 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Vector Detection Network: An Application Study on Robots Reading Analog Meters in the Wild
May 30, 2021


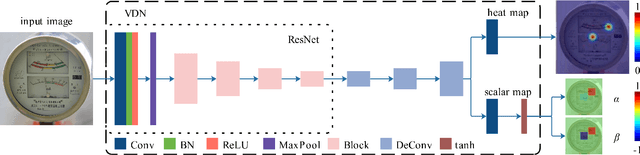

Analog meters equipped with one or multiple pointers are wildly utilized to monitor vital devices' status in industrial sites for safety concerns. Reading these legacy meters {\bi autonomously} remains an open problem since estimating pointer origin and direction under imaging damping factors imposed in the wild could be challenging. Nevertheless, high accuracy, flexibility, and real-time performance are demanded. In this work, we propose the Vector Detection Network (VDN) to detect analog meters' pointers given their images, eliminating the barriers for autonomously reading such meters using intelligent agents like robots. We tackled the pointer as a two-dimensional vector, whose initial point coincides with the tip, and the direction is along tail-to-tip. The network estimates a confidence map, wherein the peak pixels are treated as vectors' initial points, along with a two-layer scalar map, whose pixel values at each peak form the scalar components in the directions of the coordinate axes. We established the Pointer-10K dataset composing of real-world analog meter images to evaluate our approach due to no similar dataset is available for now. Experiments on the dataset demonstrated that our methods generalize well to various meters, robust to harsh imaging factors, and run in real-time.
Optimal Scheduling of Isolated Microgrids Using Automated Reinforcement Learning-based Multi-period Forecasting
Aug 15, 2021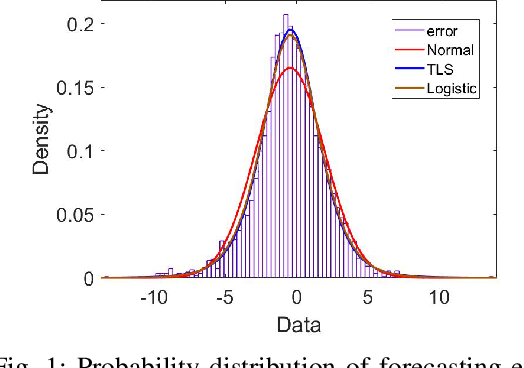
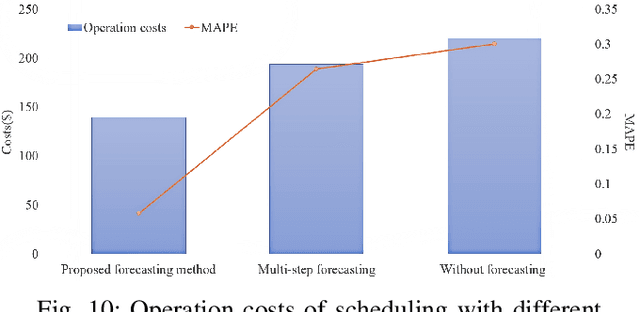
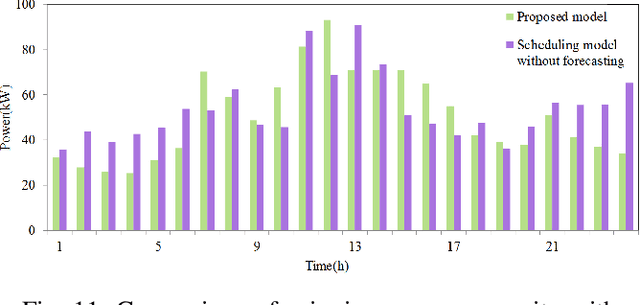
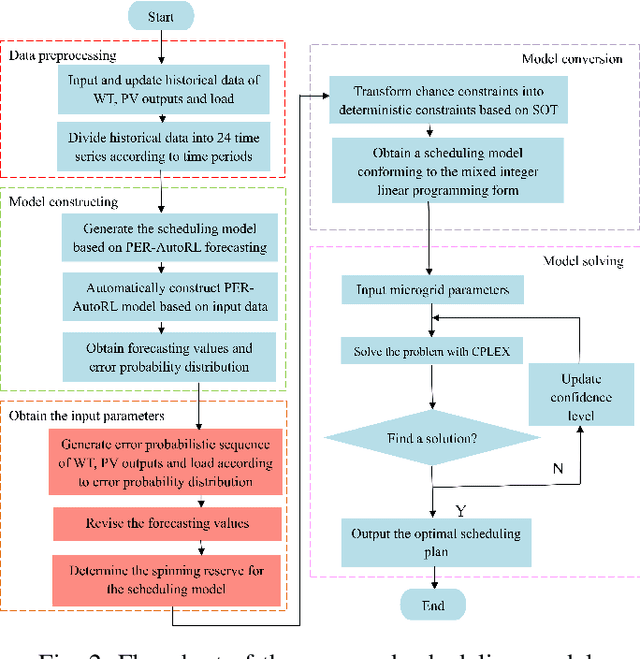
In order to reduce the negative impact of the uncertainty of load and renewable energies outputs on microgrid operation, an optimal scheduling model is proposed for isolated microgrids by using automated reinforcement learning-based multi-period forecasting of renewable power generations and loads. Firstly, a prioritized experience replay automated reinforcement learning (PER-AutoRL) is designed to simplify the