 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Pedestrian Path Modification Mobile Tool for COVID-19 Social Distancing for Use in Multi-Modal Trip Navigation
May 08, 2021
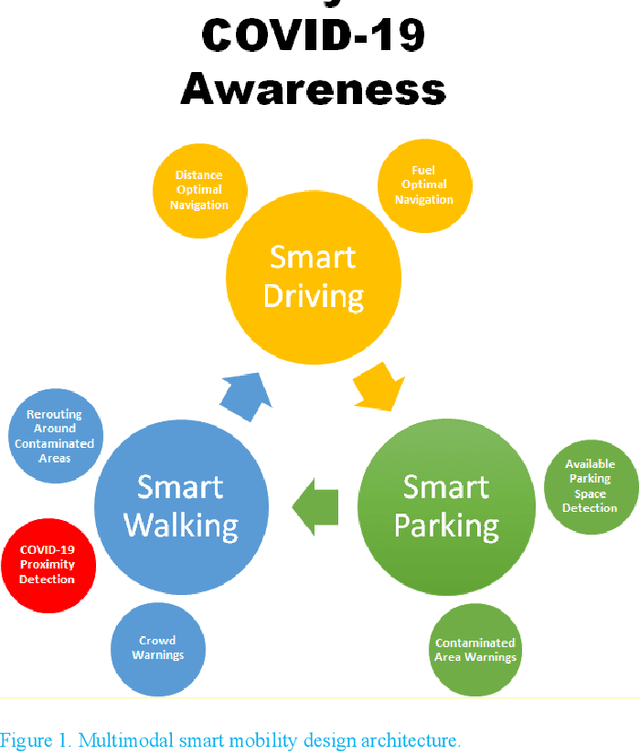
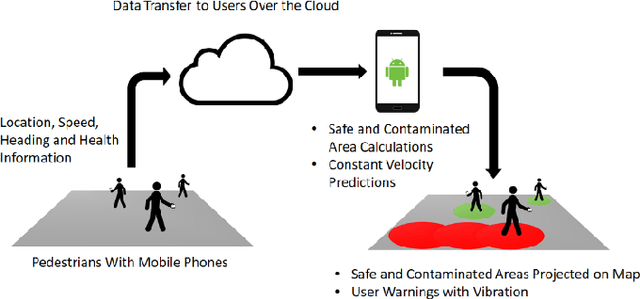
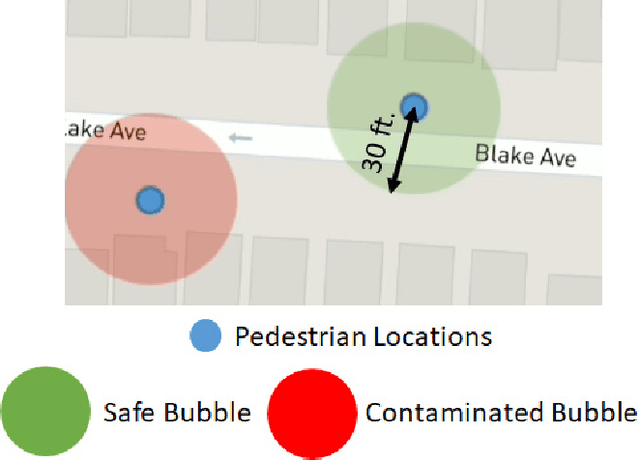
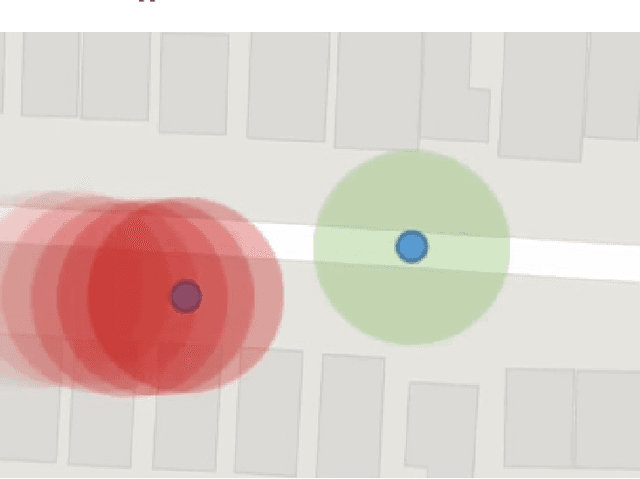
The novel Corona virus pandemic is one of the biggest worldwide problems right now. While hygiene and wearing masks make up a large portion of the currently suggested precautions by the Centers for Disease Control and Prevention (CDC) and World Health Organization (WHO), social distancing is another and arguably the most important precaution that would protect people since the airborne virus is easily transmitted through the air. Social distancing while walking outside, can be more effective, if pedestrians know locations of each other and even better if they know locations of people who are possible carriers. With this information, they can change their routes depending on the people walking nearby or they can stay away from areas that contain or have recently contained crowds. This paper presents a mobile device application that would be a very beneficial tool for social distancing during Coronavirus Disease 2019 (COVID-19). The application works, synced close to real-time, in a networking fashion with all users obtaining their locations and drawing a virtual safety bubble around them. These safety