 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Block-Structure Based Time-Series Models For Graph Sequences
Sep 18, 2018
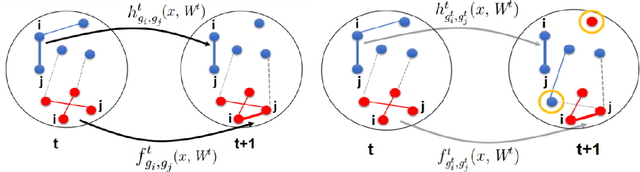


Although the computational and statistical trade-off for modeling single graphs, for instance, using block models is relatively well understood, extending such results to sequences of graphs has proven to be difficult. In this work, we take a step in this direction by proposing two models for graph sequences that capture: (a) link persistence between nodes across time, and (b) community persistence of each node across time. In the first model, we assume that the latent community of each node does not change over time, and in the second model we relax this assumption suitably. For both of these proposed models, we provide statistically and computationally efficient inference algorithms, whose unique feature is that they leverage community detection methods that work on single graphs. We also provide experimental results validating the suitability of our models and methods on synthetic and real instances.
Machine Learning Approaches to Automated Flow Cytometry Diagnosis of Chronic Lymphocytic Leukemia
Jul 20, 2021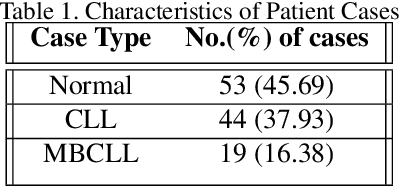
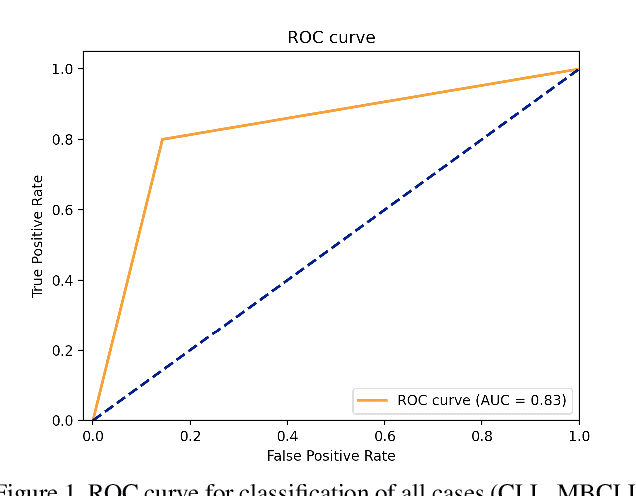
Flow cytometry is a technique that measures multiple fluorescence and light scatter-associated parameters from individual cells as they flow a single file through an excitation light source. These cells are labeled with antibodies to detect various antigens and the fluorescence signals reflect antigen expression. Interpretation of the multiparameter flow cytometry data is laborious, time-consuming, and expensive. It involves manual interpretation of cell distribution and pattern recognition on two-dimensional plots by highly trained medical technologists and pathologists. Using various machine learning algorithms, we attempted to develop an automated analysis for clinical flow cytometry cases that would automatically classify normal and chronic lymphocytic leukemia cases. We achieved the best success with the Gradient Boosting. The XGBoost classifier achieved a specificity of 1.00 and a sensitivity of 0.67, a negative predictive value of 0.75, a positive predictive value of 1.00, and an overall accuracy of 0.83 in prospectively classifying cases with malignancies.