deployment of deep reinforcement learning (DRL)-based forecasting model in a customized manner, the single-step multi-period forecasting method based on PER-AutoRL is proposed for the first time to address the error accumulation issue suffered by existing multi-step forecasting methods, then the prediction values obtained by the proposed forecasting method are revised via the error distribution to improve the prediction accuracy; secondly, a scheduling model considering demand response is constructed to minimize the total microgrid operating costs, where the revised forecasting values are used as the dispatch basis, and a spinning reserve chance constraint is set according to the error distribution; finally, by transforming the original scheduling model into a readily solvable mixed integer linear programming via the sequence operation theory (SOT), the transformed model is solved by using CPLEX solver. The simulation results show that compared with the traditional scheduling model without forecasting, this approach manages to significantly reduce the system operating costs by improving the prediction accuracy.
Automated Real-time Anomaly Detection in Human Trajectories using Sequence to Sequence Networks
Jul 15, 2019


Detection of anomalous trajectories is an important problem with potential applications to various domains, such as video surveillance, risk assessment, vessel monitoring and high-energy physics. Modeling the distribution of trajectories with statistical approaches has been a challenging task due to the fact that such time series are usually non stationary and highly dimensional. However, modern machine learning techniques provide robust approaches for data-driven modeling and critical information extraction. In this paper, we propose a Sequence to Sequence architecture for real-time detection of anomalies in human trajectories, in the context of risk-based security. Our detection scheme is tested on a synthetic dataset of diverse and realistic trajectories generated by the ISL iCrowd simulator. The experimental results indicate that our scheme accurately detects motion patterns that deviate from normal behaviors and is promising for future real-world applications.
