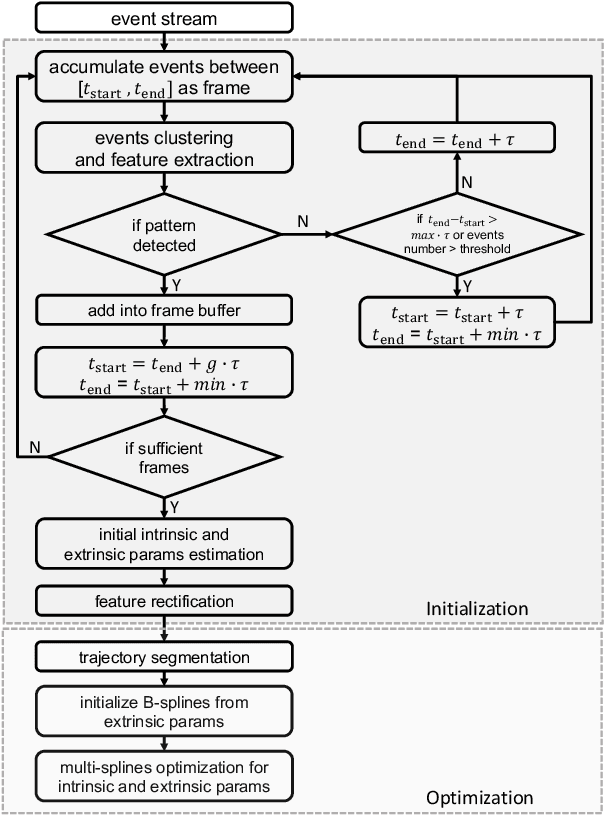


Camera calibration is an important prerequisite towards the solution of 3D computer vision problems. Traditional methods rely on static images of a calibration pattern. This raises interesting challenges towards the practical usage of event cameras, which notably require image change to produce sufficient measurements. The current standard for event camera calibration therefore consists of using flashing patterns. They have the advantage of simultaneously triggering events in all reprojected pattern feature locations, but it is difficult to construct or use such patterns in the field. We present the first dynamic event camera calibration algorithm. It calibrates directly from events captured during relative motion between camera and calibration pattern. The method is propelled by a novel feature extraction mechanism for calibration patterns, and leverages existing calibration tools before optimizing all parameters through a multi-segment continuous-time formulation. As demonstrated through our results on real data, the obtained calibration method is highly convenient and reliably calibrates from data sequences spanning less than 10 seconds.
'Skimming-Perusal' Tracking: A Framework for Real-Time and Robust Long-term Tracking
Sep 04, 2019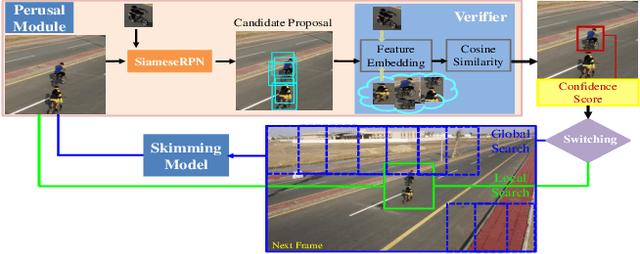
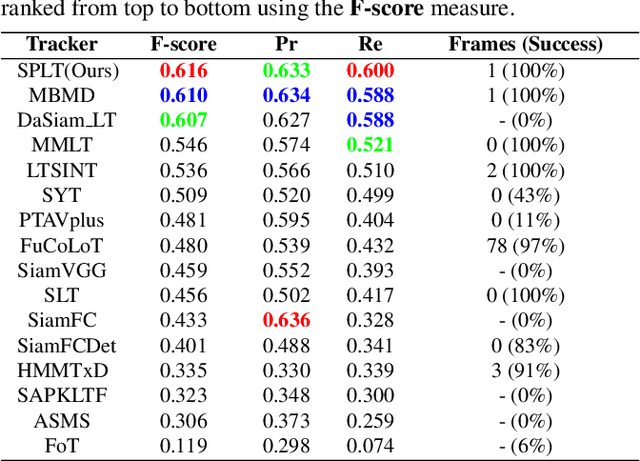
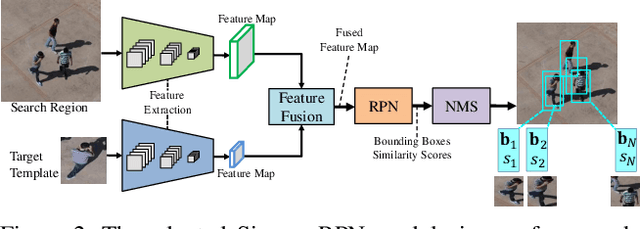
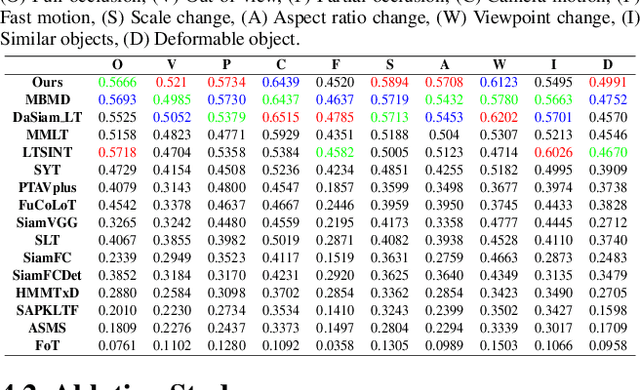
