 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Meta-Learning for Few-Shot Time Series Classification
Sep 25, 2019
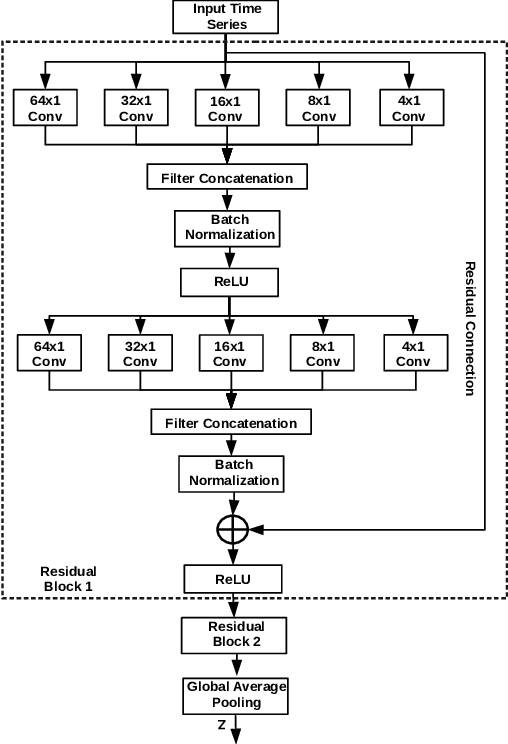
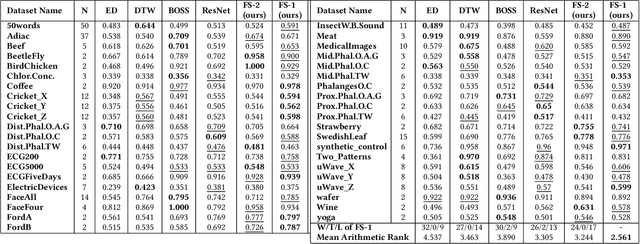
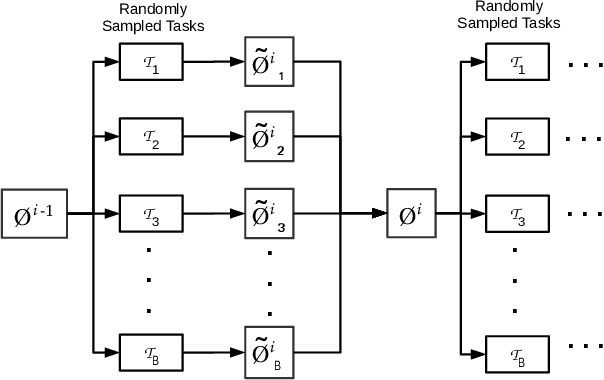
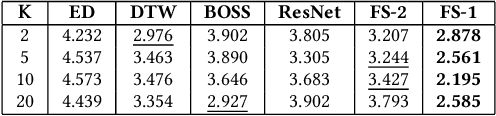
Deep neural networks (DNNs) have achieved state-of-the-art results on time series classification (TSC) tasks. In this work, we focus on leveraging DNNs in the often-encountered practical scenario where access to labeled training data is difficult, and where DNNs would be prone to overfitting. We leverage recent advancements in gradient-based meta-learning, and propose an approach to train a residual neural network with convolutional layers as a meta-learning agent for few-shot TSC. The network is trained on a diverse set of few-shot tasks sampled from various domains (e.g. healthcare, activity recognition, etc.) such that it can solve a target task from another domain using only a small number of training samples from the target task. Most existing meta-learning approaches are limited in practice as they assume a fixed number of target classes across tasks. We overcome this limitation in order to train a common agent across domains with each domain having different number of target classes, we utilize a triplet-loss based learning procedure that does not require any constraints to be enforced on the number of classes for the few-shot TSC tasks. To the best of our knowledge, we are the first to use meta-learning based pre-training for TSC. Our approach sets a new benchmark for few-shot TSC, outperforming several strong baselines on few-shot tasks sampled from 41 datasets in UCR TSC Archive. We observe that pre-training under the meta-learning paradigm allows the network to quickly adapt to new unseen tasks with small number of labeled instances.