FisheyeMultiNet: Real-time Multi-task Learning Architecture for Surround-view Automated Parking System
Dec 23, 2019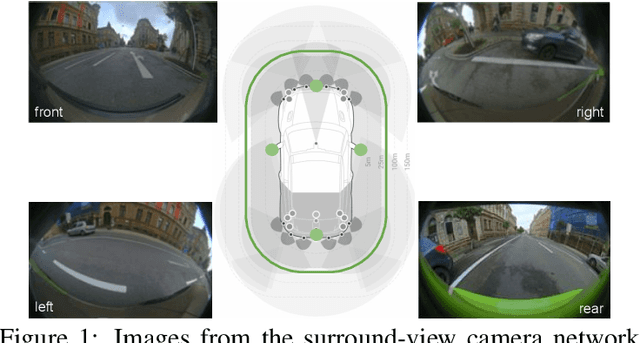
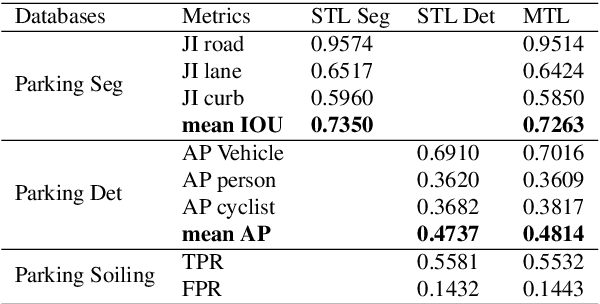
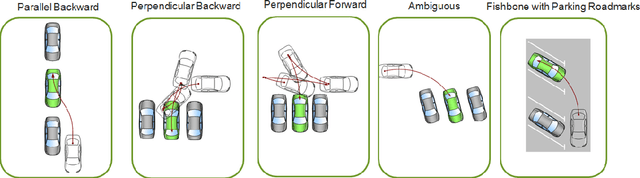
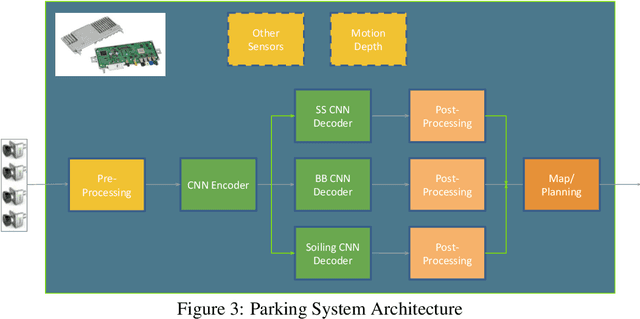
Automated Parking is a low speed manoeuvring scenario which is quite unstructured and complex, requiring full 360{\deg} near-field sensing around the vehicle. In this paper, we discuss the design and implementation of an automated parking system from the perspective of camera based deep learning algorithms. We provide a holistic overview of an industrial system covering the embedded system, use cases and the deep learning architecture. We demonstrate a real-time multi-task deep learning network called FisheyeMultiNet, which detects all the necessary objects for parking on a low-power embedded system. FisheyeMultiNet runs at 15 fps for 4 cameras and it has three tasks namely object detection, semantic segmentation and soiling detection. To encourage further research, we release a partial dataset of 5,000 images containing semantic segmentation and bounding box detection ground truth via WoodScape project \cite{yogamani2019woodscape}.
Statistically Meaningful Approximation: a Case Study on Approximating Turing Machines with Transformers
Jul 28, 2021A common lens to theoretically study neural net architectures is to analyze the functions they can approximate. However, the constructions from approximation theory often have unrealistic aspects, for example, reliance on infinite precision to memorize target function values, which make these results potentially less meaningful. To address these issues, this work proposes a formal definition of statistically meaningful approximation which requires the approximating network to exhibit good statistical learnability. We present case studies on statistically meaningful approximation for two classes of functions: boolean circuits and Turing machines. We show that overparameterized feedforward neural nets can statistically meaningfully approximate boolean circuits with sample complexity depending only polynomially on the circuit size, not the size of the approximating network. In addition, we show that transformers can statistically meaningfully approximate Turing machines with computation time bounded by $T$, requiring sample complexity polynomial in the alphabet size, state space size, and $\log (T)$. Our analysis introduces new tools for generalization bounds that provide much tighter sample complexity guarantees than the typical VC-dimension or norm-based bounds, which may be of independent interest.