Compared with traditional short-term tracking, long-term tracking poses more challenges and is much closer to realistic applications. However, few works have been done and their performance have also been limited. In this work, we present a novel robust and real-time long-term tracking framework based on the proposed skimming and perusal modules. The perusal module consists of an effective bounding box regressor to generate a series of candidate proposals and a robust target verifier to infer the optimal candidate with its confidence score. Based on this score, our tracker determines whether the tracked object being present or absent, and then chooses the tracking strategies of local search or global search respectively in the next frame. To speed up the image-wide global search, a novel skimming module is designed to efficiently choose the most possible regions from a large number of sliding windows. Numerous experimental results on the VOT-2018 long-term and OxUvA long-term benchmarks demonstrate that the proposed method achieves the best performance and runs in real-time. The source codes are available at https://github.com/iiau-tracker/SPLT.
OncoNet: Weakly Supervised Siamese Network to automate cancer treatment response assessment between longitudinal FDG PET/CT examinations
Aug 03, 2021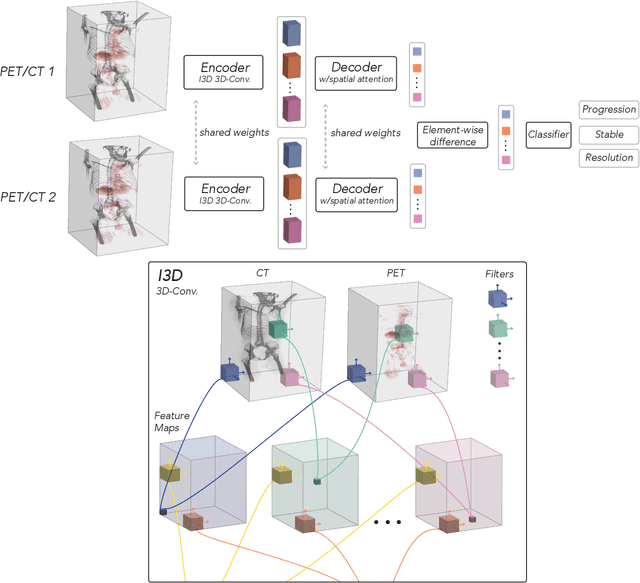

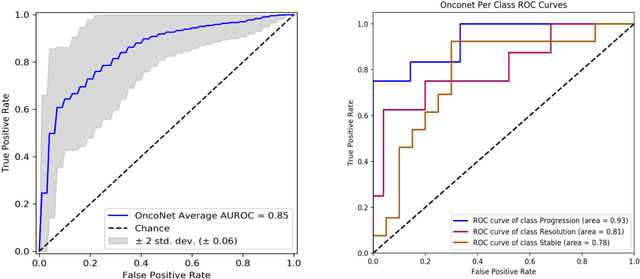
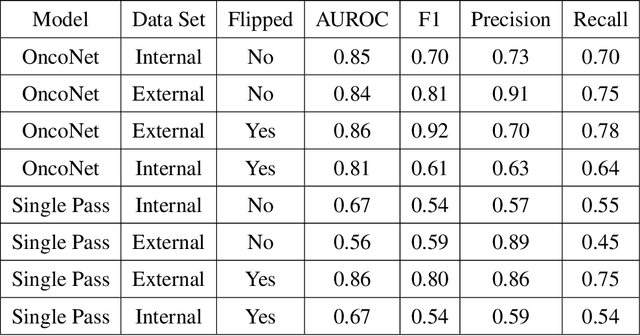
FDG PET/CT imaging is a resource intensive examination critical for managing malignant disease and is particularly important for longitudinal assessment during therapy. Approaches to automate longtudinal analysis present many challenges