 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
DNNFusion: Accelerating Deep Neural Networks Execution with Advanced Operator Fusion
Aug 30, 2021
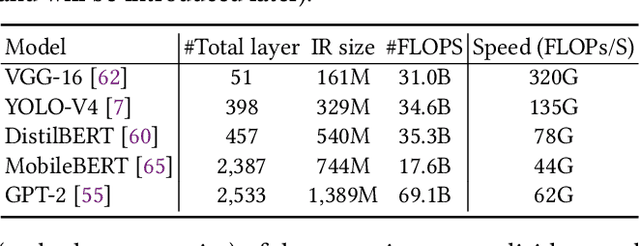
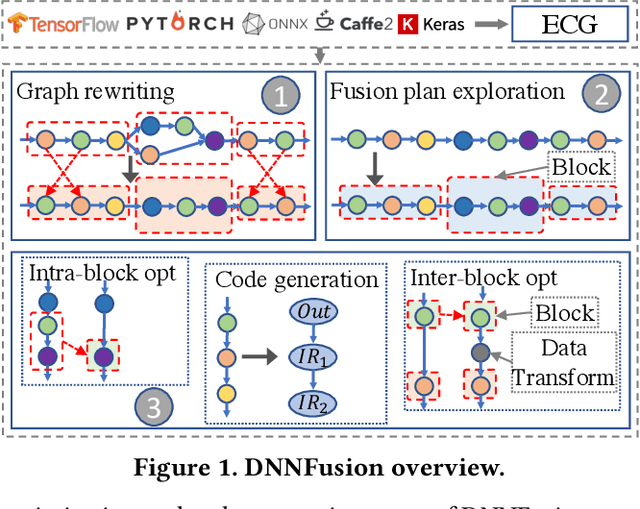

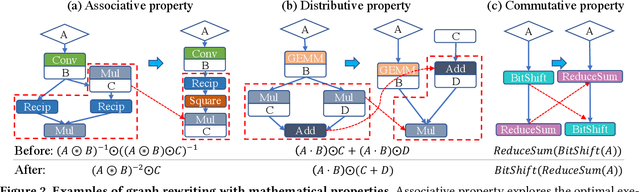
Deep Neural Networks (DNNs) have emerged as the core enabler of many major applications on mobile devices. To achieve high accuracy, DNN models have become increasingly deep with hundreds or even thousands of operator layers, leading to high memory and computational requirements for inference. Operator fusion (or kernel/layer fusion) is key optimization in many state-of-the-art DNN execution frameworks, such as TensorFlow, TVM, and MNN. However, these frameworks usually adopt fusion approaches based on certain patterns that are too restrictive to cover the diversity of operators and layer connections. Polyhedral-based loop fusion techniques, on the other hand, work on a low-level view of the computation without operator-level information, and can also miss potential fusion opportunities. To address this challenge, this paper proposes a novel and extensive loop fusion framework called DNNFusion. The basic idea of this work is to work at an operator view of DNNs, but expand fusion opportunities by developing a classification of both individual operators and their combinations. In addition, DNNFusion includes 1) a novel mathematical-property-based graph rewriting framework to reduce evaluation costs and facilitate subsequent operator fusion, 2) an integrated fusion plan generation that leverages the high-level analysis and accurate light-weight profiling, and 3) additional optimizations during fusion code generation. DNNFusion is extensively evaluated on 15 DNN models with varied types of tasks, model sizes, and layer counts. The evaluation results demonstrate that DNNFusion finds up to 8.8x higher fusion opportunities, outperforms four state-of-the-art DNN execution frameworks with 9.3x speedup. The memory requirement reduction and speedups can enable the execution of many of the target models on mobile devices and even make them part of a real-time application.
