 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Learning Sparse Interaction Graphs of Partially Observed Pedestrians for Trajectory Prediction
Jul 15, 2021
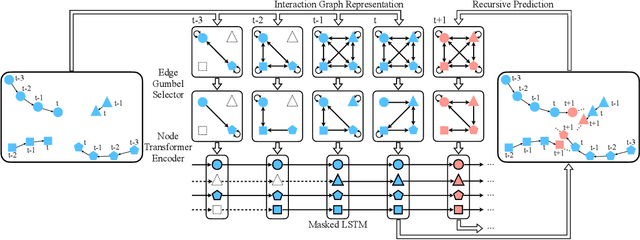
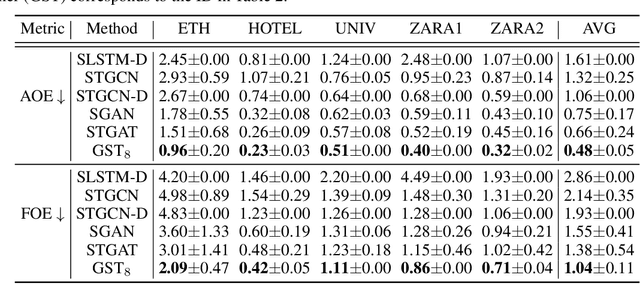
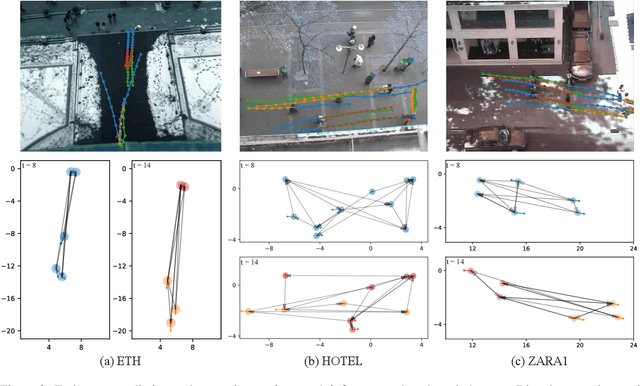
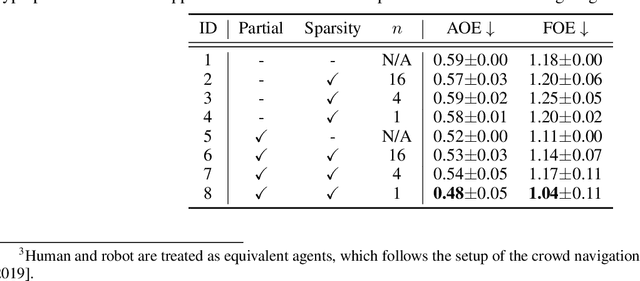
Multi-pedestrian trajectory prediction is an indispensable safety element of autonomous systems that interact with crowds in unstructured environments. Many recent efforts have developed trajectory prediction algorithms with focus on understanding social norms behind pedestrian motions. Yet we observe these works usually hold two assumptions that prevent them from being smoothly applied to robot applications: positions of all pedestrians are consistently tracked; the target agent pays attention to all pedestrians in the scene. The first assumption leads to biased interaction modeling with incomplete pedestrian data, and the second assumption introduces unnecessary disturbances and leads to the freezing robot problem. Thus, we propose Gumbel Social Transformer, in which an Edge Gumbel Selector samples a sparse interaction graph of partially observed pedestrians at each time step. A Node Transformer Encoder and a Masked LSTM encode the pedestrian features with the sampled sparse graphs to predict trajectories. We demonstrate that our model overcomes the potential problems caused by the assumptions, and our approach outperforms the related works in benchmark evaluation.
