 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Knowledge-intensive Language Understanding for Explainable AI
Aug 02, 2021
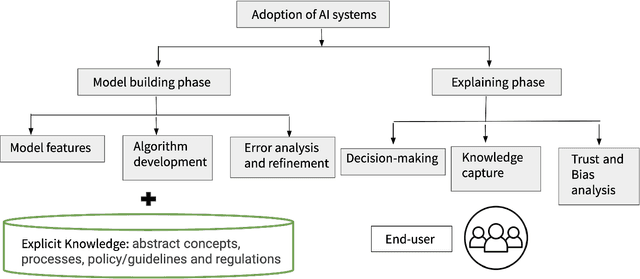

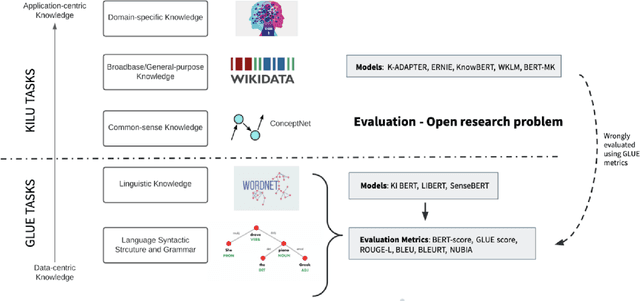
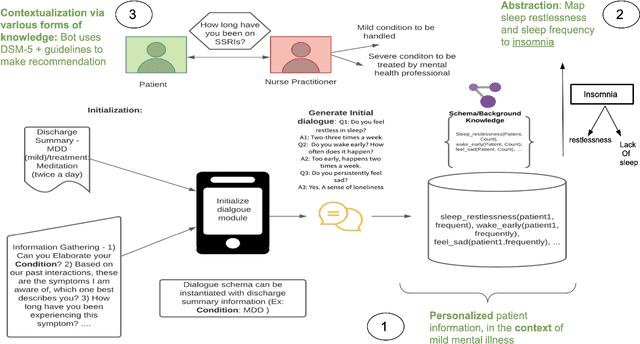
AI systems have seen significant adoption in various domains. At the same time, further adoption in some domains is hindered by inability to fully trust an AI system that it will not harm a human. Besides the concerns for fairness, privacy, transparency, and explainability are key to developing trusts in AI systems. As stated in describing trustworthy AI "Trust comes through understanding. How AI-led decisions are made and what determining factors were included are crucial to understand." The subarea of explaining AI systems has come to be known as XAI. Multiple aspects of an AI system can be explained; these include biases that the data might have, lack of data points in a particular region of the example space, fairness of gathering the data, feature importances, etc. However, besides these, it is critical to have human-centered explanations that are directly related to decision-making similar to how a domain expert makes decisions based on "domain knowledge," that also include well-established, peer-validated explicit guidelines. To understand and validate an AI system's outcomes (such as classification, recommendations, predictions), that lead to developing trust in the AI system, it is necessary to involve explicit domain knowledge that humans understand and use.
Conditional Neural Relational Inference for Interacting Systems
Jun 21, 2021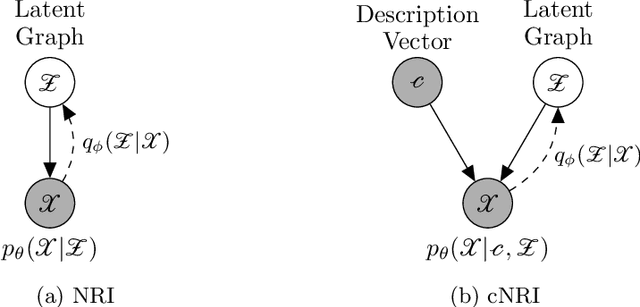
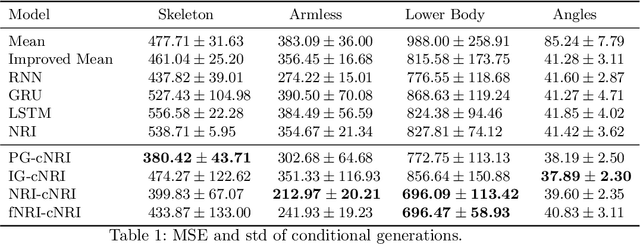
