 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Edge Intelligence in Softwarized 6G: Deep Learning-enabled Network Traffic Predictions
Jul 31, 2021
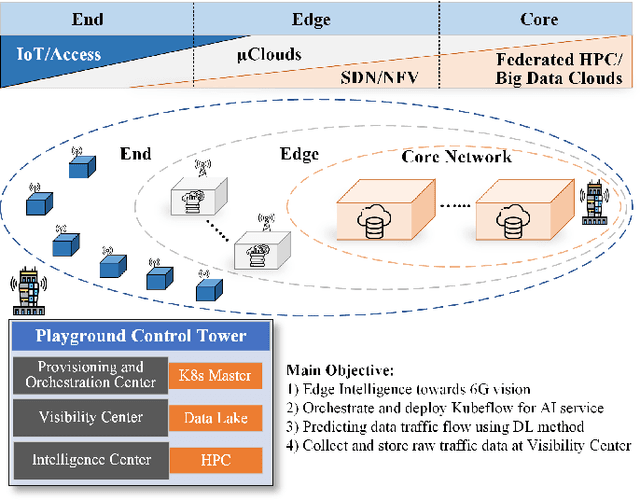
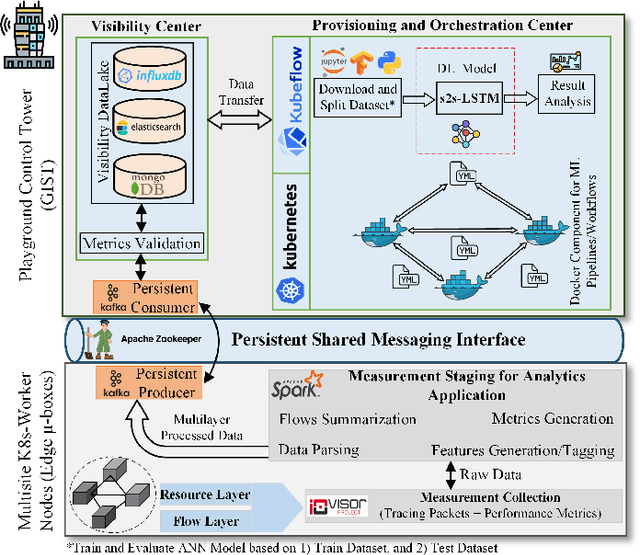
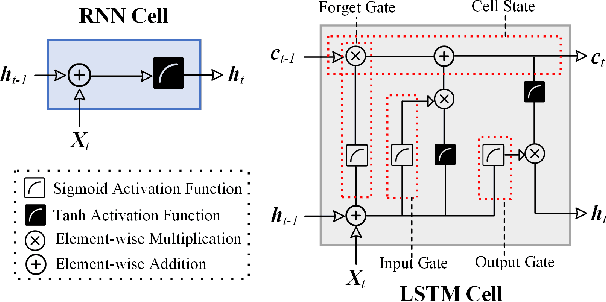
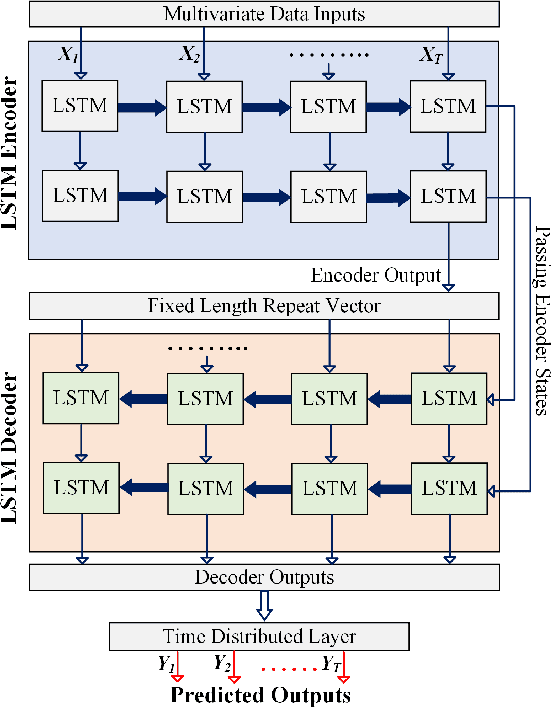
The 6G vision is envisaged to enable agile network expansion and rapid deployment of new on-demand microservices (i.e., visibility services for data traffic management, mobile edge computing services) closer to the network's edge IoT devices. However, providing one of the critical features of network visibility services, i.e., data flow prediction in the network, is challenging at the edge devices within a dynamic cloud-native environment as the traffic flow characteristics are random and sporadic. To provide the AI-native services for the 6G vision, we propose a novel edge-native framework to provide an intelligent prognosis technique for data traffic management in this paper. The prognosis model uses long short-term memory (LSTM)-based encoder-decoder deep learning, which we train on real time-series multivariate data records collected from the edge $\mu$-boxes of a selected testbed network. Our result accurately predicts the statistical characteristics of data traffic and verify against the ground truth observations. Moreover, we validate our novel framework model with two performance metrics for each feature of the multivariate data.