Space-time error estimates for deep neural network approximations for differential equations
Aug 11, 2019Over the last few years deep artificial neural networks (DNNs) have very successfully been used in numerical simulations for a wide variety of computational problems including computer vision, image classification, speech recognition, natural language processing, as well as computational advertisement. In addition, it has recently been proposed to approximate solutions of partial differential equations (PDEs) by means of stochastic learning problems involving DNNs. There are now also a few rigorous mathematical results in the scientific literature which provide error estimates for such deep learning based approximation methods for PDEs. All of these articles provide spatial error estimates for neural network approximations for PDEs but do not provide error estimates for the entire space-time error for the considered neural network approximations. It is the subject of the main result of this article to provide space-time error estimates for DNN approximations of Euler approximations of certain perturbed differential equations. Our proof of this result is based (i) on a certain artificial neural network (ANN) calculus and (ii) on ANN approximation results for products of the form $[0,T]\times \mathbb{R}^d\ni (t,x)\mapsto tx\in \mathbb{R}^d$ where $T\in (0,\infty)$, $d\in \mathbb{N}$, which we both develop within this article.
External-Memory Networks for Low-Shot Learning of Targets in Forward-Looking-Sonar Imagery
Jul 22, 2021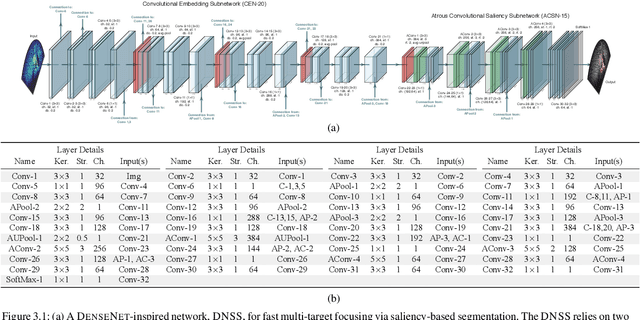
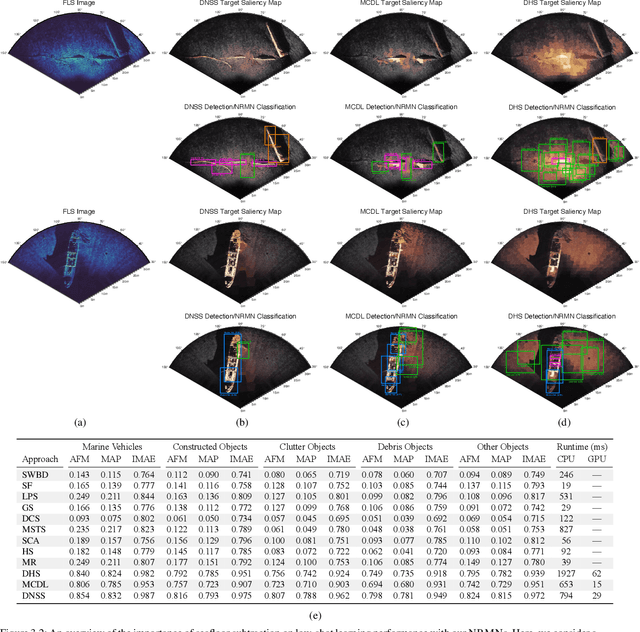
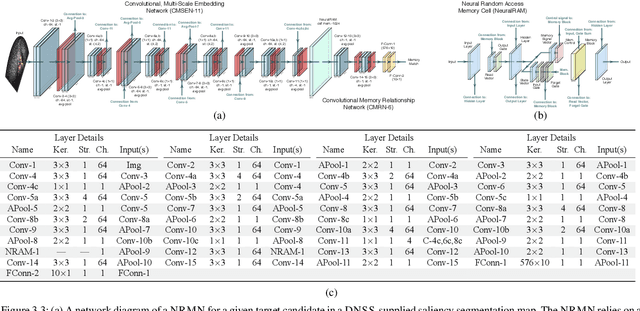
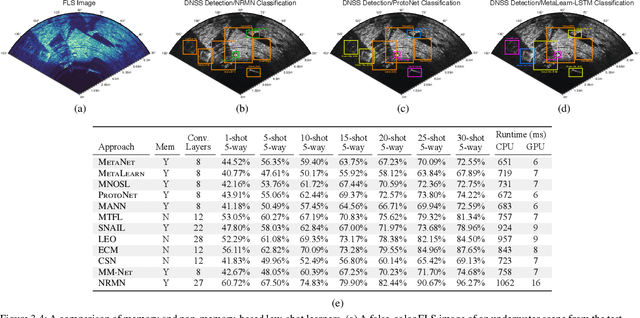
