 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Exploring the Properties and Evolution of Neural Network Eigenspaces during Training
Jun 18, 2021
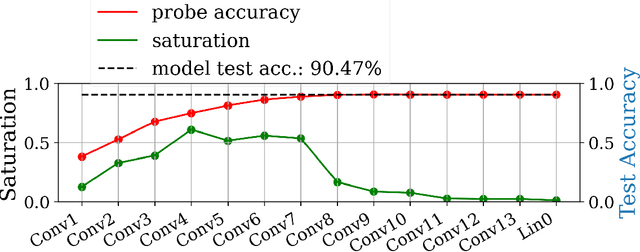
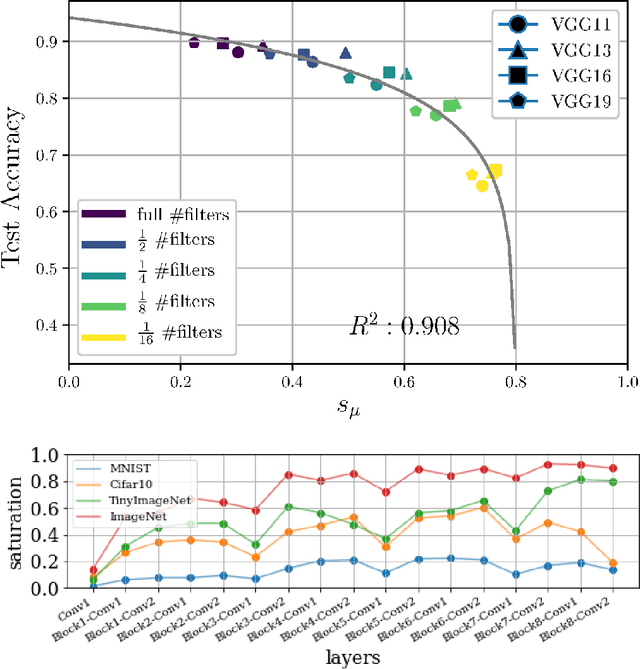
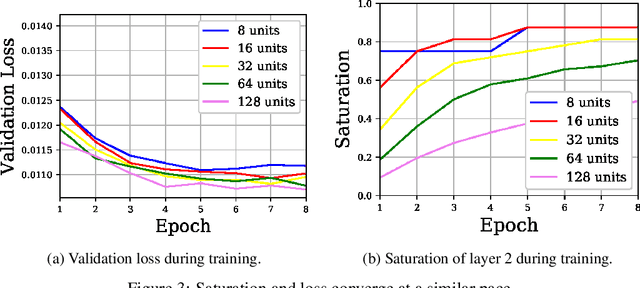
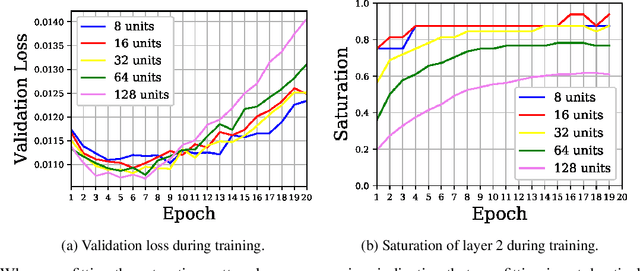
In this work we explore the information processing inside neural networks using logistic regression probes \cite{probes} and the saturation metric \cite{featurespace_saturation}. We show that problem difficulty and neural network capacity affect the predictive performance in an antagonistic manner, opening the possibility of detecting over- and under-parameterization of neural networks for a given task. We further show that the observed effects are independent from previously reported pathological patterns like the ``tail pattern'' described in \cite{featurespace_saturation}. Finally we are able to show that saturation patterns converge early during training, allowing for a quicker cycle time during analysis
Sliding Spectrum Decomposition for Diversified Recommendation
Jul 12, 2021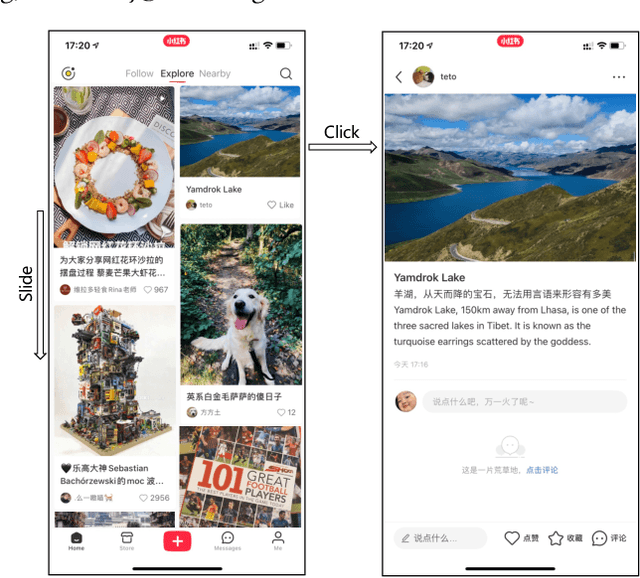
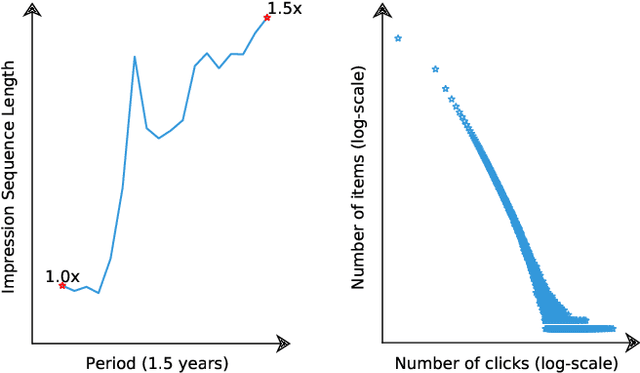
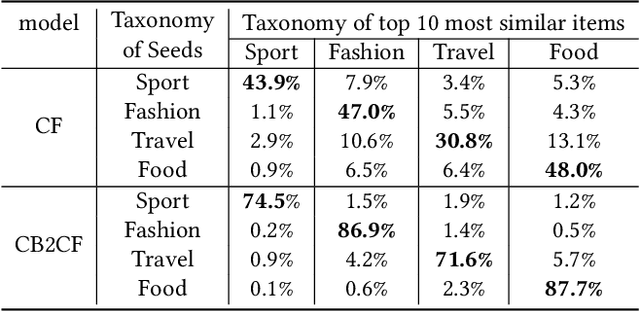

Content feed, a type of product that recommends a sequence of items for users to browse and engage with, has gained tremendous popularity among social media platforms. In this paper, we propose to study the diversity problem in such a scenario from an item sequence perspective using time series analysis techniques. We derive a method called