A Sensor Fusion-based GNSS Spoofing Attack Detection Framework for Autonomous Vehicles
Aug 19, 2021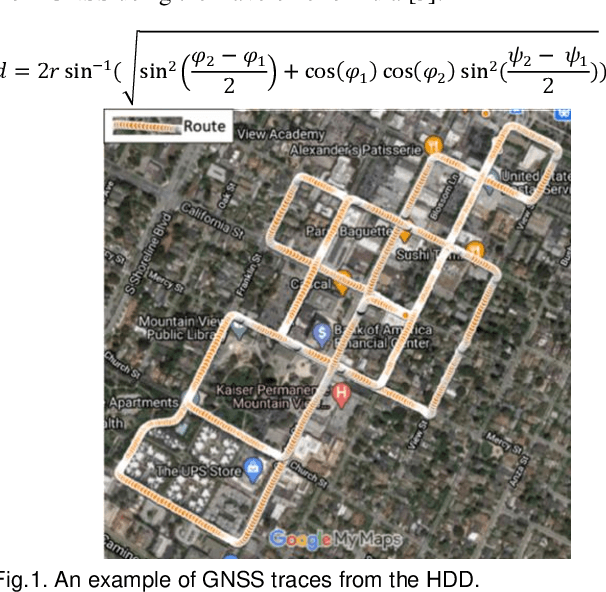



This paper presents a sensor fusion based Global Navigation Satellite System (GNSS) spoofing attack detection framework for autonomous vehicles (AV) that consists of two concurrent strategies: (i) detection of vehicle state using predicted location shift -- i.e., distance traveled between two consecutive timestamps -- and monitoring of vehicle motion state -- i.e., standstill/ in motion; and (ii) detection and classification of turns (i.e., left or right). Data from multiple low-cost in-vehicle sensors (i.e., accelerometer, steering angle sensor, speed sensor, and GNSS) are fused and fed into a recurrent neural network model, which is a long short-term memory (LSTM) network for predicting the location shift, i.e., the distance that an AV travels between two consecutive timestamps. This location shift is then compared with the GNSS-based location shift to detect an attack. We have then combined k-Nearest Neighbors (k-NN) and Dynamic Time Warping (DTW) algorithms to detect and classify left and right turns using data from the steering angle sensor. To prove the efficacy of the sensor fusion-based attack detection framework, attack datasets are created for four unique and sophisticated spoofing attacks-turn-by-turn, overshoot, wrong turn, and stop, using the publicly available real-world Honda Research Institute Driving Dataset (HDD). Our analysis reveals that the sensor fusion-based detection framework successfully detects all four types of spoofing attacks within the required computational latency threshold.