ProAI: An Efficient Embedded AI Hardware for Automotive Applications - a Benchmark Study
Aug 11, 2021
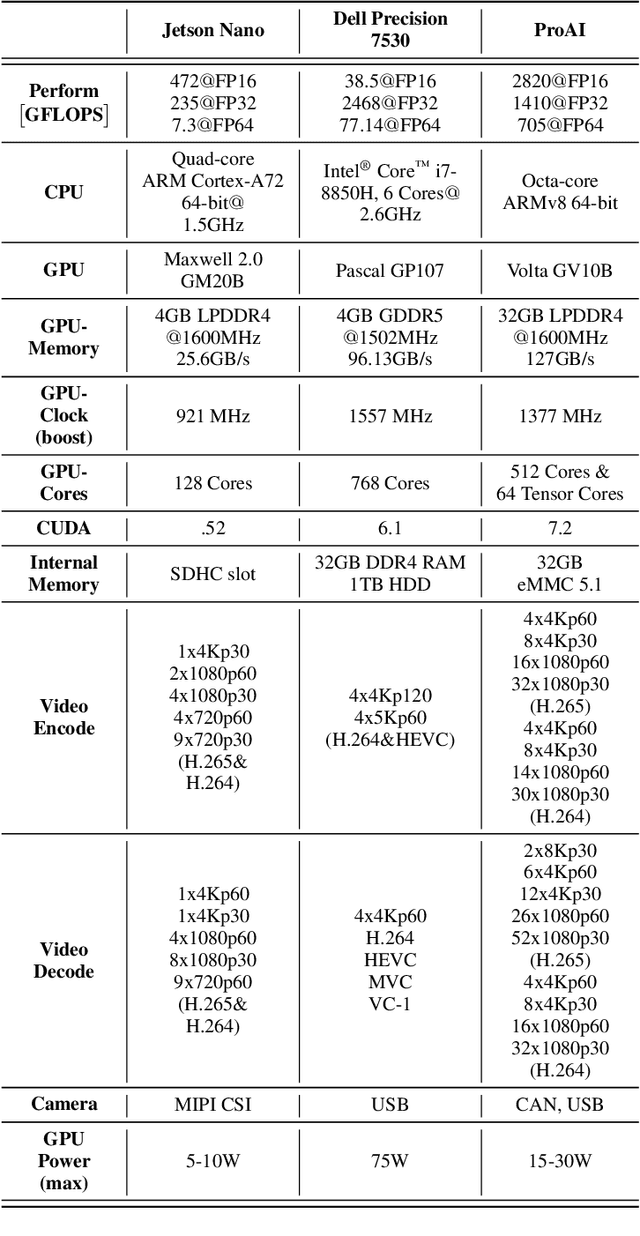

Development in the field of Single Board Computers (SBC) have been increasing for several years. They provide a good balance between computing performance and power consumption which is usually required for mobile platforms, like application in vehicles for Advanced Driver Assistance Systems (ADAS) and Autonomous Driving (AD). However, there is an ever-increasing need of more powerful and efficient SBCs which can run power intensive Deep Neural Networks (DNNs) in real-time and can also satisfy necessary functional safety requirements such as Automotive Safety Integrity Level (ASIL). ProAI is being developed by ZF mainly to run powerful and efficient applications such as multitask DNNs and on top of that it also has the required safety certification for AD. In this work, we compare and discuss state of the art SBC on the basis of power intensive multitask DNN architecture called Multitask-CenterNet with respect to performance measures such as, FPS and power efficiency. As an automotive supercomputer, ProAI delivers an excellent combination of performance and efficiency, managing nearly twice the number of FPS per watt than a modern workstation laptop and almost four times compared to the Jetson Nano. Furthermore, it was also shown that there is still power in reserve for further and more complex tasks on the ProAI, based on the CPU and GPU utilization during the benchmark.