Neural Calibration for Scalable Beamforming in FDD Massive MIMO with Implicit Channel Estimation
Aug 03, 2021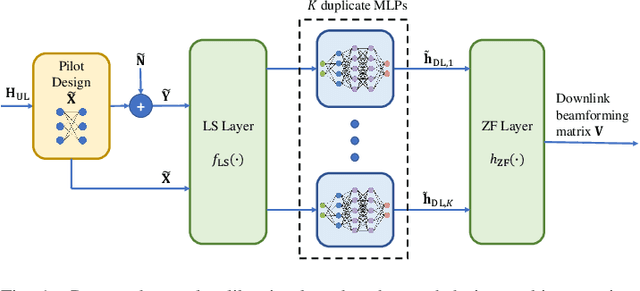
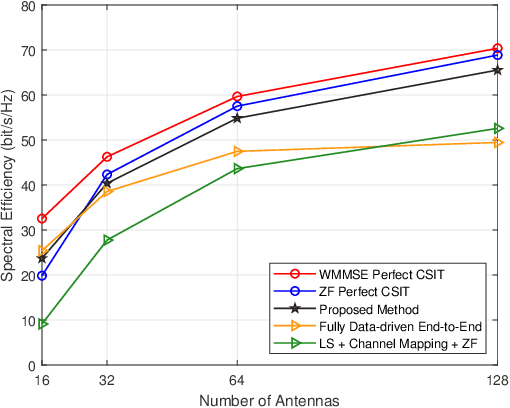
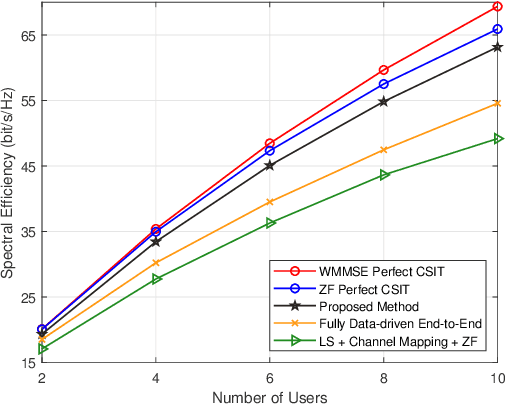
Channel estimation and beamforming play critical roles in frequency-division duplexing (FDD) massive multiple-input multiple-output (MIMO) systems. However, these two modules have been treated as two stand-alone components, which makes it difficult to achieve a global system optimality. In this paper, we propose a deep learning-based approach that directly optimizes the beamformers at the base station according to the received uplink pilots, thereby, bypassing the explicit channel estimation. Different from the existing fully data-driven approach where all the modules are replaced by deep neural networks (DNNs), a neural calibration method is proposed to improve the scalability of the end-to-end design. In particular, the backbone of conventional time-efficient algorithms, i.e., the least-squares (LS) channel estimator and the zero-forcing (ZF) beamformer, is preserved and DNNs are leveraged to calibrate their inputs for better performance. The permutation equivariance property of the formulated resource allocation problem is then identified to design a low-complexity neural network architecture. Simulation results will show the superiority of the proposed neural calibration method over benchmark schemes in terms of both the spectral efficiency and scalability in large-scale wireless networks.
FL-MISR: Fast Large-Scale Multi-Image Super-Resolution for Computed Tomography Based on Multi-GPU Acceleration
Aug 09, 2021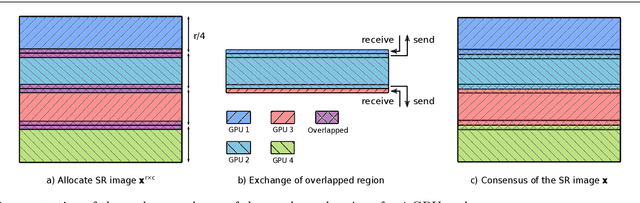

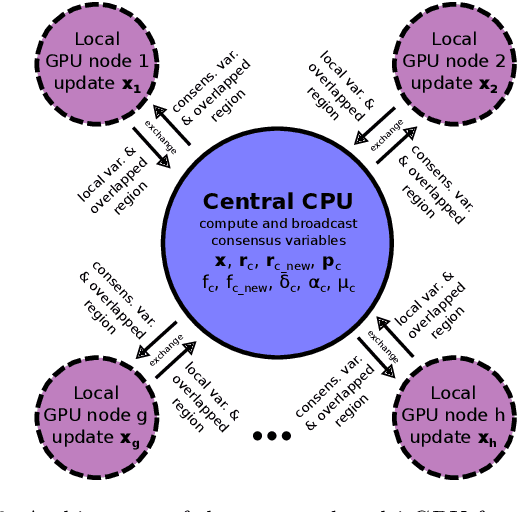

Multi-image super-resolution (MISR) usually outperforms single-image super-resolution (SISR) under a proper inter-image alignment by explicitly exploiting the inter-image correlation. However, the large computational demand encumbers the deployment of MISR methods in practice. In this work, we propose a distributed optimization framework based on data parallelism for fast large-scale MISR which supports multi- GPU acceleration, named FL-MISR. Inter-GPU communication for the exchange of local variables and over-lapped regions is enabled to impose a consensus convergence of the distributed task allocated to each GPU node. We have seamlessly integrated FL-MISR into the computed tomography (CT) imaging system by super-resolving multiple projections of the same view acquired by subpixel detector shift. The SR reconstruction is performed on the fly during the CT acquisition such that no additional computation time is introduced. We evaluated FL-MISR quantitatively and qualitatively on multiple objects including aluminium cylindrical phantoms, QRM bar pattern phantoms, and concrete joints. Experiments show that FL-MISR can effectively improve the spatial resolution of CT systems in modulation transfer function (MTF) and visual perception. Besides, comparing to a multi-core CPU implementation, FL-MISR achieves a more than 50x speedup on an off-the-shelf 4-GPU system.