bubbles are used with the constant velocity pedestrian model to predict possible future social distancing violations and warn the user with sound and vibration. Moreover, it takes into account the virus staying airborne for a certain time, hence, creating time-decaying non-safe areas in the past trajectories of the users. The mobile app generates collision free paths for navigating around the undesired locations for the pedestrian mode of transportation when used as part of a multi-modal trip planning app. Results are applicable to other modes of transportation also. Features and the methods used for implementation are discussed in the paper. The application is tested using previously collected real pedestrian walking data in a realistic environment.
Affinity Mixup for Weakly Supervised Sound Event Detection
Jun 21, 2021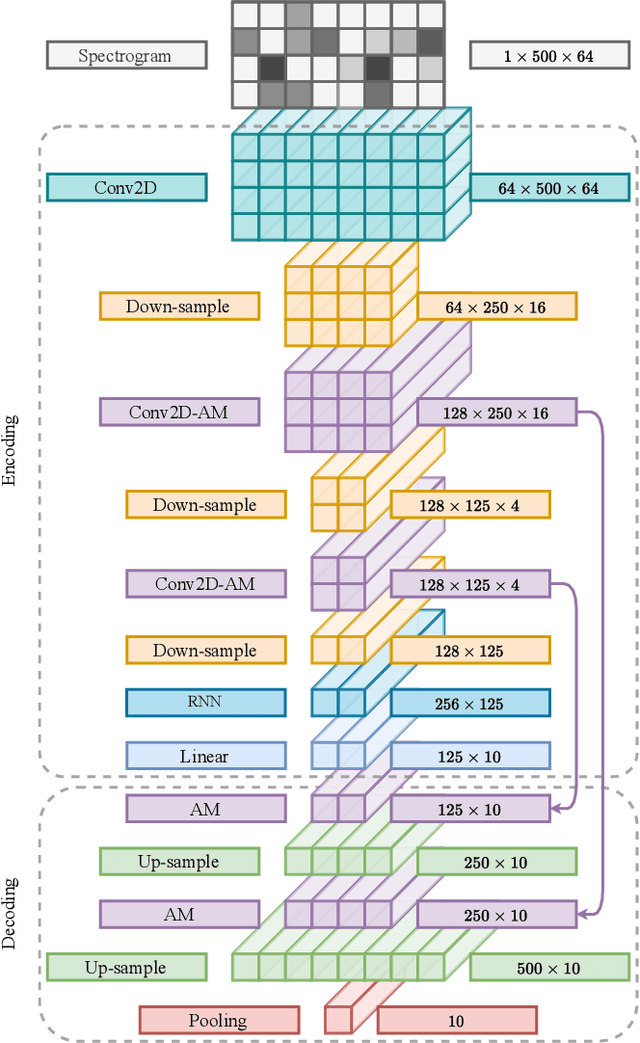
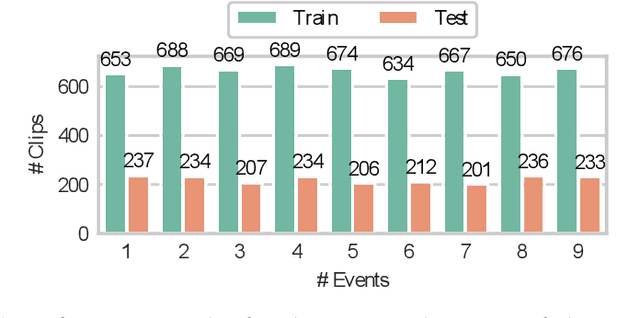
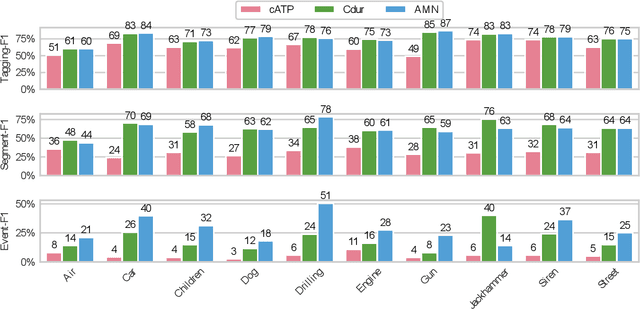
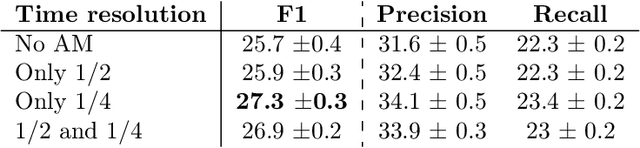
The weakly supervised sound event detection problem is the task of predicting the presence of sound events and their corresponding starting and ending points in a weakly labeled dataset. A weak dataset associates each training sample (a short recording) to one or more present sources. Networks that solely rely on convolutional and recurrent layers cannot directly relate multiple frames in a recording. Motivated by attention and graph neural networks, we