sliding spectrum decomposition (SSD) that captures users' perception of diversity in browsing a long item sequence. We also share our experiences in designing and implementing a suitable item embedding method for accurate similarity measurement under long tail effect. Combined together, they are now fully implemented and deployed in Xiaohongshu App's production recommender system that serves the main Explore Feed product for tens of millions of users every day. We demonstrate the effectiveness and efficiency of the method through theoretical analysis, offline experiments and online A/B tests.
Retinal-inspired Filtering for Dynamic Image Coding
Mar 22, 2021
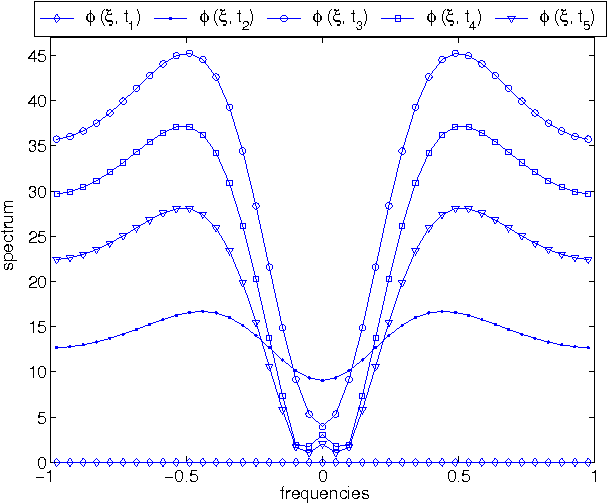


This paper introduces a novel non-Separable sPAtioteMporal filter (non-SPAM) which enables the spatiotemporal decomposition of a still-image. The construction of this filter is inspired by the model of the retina which is able to selectively transmit information to the brain. The non-SPAM filter mimics the retinal-way to extract necessary information for a dynamic encoding/decoding system. We applied the non-SPAM filter on a still image which is flashed for a long time. We prove that the non-SPAM filter decomposes the still image over a set of time-varying difference of Gaussians, which form a frame. We simulate the analysis and synthesis system based on this frame. This system results in a progressive reconstruction of the input image. Both the theoretical and numerical results show that the quality of the reconstruction improves while the time increases.