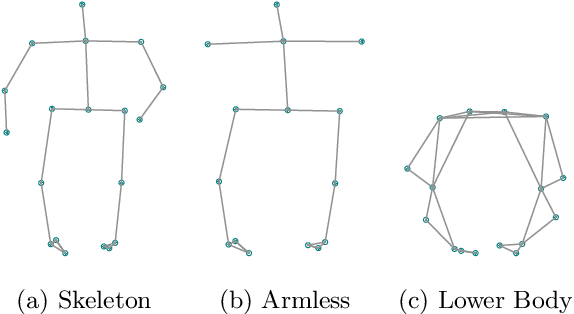
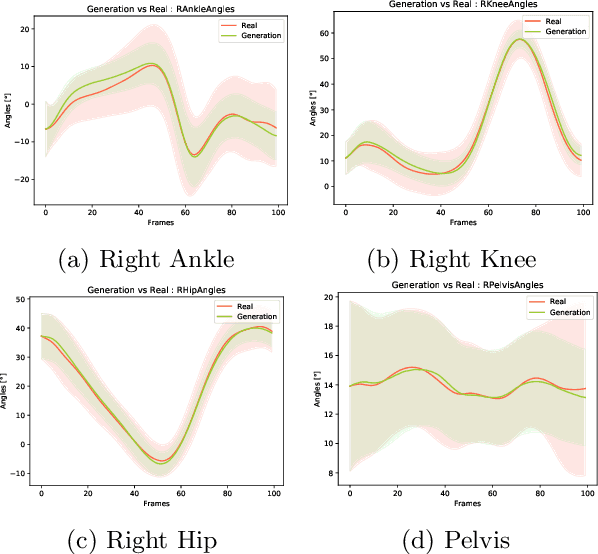
In this work, we want to learn to model the dynamics of similar yet distinct groups of interacting objects. These groups follow some common physical laws that exhibit specificities that are captured through some vectorial description. We develop a model that allows us to do conditional generation from any such group given its vectorial description. Unlike previous work on learning dynamical systems that can only do trajectory completion and require a part of the trajectory dynamics to be provided as input in generation time, we do generation using only the conditioning vector with no access to generation time's trajectories. We evaluate our model in the setting of modeling human gait and, in particular pathological human gait.
A preliminary study on evaluating Consultation Notes with Post-Editing
Apr 09, 2021

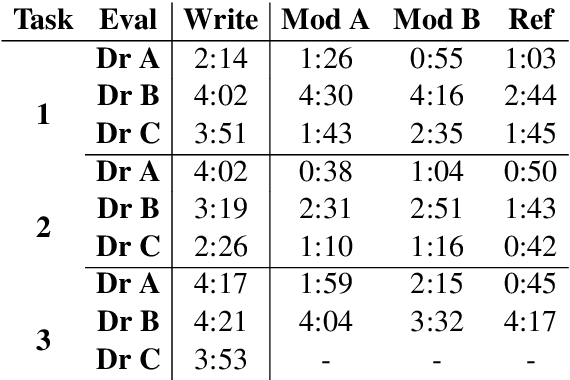
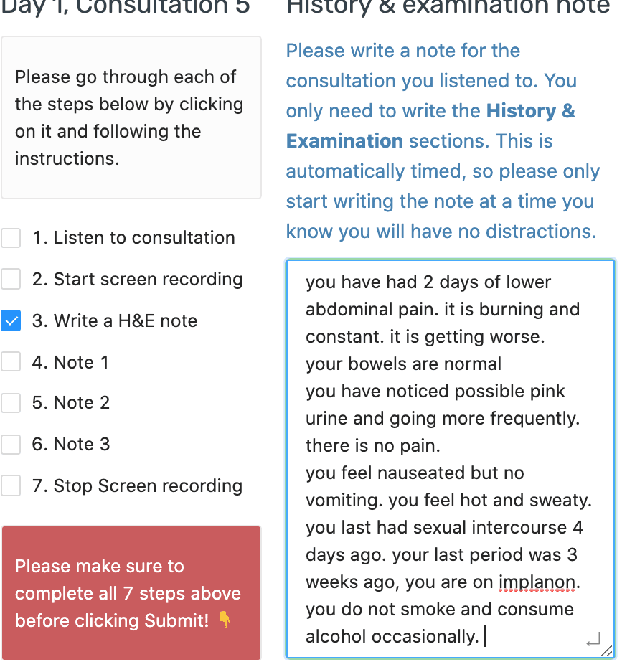
Automatic summarisation has the potential to aid physicians in streamlining clerical tasks such as note taking. But it is notoriously difficult to evaluate these systems and demonstrate that they are safe to be used in a clinical setting. To circumvent this issue, we propose a semi-automatic approach whereby physicians post-edit generated notes before submitting them. We conduct a preliminary study on the time saving of automatically generated consultation notes with post-editing. Our evaluators are asked to listen to mock consultations and to post-edit three generated notes. We time this and find that it is faster than writing the note from scratch. We present insights and lessons learnt from this experiment.
