 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Foundations of Sequence-to-Sequence Modeling for Time Series
May 09, 2018

The availability of large amounts of time series data, paired with the performance of deep-learning algorithms on a broad class of problems, has recently led to significant interest in the use of sequence-to-sequence models for time series forecasting. We provide the first theoretical analysis of this time series forecasting framework. We include a comparison of sequence-to-sequence modeling to classical time series models, and as such our theory can serve as a quantitative guide for practitioners choosing between different modeling methodologies.
Optimal and Fast Real-time Resources Slicing with Deep Dueling Neural Networks
Feb 26, 2019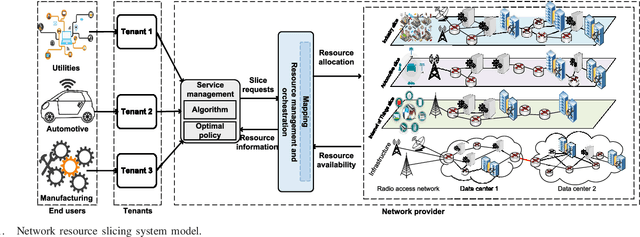
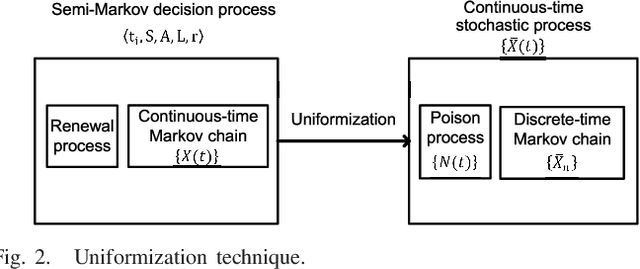
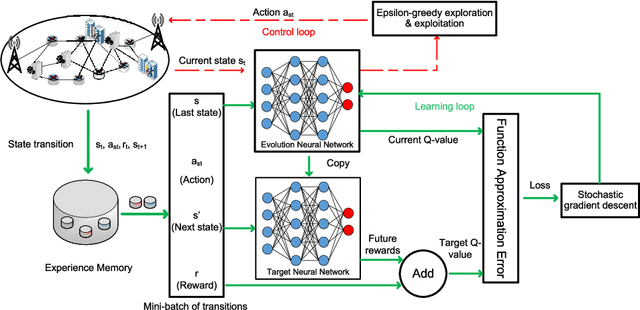
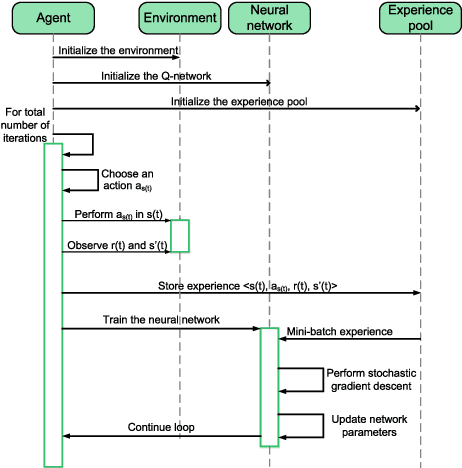
Effective network slicing requires an infrastructure/network provider to deal with the uncertain demand and real-time dynamics of network resource requests. Another challenge is the combinatorial optimization of numerous resources, e.g., radio, computing, and storage. This article develops an optimal and fast real-time resource slicing framework that maximizes the long-term return of the network provider while taking into account the uncertainty of resource demand from tenants. Specifically, we first propose a novel system model which enables the network provider to effectively slice various types of resources to different classes of users under separate virtual slices. We then capture the real-time arrival of slice requests by a semi-Markov decision process. To obtain the optimal resource allocation policy under the dynamics of slicing requests, e.g., uncertain service time and resource demands, a Q-learning algorithm is often adopted in the literature. However, such an algorithm is notorious for its slow convergence, especially for problems with large state/action spaces. This makes Q-learning practically inapplicable to our case in which multiple resources are simultaneously optimized. To tackle it, we propose a novel network slicing approach with an advanced deep learning architecture, called deep dueling that attains the optimal average reward much faster than the conventional Q-learning algorithm. This property is especially desirable to cope with real-time resource requests and the dynamic demands of users. Extensive simulations show that the proposed framework yields up to 40% higher long-term average return while being few thousand times faster, compared with state of the art network slicing approaches.
