 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Is it Fake? News Disinformation Detection on South African News Websites
Aug 09, 2021
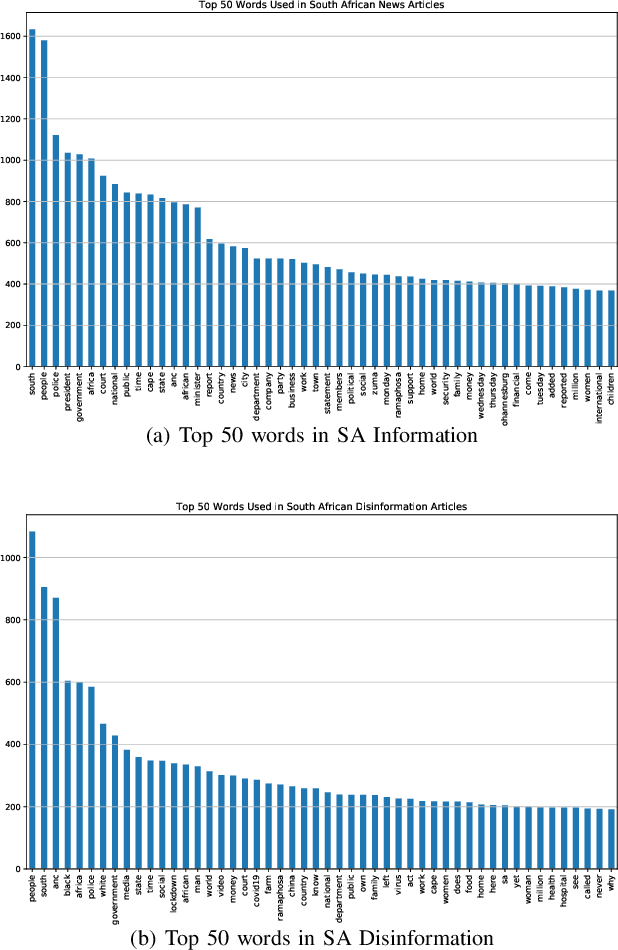

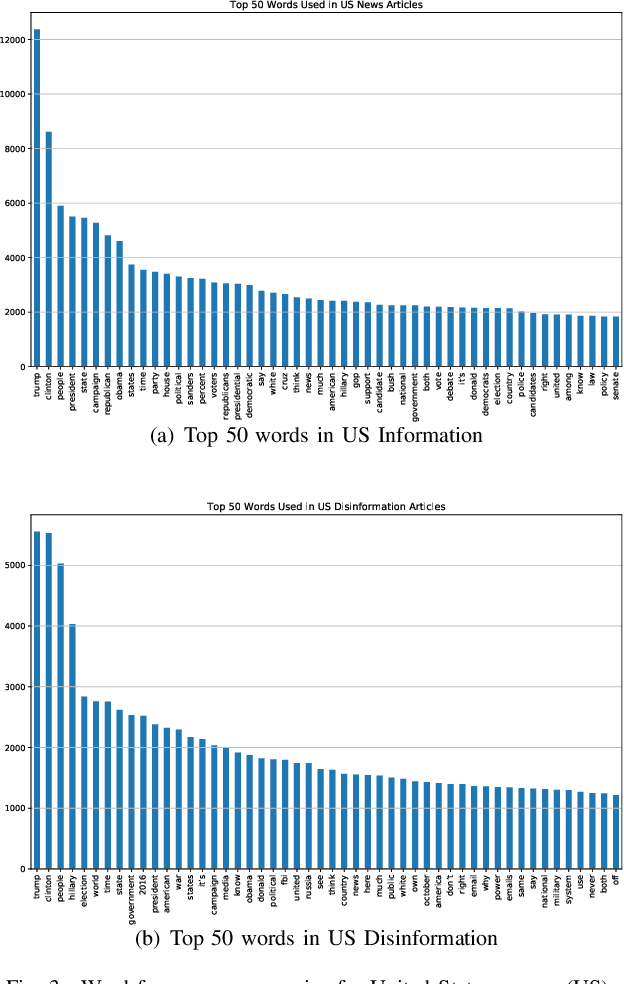

Disinformation through fake news is an ongoing problem in our society and has become easily spread through social media. The most cost and time effective way to filter these large amounts of data is to use a combination of human and technical interventions to identify it. From a technical perspective, Natural Language Processing (NLP) is widely used in detecting fake news. Social media companies use NLP techniques to identify the fake news and warn their users, but fake news may still slip through undetected. It is especially a problem in more localised contexts (outside the United States of America). How do we adjust fake news detection systems to work better for local contexts such as in South Africa. In this work we investigate fake news detection on South African websites. We curate a dataset of South African fake news and then train detection models. We contrast this with using widely available fake news datasets (from mostly USA website). We also explore making the datasets more diverse by combining them and observe the differences in behaviour in writing between nations' fake news using interpretable machine learning.
