 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
An Interpretable Web-based Glioblastoma Multiforme Prognosis Prediction Tool using Random Forest Model
Sep 09, 2021
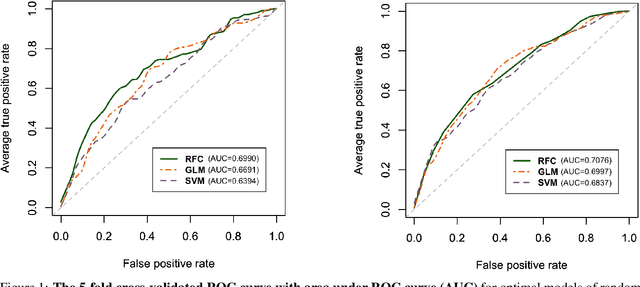
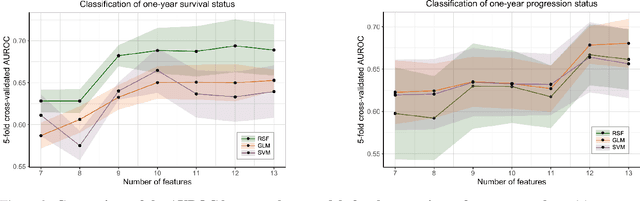
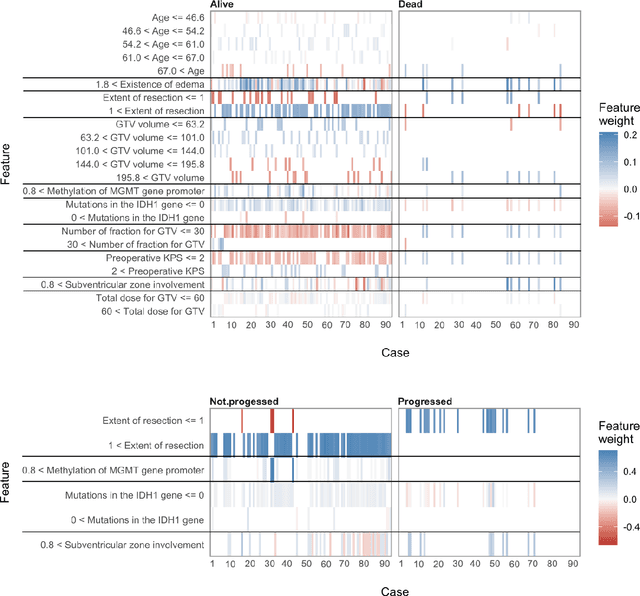
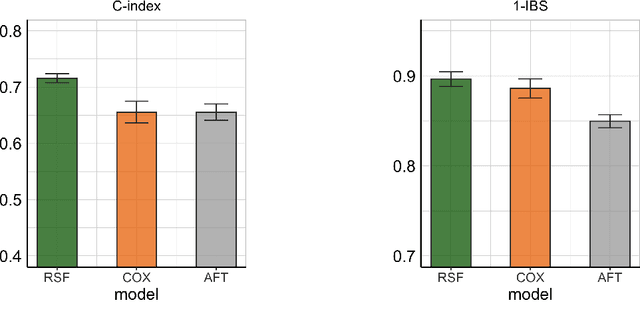
We propose predictive models that estimate GBM patients' health status of one-year after treatments (Classification task), predict the long-term prognosis of GBM patients at an individual level (Survival task). We used total of 467 GBM patients' clinical profile consists of 13 features and two follow-up dates. For baseline models of random forest classifier(RFC) and random survival forest model (RSF), we introduced generalized linear model (GLM), support vector machine (SVM) and Cox proportional hazardous model (COX), accelerated failure time model (AFT) respectively. After preprocessing and prefixing stratified 5-fold data set, we generated best performing models for model types using recursive feature elimination process. Total 10, 4, and 13 features were extracted for best performing one-year survival/progression status RFC models and RSF model via the recursive feature elimination process. In classification task, AUROC of best performing RFC recorded 0.6990 (for one-year survival status classification) and 0.7076 (for one-year progression classification) while that of second best baseline models (GLM in both cases) recorded 0.6691 and 0.6997 respectively. About survival task, the highest C-index of 0.7157 and the lowest IBS of 0.1038 came from the best performing RSF model while that of second best baseline models were 0.6556 and 0.1139 respectively. A simplified linear correlation (extracted from LIME and virtual patient group analysis) between each feature and prognosis of GBM patient were consistent with proven medical knowledge. Our machine learning models suggest that the top three prognostic factors for GBM patient survival were MGMT gene promoter, the extent of resection, and age. To the best of our knowledge, this study is the very first study introducing a interpretable and medical knowledge consistent GBM prognosis predictive models.
