 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Using Query Expansion in Manifold Ranking for Query-Oriented Multi-Document Summarization
Jul 31, 2021
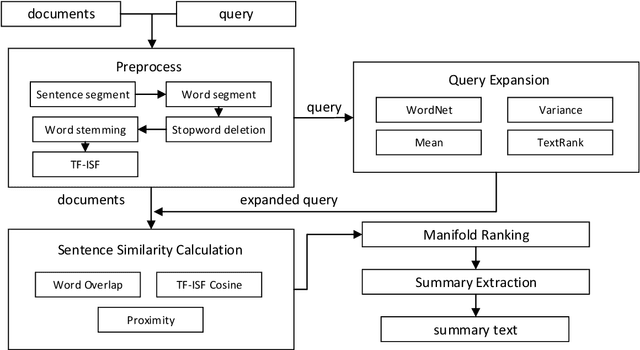
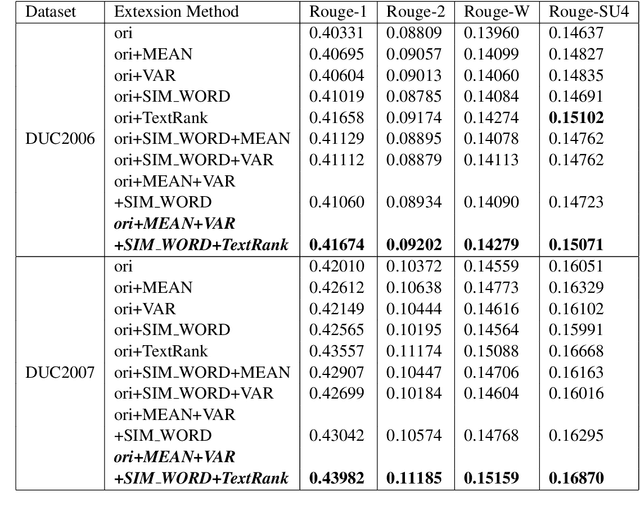
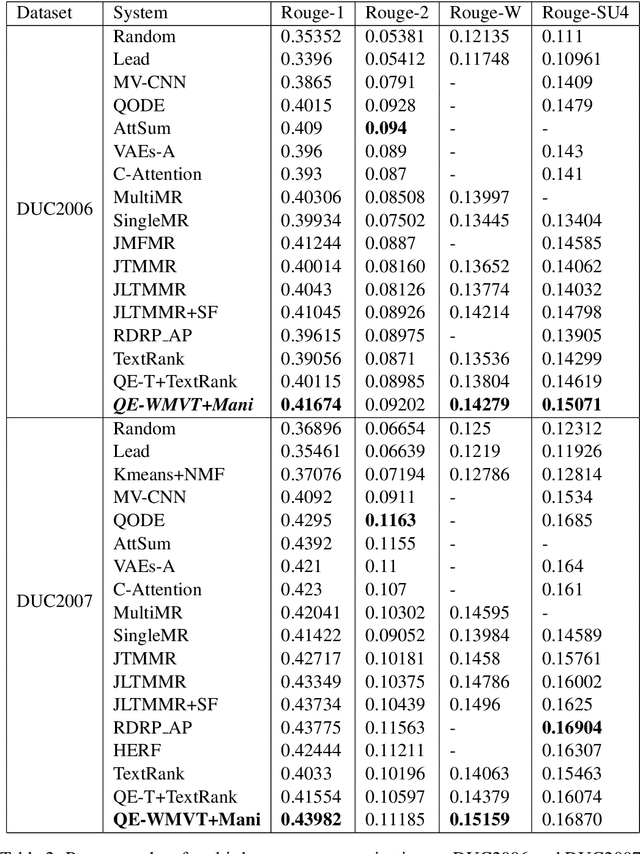
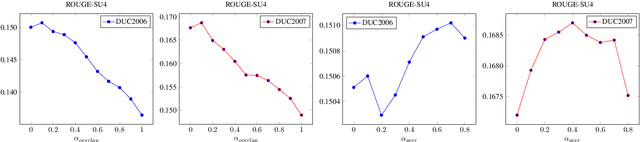
Manifold ranking has been successfully applied in query-oriented multi-document summarization. It not only makes use of the relationships among the sentences, but also the relationships between the given query and the sentences. However, the information of original query is often insufficient. So we present a query expansion method, which is combined in the manifold ranking to resolve this problem. Our method not only utilizes the information of the query term itself and the knowledge base WordNet to expand it by synonyms, but also uses the information of the document set itself to expand the query in various ways (mean expansion, variance expansion and TextRank expansion). Compared with the previous query expansion methods, our method combines multiple query expansion methods to better represent query information, and at the same time, it makes a useful attempt on manifold ranking. In addition, we use the degree of word overlap and the proximity between words to calculate the similarity between sentences. We performed experiments on the datasets of DUC 2006 and DUC2007, and the evaluation results show that the proposed query expansion method can significantly improve the system performance and make our system comparable to the state-of-the-art systems.
