 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Timestamping Documents and Beliefs
Jun 09, 2021
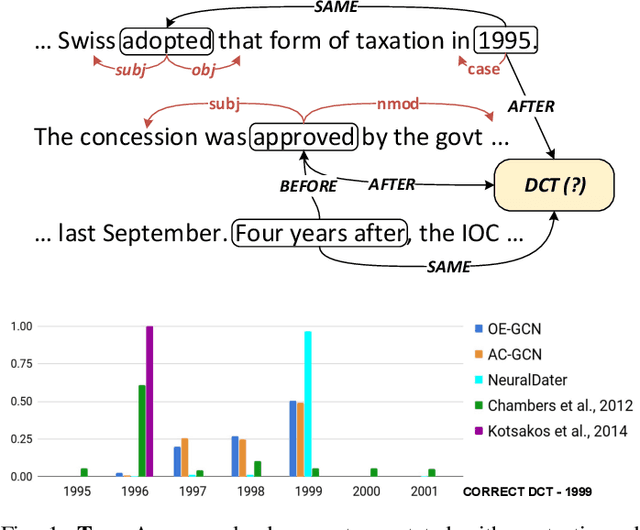
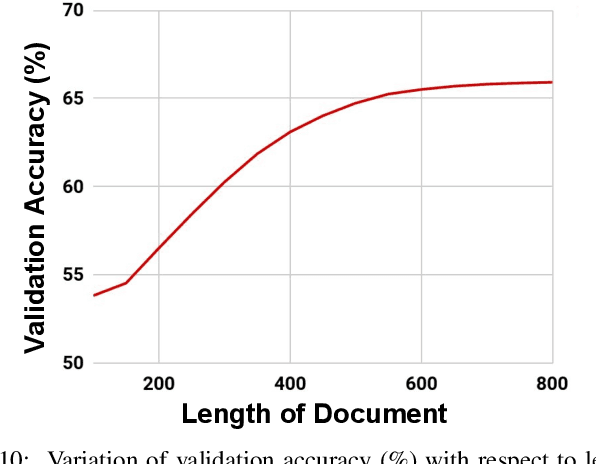
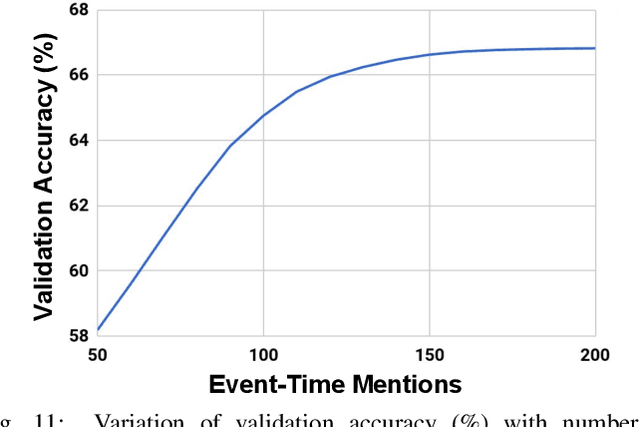
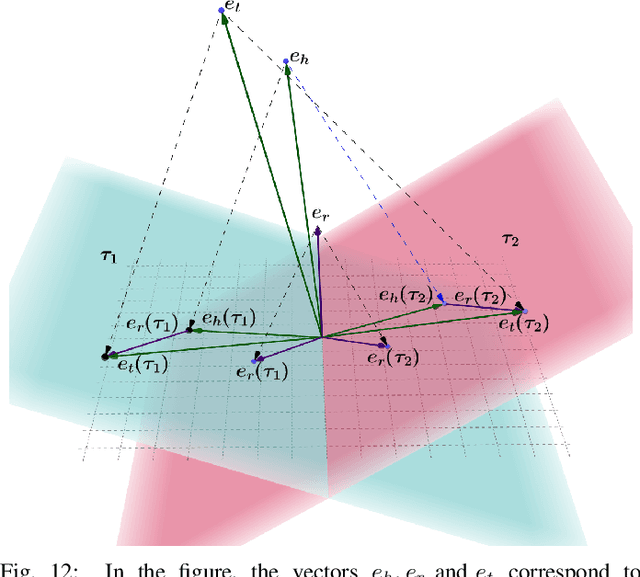
Most of the textual information available to us are temporally variable. In a world where information is dynamic, time-stamping them is a very important task. Documents are a good source of information and are used for many tasks like, sentiment analysis, classification of reviews etc. The knowledge of creation date of documents facilitates several tasks like summarization, event extraction, temporally focused information extraction etc. Unfortunately, for most of the documents on the web, the time-stamp meta-data is either erroneous or missing. Thus document dating is a challenging problem which requires inference over the temporal structure of the document alongside the contextual information of the document. Prior document dating systems have largely relied on handcrafted features while ignoring such document-internal structures. In this paper we propose NeuralDater, a Graph Convolutional Network (GCN) based document dating approach which jointly exploits syntactic and temporal graph structures of document in a principled way. We also pointed out some limitations of NeuralDater and tried to utilize both context and temporal information in documents in a more flexible and intuitive manner proposing AD3: Attentive Deep Document Dater, an attention-based document dating system. To the best of our knowledge these are the first application of deep learning methods for the task. Through extensive experiments on real-world datasets, we find that our models significantly outperforms state-of-the-art baselines by a significant margin.