Segmenting Hybrid Trajectories using Latent ODEs
May 09, 2021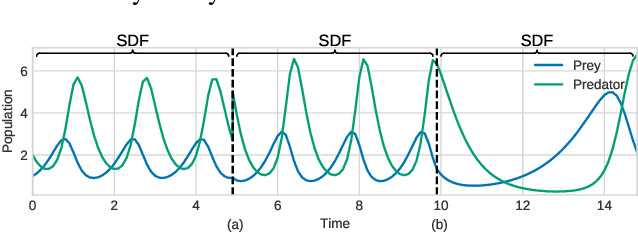
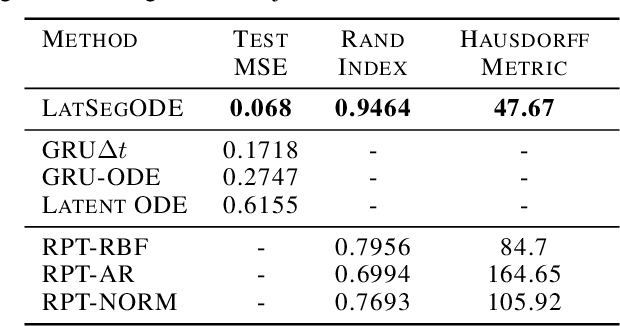
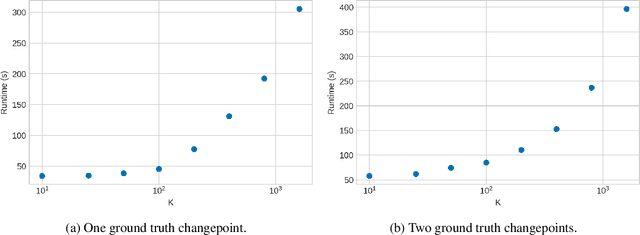
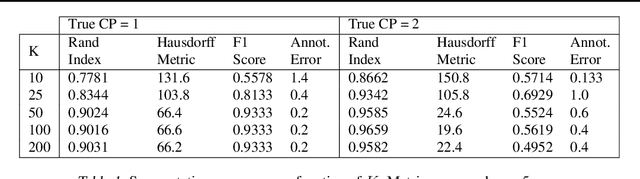
Smooth dynamics interrupted by discontinuities are known as hybrid systems and arise commonly in nature. Latent ODEs allow for powerful representation of irregularly sampled time series but are not designed to capture trajectories arising from hybrid systems. Here, we propose the Latent Segmented ODE (LatSegODE), which uses Latent ODEs to perform reconstruction and changepoint detection within hybrid trajectories featuring jump discontinuities and switching dynamical modes. Where it is possible to train a Latent ODE on the smooth dynamical flows between discontinuities, we apply the pruned exact linear time (PELT) algorithm to detect changepoints where latent dynamics restart, thereby maximizing the joint probability of a piece-wise continuous latent dynamical representation. We propose usage of the marginal likelihood as a score function for PELT, circumventing the need for model complexity-based penalization. The LatSegODE outperforms baselines in reconstructive and segmentation tasks including synthetic data sets of sine waves, Lotka Volterra dynamics, and UCI Character Trajectories.
Block-Structure Based Time-Series Models For Graph Sequences
Sep 18, 2018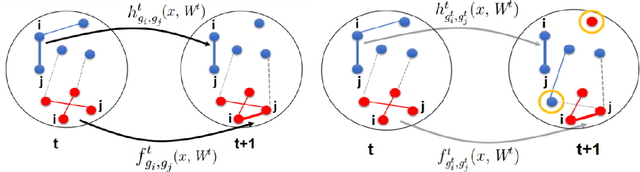


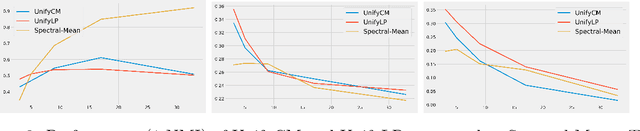
Although the computational and statistical trade-off for modeling single graphs, for instance, using block models is relatively well understood, extending such results to sequences of graphs has proven to be difficult. In this work, we take a step in this direction by proposing two models for graph sequences that capture: (a) link persistence between nodes across time, and (b) community persistence of each node across time. In the first model, we assume that the latent community of each node does not change over time, and in the second model we relax this assumption suitably. For both of these proposed models, we provide statistically and computationally efficient inference algorithms, whose unique feature is that they leverage community detection methods that work on single graphs. We also provide experimental results validating the suitability of our models and methods on synthetic and real instances.