including lack of available longitudinal datasets, managing complex large multimodal imaging examinations, and need for detailed annotations for traditional supervised machine learning. In this work we develop OncoNet, novel machine learning algorithm that assesses treatment response from a 1,954 pairs of sequential FDG PET/CT exams through weak supervision using the standard uptake values (SUVmax) in associated radiology reports. OncoNet demonstrates an AUROC of 0.86 and 0.84 on internal and external institution test sets respectively for determination of change between scans while also showing strong agreement to clinical scoring systems with a kappa score of 0.8. We also curated a dataset of 1,954 paired FDG PET/CT exams designed for response assessment for the broader machine learning in healthcare research community. Automated assessment of radiographic response from FDG PET/CT with OncoNet could provide clinicians with a valuable tool to rapidly and consistently interpret change over time in longitudinal multi-modal imaging exams.
Physics-informed neural networks for improving cerebral hemodynamics predictions
Aug 25, 2021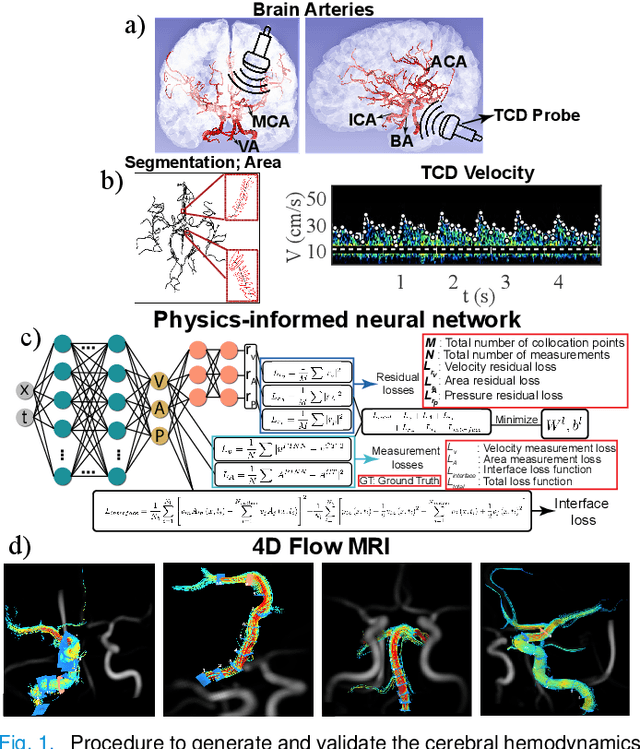
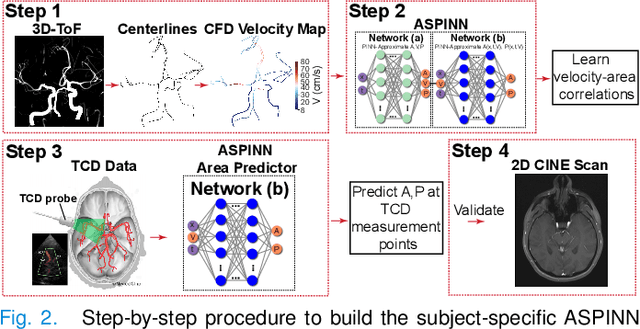
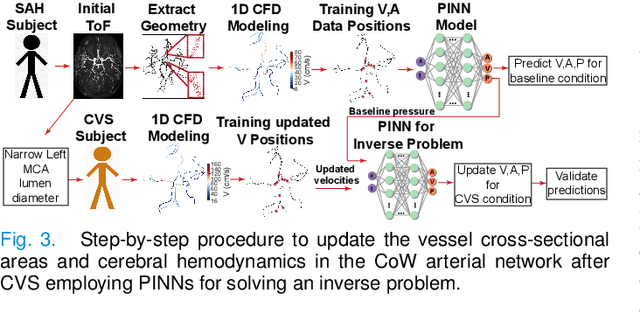
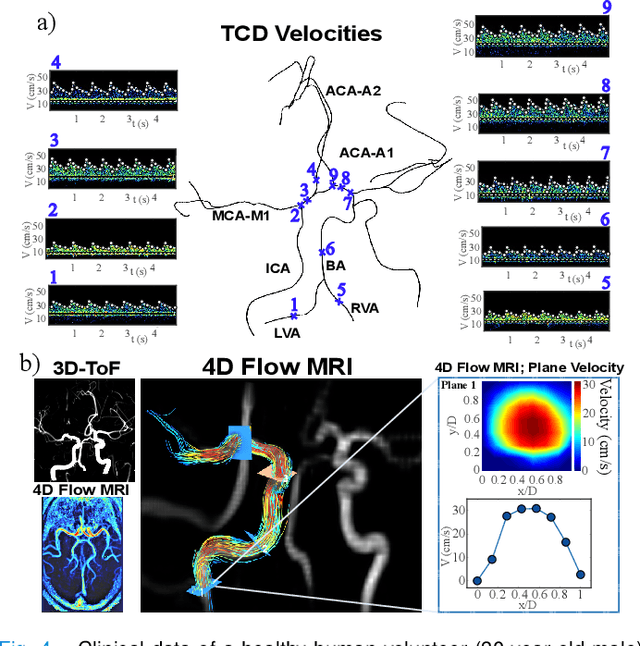
Determining brain hemodynamics plays a critical role in the diagnosis and treatment of various cerebrovascular diseases. In this work, we put forth a physics-informed deep learning framework that augments sparse clinical measurements with fast computational fluid dynamics (CFD) simulations to generate physically consistent and high spatiotemporal resolution of brain hemodynamic parameters. Transcranial Doppler (TCD) ultrasound is one of the most common techniques in the current clinical workflow that enables noninvasive and instantaneous evaluation of blood flow velocity within the cerebral arteries. However, it is spatially limited to only a handful of locations across the cerebrovasculature due to the constrained accessibility through the skull's acoustic windows. Our deep learning framework employs in-vivo real-time TCD velocity measurements at several locations in the brain and the baseline vessel cross-sectional areas acquired from 3D angiography images, and provides high-resolution maps of velocity, area, and pressure in the entire vasculature. We validated the predictions of our model against in-vivo velocity measurements obtained via 4D flow MRI scans. We then showcased the clinical significance of this technique in diagnosing the cerebral vasospasm (CVS) by successfully predicting the changes in vasospastic local vessel diameters based on corresponding sparse velocities measurements. The key finding here is that the combined effects of uncertainties in outlet boundary condition subscription and modeling physics deficiencies render the conventional purely physics-based computational models unsuccessful in recovering accurate brain hemodynamics. Nonetheless, fusing these models with clinical measurements through a data-driven approach ameliorates predictions of brain hemodynamic variables.