Using CNNs for AD classification based on spatial correlation of BOLD signals during the observation
Apr 21, 2021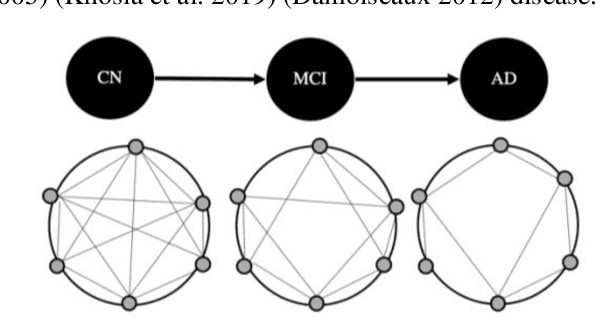
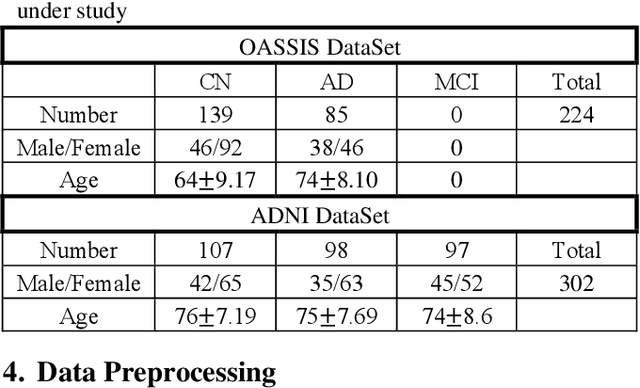
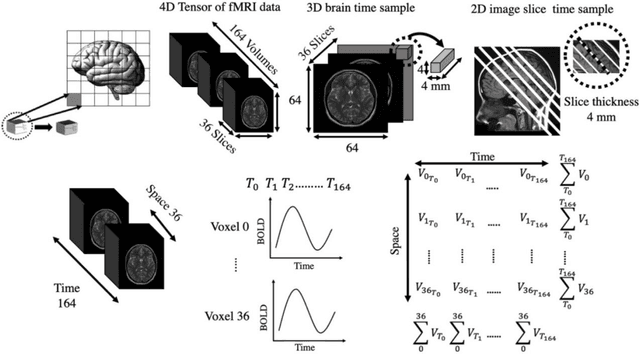
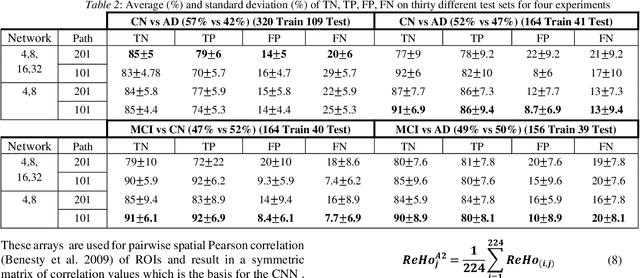
Resting state functional magnetic resonance images (fMRI) are commonly used for classification of patients as having Alzheimer's disease (AD), mild cognitive impairment (MCI), or being cognitive normal (CN). Most methods use time-series correlation of voxels signals during the observation period as a basis for the classification. In this paper we show that Convolutional Neural Network (CNN) classification based on spatial correlation of time-averaged signals yield a classification accuracy of up to 82% (sensitivity 86%, specificity 80%)for a data set with 429 subjects (246 cognitive normal and 183 Alzheimer patients). For the spatial correlation of time-averaged signal values we use voxel subdomains around center points of the 90 regions AAL atlas. We form the subdomains as sets of voxels along a Hilbert curve of a bounding box in which the brain is embedded with the AAL regions center points serving as subdomain seeds. The matrix resulting from the spatial correlation of the 90 arrays formed by the subdomain segments of the Hilbert curve yields a symmetric 90x90 matrix that is used for the classification based on two different CNN networks, a 4-layer CNN network with 3x3 filters and with 4, 8, 16, and 32 output channels respectively, and a 2-layer CNN network with 3x3 filters and with 4 and 8 output channels respectively. The results of the two networks are reported and compared.