Sliding Spectrum Decomposition for Diversified Recommendation
Jul 12, 2021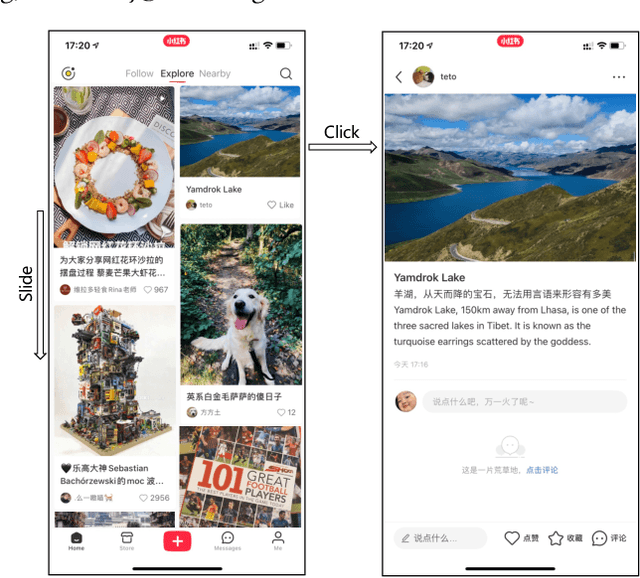
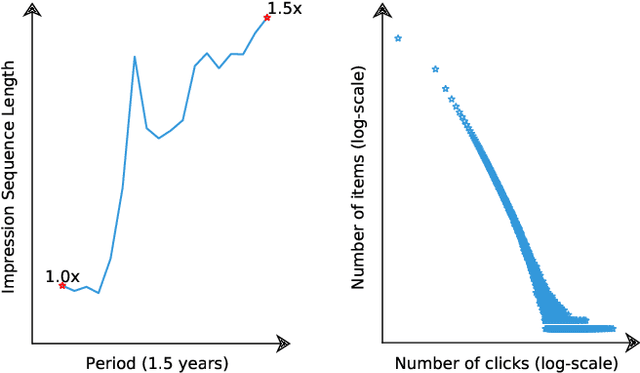
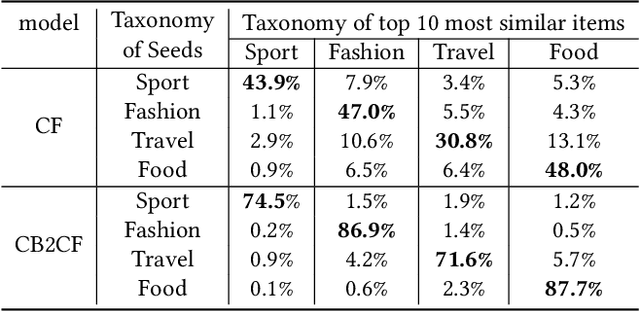

Content feed, a type of product that recommends a sequence of items for users to browse and engage with, has gained tremendous popularity among social media platforms. In this paper, we propose to study the diversity problem in such a scenario from an item sequence perspective using time series analysis techniques. We derive a method called sliding spectrum decomposition (SSD) that captures users' perception of diversity in browsing a long item sequence. We also share our experiences in designing and implementing a suitable item embedding method for accurate similarity measurement under long tail effect. Combined together, they are now fully implemented and deployed in Xiaohongshu App's production recommender system that serves the main Explore Feed product for tens of millions of users every day. We demonstrate the effectiveness and efficiency of the method through theoretical analysis, offline experiments and online A/B tests.