From Navigation to Racing: Reward Signal Design for Autonomous Racing
Mar 18, 2021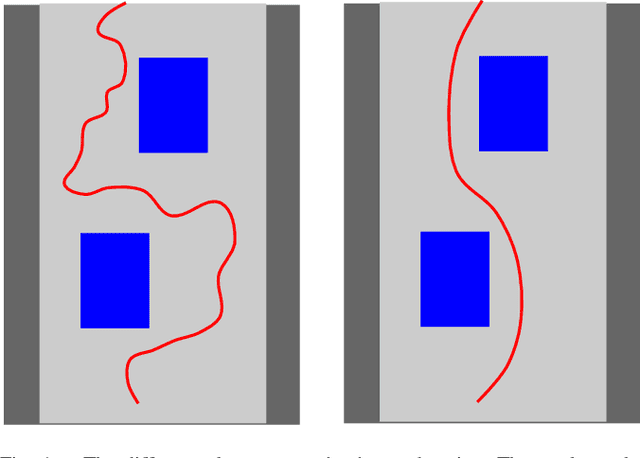
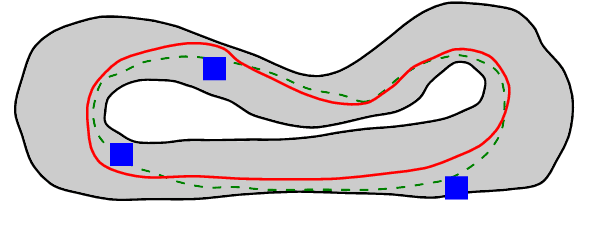
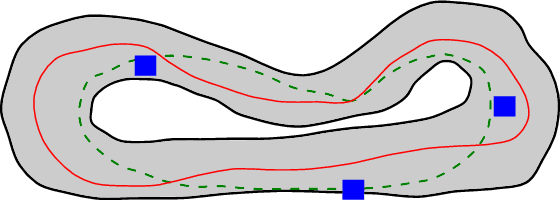
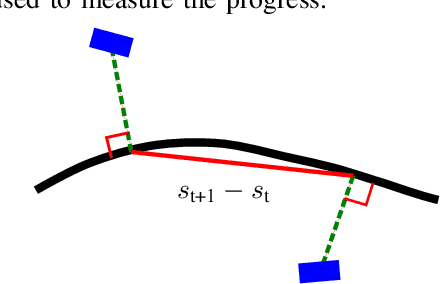
The problem of autonomous navigation is to generate a set of navigation references which when followed move the vehicle from a starting position to and end goal location while avoiding obstacles. Autonomous racing complicates the navigation problem by adding the objective of minimising the time to complete a track. Solutions aiming for a minimum time solution require that the planner is concerned with the optimality of the trajectory according to the vehicle dynamics. Neural networks, trained from experience with reinforcement learning, have shown to be effective local planners which generate navigation references to follow a global plan and avoid obstacles. We address the problem designing a reward signal which can be used to train neural network-based local planners to race in a time-efficient manner and avoid obstacles. The general challenge of reward signal design is to represent a desired behavior in an equation that can be calculated at each time step. The specific challenge of designing a reward signal for autonomous racing is to encode obstacle-free, time optimal racing trajectories in a clear signal We propose several methods of encoding ideal racing behavior based using a combination of the position and velocity of the vehicle and the actions taken by the network. The reward function candidates are expressed as equations and evaluated in the context of F1/10th autonomous racing. The results show that the best reward signal rewards velocity along, and punishes the lateral deviation from a precalculated, optimal reference trajectory.