A Unified Model for Zero-shot Music Source Separation, Transcription and Synthesis
Aug 07, 2021

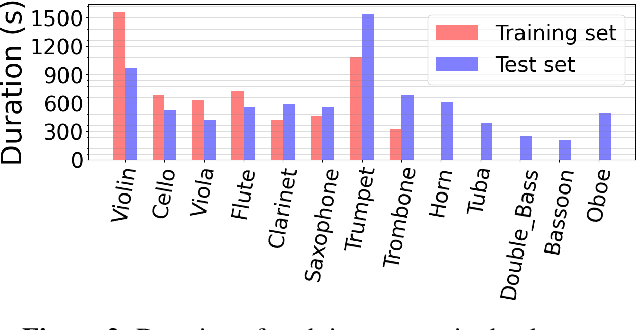
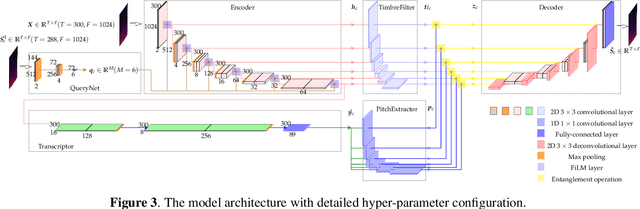
We propose a unified model for three inter-related tasks: 1) to \textit{separate} individual sound sources from a mixed music audio, 2) to \textit{transcribe} each sound source to MIDI notes, and 3) to\textit{ synthesize} new pieces based on the timbre of separated sources. The model is inspired by the fact that when humans listen to music, our minds can not only separate the sounds of different instruments, but also at the same time perceive high-level representations such as score and timbre. To mirror such capability computationally, we designed a pitch-timbre disentanglement module based on a popular encoder-decoder neural architecture for source separation. The key inductive biases are vector-quantization for pitch representation and pitch-transformation invariant for timbre representation. In addition, we adopted a query-by-example method to achieve \textit{zero-shot} learning, i.e., the model is capable of doing source separation, transcription, and synthesis for \textit{unseen} instruments. The current design focuses on audio mixtures of two monophonic instruments. Experimental results show that our model outperforms existing multi-task baselines, and the transcribed score serves as a powerful auxiliary for separation tasks.
MERLOT: Multimodal Neural Script Knowledge Models
Jun 10, 2021
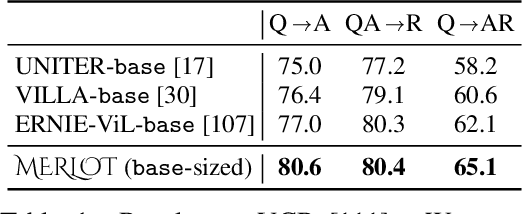
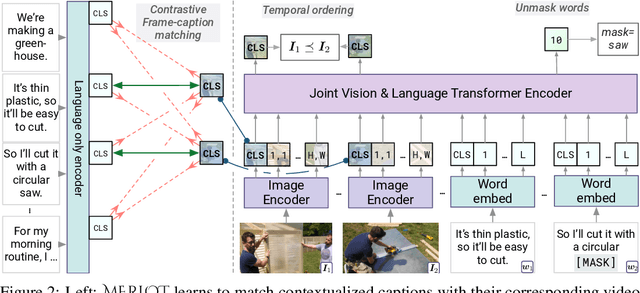
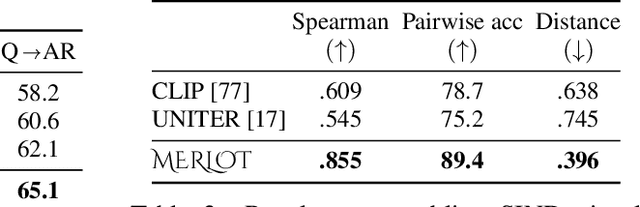
As humans, we understand events in the visual world contextually, performing multimodal reasoning across time to make inferences about the past, present, and future. We introduce MERLOT, a model that learns multimodal script knowledge by watching millions of YouTube videos with transcribed speech -- in an entirely label-free, self-supervised manner. By pretraining with a mix of both frame-level (spatial) and video-level (temporal) objectives, our model not only learns to match images to temporally corresponding words, but also to contextualize what is happening globally over time. As a result, MERLOT exhibits strong out-of-the-box representations of temporal commonsense, and achieves state-of-the-art performance on 12 different video QA datasets when finetuned. It also transfers well to the world of static images, allowing models to reason about the dynamic context behind visual scenes. On Visual Commonsense Reasoning, MERLOT answers questions correctly with 80.6% accuracy, outperforming state-of-the-art models of similar size by over 3%, even those that make heavy use of auxiliary supervised data (like object bounding boxes). Ablation analyses demonstrate the complementary importance of: 1) training on videos versus static images; 2) scaling the magnitude and diversity of the pretraining video corpus; and 3) using diverse objectives that encourage full-stack multimodal reasoning, from the recognition to cognition level.
