 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Technology Report : Robotic Localization and Navigation System for Visible Light Positioning and SLAM
Apr 30, 2021
Visible light positioning (VLP) technology is a promising technique as it can provide high accuracy positioning based on the existing lighting infrastructure. However, existing approaches often require dense lighting distributions. Additionally, due to complicated indoor environments, it is still challenging to develop a robust VLP. In this work, we proposed loosely-coupled multi-sensor fusion method based on VLP and Simultaneous Localization and Mapping (SLAM), with light detection and ranging (LiDAR), odometry, and rolling shutter camera. Our method can provide accurate and robust robotics localization and navigation in LED-shortage or even outage situations. The efficacy of the proposed scheme is verified by extensive real-time experiment 1 . The results show that our proposed scheme can provide an average accuracy of 2 cm and the average computational time in low-cost embedded platforms is around 50 ms.
Exploiting a Joint Embedding Space for Generalized Zero-Shot Semantic Segmentation
Aug 14, 2021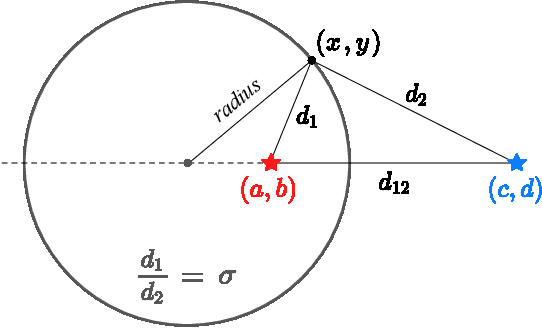


We address the problem of generalized zero-shot semantic segmentation (GZS3) predicting pixel-wise semantic labels for seen and unseen classes. Most GZS3 methods adopt a generative approach that synthesizes visual features of unseen classes from corresponding semantic ones (e.g., word2vec) to train novel classifiers for both seen and unseen classes. Although generative methods show decent performance, they have two limitations: (1) the visual features are biased towards seen classes; (2) the classifier should be retrained whenever novel unseen classes appear. We propose a discriminative approach to address these limitations in a unified framework. To this end, we leverage visual and semantic encoders to learn a joint embedding space, where the semantic encoder transforms semantic features to semantic prototypes that act as centers for visual features of corresponding classes. Specifically, we introduce boundary-aware regression (BAR) and semantic consistency (SC) losses to learn discriminative features. Our approach to exploiting the joint embedding space, together with BAR and SC terms, alleviates the seen bias problem. At test time, we avoid the retraining process by exploiting semantic prototypes as a nearest-neighbor (NN) classifier. To further alleviate the bias problem, we also propose an inference technique, dubbed Apollonius calibration (AC), that modulates the decision boundary of the NN classifier to the Apollonius circle adaptively. Experimental results demonstrate the effectiveness of our framework, achieving a new state of the art on standard benchmarks.
GenRadar: Self-supervised Probabilistic Camera Synthesis based on Radar Frequencies
Jul 19, 2021
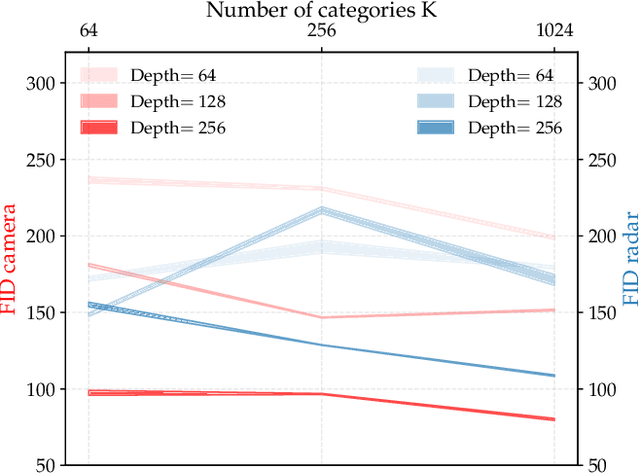
Autonomous systems require a continuous and dependable environment perception for navigation and decision-making, which is best achieved by combining different sensor types. Radar continues to function robustly in compromised circumstances in which cameras become impaired, guaranteeing a steady inflow of information. Yet, camera images provide a more intuitive and readily applicable impression of the world. This work combines the complementary strengths of both sensor types in a unique self-learning fusion approach for a probabilistic scene reconstruction in adverse surrounding conditions. After reducing the memory requirements of both high-dimensional measurements through a decoupled stochastic self-supervised compression technique, the proposed algorithm exploits similarities and establishes correspondences between both domains at different feature levels during training. Then, at inference time, relying exclusively on radio frequencies, the model successively predicts camera constituents in an autoregressive and self-contained process. These discrete tokens are finally transformed back into an instructive view of the respective surrounding, allowing to visually perceive potential dangers for important tasks downstream.