Cross-Modal Knowledge Transfer via Inter-Modal Translation and Alignment for Affect Recognition
Aug 02, 2021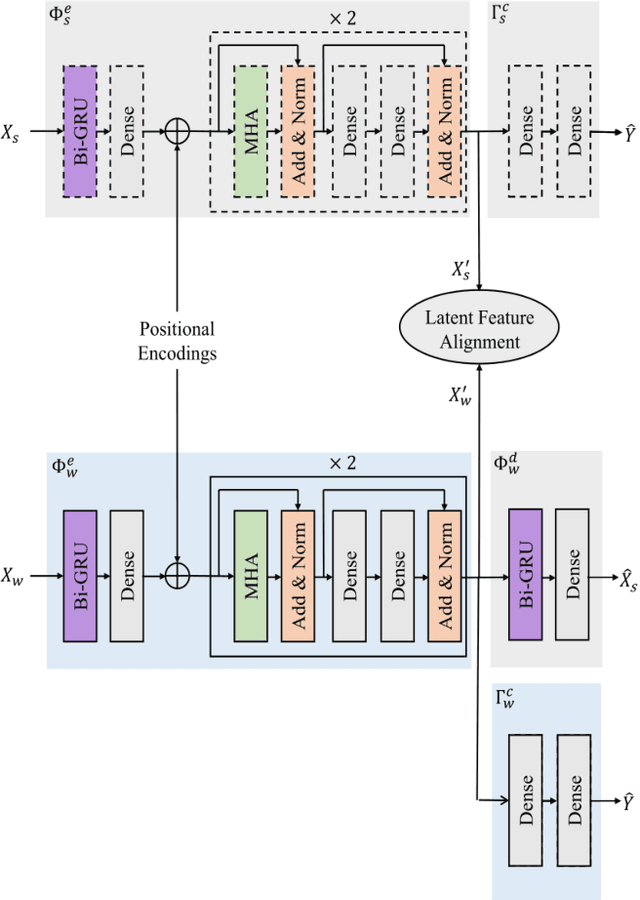
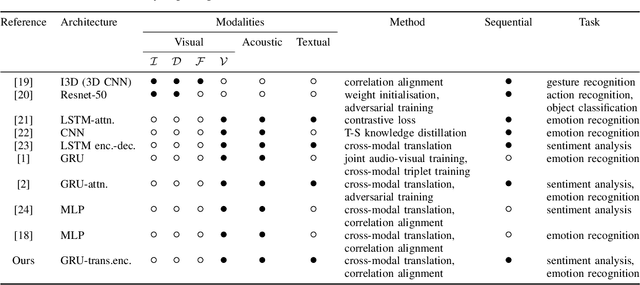
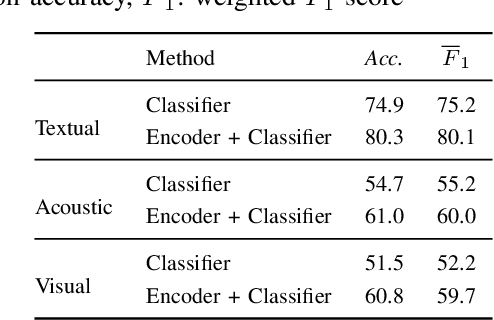
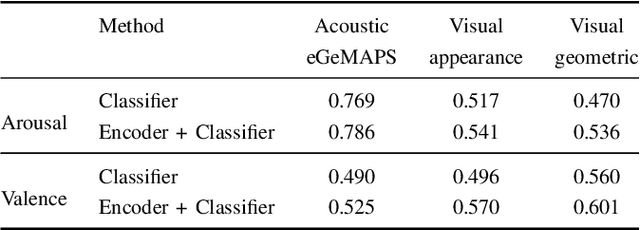
Multi-modal affect recognition models leverage complementary information in different modalities to outperform their uni-modal counterparts. However, due to the unavailability of modality-specific sensors or data, multi-modal models may not be always employable. For this reason, we aim to improve the performance of uni-modal affect recognition models by transferring knowledge from a better-performing (or stronger) modality to a weaker modality during training. Our proposed multi-modal training framework for cross-modal knowledge transfer relies on two main steps. First, an encoder-classifier model creates task-specific representations for the stronger modality. Then, cross-modal translation generates multi-modal intermediate representations, which are also aligned in the latent space with the stronger modality representations. To exploit the contextual information in temporal sequential affect data, we use Bi-GRU and transformer encoder. We validate our approach on two multi-modal affect datasets, namely CMU-MOSI for binary sentiment classification and RECOLA for dimensional emotion regression. The results show that the proposed approach consistently improves the uni-modal test-time performance of the weaker modalities.