We propose a memory-based framework for real-time, data-efficient target analysis in forward-looking-sonar (FLS) imagery. Our framework relies on first removing non-discriminative details from the imagery using a small-scale DenseNet-inspired network. Doing so simplifies ensuing analyses and permits generalizing from few labeled examples. We then cascade the filtered imagery into a novel NeuralRAM-based convolutional matching network, NRMN, for low-shot target recognition. We employ a small-scale FlowNet, LFN to align and register FLS imagery across local temporal scales. LFN enables target label consensus voting across images and generally improves target detection and recognition rates. We evaluate our framework using real-world FLS imagery with multiple broad target classes that have high intra-class variability and rich sub-class structure. We show that few-shot learning, with anywhere from ten to thirty class-specific exemplars, performs similarly to supervised deep networks trained on hundreds of samples per class. Effective zero-shot learning is also possible. High performance is realized from the inductive-transfer properties of NRMNs when distractor elements are removed.
Forecaster: A Graph Transformer for Forecasting Spatial and Time-Dependent Data
Sep 09, 2019
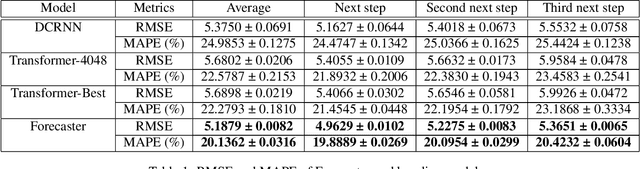
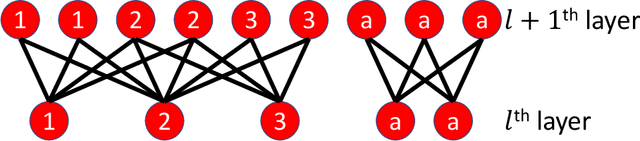
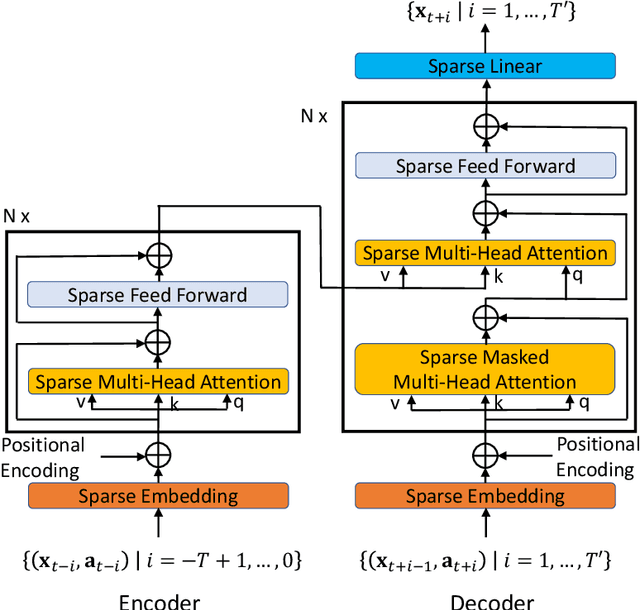
Spatial and time-dependent data is of interest in many applications. This task is difficult due to its complex spatial dependency, long-range temporal dependency, data non-stationarity, and data heterogeneity. To address these challenges, we propose Forecaster, a graph Transformer architecture. Specifically, we start by learning the structure of the graph that parsimoniously represents the spatial dependency between the data at different locations. Based on the topology of the graph, we sparsify the Transformer to account for the strength of spatial dependency, long-range temporal dependency, data non-stationarity, and data heterogeneity. We evaluate Forecaster in the problem of forecasting taxi ride-hailing demand and show that our proposed architecture significantly outperforms the state-of-the-art baselines.