Real time backbone for semantic segmentation
Mar 16, 2019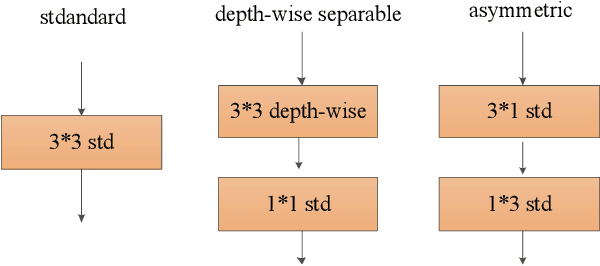
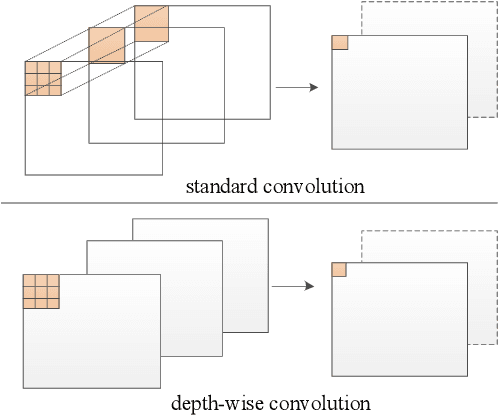
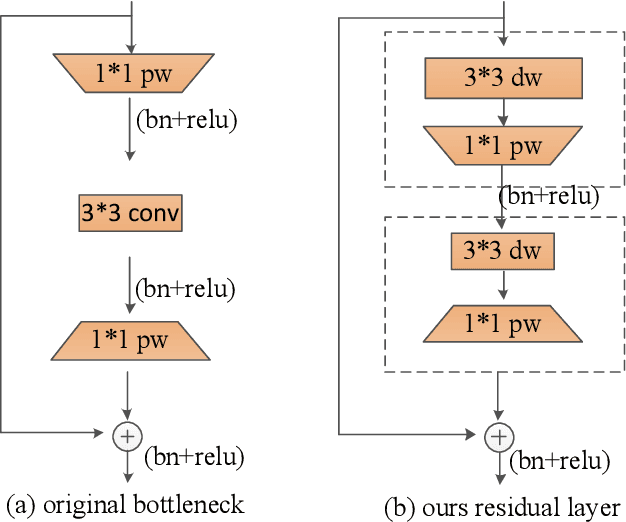
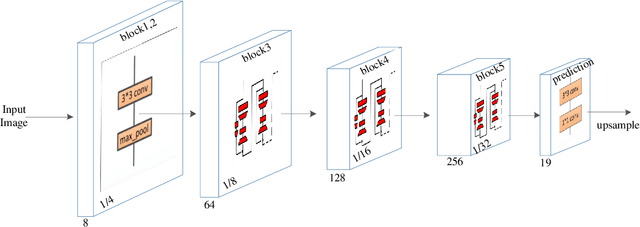
The rapid development of autonomous driving in recent years presents lots of challenges for scene understanding. As an essential step towards scene understanding, semantic segmentation thus received lots of attention in past few years. Although deep learning based state-of-the-arts have achieved great success in improving the segmentation accuracy, most of them suffer from an inefficiency problem and can hardly applied to practical applications. In this paper, we systematically analyze the computation cost of Convolutional Neural Network(CNN) and found that the inefficiency of CNN is mainly caused by its wide structure rather than the deep structure. In addition, the success of pruning based model compression methods proved that there are many redundant channels in CNN. Thus, we designed a very narrow while deep backbone network to improve the efficiency of semantic segmentation. By casting our network to FCN32 segmentation architecture, the basic structure of most segmentation methods, we achieved 60.6\% mIoU on Cityscape val dataset with 54 frame per seconds(FPS) on $1024\times2048$ inputs, which already outperforms one of the earliest real time deep learning based segmentation methods: ENet.