RTM3D: Real-time Monocular 3D Detection from Object Keypoints for Autonomous Driving
Jan 10, 2020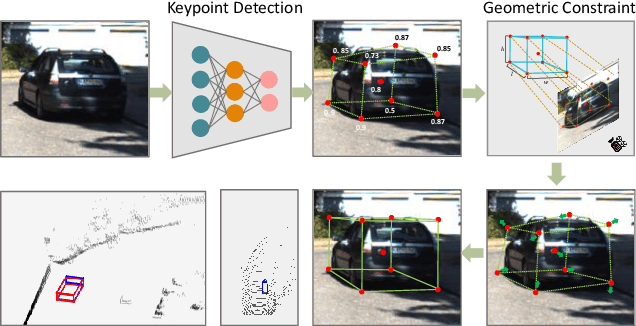
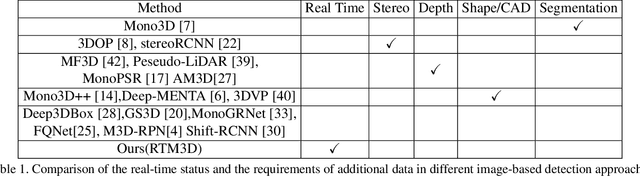
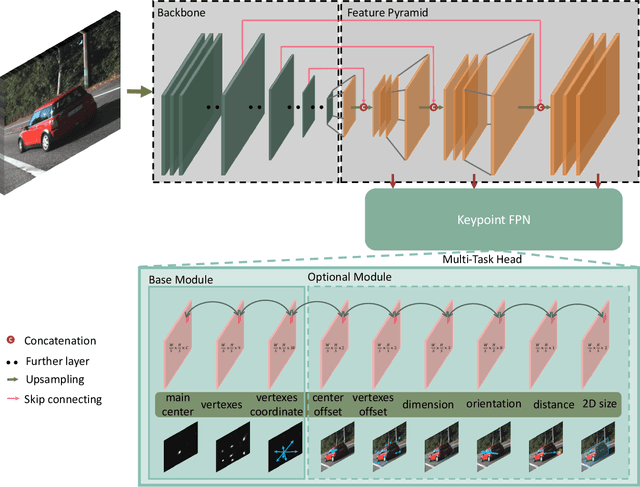
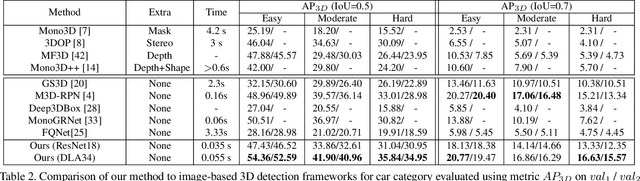
In this work, we propose an efficient and accurate monocular 3D detection framework in single shot. Most successful 3D detectors take the projection constraint from the 3D bounding box to the 2D box as an important component. Four edges of a 2D box provide only four constraints and the performance deteriorates dramatically with the small error of the 2D detector. Different from these approaches, our method predicts the nine perspective keypoints of a 3D bounding box in image space, and then utilize the geometric relationship of 3D and 2D perspectives to recover the dimension, location, and orientation in 3D space. In this method, the properties of the object can be predicted stably even when the estimation of keypoints is very noisy, which enables us to obtain fast detection speed with a small architecture. Training our method only uses the 3D properties of the object without the need for external networks or supervision data. Our method is the first real-time system for monocular image 3D detection while achieves state-of-the-art performance on the KITTI benchmark. Code will be released at https://github.com/Banconxuan/RTM3D.
'Skimming-Perusal' Tracking: A Framework for Real-Time and Robust Long-term Tracking
Sep 04, 2019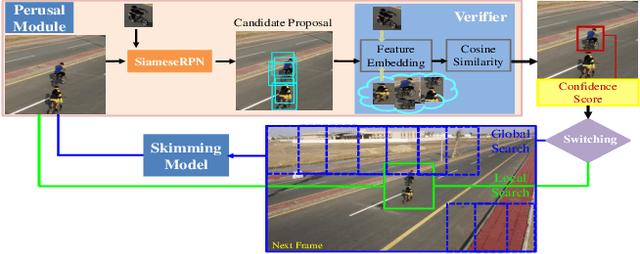
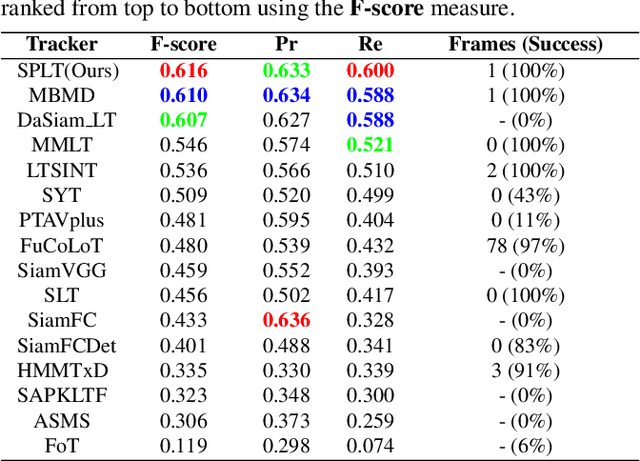
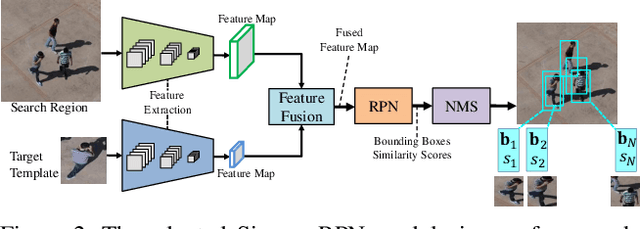
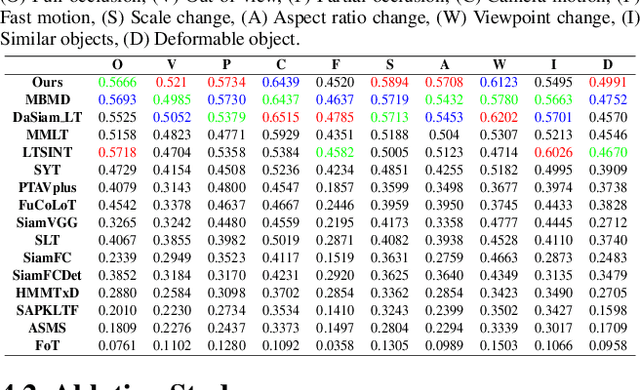