Multi-agent Natural Actor-critic Reinforcement Learning Algorithms
Sep 03, 2021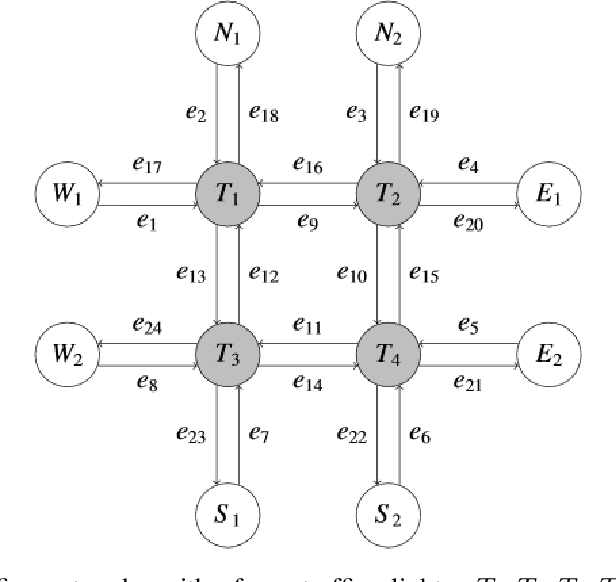
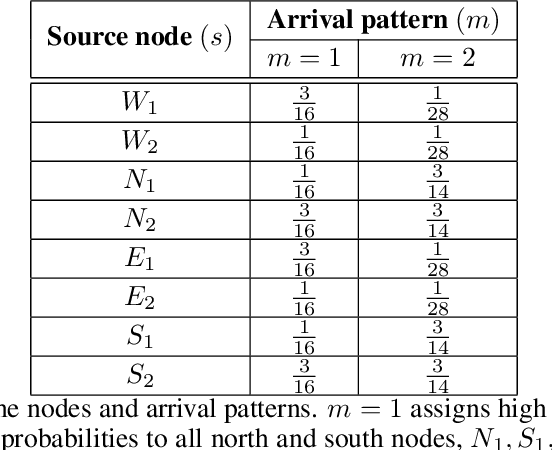
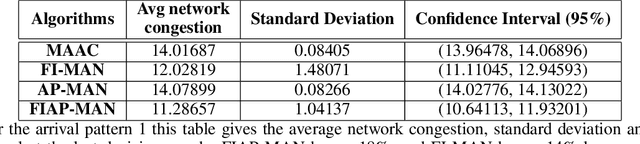
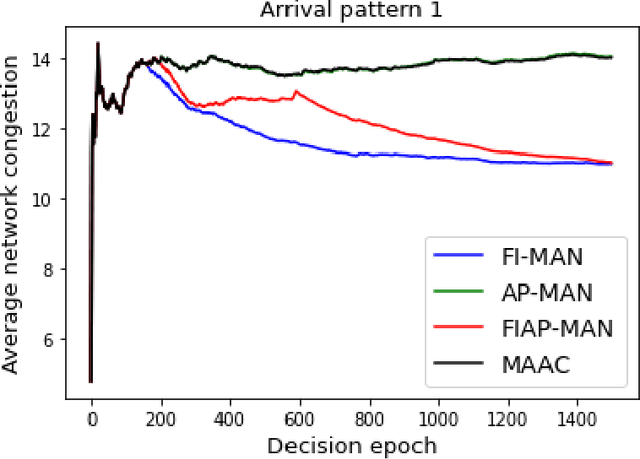
Both single-agent and multi-agent actor-critic algorithms are an important class of Reinforcement Learning algorithms. In this work, we propose three fully decentralized multi-agent natural actor-critic (MAN) algorithms. The agents' objective is to collectively learn a joint policy that maximizes the sum of averaged long-term returns of these agents. In the absence of a central controller, agents communicate the information to their neighbors via a time-varying communication network while preserving privacy. We prove the convergence of all the 3 MAN algorithms to a globally asymptotically stable point of the ODE corresponding to the actor update; these use linear function approximations. We use the Fisher information matrix to obtain the natural gradients. The Fisher information matrix captures the curvature of the Kullback-Leibler (KL) divergence between polices at successive iterates. We also show that the gradient of this KL divergence between policies of successive iterates is proportional to the objective function's gradient. Our MAN algorithms indeed use this \emph{representation} of the objective function's gradient. Under certain conditions on the Fisher information matrix, we prove that at each iterate, the optimal value via MAN algorithms can be better than that of the multi-agent actor-critic (MAAC) algorithm using the standard gradients. To validate the usefulness of our proposed algorithms, we implement all the 3 MAN algorithms on a bi-lane traffic network to reduce the average network congestion. We