Preventing Catastrophic Forgetting and Distribution Mismatch in Knowledge Distillation via Synthetic Data
Aug 11, 2021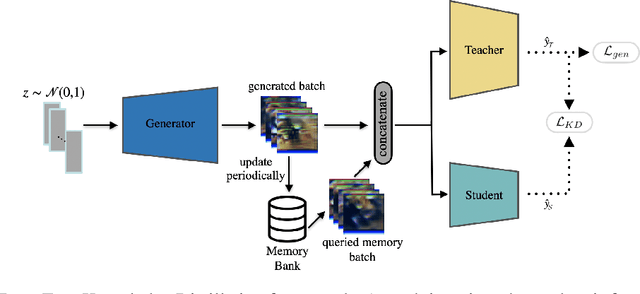
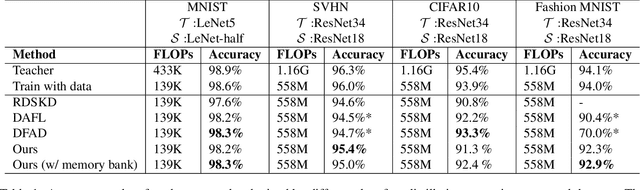

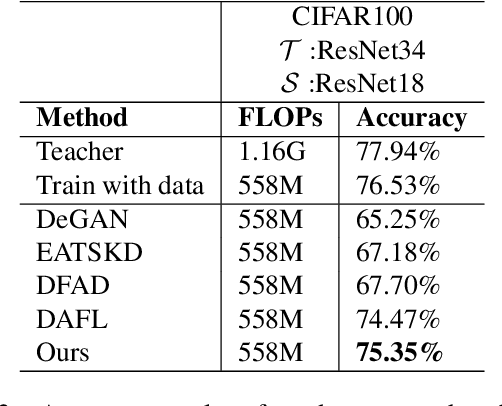
With the increasing popularity of deep learning on edge devices, compressing large neural networks to meet the hardware requirements of resource-constrained devices became a significant research direction. Numerous compression methodologies are currently being used to reduce the memory sizes and energy consumption of neural networks. Knowledge distillation (KD) is among such methodologies and it functions by using data samples to transfer the knowledge captured by a large model (teacher) to a smaller one(student). However, due to various reasons, the original training data might not be accessible at the compression stage. Therefore, data-free model compression is an ongoing research problem that has been addressed by various works. In this paper, we point out that catastrophic forgetting is a problem that can potentially be observed in existing data-free distillation methods. Moreover, the sample generation strategies in some of these methods could result in a mismatch between the synthetic and real data distributions. To prevent such problems, we propose a data-free KD framework that maintains a dynamic collection of generated samples over time. Additionally, we add the constraint of matching the real data distribution in sample generation strategies that target maximum information gain. Our experiments demonstrate that we can improve the accuracy of the student models obtained via KD when compared with state-of-the-art approaches on the SVHN, Fashion MNIST and CIFAR100 datasets.
Millimeter-Wave NR-U and WiGig Coexistence: Joint User Grouping, Beam Coordination and Power Control
Aug 11, 2021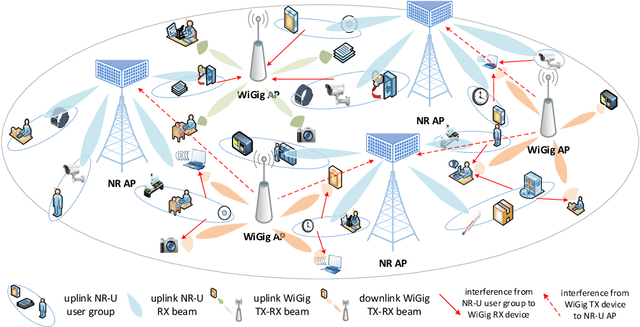
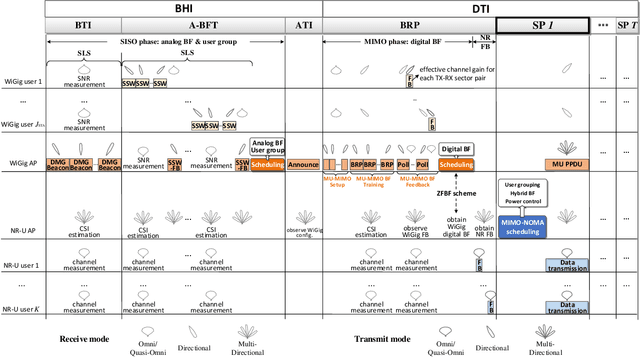
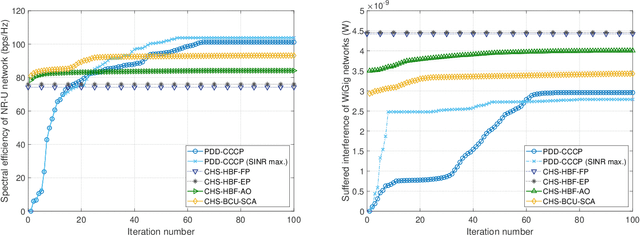
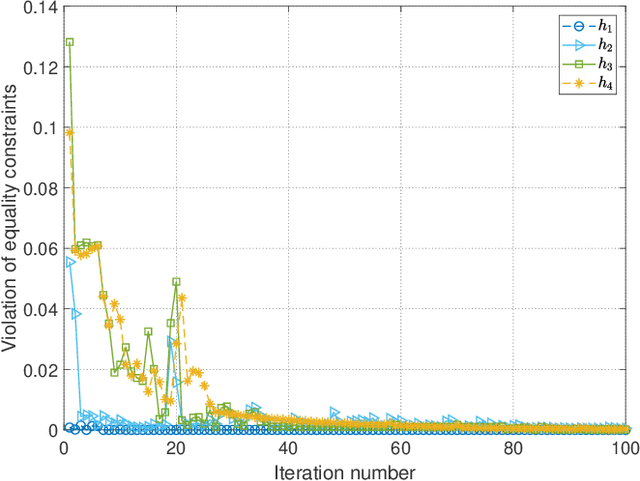
Millimeter wave (mmWave) communication is a promising New Radio in Unlicensed (NR-U) technology to meet with the ever-increasing data rate and connectivity requirements in future wireless networks. However, the development of NR-U networks should consider the coexistence with the incumbent Wireless Gigabit (WiGig) networks. In this paper, we introduce a novel multiple-input multiple-output non-orthogonal multiple access (MIMO-NOMA) based mmWave NR-U and WiGig coexistence network for uplink transmission. Our aim for the proposed coexistence network is to maximize the spectral efficiency while ensuring the strict NR-U delay requirement