introduce the concept of an affinity mixup to incorporate time-level similarities and make a connection between frames. This regularization technique mixes up features in different layers using an adaptive affinity matrix. Our proposed affinity mixup network improves over state-of-the-art techniques event-F1 scores by $8.2\%$.
Online Adaptation to Label Distribution Shift
Jul 09, 2021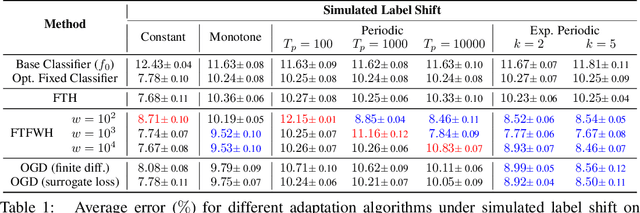
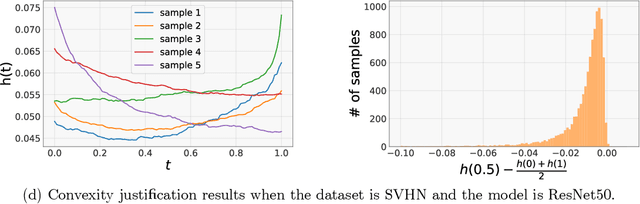

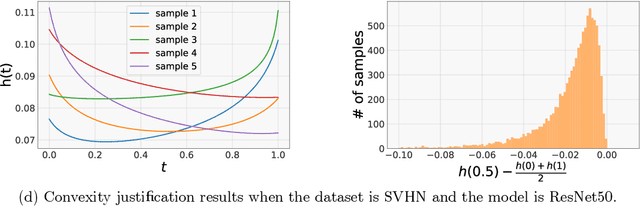
Machine learning models often encounter distribution shifts when deployed in the real world. In this paper, we focus on adaptation to label distribution shift in the online setting, where the test-time label distribution is continually changing and the model must dynamically adapt to it without observing the true label. Leveraging a novel analysis, we show that the lack of true label does not hinder estimation of the expected test loss, which enables the reduction of online label shift adaptation to conventional online learning. Informed by this observation, we propose adaptation algorithms inspired by classical online learning techniques such as Follow The Leader (FTL) and Online Gradient Descent (OGD) and derive their regret bounds. We empirically verify our findings under both simulated and real world label distribution shifts and show that OGD is particularly effective and robust to a variety of challenging label shift scenarios.