Deep Metric Learning Model for Imbalanced Fault Diagnosis
Jul 14, 2021
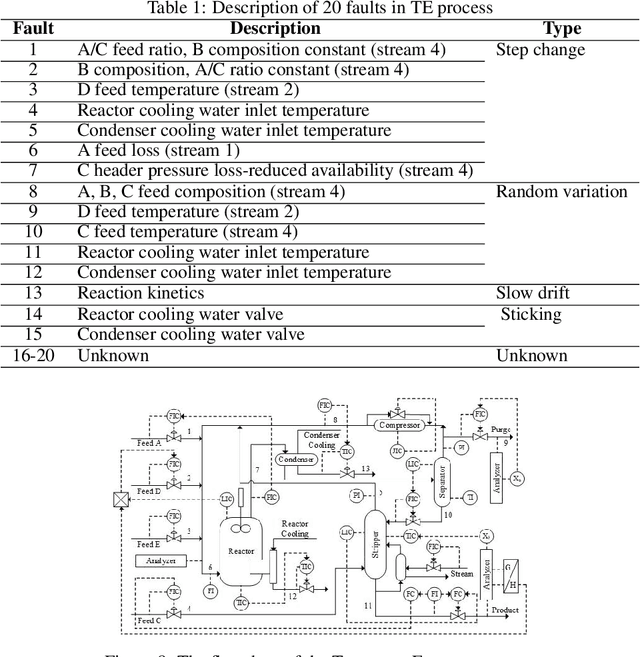
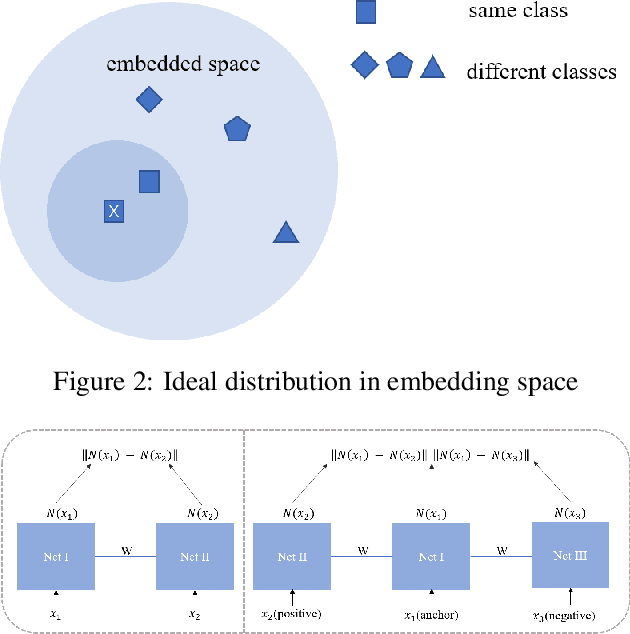

Intelligent diagnosis method based on data-driven and deep learning is an attractive and meaningful field in recent years. However, in practical application scenarios, the imbalance of time-series fault is an urgent problem to be solved. This paper proposes a novel deep metric learning model, where imbalanced fault data and a quadruplet data pair design manner are considered. Based on such data pair, a quadruplet loss function which takes into account the inter-class distance and the intra-class data distribution are proposed. This quadruplet loss pays special attention to imbalanced sample pair. The reasonable combination of quadruplet loss and softmax loss function can reduce the impact of imbalance. Experiment results on two open-source datasets show that the proposed method can effectively and robustly improve the performance of imbalanced fault diagnosis.
Table-to-Text Generation with Effective Hierarchical Encoder on Three Dimensions (Row, Column and Time)
Sep 05, 2019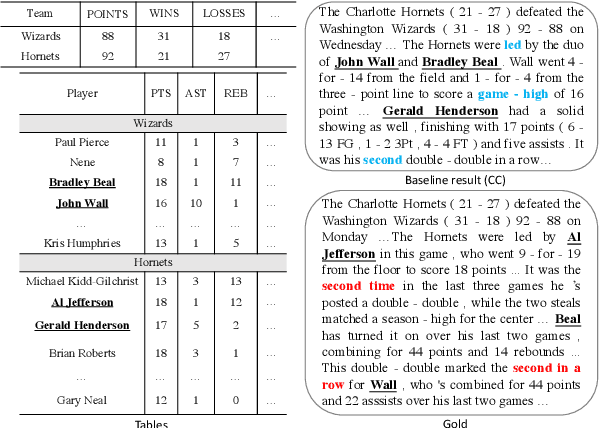
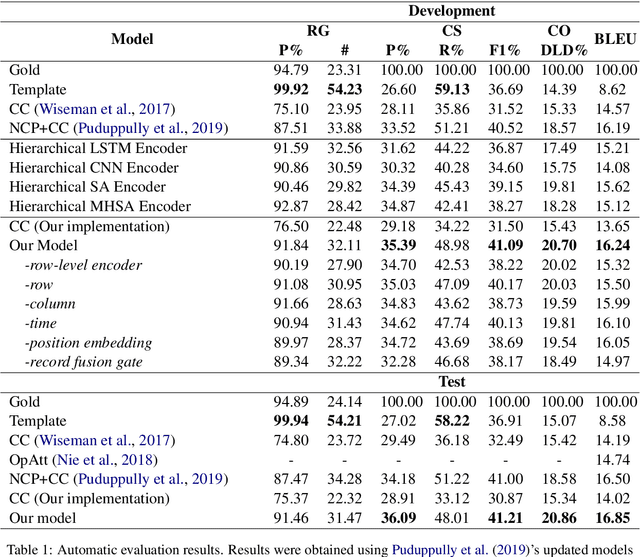
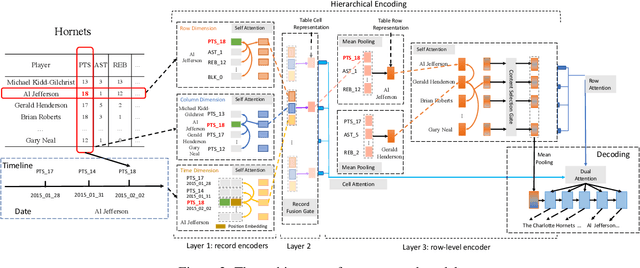
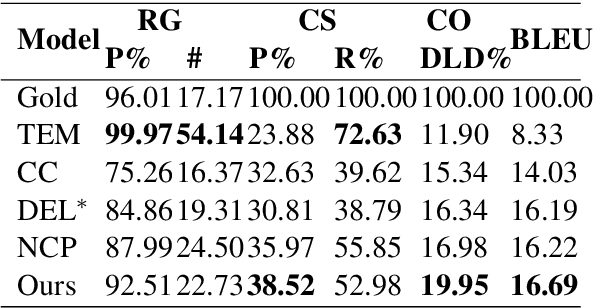
Although Seq2Seq models for table-to-text generation have achieved remarkable progress, modeling table representation in one dimension is inadequate. This is because (1) the table consists of multiple rows and columns, which means that encoding a table should not depend only on one dimensional sequence or set of records and (2) most of the tables are time series data (e.g. NBA game data, stock market data), which means that the description of the current table may be affected by its historical data. To address aforementioned problems, not only do we model each table cell considering other records in the same row, we also enrich table's representation by modeling each table cell in context of other cells in the same column or with historical (time dimension) data respectively. In addition, we develop a table cell fusion gate to combine representations from row, column and time dimension into one dense vector according to the saliency of each dimension's representation. We evaluated our methods on ROTOWIRE, a benchmark dataset of NBA basketball games. Both automatic and human evaluation results demonstrate the effectiveness of our model with improvement of 2.66 in BLEU over the strong baseline and outperformance of state-of-the-art model.