Time-Aware and Corpus-Specific Entity Relatedness
Oct 23, 2018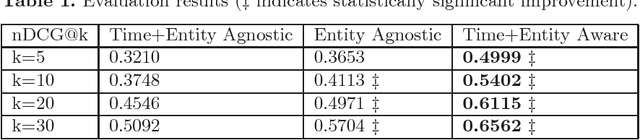
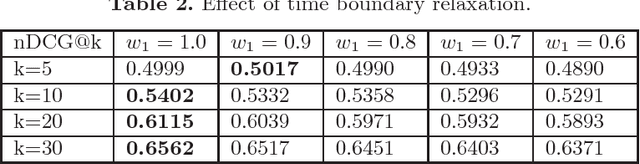
Entity relatedness has emerged as an important feature in a plethora of applications such as information retrieval, entity recommendation and entity linking. Given an entity, for instance a person or an organization, entity relatedness measures can be exploited for generating a list of highly-related entities. However, the relation of an entity to some other entity depends on several factors, with time and context being two of the most important ones (where, in our case, context is determined by a particular corpus). For example, the entities related to the International Monetary Fund are different now compared to some years ago, while these entities also may highly differ in the context of a USA news portal compared to a Greek news portal. In this paper, we propose a simple but flexible model for entity relatedness which considers time and entity aware word embeddings by exploiting the underlying corpus. The proposed model does not require external knowledge and is language independent, which makes it widely useful in a variety of applications.
Predicting Risk-adjusted Returns using an Asset Independent Regime-switching Model
Jul 07, 2021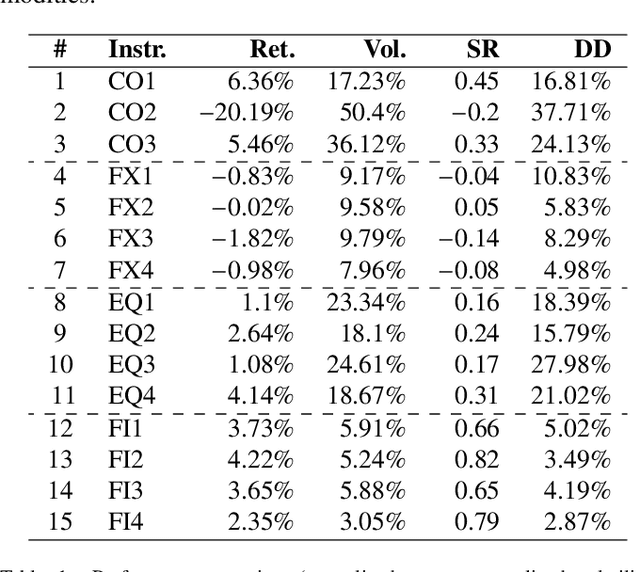
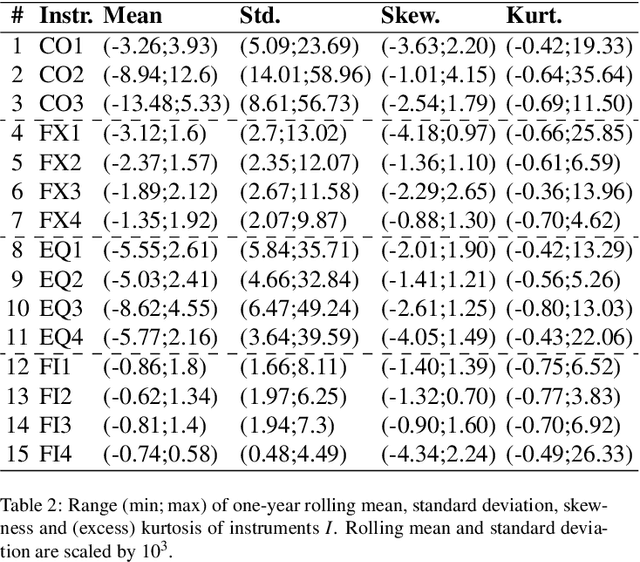
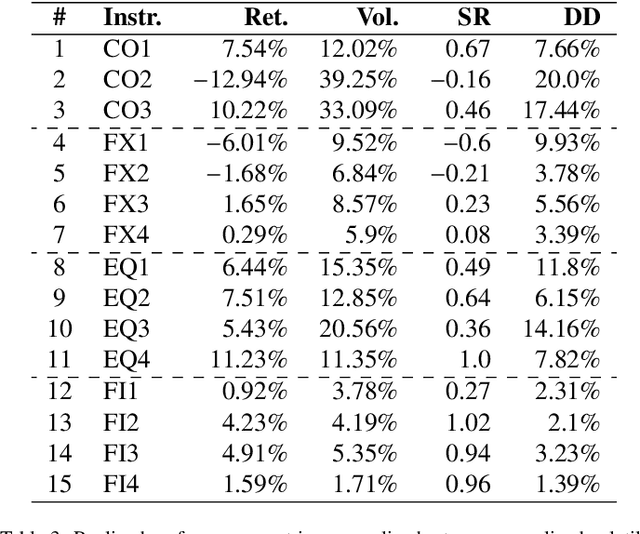
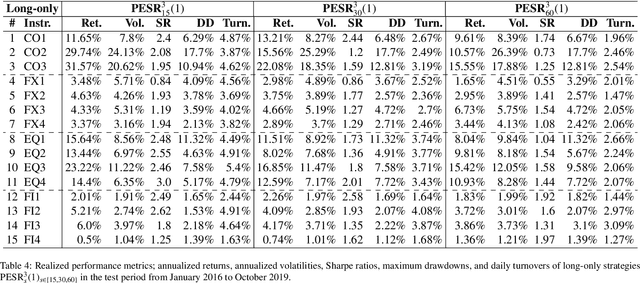
