 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
RTM3D: Real-time Monocular 3D Detection from Object Keypoints for Autonomous Driving
Jan 10, 2020
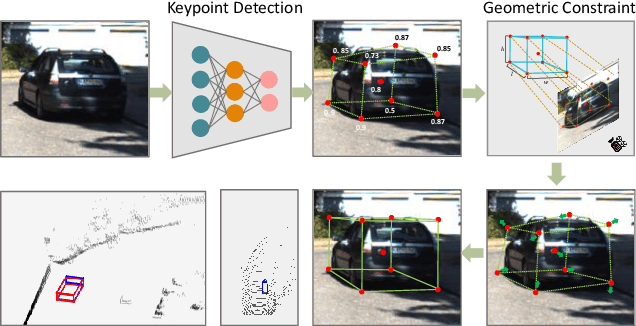
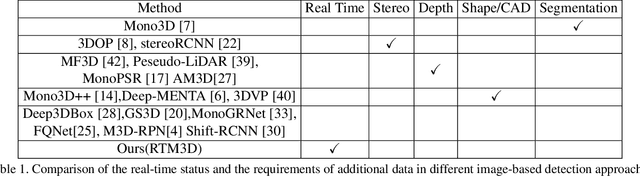
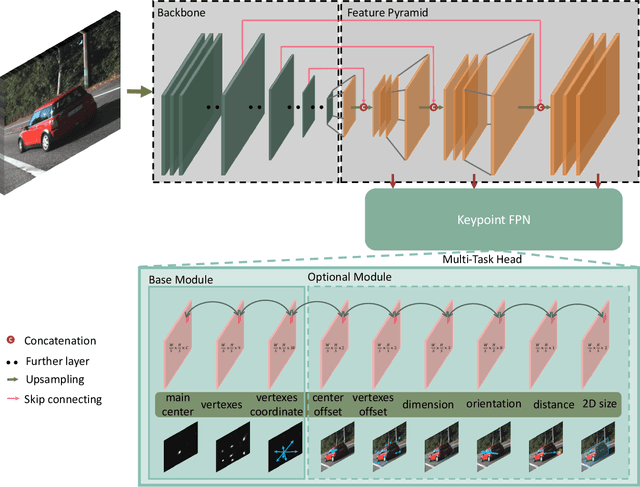
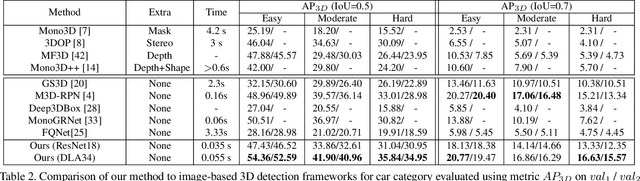
In this work, we propose an efficient and accurate monocular 3D detection framework in single shot. Most successful 3D detectors take the projection constraint from the 3D bounding box to the 2D box as an important component. Four edges of a 2D box provide only four constraints and the performance deteriorates dramatically with the small error of the 2D detector. Different from these approaches, our method predicts the nine perspective keypoints of a 3D bounding box in image space, and then utilize the geometric relationship of 3D and 2D perspectives to recover the dimension, location, and orientation in 3D space. In this method, the properties of the object can be predicted stably even when the estimation of keypoints is very noisy, which enables us to obtain fast detection speed with a small architecture. Training our method only uses the 3D properties of the object without the need for external networks or supervision data. Our method is the first real-time system for monocular image 3D detection while achieves state-of-the-art performance on the KITTI benchmark. Code will be released at https://github.com/Banconxuan/RTM3D.