observe an almost 25% reduction in the average congestion in 2 MAN algorithms; the average congestion in another MAN algorithm is on par with the MAAC algorithm. We also consider a generic 15 agent MARL; the performance of the MAN algorithms is again as good as the MAAC algorithm. We attribute the better performance of the MAN algorithms to their use of the above representation.
Optimal Scheduling of Isolated Microgrids Using Automated Reinforcement Learning-based Multi-period Forecasting
Aug 15, 2021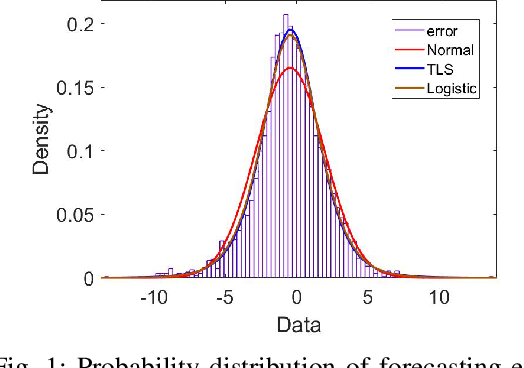
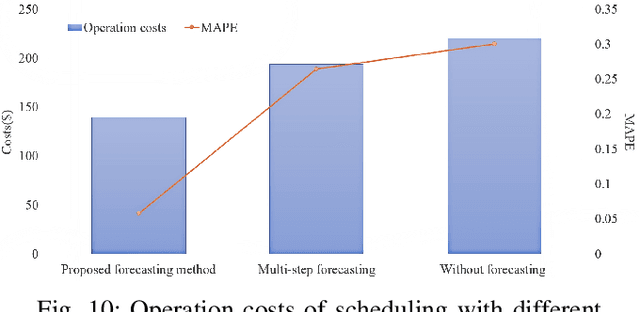
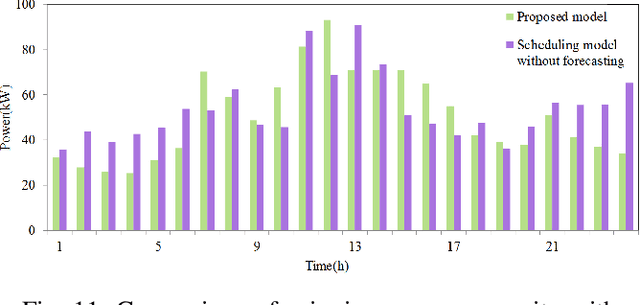
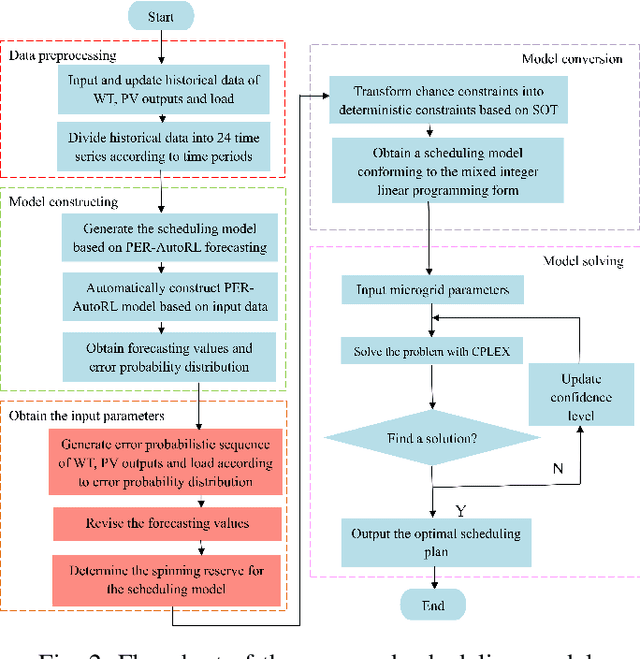
In order to reduce the negative impact of the uncertainty of load and renewable energies outputs on microgrid operation, an optimal scheduling model is proposed for isolated microgrids by using automated reinforcement learning-based multi-period forecasting of renewable power generations and loads. Firstly, a prioritized experience replay automated reinforcement learning (PER-AutoRL) is designed to simplify the deployment of deep reinforcement learning (DRL)-based forecasting model in a customized manner, the single-step multi-period forecasting method based on PER-AutoRL is proposed for the first time to address the error accumulation issue suffered by existing multi-step forecasting methods, then the prediction values obtained by the proposed forecasting method are revised via the error distribution to improve the prediction accuracy; secondly, a scheduling model considering demand response is constructed to minimize the total microgrid operating costs, where the revised forecasting values are used as the dispatch basis, and a spinning reserve chance constraint is set according to the error