 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Diverse Branch Block: Building a Convolution as an Inception-like Unit
Mar 29, 2021
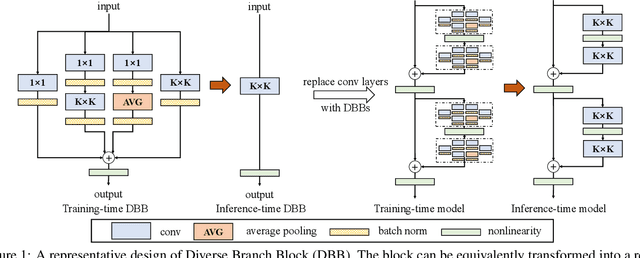
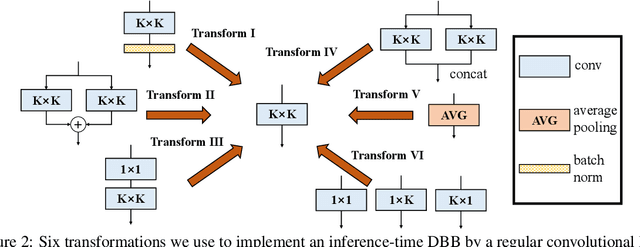
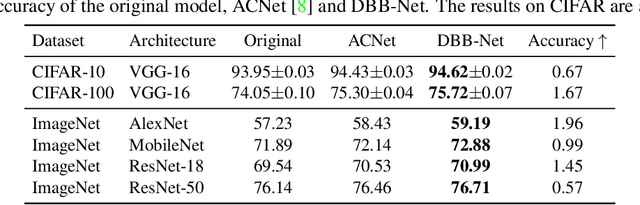
We propose a universal building block of Convolutional Neural Network (ConvNet) to improve the performance without any inference-time costs. The block is named Diverse Branch Block (DBB), which enhances the representational capacity of a single convolution by combining diverse branches of different scales and complexities to enrich the feature space, including sequences of convolutions, multi-scale convolutions, and average pooling. After training, a DBB can be equivalently converted into a single conv layer for deployment. Unlike the advancements of novel ConvNet architectures, DBB complicates the training-time microstructure while maintaining the macro architecture, so that it can be used as a drop-in replacement for regular conv layers of any architecture. In this way, the model can be trained to reach a higher level of performance and then transformed into the original inference-time structure for inference. DBB improves ConvNets on image classification (up to 1.9% higher top-1 accuracy on ImageNet), object detection and semantic segmentation. The PyTorch code and models are released at https://github.com/DingXiaoH/DiverseBranchBlock.
Design and Experimental Evaluation of a Hierarchical Controller for an Autonomous Ground Vehicle with Large Uncertainties