FastS2S-VC: Streaming Non-Autoregressive Sequence-to-Sequence Voice Conversion
Apr 14, 2021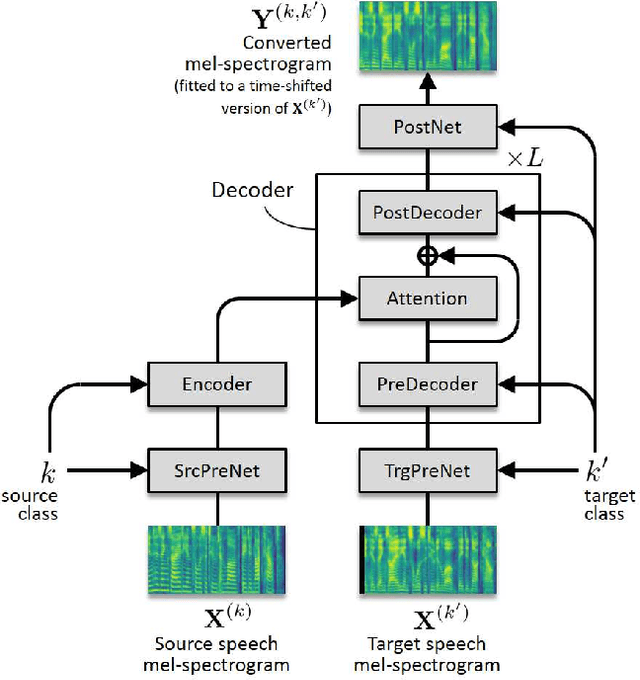
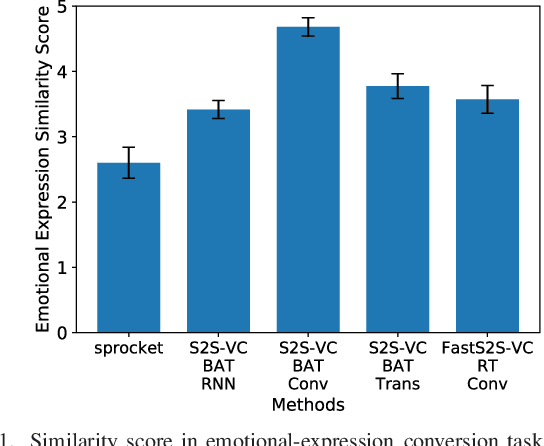
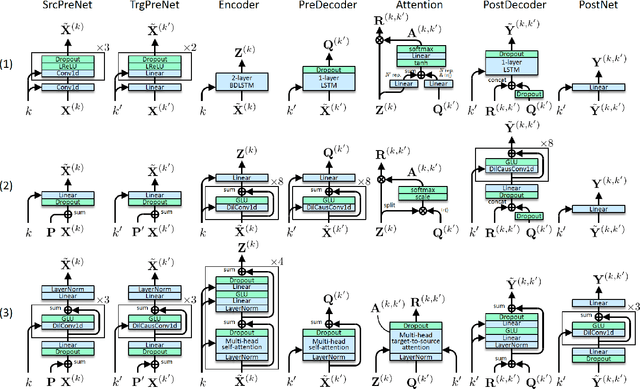
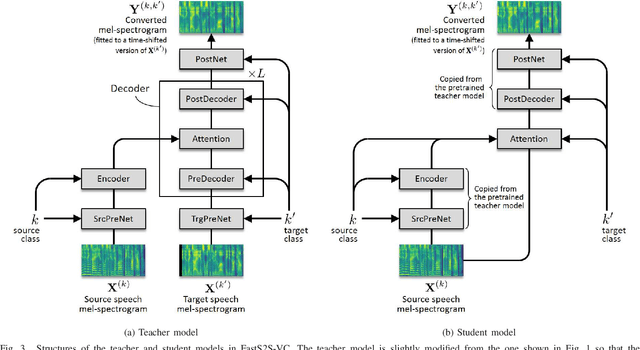
This paper proposes a non-autoregressive extension of our previously proposed sequence-to-sequence (S2S) model-based voice conversion (VC) methods. S2S model-based VC methods have attracted particular attention in recent years for their flexibility in converting not only the voice identity but also the pitch contour and local duration of input speech, thanks to the ability of the encoder-decoder architecture with the attention mechanism. However, one of the obstacles to making these methods work in real-time is the autoregressive (AR) structure. To overcome this obstacle, we develop a method to obtain a model that is free from an AR structure and behaves similarly to the original S2S models, based on a teacher-student learning framework. In our method, called "FastS2S-VC", the student model consists of encoder, decoder, and attention predictor. The attention predictor learns to predict attention distributions solely from source speech along with a target class index with the guidance of those predicted by the teacher model from both source and target speech. Thanks to this structure, the model is freed from an AR structure and allows for parallelization. Furthermore, we show that FastS2S-VC is suitable for real-time implementation based on a sliding-window approach, and describe how to make it run in real-time. Through speaker-identity and emotional-expression conversion experiments, we confirmed that FastS2S-VC was able to speed up the conversion process by 70 to 100 times compared to the original AR-type S2S-VC methods, without significantly degrading the audio quality and similarity to target speech. We also confirmed that the real-time version of FastS2S-VC can be run with a latency of 32 ms when run on a GPU.