PoseDet: Fast Multi-Person Pose Estimation Using Pose Embedding
Jul 22, 2021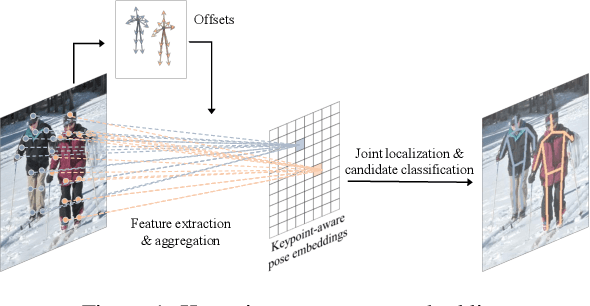
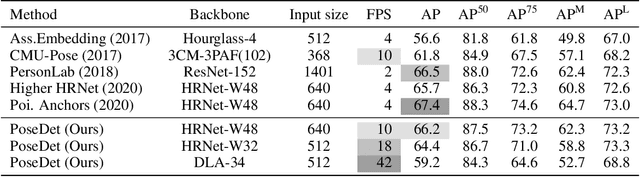
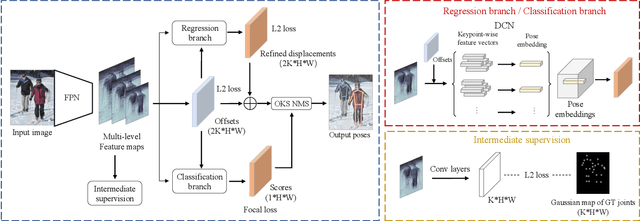
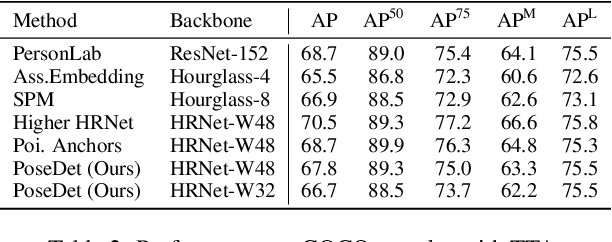
Current methods of multi-person pose estimation typically treat the localization and the association of body joints separately. It is convenient but inefficient, leading to additional computation and a waste of time. This paper, however, presents a novel framework PoseDet (Estimating Pose by Detection) to localize and associate body joints simultaneously at higher inference speed. Moreover, we propose the keypoint-aware pose embedding to represent an object in terms of the locations of its keypoints. The proposed pose embedding contains semantic and geometric information, allowing us to access discriminative and informative features efficiently. It is utilized for candidate classification and body joint localization in PoseDet, leading to robust predictions of various poses. This simple framework achieves an unprecedented speed and a competitive accuracy on the COCO benchmark compared with state-of-the-art methods. Extensive experiments on the CrowdPose benchmark show the robustness in the crowd scenes. Source code is available.
Whittle Index for A Class of Restless Bandits with Imperfect Observations
Aug 09, 2021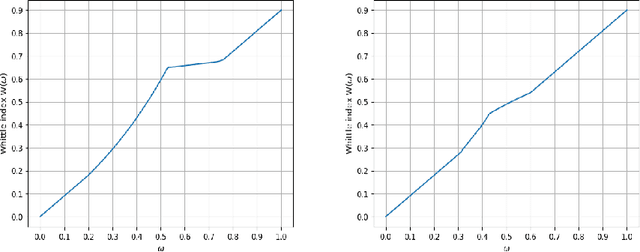
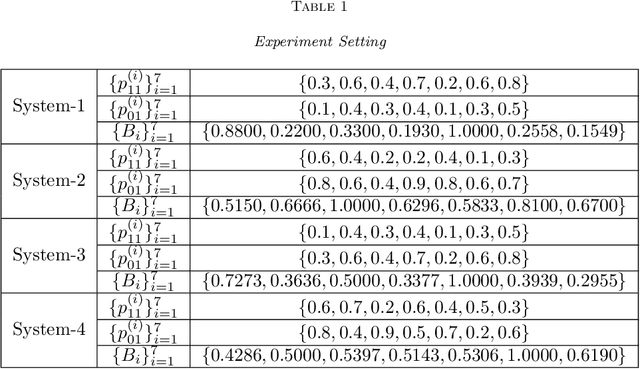
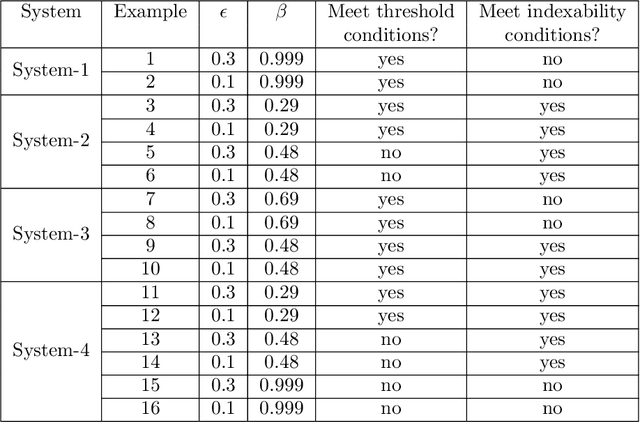
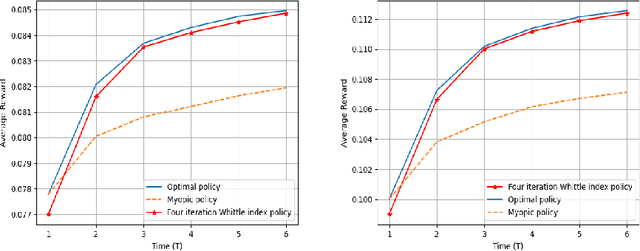
We consider a class of restless bandit problems that finds a broad application area in stochastic optimization, reinforcement learning and operations research. In our model, there are $N$ independent $2$-state Markov processes that may be observed and accessed for accruing rewards. The observation is error-prone, i.e., both false alarm and miss detection may happen. Furthermore, the user can only choose a subset of $M~(M<N)$ processes to observe at each discrete time. If a process in state~$1$ is correctly observed, then