FuseMODNet: Real-Time Camera and LiDAR based Moving Object Detection for robust low-light Autonomous Driving
Nov 21, 2019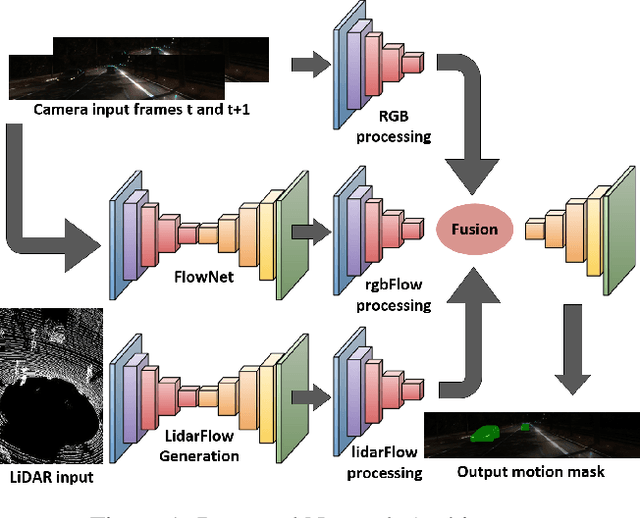
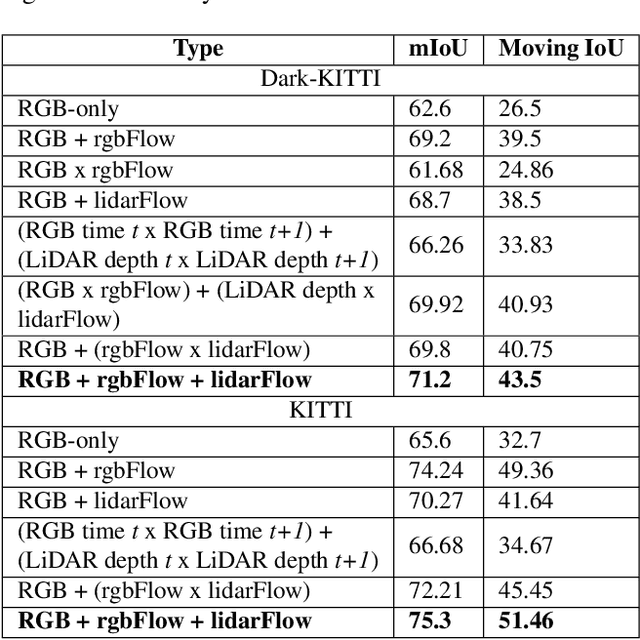


Moving object detection is a critical task for autonomous vehicles. As dynamic objects represent higher collision risk than static ones, our own ego-trajectories have to be planned attending to the future states of the moving elements of the scene. Motion can be perceived using temporal information such as optical flow. Conventional optical flow computation is based on camera sensors only, which makes it prone to failure in conditions with low illumination. On the other hand, LiDAR sensors are independent of illumination, as they measure the time-of-flight of their own emitted lasers. In this work, we propose a robust and real-time CNN architecture for Moving Object Detection (MOD) under low-light conditions by capturing motion information from both camera and LiDAR sensors. We demonstrate the impact of our algorithm on KITTI dataset where we simulate a low-light environment creating a novel dataset "Dark KITTI". We obtain a 10.1% relative improvement on Dark-KITTI, and a 4.25% improvement on standard KITTI relative to our baselines. The proposed algorithm runs at 18 fps on a standard desktop GPU using $256\times1224$ resolution images.