Compared with traditional short-term tracking, long-term tracking poses more challenges and is much closer to realistic applications. However, few works have been done and their performance have also been limited. In this work, we present a novel robust and real-time long-term tracking framework based on the proposed skimming and perusal modules. The perusal module consists of an effective bounding box regressor to generate a series of candidate proposals and a robust target verifier to infer the optimal candidate with its confidence score. Based on this score, our tracker determines whether the tracked object being present or absent, and then chooses the tracking strategies of local search or global search respectively in the next frame. To speed up the image-wide global search, a novel skimming module is designed to efficiently choose the most possible regions from a large number of sliding windows. Numerous experimental results on the VOT-2018 long-term and OxUvA long-term benchmarks demonstrate that the proposed method achieves the best performance and runs in real-time. The source codes are available at https://github.com/iiau-tracker/SPLT.
Fairness-Aware Online Meta-learning
Aug 21, 2021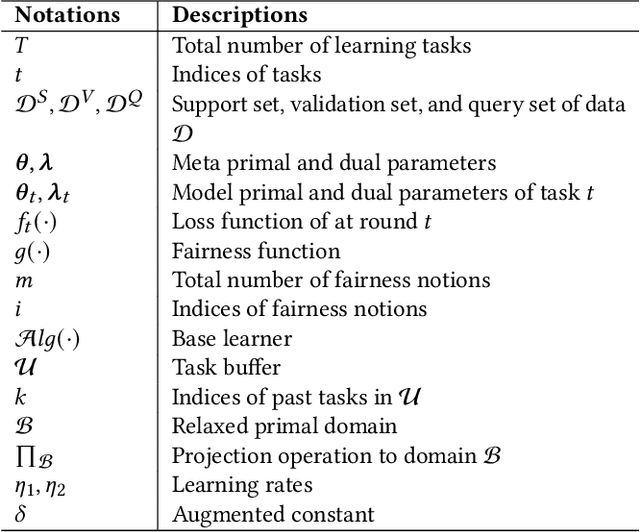
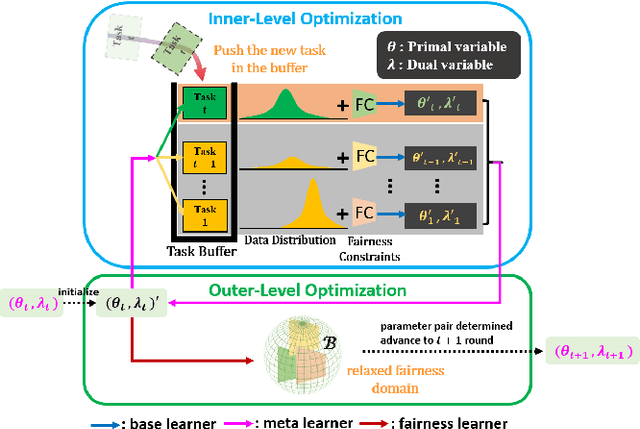

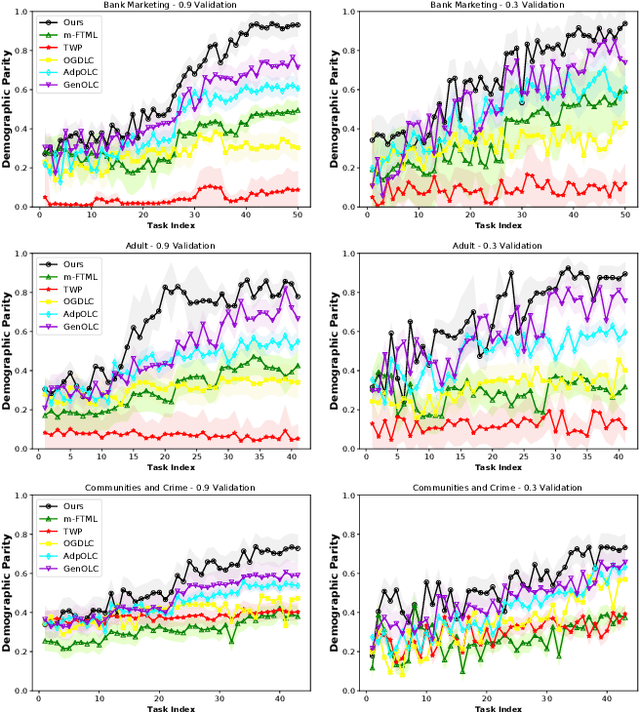
In contrast to offline working fashions, two research paradigms are devised for online learning: (1) Online Meta Learning (OML) learns good priors over model parameters (or learning to learn) in a sequential setting where tasks are revealed one after another. Although it provides a sub-linear regret bound, such techniques completely ignore the importance of learning with fairness which is a significant