EG-Booster: Explanation-Guided Booster of ML Evasion Attacks
Aug 31, 2021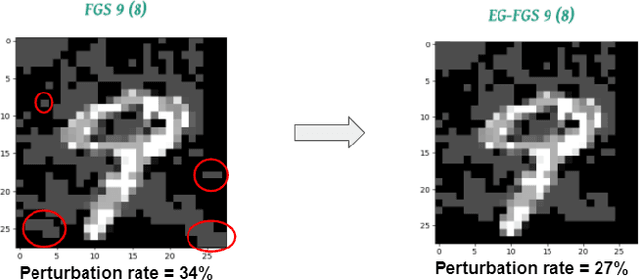
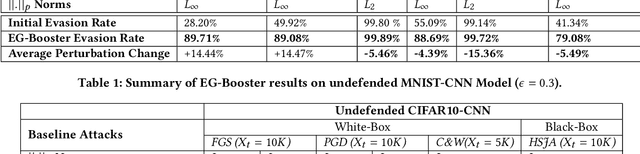
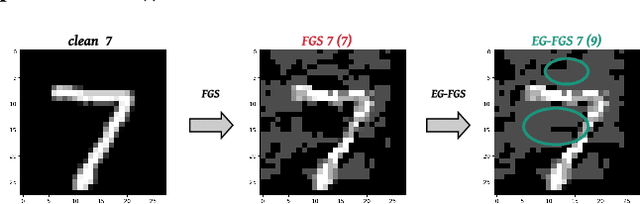

The widespread usage of machine learning (ML) in a myriad of domains has raised questions about its trustworthiness in security-critical environments. Part of the quest for trustworthy ML is robustness evaluation of ML models to test-time adversarial examples. Inline with the trustworthy ML goal, a useful input to potentially aid robustness evaluation is feature-based explanations of model predictions. In this paper, we present a novel approach called EG-Booster that leverages techniques from explainable ML to guide adversarial example crafting for improved robustness evaluation of ML models before deploying them in security-critical settings. The key insight in EG-Booster is the use of feature-based explanations of model predictions to guide adversarial example crafting by adding consequential perturbations likely to result in model evasion and avoiding non-consequential ones unlikely to contribute to evasion. EG-Booster is agnostic to model architecture, threat model, and supports diverse distance metrics used previously in the literature. We evaluate EG-Booster using image classification benchmark datasets, MNIST and CIFAR10. Our findings suggest that EG-Booster significantly improves evasion rate of state-of-the-art attacks while performing less number of perturbations. Through extensive experiments that covers four white-box and three black-box attacks, we demonstrate the effectiveness of EG-Booster against two undefended neural networks trained on MNIST and CIFAR10, and another adversarially-trained ResNet model trained on CIFAR10. Furthermore, we introduce a stability assessment metric and evaluate the reliability of our explanation-based approach by observing the similarity between the model's classification outputs across multiple runs of EG-Booster.