Triangular body-cover model of the vocal folds with coordinated activation of five intrinsic laryngeal muscles with applications to vocal hyperfunction
Aug 02, 2021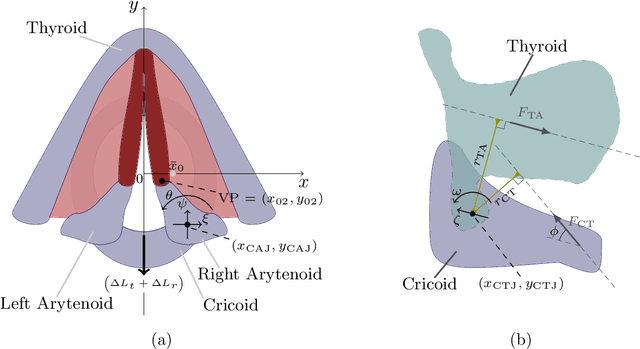
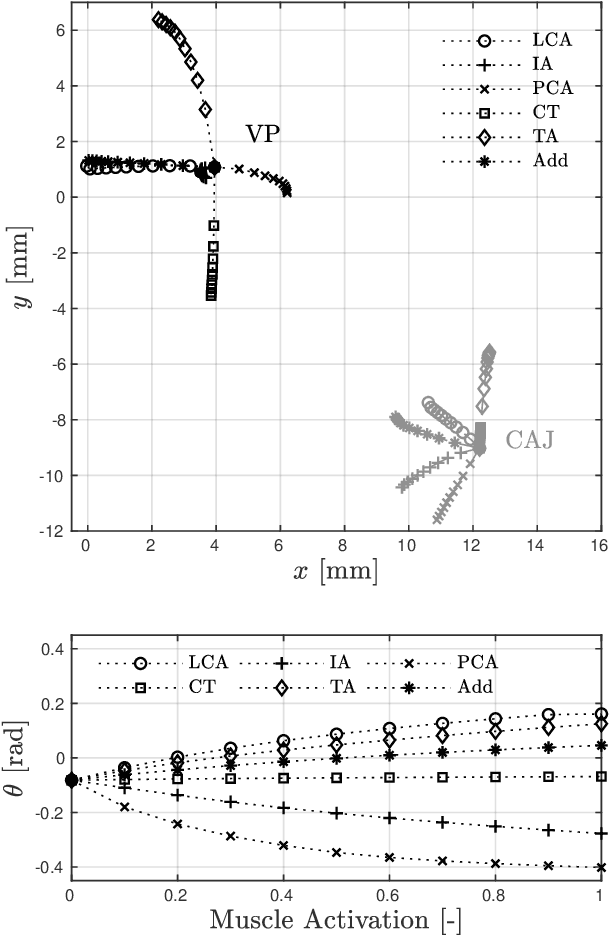
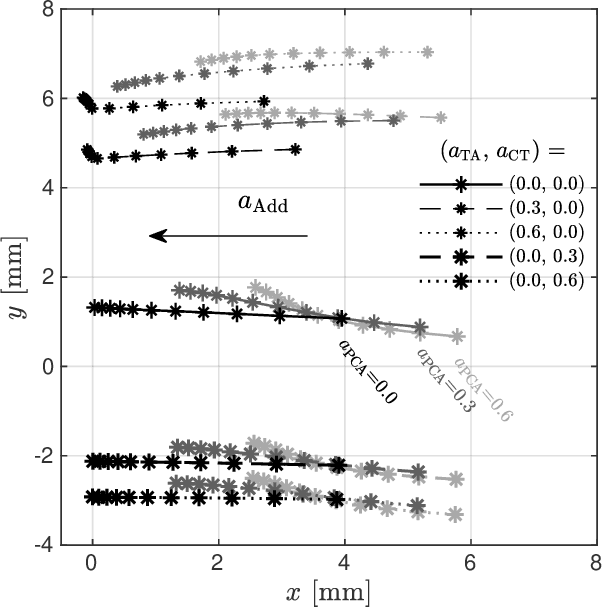
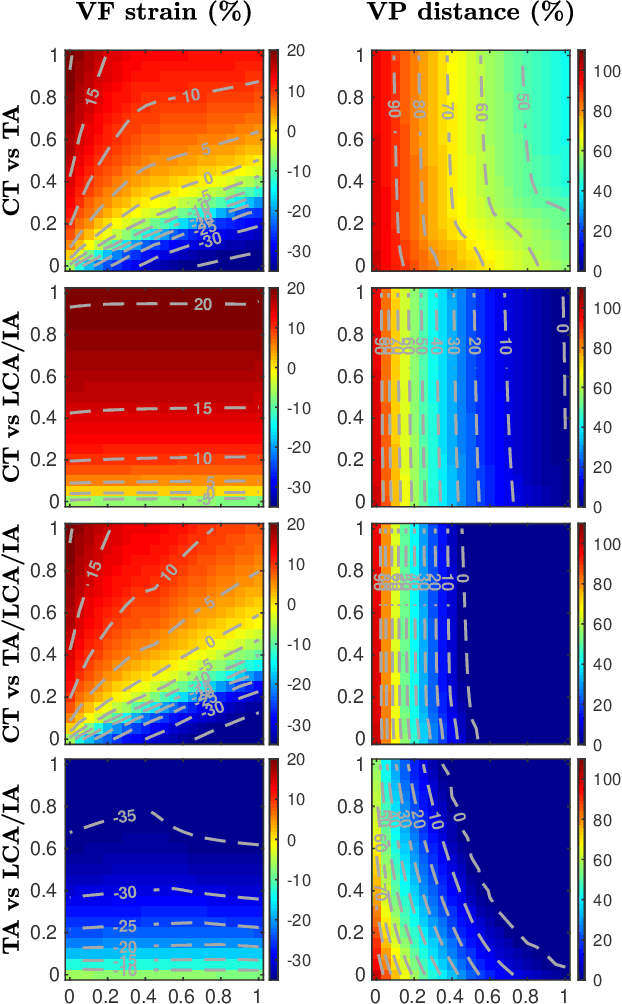
Poor laryngeal muscle coordination that results in abnormal glottal posturing is believed to be a primary etiologic factor in common voice disorders such as non-phonotraumatic vocal hyperfunction. An imbalance in the activity of antagonistic laryngeal muscles is hypothesized to play a key role in the alteration of normal vocal fold biomechanics that results in the dysphonia associated with such disorders. Current low-order models are unsatisfactory to test this hypothesis since they do not capture the co-contraction of antagonist laryngeal muscle pairs. To address this limitation, a scheme for controlling a self-sustained triangular body-cover model with intrinsic muscle control is introduced. The approach builds upon prior efforts and allows for exploring the role of antagonistic muscle pairs in phonation. The proposed scheme is illustrated through the ample agreement with prior studies using finite element models, excised larynges, and clinical studies in sustained and time-varying vocal gestures. Pilot simulations of abnormal scenarios illustrated that poorly regulated and elevated muscle activities result in more abducted prephonatory posturing, which lead to inefficient phonation and subglottal pressure compensation to regain loudness. The proposed tool is deemed sufficiently accurate and flexible for future comprehensive investigations of non-phonotraumatic vocal hyperfunction and other laryngeal motor control disorders.