Generating Adversarial Examples with Graph Neural Networks
May 30, 2021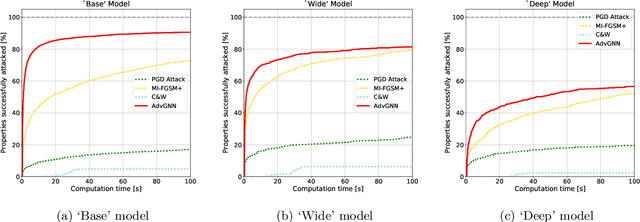
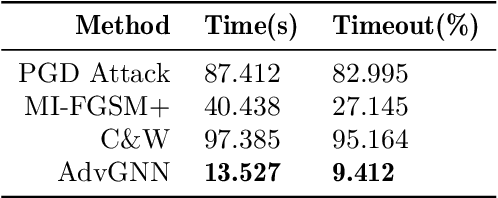
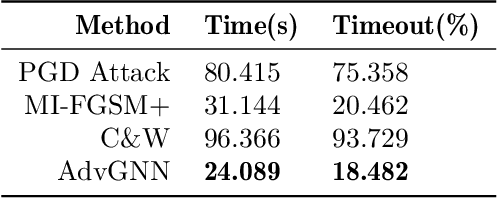
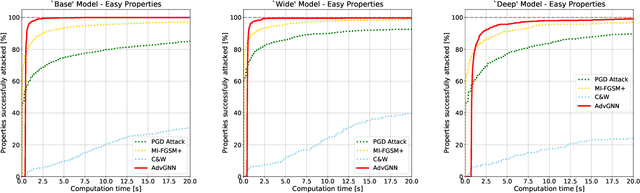
Recent years have witnessed the deployment of adversarial attacks to evaluate the robustness of Neural Networks. Past work in this field has relied on traditional optimization algorithms that ignore the inherent structure of the problem and data, or generative methods that rely purely on learning and often fail to generate adversarial examples where they are hard to find. To alleviate these deficiencies, we propose a novel attack based on a graph neural network (GNN) that takes advantage of the strengths of both approaches; we call it AdvGNN. Our GNN architecture closely resembles the network we wish to attack. During inference, we perform forward-backward passes through the GNN layers to guide an iterative procedure towards adversarial examples. During training, its parameters are estimated via a loss function that encourages the efficient computation of adversarial examples over a time horizon. We show that our method beats state-of-the-art adversarial attacks, including PGD-attack, MI-FGSM, and Carlini and Wagner attack, reducing the time required to generate adversarial examples with small perturbation norms by over 65\%. Moreover, AdvGNN achieves good generalization performance on unseen networks. Finally, we provide a new challenging dataset specifically designed to allow for a more illustrative comparison of adversarial attacks.
Input Augmentation Improves Constrained Beam Search for Neural Machine Translation: NTT at WAT 2021
Jun 10, 2021
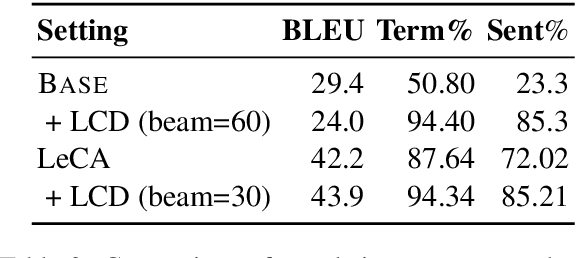
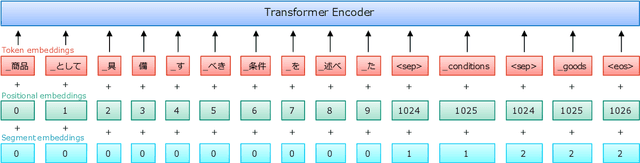
This paper describes our systems that were submitted to the restricted translation task at WAT 2021. In this task, the systems are required to output translated sentences that contain all given word constraints. Our system combined input augmentation and constrained beam search algorithms. Through experiments, we found that this combination significantly improves translation accuracy and can save inference time while containing all the constraints in the output. For both En->Ja and Ja->En, our systems obtained the best evaluation performances in automatic evaluation.