Aug 09, 2021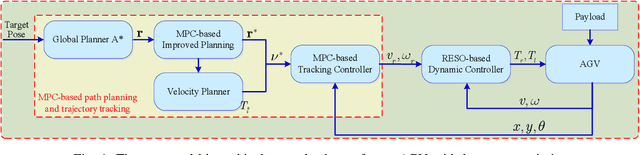

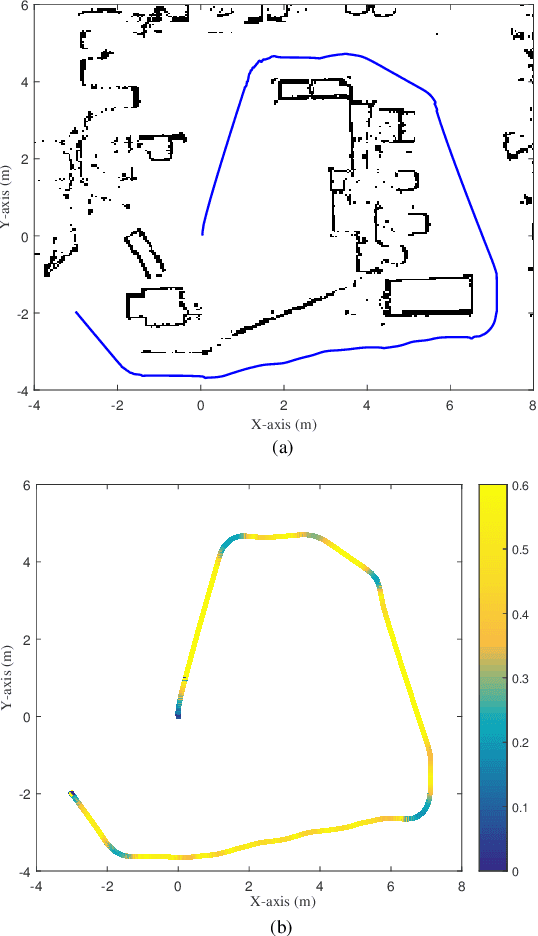
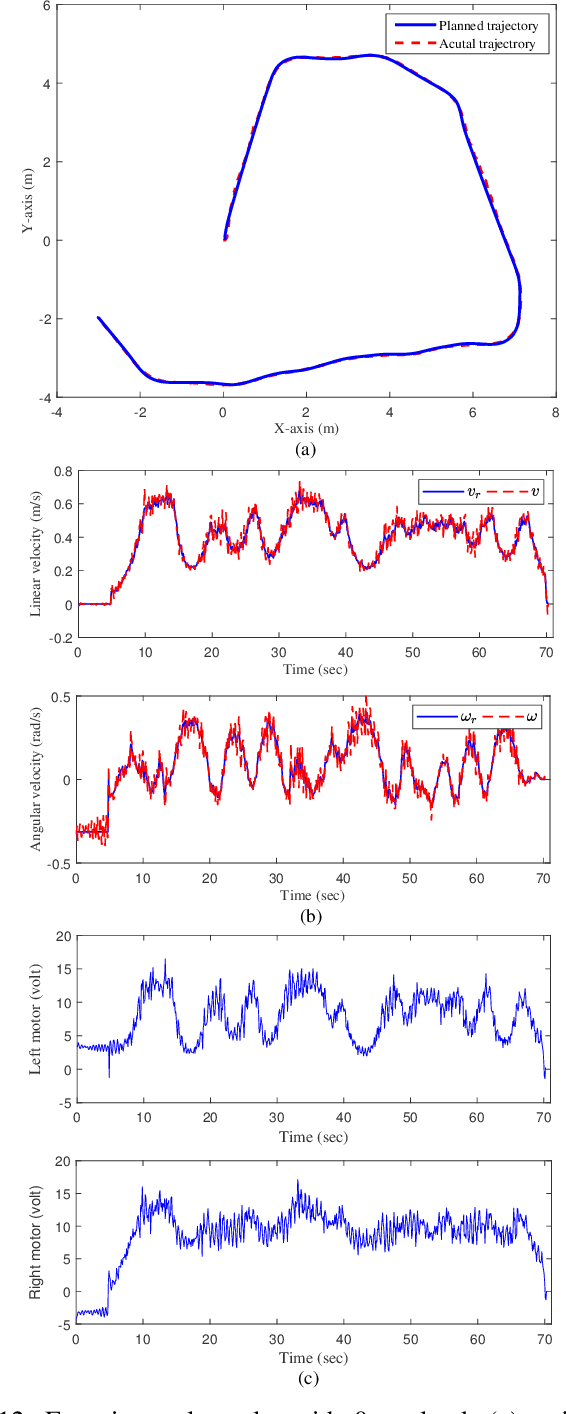
Autonomous ground vehicles (AGVs) are receiving increasing attention, and the motion planning and control problem for these vehicles has become a hot research topic. In real applications such as material handling, an AGV is subject to large uncertainties and its motion planning and control become challenging. In this paper, we investigate this problem by proposing a hierarchical control scheme, which is integrated by a model predictive control (MPC) based path planning and trajectory tracking control at the high level, and a reduced-order extended state observer (RESO) based dynamic control at the low level. The control at the high level consists of an MPC-based improved path planner, a velocity planner, and an MPC-based tracking controller. Both the path planning and trajectory tracking control problems are formulated under an MPC framework. The control at the low level employs the idea of active disturbance rejection control (ADRC). The uncertainties are estimated via a RESO and then compensated in the control in real-time. We show that, for the first-order uncertain AGV dynamic model, the RESO-based control only needs to know the control direction. Finally, simulations and experiments on an AGV with different payloads are conducted. The results illustrate that the proposed hierarchical control scheme achieves satisfactory motion planning and control performance with large uncertainties.