Model-based micro-data reinforcement learning: what are the crucial model properties and which model to choose?
Jul 24, 2021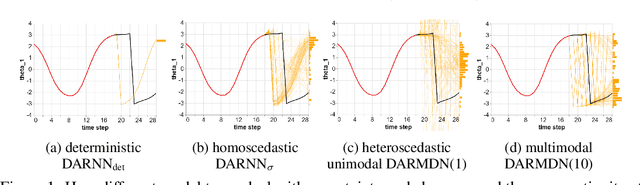
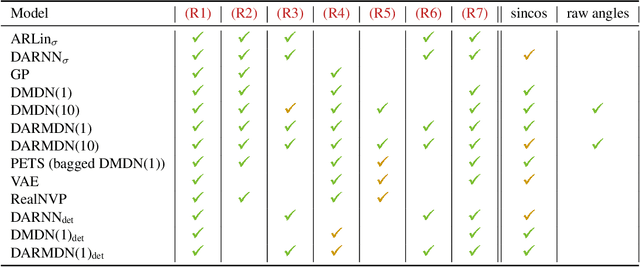

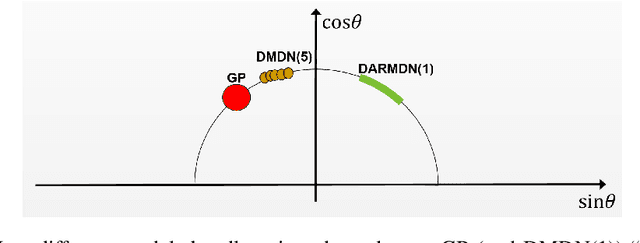
We contribute to micro-data model-based reinforcement learning (MBRL) by rigorously comparing popular generative models using a fixed (random shooting) control agent. We find that on an environment that requires multimodal posterior predictives, mixture density nets outperform all other models by a large margin. When multimodality is not required, our surprising finding is that we do not need probabilistic posterior predictives: deterministic models are on par, in fact they consistently (although non-significantly) outperform their probabilistic counterparts. We also found that heteroscedasticity at training time, perhaps acting as a regularizer, improves predictions at longer horizons. At the methodological side, we design metrics and an experimental protocol which can be used to evaluate the various models, predicting their asymptotic performance when using them on the control problem. Using this framework, we improve the state-of-the-art sample complexity of MBRL on Acrobot by two to four folds, using an aggressive training schedule which is outside of the hyperparameter interval usually considered
Deep Self-Organization: Interpretable Discrete Representation Learning on Time Series
Oct 05, 2018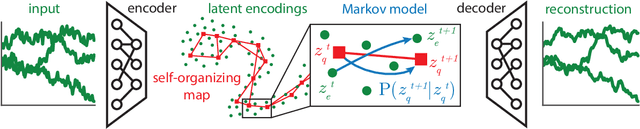
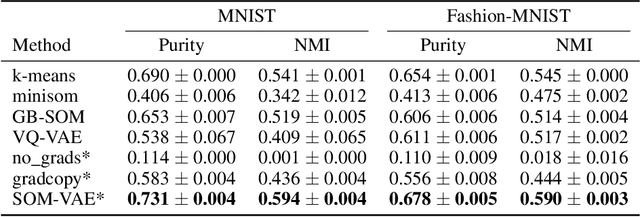

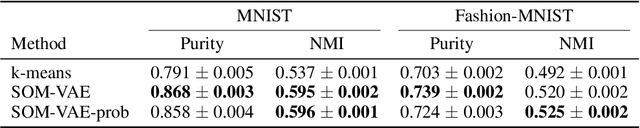
High-dimensional time series are common in many domains. Since human cognition is not optimized to work well in high-dimensional spaces, these areas could benefit from interpretable low-dimensional representations. However, most representation learning algorithms for time series data are difficult to interpret. This is due to non-intuitive mappings from data features to salient properties of the representation and non-smoothness over time. To address this problem, we propose a new representation learning framework building on ideas from interpretable discrete dimensionality reduction and deep generative modeling. This framework allows us to learn discrete representations of time series, which give rise to smooth and interpretable embeddings with superior clustering performance. We introduce a new way to overcome the non-differentiability in discrete representation learning and present a gradient-based version of the traditional self-organizing map algorithm that is more performant than the original. Furthermore, to allow for a probabilistic interpretation of our method, we integrate a Markov model in the representation space. This model uncovers the temporal transition structure, improves clustering performance even further and provides additional explanatory insights as well as a natural representation of uncertainty. We evaluate our model in terms of clustering performance and interpretability on static (Fashion-)MNIST data, a time series of linearly interpolated (Fashion-)MNIST images, a chaotic Lorenz attractor system with two macro states, as well as on a challenging real world medical time series application on the eICU data set. Our learned representations compare favorably with competitor methods and facilitate downstream tasks on the real world data.