it will offer some reward. Due to the partial and imperfect observation model, the system is formulated as a restless multi-armed bandit problem with an information state space of uncountable cardinality. Restless bandit problems with finite state spaces are PSPACE-HARD in general. In this paper, we establish a low-complexity algorithm that achieves a strong performance for this class of restless bandits. Under certain conditions, we theoretically prove the existence (indexability) of Whittle index and its equivalence to our algorithm. When those conditions do not hold, we show by numerical experiments the near-optimal performance of our algorithm in general.
Flip Learning: Erase to Segment
Aug 02, 2021
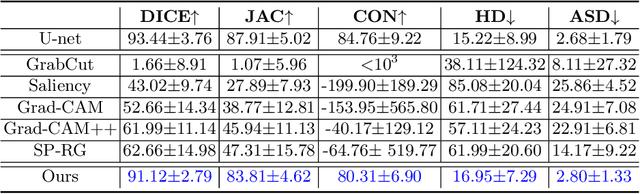
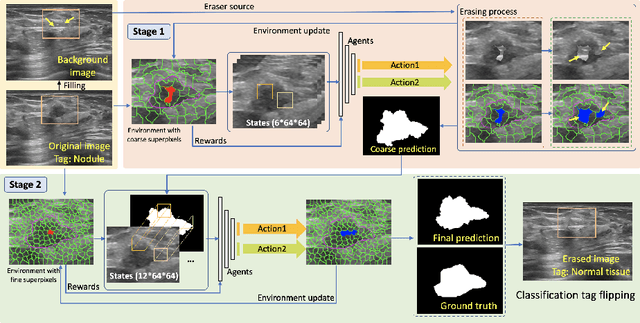
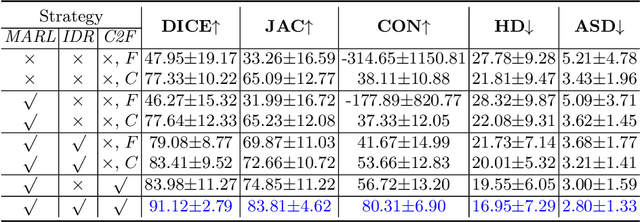
Nodule segmentation from breast ultrasound images is challenging yet essential for the diagnosis. Weakly-supervised segmentation (WSS) can help reduce time-consuming and cumbersome manual annotation. Unlike existing weakly-supervised approaches, in this study, we propose a novel and general WSS framework called Flip Learning, which only needs the box annotation. Specifically, the target in the label box will be erased gradually to flip the classification tag, and the erased region will be considered as the segmentation result finally. Our contribution is three-fold. First, our proposed approach erases on superpixel level using a Multi-agent Reinforcement Learning framework to exploit the prior boundary knowledge and accelerate the learning process. Second, we design two rewards: classification score and intensity distribution reward, to avoid under- and over-segmentation, respectively. Third, we adopt a coarse-to-fine learning strategy to reduce the residual errors and improve the segmentation performance. Extensively validated on a large dataset, our proposed approach achieves competitive performance and shows great potential to narrow the gap between fully-supervised and weakly-supervised learning.