hallmark of human intelligence. (2) Online Fairness-Aware Learning. This setting captures many classification problems for which fairness is a concern. But it aims to attain zero-shot generalization without any task-specific adaptation. This therefore limits the capability of a model to adapt onto newly arrived data. To overcome such issues and bridge the gap, in this paper for the first time we proposed a novel online meta-learning algorithm, namely FFML, which is under the setting of unfairness prevention. The key part of FFML is to learn good priors of an online fair classification model's primal and dual parameters that are associated with the model's accuracy and fairness, respectively. The problem is formulated in the form of a bi-level convex-concave optimization. Theoretic analysis provides sub-linear upper bounds for loss regret and for violation of cumulative fairness constraints. Our experiments demonstrate the versatility of FFML by applying it to classification on three real-world datasets and show substantial improvements over the best prior work on the tradeoff between fairness and classification accuracy
Sample Efficient Detection and Classification of Adversarial Attacks via Self-Supervised Embeddings
Aug 30, 2021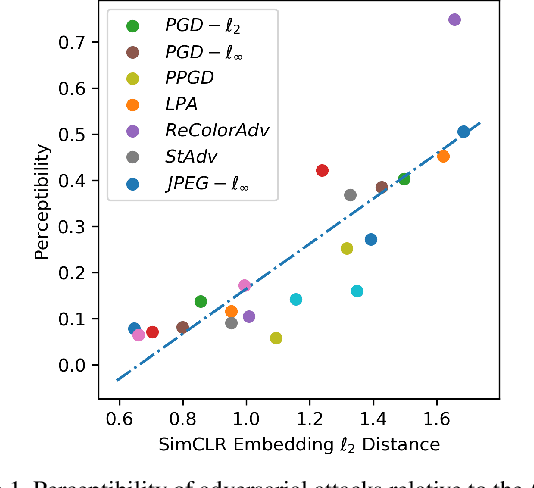
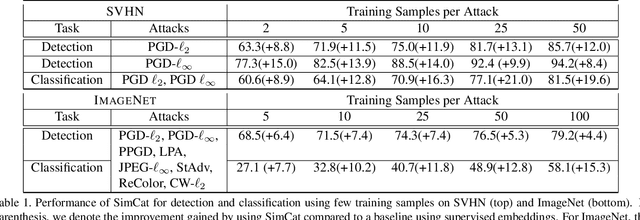
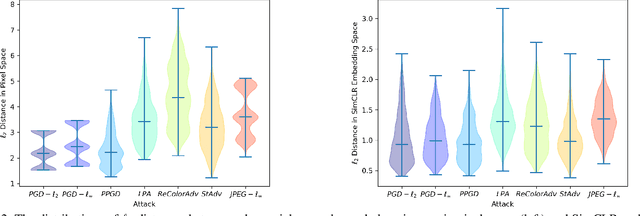

Adversarial robustness of deep models is pivotal in ensuring safe deployment in real world settings, but most modern defenses have narrow scope and expensive costs. In this paper, we propose a self-supervised method to detect adversarial attacks and classify them to their respective threat models, based on a linear model