Proximity Forest: An effective and scalable distance-based classifier for time series
Aug 31, 2018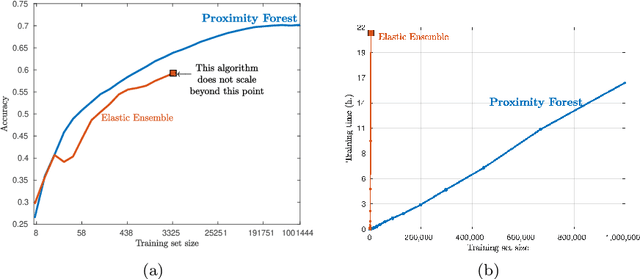
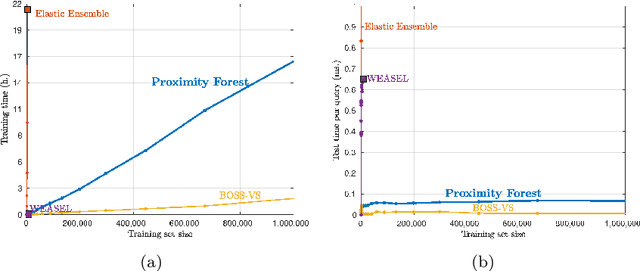
Research into the classification of time series has made enormous progress in the last decade. The UCR time series archive has played a significant role in challenging and guiding the development of new learners for time series classification. The largest dataset in the UCR archive holds 10 thousand time series only; which may explain why the primary research focus has been in creating algorithms that have high accuracy on relatively small datasets. This paper introduces Proximity Forest, an algorithm that learns accurate models from datasets with millions of time series, and classifies a time series in milliseconds. The models are ensembles of highly randomized Proximity Trees. Whereas conventional decision trees branch on attribute values (and usually perform poorly on time series), Proximity Trees branch on the proximity of time series to one exemplar time series or another; allowing us to leverage the decades of work into developing relevant measures for time series. Proximity Forest gains both efficiency and accuracy by stochastic selection of both exemplars and similarity measures. Our work is motivated by recent time series applications that provide orders of magnitude more time series than the UCR benchmarks. Our experiments demonstrate that Proximity Forest is highly competitive on the UCR archive: it ranks among the most accurate classifiers while being significantly faster. We demonstrate on a 1M time series Earth observation dataset that Proximity Forest retains this accuracy on datasets that are many orders of magnitude greater than those in the UCR repository, while learning its models at least 100,000 times faster than current state of the art models Elastic Ensemble and COTE.
