 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Automatic Brain Tumor Segmentation using Convolutional Neural Networks with Test-Time Augmentation
Oct 18, 2018
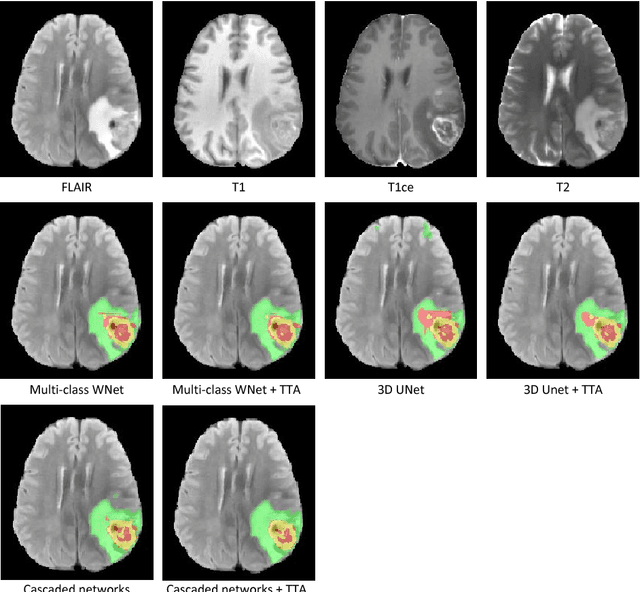
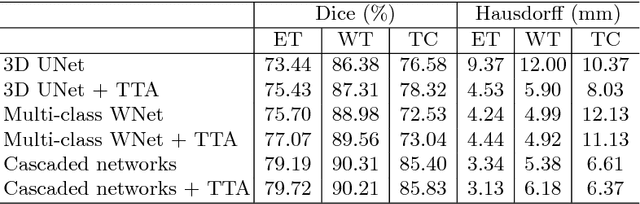
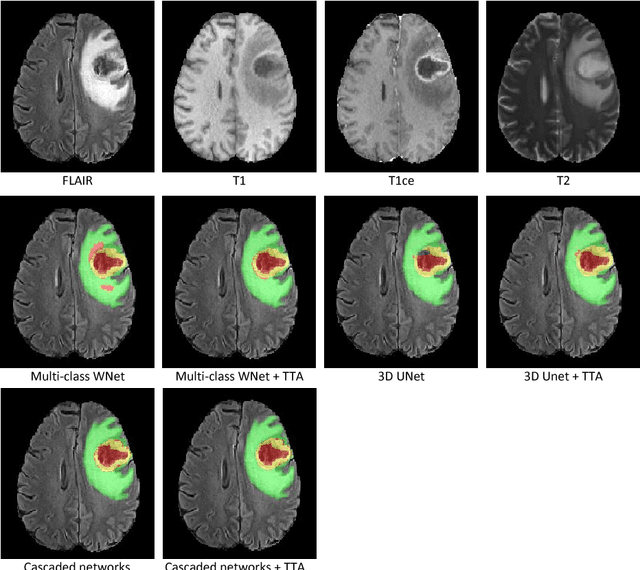
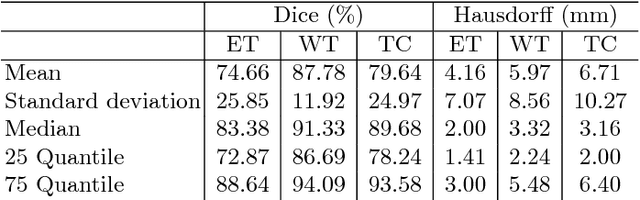
Automatic brain tumor segmentation plays an important role for diagnosis, surgical planning and treatment assessment of brain tumors. Deep convolutional neural networks (CNNs) have been widely used for this task. Due to the relatively small data set for training, data augmentation at training time has been commonly used for better performance of CNNs. Recent works also demonstrated the usefulness of using augmentation at test time, in addition to training time, for achieving more robust predictions. We investigate how test-time augmentation can improve CNNs' performance for brain tumor segmentation. We used different underpinning network structures and augmented the image by 3D rotation, flipping, scaling and adding random noise at both training and test time. Experiments with BraTS 2018 training and validation set show that test-time augmentation helps to improve the brain tumor segmentation accuracy and obtain uncertainty estimation of the segmentation results.