Beyond Voice Identity Conversion: Manipulating Voice Attributes by Adversarial Learning of Structured Disentangled Representations
Jul 27, 2021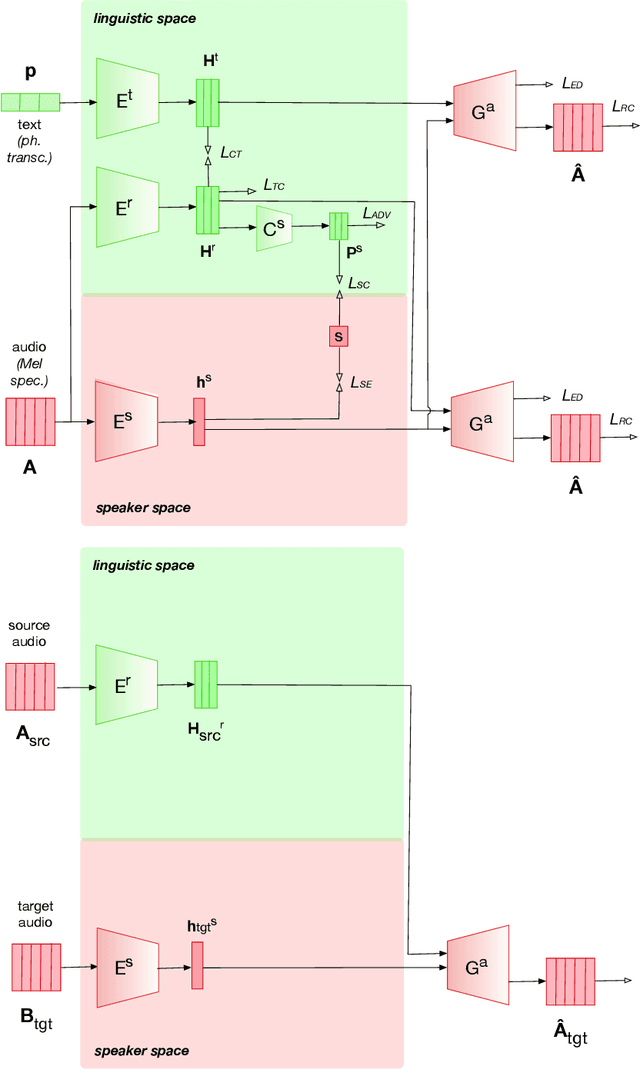

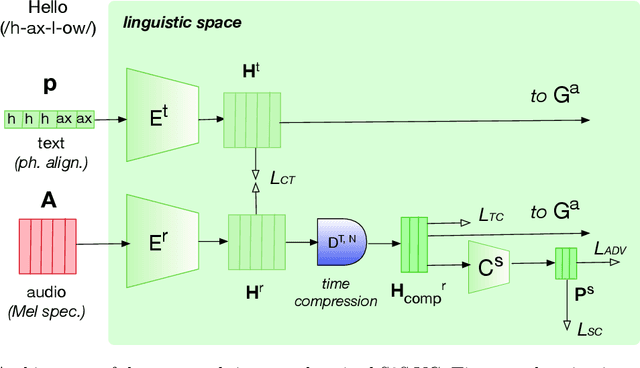
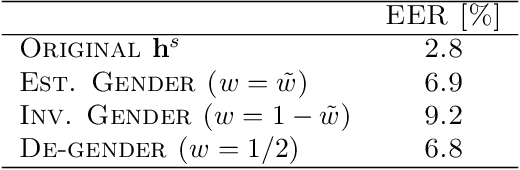
Voice conversion (VC) consists of digitally altering the voice of an individual to manipulate part of its content, primarily its identity, while maintaining the rest unchanged. Research in neural VC has accomplished considerable breakthroughs with the capacity to falsify a voice identity using a small amount of data with a highly realistic rendering. This paper goes beyond voice identity and presents a neural architecture that allows the manipulation of voice attributes (e.g., gender and age). Leveraging the latest advances on adversarial learning of structured speech representation, a novel structured neural network is proposed in which multiple auto-encoders are used to encode speech as a set of idealistically independent linguistic and extra-linguistic representations, which are learned adversariarly and can be manipulated during VC. Moreover, the proposed architecture is time-synchronized so that the original voice timing is preserved during conversion which allows lip-sync applications. Applied to voice gender conversion on the real-world VCTK dataset, our proposed architecture can learn successfully gender-independent representation and convert the voice gender with a very high efficiency and naturalness.