When Liebig's Barrel Meets Facial Landmark Detection: A Practical Model
Jun 02, 2021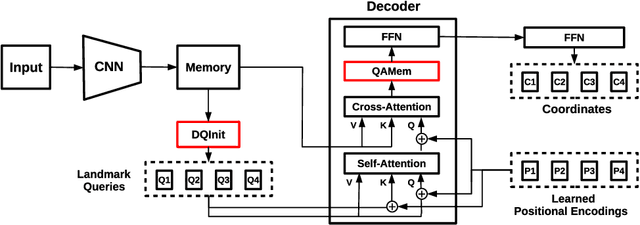
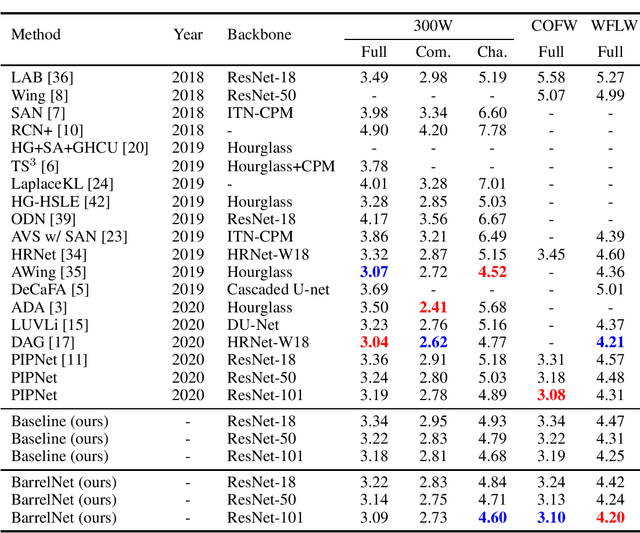
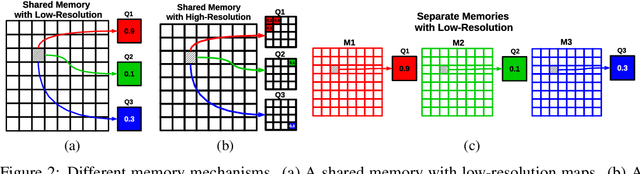
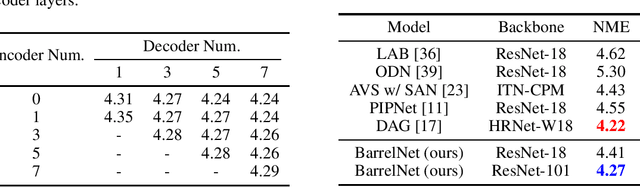
In recent years, significant progress has been made in the research of facial landmark detection. However, few prior works have thoroughly discussed about models for practical applications. Instead, they often focus on improving a couple of issues at a time while ignoring the others. To bridge this gap, we aim to explore a practical model that is accurate, robust, efficient, generalizable, and end-to-end trainable at the same time. To this end, we first propose a baseline model equipped with one transformer decoder as detection head. In order to achieve a better accuracy, we further propose two lightweight modules, namely dynamic query initialization (DQInit) and query-aware memory (QAMem). Specifically, DQInit dynamically initializes the queries of decoder from the inputs, enabling the model to achieve as good accuracy as the ones with multiple decoder layers. QAMem is designed to enhance the discriminative ability of queries on low-resolution feature maps by assigning separate memory values to each query rather than a shared one. With the help of QAMem, our model removes the dependence on high-resolution feature maps and is still able to obtain superior accuracy. Extensive experiments and analysis on three popular benchmarks show the effectiveness and practical advantages of the proposed model. Notably, our model achieves new state of the art on WFLW as well as competitive results on 300W and COFW, while still running at 50+ FPS.
Deep Learning-based Biological Anatomical Landmark Detection in Colonoscopy Videos
Aug 06, 2021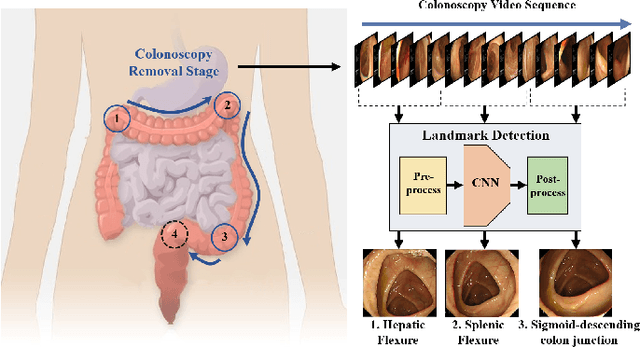
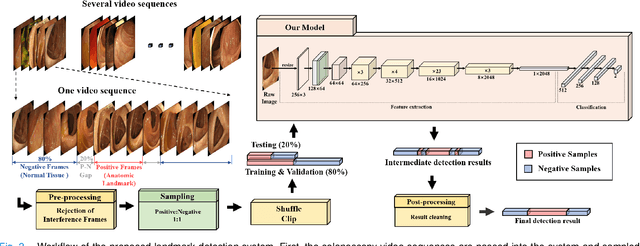
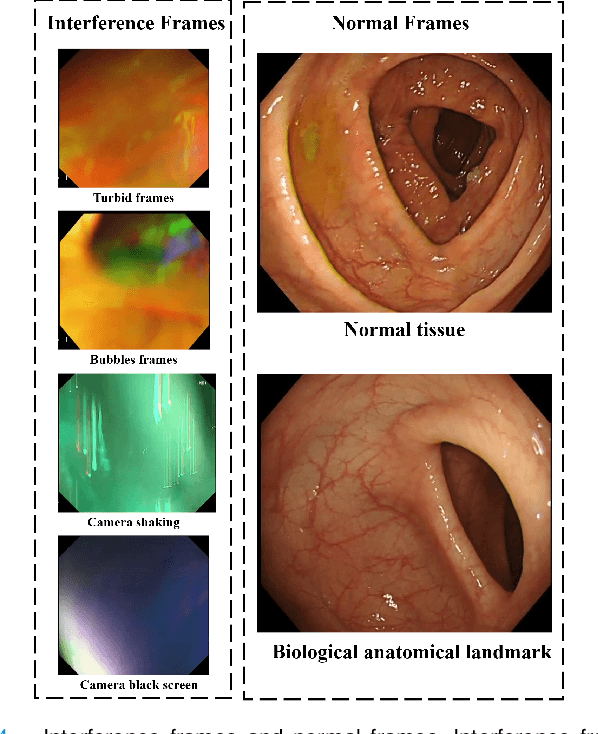