and the WiGig transmission performance in real time environments. A joint user grouping, hybrid beam coordination and power control strategy is proposed, which is formulated as a Lyapunov optimization based mixed-integer nonlinear programming (MINLP) with unit-modulus and nonconvex coupling constraints. Hence, we introduce a penalty dual decomposition (PDD) framework, which first transfers the formulated MINLP into a tractable augmented Lagrangian (AL) problem. Thereafter, we integrate both convex-concave procedure (CCCP) and inexact block coordinate update (BCU) methods to approximately decompose the AL problem into multiple nested convex subproblems, which can be iteratively solved under the PDD framework. Numerical results illustrate the performance improvement ability of the proposed strategy, as well as demonstrate the effectiveness to guarantee the NR-U traffic delay and WiGig network performance.
Masked Face Recognition Challenge: The WebFace260M Track Report
Aug 16, 2021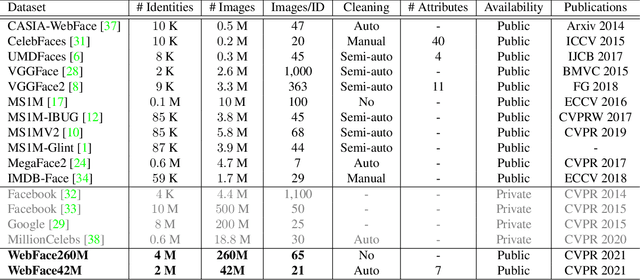
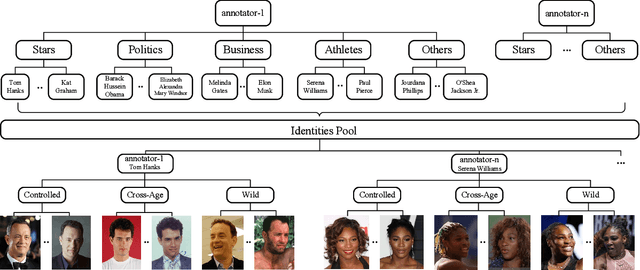
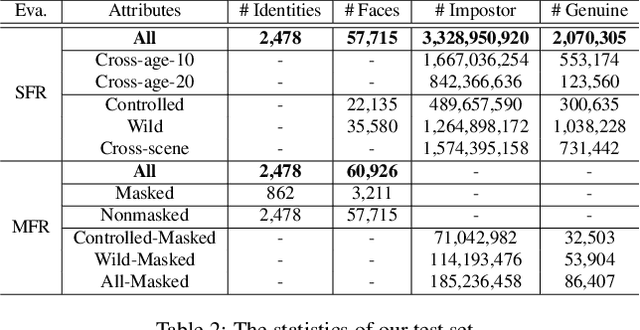
According to WHO statistics, there are more than 204,617,027 confirmed COVID-19 cases including 4,323,247 deaths worldwide till August 12, 2021. During the coronavirus epidemic, almost everyone wears a facial mask. Traditionally, face recognition approaches process mostly non-occluded faces, which include primary facial features such as the eyes, nose, and mouth. Removing the mask for authentication in airports or laboratories will increase the risk of virus infection, posing a huge challenge to current face recognition systems. Due to the sudden outbreak of the epidemic, there are yet no publicly available real-world masked face recognition (MFR) benchmark. To cope with the above-mentioned issue, we organize the Face Bio-metrics under COVID Workshop and Masked Face Recognition Challenge in ICCV 2021. Enabled by the ultra-large-scale WebFace260M benchmark and the Face Recognition Under Inference Time conStraint (FRUITS) protocol, this challenge (WebFace260M Track) aims to push the frontiers of practical MFR. Since public evaluation sets are mostly saturated or contain noise, a new test set is gathered consisting of elaborated 2,478 celebrities and 60,926 faces. Meanwhile, we collect the world-largest real-world masked test set. In the first phase of WebFace260M Track, 69 teams (total 833 solutions) participate in the challenge and 49 teams exceed the performance of our baseline. There are second phase of the challenge till October 1, 2021 and on-going leaderboard. We will actively update this report in the future.