Pre-Clustering Point Clouds of Crop Fields Using Scalable Methods
Jul 22, 2021
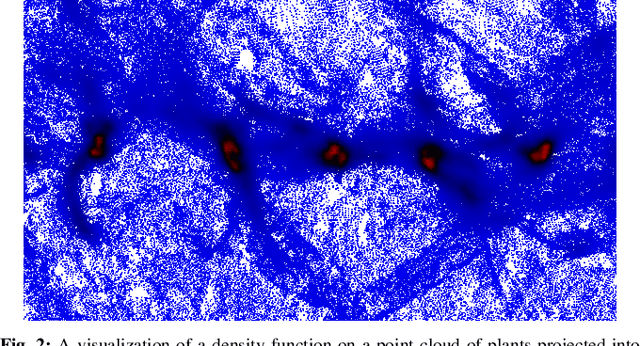


In order to apply the recent successes of automated plant phenotyping and machine learning on a large scale, efficient and general algorithms must be designed to intelligently split crop fields into small, yet actionable, portions that can then be processed by more complex algorithms. In this paper we notice a similarity between the current state-of-the-art for this problem and a commonly used density-based clustering algorithm, Quickshift. Exploiting this similarity we propose a number of novel, application specific algorithms with the goal of producing a general and scalable plant segmentation algorithm. The novel algorithms proposed in this work are shown to produce quantitatively better results than the current state-of-the-art while being less sensitive to input parameters and maintaining the same algorithmic time complexity. When incorporated into field-scale phenotyping systems, the proposed algorithms should work as a drop in replacement that can greatly improve the accuracy of results while ensuring that performance and scalability remain undiminished.
Automated Parking Space Detection Using Convolutional Neural Networks
Jun 14, 2021

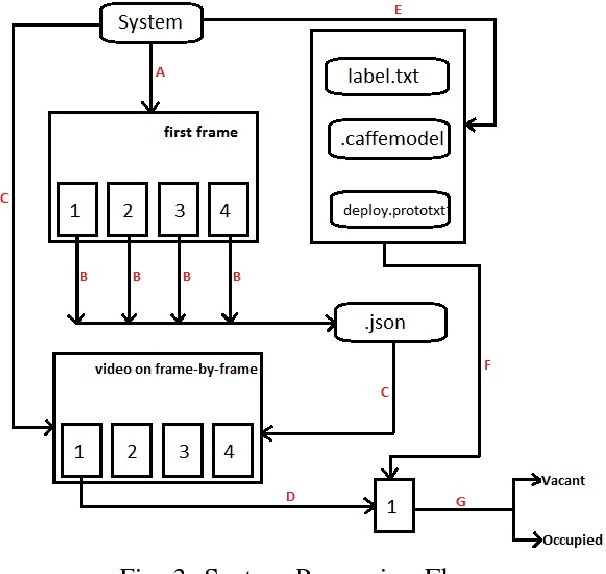
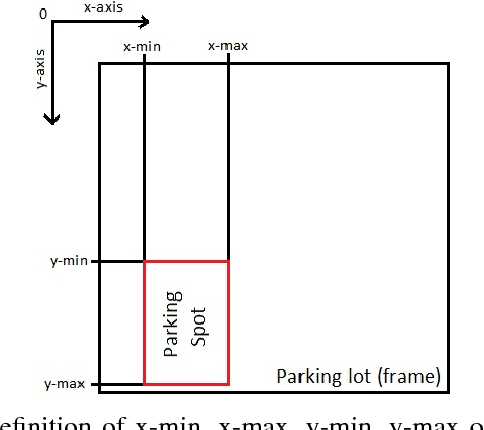
Finding a parking space nowadays becomes an issue that is not to be neglected, it consumes time and energy. We have used computer vision techniques to infer the state of the parking lot given the data collected from the University of The Witwatersrand. This paper presents an approach for a real-time parking space classification based on Convolutional Neural Networks (CNN) using Caffe and Nvidia DiGITS framework. The training process has been done using DiGITS and the output is a caffemodel used for predictions to detect vacant and occupied parking spots. The system checks a defined area whether a parking spot (bounding boxes defined at initialization of the system) is containing a car or not (occupied or vacant). Those bounding box coordinates are saved from a frame of the video of the parking lot in a JSON format, to be later used by the system for sequential prediction on each parking spot. The system has been trained using the LeNet network with the Nesterov Accelerated Gradient as solver and the AlexNet network with the Stochastic Gradient Descent as solver. We were able to get an accuracy on the validation set of 99\% for both networks. The accuracy on a foreign dataset(PKLot) returned as well 99\%. Those are experimental results based on the training set shows how robust the system can be when the prediction has to take place in a different parking space.