edge-SR: Super-Resolution For The Masses
Aug 23, 2021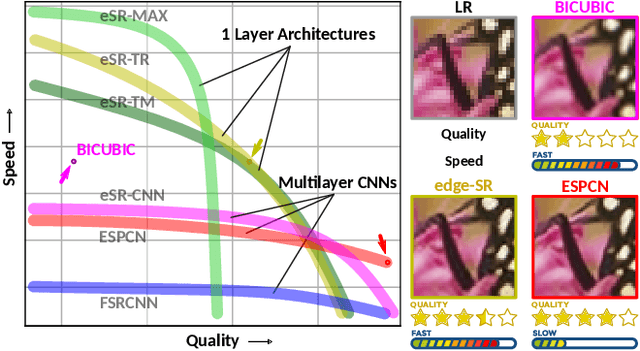

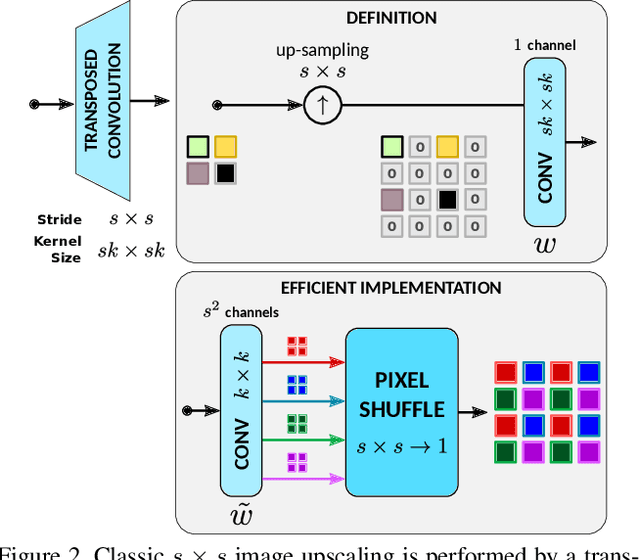
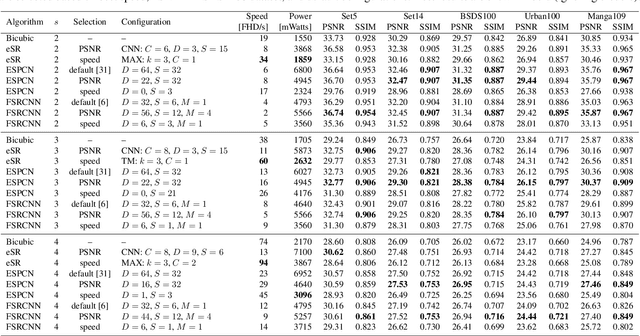
Classic image scaling (e.g. bicubic) can be seen as one convolutional layer and a single upscaling filter. Its implementation is ubiquitous in all display devices and image processing software. In the last decade deep learning systems have been introduced for the task of image super-resolution (SR), using several convolutional layers and numerous filters. These methods have taken over the benchmarks of image quality for upscaling tasks. Would it be possible to replace classic upscalers with deep learning architectures on edge devices such as display panels, tablets, laptop computers, etc.? On one hand, the current trend in Edge-AI chips shows a promising future in this direction, with rapid development of hardware that can run deep-learning tasks efficiently. On the other hand, in image SR only few architectures have pushed the limit to extreme small sizes that can actually run on edge devices at real-time. We explore possible solutions to this problem with the aim to fill the gap between classic upscalers and small deep learning configurations. As a transition from classic to deep-learning upscaling we propose edge-SR (eSR), a set of one-layer architectures that use interpretable mechanisms to upscale images. Certainly, a one-layer architecture cannot reach the quality of deep learning systems. Nevertheless, we find that for high speed requirements, eSR becomes better at trading-off image quality and runtime performance. Filling the gap between classic and deep-learning architectures for image upscaling is critical for massive adoption of this technology. It is equally important to have an interpretable system that can reveal the inner strategies to solve this problem and guide us to future improvements and better understanding of larger networks.