Time Series Analysis of Electricity Price and Demand to Find Cyber-attacks using Stationary Analysis
Aug 20, 2019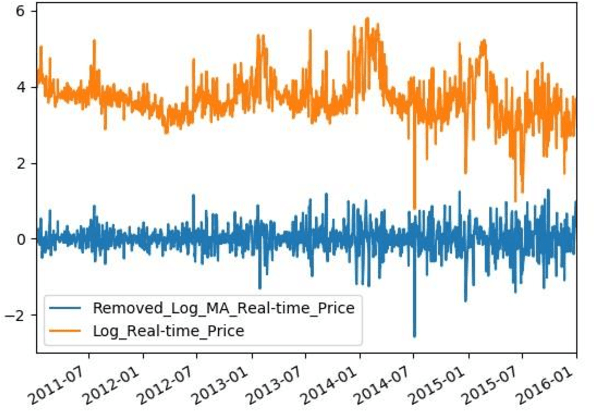
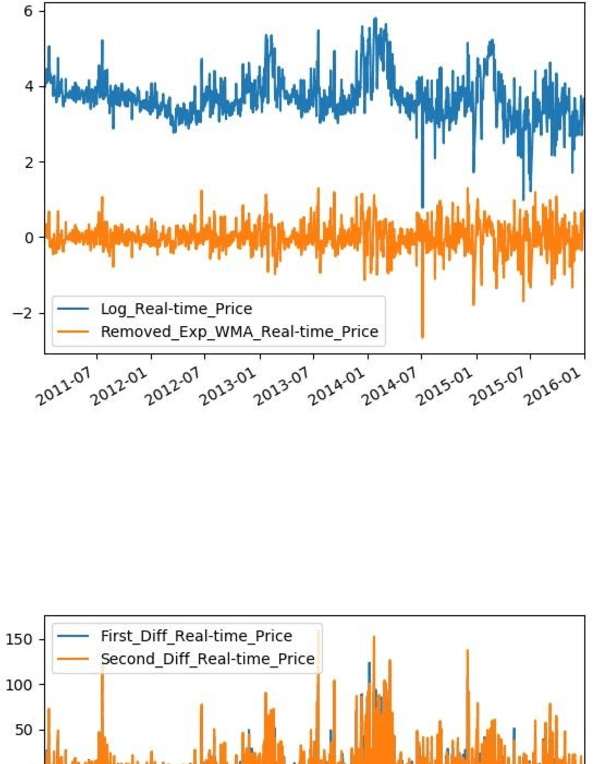
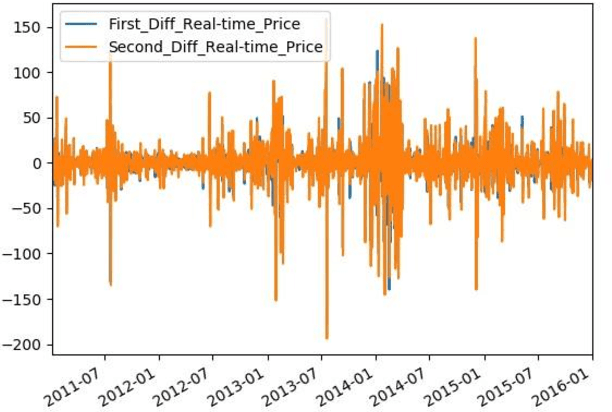
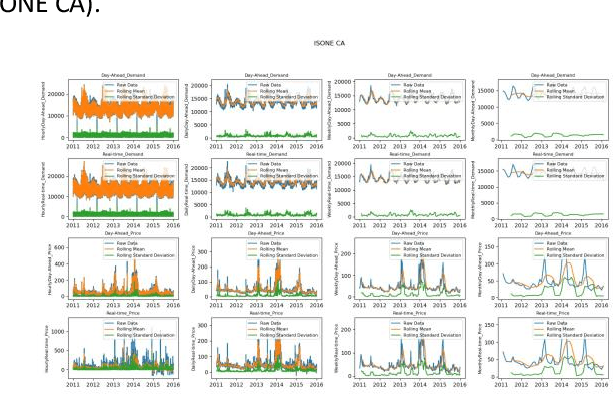
With developing of computation tools in the last years, data analysis methods to find insightful information are becoming more common among industries and researchers. This paper is the first part of the times series analysis of New England electricity price and demand to find anomaly in the data. In this paper time-series stationary criteria to prepare data for further times-series related analysis is investigated. Three main analysis are conducted in this paper, including moving average, moving standard deviation and augmented Dickey-Fuller test. The data used in this paper is New England big data from 9 different operational zones. For each zone, 4 different variables including day-ahead (DA) electricity demand, price and real-time (RT) electricity demand price are considered.