Colonoscopy is a standard imaging tool for visualizing the entire gastrointestinal (GI) tract of patients to capture lesion areas. However, it takes the clinicians excessive time to review a large number of images extracted from colonoscopy videos. Thus, automatic detection of biological anatomical landmarks within the colon is highly demanded, which can help reduce the burden of clinicians by providing guidance information for the locations of lesion areas. In this article, we propose a novel deep learning-based approach to detect biological anatomical landmarks in colonoscopy videos. First, raw colonoscopy video sequences are pre-processed to reject interference frames. Second, a ResNet-101 based network is used to detect three biological anatomical landmarks separately to obtain the intermediate detection results. Third, to achieve more reliable localization of the landmark periods within the whole video period, we propose to post-process the intermediate detection results by identifying the incorrectly predicted frames based on their temporal distribution and reassigning them back to the correct class. Finally, the average detection accuracy reaches 99.75\%. Meanwhile, the average IoU of 0.91 shows a high degree of similarity between our predicted landmark periods and ground truth. The experimental results demonstrate that our proposed model is capable of accurately detecting and localizing biological anatomical landmarks from colonoscopy videos.
Decision-making Oriented Clustering: Application to Pricing and Power Consumption Scheduling
Jun 02, 2021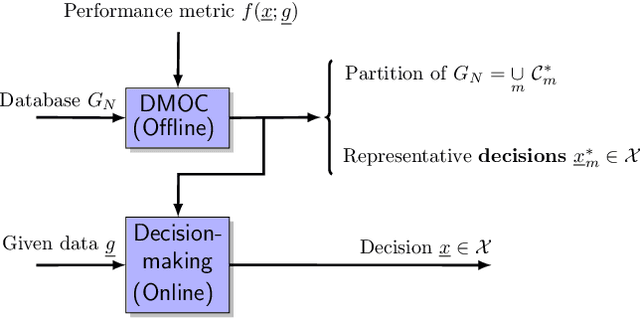
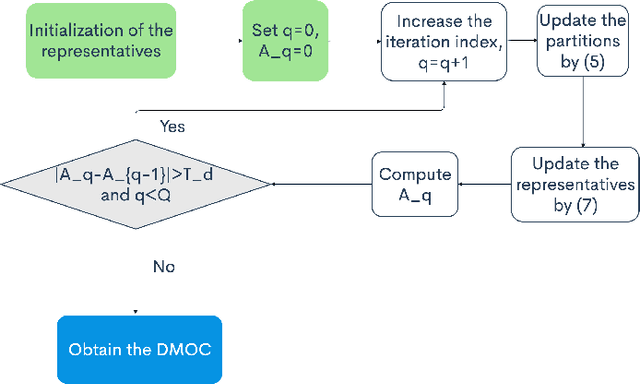
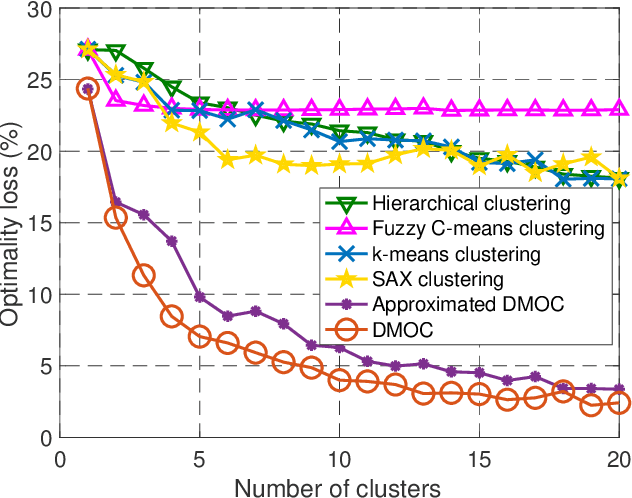
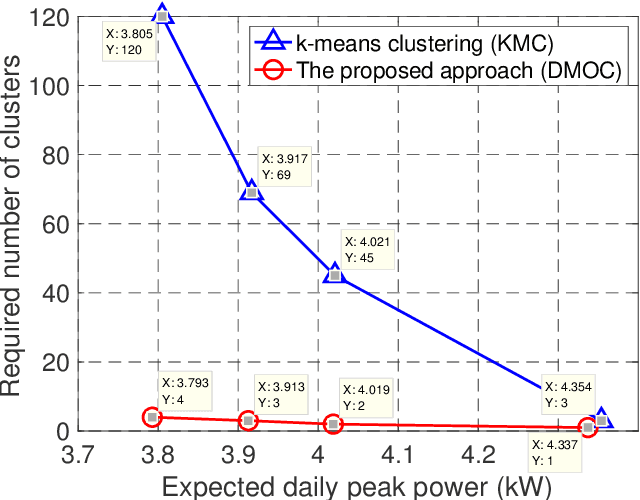
Data clustering is an instrumental tool in the area of energy resource management. One problem with conventional clustering is that it does not take the final use of the clustered data into account, which may lead to a very suboptimal use of energy or computational resources. When clustered data are used by a decision-making entity, it turns out that significant gains can be obtained by tailoring the clustering scheme to the final task performed by the decision-making entity. The key to having good final performance is to automatically extract the important attributes of the