Personalized Federated Learning over non-IID Data for Indoor Localization
Jul 09, 2021
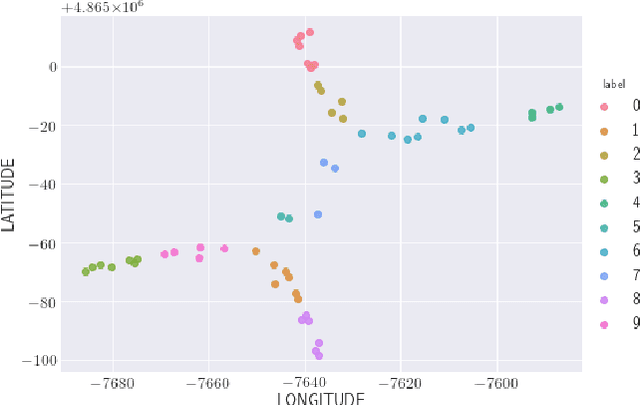
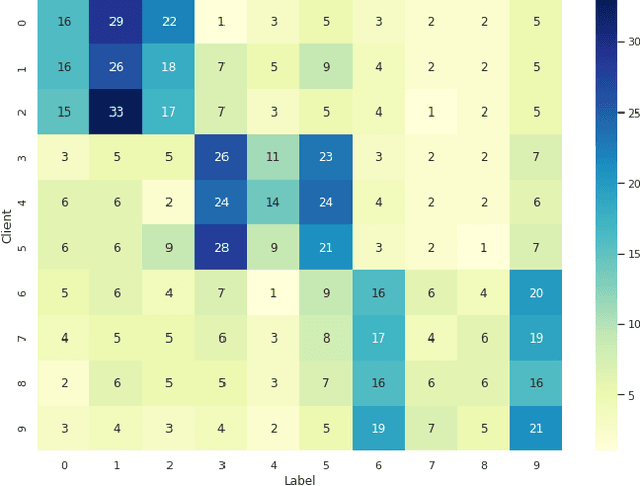
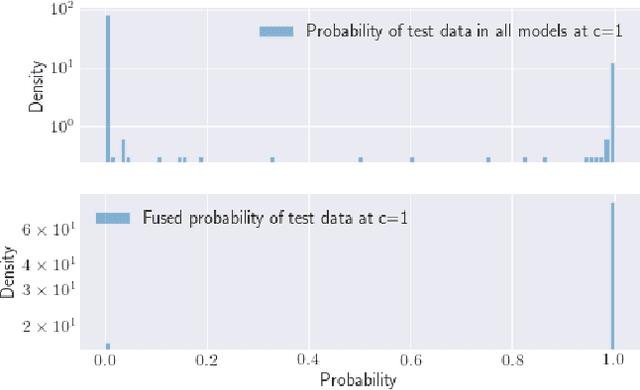
Localization and tracking of objects using data-driven methods is a popular topic due to the complexity in characterizing the physics of wireless channel propagation models. In these modeling approaches, data needs to be gathered to accurately train models, at the same time that user's privacy is maintained. An appealing scheme to cooperatively achieve these goals is known as Federated Learning (FL). A challenge in FL schemes is the presence of non-independent and identically distributed (non-IID) data, caused by unevenly exploration of different areas. In this paper, we consider the use of recent FL schemes to train a set of personalized models that are then optimally fused through Bayesian rules, which makes it appropriate in the context of indoor localization.