Financial markets tend to switch between various market regimes over time, making stationarity-based models unsustainable. We construct a regime-switching model independent of asset classes for risk-adjusted return predictions based on hidden Markov models. This framework can distinguish between market regimes in a wide range of financial markets such as the commodity, currency, stock, and fixed income market. The proposed method employs sticky features that directly affect the regime stickiness and thereby changing turnover levels. An investigation of our metric for risk-adjusted return predictions is conducted by analyzing daily financial market changes for almost twenty years. Empirical demonstrations of out-of-sample observations obtain an accurate detection of bull, bear, and high volatility periods, improving risk-adjusted returns while keeping a preferable turnover level.
Cross-Referencing Self-Training Network for Sound Event Detection in Audio Mixtures
May 27, 2021
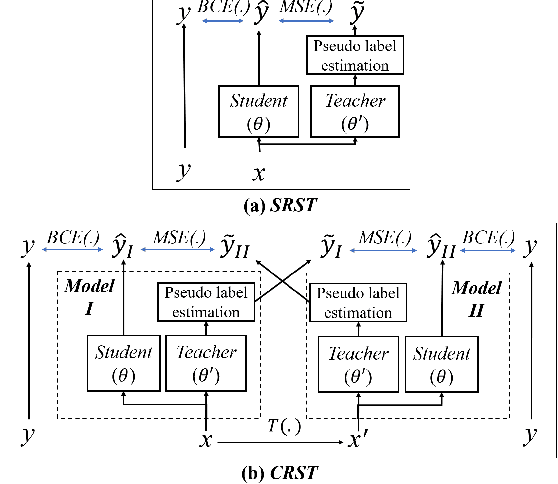
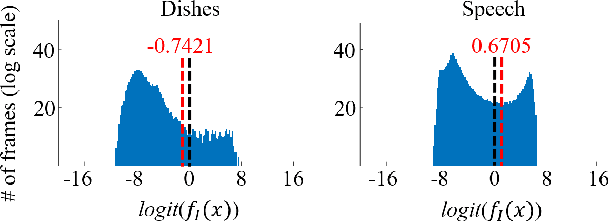
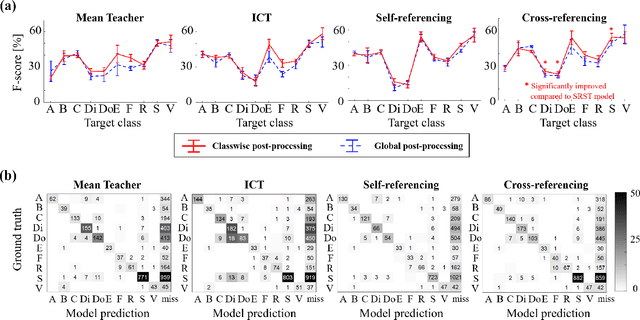
Sound event detection is an important facet of audio tagging that aims to identify sounds of interest and define both the sound category and time boundaries for each sound event in a continuous recording. With advances in deep neural networks, there has been tremendous improvement in the performance of sound event detection systems, although at the expense of costly data collection and labeling efforts. In fact, current state-of-the-art methods employ supervised training methods that leverage large amounts of data samples and corresponding labels in order to facilitate identification of sound category and time stamps of events. As an alternative, the