RLTutor: Reinforcement Learning Based Adaptive Tutoring System by Modeling Virtual Student with Fewer Interactions
Jul 31, 2021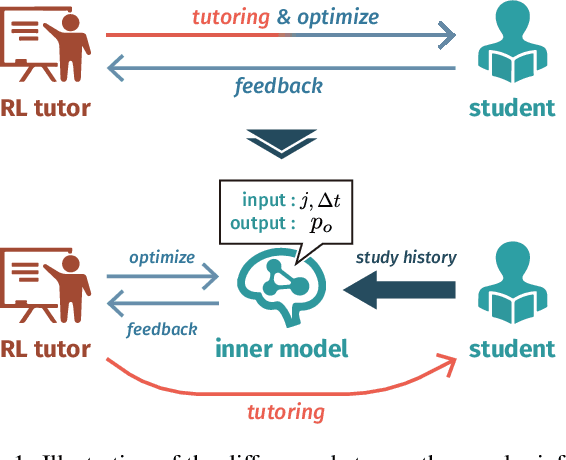
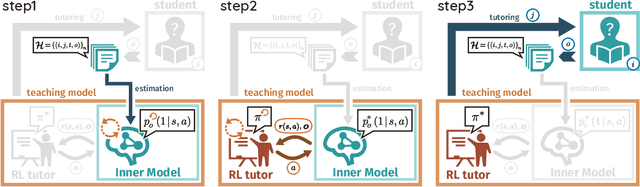
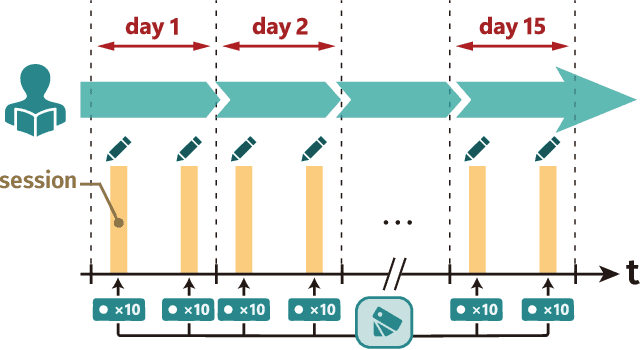
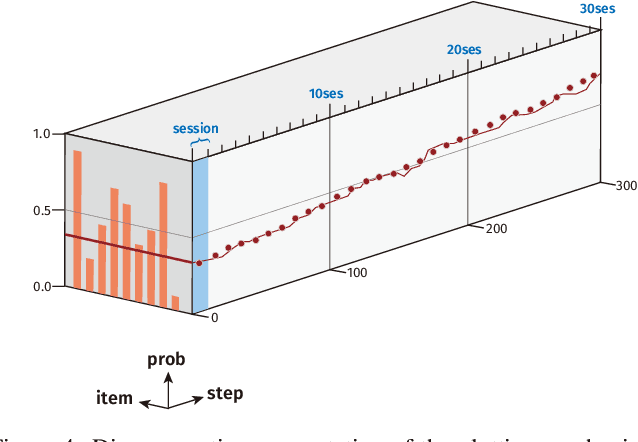
A major challenge in the field of education is providing review schedules that present learned items at appropriate intervals to each student so that memory is retained over time. In recent years, attempts have been made to formulate item reviews as sequential decision-making problems to realize adaptive instruction based on the knowledge state of students. It has been reported previously that reinforcement learning can help realize mathematical models of students learning strategies to maintain a high memory rate. However, optimization using reinforcement learning requires a large number of interactions, and thus it cannot be applied directly to actual students. In this study, we propose a framework for optimizing teaching strategies by constructing a virtual model of the student while minimizing the interaction with the actual teaching target. In addition, we conducted an experiment considering actual instructions using the mathematical model and confirmed that the model performance is comparable to that of conventional teaching methods. Our framework can directly substitute mathematical models used in experiments with human students, and our results can serve as a buffer between theoretical instructional optimization and practical applications in e-learning systems.