MutualEyeContact: A conversation analysis tool with focus on eye contact
Jul 09, 2021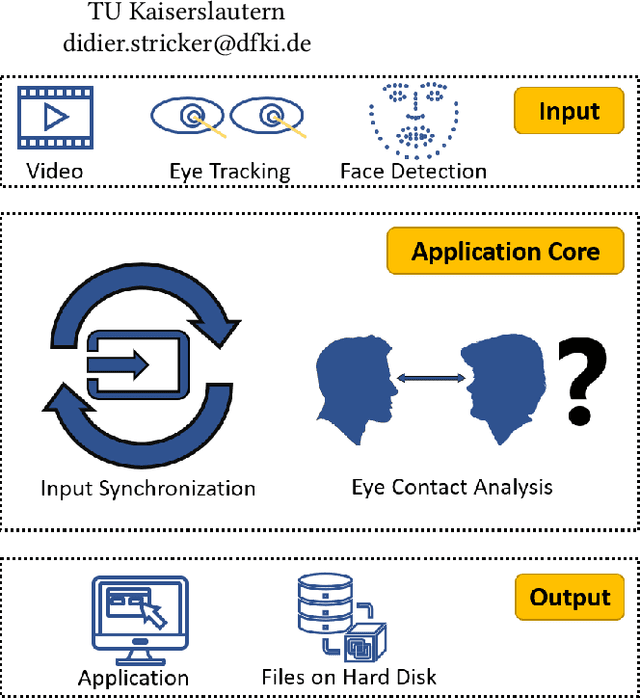
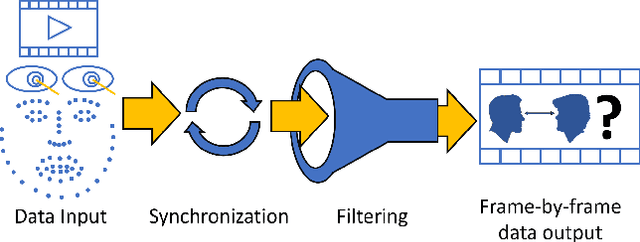

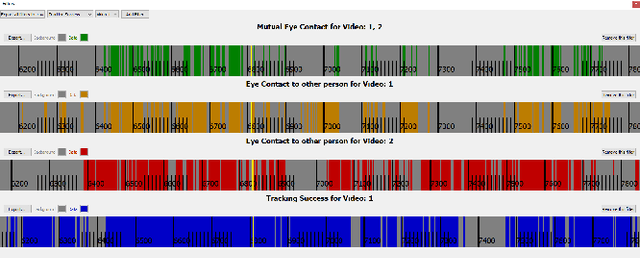
Eye contact between individuals is particularly important for understanding human behaviour. To further investigate the importance of eye contact in social interactions, portable eye tracking technology seems to be a natural choice. However, the analysis of available data can become quite complex. Scientists need data that is calculated quickly and accurately. Additionally, the relevant data must be automatically separated to save time. In this work, we propose a tool called MutualEyeContact which excels in those tasks and can help scientists to understand the importance of (mutual) eye contact in social interactions. We combine state-of-the-art eye tracking with face recognition based on machine learning and provide a tool for analysis and visualization of social interaction sessions. This work is a joint collaboration of computer scientists and cognitive scientists. It combines the fields of social and behavioural science with computer vision and deep learning.
A preliminary study on evaluating Consultation Notes with Post-Editing
Apr 09, 2021

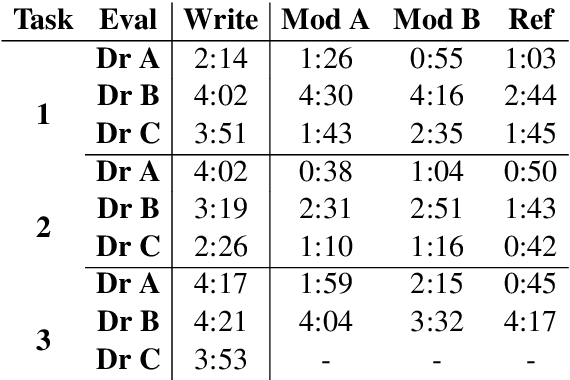
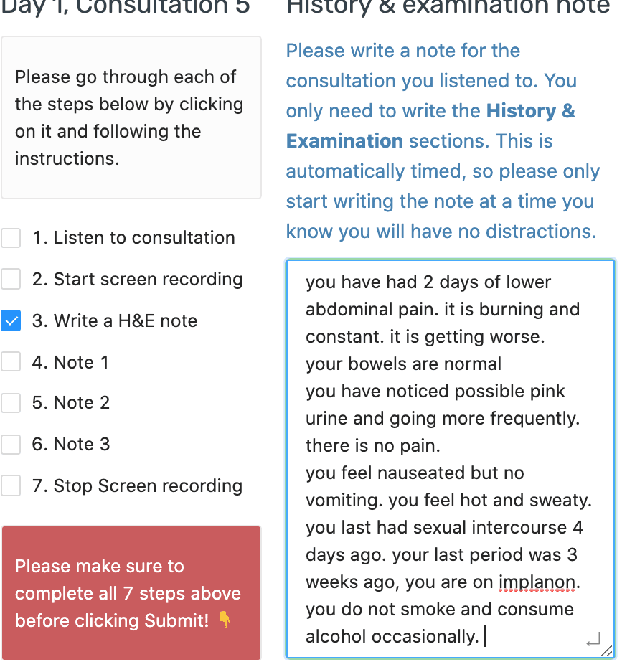
Automatic summarisation has the potential to aid physicians in streamlining clerical tasks such as note taking. But it is notoriously difficult to evaluate these systems and demonstrate that they are safe to be used in a clinical setting. To circumvent this issue, we propose a semi-automatic approach whereby physicians post-edit generated notes before submitting them. We conduct a preliminary study on the time saving of automatically generated consultation notes with post-editing. Our evaluators are asked to listen to mock consultations and to post-edit three generated notes. We time this and find that it is faster than writing the note from scratch. We present insights and lessons learnt from this experiment.