Fast approximations of the Jeffreys divergence between univariate Gaussian mixture models via exponential polynomial densities
Aug 04, 2021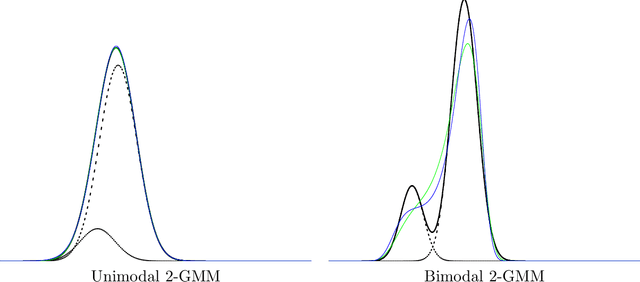
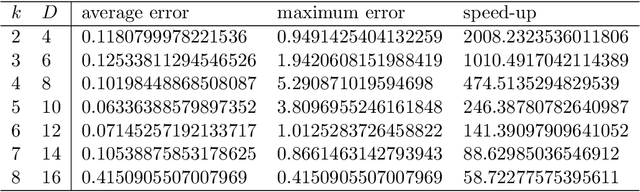
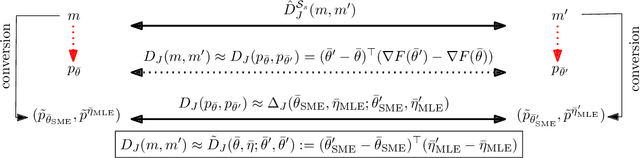

The Jeffreys divergence is a renown symmetrization of the statistical Kullback-Leibler divergence which is often used in statistics, machine learning, signal processing, and information sciences in general. Since the Jeffreys divergence between the ubiquitous Gaussian Mixture Models are not available in closed-form, many techniques with various pros and cons have been proposed in the literature to either (i) estimate, (ii) approximate, or (iii) lower and/or upper bound this divergence. In this work, we propose a simple yet fast heuristic to approximate the Jeffreys divergence between two univariate GMMs of arbitrary number of components. The heuristic relies on converting GMMs into pairs of dually parameterized probability densities belonging to exponential families. In particular, we consider Exponential-Polynomial Densities, and design a goodness-of-fit criterion to measure the dissimilarity between a GMM and a EPD which is a generalization of the Hyv\"arinen divergence. This criterion allows one to select the orders of the EPDs to approximate the GMMs. We demonstrate experimentally that the computational time of our heuristic improves over the stochastic Monte Carlo estimation baseline by several orders of magnitude while approximating reasonably well the Jeffreys divergence, specially when the univariate mixtures have a small number of modes.