data space that are inherently relevant to the subsequent decision-making entity, and partition the data space based on these attributes instead of partitioning the data space based on predefined conventional metrics. For this purpose, we formulate the framework of decision-making oriented clustering and propose an algorithm providing a decision-based partition of the data space and good representative decisions. By applying this novel framework and algorithm to a typical problem of real-time pricing and that of power consumption scheduling, we obtain several insightful analytical results such as the expression of the best representative price profiles for real-time pricing and a very significant reduction in terms of required clusters to perform power consumption scheduling as shown by our simulations.
* Published in Applied Energy
A tale of two toolkits, report the first: benchmarking time series classification algorithms for correctness and efficiency
Sep 16, 2019
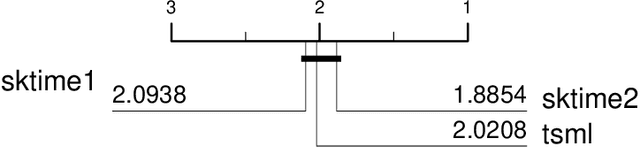
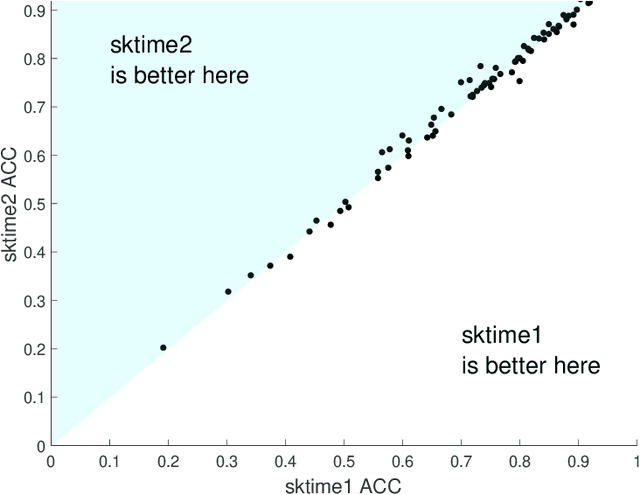
sktime is an open source, Python based, sklearn compatible toolkit for time series analysis developed by researchers at the University of East Anglia, University College London and the Alan Turing Institute. A key initial goal for sktime was to provide time series classification functionality equivalent to that available in a related java package, tsml. We describe the implementation of six such classifiers in sktime and compare them to their tsml equivalents. We demonstrate correctness through equivalence of accuracy on a range of standard test problems and compare the build time of the different implementations. We find that there is significant difference in accuracy on only one of the six algorithms, and this difference was to be expected. We found a much wider range of difference in efficiency. Again, this was not unexpected, but it does highlight ways both toolkits could be improved. PLEASE NOTE THIS PAPER IS NOT COMPLETE. It is a work in progress and we have pushed it early so that we can reference it in another paper. More to follow!