MONCAE: Multi-Objective Neuroevolution of Convolutional Autoencoders
Jun 07, 2021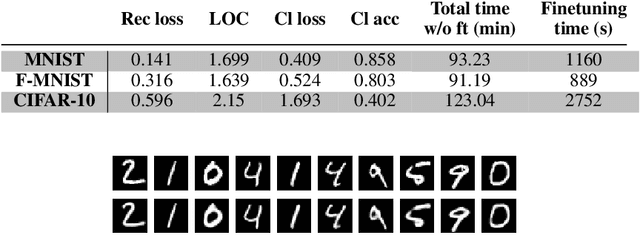

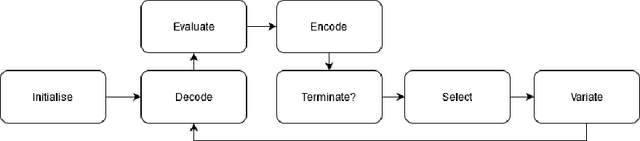

In this paper, we present a novel neuroevolutionary method to identify the architecture and hyperparameters of convolutional autoencoders. Remarkably, we used a hypervolume indicator in the context of neural architecture search for autoencoders, for the first time to our current knowledge. Results show that images were compressed by a factor of more than 10, while still retaining enough information to achieve image classification for the majority of the tasks. Thus, this new approach can be used to speed up the AutoML pipeline for image compression.
Long short-term relevance learning
Jun 21, 2021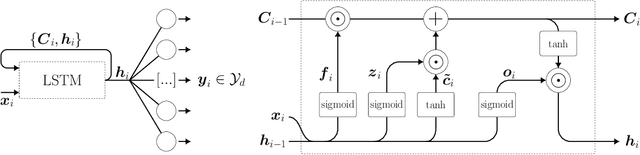
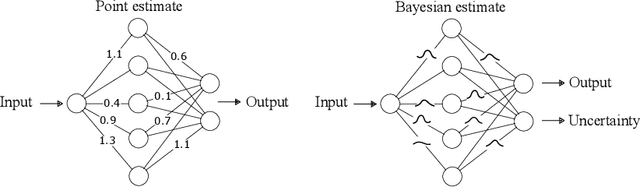
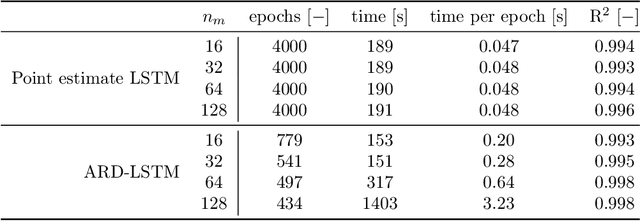
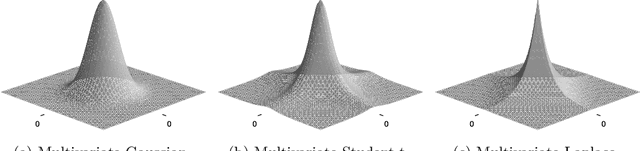
To incorporate prior knowledge as well as measurement uncertainties in the traditional long short term memory (LSTM) neural networks, an efficient sparse Bayesian training algorithm is introduced to the network architecture. The proposed scheme automatically determines relevant neural connections and adapts accordingly, in contrast to the classical LSTM solution. Due to its flexibility, the new LSTM scheme is less prone to overfitting, and hence can approximate time dependent solutions by use of a smaller data set. On a structural nonlinear finite element application we show that the self-regulating framework does not require prior knowledge of a suitable network architecture and size, while ensuring satisfying accuracy at reasonable computational cost.