Detection of data drift and outliers affecting machine learning model performance over time
Dec 16, 2020

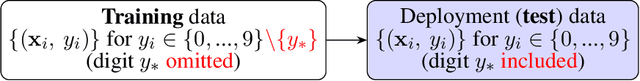
A trained ML model is deployed on another `test' dataset where target feature values (labels) are unknown. Drift is distribution change between the training and deployment data, which is concerning if model performance changes. For a cat/dog image classifier, for instance, drift during deployment could be rabbit images (new class) or cat/dog images with changed characteristics (change in distribution). We wish to detect these changes but can't measure accuracy without deployment data labels. We instead detect drift indirectly by nonparametrically testing the distribution of model prediction confidence for changes. This generalizes our method and sidesteps domain-specific feature representation. We address important statistical issues, particularly Type-1 error control in sequential testing, using Change Point Models (CPMs; see Adams and Ross 2012). We also use nonparametric outlier methods to show the user suspicious observations for model diagnosis, since the before/after change confidence distributions overlap significantly. In experiments to demonstrate robustness, we train on a subset of MNIST digit classes, then insert drift (e.g., unseen digit class) in deployment data in various settings (gradual/sudden changes in the drift proportion). A novel loss function is introduced to compare the performance (detection delay, Type-1 and 2 errors) of a drift detector under different levels of drift class contamination.
An Adaptive Receiver for Underwater Acoustic Full-Duplex Communication with Joint Tracking of the Remote and Self-Interference Channels
Mar 11, 2021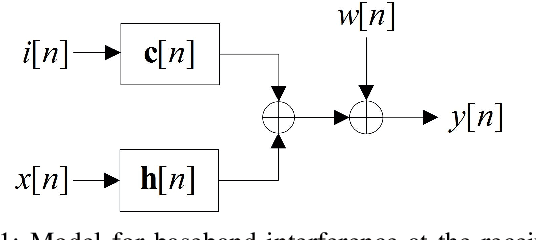
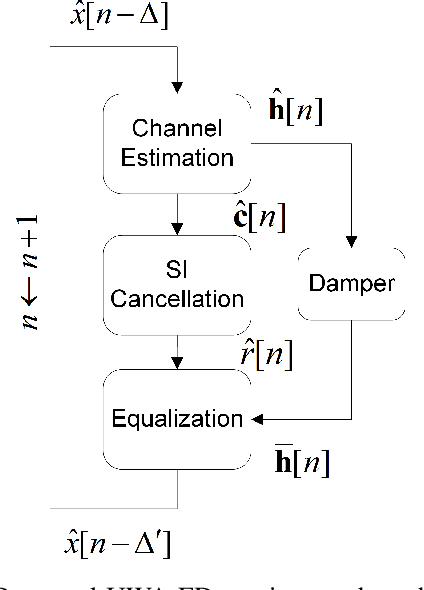
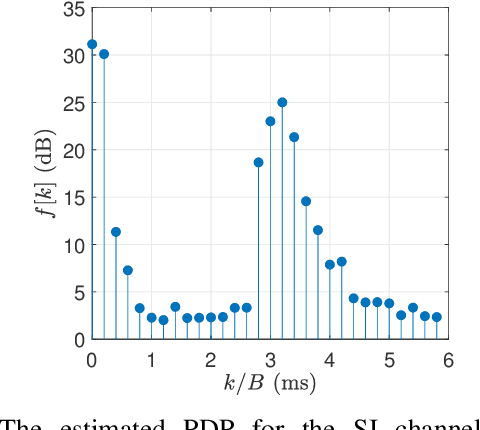
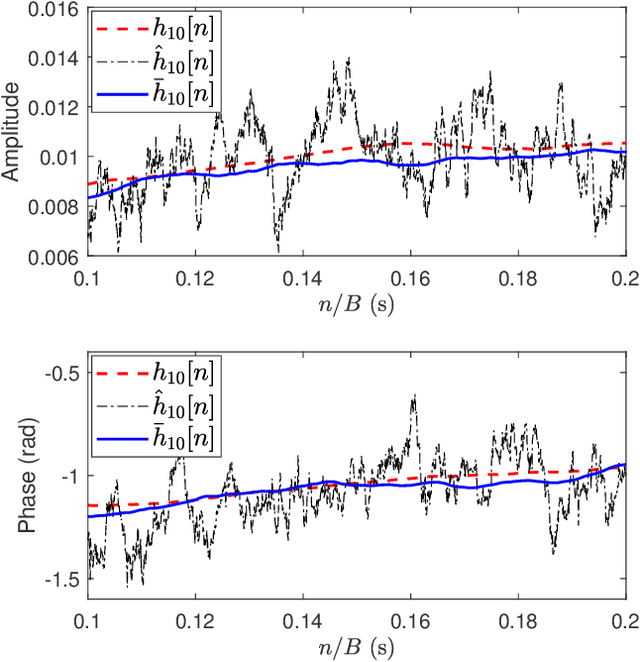