distribution; finally, by transforming the original scheduling model into a readily solvable mixed integer linear programming via the sequence operation theory (SOT), the transformed model is solved by using CPLEX solver. The simulation results show that compared with the traditional scheduling model without forecasting, this approach manages to significantly reduce the system operating costs by improving the prediction accuracy.
Neural Calibration for Scalable Beamforming in FDD Massive MIMO with Implicit Channel Estimation
Aug 03, 2021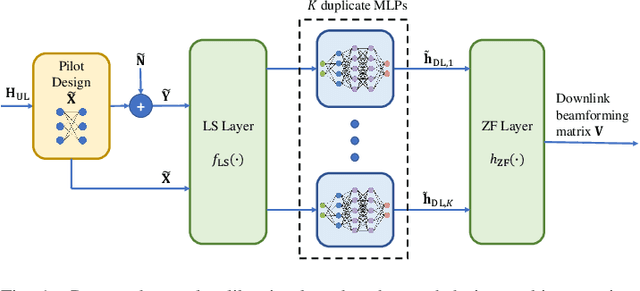
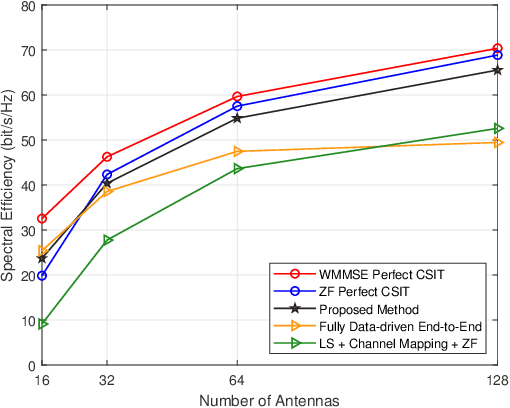
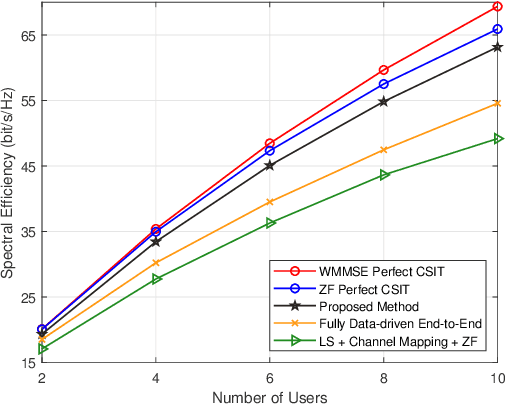
Channel estimation and beamforming play critical roles in frequency-division duplexing (FDD) massive multiple-input multiple-output (MIMO) systems. However, these two modules have been treated as two stand-alone components, which makes it difficult to achieve a global system optimality. In this paper, we propose a deep learning-based approach that directly optimizes the beamformers at the base station according to the received uplink pilots, thereby, bypassing the explicit channel estimation. Different from the existing fully data-driven approach where all the modules are replaced by deep neural networks (DNNs), a neural calibration method is proposed to improve the scalability of the end-to-end design. In particular, the backbone of conventional time-efficient algorithms, i.e., the least-squares (LS) channel estimator and the zero-forcing (ZF) beamformer, is preserved and DNNs are leveraged to calibrate their inputs for better performance. The permutation equivariance property of the formulated resource allocation problem is then identified to design a low-complexity neural network architecture. Simulation results will show the superiority of the proposed neural calibration method over benchmark schemes in terms of both the spectral efficiency and scalability in large-scale wireless networks.