Automatic digital twin data model generation of building energy systems from piping and instrumentation diagrams
Aug 31, 2021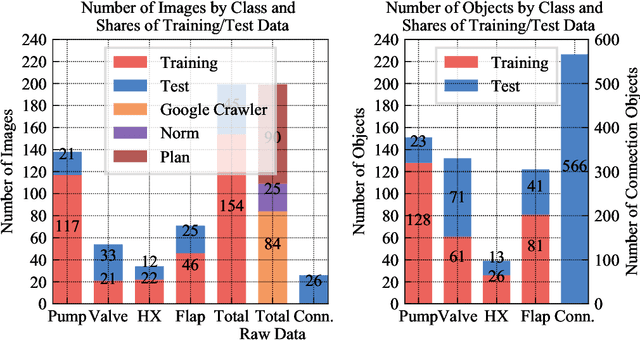
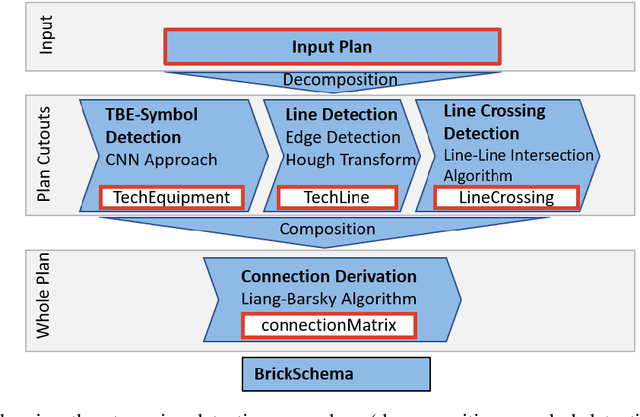
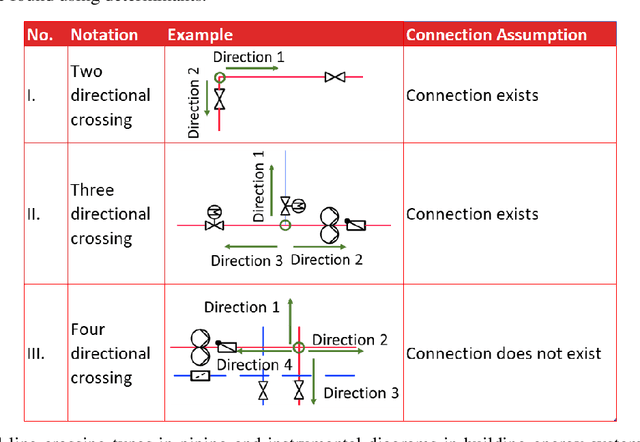
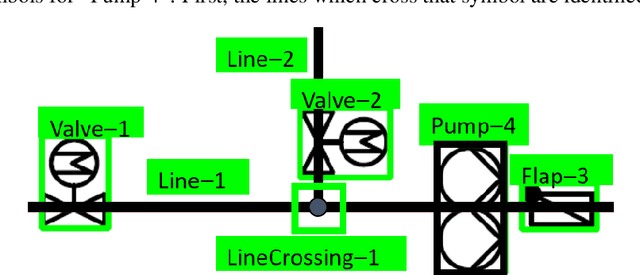
Buildings directly and indirectly emit a large share of current CO2 emissions. There is a high potential for CO2 savings through modern control methods in building automation systems (BAS) like model predictive control (MPC). For a proper control, MPC needs mathematical models to predict the future behavior of the controlled system. For this purpose, digital twins of the building can be used. However, with current methods in existing buildings, a digital twin set up is usually labor-intensive. Especially connecting the different components of the technical system to an overall digital twin of the building is time-consuming. Piping and instrument diagrams (P&ID) can provide the needed information, but it is necessary to extract the information and provide it in a standardized format to process it further. In this work, we present an approach to recognize symbols and connections of P&ID from buildings in a completely automated way. There are various standards for graphical representation of symbols in P&ID of building energy systems. Therefore, we use different data sources and standards to generate a holistic training data set. We apply algorithms for symbol recognition, line recognition and derivation of connections to the data sets. Furthermore, the result is exported to a format that provides semantics of building energy systems. The symbol recognition, line recognition and connection recognition show good results with an average precision of 93.7%, which can be used in further processes like control generation, (distributed) model predictive control or fault detection. Nevertheless, the approach needs further research.