Full-duplex (FD) communication is a promising candidate to address the data rate limitations in underwater acoustic (UWA) channels. Because of transmission at the same time and on the same frequency band, the signal from the local transmitter creates self-interference (SI) that contaminates the signal from the remote transmitter. At the local receiver, channel state information for both the SI and remote channels is required to remove the SI and equalize the SI-free signal, respectively. However, because of the rapid time-variations of the UWA environment, real-time tracking of the channels is necessary. In this paper, we propose a receiver for UWA-FD communication in which the variations of the SI and remote channels are jointly tracked by using a recursive least squares (RLS) algorithm fed by feedback from the previously detected data symbols. Because of the joint channel estimation, SI cancellation is more successful compared to UWA-FD receivers with separate channel estimators. In addition, due to providing a real-time channel tracking without the need for frequent training sequences, the bandwidth efficiency is preserved in the proposed receiver.
* 7 pages, 7 figures
Revisiting Hierarchical Approach for Persistent Long-Term Video Prediction
Apr 14, 2021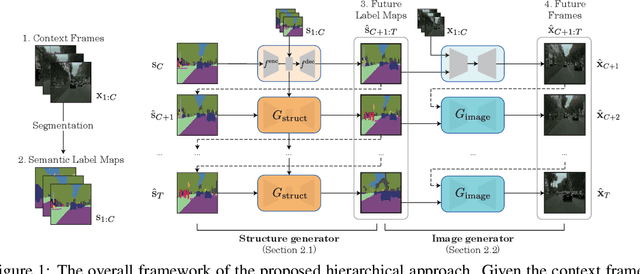
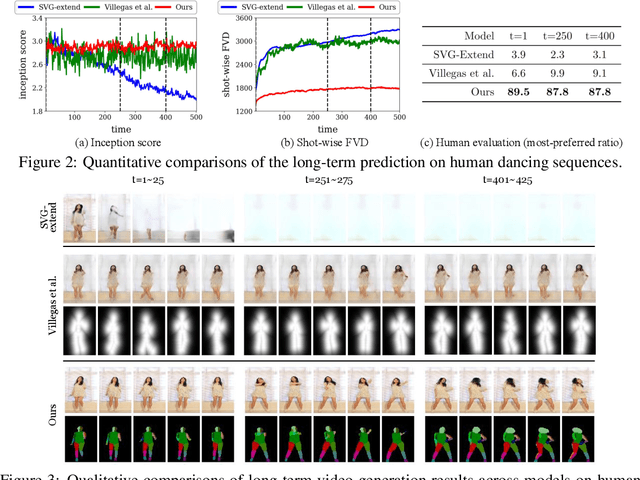
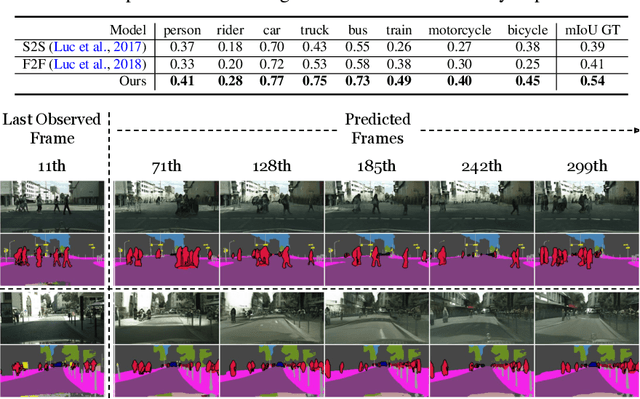
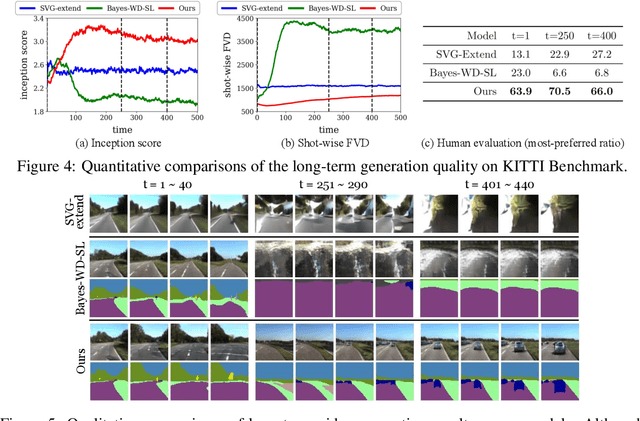
Learning to predict the long-term future of video frames is notoriously challenging due to inherent ambiguities in the distant future and dramatic amplifications of prediction error through time. Despite the recent advances in the literature, existing approaches are limited to moderately short-term prediction (less than a few seconds), while extrapolating it to a longer future quickly leads to destruction in structure and content. In this work, we revisit