An Efficient One-Class SVM for Anomaly Detection in the Internet of Things
Apr 22, 2021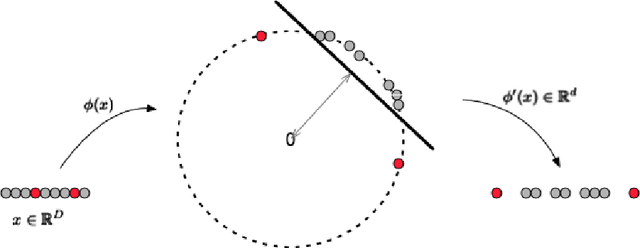
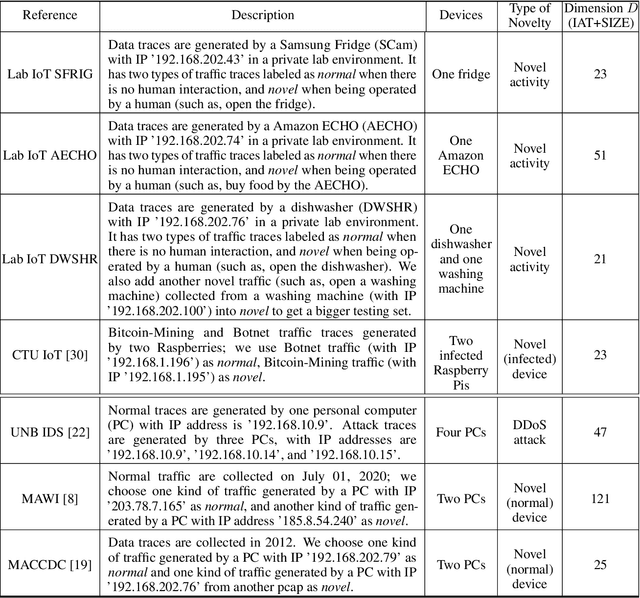


Insecure Internet of things (IoT) devices pose significant threats to critical infrastructure and the Internet at large; detecting anomalous behavior from these devices remains of critical importance, but fast, efficient, accurate anomaly detection (also called "novelty detection") for these classes of devices remains elusive. One-Class Support Vector Machines (OCSVM) are one of the state-of-the-art approaches for novelty detection (or anomaly detection) in machine learning, due to their flexibility in fitting complex nonlinear boundaries between {normal} and {novel} data. IoT devices in smart homes and cities and connected building infrastructure present a compelling use case for novelty detection with OCSVM due to the variety of devices, traffic patterns, and types of anomalies that can manifest in such environments. Much previous research has thus applied OCSVM to novelty detection for IoT. Unfortunately, conventional OCSVMs introduce significant memory requirements and are computationally expensive at prediction time as the size of the train set grows, requiring space and time that scales with the number of training points. These memory and computational constraints can be prohibitive in practical, real-world deployments, where large training sets are typically needed to develop accurate models when fitting complex decision boundaries. In this work, we extend so-called Nystr\"om and (Gaussian) Sketching approaches to OCSVM, by combining these methods with clustering and Gaussian mixture models to achieve significant speedups in prediction time and space in various IoT settings, without sacrificing detection accuracy.