Understanding and Accelerating Neural Architecture Search with Training-Free and Theory-Grounded Metrics
Aug 26, 2021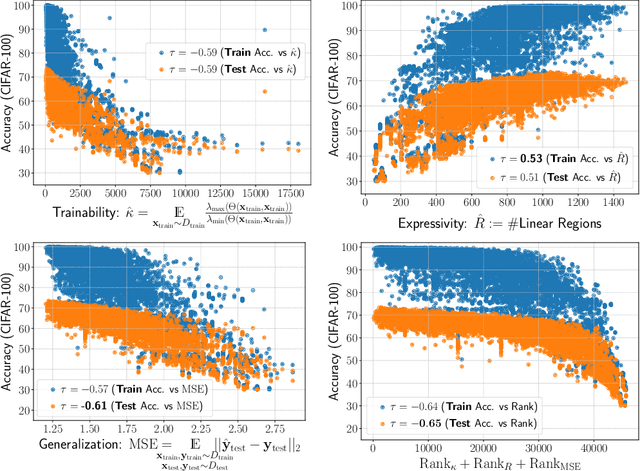

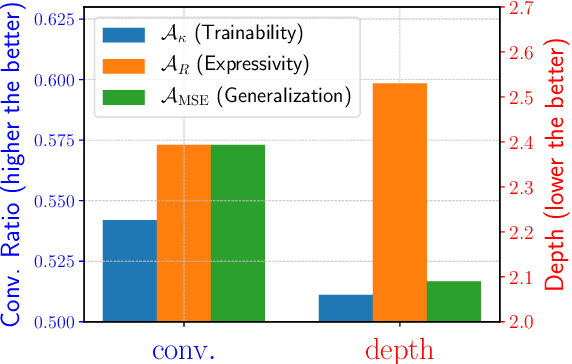
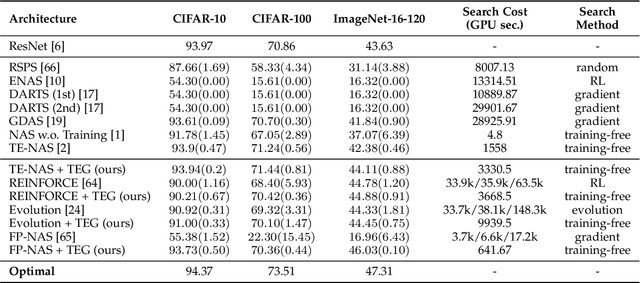
This work targets designing a principled and unified training-free framework for Neural Architecture Search (NAS), with high performance, low cost, and in-depth interpretation. NAS has been explosively studied to automate the discovery of top-performer neural networks, but suffers from heavy resource consumption and often incurs search bias due to truncated training or approximations. Recent NAS works start to explore indicators that can predict a network's performance without training. However, they either leveraged limited properties of deep networks, or the benefits of their training-free indicators are not applied to more extensive search methods. By rigorous correlation analysis, we present a unified framework to understand and accelerate NAS, by disentangling "TEG" characteristics of searched networks - Trainability, Expressivity, Generalization - all assessed in a training-free manner. The TEG indicators could be scaled up and integrated with various NAS search methods, including both supernet and single-path approaches. Extensive studies validate the effective and efficient guidance from our TEG-NAS framework, leading to both improved search accuracy and over 2.3x reduction in search time cost. Moreover, we visualize search trajectories on three landscapes of "TEG" characteristics, observing that while a good local minimum is easier to find on NAS-Bench-201 given its simple topology, balancing "TEG" characteristics is much harder on the DARTS search space due to its complex landscape geometry. Our code is available at https://github.com/VITA-Group/TEGNAS.
Real-Time Well Log Prediction From Drilling Data Using Deep Learning
Jan 28, 2020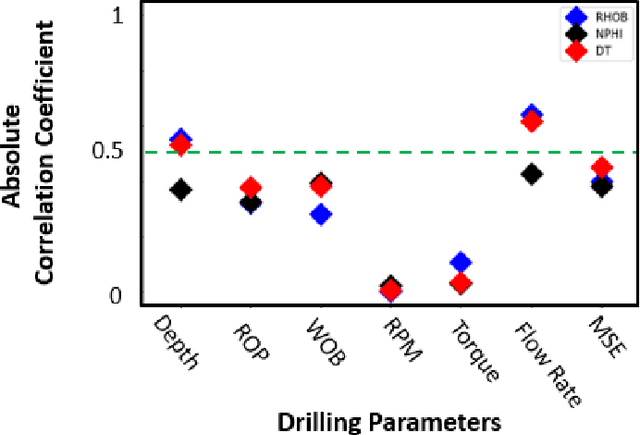
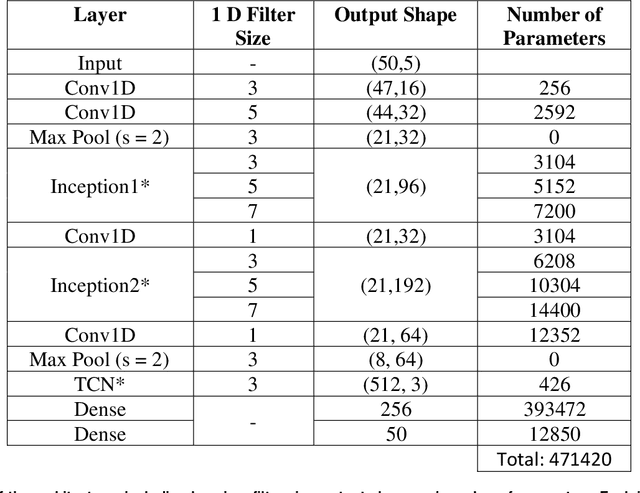
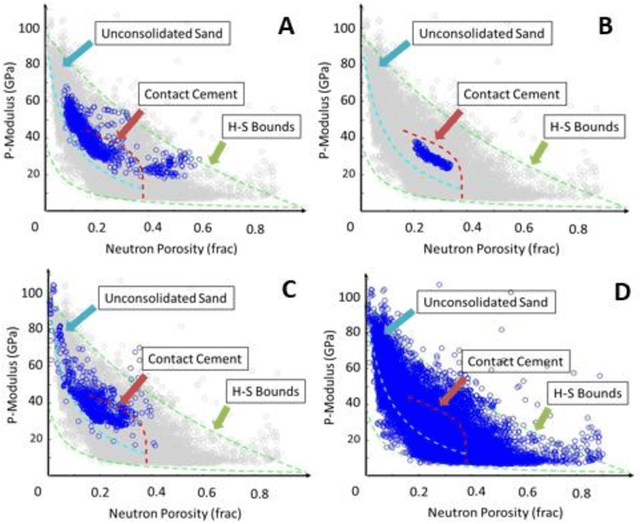
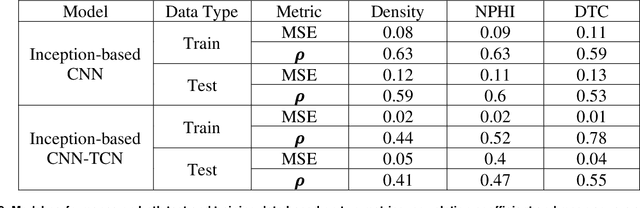