A real-time iterative machine learning approach for temperature profile prediction in additive manufacturing processes
Jul 28, 2019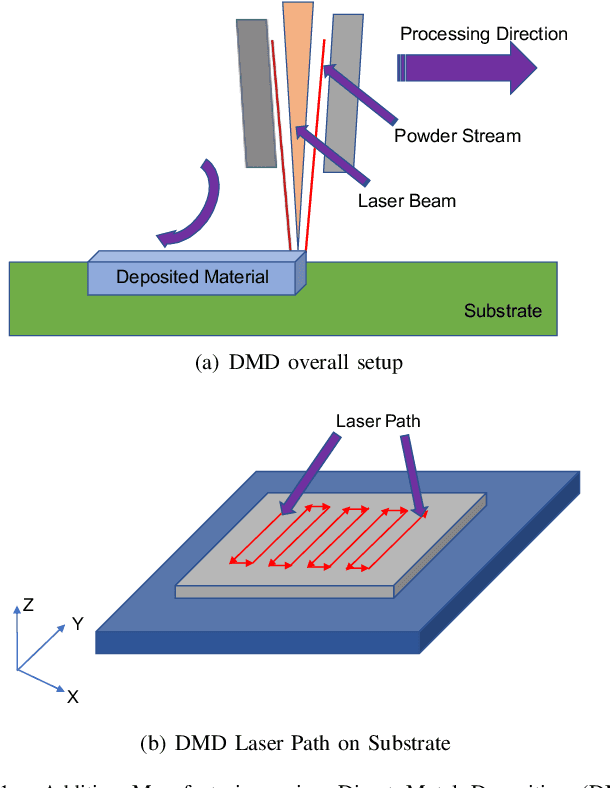

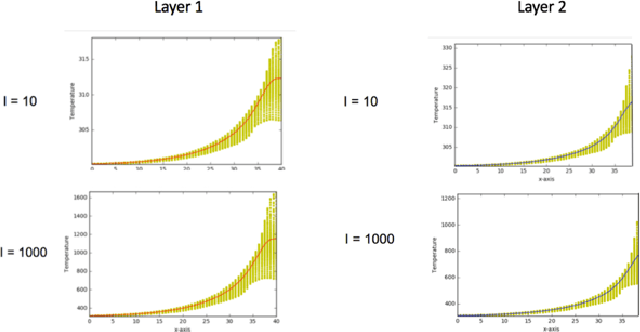
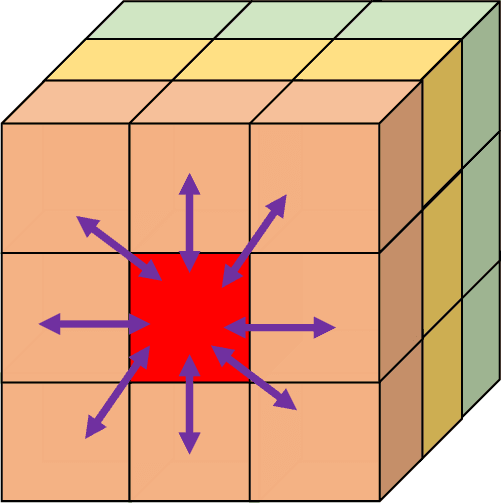
Additive Manufacturing (AM) is a manufacturing paradigm that builds three-dimensional objects from a computer-aided design model by successively adding material layer by layer. AM has become very popular in the past decade due to its utility for fast prototyping such as 3D printing as well as manufacturing functional parts with complex geometries using processes such as laser metal deposition that would be difficult to create using traditional machining. As the process for creating an intricate part for an expensive metal such as Titanium is prohibitive with respect to cost, computational models are used to simulate the behavior of AM processes before the experimental run. However, as the simulations are computationally costly and time-consuming for predicting multiscale multi-physics phenomena in AM, physics-informed data-driven machine-learning systems for predicting the behavior of AM processes are immensely beneficial. Such models accelerate not only multiscale simulation tools but also empower real-time control systems using in-situ data. In this paper, we design and develop essential components of a scientific framework for developing a data-driven model-based real-time control system. Finite element methods are employed for solving time-dependent heat equations and developing the database. The proposed framework uses extremely randomized trees - an ensemble of bagged decision trees as the regression algorithm iteratively using temperatures of prior voxels and laser information as inputs to predict temperatures of subsequent voxels. The models achieve mean absolute percentage errors below 1% for predicting temperature profiles for AM processes. The code is made available for the research community at https://anonymous.4open.science/r/112b41b9-05cb-478c-8a07-9366770ee504.