Set-Valued Rigid Body Dynamics for Simultaneous Frictional Impact
Apr 06, 2021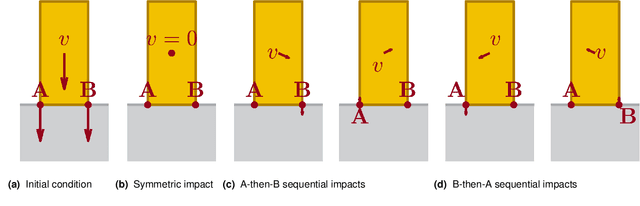

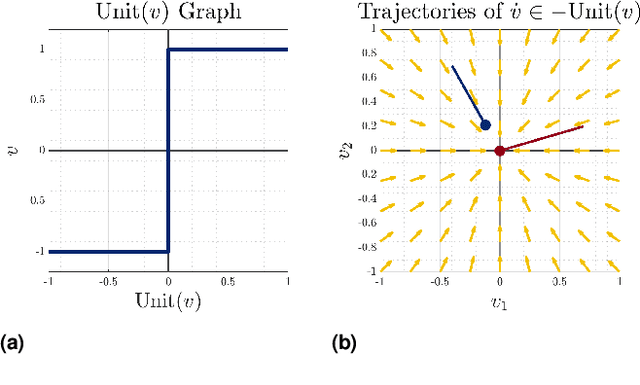

Robotic manipulation and locomotion often entail nearly-simultaneous collisions -- such as heel and toe strikes during a foot step -- with outcomes that are extremely sensitive to the order in which impacts occur. Robotic simulators commonly lack the accuracy to predict this ordering, and instead pick one with a heuristic. This discrepancy degrades performance when model-based controllers and policies learned in simulation are placed on a real robot. We reconcile this issue with a set-valued rigid-body model which generates a broad set of physically reasonable outcomes of simultaneous frictional impacts. We first extend Routh's impact model to multiple impacts by reformulating it as a differential inclusion (DI), and show that any solution will resolve all impacts in finite time. By considering time as a state, we embed this model into another DI which captures the continuous-time evolution of rigid body dynamics, and guarantee existence of solutions. We finally cast simulation of simultaneous impacts as a linear complementarity problem (LCP), and develop an algorithm for tight approximation of the post-impact velocity set with probabilistic guarantees. We demonstrate our approach on several examples drawn from manipulation and legged locomotion.