hierarchical models in video prediction. Our method predicts future frames by first estimating a sequence of semantic structures and subsequently translating the structures to pixels by video-to-video translation. Despite the simplicity, we show that modeling structures and their dynamics in the discrete semantic structure space with a stochastic recurrent estimator leads to surprisingly successful long-term prediction. We evaluate our method on three challenging datasets involving car driving and human dancing, and demonstrate that it can generate complicated scene structures and motions over a very long time horizon (i.e., thousands frames), setting a new standard of video prediction with orders of magnitude longer prediction time than existing approaches. Full videos and codes are available at https://1konny.github.io/HVP/.
Point Cloud Pre-training by Mixing and Disentangling
Sep 01, 2021
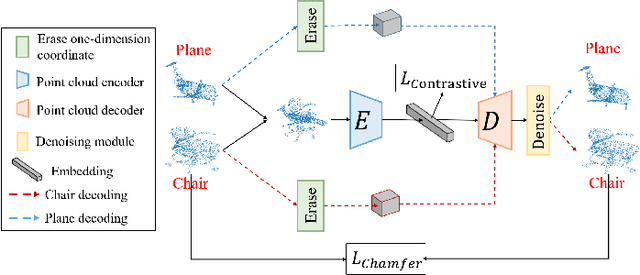
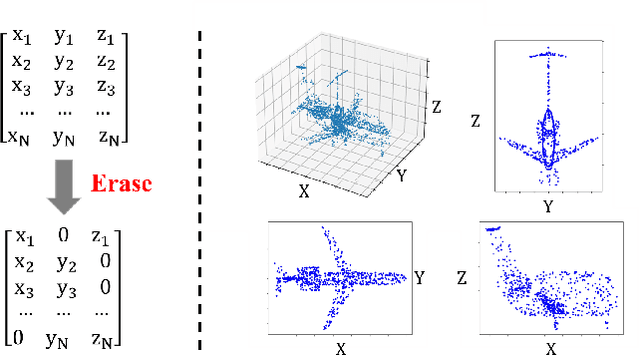
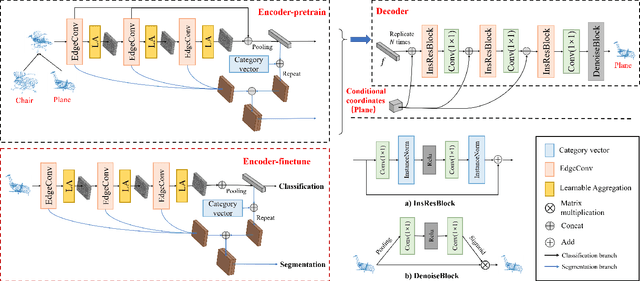
The annotation for large-scale point clouds is still time-consuming and unavailable for many real-world tasks. Point cloud pre-training is one potential solution for obtaining a scalable model for fast adaptation. Therefore, in this paper, we investigate a new self-supervised learning approach, called Mixing and Disentangling (MD), for point cloud pre-training. As the name implies, we explore how to separate the original point cloud from the mixed point cloud, and leverage this challenging task as a pretext optimization objective for model training. Considering the limited training data in the original dataset, which is much less than prevailing ImageNet, the mixing process can efficiently generate more high-quality samples. We build one baseline network to verify our intuition, which simply contains two modules, encoder and decoder. Given a mixed point cloud, the