An efficient approach for tracking the aerosol-cloud interactions formed by ship emissions using GOES-R satellite imagery and AIS ship tracking information
Aug 20, 2021
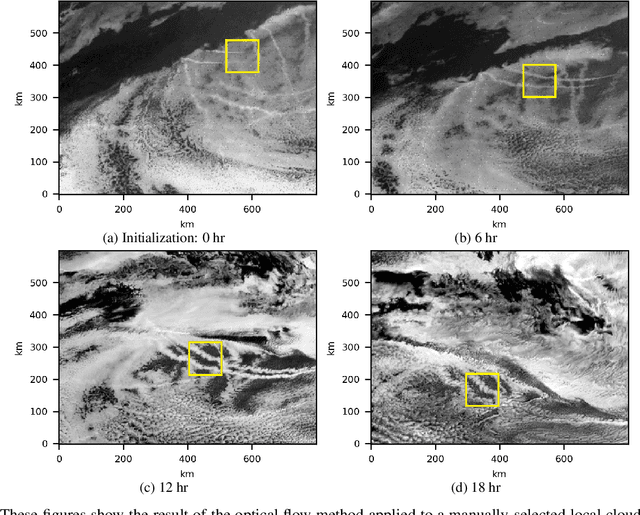

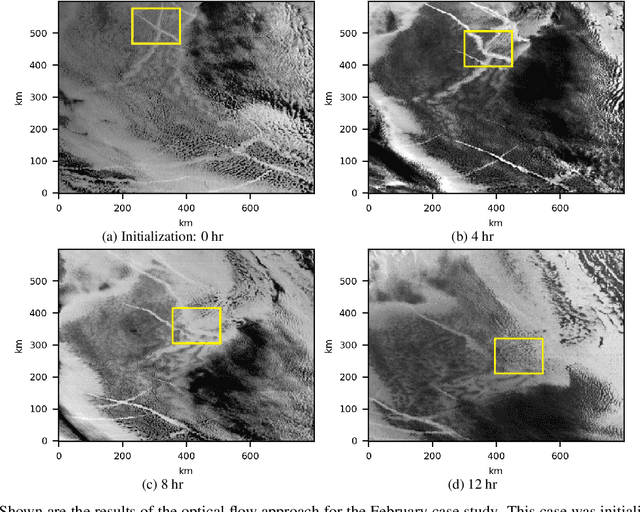
Ship emissions can form linear cloud features, or ship tracks, when atmospheric water vapor condenses on aerosols in the ship exhaust. These features are of interest because they are observable and traceable examples of marine cloud brightening, a mechanism that has been studied as a potential approach for solar climate intervention. Ship tracks can be observed throughout the diurnal cycle via space-borne assets like the Advanced Baseline Imagers on the National Oceanic and Atmospheric Administration Geostationary Operational Environmental Satellites, the GOES-R series. Due to complex atmospheric dynamics, it can be difficult to track these aerosol perturbations over space and time to precisely characterize how long a single emission source can significantly contribute to indirect radiative forcing. We combine GOES-17 satellite imagery with ship location information to demonstrate two feasible methods of tracing the trajectories of ship-emitted aerosols after they begin mixing with low boundary layer clouds in three test cases. The first method uses the parcel trajectory model HYSPLIT, which was driven by well-studied physical processes but often could not follow the ship track beyond 8 hours. The second method uses the image processing technique, optical flow, which could follow the track throughout its lifetime, but requires high contrast features for best performance. These approaches show that ship tracks persist as visible, linear features beyond 9 hr and sometimes longer than 24 hr. This research sets the stage for a more thorough exploration of the atmospheric conditions and exhaust compositions that produce ship tracks and factors that determine track persistence.