operating on the embeddings from a pre-trained self-supervised encoder. We use a SimCLR encoder in our experiments, since we show the SimCLR embedding distance is a good proxy for human perceptibility, enabling it to encapsulate many threat models at once. We call our method SimCat since it uses SimCLR encoder to catch and categorize various types of adversarial attacks, including L_p and non-L_p evasion attacks, as well as data poisonings. The simple nature of a linear classifier makes our method efficient in both time and sample complexity. For example, on SVHN, using only five pairs of clean and adversarial examples computed with a PGD-L_inf attack, SimCat's detection accuracy is over 85%. Moreover, on ImageNet, using only 25 examples from each threat model, SimCat can classify eight different attack types such as PGD-L_2, PGD-L_inf, CW-L_2, PPGD, LPA, StAdv, ReColor, and JPEG-L_inf, with over 40% accuracy. On STL10 data, we apply SimCat as a defense against poisoning attacks, such as BP, CP, FC, CLBD, HTBD, halving the success rate while using only twenty total poisons for training. We find that the detectors generalize well to unseen threat models. Lastly, we investigate the performance of our detection method under adaptive attacks and further boost its robustness against such attacks via adversarial training.
SCIDA: Self-Correction Integrated Domain Adaptation from Single- to Multi-label Aerial Images
Aug 15, 2021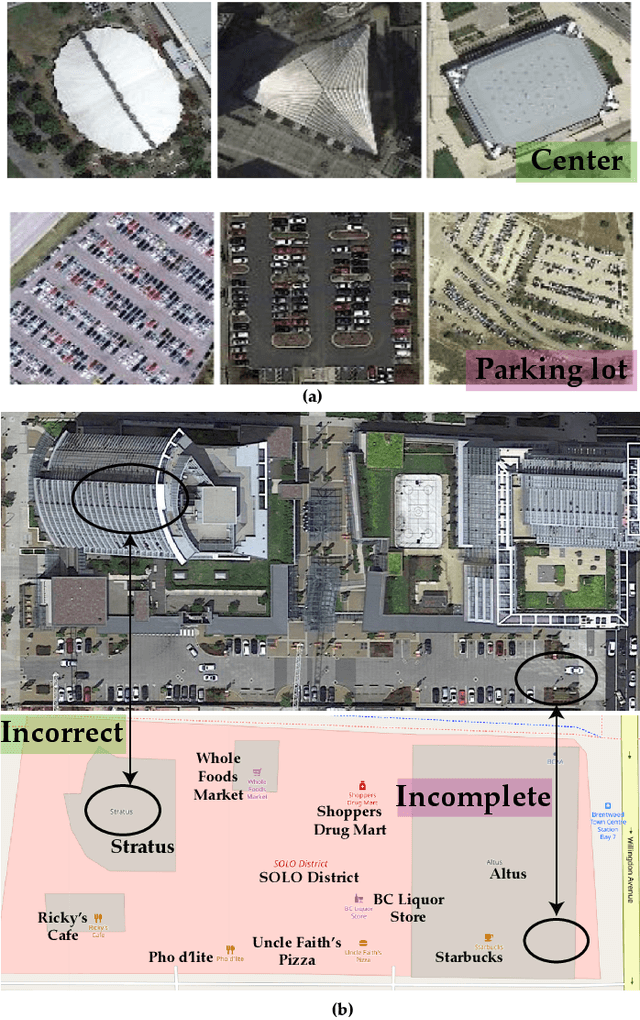
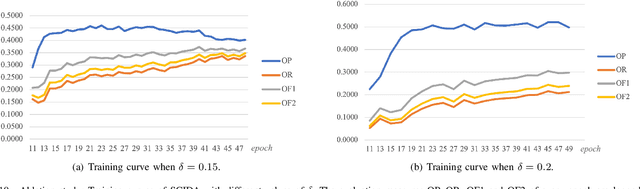
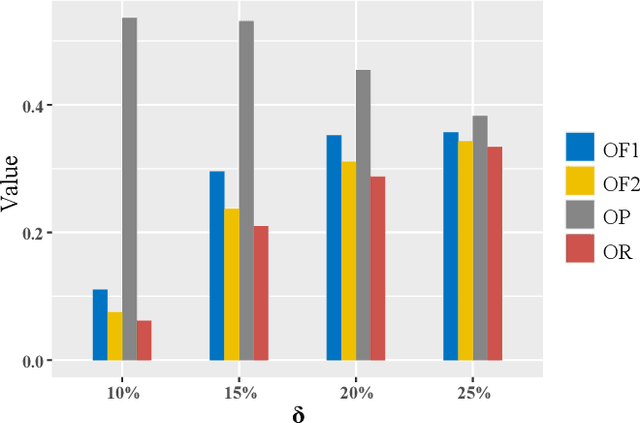
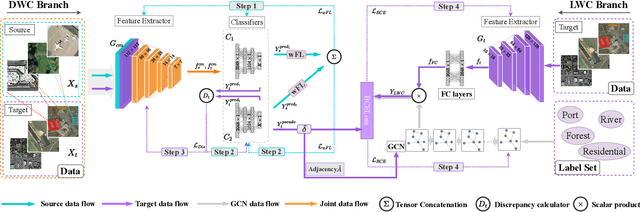