FisheyeMultiNet: Real-time Multi-task Learning Architecture for Surround-view Automated Parking System
Dec 23, 2019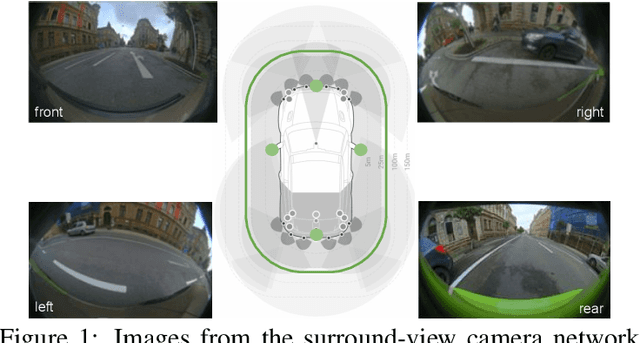
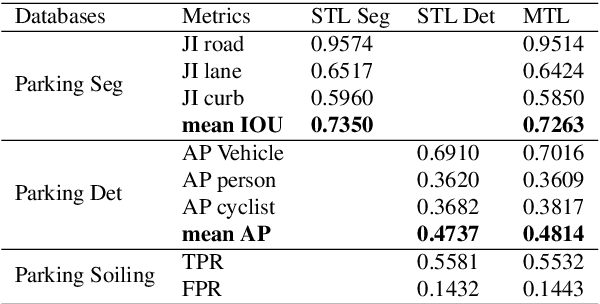
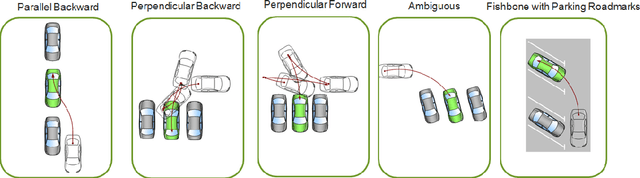
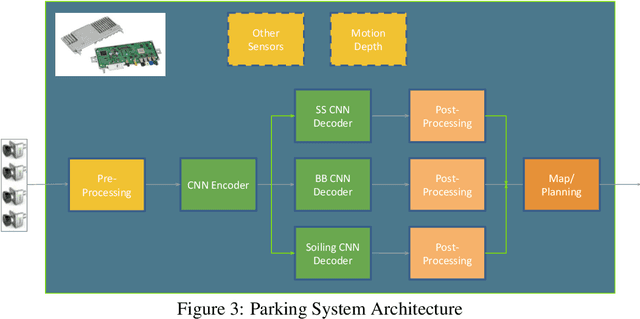
Automated Parking is a low speed manoeuvring scenario which is quite unstructured and complex, requiring full 360{\deg} near-field sensing around the vehicle. In this paper, we discuss the design and implementation of an automated parking system from the perspective of camera based deep learning algorithms. We provide a holistic overview of an industrial system covering the embedded system, use cases and the deep learning architecture. We demonstrate a real-time multi-task deep learning network called FisheyeMultiNet, which detects all the necessary objects for parking on a low-power embedded system. FisheyeMultiNet runs at 15 fps for 4 cameras and it has three tasks namely object detection, semantic segmentation and soiling detection. To encourage further research, we release a partial dataset of 5,000 images containing semantic segmentation and bounding box detection ground truth via WoodScape project \cite{yogamani2019woodscape}.