Derivative Based Proportionate Approach for Sparse Impulse Response Identification
Jul 08, 2021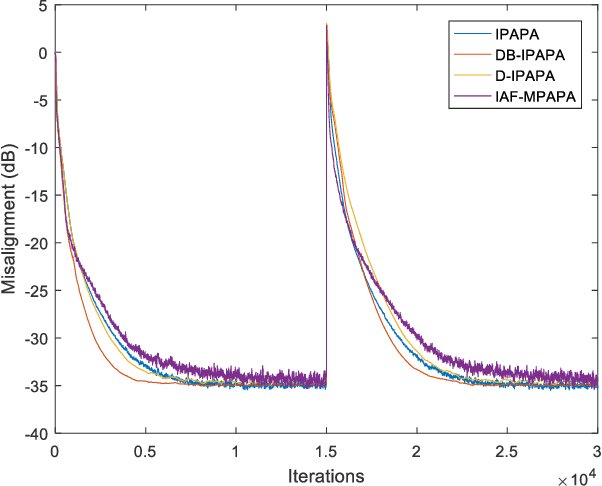
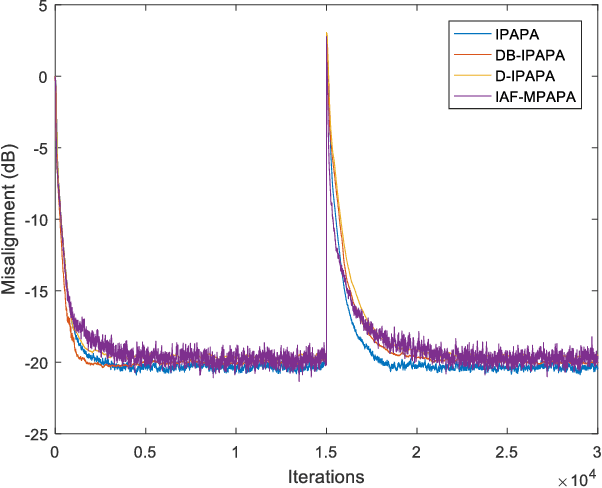
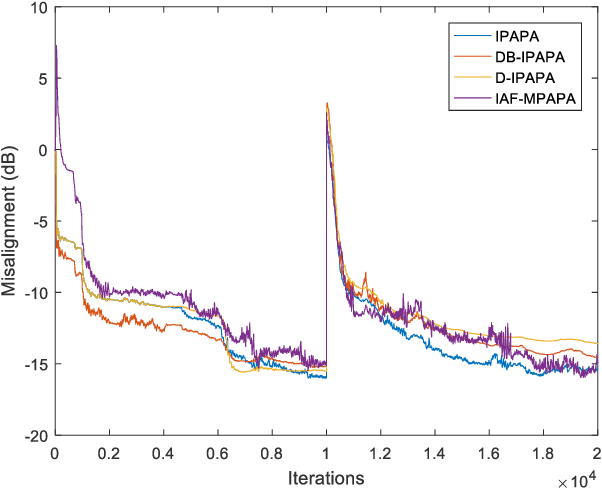
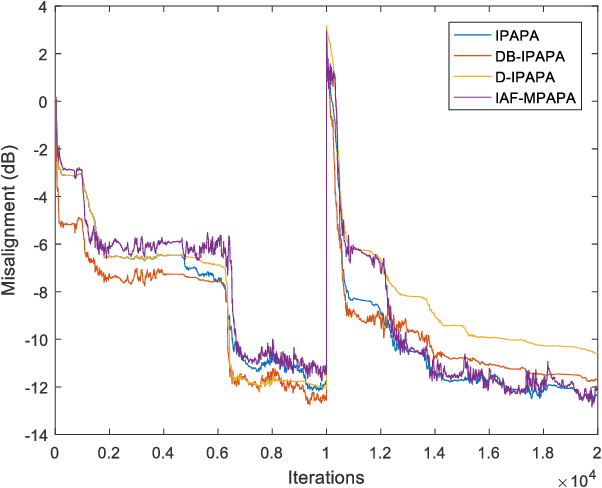
Proportionate type algorithms were developed and excessively used in the echo cancellation problems due to sparse characteristics of the echo channels. In the past, most of the attention was paid to a particular type of proportionate approach, which assigns step-sizes to filter coefficients proportional to the magnitude of the corresponding coefficient. In this letter, we propose a new proportionate type algorithm, which takes dynamic behavior of the estimated filter coefficient into account while assigning individual step-sizes to each coefficient. Proposed algorithm introduces an effective way to assign individual step-sizes using the time derivatives of the filter coefficients. Computational complexity of the proposed algorithm is similar to those of previously proposed algorithms. Simulation results have shown the improvements in the convergence rate achieved by the proposed algorithm.