current study proposes a semi-supervised method for generating pseudo-labels from unsupervised data using a student-teacher scheme that balances self-training and cross-training. Additionally, this paper explores post-processing which extracts sound intervals from network prediction, for further improvement in sound event detection performance. The proposed approach is evaluated on sound event detection task for the DCASE2020 challenge. The results of these methods on both "validation" and "public evaluation" sets of DESED database show significant improvement compared to the state-of-the art systems in semi-supervised learning.
Conditional Neural Relational Inference for Interacting Systems
Jul 02, 2021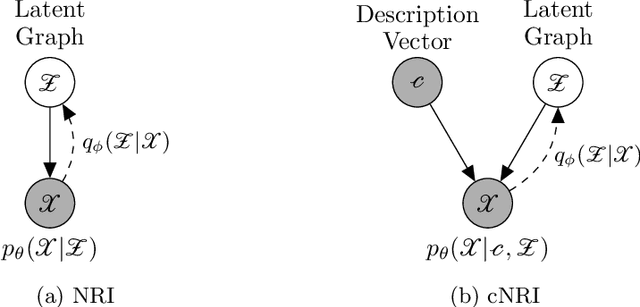
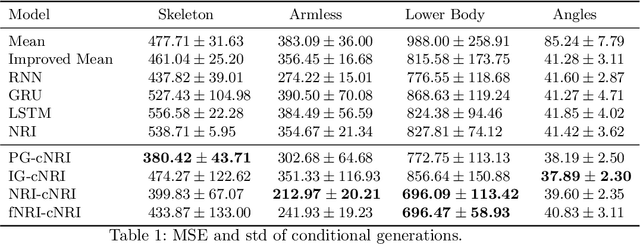
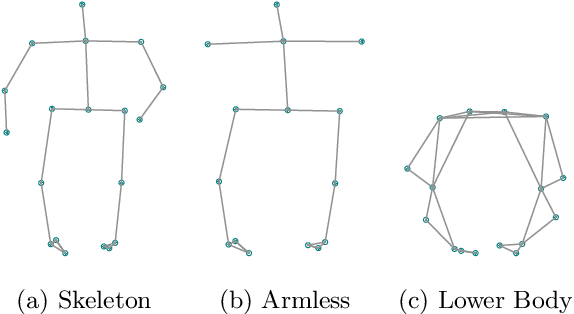
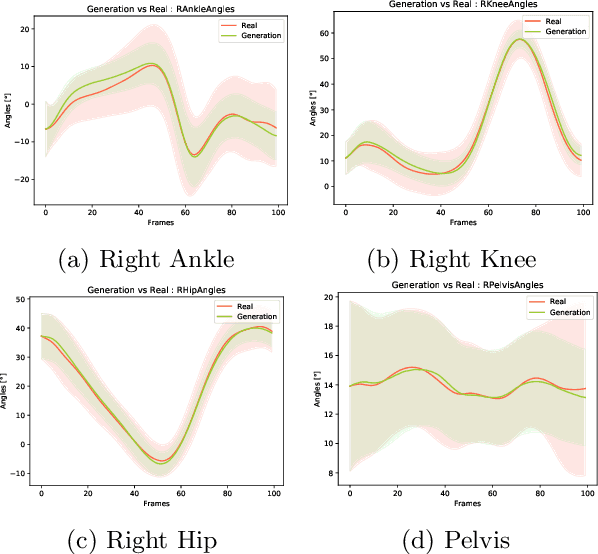
In this work, we want to learn to model the dynamics of similar yet distinct groups of interacting objects. These groups follow some common physical laws that exhibit specificities that are captured through some vectorial description. We develop a model that allows us to do conditional generation from any such group given its vectorial description. Unlike previous work on learning dynamical systems that can only do trajectory completion and require a part of the trajectory dynamics to be provided as input in generation time, we do generation using only the conditioning vector with no access to generation time's trajectories. We evaluate our model in the setting of modeling human gait and, in particular pathological human gait.