Towards Unsupervised Fine-Tuning for Edge Video Analytics
Apr 14, 2021
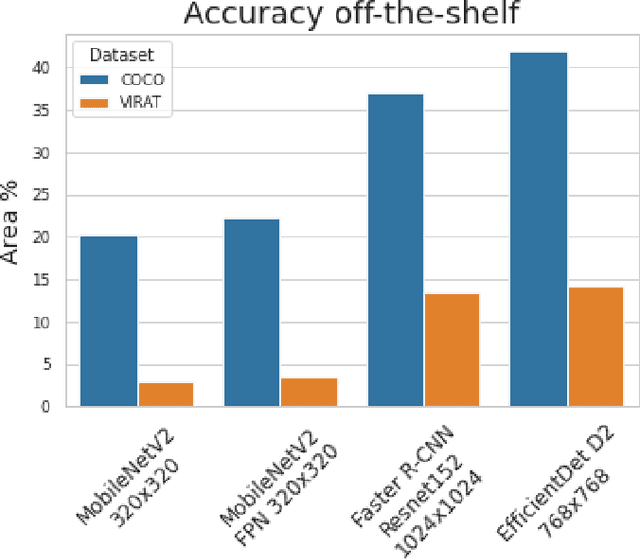
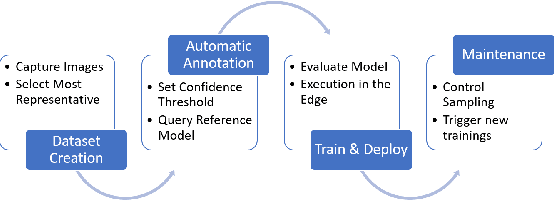
Judging by popular and generic computer vision challenges, such as the ImageNet or PASCAL VOC, neural networks have proven to be exceptionally accurate in recognition tasks. However, state-of-the-art accuracy often comes at a high computational price, requiring equally state-of-the-art and high-end hardware acceleration to achieve anything near real-time performance. At the same time, use cases such as smart cities or autonomous vehicles require an automated analysis of images from fixed cameras in real-time. Due to the huge and constant amount of network bandwidth these streams would generate, we cannot rely on offloading compute to the omnipresent and omnipotent cloud. Therefore, a distributed Edge Cloud must be in charge to process images locally. However, the Edge Cloud is, by nature, resource-constrained, which puts a limit on the computational complexity of the models executed in the edge. Nonetheless, there is a need for a meeting point between the Edge Cloud and accurate real-time video analytics. In this paper, we propose a method for improving accuracy of edge models without any extra compute cost by means of automatic model specialization. First, we show how the sole assumption of static cameras allows us to make a series of considerations that greatly simplify the scope of the problem. Then, we present Edge AutoTuner, a framework that implements and brings these considerations together to automate the end-to-end fine-tuning of models. Finally, we show that complex neural networks - able to generalize better - can be effectively used as teachers to annotate datasets for the fine-tuning of lightweight neural networks and tailor them to the specific edge context, which boosts accuracy at constant computational cost, and do so without any human interaction. Results show that our method can automatically improve accuracy of pre-trained models by an average of 21%.