Standardized Max Logits: A Simple yet Effective Approach for Identifying Unexpected Road Obstacles in Urban-Scene Segmentation
Aug 12, 2021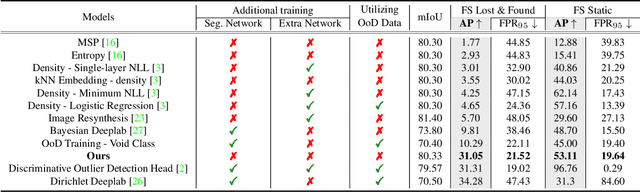
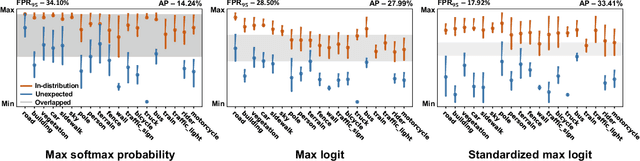


Identifying unexpected objects on roads in semantic segmentation (e.g., identifying dogs on roads) is crucial in safety-critical applications. Existing approaches use images of unexpected objects from external datasets or require additional training (e.g., retraining segmentation networks or training an extra network), which necessitate a non-trivial amount of labor intensity or lengthy inference time. One possible alternative is to use prediction scores of a pre-trained network such as the max logits (i.e., maximum values among classes before the final softmax layer) for detecting such objects. However, the distribution of max logits of each predicted class is significantly different from each other, which degrades the performance of identifying unexpected objects in urban-scene segmentation. To address this issue, we propose a simple yet effective approach that standardizes the max logits in order to align the different distributions and reflect the relative meanings of max logits within each predicted class. Moreover, we consider the local regions from two different perspectives based on the intuition that neighboring pixels share similar semantic information. In contrast to previous approaches, our method does not utilize any external datasets or require additional training, which makes our method widely applicable to existing pre-trained segmentation models. Such a straightforward approach achieves a new state-of-the-art performance on the publicly available Fishyscapes Lost & Found leaderboard with a large margin.
RTM3D: Real-time Monocular 3D Detection from Object Keypoints for Autonomous Driving
Jan 10, 2020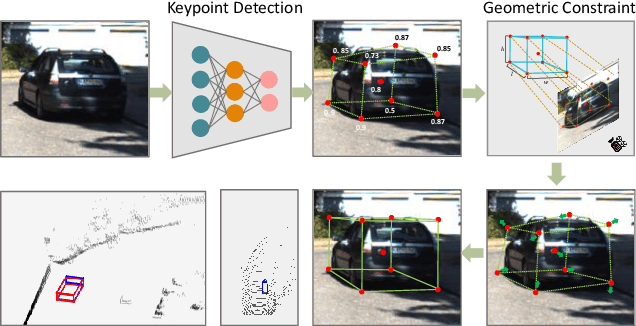
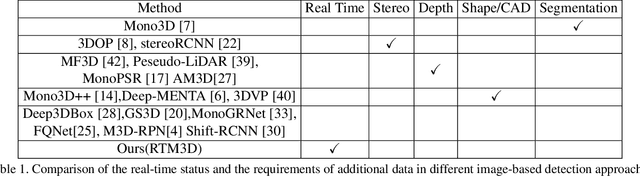
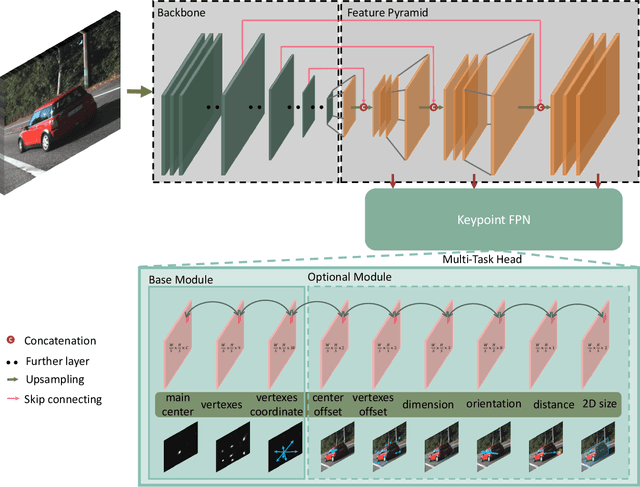
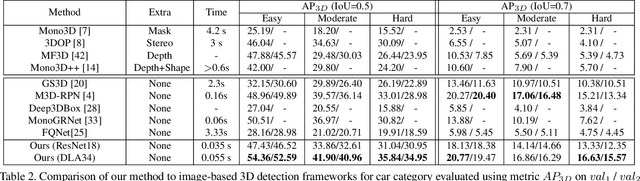