On Single and Multiple Representations in Dense Passage Retrieval
Aug 19, 2021
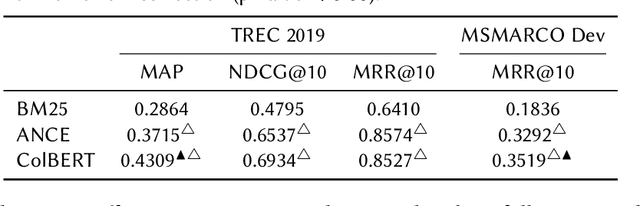
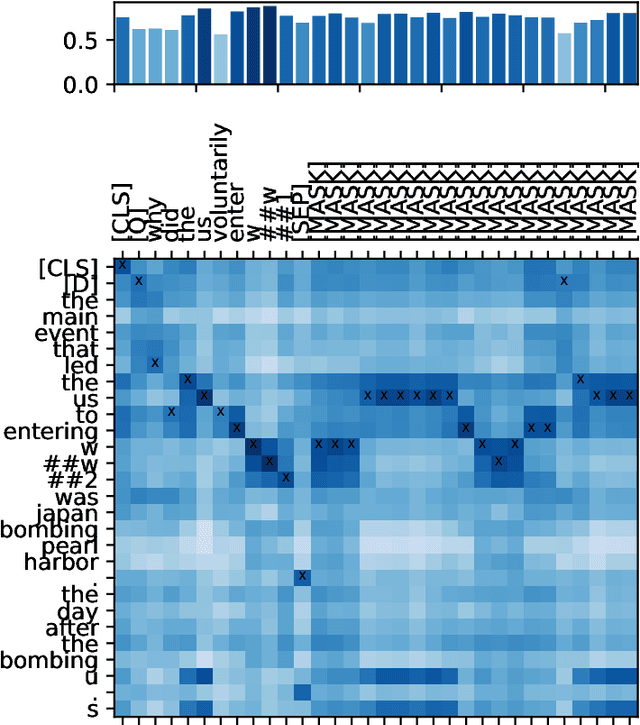
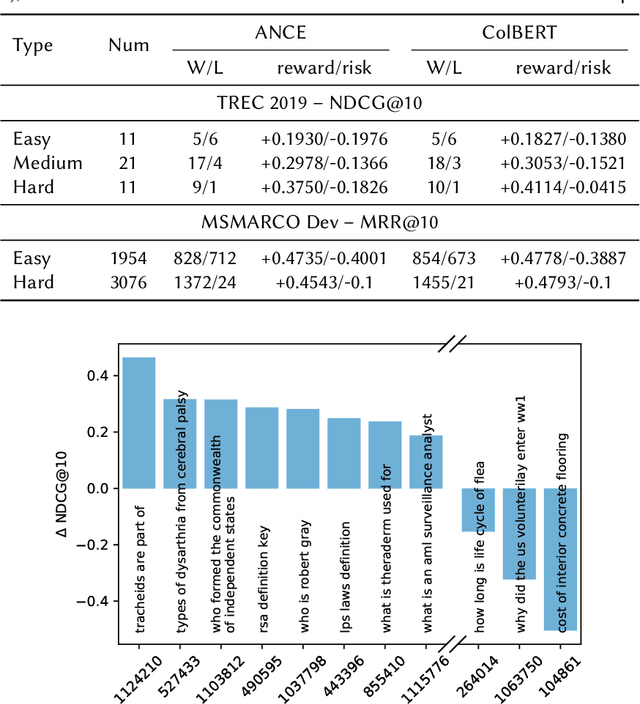
The advent of contextualised language models has brought gains in search effectiveness, not just when applied for re-ranking the output of classical weighting models such as BM25, but also when used directly for passage indexing and retrieval, a technique which is called dense retrieval. In the existing literature in neural ranking, two dense retrieval families have become apparent: single representation, where entire passages are represented by a single embedding (usually BERT's [CLS] token, as exemplified by the recent ANCE approach), or multiple representations, where each token in a passage is represented by its own embedding (as exemplified by the recent ColBERT approach). These two families have not been directly compared. However, because of the likely importance of dense retrieval moving forward, a clear understanding of their advantages and disadvantages is paramount. To this end, this paper contributes a direct study on their comparative effectiveness, noting situations where each method under/over performs w.r.t. each other, and w.r.t. a BM25 baseline. We observe that, while ANCE is more efficient than ColBERT in terms of response time and memory usage, multiple representations are statistically more effective than the single representations for MAP and MRR@10. We also show that multiple representations obtain better improvements than single representations for queries that are the hardest for BM25, as well as for definitional queries, and those with complex information needs.