"What makes my queries slow?": Subgroup Discovery for SQL Workload Analysis
Aug 09, 2021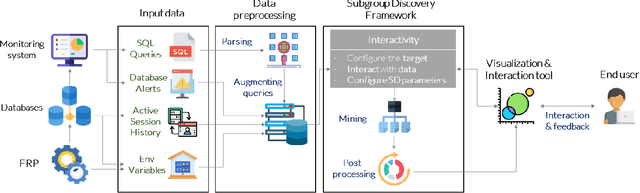

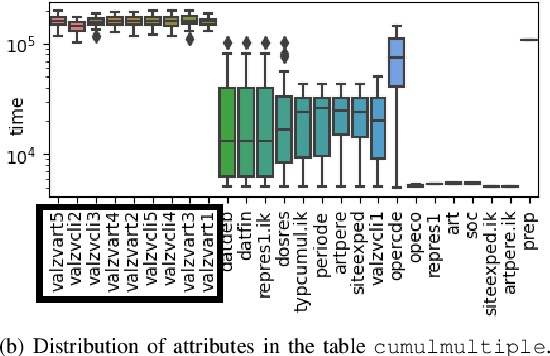
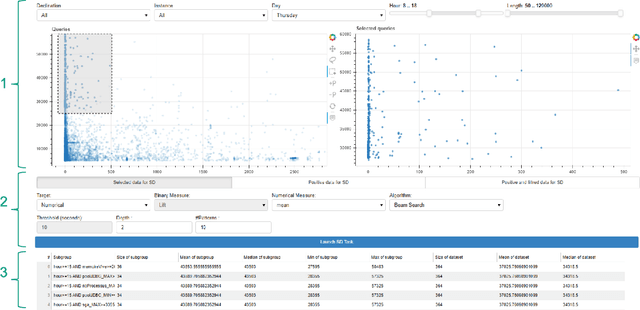
Among daily tasks of database administrators (DBAs), the analysis of query workloads to identify schema issues and improving performances is crucial. Although DBAs can easily pinpoint queries repeatedly causing performance issues, it remains challenging to automatically identify subsets of queries that share some properties only (a pattern) and simultaneously foster some target measures, such as execution time. Patterns are defined on combinations of query clauses, environment variables, database alerts and metrics and help answer questions like what makes SQL queries slow? What makes I/O communications high? Automatically discovering these patterns in a huge search space and providing them as hypotheses for helping to localize issues and root-causes is important in the context of explainable AI. To tackle it, we introduce an original approach rooted on Subgroup Discovery. We show how to instantiate and develop this generic data-mining framework to identify potential causes of SQL workloads issues. We believe that such data-mining technique is not trivial to apply for DBAs. As such, we also provide a visualization tool for interactive knowledge discovery. We analyse a one week workload from hundreds of databases from our company, make both the dataset and source code available, and experimentally show that insightful hypotheses can be discovered.