In this work, we propose an efficient and accurate monocular 3D detection framework in single shot. Most successful 3D detectors take the projection constraint from the 3D bounding box to the 2D box as an important component. Four edges of a 2D box provide only four constraints and the performance deteriorates dramatically with the small error of the 2D detector. Different from these approaches, our method predicts the nine perspective keypoints of a 3D bounding box in image space, and then utilize the geometric relationship of 3D and 2D perspectives to recover the dimension, location, and orientation in 3D space. In this method, the properties of the object can be predicted stably even when the estimation of keypoints is very noisy, which enables us to obtain fast detection speed with a small architecture. Training our method only uses the 3D properties of the object without the need for external networks or supervision data. Our method is the first real-time system for monocular image 3D detection while achieves state-of-the-art performance on the KITTI benchmark. Code will be released at https://github.com/Banconxuan/RTM3D.
Bayesian analysis of the prevalence bias: learning and predicting from imbalanced data
Jul 31, 2021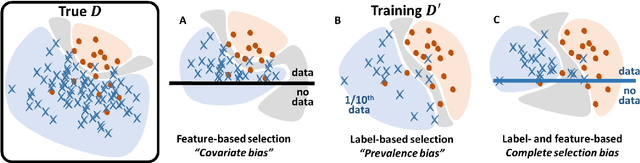
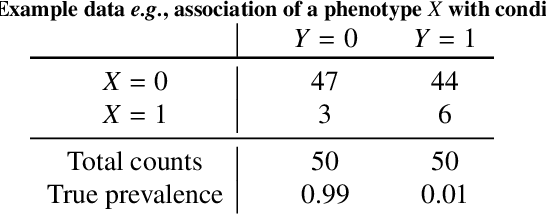

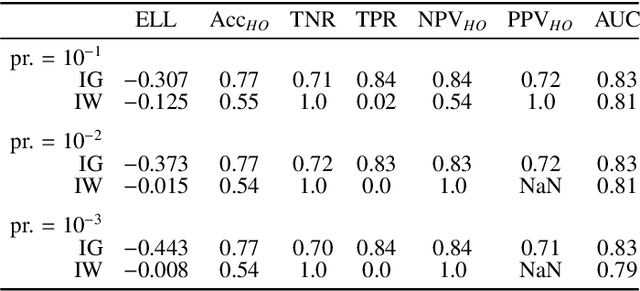
Datasets are rarely a realistic approximation of the target population. Say, prevalence is misrepresented, image quality is above clinical standards, etc. This mismatch is known as sampling bias. Sampling biases are a major hindrance for machine learning models. They cause significant gaps between model performance in the lab and in the real world. Our work is a solution to prevalence bias. Prevalence bias is the discrepancy between the prevalence of a pathology and its sampling rate in the training dataset, introduced upon collecting data or due to the practioner rebalancing the training batches. This paper lays the theoretical and computational framework for training models, and for prediction, in the presence of prevalence bias. Concretely a bias-corrected loss function, as well as bias-corrected predictive rules, are derived under the principles of Bayesian risk minimization. The loss exhibits a direct connection to the information gain. It offers a principled alternative to heuristic training losses and complements test-time procedures based on selecting an operating point from summary curves. It integrates seamlessly in the current paradigm of (deep) learning using stochastic backpropagation and naturally with Bayesian models.