Focusing on Persons: Colorizing Old Images Learning from Modern Historical Movies
Aug 14, 2021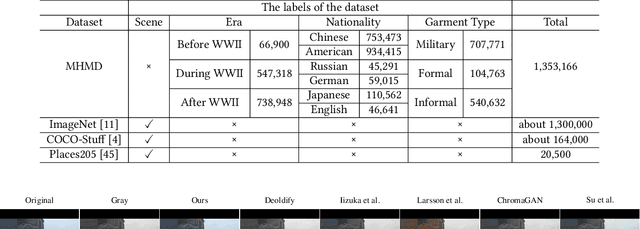
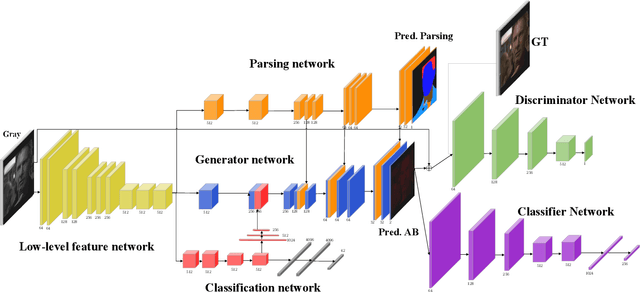
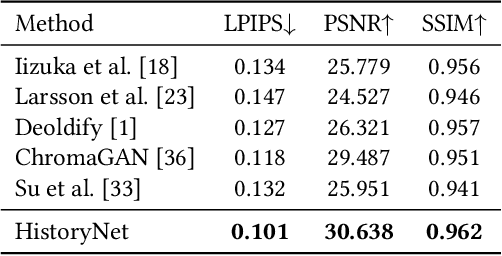
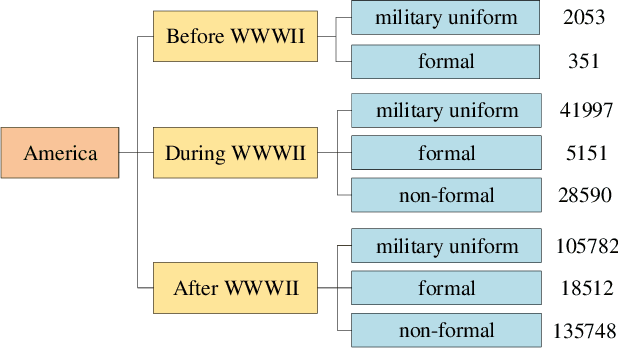
In industry, there exist plenty of scenarios where old gray photos need to be automatically colored, such as video sites and archives. In this paper, we present the HistoryNet focusing on historical person's diverse high fidelity clothing colorization based on fine grained semantic understanding and prior. Colorization of historical persons is realistic and practical, however, existing methods do not perform well in the regards. In this paper, a HistoryNet including three parts, namely, classification, fine grained semantic parsing and colorization, is proposed. Classification sub-module supplies classifying of images according to the eras, nationalities and garment types; Parsing sub-network supplies the semantic for person contours, clothing and background in the image to achieve more accurate colorization of clothes and persons and prevent color overflow. In the training process, we integrate classification and semantic parsing features into the coloring generation network to improve colorization. Through the design of classification and parsing subnetwork, the accuracy of image colorization can be improved and the boundary of each part of image can be more clearly. Moreover, we also propose a novel Modern Historical Movies Dataset (MHMD) containing 1,353,166 images and 42 labels of eras, nationalities, and garment types for automatic colorization from 147 historical movies or TV series made in modern time. Various quantitative and qualitative comparisons demonstrate that our method outperforms the state-of-the-art colorization methods, especially on military uniforms, which has correct colors according to the historical literatures.
Spatial-Temporal Super-Resolution of Satellite Imagery via Conditional Pixel Synthesis
Jun 22, 2021
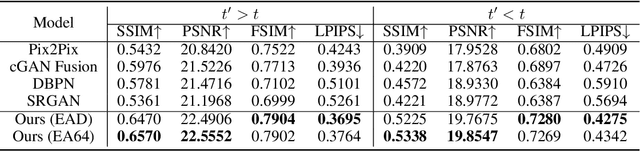
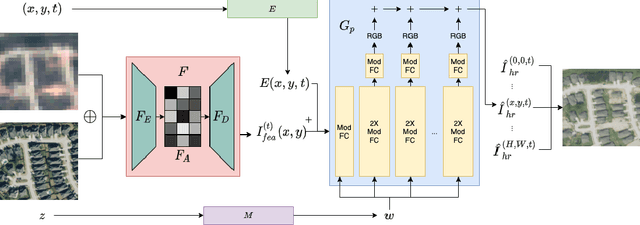

High-resolution satellite imagery has proven useful for a broad range of tasks, including measurement of global human population, local economic livelihoods, and biodiversity, among many others. Unfortunately, high-resolution imagery is both infrequently collected and expensive to purchase, making it hard to efficiently and effectively scale these downstream tasks over both time and space. We propose a new conditional pixel synthesis model that uses abundant, low-cost, low-resolution imagery to generate accurate high-resolution imagery at locations and times in which it is unavailable. We show that our model attains photo-realistic sample quality and outperforms competing baselines on a key downstream task -- object counting -- particularly in geographic locations where conditions on the ground are changing rapidly.