Efficient Anytime CLF Reactive Planning System for a Bipedal Robot on Undulating Terrain
Aug 15, 2021
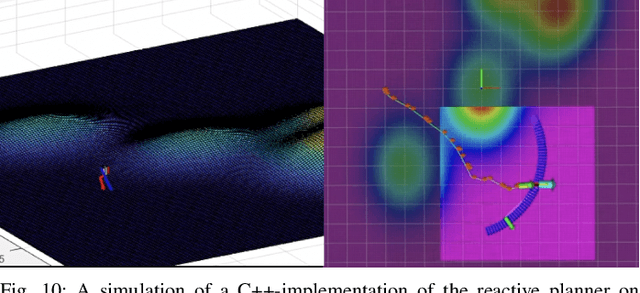
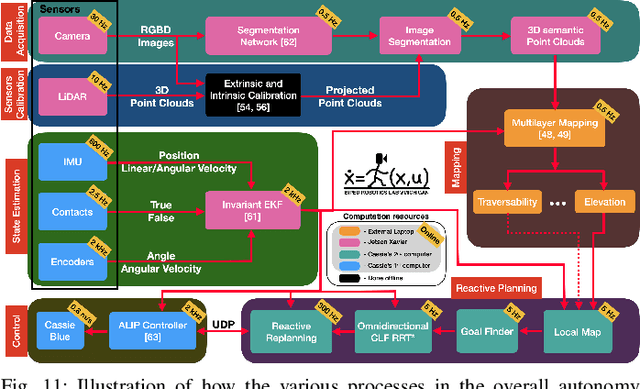

We propose and experimentally demonstrate a reactive planning system for bipedal robots on unexplored, challenging terrains. The system consists of a low-frequency planning thread (5 Hz) to find an asymptotically optimal path and a high-frequency reactive thread (300 Hz) to accommodate robot deviation. The planning thread includes: a multi-layer local map to compute traversability for the robot on the terrain; an anytime omnidirectional Control Lyapunov Function (CLF) for use with a Rapidly Exploring Random Tree Star (RRT*) that generates a vector field for specifying motion between nodes; a sub-goal finder when the final goal is outside of the current map; and a finite-state machine to handle high-level mission decisions. The system also includes a reactive thread to obviate the non-smooth motions that arise with traditional RRT* algorithms when performing path following. The reactive thread copes with robot deviation while eliminating non-smooth motions via a vector field (defined by a closed-loop feedback policy) that provides real-time control commands to the robot's gait controller as a function of instantaneous robot pose. The system is evaluated on various challenging outdoor terrains and cluttered indoor scenes in both simulation and experiment on Cassie Blue, a bipedal robot with 20 degrees of freedom. All implementations are coded in C++ with the Robot Operating System (ROS) and are available at https://github.com/UMich-BipedLab/CLF_reactive_planning_system.