ALLNet: A Hybrid Convolutional Neural Network to Improve Diagnosis of Acute Lymphocytic Leukemia (ALL) in White Blood Cells
Aug 18, 2021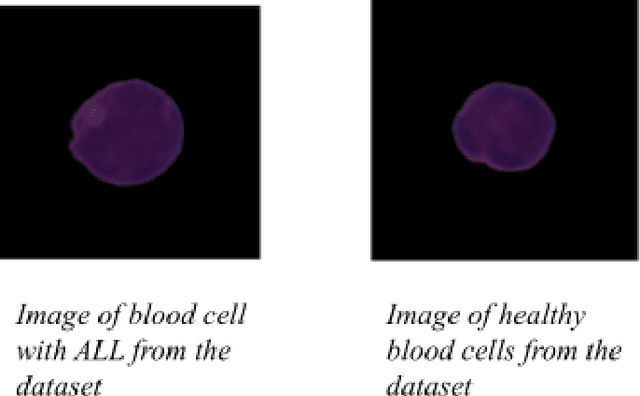
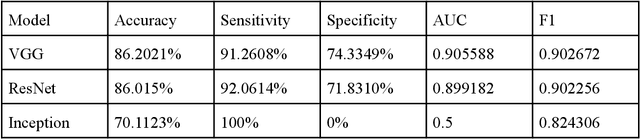
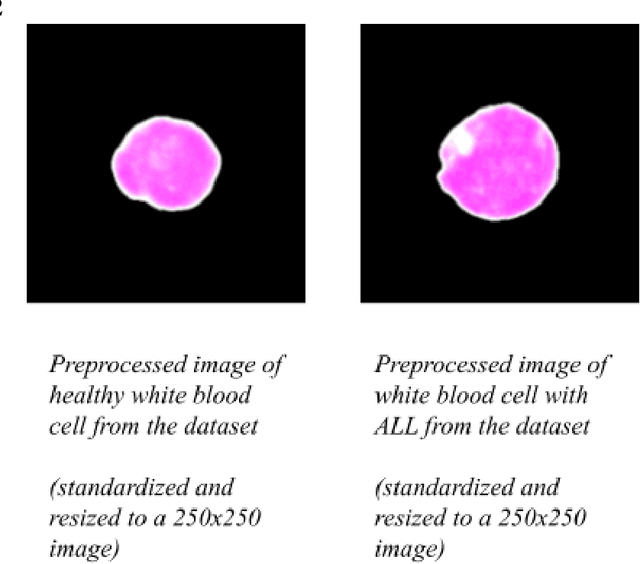
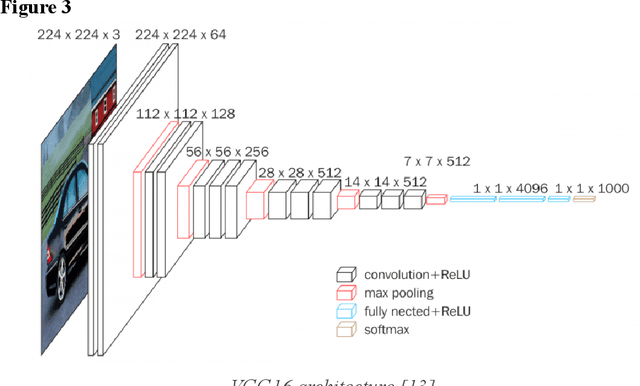
Due to morphological similarity at the microscopic level, making an accurate and time-sensitive distinction between blood cells affected by Acute Lymphocytic Leukemia (ALL) and their healthy counterparts calls for the usage of machine learning architectures. However, three of the most common models, VGG, ResNet, and Inception, each come with their own set of flaws with room for improvement which demands the need for a superior model. ALLNet, the proposed hybrid convolutional neural network architecture, consists of a combination of the VGG, ResNet, and Inception models. The ALL Challenge dataset of ISBI 2019 (available here) contains 10,691 images of white blood cells which were used to train and test the models. 7,272 of the images in the dataset are of cells with ALL and 3,419 of them are of healthy cells. Of the images, 60% were used to train the model, 20% were used for the cross-validation set, and 20% were used for the test set. ALLNet outperformed the VGG, ResNet, and the Inception models across the board, achieving an accuracy of 92.6567%, a sensitivity of 95.5304%, a specificity of 85.9155%, an AUC score of 0.966347, and an F1 score of 0.94803 in the cross-validation set. In the test set, ALLNet achieved an accuracy of 92.0991%, a sensitivity of 96.5446%, a specificity of 82.8035%, an AUC score of 0.959972, and an F1 score of 0.942963. The utilization of ALLNet in the clinical workspace can better treat the thousands of people suffering from ALL across the world, many of whom are children.