Pseudo Relevance Feedback with Deep Language Models and Dense Retrievers: Successes and Pitfalls
Aug 25, 2021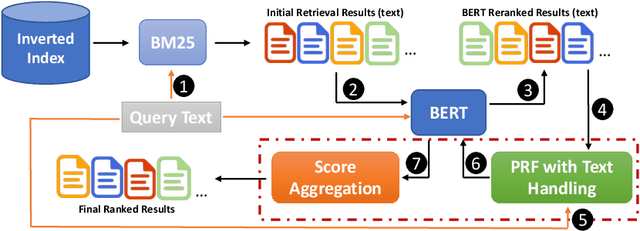
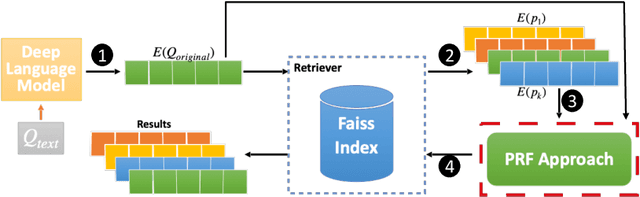
Pseudo Relevance Feedback (PRF) is known to improve the effectiveness of bag-of-words retrievers. At the same time, deep language models have been shown to outperform traditional bag-of-words rerankers. However, it is unclear how to integrate PRF directly with emergent deep language models. In this article, we address this gap by investigating methods for integrating PRF signals into rerankers and dense retrievers based on deep language models. We consider text-based and vector-based PRF approaches, and investigate different ways of combining and scoring relevance signals. An extensive empirical evaluation was conducted across four different datasets and two task settings (retrieval and ranking). Text-based PRF results show that the use of PRF had a mixed effect on deep rerankers across different datasets. We found that the best effectiveness was achieved when (i) directly concatenating each PRF passage with the query, searching with the new set of queries, and then aggregating the scores; (ii) using Borda to aggregate scores from PRF runs. Vector-based PRF results show that the use of PRF enhanced the effectiveness of deep rerankers and dense retrievers over several evaluation metrics. We found that higher effectiveness was achieved when (i) the query retains either the majority or the same weight within the PRF mechanism, and (ii) a shallower PRF signal (i.e., a smaller number of top-ranked passages) was employed, rather than a deeper signal. Our vector-based PRF method is computationally efficient; thus this represents a general PRF method others can use with deep rerankers and dense retrievers.
Vector Detection Network: An Application Study on Robots Reading Analog Meters in the Wild
May 30, 2021

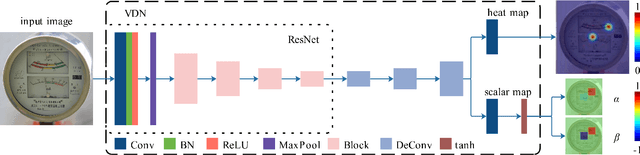

Analog meters equipped with one or multiple pointers are wildly utilized to monitor vital devices' status in industrial sites for safety concerns. Reading these legacy meters {\bi autonomously} remains an open problem since estimating pointer origin and direction under imaging damping factors imposed in the wild could be challenging. Nevertheless, high accuracy, flexibility, and real-time performance are demanded. In this work, we propose the Vector Detection Network (VDN) to detect analog meters' pointers given their images, eliminating the barriers for autonomously reading such meters using intelligent agents like robots. We tackled the pointer as a two-dimensional vector, whose initial point coincides with the tip, and the direction is along tail-to-tip. The network estimates a confidence map, wherein the peak pixels are treated as vectors' initial points, along with a two-layer scalar map, whose pixel values at each peak form the scalar components in the directions of the coordinate axes. We established the Pointer-10K dataset composing of real-world analog meter images to evaluate our approach due to no similar dataset is available for now. Experiments on the dataset demonstrated that our methods generalize well to various meters, robust to harsh imaging factors, and run in real-time.