The objective is to study the feasibility of predicting subsurface rock properties in wells from real-time drilling data. Geophysical logs, namely, density, porosity and sonic logs are of paramount importance for subsurface resource estimation and exploitation. These wireline petro-physical measurements are selectively deployed as they are expensive to acquire; meanwhile, drilling information is recorded in every drilled well. Hence a predictive tool for wireline log prediction from drilling data can help management make decisions about data acquisition, especially for delineation and production wells. This problem is non-linear with strong ineractions between drilling parameters; hence the potential for deep learning to address this problem is explored. We present a workflow for data augmentation and feature engineering using Distance-based Global Sensitivity Analysis. We propose an Inception-based Convolutional Neural Network combined with a Temporal Convolutional Network as the deep learning model. The model is designed to learn both low and high frequency content of the data. 12 wells from the Equinor dataset for the Volve field in the North Sea are used for learning. The model predictions not only capture trends but are also physically consistent across density, porosity, and sonic logs. On the test data, the mean square error reaches a low value of 0.04 but the correlation coefficient plateaus around 0.6. The model is able however to differentiate between different types of rocks such as cemented sandstone, unconsolidated sands, and shale.
DRINet: A Dual-Representation Iterative Learning Network for Point Cloud Segmentation
Aug 09, 2021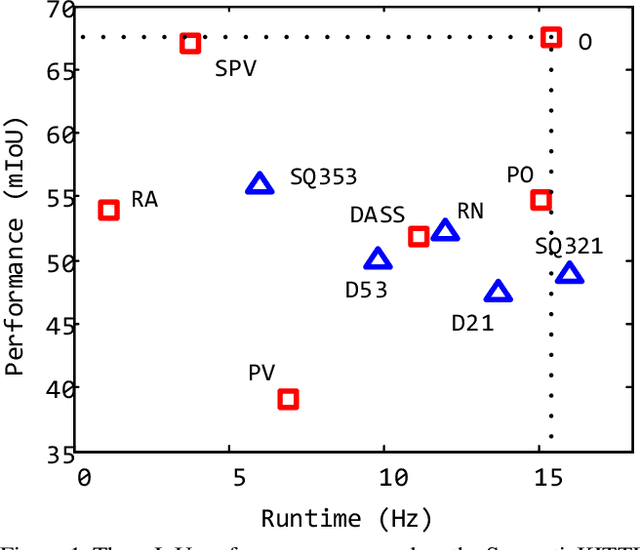
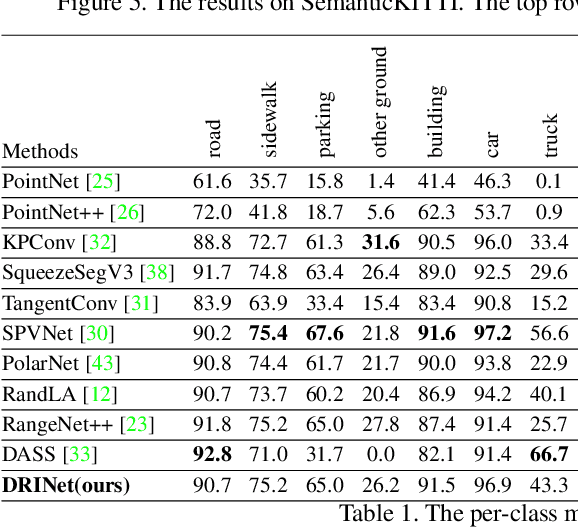
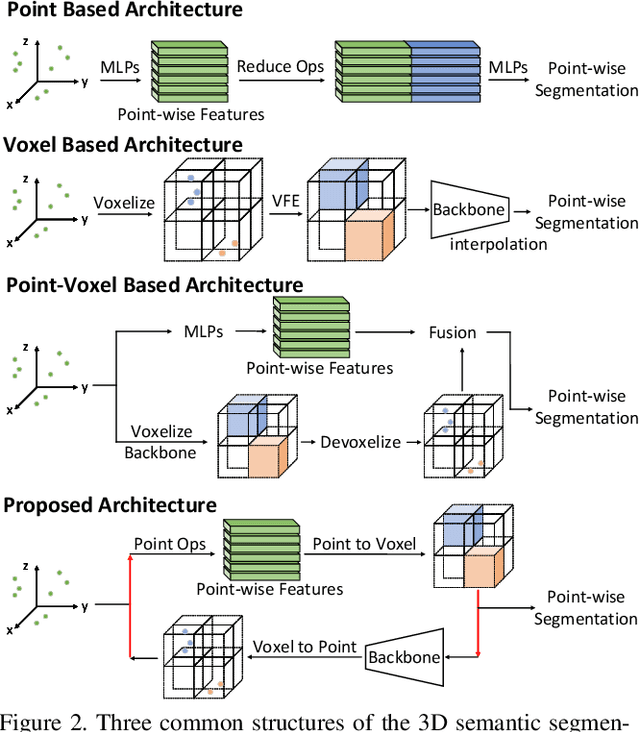

We present a novel and flexible architecture for point cloud segmentation with dual-representation iterative learning. In point cloud processing, different representations have their own pros and cons. Thus, finding suitable ways to represent point cloud data structure while keeping its own internal physical property such as permutation and scale-invariant is a fundamental problem. Therefore, we