Imitation and Mirror Systems in Robots through Deep Modality Blending Networks
Jun 15, 2021

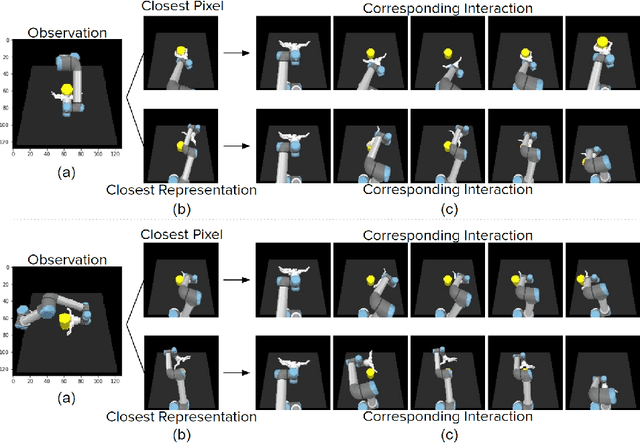

Learning to interact with the environment not only empowers the agent with manipulation capability but also generates information to facilitate building of action understanding and imitation capabilities. This seems to be a strategy adopted by biological systems, in particular primates, as evidenced by the existence of mirror neurons that seem to be involved in multi-modal action understanding. How to benefit from the interaction experience of the robots to enable understanding actions and goals of other agents is still a challenging question. In this study, we propose a novel method, deep modality blending networks (DMBN), that creates a common latent space from multi-modal experience of a robot by blending multi-modal signals with a stochastic weighting mechanism. We show for the first time that deep learning, when combined with a novel modality blending scheme, can facilitate action recognition and produce structures to sustain anatomical and effect-based imitation capabilities. Our proposed system, can be conditioned on any desired sensory/motor value at any time-step, and can generate a complete multi-modal trajectory consistent with the desired conditioning in parallel avoiding accumulation of prediction errors. We further showed that given desired images from different perspectives, i.e. images generated by the observation of other robots placed on different sides of the table, our system could generate image and joint angle sequences that correspond to either anatomical or effect based imitation behavior. Overall, the proposed DMBN architecture not only serves as a computational model for sustaining mirror neuron-like capabilities, but also stands as a powerful machine learning architecture for high-dimensional multi-modal temporal data with robust retrieval capabilities operating with partial information in one or multiple modalities.