Recurrent Coupled Topic Modeling over Sequential Documents
Jun 23, 2021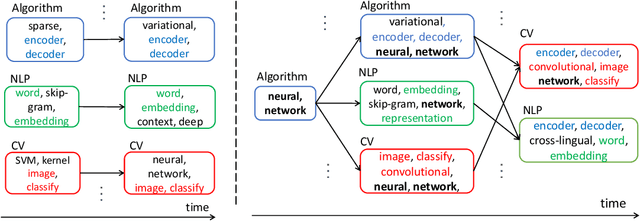
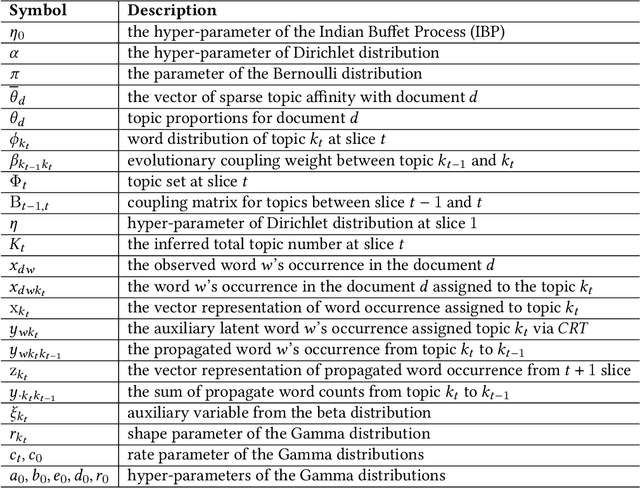
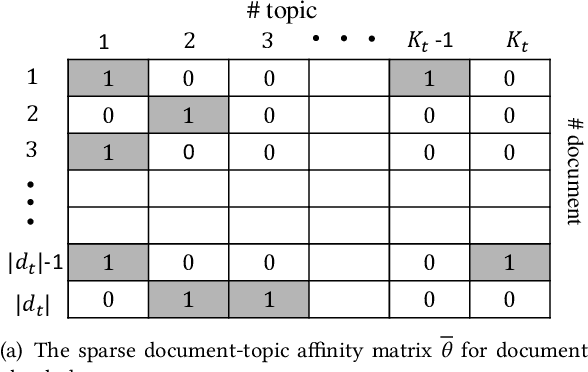
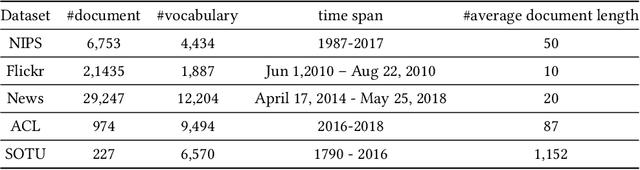
The abundant sequential documents such as online archival, social media and news feeds are streamingly updated, where each chunk of documents is incorporated with smoothly evolving yet dependent topics. Such digital texts have attracted extensive research on dynamic topic modeling to infer hidden evolving topics and their temporal dependencies. However, most of the existing approaches focus on single-topic-thread evolution and ignore the fact that a current topic may be coupled with multiple relevant prior topics. In addition, these approaches also incur the intractable inference problem when inferring latent parameters, resulting in a high computational cost and performance degradation. In this work, we assume that a current topic evolves from all prior topics with corresponding coupling weights, forming the multi-topic-thread evolution. Our method models the dependencies between evolving topics and thoroughly encodes their complex multi-couplings across time steps. To conquer the intractable inference challenge, a new solution with a set of novel data augmentation techniques is proposed, which successfully discomposes the multi-couplings between evolving topics. A fully conjugate model is thus obtained to guarantee the effectiveness and efficiency of the inference technique. A novel Gibbs sampler with a backward-forward filter algorithm efficiently learns latent timeevolving parameters in a closed-form. In addition, the latent Indian Buffet Process (IBP) compound distribution is exploited to