propose our work, DRINet, which serves as the basic network structure for dual-representation learning with great flexibility at feature transferring and less computation cost, especially for large-scale point clouds. DRINet mainly consists of two modules called Sparse Point-Voxel Feature Extraction and Sparse Voxel-Point Feature Extraction. By utilizing these two modules iteratively, features can be propagated between two different representations. We further propose a novel multi-scale pooling layer for pointwise locality learning to improve context information propagation. Our network achieves state-of-the-art results for point cloud classification and segmentation tasks on several datasets while maintaining high runtime efficiency. For large-scale outdoor scenarios, our method outperforms state-of-the-art methods with a real-time inference speed of 62ms per frame.
Avaya Conversational Intelligence: A Real-Time System for Spoken Language Understanding in Human-Human Call Center Conversations
Sep 02, 2019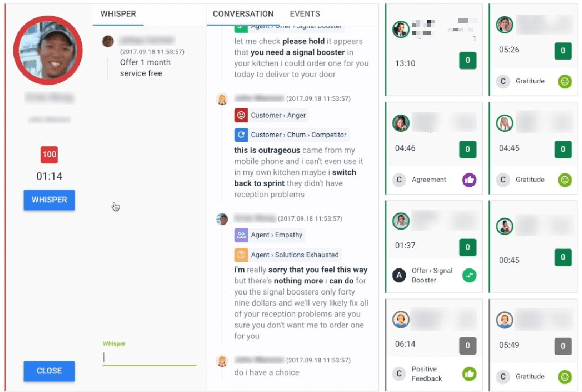
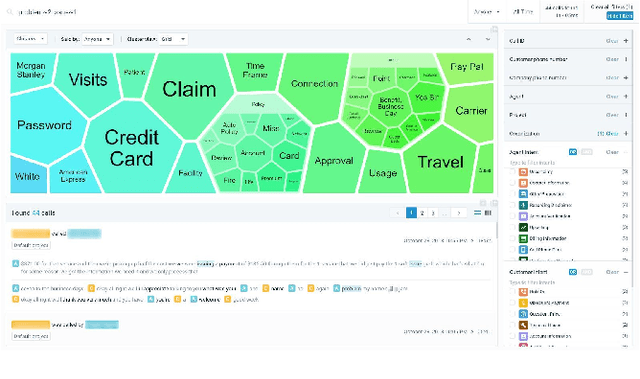
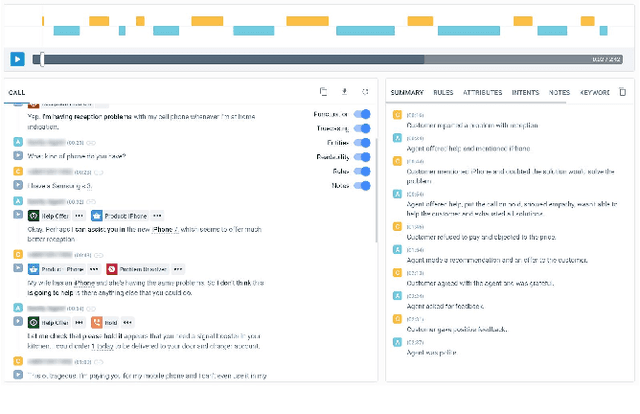
Avaya Conversational Intelligence(ACI) is an end-to-end, cloud-based solution for real-time Spoken Language Understanding for call centers. It combines large vocabulary, real-time speech recognition, transcript refinement, and entity and intent recognition in order to convert live audio into a rich, actionable stream of structured events. These events can be further leveraged with a business rules engine, thus serving as a foundation for real-time supervision and assistance applications. After the ingestion, calls are enriched with unsupervised keyword extraction, abstractive summarization, and business-defined attributes, enabling offline use cases, such as business intelligence, topic mining, full-text search, quality assurance, and agent training. ACI comes with a pretrained, configurable library of hundreds of intents and a robust intent training environment that allows for efficient, cost-effective creation and customization of customer-specific intents.