Conditional Neural Relational Inference for Interacting Systems
Jun 21, 2021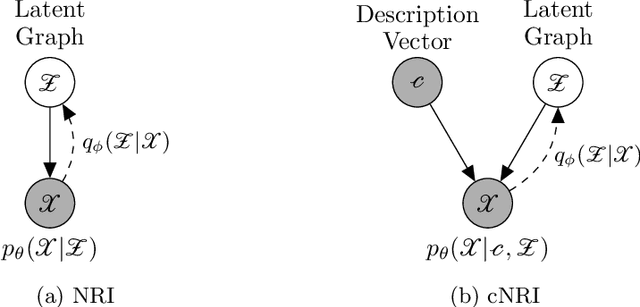
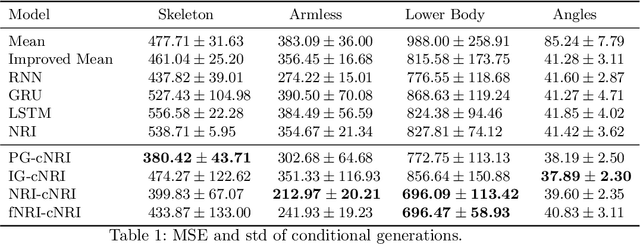
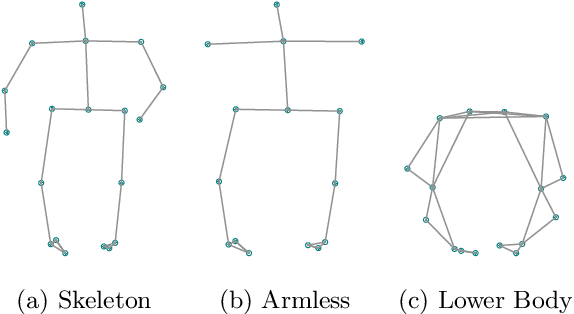
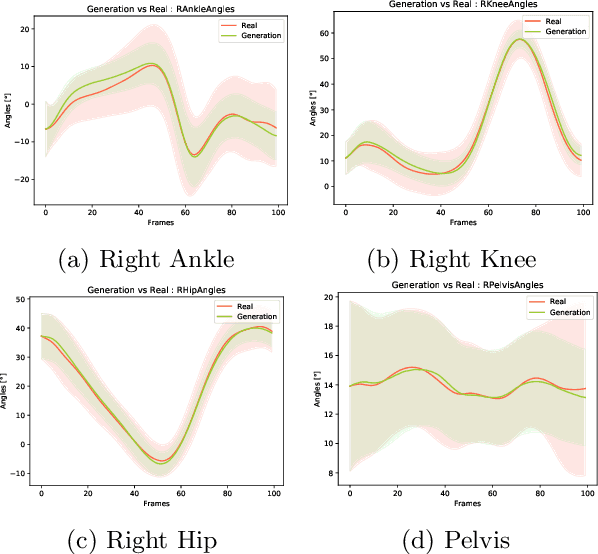
In this work, we want to learn to model the dynamics of similar yet distinct groups of interacting objects. These groups follow some common physical laws that exhibit specificities that are captured through some vectorial description. We develop a model that allows us to do conditional generation from any such group given its vectorial description. Unlike previous work on learning dynamical systems that can only do trajectory completion and require a part of the trajectory dynamics to be provided as input in generation time, we do generation using only the conditioning vector with no access to generation time's trajectories. We evaluate our model in the setting of modeling human gait and, in particular pathological human gait.
Road Network and Travel Time Extraction from Multiple Look Angles with SpaceNet Data
Jan 16, 2020
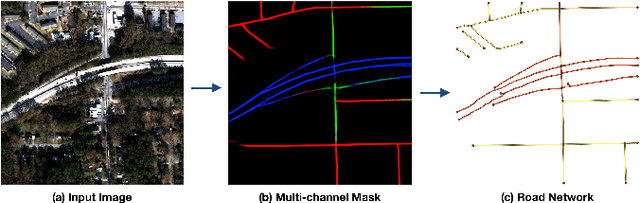


Identification of road networks and optimal routes directly from remote sensing is of critical importance to a broad array of humanitarian and commercial applications. Yet while identification of road pixels has been attempted before, estimation of route travel times from overhead imagery remains a novel problem, particularly for off-nadir overhead imagery. To this end, we extract road networks with travel time estimates from the SpaceNet MVOI dataset. Utilizing the CRESIv2 framework, we demonstrate the ability to extract road networks in various observation angles and quantify performance at 27 unique nadir angles with the graph-theoretic APLS_length and APLS_time metrics. A minimal gap of 0.03 between APLS_length and APLS_time scores indicates that our approach yields speed limits and travel times with very high fidelity. We also explore the utility of incorporating all available angles during model training, and find a peak score of APLS_time = 0.56. The combined model exhibits greatly improved robustness over angle-specific models, despite the very different appearance of road networks at extremely oblique off-nadir angles versus images captured from directly overhead.