A Non-sequential Approach to Deep User Interest Model for Click-Through Rate Prediction
Apr 05, 2021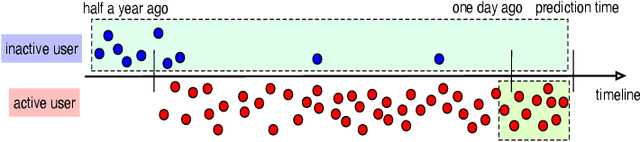
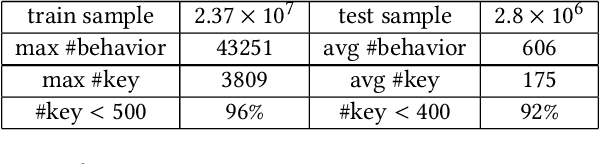
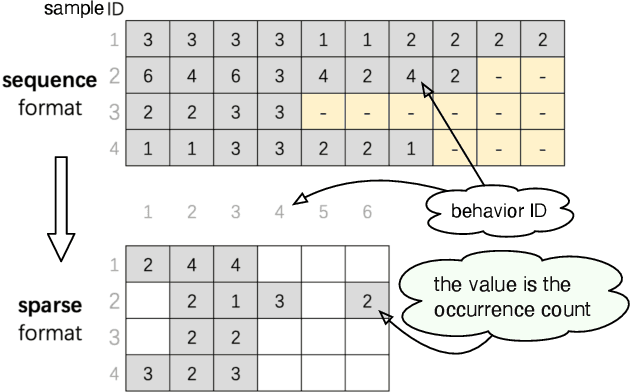

Click-Through Rate (CTR) prediction plays an important role in many industrial applications, and recently a lot of attention is paid to the deep interest models which use attention mechanism to capture user interests from historical behaviors. However, most current models are based on sequential models which truncate the behavior sequences by a fixed length, thus have difficulties in handling very long behavior sequences. Another big problem is that sequences with the same length can be quite different in terms of time, carrying completely different meanings. In this paper, we propose a non-sequential approach to tackle the above problems. Specifically, we first represent the behavior data in a sparse key-vector format, where the vector contains rich behavior info such as time, count and category. Next, we enhance the Deep Interest Network to take such rich information into account by a novel attention network. The sparse representation makes it practical to handle large scale long behavior sequences. Finally, we introduce a multidimensional partition framework to mine behavior interactions. The framework can partition data into custom designed time buckets to capture the interactions among information aggregated in different time buckets. Similarly, it can also partition the data into different categories and capture the interactions among them. Experiments are conducted on two public datasets: one is an advertising dataset and the other is a production recommender dataset. Our models outperform other state-of-the-art models on both datasets.