STAR-IOS Aided NOMA Networks: Channel Model Approximation and Performance Analysis
Jul 04, 2021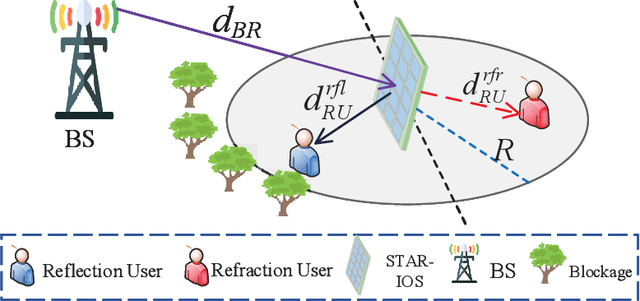
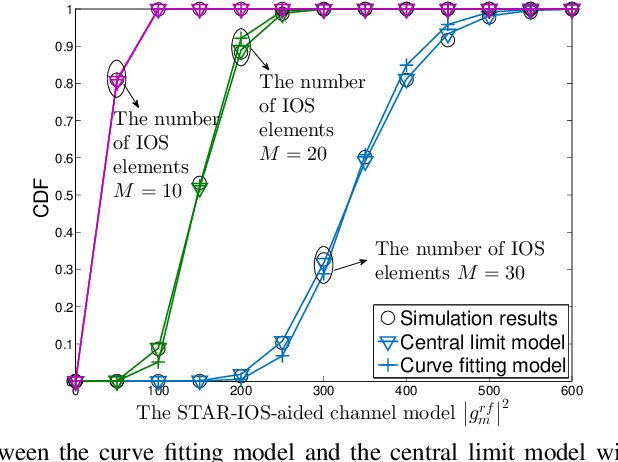
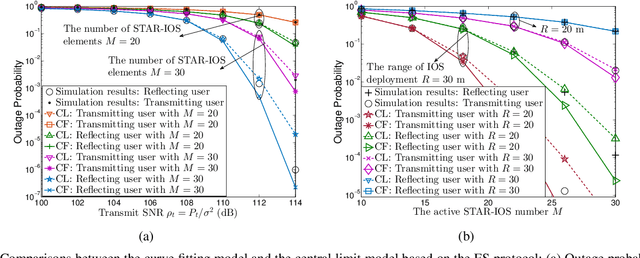
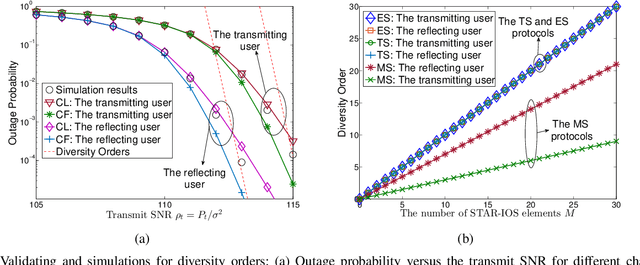
Simultaneous transmitting and reflecting intelligent omini-surfaces (STAR-IOSs) are able to achieve full coverage "smart radio environments". By splitting the energy or altering the active number of STAR-IOS elements, STAR-IOSs provide high flexibility of successive interference cancellation (SIC) orders for non-orthogonal multiple access (NOMA) systems. Based on the aforementioned advantages, this paper investigates a STAR-IOS-aided downlink NOMA network with randomly deployed users. We first propose three tractable channel models for different application scenarios, namely the central limit model, the curve fitting model, and the M-fold convolution model. More specifically, the central limit model fits the scenarios with large-size STAR-IOSs while the curve fitting model is extended to evaluate multi-cell networks. However, these two models cannot obtain accurate diversity orders. Hence, we figure out the M-fold convolution model to derive accurate diversity orders. We consider three protocols for STAR-IOSs, namely, the energy splitting (ES) protocol, the time switching (TS) protocol, and the mode switching (MS) protocol. Based on the ES protocol, we derive analytical outage probability expressions for the paired NOMA users by the central limit model and the curve fitting model. Based on three STAR-IOS protocols, we derive the diversity gains of NOMA users by the M-fold convolution model. The analytical results reveal that the diversity gain of NOMA users is equal to the active number of STAR-IOS elements. Numerical results indicate that 1) in high signal-to-noise ratio regions, the central limit model performs as an upper bound, while a lower bound is obtained by the curve fitting model; 2) the TS protocol has the best performance but requesting more time blocks than other protocols; 3) the ES protocol outperforms the MS protocol as the ES protocol has higher diversity gains.