A Deep Learning Based Automatic Defect Analysis Framework for In-situ TEM Ion Irradiations
Aug 19, 2021

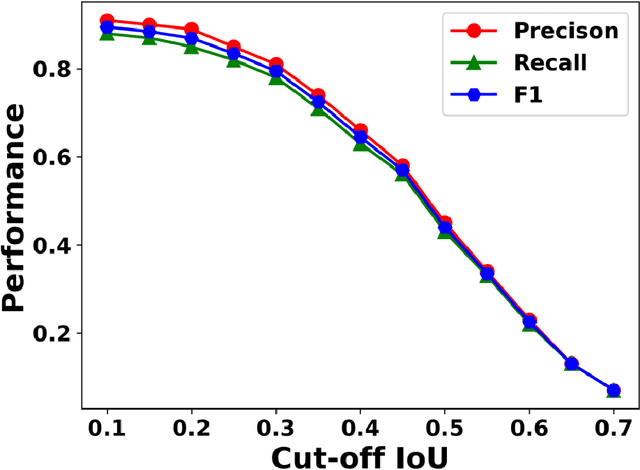

Videos captured using Transmission Electron Microscopy (TEM) can encode details regarding the morphological and temporal evolution of a material by taking snapshots of the microstructure sequentially. However, manual analysis of such video is tedious, error-prone, unreliable, and prohibitively time-consuming if one wishes to analyze a significant fraction of frames for even videos of modest length. In this work, we developed an automated TEM video analysis system for microstructural features based on the advanced object detection model called YOLO and tested the system on an in-situ ion irradiation TEM video of dislocation loops formed in a FeCrAl alloy. The system provides analysis of features observed in TEM including both static and dynamic properties using the YOLO-based defect detection module coupled to a geometry analysis module and a dynamic tracking module. Results show that the system can achieve human comparable performance with an F1 score of 0.89 for fast, consistent, and scalable frame-level defect analysis. This result is obtained on a real but exceptionally clean and stable data set and more challenging data sets may not achieve this performance. The dynamic tracking also enabled evaluation of individual defect evolution like per defect growth rate at a fidelity never before achieved using common human analysis methods. Our work shows that automatically detecting and tracking interesting microstructures and properties contained in TEM videos is viable and opens new doors for evaluating materials dynamics.
Anomaly Detection Based on Multiple-Hypothesis Autoencoder
Jul 07, 2021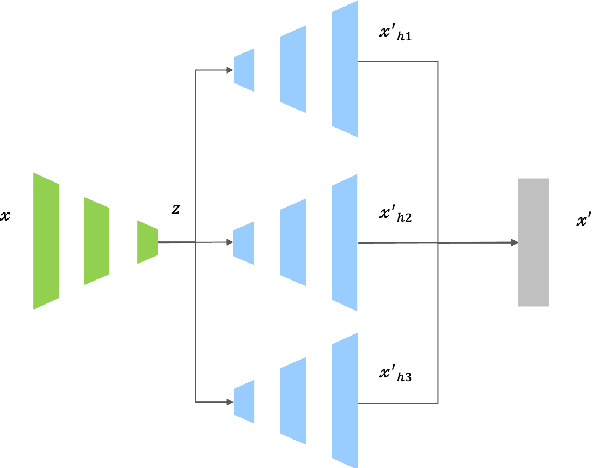
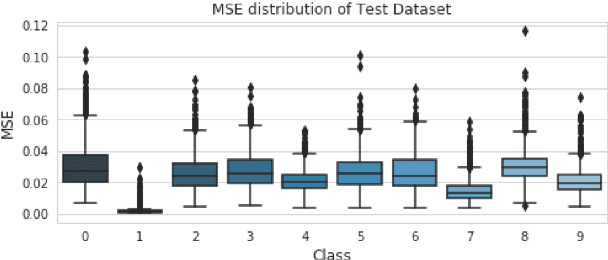

Recently Autoencoder(AE) based models are widely used in the field of anomaly detection. A model trained with normal data generates a larger restoration error for abnormal data. Whether or not abnormal data is determined by observing the restoration error. It takes a lot of cost and time to obtain abnormal data in the industrial field. Therefore the model trains only normal data and detects abnormal data in the inference phase. However, the restoration area for the input data of AE is limited in the latent space. To solve this problem, we propose Multiple-hypothesis Autoencoder(MH-AE) model composed of several decoders. MH-AE model increases the restoration area through contention between decoders. The proposed method shows that the anomaly detection performance is improved compared to the traditional AE for various input datasets.