Most publicly available datasets for image classification are with single labels, while images are inherently multi-labeled in our daily life. Such an annotation gap makes many pre-trained single-label classification models fail in practical scenarios. This annotation issue is more concerned for aerial images: Aerial data collected from sensors naturally cover a relatively large land area with multiple labels, while annotated aerial datasets, which are publicly available (e.g., UCM, AID), are single-labeled. As manually annotating multi-label aerial images would be time/labor-consuming, we propose a novel self-correction integrated domain adaptation (SCIDA) method for automatic multi-label learning. SCIDA is weakly supervised, i.e., automatically learning the multi-label image classification model from using massive, publicly available single-label images. To achieve this goal, we propose a novel Label-Wise self-Correction (LWC) module to better explore underlying label correlations. This module also makes the unsupervised domain adaptation (UDA) from single- to multi-label data possible. For model training, the proposed model only uses single-label information yet requires no prior knowledge of multi-labeled data; and it predicts labels for multi-label aerial images. In our experiments, trained with single-labeled MAI-AID-s and MAI-UCM-s datasets, the proposed model is tested directly on our collected Multi-scene Aerial Image (MAI) dataset.
Learning-based Predictive Beamforming for Integrated Sensing and Communication in Vehicular Networks
Aug 26, 2021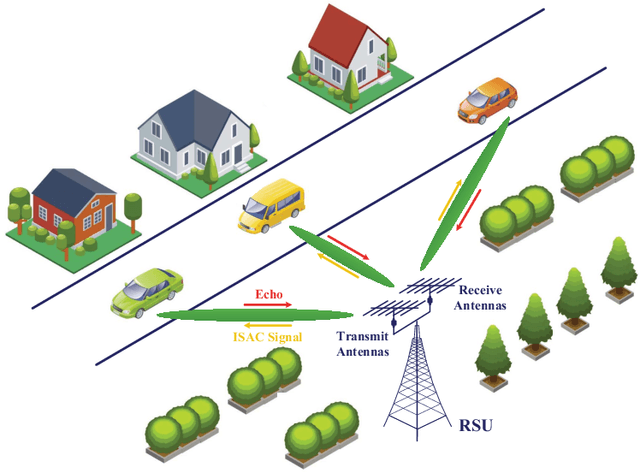
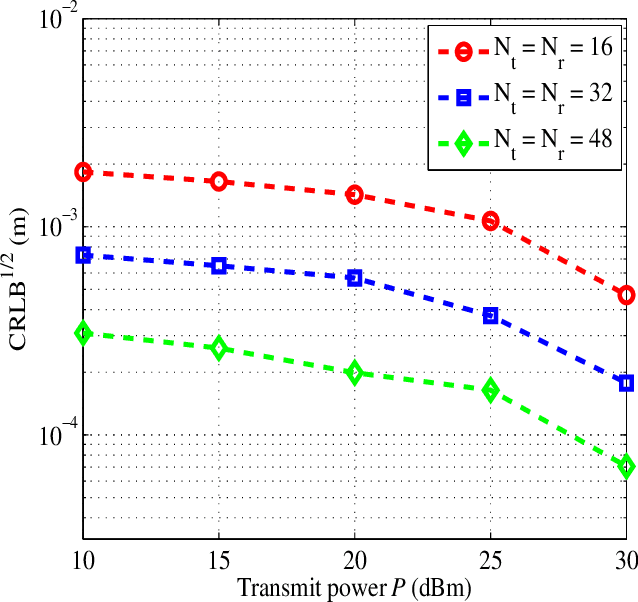
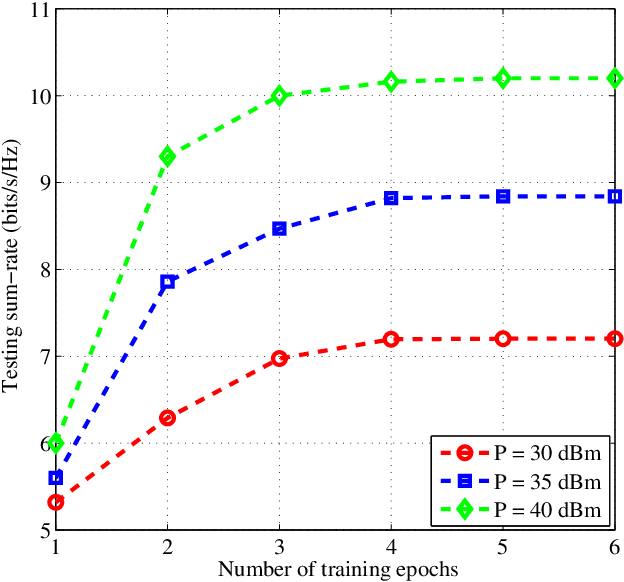
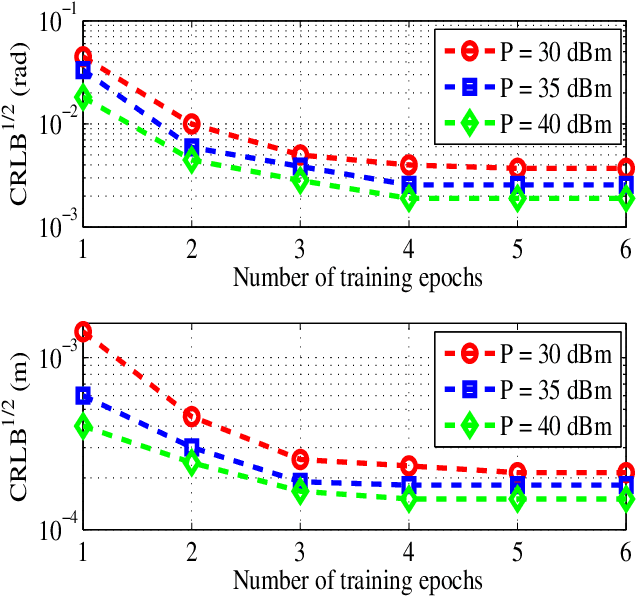