Incentivized Bandit Learning with Self-Reinforcing User Preferences
May 31, 2021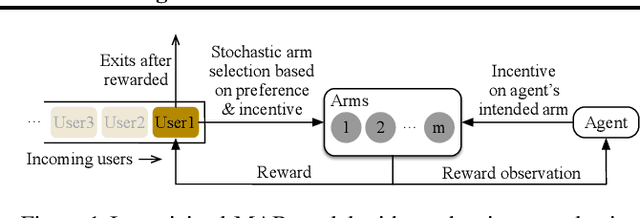
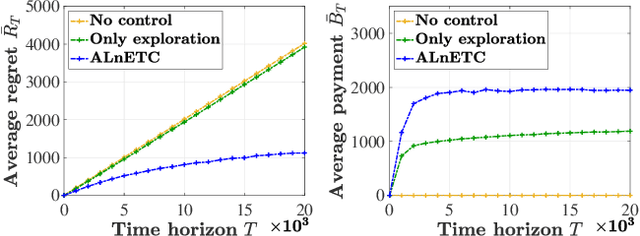
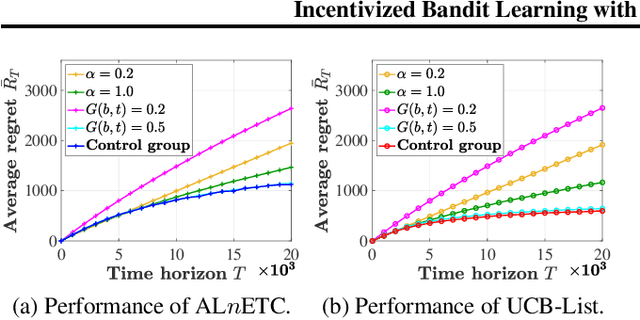
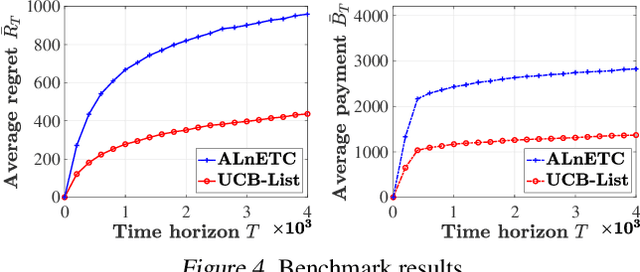
In this paper, we investigate a new multi-armed bandit (MAB) online learning model that considers real-world phenomena in many recommender systems: (i) the learning agent cannot pull the arms by itself and thus has to offer rewards to users to incentivize arm-pulling indirectly; and (ii) if users with specific arm preferences are well rewarded, they induce a "self-reinforcing" effect in the sense that they will attract more users of similar arm preferences. Besides addressing the tradeoff of exploration and exploitation, another key feature of this new MAB model is to balance reward and incentivizing payment. The goal of the agent is to maximize the total reward over a fixed time horizon $T$ with a low total payment. Our contributions in this paper are two-fold: (i) We propose a new MAB model with random arm selection that considers the relationship of users' self-reinforcing preferences and incentives; and (ii) We leverage the properties of a multi-color Polya urn with nonlinear feedback model to propose two MAB policies termed "At-Least-$n$ Explore-Then-Commit" and "UCB-List". We prove that both policies achieve $O(log T)$ expected regret with $O(log T)$ expected payment over a time horizon $T$. We conduct numerical simulations to demonstrate and verify the performances of these two policies and study their robustness under various settings.