FisheyeMultiNet: Real-time Multi-task Learning Architecture for Surround-view Automated Parking System
Dec 23, 2019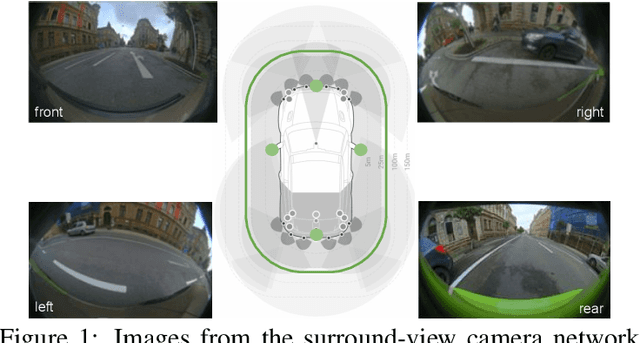
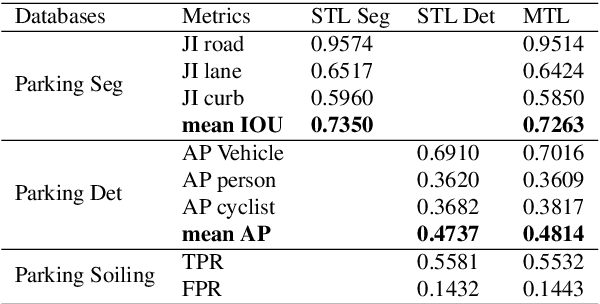
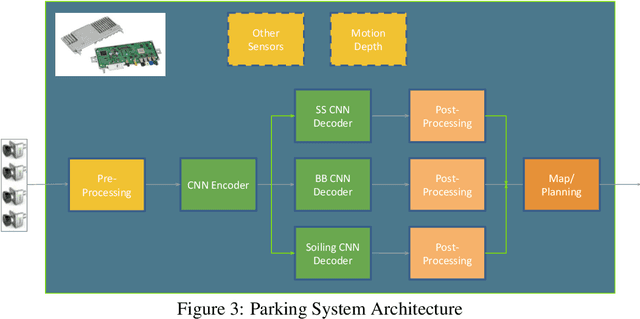
Automated Parking is a low speed manoeuvring scenario which is quite unstructured and complex, requiring full 360{\deg} near-field sensing around the vehicle. In this paper, we discuss the design and implementation of an automated parking system from the perspective of camera based deep learning algorithms. We provide a holistic overview of an industrial system covering the embedded system, use cases and the deep learning architecture. We demonstrate a real-time multi-task deep learning network called FisheyeMultiNet, which detects all the necessary objects for parking on a low-power embedded system. FisheyeMultiNet runs at 15 fps for 4 cameras and it has three tasks namely object detection, semantic segmentation and soiling detection. To encourage further research, we release a partial dataset of 5,000 images containing semantic segmentation and bounding box detection ground truth via WoodScape project \cite{yogamani2019woodscape}.
Combining 3D Image and Tabular Data via the Dynamic Affine Feature Map Transform
Jul 13, 2021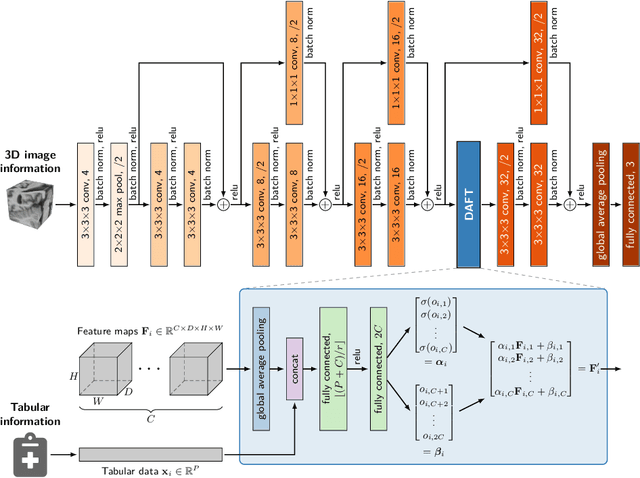

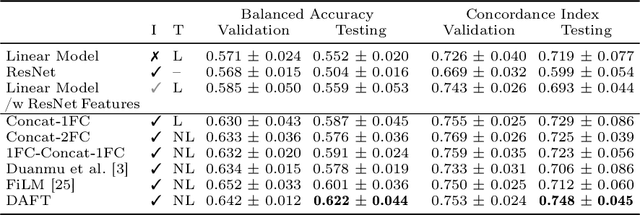
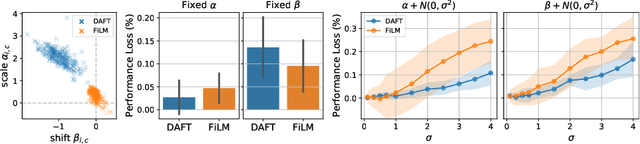
Prior work on diagnosing Alzheimer's disease from magnetic resonance images of the brain established that convolutional neural networks (CNNs) can leverage the high-dimensional image information for classifying patients. However, little research focused on how these models can utilize the usually low-dimensional tabular information, such as patient demographics or laboratory measurements. We introduce the Dynamic Affine Feature Map Transform (DAFT), a general-purpose module for CNNs that dynamically rescales and shifts the feature maps of a convolutional layer, conditional on a patient's tabular clinical information. We show that DAFT is highly effective in combining 3D image and tabular information for diagnosis and time-to-dementia prediction, where it outperforms competing CNNs with a mean balanced accuracy of 0.622 and mean c-index of 0.748, respectively. Our extensive ablation study provides valuable insights into the architectural properties of DAFT. Our implementation is available at https://github.com/ai-med/DAFT.