encoder is first pre-trained to extract the semantic embedding. Then an instance-adaptive decoder is harnessed to disentangle the point clouds according to the embedding. Albeit simple, the encoder is inherently able to capture the point cloud keypoints after training and can be fast adapted to downstream tasks including classification and segmentation by the pre-training and fine-tuning paradigm. Extensive experiments on two datasets show that the encoder + ours (MD) significantly surpasses that of the encoder trained from scratch and converges quickly. In ablation studies, we further study the effect of each component and discuss the advantages of the proposed self-supervised learning strategy. We hope this self-supervised learning attempt on point clouds can pave the way for reducing the deeply-learned model dependence on large-scale labeled data and saving a lot of annotation costs in the future.
Real-time Person Re-identification at the Edge: A Mixed Precision Approach
Aug 19, 2019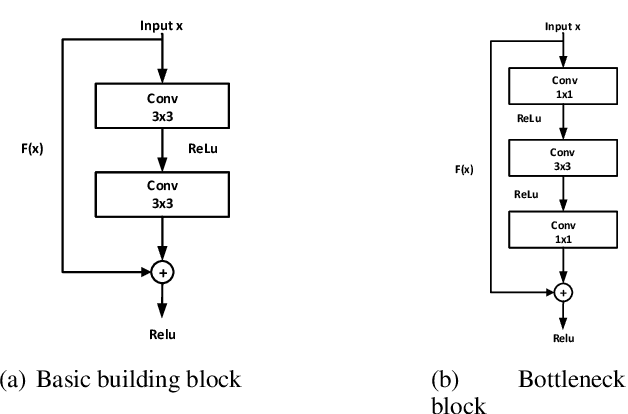
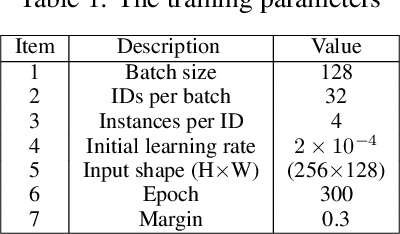
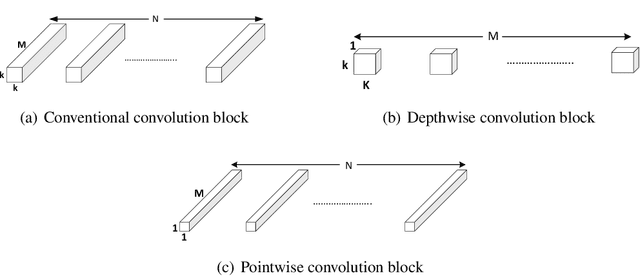
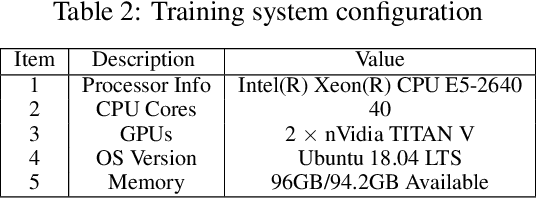
A critical part of multi-person multi-camera tracking is person re-identification (re-ID) algorithm, which recognizes and retains identities of all detected unknown people throughout the video stream. Many re-ID algorithms today exemplify state of the art results, but not much work has been done to explore the deployment of such algorithms for computation and power constrained real-time scenarios. In this paper, we study the effect of using a light-weight model, MobileNet-v2 for re-ID and investigate the impact of single (FP32) precision versus half (FP16) precision for training on the server and inference on the edge nodes. We further compare the results with the baseline model which uses ResNet-50 on state of the art benchmarks