Agile wide-field imaging with selective high resolution
Jun 09, 2021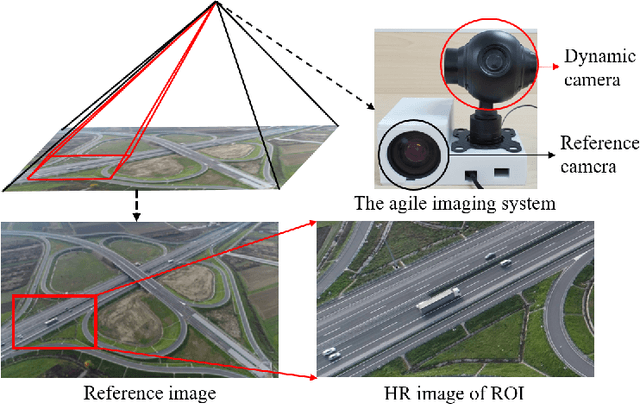
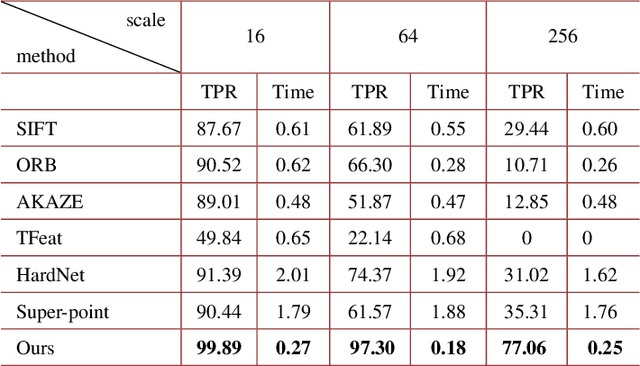
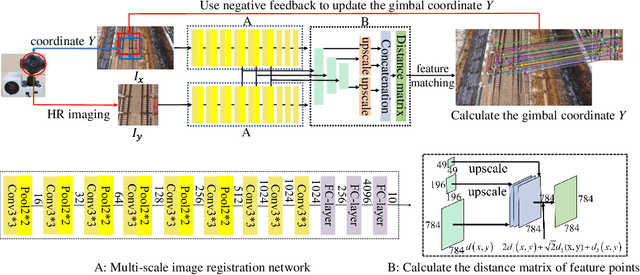
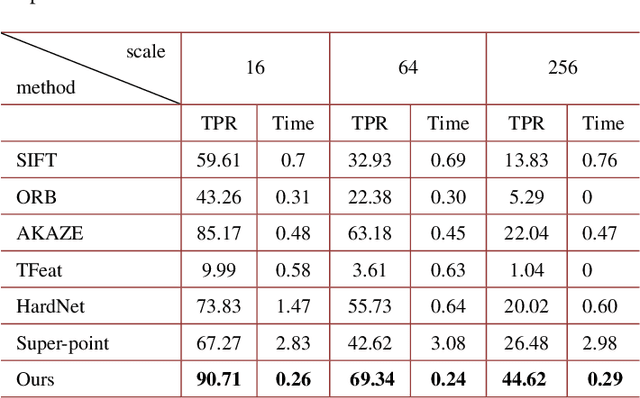
Wide-field and high-resolution (HR) imaging is essential for various applications such as aviation reconnaissance, topographic mapping and safety monitoring. The existing techniques require a large-scale detector array to capture HR images of the whole field, resulting in high complexity and heavy cost. In this work, we report an agile wide-field imaging framework with selective high resolution that requires only two detectors. It builds on the statistical sparsity prior of natural scenes that the important targets locate only at small regions of interests (ROI), instead of the whole field. Under this assumption, we use a short-focal camera to image wide field with a certain low resolution, and use a long-focal camera to acquire the HR images of ROI. To automatically locate ROI in the wide field in real time, we propose an efficient deep-learning based multiscale registration method that is robust and blind to the large setting differences (focal, white balance, etc) between the two cameras. Using the registered location, the long-focal camera mounted on a gimbal enables real-time tracking of the ROI for continuous HR imaging. We demonstrated the novel imaging framework by building a proof-of-concept setup with only 1181 gram weight, and assembled it on an unmanned aerial vehicle for air-to-ground monitoring. Experiments show that the setup maintains 120$^{\circ}$ wide field-of-view (FOV) with selective 0.45$mrad$ instantaneous FOV.