automatically infer the overall topic number and customize the sparse topic proportions for each sequential document without bias. The proposed method is evaluated on both synthetic and real-world datasets against the competitive baselines, demonstrating its superiority over the baselines in terms of the low per-word perplexity, high coherent topics, and better document time prediction.
Robust Model-based Reinforcement Learning for Autonomous Greenhouse Control
Aug 26, 2021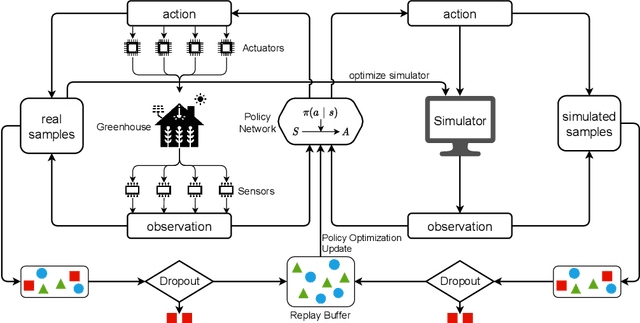
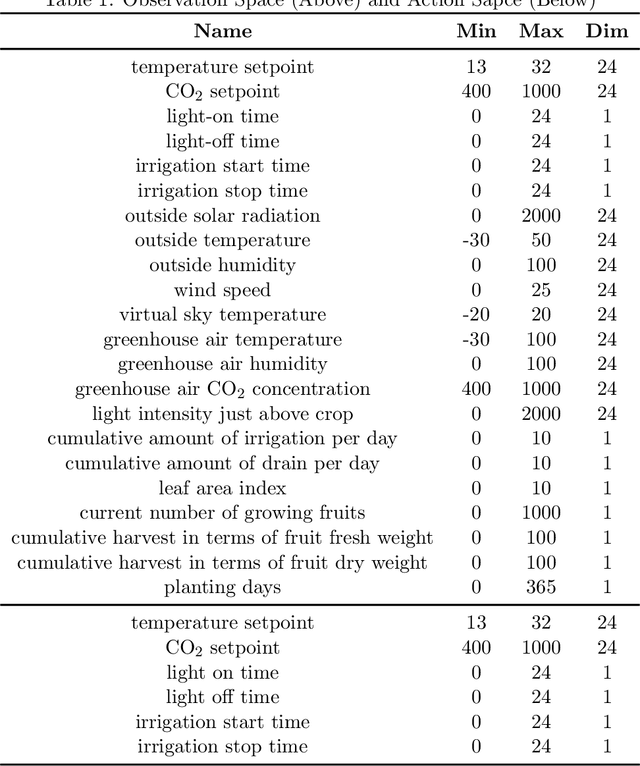

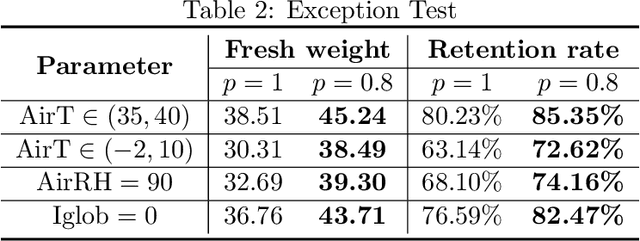
Due to the high efficiency and less weather dependency, autonomous greenhouses provide an ideal solution to meet the increasing demand for fresh food. However, managers are faced with some challenges in finding appropriate control strategies for crop growth, since the decision space of the greenhouse control problem is an astronomical number. Therefore, an intelligent closed-loop control framework is highly desired to generate an automatic control policy. As a powerful tool for optimal control, reinforcement learning (RL) algorithms can surpass human beings' decision-making and can also be seamlessly integrated into the closed-loop control framework. However, in complex real-world scenarios such as agricultural automation control, where the interaction with the environment is time-consuming and expensive, the application of RL algorithms encounters two main challenges, i.e., sample efficiency and safety. Although model-based RL methods can greatly mitigate the efficiency problem of greenhouse control, the safety problem has not got too much attention. In this paper, we present a model-based robust RL framework for autonomous greenhouse control to