Efficient TBox Reasoning with Value Restrictions using the $\mathcal{FL}_{o}$wer reasoner
Jul 27, 2021
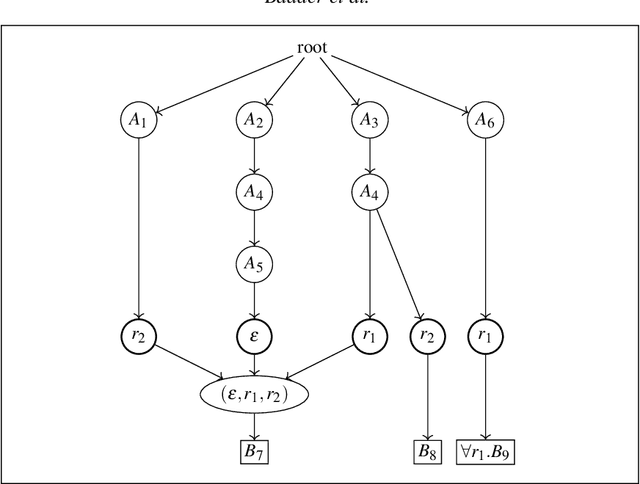
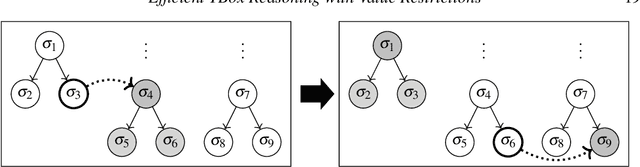
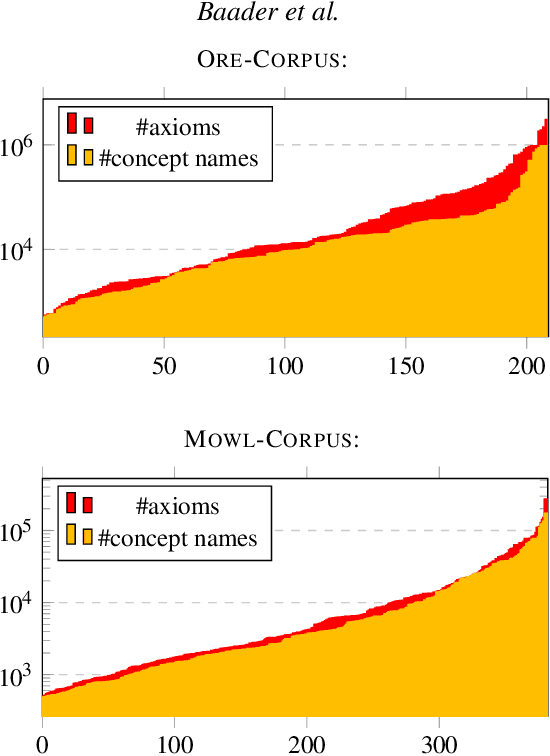
The inexpressive Description Logic (DL) $\mathcal{FL}_0$, which has conjunction and value restriction as its only concept constructors, had fallen into disrepute when it turned out that reasoning in $\mathcal{FL}_0$ w.r.t. general TBoxes is ExpTime-complete, i.e., as hard as in the considerably more expressive logic $\mathcal{ALC}$. In this paper, we rehabilitate $\mathcal{FL}_0$ by presenting a dedicated subsumption algorithm for $\mathcal{FL}_0$, which is much simpler than the tableau-based algorithms employed by highly optimized DL reasoners. Our experiments show that the performance of our novel algorithm, as prototypically implemented in our $\mathcal{FL}_o$wer reasoner, compares very well with that of the highly optimized reasoners. $\mathcal{FL}_o$wer can also deal with ontologies written in the extension $\mathcal{FL}_{\bot}$ of $\mathcal{FL}_0$ with the top and the bottom concept by employing a polynomial-time reduction, shown in this paper, which eliminates top and bottom. We also investigate the complexity of reasoning in DLs related to the Horn-fragments of $\mathcal{FL}_0$ and $\mathcal{FL}_{\bot}$.
Technology Report : Robotic Localization and Navigation System for Visible Light Positioning and SLAM
Apr 30, 2021Visible light positioning (VLP) technology is a promising technique as it can provide high accuracy positioning based on the existing lighting infrastructure. However, existing approaches often require dense lighting distributions. Additionally, due to complicated indoor environments, it is still challenging to develop a robust VLP. In this work, we proposed loosely-coupled multi-sensor fusion method based on VLP and Simultaneous Localization and Mapping (SLAM), with light detection and ranging (LiDAR), odometry, and rolling shutter camera. Our method can provide accurate and robust robotics localization and navigation in LED-shortage or even outage situations. The efficacy of the proposed scheme is verified by extensive real-time experiment 1 . The results show that our proposed scheme can provide an average accuracy of 2 cm and the average computational time in low-cost embedded platforms is around 50 ms.