Model-Parallel Model Selection for Deep Learning Systems
Jul 14, 2021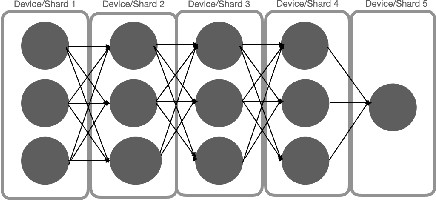
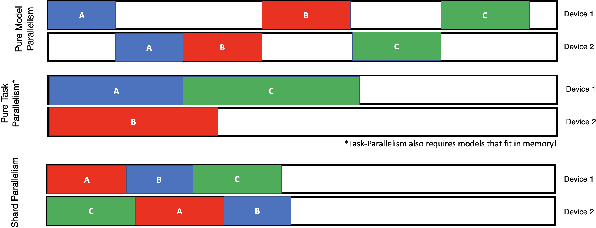
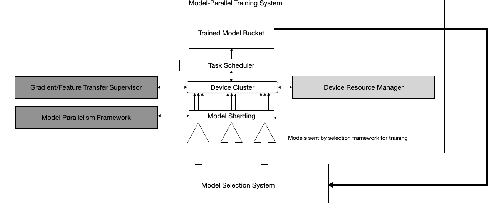
As deep learning becomes more expensive, both in terms of time and compute, inefficiencies in machine learning (ML) training prevent practical usage of state-of-the-art models for most users. The newest model architectures are simply too large to be fit onto a single processor. To address the issue, many ML practitioners have turned to model parallelism as a method of distributing the computational requirements across several devices. Unfortunately, the sequential nature of neural networks causes very low efficiency and device utilization in model parallel training jobs. We propose a new form of "shard parallelism" combining task and model parallelism, then package it into a framework we name Hydra. Hydra recasts the problem of model parallelism in the multi-model context to produce a fine-grained parallel workload of independent model shards, rather than independent models. This new parallel design promises dramatic speedups relative to the traditional model parallelism paradigm.
Deep learning for solution and inversion of structural mechanics and vibrations
May 18, 2021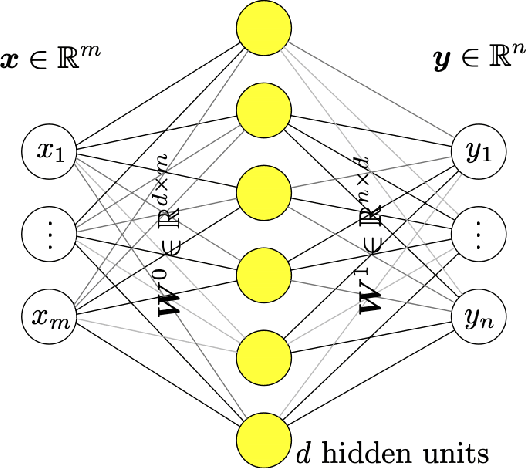
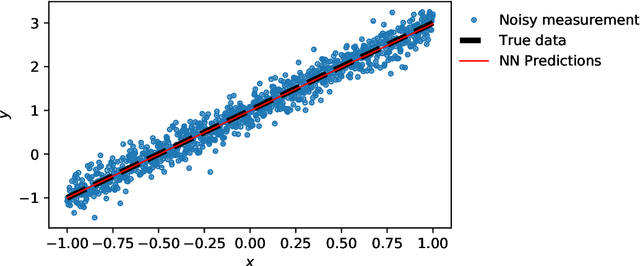
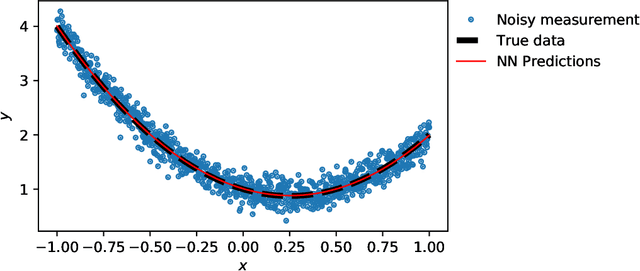
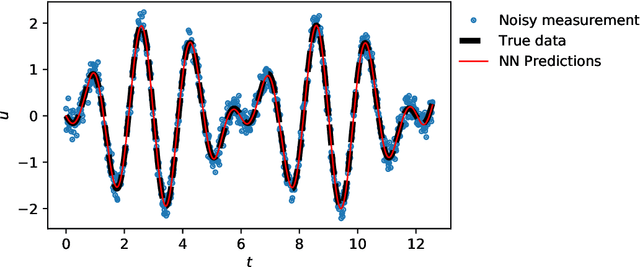
Deep learning has been the most popular machine learning method in the last few years. In this chapter, we present the application of deep learning and physics-informed neural networks concerning structural mechanics and vibration problems. Demonstration problems involve de-noising data, solution to time-dependent ordinary and partial differential equations, and characterizing the system's response for a given data.