Contrastive Learning for Sports Video: Unsupervised Player Classification
May 03, 2021
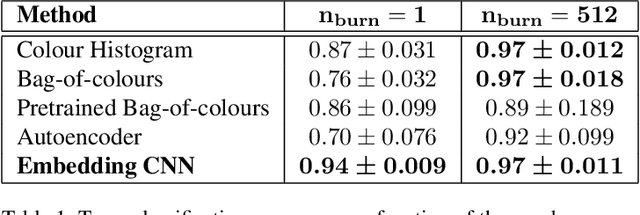

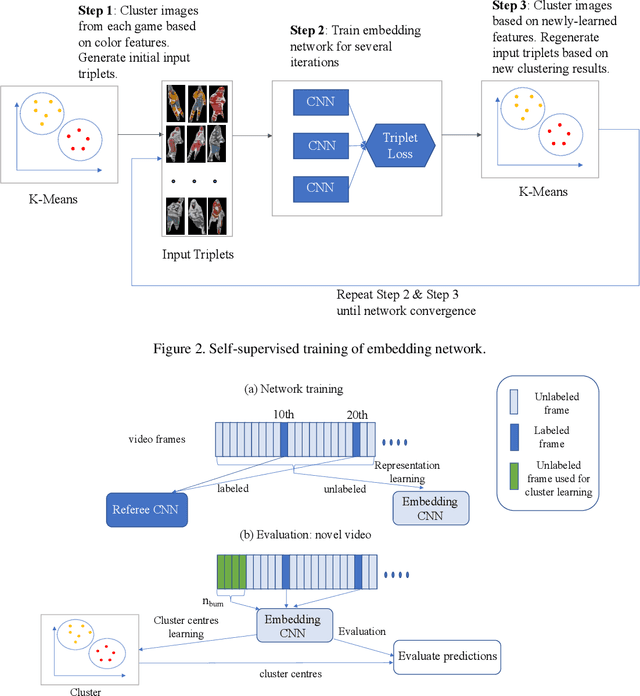
We address the problem of unsupervised classification of players in a team sport according to their team affiliation, when jersey colours and design are not known a priori. We adopt a contrastive learning approach in which an embedding network learns to maximize the distance between representations of players on different teams relative to players on the same team, in a purely unsupervised fashion, without any labelled data. We evaluate the approach using a new hockey dataset and find that it outperforms prior unsupervised approaches by a substantial margin, particularly for real-time application when only a small number of frames are available for unsupervised learning before team assignments must be made. Remarkably, we show that our contrastive method achieves 94% accuracy after unsupervised training on only a single frame, with accuracy rising to 97% within 500 frames (17 seconds of game time). We further demonstrate how accurate team classification allows accurate team-conditional heat maps of player positioning to be computed.
OLR 2021 Challenge: Datasets, Rules and Baselines
Jul 23, 2021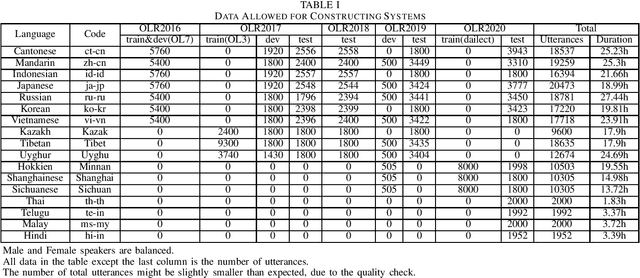

This paper introduces the sixth Oriental Language Recognition (OLR) 2021 Challenge, which intends to improve the performance of language recognition systems and speech recognition systems within multilingual scenarios. The data profile, four tasks, two baselines, and the evaluation principles are introduced in this paper. In addition to the Language Identification (LID) tasks, multilingual Automatic Speech Recognition (ASR) tasks are introduced to OLR 2021 Challenge for the first time. The challenge this year focuses on more practical and challenging problems, with four tasks: (1) constrained LID, (2) unconstrained LID, (3) constrained multilingual ASR, (4) unconstrained multilingual ASR. Baselines for LID tasks and multilingual ASR tasks are provided, respectively. The LID baseline system is an extended TDNN x-vector model constructed with Pytorch. A transformer-based end-to-end model is provided as the multilingual ASR baseline system. These recipes will be online published, and available for participants to construct their own LID or ASR systems. The baseline results demonstrate that those tasks are rather challenging and deserve more effort to achieve better performance.