Adaptive Anomaly Detection for Internet of Things in Hierarchical Edge Computing: A Contextual-Bandit Approach
Aug 09, 2021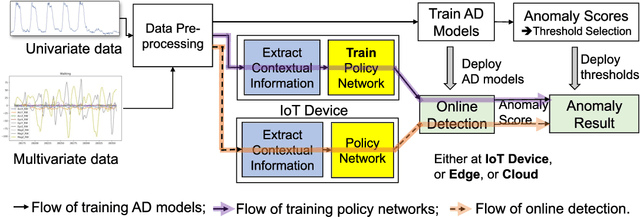
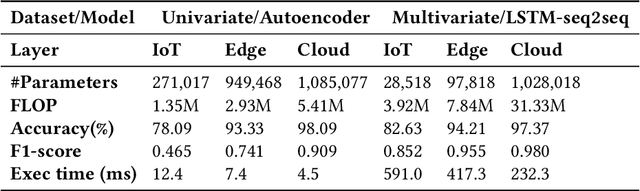
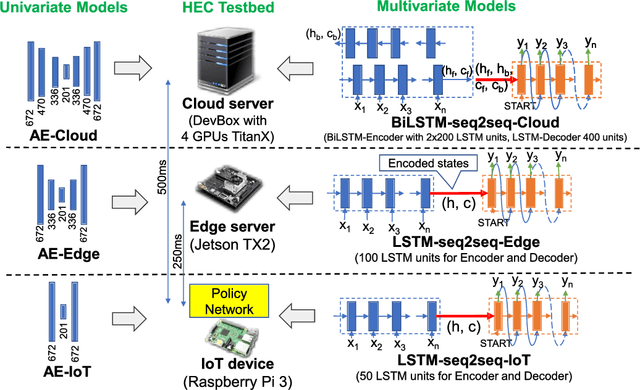
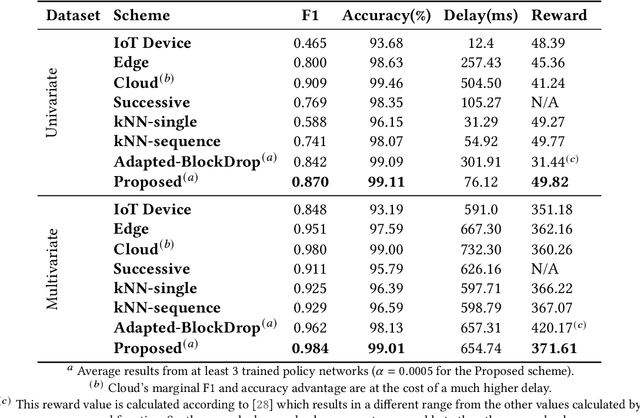
The advances in deep neural networks (DNN) have significantly enhanced real-time detection of anomalous data in IoT applications. However, the complexity-accuracy-delay dilemma persists: complex DNN models offer higher accuracy, but typical IoT devices can barely afford the computation load, and the remedy of offloading the load to the cloud incurs long delay. In this paper, we address this challenge by proposing an adaptive anomaly detection scheme with hierarchical edge computing (HEC). Specifically, we first construct multiple anomaly detection DNN models with increasing complexity, and associate each of them to a corresponding HEC layer. Then, we design an adaptive model selection scheme that is formulated as a contextual-bandit problem and solved by using a reinforcement learning policy network. We also incorporate a parallelism policy training method to accelerate the training process by taking advantage of distributed models. We build an HEC testbed using real IoT devices, implement and evaluate our contextual-bandit approach with both univariate and multivariate IoT datasets. In comparison with both baseline and state-of-the-art schemes, our adaptive approach strikes the best accuracy-delay tradeoff on the univariate dataset, and achieves the best accuracy and F1-score on the multivariate dataset with only negligibly longer delay than the best (but inflexible) scheme.
Hamiltonian-Driven Shadow Tomography of Quantum States
Feb 19, 2021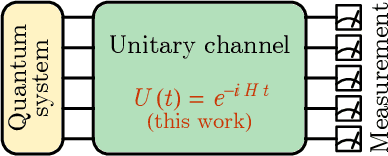
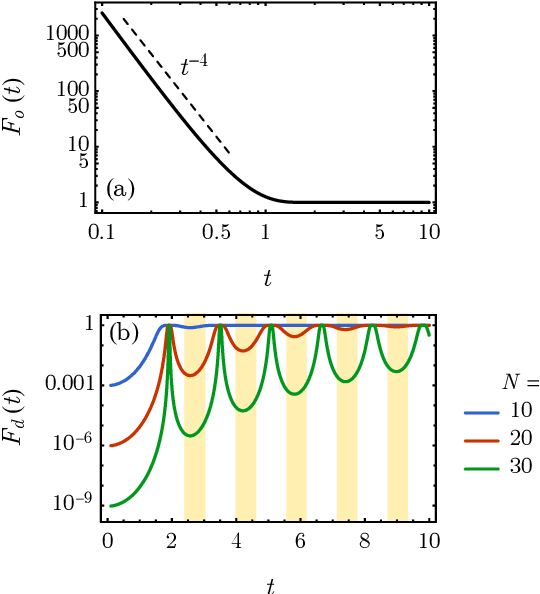
Classical shadow tomography provides an efficient method for predicting functions of an unknown quantum state from a few measurements of the state. It relies on a unitary channel that efficiently scrambles the quantum information of the state to the measurement basis. Facing the challenge of realizing deep unitary circuits on near-term quantum devices, we explore the scenario in which the unitary channel can be shallow and is generated by a quantum chaotic Hamiltonian via time evolution. We provide an unbiased estimator of the density matrix for all ranges of the evolution time. We analyze the sample complexity of the Hamiltonian-driven shadow tomography. We find that it can be more efficient than the unitary-2-design-based shadow tomography in a sequence of intermediate time windows that range from an order-1 scrambling time to a time scale of $D^{1/6}$, given the Hilbert space dimension $D$. In particular, the efficiency of predicting diagonal observables is improved by a factor of $D$ without sacrificing the efficiency of predicting off-diagonal observables.