V2V Spatiotemporal Interactive Pattern Recognition and Risk Analysis in Lane Changes
May 22, 2021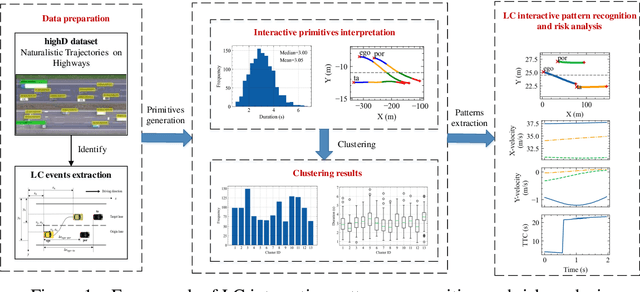
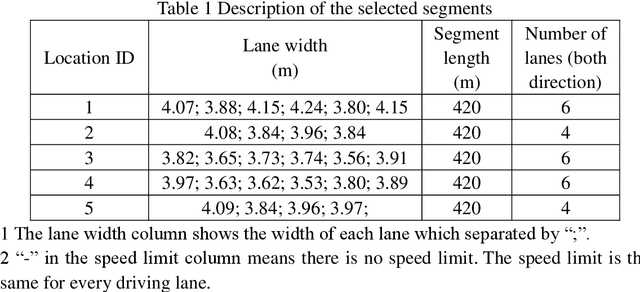
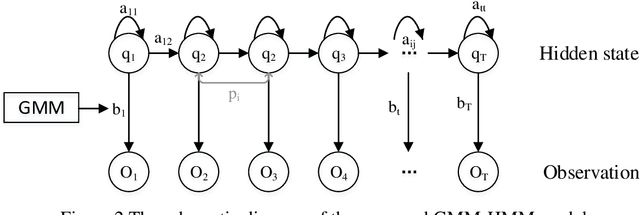
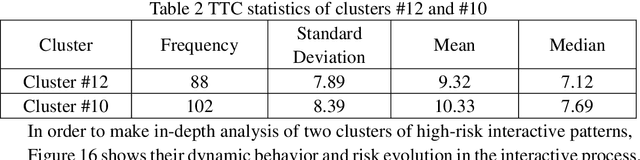
In complex lane change (LC) scenarios, semantic interpretation and safety analysis of dynamic interactive pattern are necessary for autonomous vehicles to make appropriate decisions. This study proposes an unsupervised learning framework that combines primitive-based interactive pattern recognition methods and risk analysis methods. The Hidden Markov Model with the Gaussian mixture model (GMM-HMM) approach is developed to decompose the LC scenarios into primitives. Then the Dynamic Time Warping (DTW) distance based K-means clustering is applied to gather the primitives to 13 types of interactive patterns. Finally, this study considers two types of time-to-collision (TTC) involved in the LC process as indicators to analyze the risk of the interactive patterns and extract high-risk LC interactive patterns. The results obtained from The Highway Drone Dataset (highD) demonstrate that the identified LC interactive patterns contain interpretable semantic information. This study explores the spatiotemporal evolution law and risk formation mechanism of the LC interactive patterns and the findings are useful for comprehensively understanding the latent interactive patterns, improving the rationality and safety of autonomous vehicle's decision-making.