meet the sample efficiency and safety challenges. Specifically, our framework introduces an ensemble of environment models to work as a simulator and assist in policy optimization, thereby addressing the low sample efficiency problem. As for the safety concern, we propose a sample dropout module to focus more on worst-case samples, which can help improve the adaptability of the greenhouse planting policy in extreme cases. Experimental results demonstrate that our approach can learn a more effective greenhouse planting policy with better robustness than existing methods.
FisheyeMultiNet: Real-time Multi-task Learning Architecture for Surround-view Automated Parking System
Dec 23, 2019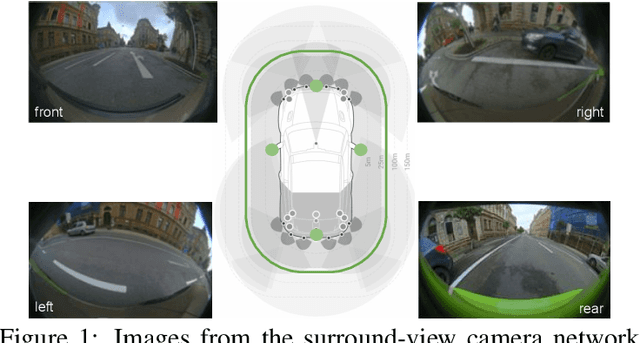
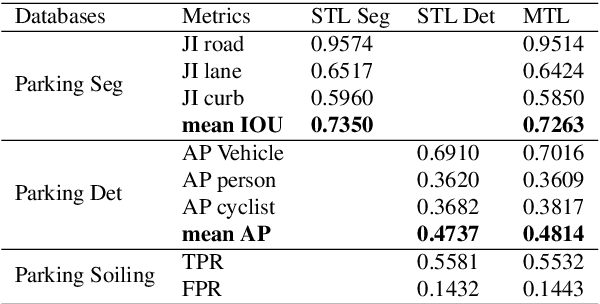
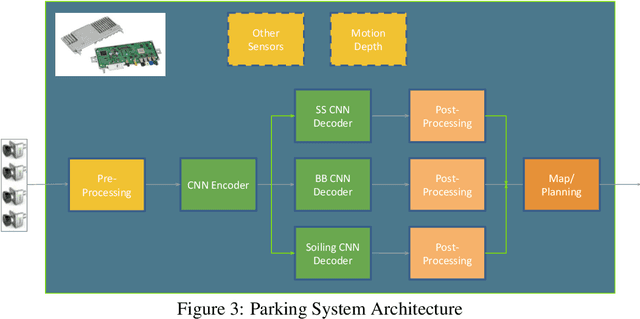
Automated Parking is a low speed manoeuvring scenario which is quite unstructured and complex, requiring full 360{\deg} near-field sensing around the vehicle. In this paper, we discuss the design and implementation of an automated parking system from the perspective of camera based deep learning algorithms. We provide a holistic overview of an industrial system covering the embedded system, use cases and the deep learning architecture. We demonstrate a real-time multi-task deep learning network called FisheyeMultiNet, which detects all the necessary objects for parking on a low-power embedded system. FisheyeMultiNet runs at 15 fps for 4 cameras and it has three tasks namely object detection, semantic segmentation and soiling detection. To encourage further research, we release a partial dataset of 5,000 images containing semantic segmentation and bounding box detection ground truth via WoodScape project \cite{yogamani2019woodscape}.