A persistent homology-based topological loss for CNN-based multi-class segmentation of CMR
Jul 27, 2021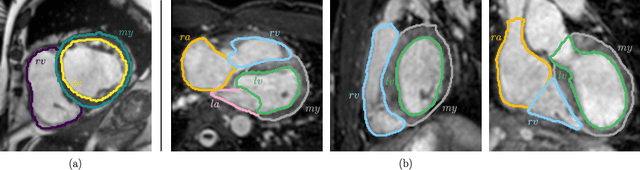

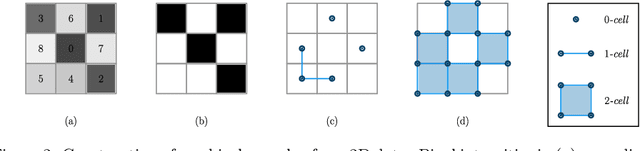

Multi-class segmentation of cardiac magnetic resonance (CMR) images seeks a separation of data into anatomical components with known structure and configuration. The most popular CNN-based methods are optimised using pixel wise loss functions, ignorant of the spatially extended features that characterise anatomy. Therefore, whilst sharing a high spatial overlap with the ground truth, inferred CNN-based segmentations can lack coherence, including spurious connected components, holes and voids. Such results are implausible, violating anticipated anatomical topology. In response, (single-class) persistent homology-based loss functions have been proposed to capture global anatomical features. Our work extends these approaches to the task of multi-class segmentation. Building an enriched topological description of all class labels and class label pairs, our loss functions make predictable and statistically significant improvements in segmentation topology using a CNN-based post-processing framework. We also present (and make available) a highly efficient implementation based on cubical complexes and parallel execution, enabling practical application within high resolution 3D data for the first time. We demonstrate our approach on 2D short axis and 3D whole heart CMR segmentation, advancing a detailed and faithful analysis of performance on two publicly available datasets.
Value Function is All You Need: A Unified Learning Framework for Ride Hailing Platforms
Jun 04, 2021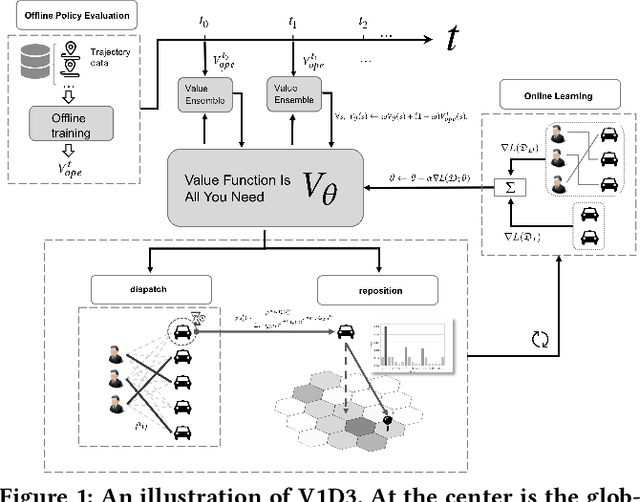
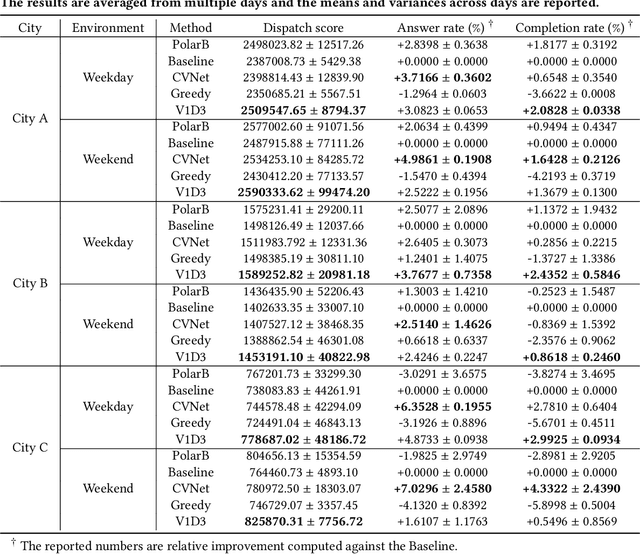
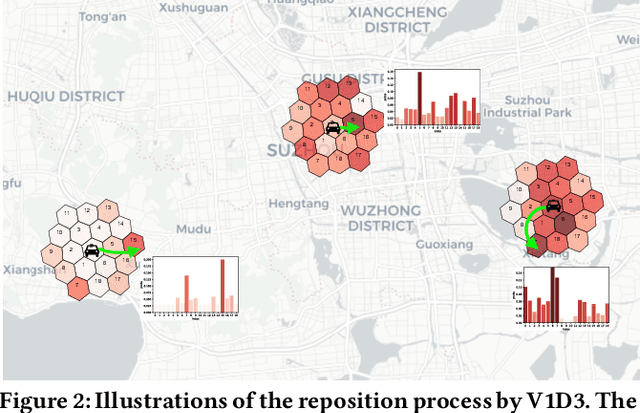
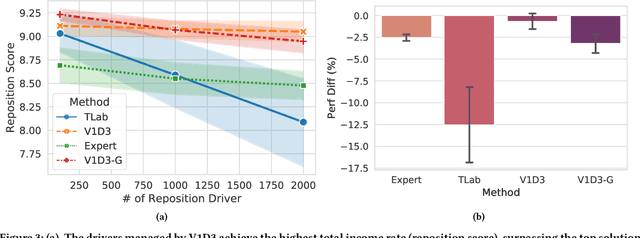
Large ride-hailing platforms, such as DiDi, Uber and Lyft, connect tens of thousands of vehicles in a city to millions of ride demands throughout the day, providing great promises for improving transportation efficiency through the tasks of order dispatching and vehicle repositioning. Existing studies, however, usually consider the two tasks in simplified settings that hardly address the complex interactions between the two, the real-time fluctuations between supply and