Latency-Constrained Highly-Reliable mmWave Communication via Multi-point Connectivity
Aug 20, 2021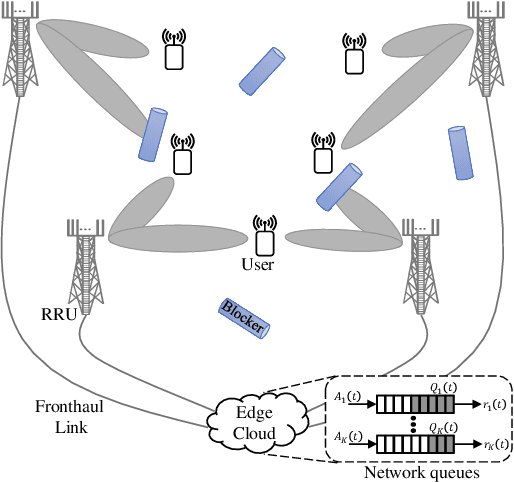
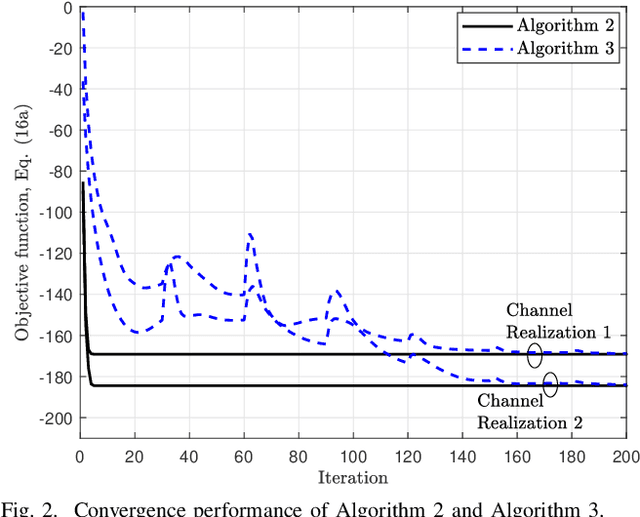
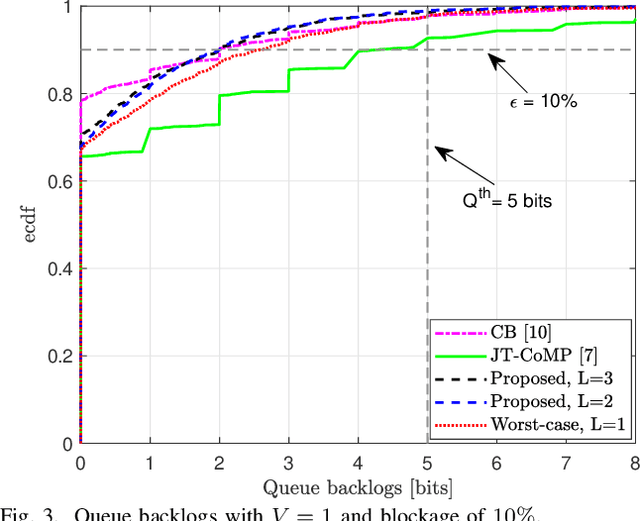
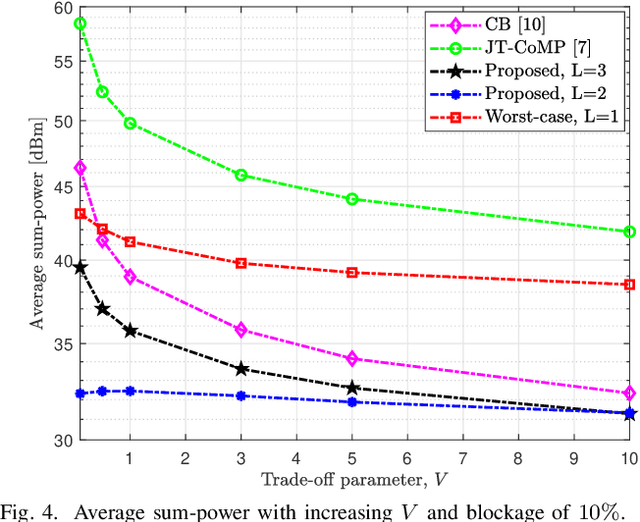
The sensitivity of millimeter-wave (mmWave) radio channel to blockage is a fundamental challenge in achieving low-latency and ultra-reliable connectivity. In this paper, we explore the viability of using coordinated multi-point (CoMP) transmission for a delay bounded and reliable mmWave communication. We propose a novel blockage-aware algorithm for the sum-power minimization problem under the user-specific latency requirements in a dynamic mobile access network. We use the Lyapunov optimization framework, and provide a dynamic control algorithm, which efficiently transforms a time-average stochastic problem into a sequence of deterministic subproblems. A robust beamformer design is then proposed by exploiting the queue backlogs and channel information, that efficiently allocates the required radio and cooperation resources, and proactively leverages the multi-antenna spatial diversity according to the instantaneous needs of the users. Further, to adapt to the uncertainties of the mmWave channel, we consider a pessimistic estimate of the rates over link blockage combinations and an adaptive selection of the CoMP serving set from the available remote radio units (RRUs). Moreover, after the relaxation of coupled and non-convex constraints via the Fractional Program (FP) techniques, a low-complexity closed-form iterative algorithm