CycleGAN-based Non-parallel Speech Enhancement with an Adaptive Attention-in-attention Mechanism
Jul 28, 2021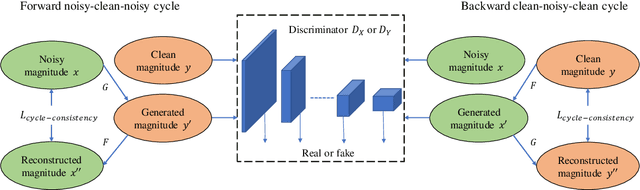
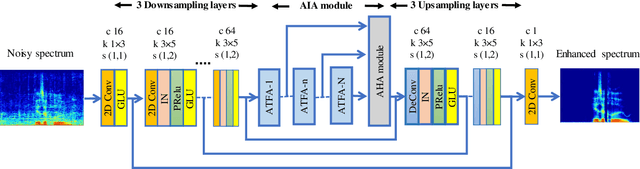
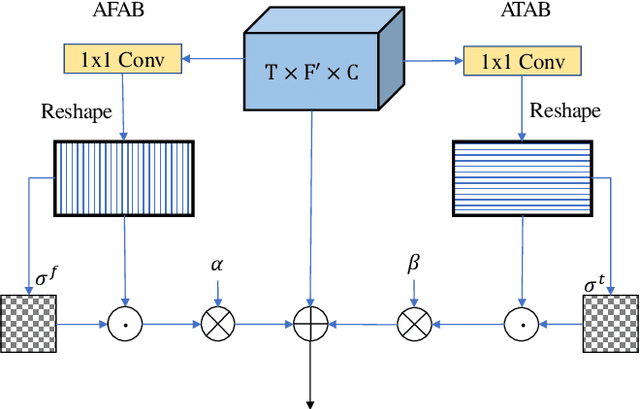
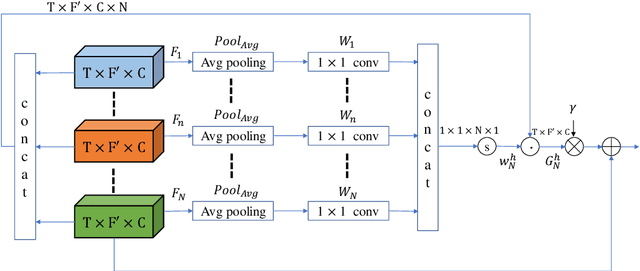
Non-parallel training is a difficult but essential task for DNN-based speech enhancement methods, for the lack of adequate noisy and paired clean speech corpus in many real scenarios. In this paper, we propose a novel adaptive attention-in-attention CycleGAN (AIA-CycleGAN) for non-parallel speech enhancement. In previous CycleGAN-based non-parallel speech enhancement methods, the limited mapping ability of the generator may cause performance degradation and insufficient feature learning. To alleviate this degradation, we propose an integration of adaptive time-frequency attention (ATFA) and adaptive hierarchical attention (AHA) to form an attention-in-attention (AIA) module for more flexible feature learning during the mapping procedure. More specifically, ATFA can capture the long-range temporal-spectral contextual information for more effective feature representations, while AHA can flexibly aggregate different intermediate feature maps by weights depending on the global context. Numerous experimental results demonstrate that the proposed approach achieves consistently more superior performance over previous GAN-based and CycleGAN-based methods in non-parallel training. Moreover, experiments in parallel training verify that the proposed AIA-CycleGAN also outperforms most advanced GAN-based speech enhancement approaches, especially in maintaining speech integrity and reducing speech distortion.