Meta-Learning for Few-Shot Time Series Classification
Sep 25, 2019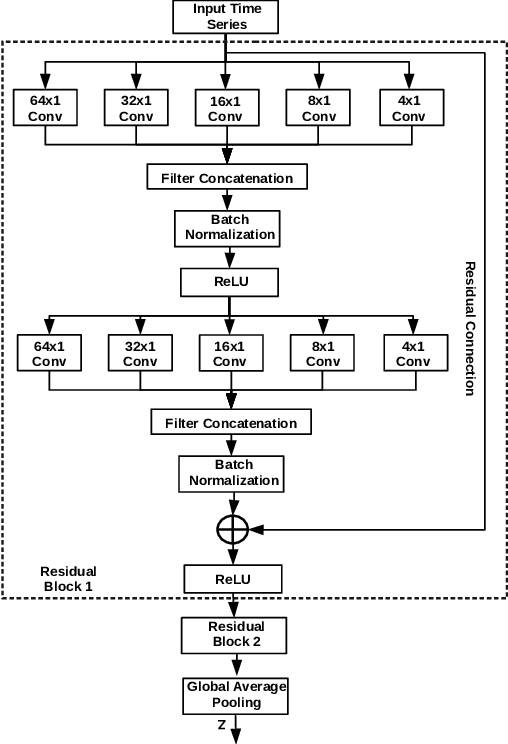
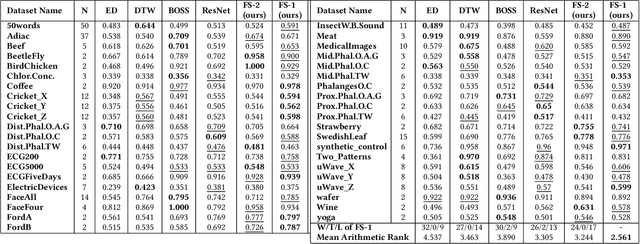
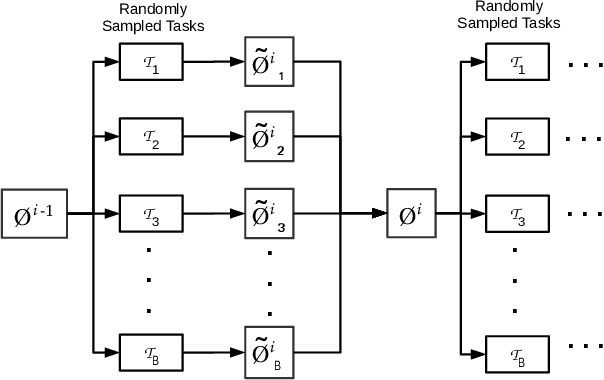
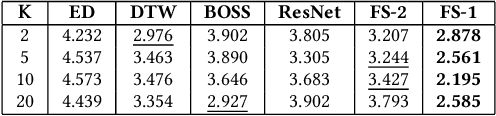
Deep neural networks (DNNs) have achieved state-of-the-art results on time series classification (TSC) tasks. In this work, we focus on leveraging DNNs in the often-encountered practical scenario where access to labeled training data is difficult, and where DNNs would be prone to overfitting. We leverage recent advancements in gradient-based meta-learning, and propose an approach to train a residual neural network with convolutional layers as a meta-learning agent for few-shot TSC. The network is trained on a diverse set of few-shot tasks sampled from various domains (e.g. healthcare, activity recognition, etc.) such that it can solve a target task from another domain using only a small number of training samples from the target task. Most existing meta-learning approaches are limited in practice as they assume a fixed number of target classes across tasks. We overcome this limitation in order to train a common agent across domains with each domain having different number of target classes, we utilize a triplet-loss based learning procedure that does not require any constraints to be enforced on the number of classes for the few-shot TSC tasks. To the best of our knowledge, we are the first to use meta-learning based pre-training for TSC. Our approach sets a new benchmark for few-shot TSC, outperforming several strong baselines on few-shot tasks sampled from 41 datasets in UCR TSC Archive. We observe that pre-training under the meta-learning paradigm allows the network to quickly adapt to new unseen tasks with small number of labeled instances.