Disentangling and Vectorization: A 3D Visual Perception Approach for Autonomous Driving Based on Surround-View Fisheye Cameras
Jul 19, 2021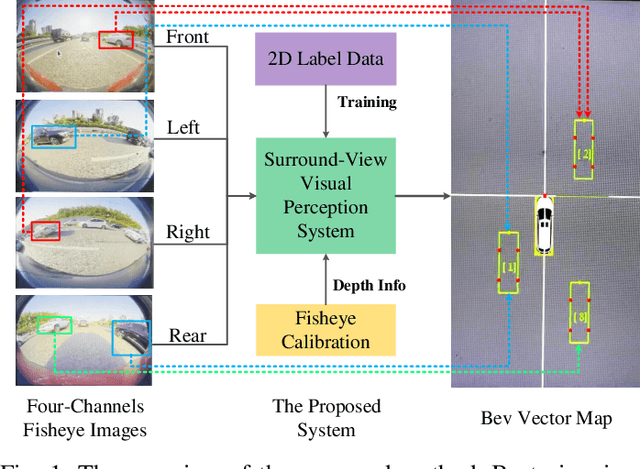

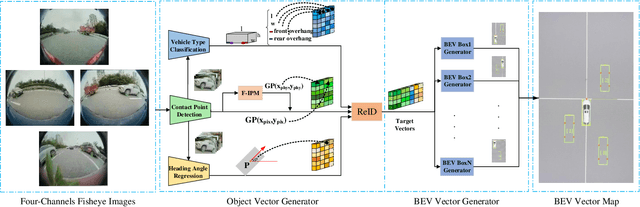
The 3D visual perception for vehicles with the surround-view fisheye camera system is a critical and challenging task for low-cost urban autonomous driving. While existing monocular 3D object detection methods perform not well enough on the fisheye images for mass production, partly due to the lack of 3D datasets of such images. In this paper, we manage to overcome and avoid the difficulty of acquiring the large scale of accurate 3D labeled truth data, by breaking down the 3D object detection task into some sub-tasks, such as vehicle's contact point detection, type classification, re-identification and unit assembling, etc. Particularly, we propose the concept of Multidimensional Vector to include the utilizable information generated in different dimensions and stages, instead of the descriptive approach for the bird's eye view (BEV) or a cube of eight points. The experiments of real fisheye images demonstrate that our solution achieves state-of-the-art accuracy while being real-time in practice.
Agile wide-field imaging with selective high resolution
Jun 11, 2021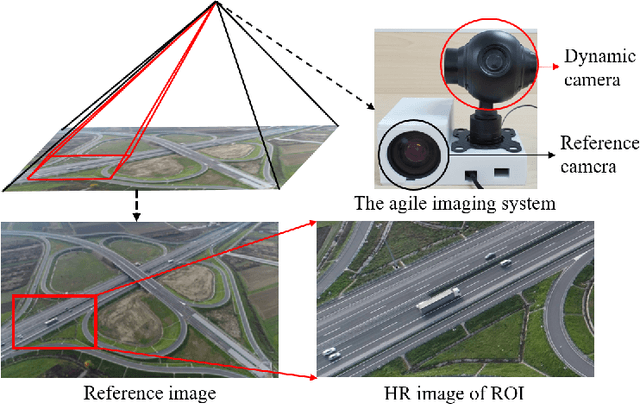
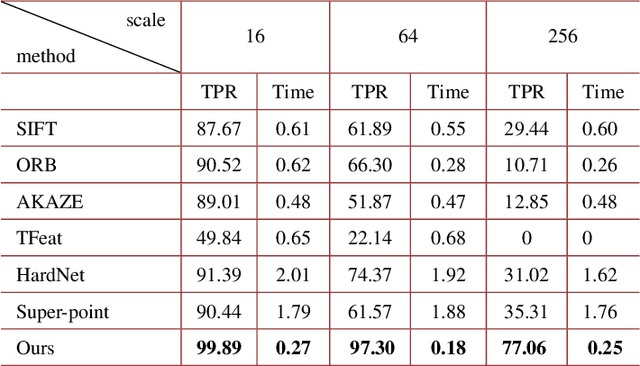
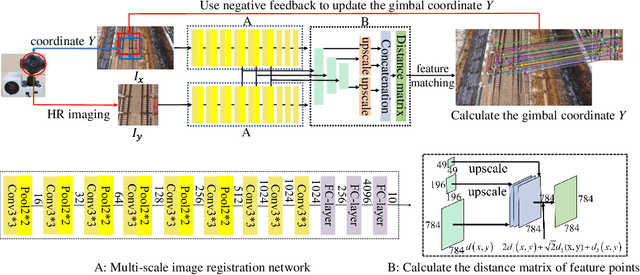
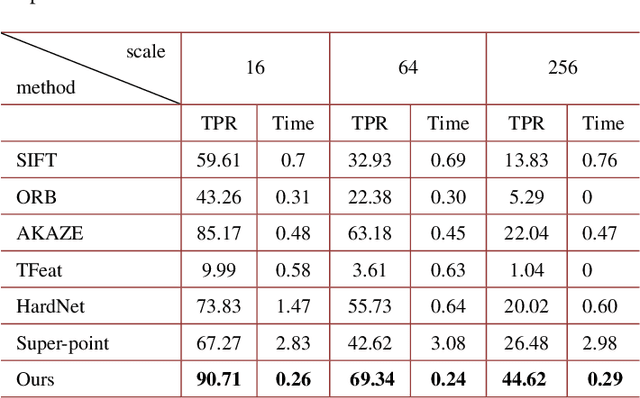
Wide-field and high-resolution (HR) imaging is essential for various applications such as aviation reconnaissance, topographic mapping and safety monitoring. The existing techniques require a large-scale detector array to capture HR images of the whole field, resulting in high complexity and heavy cost. In this work, we report an agile wide-field imaging framework with selective high resolution that requires only two detectors. It builds on the statistical sparsity prior of natural scenes that the important targets locate only at small regions of interests (ROI), instead of the whole field. Under this assumption, we use a short-focal camera to image wide field with a certain low resolution, and use a long-focal camera to acquire the HR images of