'Skimming-Perusal' Tracking: A Framework for Real-Time and Robust Long-term Tracking
Sep 04, 2019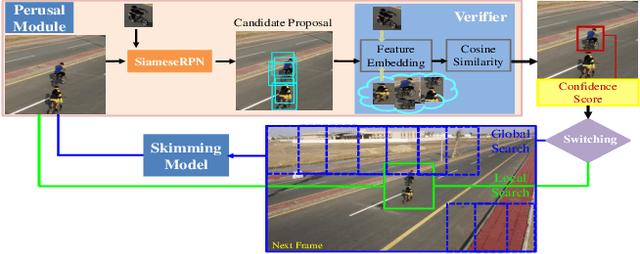
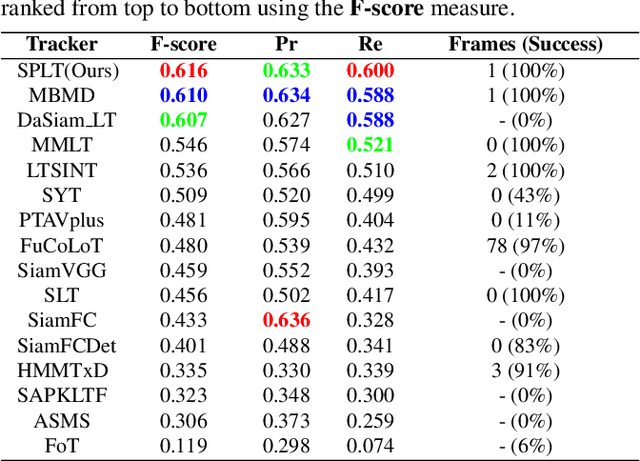
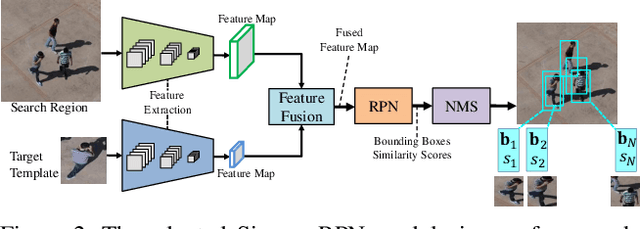
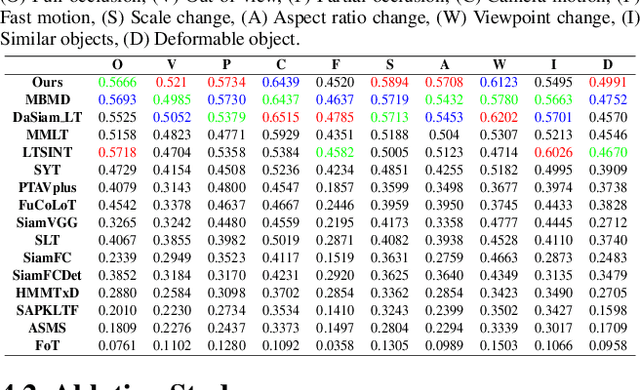
Compared with traditional short-term tracking, long-term tracking poses more challenges and is much closer to realistic applications. However, few works have been done and their performance have also been limited. In this work, we present a novel robust and real-time long-term tracking framework based on the proposed skimming and perusal modules. The perusal module consists of an effective bounding box regressor to generate a series of candidate proposals and a robust target verifier to infer the optimal candidate with its confidence score. Based on this score, our tracker determines whether the tracked object being present or absent, and then chooses the tracking strategies of local search or global search respectively in the next frame. To speed up the image-wide global search, a novel skimming module is designed to efficiently choose the most possible regions from a large number of sliding windows. Numerous experimental results on the VOT-2018 long-term and OxUvA long-term benchmarks demonstrate that the proposed method achieves the best performance and runs in real-time. The source codes are available at https://github.com/iiau-tracker/SPLT.