including CUHK03, Market-1501, and Duke-MTMC. The MobileNet-V2 mixed precision training method can improve both inference throughput on the edge node, and training time on server $3.25\times$ reaching to 27.77fps and $1.75\times$, respectively and decreases power consumption on the edge node by $1.45\times$, while it deteriorates accuracy only 5.6\% in respect to ResNet-50 single precision on the average for three different datasets. The code and pre-trained networks are publicly available at https://github.com/TeCSAR-UNCC/person-reid.
* This is a pre-print of an article published in International Conference on Image Analysis and Recognition (ICIAR 2019), Lecture Notes in Computer Science. The final authenticated version is available online at https://doi.org/10.1007/978-3-030-27272-2_3
Preliminary investigation into how limb choice affects kinesthetic perception
Jul 22, 2021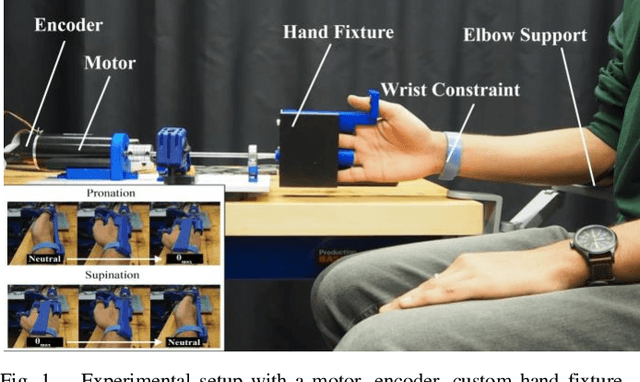
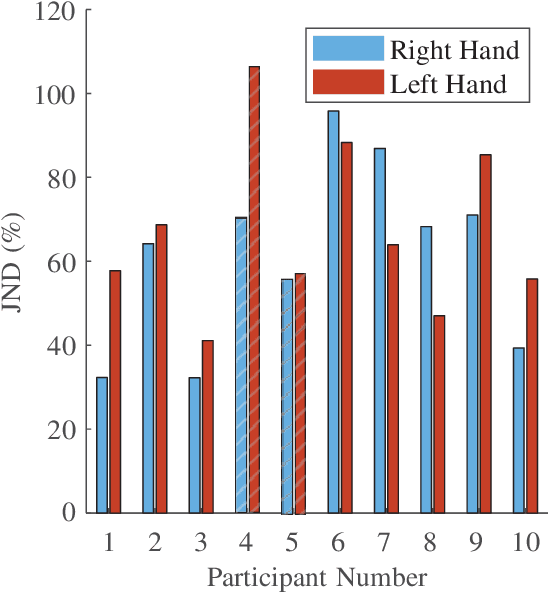
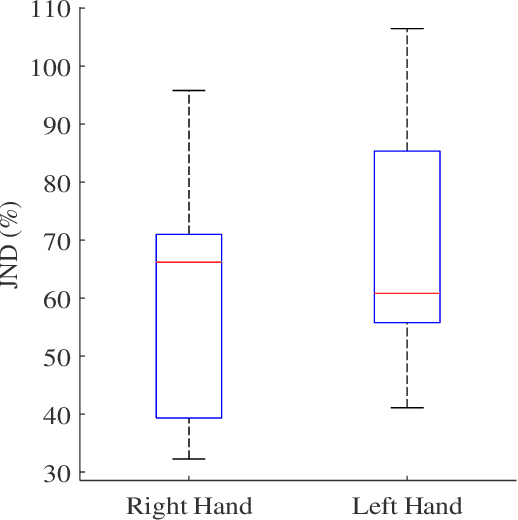
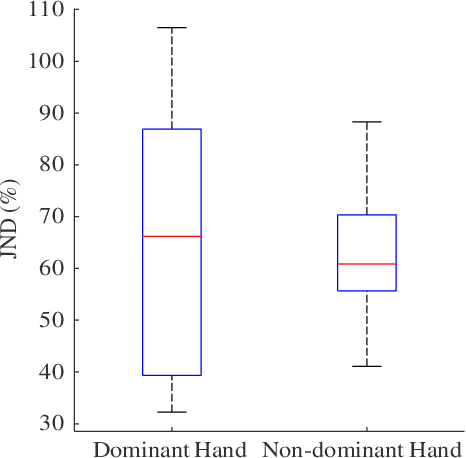
We have a limited understanding of how we integrate haptic information in real-time from our upper limbs to perform complex bimanual tasks, an ability that humans routinely employ to perform tasks of varying levels of difficulty. In order to understand how information from both limbs is used to create a unified percept, it is important to study both the limbs separately first. Prevalent theories highlighting the role of central nervous system (CNS) in accounting for internal body dynamics seem to suggest that both upper limbs should be equally sensitive to external stimuli. However, there is empirical proof demonstrating a perceptual difference in our upper limbs for tasks like shape discrimination, prompting the need to study effects of limb choice on kinesthetic perception. In this manuscript, we start evaluating Just Noticeable Difference (JND) for stiffness for both forearms separately. Early results validate the need for a more thorough investigation of limb choice on kinesthetic perception.