A Split-face Study of Novel Robotic Prototype vs Human Operator in Skin Rejuvenation Using Q-switched Nd:Yag Laser: Accuracy, Efficacy and Safety
Jun 05, 2021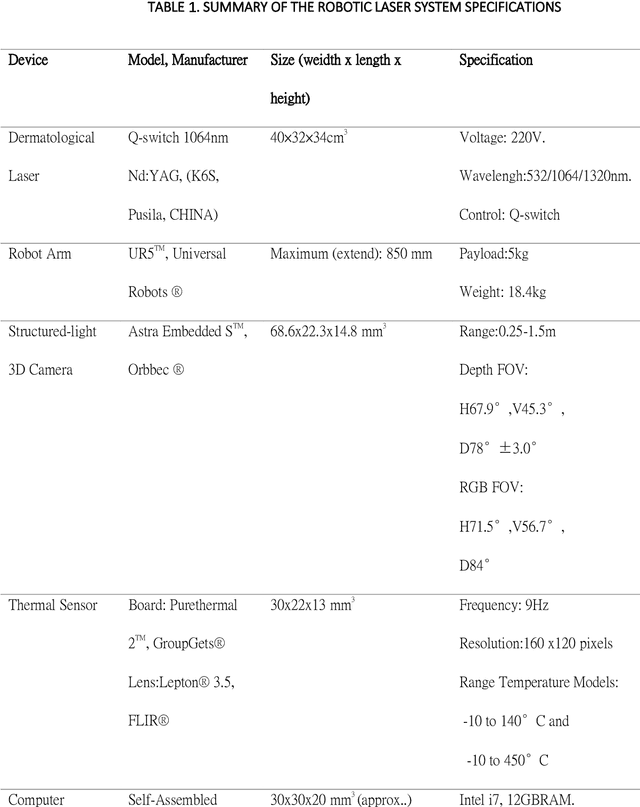
Background: Robotic technologies involved in skin laser are emerging. Objective: To compare the accuracy, efficacy and safety of novel robotic prototype with human operator in laser operation performance for skin photo-rejuvenation. Methods: Seventeen subjects were enrolled in a prospective, comparative split-face trial. Q-switch 1064nm laser conducted by the robotic prototype was provided on the right side of the face and that by the professional practitioner on the left. Each subject underwent a single time, one-pass, non-overlapped treatment on an equal size area of the forehead and cheek. Objective assessments included: treatment duration, laser irradiation shots, laser coverage percentage, VISIA parameters, skin temperature and the VAS pain scale. Results: Average time taken by robotic manipulator was longer than human operator; the average number of irradiation shots of both sides had no significant differences. Laser coverage rate of robotic manipulator (60.2 +-15.1%) was greater than that of human operator (43.6 +-12.9%). The VISIA parameters showed no significant differences between robotic manipulator and human operator. No short or long-term side effects were observed with maximum VAS score of 1 point. Limitations: Only one section of laser treatment was performed. Conclusion: Laser operation by novel robotic prototype is more reliable, stable and accurate than human operation.
Deep MRI Reconstruction with Radial Subsampling
Aug 20, 2021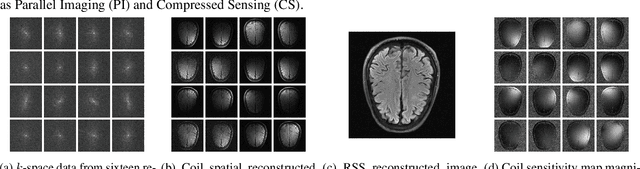
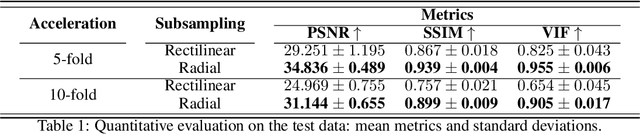
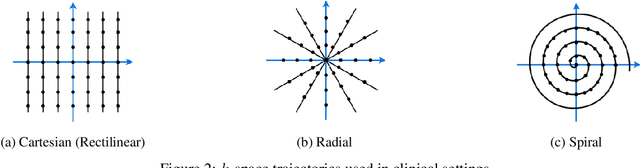

In spite of its extensive adaptation in almost every medical diagnostic and examinatorial application, Magnetic Resonance Imaging (MRI) is still a slow imaging modality which limits its use for dynamic imaging. In recent years, Parallel Imaging (PI) and Compressed Sensing (CS) have been utilised to accelerate the MRI acquisition. In clinical settings, subsampling the k-space measurements during scanning time using Cartesian trajectories, such as rectilinear sampling, is currently the most conventional CS approach applied which, however, is prone to producing aliased reconstructions. With the advent of the involvement of Deep Learning (DL) in accelerating the MRI, reconstructing faithful images from subsampled data became increasingly promising. Retrospectively applying a subsampling mask onto the k-space data is a way of simulating the accelerated acquisition of k-space data in real clinical setting. In this paper we compare and provide a review for the effect of applying either rectilinear or radial retrospective subsampling on the quality of the reconstructions outputted by trained deep neural networks. With the same choice of hyper-parameters, we train and evaluate two distinct Recurrent Inference Machines (RIMs), one for each type of subsampling. The qualitative and quantitative results of our experiments indicate that the model trained on data with radial subsampling attains higher performance and learns to estimate reconstructions with higher fidelity paving the way for other DL approaches to involve radial subsampling.