A Point Cloud Generative Model via Tree-Structured Graph Convolutions for 3D Brain Shape Reconstruction
Jul 21, 2021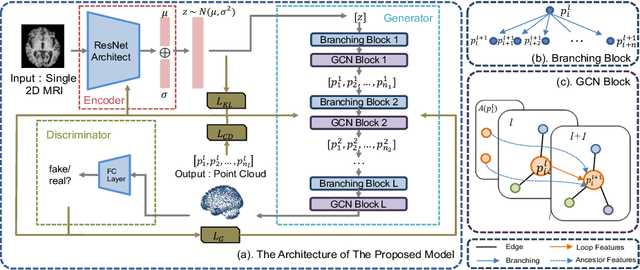

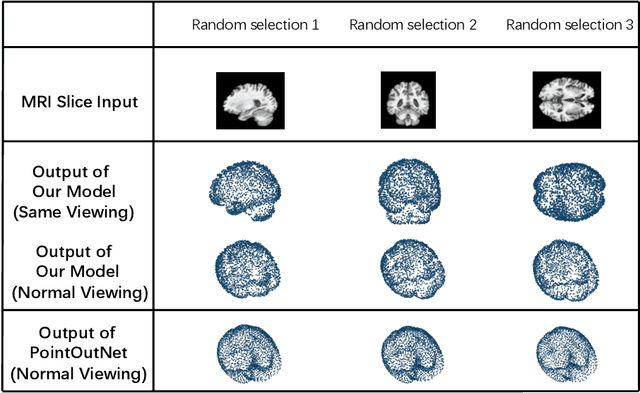

Fusing medical images and the corresponding 3D shape representation can provide complementary information and microstructure details to improve the operational performance and accuracy in brain surgery. However, compared to the substantial image data, it is almost impossible to obtain the intraoperative 3D shape information by using physical methods such as sensor scanning, especially in minimally invasive surgery and robot-guided surgery. In this paper, a general generative adversarial network (GAN) architecture based on graph convolutional networks is proposed to reconstruct the 3D point clouds (PCs) of brains by using one single 2D image, thus relieving the limitation of acquiring 3D shape data during surgery. Specifically, a tree-structured generative mechanism is constructed to use the latent vector effectively and transfer features between hidden layers accurately. With the proposed generative model, a spontaneous image-to-PC conversion is finished in real-time. Competitive qualitative and quantitative experimental results have been achieved on our model. In multiple evaluation methods, the proposed model outperforms another common point cloud generative model PointOutNet.
Mixture-Based Correction for Position and Trust Bias in Counterfactual Learning to Rank
Aug 19, 2021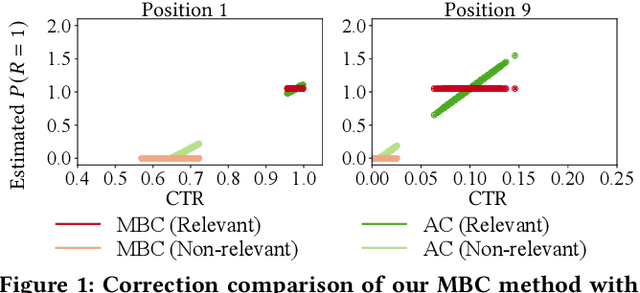
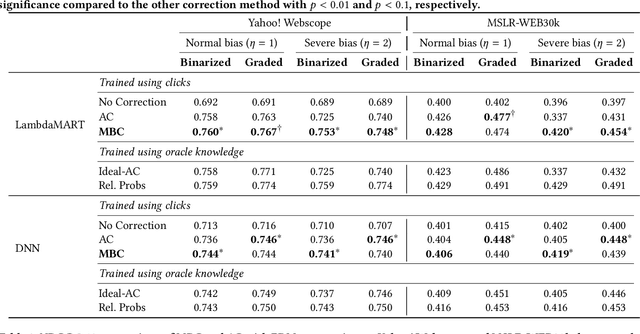
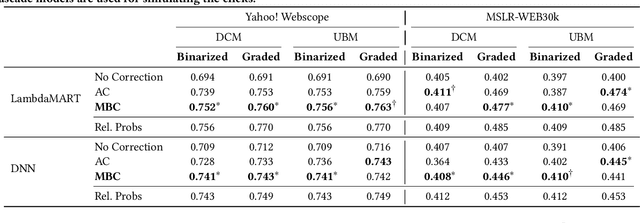
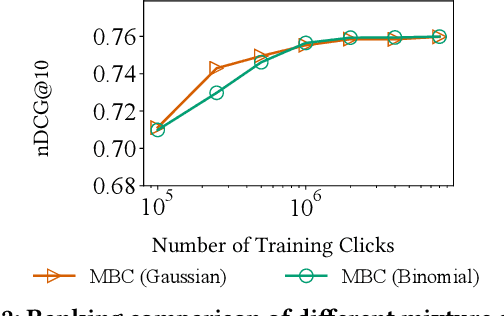
In counterfactual learning to rank (CLTR) user interactions are used as a source of supervision. Since user interactions come with bias, an important focus of research in this field lies in developing methods to correct for the bias of interactions. Inverse propensity scoring (IPS) is a popular method suitable for correcting position bias. Affine correction (AC) is a generalization of IPS that corrects for position bias and trust bias. IPS and AC provably remove bias, conditioned on an accurate estimation of the bias parameters. Estimating the bias parameters, in turn, requires an accurate estimation of the relevance probabilities. This cyclic dependency introduces practical limitations in terms of sensitivity, convergence and efficiency. We propose a new