CARL-DTN: Context Adaptive Reinforcement Learning based Routing Algorithm in Delay Tolerant Network
May 02, 2021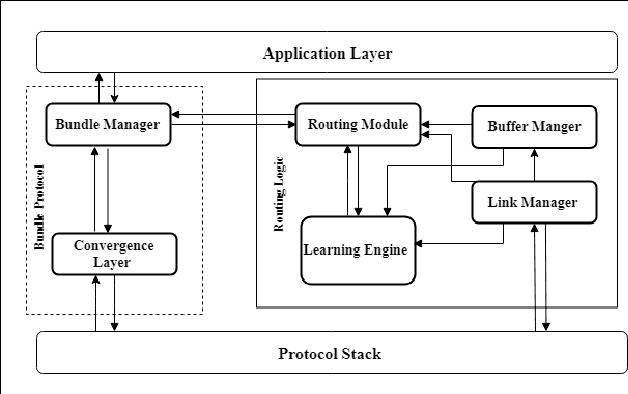
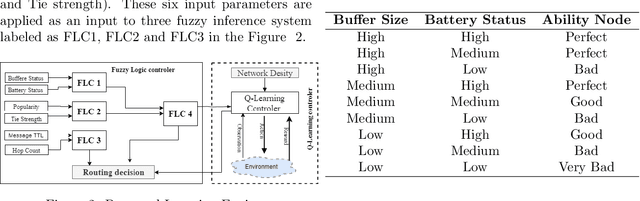
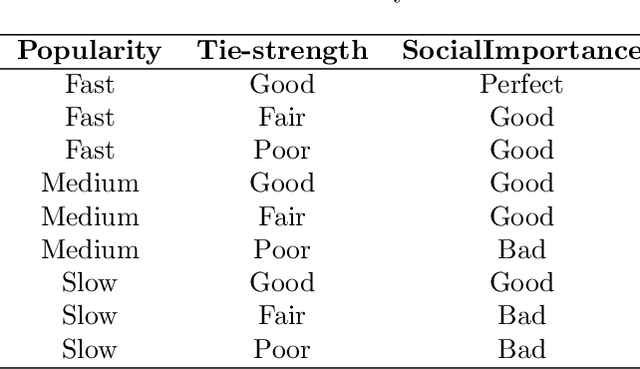
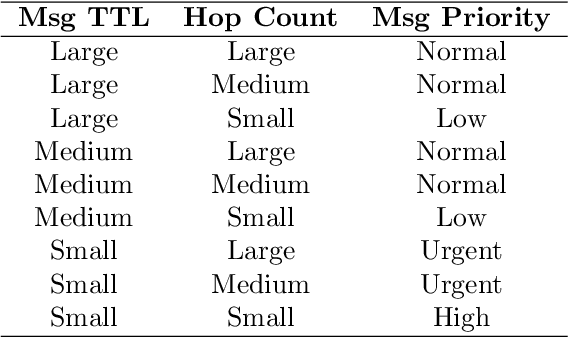
The term Delay/Disruption-Tolerant Networks (DTN) invented to describe and cover all types of long-delay, disconnected, intermittently connected networks, where mobility and outages or scheduled contacts may be experienced. This environment is characterized by frequent network partitioning, intermittent connectivity, large or variable delay, asymmetric data rate, and low transmission reliability. There have been routing protocols developed in DTN. However, those routing algorithms are design based upon specific assumptions. The assumption makes existing algorithms suitable for specific environment scenarios. Different routing algorithm uses different relay node selection criteria to select the replication node. Too Frequently forwarding messages can result in excessive packet loss and large buffer and network overhead. On the other hand, less frequent transmission leads to a lower delivery ratio. In DTN there is a trade-off off between delivery ratio and overhead. In this study, we proposed context-adaptive reinforcement learning based routing(CARL-DTN) protocol to determine optimal replicas of the message based on the real-time density. Our routing protocol jointly uses a real-time physical context, social-tie strength, and real-time message context using fuzzy logic in the routing decision. Multi-hop forwarding probability is also considered for the relay node selection by employing Q-Learning algorithm to estimate the encounter probability between nodes and to learn about nodes available in the neighbor by discounting reward. The performance of the proposed protocol is evaluated based on various simulation scenarios. The result shows that the proposed protocol has better performance in terms of message delivery ratio and overhead.