is provided by solving a system of Karush-Kuhn-Tucker (KKT) optimality conditions. The simulation results manifest that, in the presence of random blockages, the proposed methods outperform the baseline scenarios and provide power-efficient, high-reliable, and low-latency mmWave communication.
A quantum algorithm for training wide and deep classical neural networks
Jul 19, 2021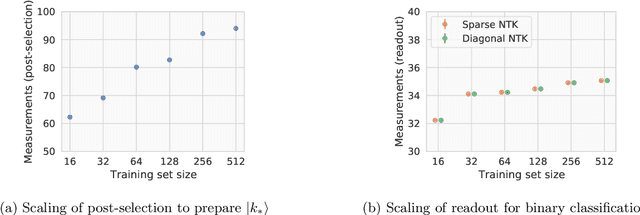
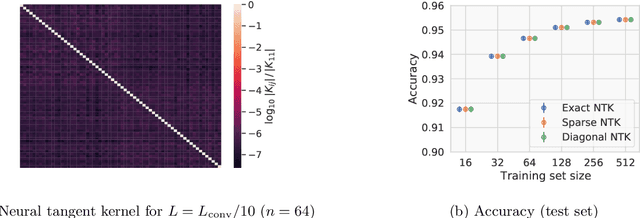
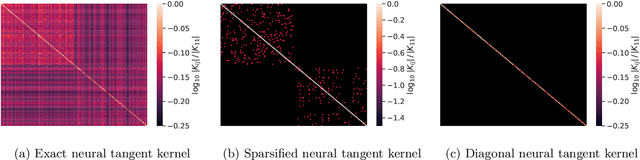
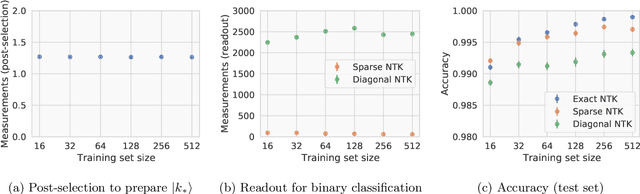
Given the success of deep learning in classical machine learning, quantum algorithms for traditional neural network architectures may provide one of the most promising settings for quantum machine learning. Considering a fully-connected feedforward neural network, we show that conditions amenable to classical trainability via gradient descent coincide with those necessary for efficiently solving quantum linear systems. We propose a quantum algorithm to approximately train a wide and deep neural network up to $O(1/n)$ error for a training set of size $n$ by performing sparse matrix inversion in $O(\log n)$ time. To achieve an end-to-end exponential speedup over gradient descent, the data distribution must permit efficient state preparation and readout. We numerically demonstrate that the MNIST image dataset satisfies such conditions; moreover, the quantum algorithm matches the accuracy of the fully-connected network. Beyond the proven architecture, we provide empirical evidence for $O(\log n)$ training of a convolutional neural network with pooling.