Time Series Prediction : Predicting Stock Price
Oct 19, 2017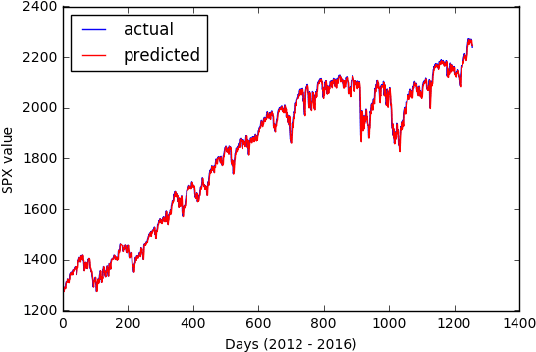
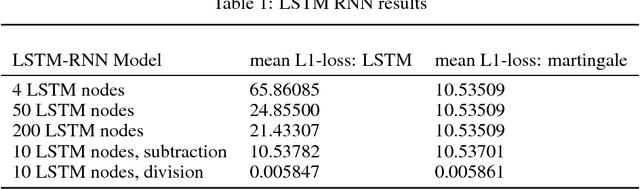
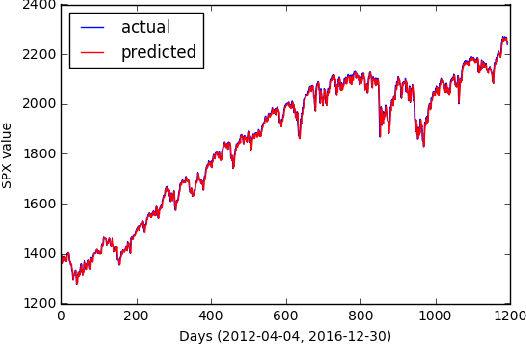
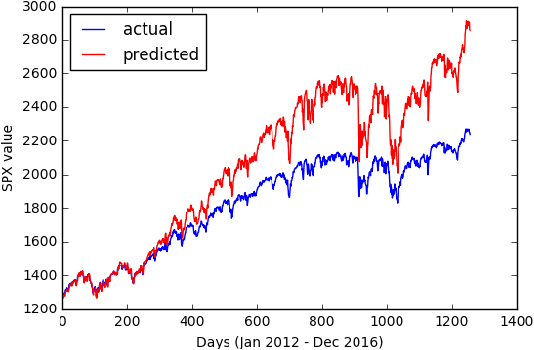
Time series forecasting is widely used in a multitude of domains. In this paper, we present four models to predict the stock price using the SPX index as input time series data. The martingale and ordinary linear models require the strongest assumption in stationarity which we use as baseline models. The generalized linear model requires lesser assumptions but is unable to outperform the martingale. In empirical testing, the RNN model performs the best comparing to other two models, because it will update the input through LSTM instantaneously, but also does not beat the martingale. In addition, we introduce an online to batch algorithm and discrepancy measure to inform readers the newest research in time series predicting method, which doesn't require any stationarity or non mixing assumptions in time series data. Finally, to apply these forecasting to practice, we introduce basic trading strategies that can create Win win and Zero sum situations.
CRIL: Continual Robot Imitation Learning via Generative and Prediction Model
Jul 02, 2021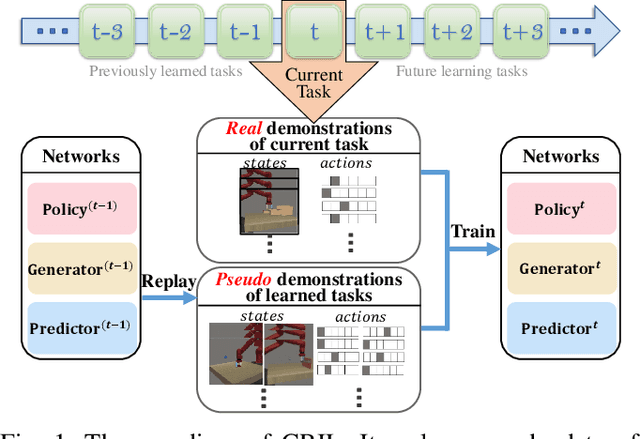
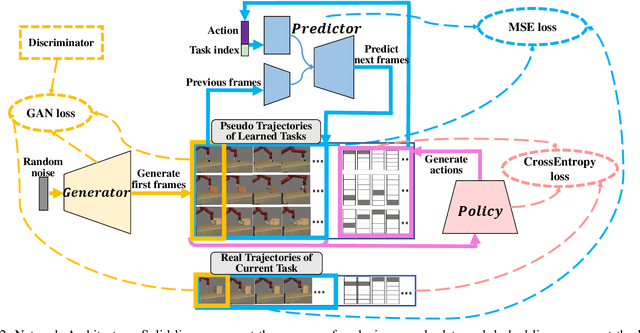
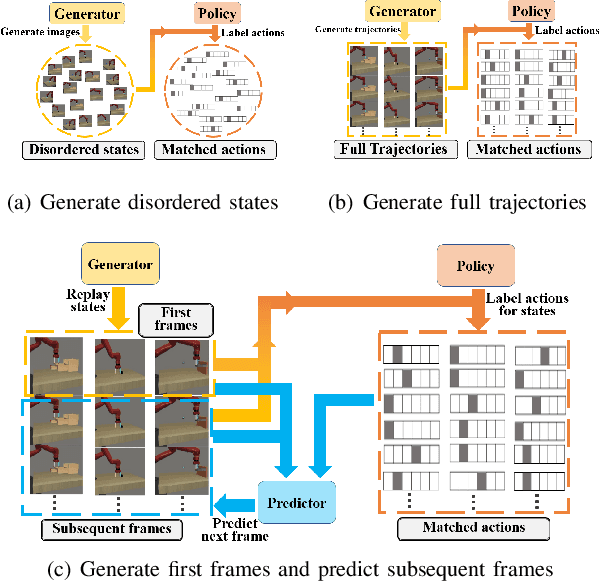