Forecaster: A Graph Transformer for Forecasting Spatial and Time-Dependent Data
Sep 12, 2019
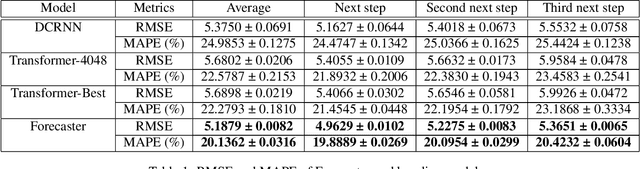
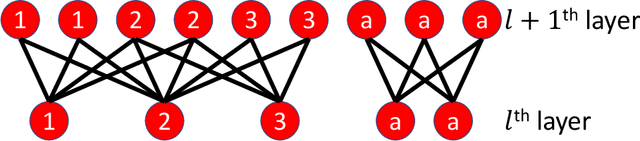
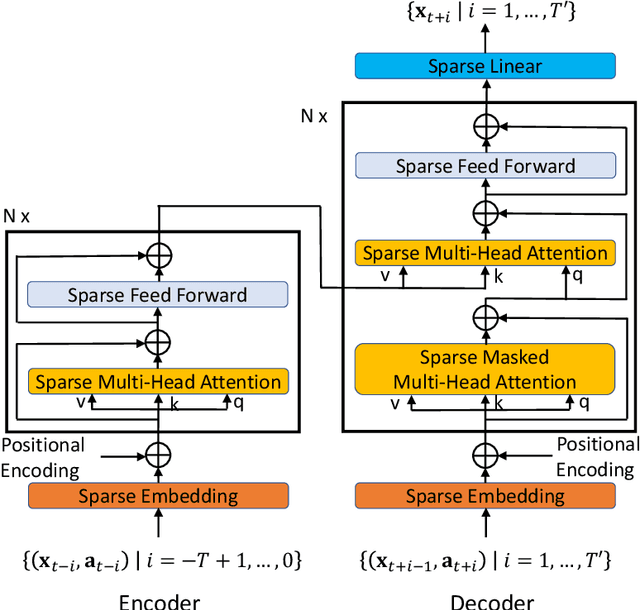
Spatial and time-dependent data is of interest in many applications. This task is difficult due to its complex spatial dependency, long-range temporal dependency, data non-stationarity, and data heterogeneity. To address these challenges, we propose Forecaster, a graph Transformer architecture. Specifically, we start by learning the structure of the graph that parsimoniously represents the spatial dependency between the data at different locations. Based on the topology of the graph, we sparsify the Transformer to account for the strength of spatial dependency, long-range temporal dependency, data non-stationarity, and data heterogeneity. We evaluate Forecaster in the problem of forecasting taxi ride-hailing demand and show that our proposed architecture significantly outperforms the state-of-the-art baselines.