This paper investigates the integrated sensing and communication (ISAC) in vehicle-to-infrastructure (V2I) networks. To realize ISAC, an effective beamforming design is essential which however, highly depends on the availability of accurate channel tracking requiring large training overhead and computational complexity. Motivated by this, we adopt a deep learning (DL) approach to implicitly learn the features of historical channels and directly predict the beamforming matrix to be adopted for the next time slot to maximize the average achievable sum-rate of an ISAC system. The proposed method can bypass the need of explicit channel tracking process and reduce the signaling overhead significantly. To this end, a general sum-rate maximization problem with Cramer-Rao lower bounds (CRLBs)-based sensing constraints is first formulated for the considered ISAC system. Then, by exploiting the penalty method, a versatile unsupervised DL-based predictive beamforming design framework is developed to address the formulated design problem. As a realization of the developed framework, a historical channels-based convolutional long short-term memory (LSTM) network (HCL-Net) is devised for predictive beamforming in the ISAC-based V2I network. Specifically, the convolution and LSTM modules are successively adopted in the proposed HCL-Net to exploit the spatial and temporal dependencies of communication channels to further improve the learning performance. Finally, simulation results show that the proposed predictive method not only guarantees the required sensing performance, but also achieves a satisfactory sum-rate that can approach the upper bound obtained by the genie-aided scheme with the perfect instantaneous channel state information.