Real-time Hand Gesture Detection and Classification Using Convolutional Neural Networks
Jan 29, 2019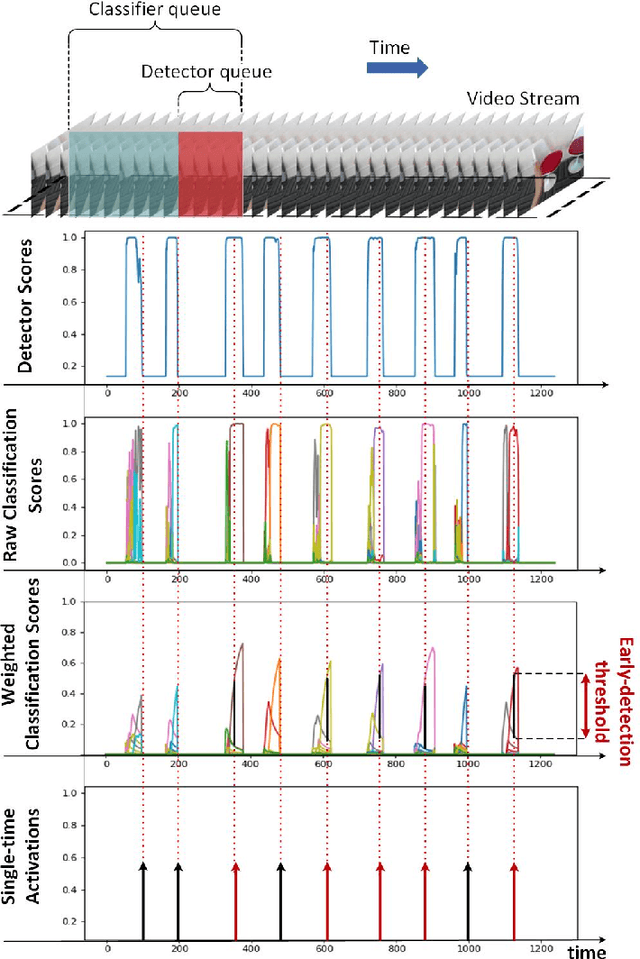
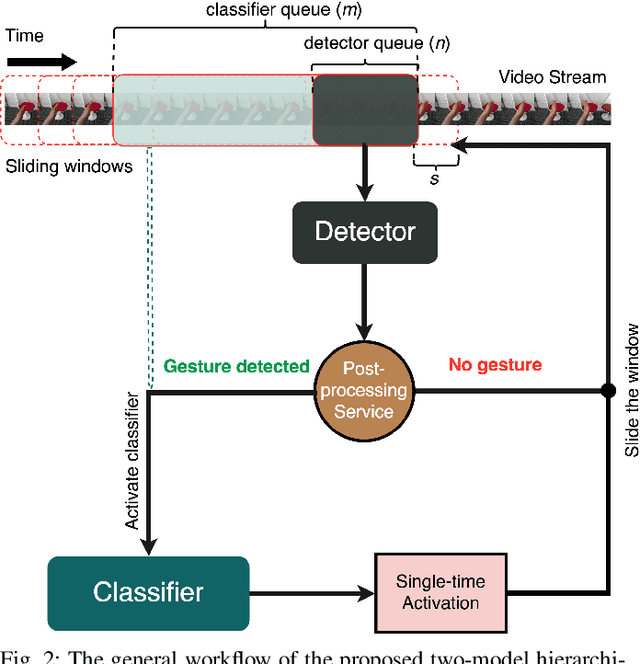
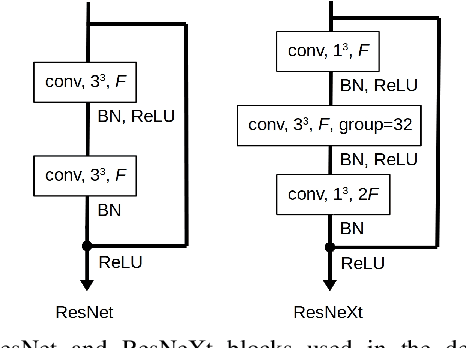
Real-time recognition of dynamic hand gestures from video streams is a challenging task since (i) there is no indication when a gesture starts and ends in the video, (ii) performed gestures should only be recognized once, and (iii) the entire architecture should be designed considering the memory and power budget. In this work, we address these challenges by proposing a hierarchical structure enabling offline-working convolutional neural network (CNN) architectures to operate online efficiently by using sliding window approach. The proposed architecture consists of two models: (1) A detector which is a lightweight CNN architecture to detect gestures and (2) a classifier which is a deep CNN to classify the detected gestures. In order to evaluate the single-time activations of the detected gestures, we propose to use the Levenshtein distance as an evaluation metric since it can measure misclassifications, multiple detections, and missing detections at the same time. We evaluate our architecture on two publicly available datasets - EgoGesture and NVIDIA Dynamic Hand Gesture Datasets - which require temporal detection and classification of the performed hand gestures. ResNeXt-101 model, which is used as a classifier, achieves the state-of-the-art offline classification accuracy of 94.04% and 83.82% for depth modality on EgoGesture and NVIDIA benchmarks, respectively. In real-time detection and classification, we obtain considerable early detections while achieving performances close to offline operation. The codes and pretrained models used in this work are publicly available.