FL-MISR: Fast Large-Scale Multi-Image Super-Resolution for Computed Tomography Based on Multi-GPU Acceleration
Aug 09, 2021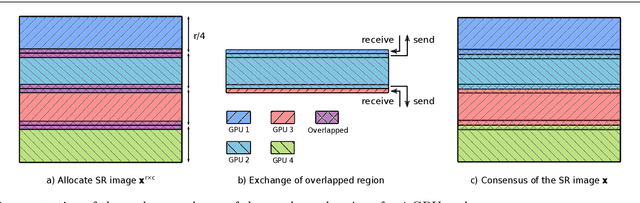

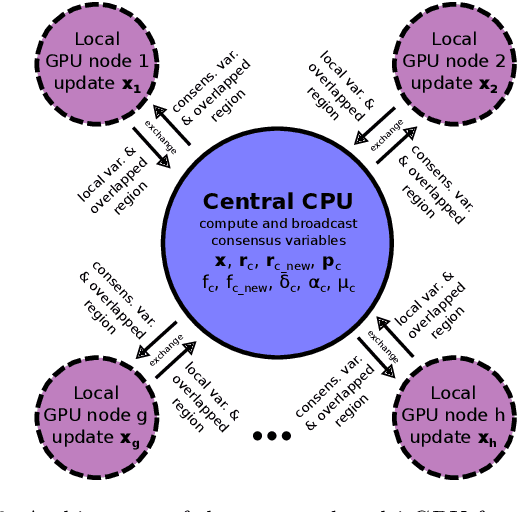

Multi-image super-resolution (MISR) usually outperforms single-image super-resolution (SISR) under a proper inter-image alignment by explicitly exploiting the inter-image correlation. However, the large computational demand encumbers the deployment of MISR methods in practice. In this work, we propose a distributed optimization framework based on data parallelism for fast large-scale MISR which supports multi- GPU acceleration, named FL-MISR. Inter-GPU communication for the exchange of local variables and over-lapped regions is enabled to impose a consensus convergence of the distributed task allocated to each GPU node. We have seamlessly integrated FL-MISR into the computed tomography (CT) imaging system by super-resolving multiple projections of the same view acquired by subpixel detector shift. The SR reconstruction is performed on the fly during the CT acquisition such that no additional computation time is introduced. We evaluated FL-MISR quantitatively and qualitatively on multiple objects including aluminium cylindrical phantoms, QRM bar pattern phantoms, and concrete joints. Experiments show that FL-MISR can effectively improve the spatial resolution of CT systems in modulation transfer function (MTF) and visual perception. Besides, comparing to a multi-core CPU implementation, FL-MISR achieves a more than 50x speedup on an off-the-shelf 4-GPU system.