Optimal personalised treatment computation through in silico clinical trials on patient digital twins
Jun 20, 2021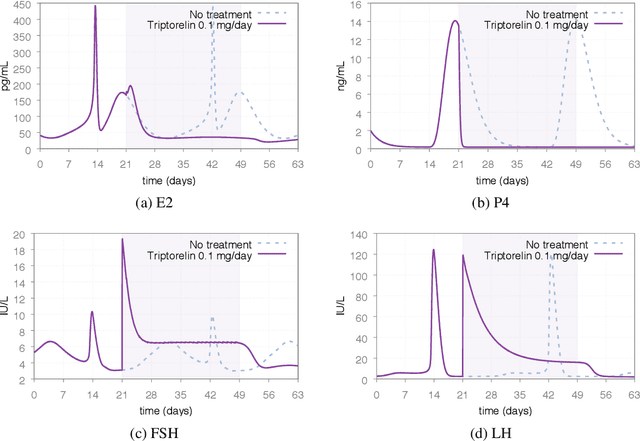

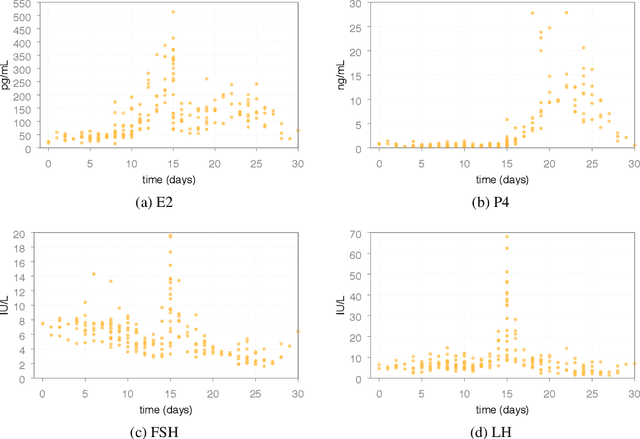
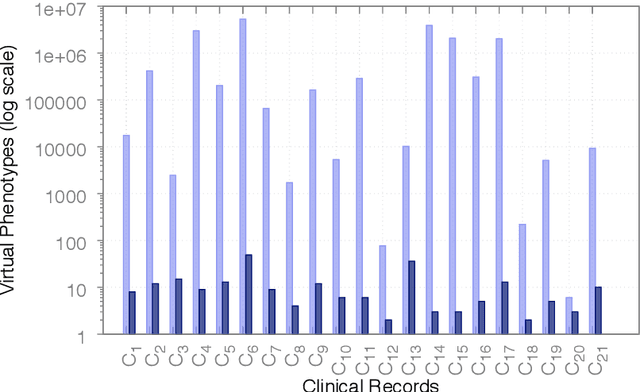
In Silico Clinical Trials (ISTC), i.e., clinical experimental campaigns carried out by means of computer simulations, hold the promise to decrease time and cost for the safety and efficacy assessment of pharmacological treatments, reduce the need for animal and human testing, and enable precision medicine. In this paper we present methods and an algorithm that, by means of extensive computer simulation--based experimental campaigns (ISTC) guided by intelligent search, optimise a pharmacological treatment for an individual patient (precision medicine). e show the effectiveness of our approach on a case study involving a real pharmacological treatment, namely the downregulation phase of a complex clinical protocol for assisted reproduction in humans.
* 31 pages, 9 figures