correction method for position and trust bias in CLTR in which, unlike the existing methods, the correction does not rely on relevance estimation. Our proposed method, mixture-based correction (MBC), is based on the assumption that the distribution of the CTRs over the items being ranked is a mixture of two distributions: the distribution of CTRs for relevant items and the distribution of CTRs for non-relevant items. We prove that our method is unbiased. The validity of our proof is not conditioned on accurate bias parameter estimation. Our experiments show that MBC, when used in different bias settings and accompanied by different LTR algorithms, outperforms AC, the state-of-the-art method for correcting position and trust bias, in some settings, while performing on par in other settings. Furthermore, MBC is orders of magnitude more efficient than AC in terms of the training time.
Time-Guided High-Order Attention Model of Longitudinal Heterogeneous Healthcare Data
Nov 28, 2019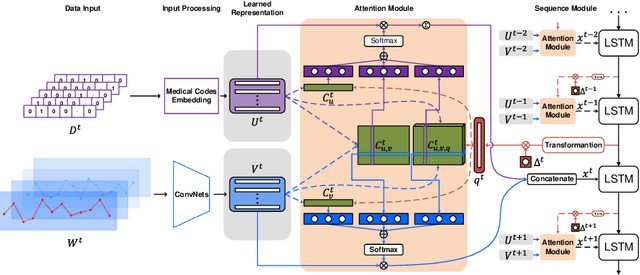
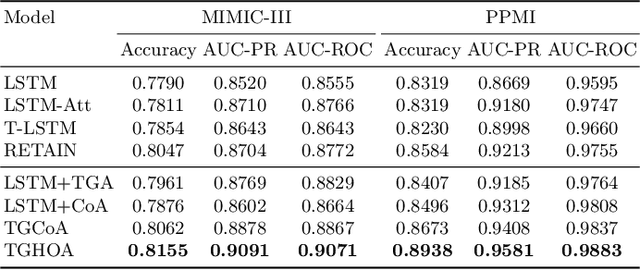
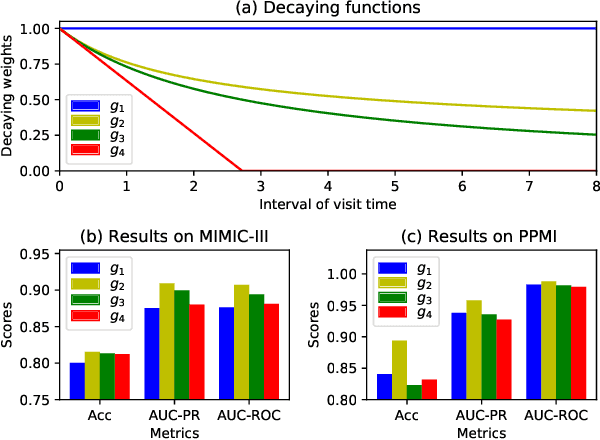

Due to potential applications in chronic disease management and personalized healthcare, the EHRs data analysis has attracted much attention of both researchers and practitioners. There are three main challenges in modeling longitudinal and heterogeneous EHRs data: heterogeneity, irregular temporality and interpretability. A series of deep learning methods have made remarkable progress in resolving these challenges. Nevertheless, most of existing attention models rely on capturing the 1-order temporal dependencies or 2-order multimodal relationships among feature elements. In this paper, we propose a time-guided high-order attention (TGHOA) model. The proposed method has three major advantages. (1) It can model longitudinal heterogeneous EHRs data via capturing the 3-order correlations of different modalities and the irregular temporal impact of historical events. (2) It can be used to identify the potential concerns of medical features to explain the reasoning process of the healthcare model. (3) It can be easily expanded into cases with more modalities and flexibly applied in different prediction tasks. We evaluate the proposed method in two tasks of mortality prediction and disease ranking on two real world EHRs datasets. Extensive experimental results show the effectiveness of the proposed model.