The Law of Large Documents: Understanding the Structure of Legal Contracts Using Visual Cues
Jul 16, 2021
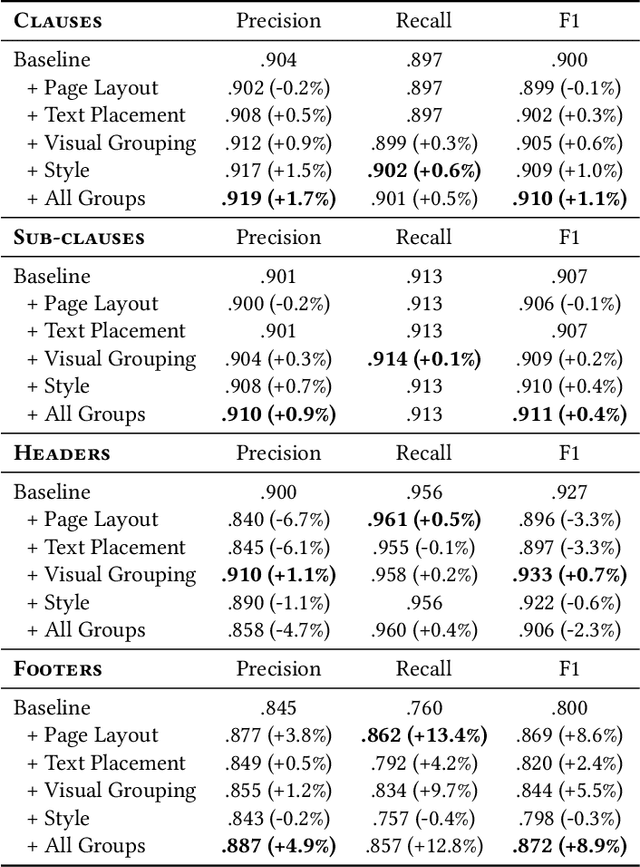
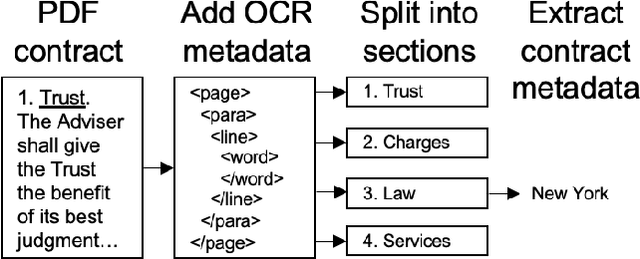
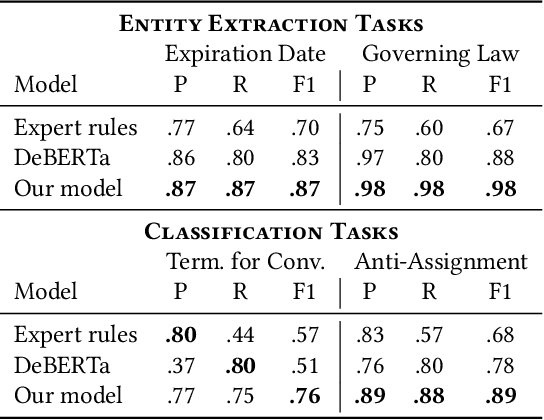
Large, pre-trained transformer models like BERT have achieved state-of-the-art results on document understanding tasks, but most implementations can only consider 512 tokens at a time. For many real-world applications, documents can be much longer, and the segmentation strategies typically used on longer documents miss out on document structure and contextual information, hurting their results on downstream tasks. In our work on legal agreements, we find that visual cues such as layout, style, and placement of text in a document are strong features that are crucial to achieving an acceptable level of accuracy on long documents. We measure the impact of incorporating such visual cues, obtained via computer vision methods, on the accuracy of document understanding tasks including document segmentation, entity extraction, and attribute classification. Our method of segmenting documents based on structural metadata out-performs existing methods on four long-document understanding tasks as measured on the Contract Understanding Atticus Dataset.
Gradient Ascent Algorithm for Enhancing Secrecy Rate in Wireless Communications for Smart Grid
Aug 11, 2021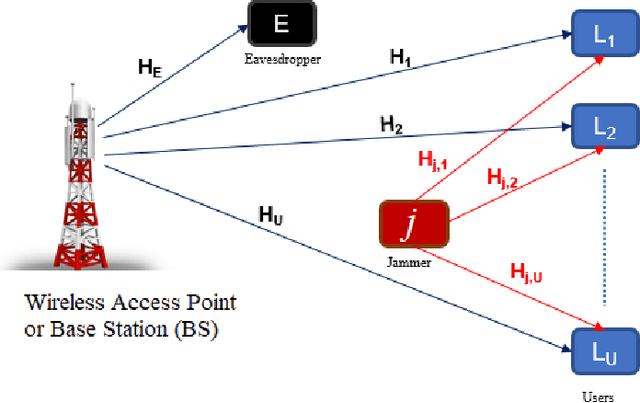
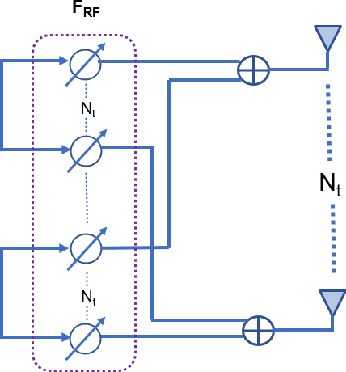
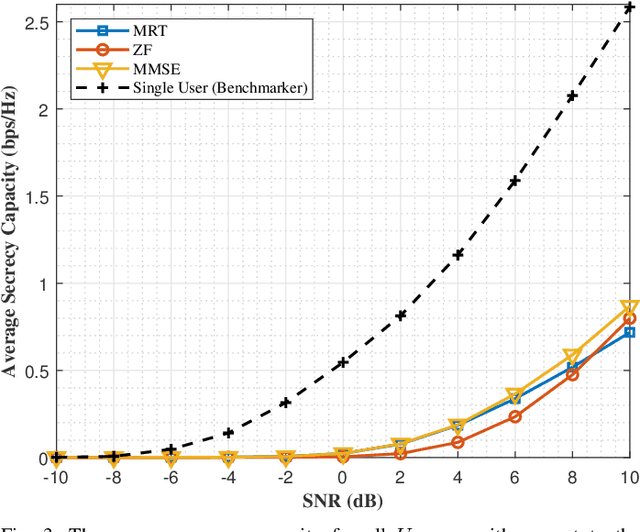
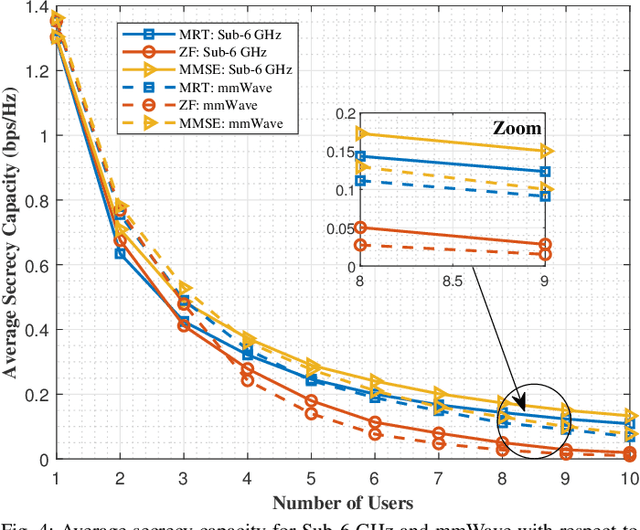
The emerging Internet of Things (IoT) and bidirectional communications in smart grid are expected to improve smart grid capabilities and electricity management. Because of massive number of IoT devices in smart grid, size of the data to be transmitted increases, that demands a high data rate to meet the real-time smart grid communications requirements. Sub-6 GHz, millimeter-wave (mmWave) technologies, and massive multiple-input multiple-output (MIMO) technologies can meet high data rate