ROI. To automatically locate ROI in the wide field in real time, we propose an efficient deep-learning based multiscale registration method that is robust and blind to the large setting differences (focal, white balance, etc) between the two cameras. Using the registered location, the long-focal camera mounted on a gimbal enables real-time tracking of the ROI for continuous HR imaging. We demonstrated the novel imaging framework by building a proof-of-concept setup with only 1181 gram weight, and assembled it on an unmanned aerial vehicle for air-to-ground monitoring. Experiments show that the setup maintains 120$^{\circ}$ wide field-of-view (FOV) with selective 0.45$mrad$ instantaneous FOV.
Foundations of Sequence-to-Sequence Modeling for Time Series
May 09, 2018
The availability of large amounts of time series data, paired with the performance of deep-learning algorithms on a broad class of problems, has recently led to significant interest in the use of sequence-to-sequence models for time series forecasting. We provide the first theoretical analysis of this time series forecasting framework. We include a comparison of sequence-to-sequence modeling to classical time series models, and as such our theory can serve as a quantitative guide for practitioners choosing between different modeling methodologies.
Virtual Reality based Digital Twin System for remote laboratories and online practical learning
Jun 17, 2021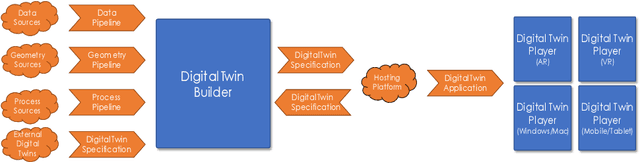

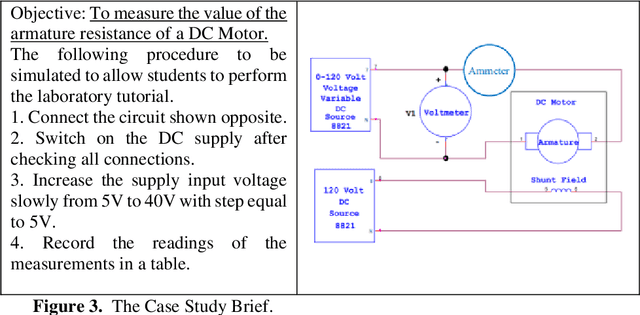
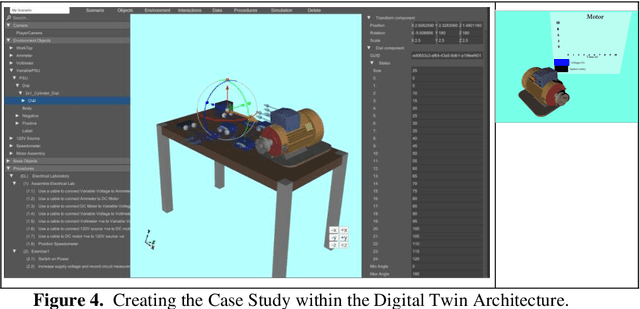
There is a need for remote learning and virtual learning applications such as virtual reality (VR) and tablet-based solutions which the current pandemic has demonstrated. Creating complex learning scenarios by developers is highly time-consuming and can take over a year. There is a need to provide a simple method to enable lecturers to create their own content for their laboratory tutorials. Research is currently being undertaken into developing generic models to enable the semi-automatic creation of a virtual learning application. A case study describing the creation of a virtual learning application for an electrical laboratory tutorial is presented.