3D Shape Registration Using Spectral Graph Embedding and Probabilistic Matching
Jun 21, 2021

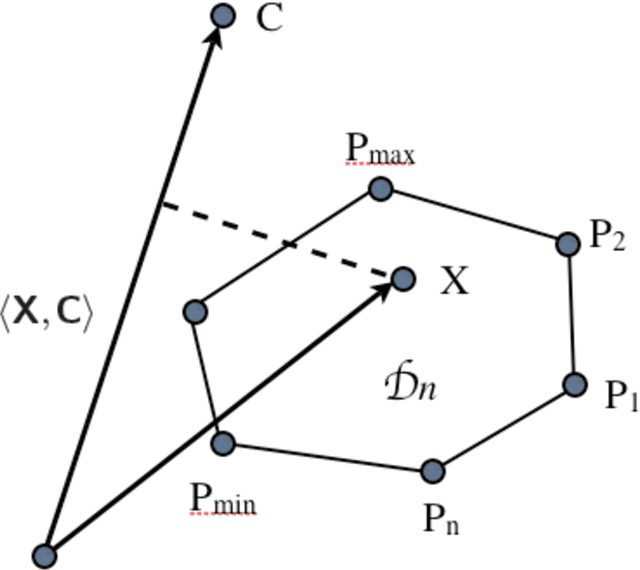
We address the problem of 3D shape registration and we propose a novel technique based on spectral graph theory and probabilistic matching. The task of 3D shape analysis involves tracking, recognition, registration, etc. Analyzing 3D data in a single framework is still a challenging task considering the large variability of the data gathered with different acquisition devices. 3D shape registration is one such challenging shape analysis task. The main contribution of this chapter is to extend the spectral graph matching methods to very large graphs by combining spectral graph matching with Laplacian embedding. Since the embedded representation of a graph is obtained by dimensionality reduction we claim that the existing spectral-based methods are not easily applicable. We discuss solutions for the exact and inexact graph isomorphism problems and recall the main spectral properties of the combinatorial graph Laplacian; We provide a novel analysis of the commute-time embedding that allows us to interpret the latter in terms of the PCA of a graph, and to select the appropriate dimension of the associated embedded metric space; We derive a unit hyper-sphere normalization for the commute-time embedding that allows us to register two shapes with different samplings; We propose a novel method to find the eigenvalue-eigenvector ordering and the eigenvector signs using the eigensignature (histogram) which is invariant to the isometric shape deformations and fits well in the spectral graph matching framework, and we present a probabilistic shape matching formulation using an expectation maximization point registration algorithm which alternates between aligning the eigenbases and finding a vertex-to-vertex assignment.