Imitation learning (IL) algorithms have shown promising results for robots to learn skills from expert demonstrations. However, they need multi-task demonstrations to be provided at once for acquiring diverse skills, which is difficult in real world. In this work we study how to realize continual imitation learning ability that empowers robots to continually learn new tasks one by one, thus reducing the burden of multi-task IL and accelerating the process of new task learning at the same time. We propose a novel trajectory generation model that employs both a generative adversarial network and a dynamics-aware prediction model to generate pseudo trajectories from all learned tasks in the new task learning process. Our experiments on both simulation and real-world manipulation tasks demonstrate the effectiveness of our method.
Minimax Regret for Bandit Convex Optimisation of Ridge Functions
Jun 06, 2021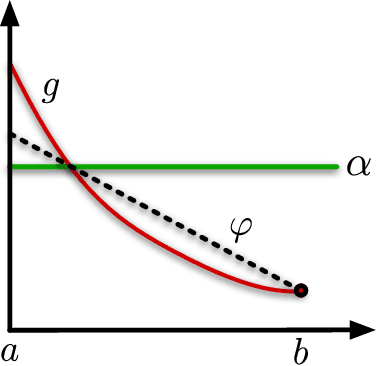
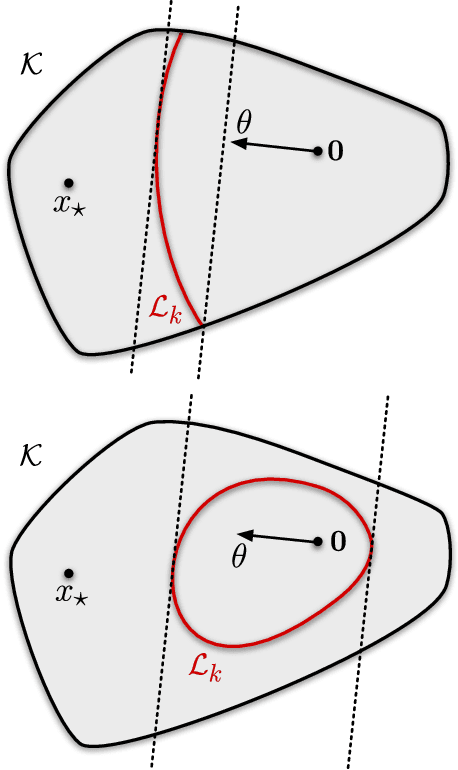
We analyse adversarial bandit convex optimisation with an adversary that is restricted to playing functions of the form $f_t(x) = g_t(\langle x, \theta\rangle)$ for convex $g_t : \mathbb R \to \mathbb R$ and unknown $\theta \in \mathbb R^d$ that is homogeneous over time. We provide a short information-theoretic proof that the minimax regret is at most $O(d \sqrt{n} \log(n \operatorname{diam}(\mathcal K)))$ where $n$ is the number of interactions, $d$ the dimension and $\operatorname{diam}(\mathcal K)$ is the diameter of the constraint set.