demand, and the necessary coordinations due to the large-scale nature of the problem. In this paper we propose a unified value-based dynamic learning framework (V1D3) for tackling both tasks. At the center of the framework is a globally shared value function that is updated continuously using online experiences generated from real-time platform transactions. To improve the sample-efficiency and the robustness, we further propose a novel periodic ensemble method combining the fast online learning with a large-scale offline training scheme that leverages the abundant historical driver trajectory data. This allows the proposed framework to adapt quickly to the highly dynamic environment, to generalize robustly to recurrent patterns and to drive implicit coordinations among the population of managed vehicles. Extensive experiments based on real-world datasets show considerably improvements over other recently proposed methods on both tasks. Particularly, V1D3 outperforms the first prize winners of both dispatching and repositioning tracks in the KDD Cup 2020 RL competition, achieving state-of-the-art results on improving both total driver income and user experience related metrics.
Enforcing Consistency in Weakly Supervised Semantic Parsing
Jul 13, 2021
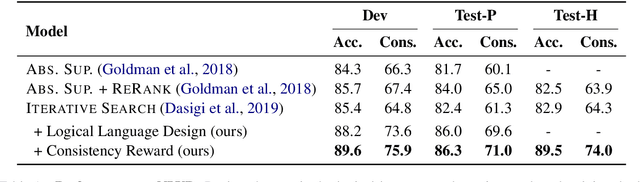

The predominant challenge in weakly supervised semantic parsing is that of spurious programs that evaluate to correct answers for the wrong reasons. Prior work uses elaborate search strategies to mitigate the prevalence of spurious programs; however, they typically consider only one input at a time. In this work we explore the use of consistency between the output programs for related inputs to reduce the impact of spurious programs. We bias the program search (and thus the model's training signal) towards programs that map the same phrase in related inputs to the same sub-parts in their respective programs. Additionally, we study the importance of designing logical formalisms that facilitate this kind of consAistency-based training. We find that a more consistent formalism leads to improved model performance even without consistency-based training. When combined together, these two insights lead to a 10% absolute improvement over the best prior result on the Natural Language Visual Reasoning dataset.