Predicting Risk-adjusted Returns using an Asset Independent Regime-switching Model
Jul 07, 2021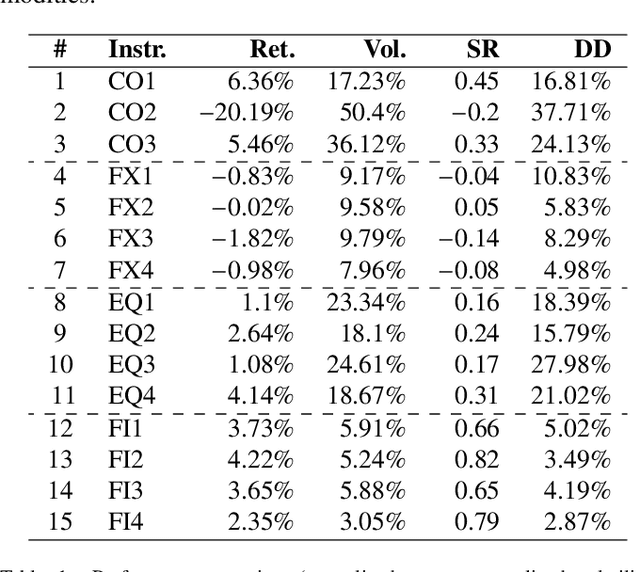
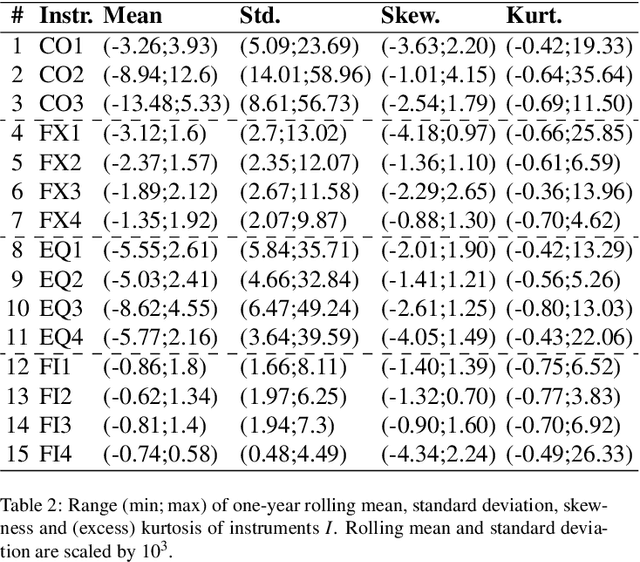
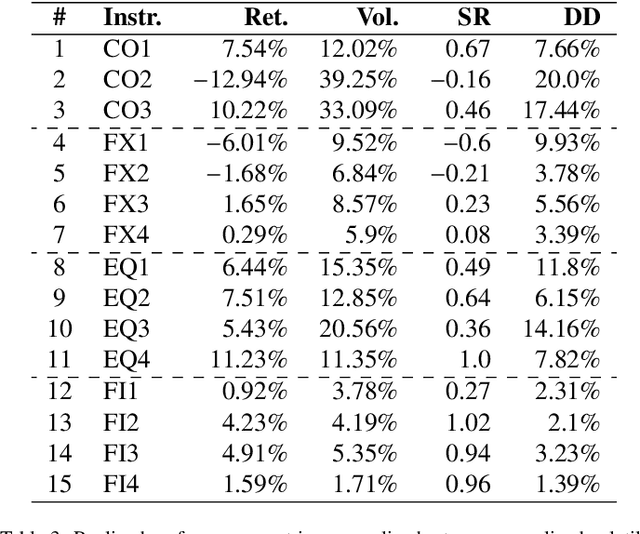
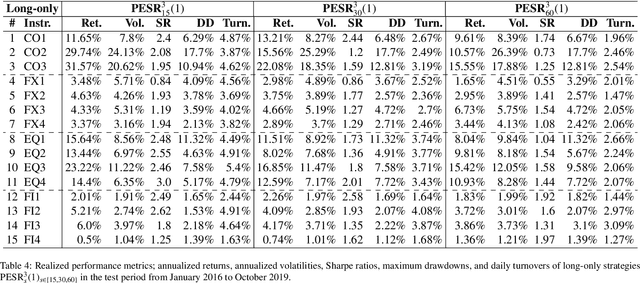
Financial markets tend to switch between various market regimes over time, making stationarity-based models unsustainable. We construct a regime-switching model independent of asset classes for risk-adjusted return predictions based on hidden Markov models. This framework can distinguish between market regimes in a wide range of financial markets such as the commodity, currency, stock, and fixed income market. The proposed method employs sticky features that directly affect the regime stickiness and thereby changing turnover levels. An investigation of our metric for risk-adjusted return predictions is conducted by analyzing daily financial market changes for almost twenty years. Empirical demonstrations of out-of-sample observations obtain an accurate detection of bull, bear, and high volatility periods, improving risk-adjusted returns while keeping a preferable turnover level.