Time to Die: Death Prediction in Dota 2 using Deep Learning
May 21, 2019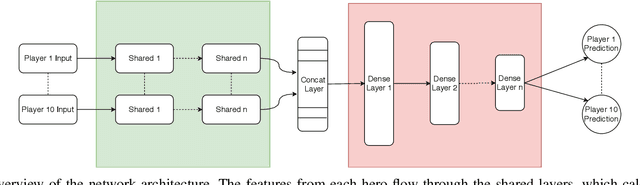
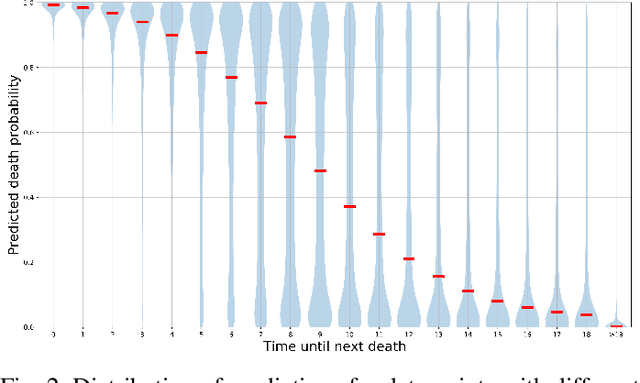
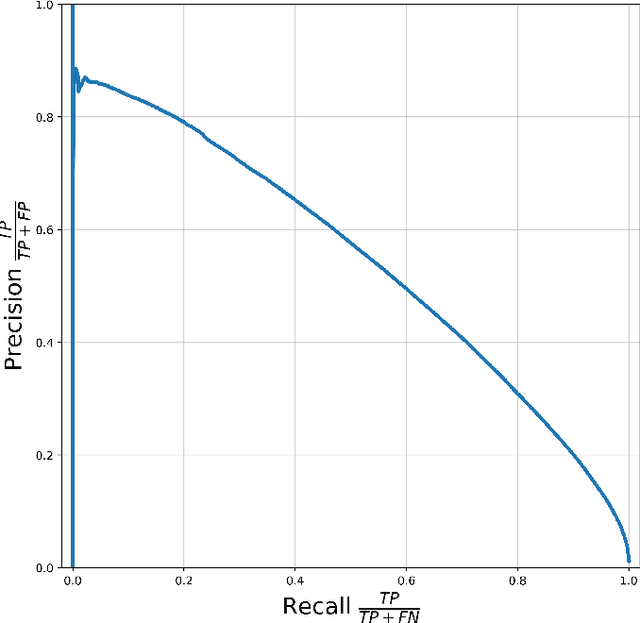
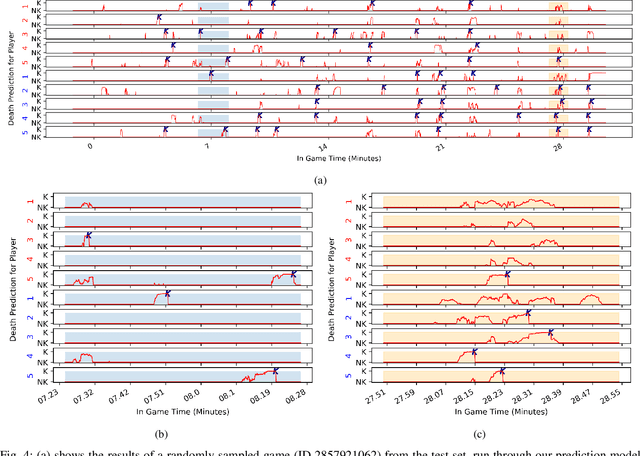
Esports have become major international sports with hundreds of millions of spectators. Esports games generate massive amounts of telemetry data. Using these to predict the outcome of esports matches has received considerable attention, but micro-predictions, which seek to predict events inside a match, is as yet unknown territory. Micro-predictions are however of perennial interest across esports commentators and audience, because they provide the ability to observe events that might otherwise be missed: esports games are highly complex with fast-moving action where the balance of a game can change in the span of seconds, and where events can happen in multiple areas of the playing field at the same time. Such events can happen rapidly, and it is easy for commentators and viewers alike to miss an event and only observe the following impact of events. In Dota 2, a player hero being killed by the opposing team is a key event of interest to commentators and audience. We present a deep learning network with shared weights which provides accurate death predictions within a five-second window. The network is trained on a vast selection of Dota 2 gameplay features and professional/semi-professional level match dataset. Even though death events are rare within a game (1\% of the data), the model achieves 0.377 precision with 0.725 recall on test data when prompted to predict which of any of the 10 players of either team will die within 5 seconds. An example of the system applied to a Dota 2 match is presented. This model enables real-time micro-predictions of kills in Dota 2, one of the most played esports titles in the world, giving commentators and viewers time to move their attention to these key events.