Arduino Controlled Spy Robo Car using Wireless Camera With live Streaming
Aug 07, 2021
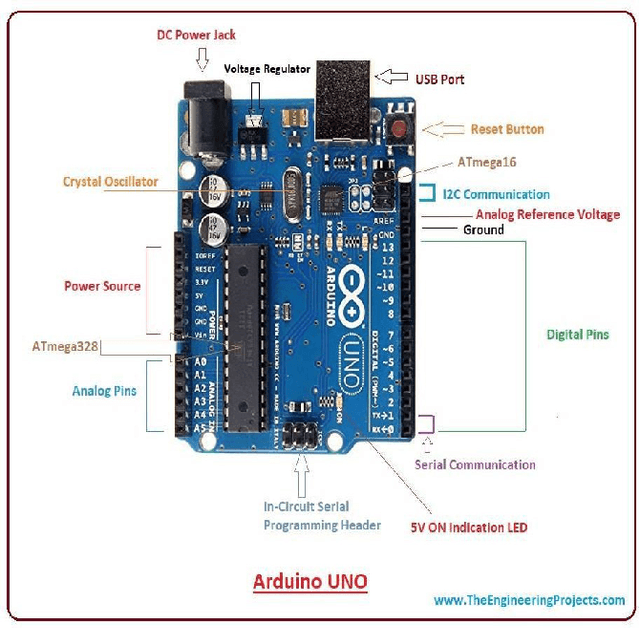
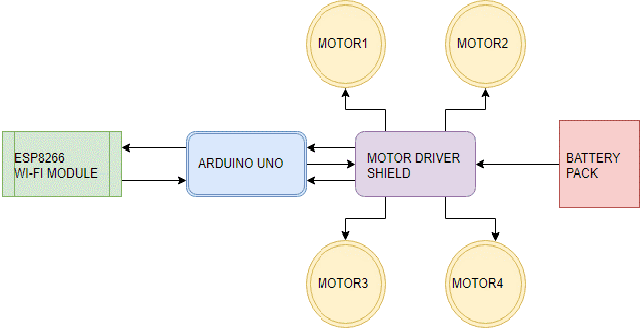
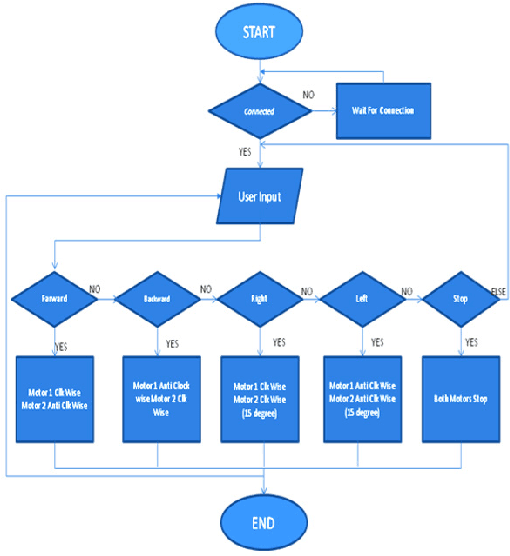
Nowadays, the technological and digital world is developing very fast. Everything is getting smart, so we are talking about the technological world the devices like home appliances and other things are getting control by mobile applications, and this only happens by the device Arduino Uno / raspberry pi3 and many others. Still, in our research we have used Arduino Uno to create a Wi-Fi controlled car with camera-top on it to monitor everything in its surrounding, we have seen many similar projects which using Arduino to makes things easy to use and its saving time and energy too. Automation is used for operating an electronic device such as the remote control car, home lighting system, and other useful things or reduced human invention. This report proposes a design and implementation of a remote-controlled camera car by Wi-Fi technology mobile devices. In this analysis work, radio code and hardware technologies area unit used, like the wireless module of ESP8266 for (transmitter and receiver), Arduino Uno as microcontroller, associate H-bridge L293D IC for motor controller and 2 electrical DC motors are used to move the car, & a Camera attached on the top of the vehicle.