On Single and Multiple Representations in Dense Passage Retrieval
Aug 19, 2021
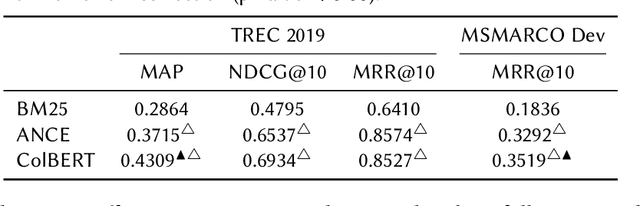
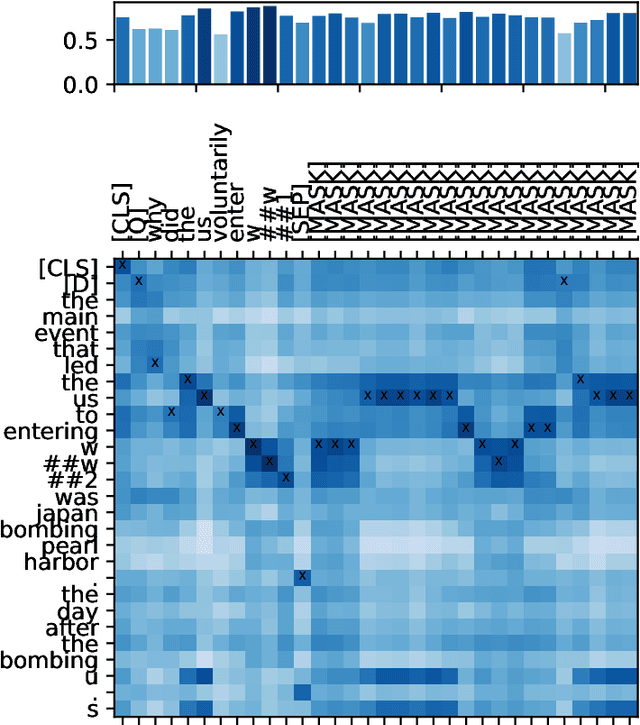
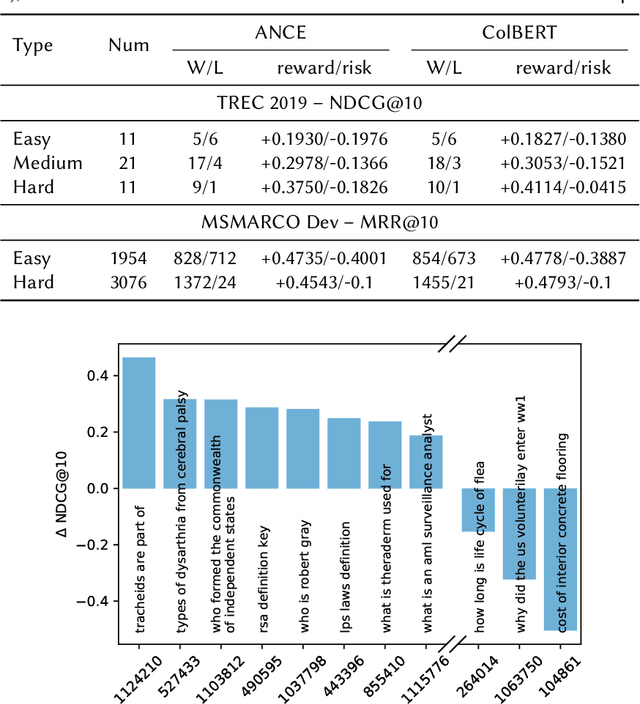
The advent of contextualised language models has brought gains in search effectiveness, not just when applied for re-ranking the output of classical weighting models such as BM25, but also when used directly for passage indexing and retrieval, a technique which is called dense retrieval. In the existing literature in neural ranking, two dense retrieval families have become apparent: single representation, where entire passages are represented by a single embedding (usually BERT's [CLS] token, as exemplified by the recent ANCE approach), or multiple representations, where each token in a passage is represented by its own embedding (as exemplified by the recent ColBERT approach). These two families have not been directly compared. However, because of the likely importance of dense retrieval moving forward, a clear understanding of their advantages and disadvantages is paramount. To this end, this paper contributes a direct study on their comparative effectiveness, noting situations where each method under/over performs w.r.t. each other, and w.r.t. a BM25 baseline. We observe that, while ANCE is more efficient than ColBERT in terms of response time and memory usage, multiple representations are statistically more effective than the single representations for MAP and MRR@10. We also show that multiple representations obtain better improvements than single representations for queries that are the hardest for BM25, as well as for definitional queries, and those with complex information needs.