Parallel Quasi-concave set optimization: A new frontier that scales without needing submodularity
Aug 19, 2021
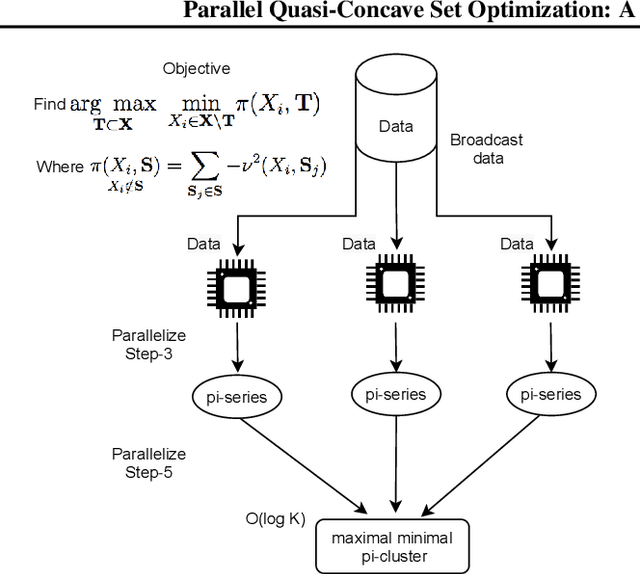
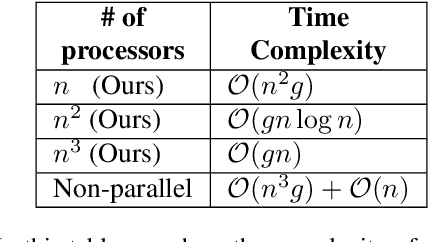
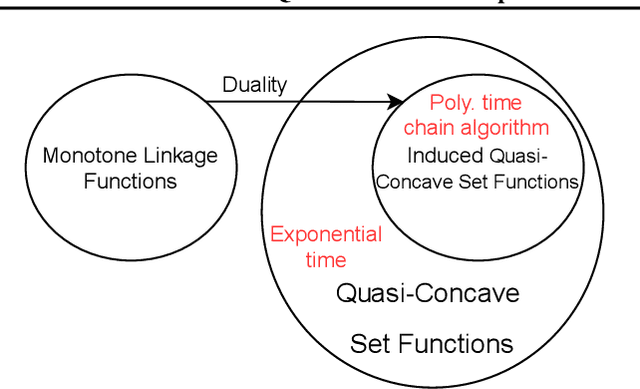
Classes of set functions along with a choice of ground set are a bedrock to determine and develop corresponding variants of greedy algorithms to obtain efficient solutions for combinatorial optimization problems. The class of approximate constrained submodular optimization has seen huge advances at the intersection of good computational efficiency, versatility and approximation guarantees while exact solutions for unconstrained submodular optimization are NP-hard. What is an alternative to situations when submodularity does not hold? Can efficient and globally exact solutions be obtained? We introduce one such new frontier: The class of quasi-concave set functions induced as a dual class to monotone linkage functions. We provide a parallel algorithm with a time complexity over $n$ processors of $\mathcal{O}(n^2g) +\mathcal{O}(\log{\log{n}})$ where $n$ is the cardinality of the ground set and $g$ is the complexity to compute the monotone linkage function that induces a corresponding quasi-concave set function via a duality. The complexity reduces to $\mathcal{O}(gn\log(n))$ on $n^2$ processors and to $\mathcal{O}(gn)$ on $n^3$ processors. Our algorithm provides a globally optimal solution to a maxi-min problem as opposed to submodular optimization which is approximate. We show a potential for widespread applications via an example of diverse feature subset selection with exact global maxi-min guarantees upon showing that a statistical dependency measure called distance correlation can be used to induce a quasi-concave set function.