Deep MRI Reconstruction with Radial Subsampling
Aug 17, 2021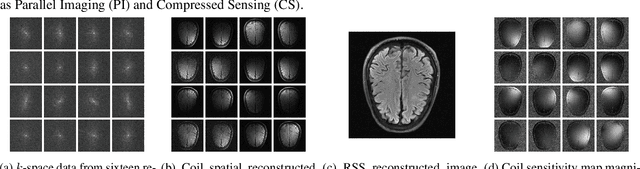
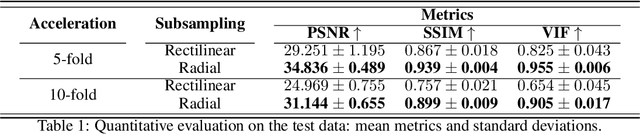
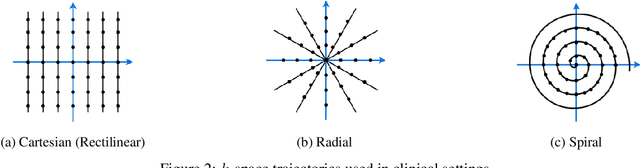

In spite of its extensive adaptation in almost every medical diagnostic and examinatorial application, Magnetic Resonance Imaging (MRI) is still a slow imaging modality which limits its use for dynamic imaging. In recent years, Parallel Imaging (PI) and Compressed Sensing (CS) have been utilised to accelerate the MRI acquisition. In clinical settings, subsampling the k-space measurements during scanning time using Cartesian trajectories, such as rectilinear sampling, is currently the most conventional CS approach applied which, however, is prone to producing aliased reconstructions. With the advent of the involvement of Deep Learning (DL) in accelerating the MRI, reconstructing faithful images from subsampled data became increasingly promising. Retrospectively applying a subsampling mask onto the k-space data is a way of simulating the accelerated acquisition of k-space data in real clinical setting. In this paper we compare and provide a review for the effect of applying either rectilinear or radial retrospective subsampling on the quality of the reconstructions outputted by trained deep neural networks. With the same choice of hyper-parameters, we train and evaluate two distinct Recurrent Inference Machines (RIMs), one for each type of subsampling. The qualitative and quantitative results of our experiments indicate that the model trained on data with radial subsampling attains higher performance and learns to estimate reconstructions with higher fidelity paving the way for other DL approaches to involve radial subsampling.