Conditional Neural Relational Inference for Interacting Systems
Jul 02, 2021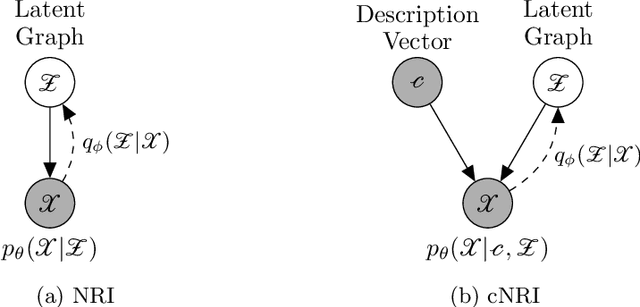
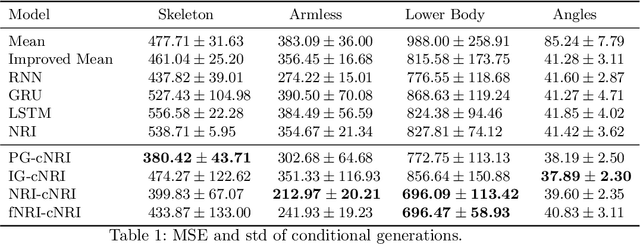
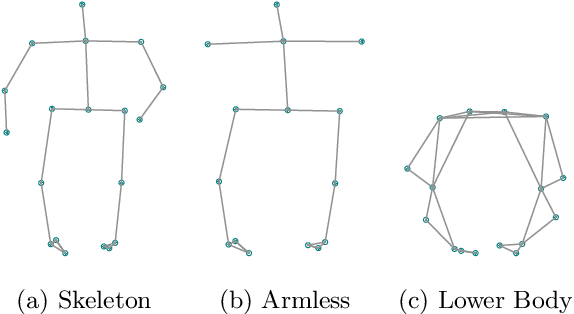
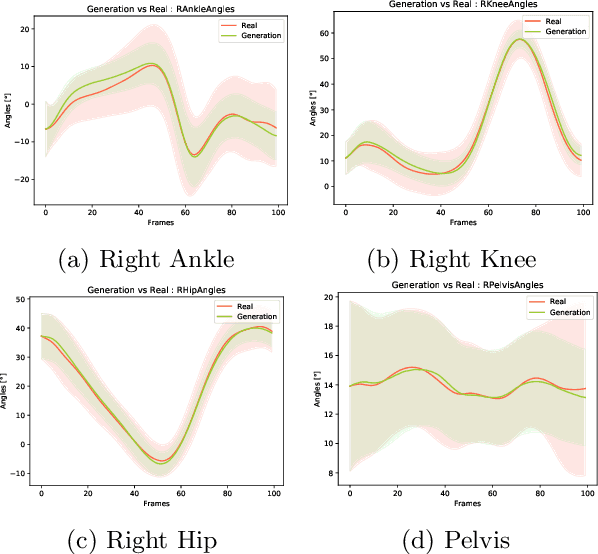
In this work, we want to learn to model the dynamics of similar yet distinct groups of interacting objects. These groups follow some common physical laws that exhibit specificities that are captured through some vectorial description. We develop a model that allows us to do conditional generation from any such group given its vectorial description. Unlike previous work on learning dynamical systems that can only do trajectory completion and require a part of the trajectory dynamics to be provided as input in generation time, we do generation using only the conditioning vector with no access to generation time's trajectories. We evaluate our model in the setting of modeling human gait and, in particular pathological human gait.