demands. However, IoT enabled smart grid is still subject to various security challenges such as eavesdropping, where attackers attempt to overhear the transmitted signals and the jamming attack, where the attacker perturbs the received signals at the receiver. In this paper, our goal is to investigate jamming and eavesdropping attacks while improving secrecy capacity for smart grid communications. Specifically, we propose to employ a hybrid beamforming design for wireless communications in smart energy grid. In previous works, the secrecy capacity is increased by randomly augmenting the source power or setting the system combiners. Unlike state-of-the-art, we design and evaluate the Gradient Ascent algorithm to search for the best combiners/waveform that maximizes the secrecy capacity in smart grid communications. We also study two different optimization scenarios by considering both fixed and variable transmit power. Numerical results are used for performance evaluation and supporting our formal analysis.
Block-Structure Based Time-Series Models For Graph Sequences
Sep 18, 2018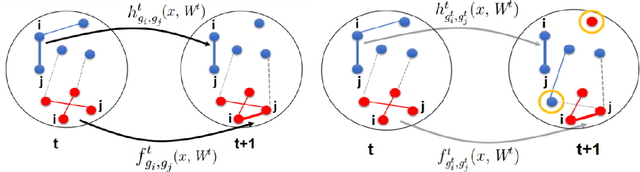


Although the computational and statistical trade-off for modeling single graphs, for instance, using block models is relatively well understood, extending such results to sequences of graphs has proven to be difficult. In this work, we take a step in this direction by proposing two models for graph sequences that capture: (a) link persistence between nodes across time, and (b) community persistence of each node across time. In the first model, we assume that the latent community of each node does not change over time, and in the second model we relax this assumption suitably. For both of these proposed models, we provide statistically and computationally efficient inference algorithms, whose unique feature is that they leverage community detection methods that work on single graphs. We also provide experimental results validating the suitability of our models and methods on synthetic and real instances.