Jointly Learnable Data Augmentations for Self-Supervised GNNs
Aug 23, 2021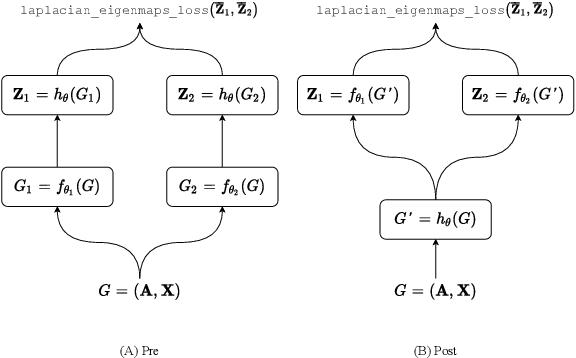
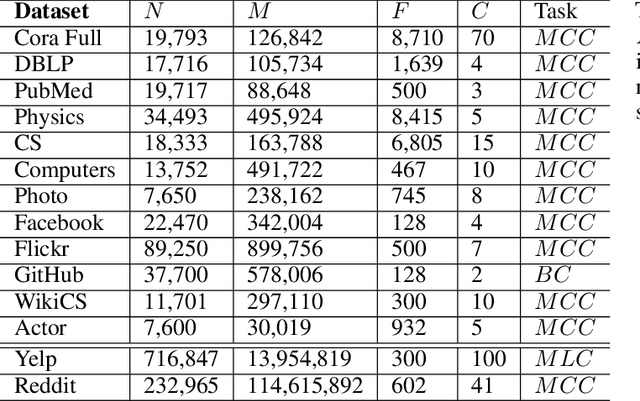
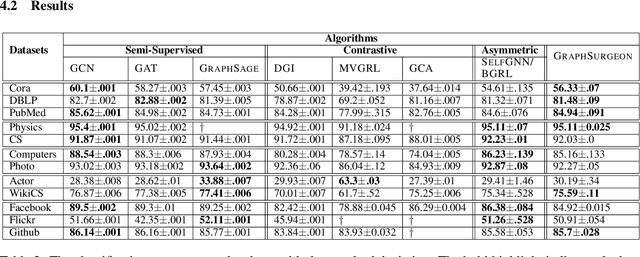
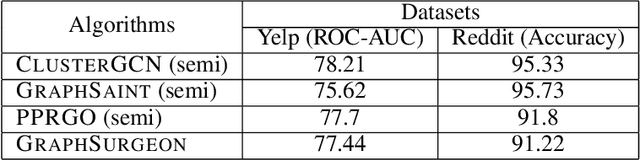
Self-supervised Learning (SSL) aims at learning representations of objects without relying on manual labeling. Recently, a number of SSL methods for graph representation learning have achieved performance comparable to SOTA semi-supervised GNNs. A Siamese network, which relies on data augmentation, is the popular architecture used in these methods. However, these methods rely on heuristically crafted data augmentation techniques. Furthermore, they use either contrastive terms or other tricks (e.g., asymmetry) to avoid trivial solutions that can occur in Siamese networks. In this study, we propose, GraphSurgeon, a novel SSL method for GNNs with the following features. First, instead of heuristics we propose a learnable data augmentation method that is jointly learned with the embeddings by leveraging the inherent signal encoded in the graph. In addition, we take advantage of the flexibility of the learnable data augmentation and introduce a new strategy that augments in the embedding space, called post augmentation. This strategy has a significantly lower memory overhead and run-time cost. Second, as it is difficult to sample truly contrastive terms, we avoid explicit negative sampling. Third, instead of relying on engineering tricks, we use a scalable constrained optimization objective motivated by Laplacian Eigenmaps to avoid trivial solutions. To validate the practical use of GraphSurgeon, we perform empirical evaluation using 14 public datasets across a number of domains and ranging from small to large scale graphs with hundreds of millions of edges. Our finding shows that GraphSurgeon is comparable to six SOTA semi-supervised and on par with five SOTA self-supervised baselines in node classification tasks. The source code is available at https://github.com/zekarias-tilahun/graph-surgeon.