 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Data-driven Neural Architecture Learning For Financial Time-series Forecasting
Mar 05, 2019
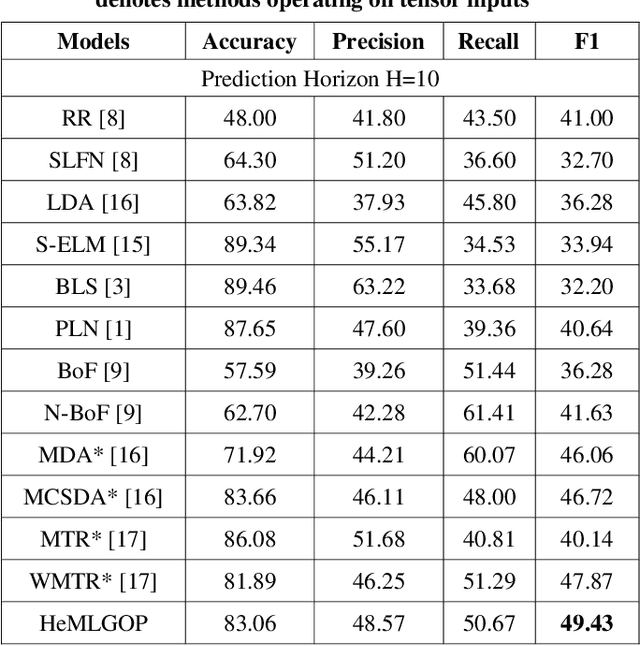
Forecasting based on financial time-series is a challenging task since most real-world data exhibits nonstationary property and nonlinear dependencies. In addition, different data modalities often embed different nonlinear relationships which are difficult to capture by human-designed models. To tackle the supervised learning task in financial time-series prediction, we propose the application of a recently formulated algorithm that adaptively learns a mapping function, realized by a heterogeneous neural architecture composing of Generalized Operational Perceptron, given a set of labeled data. With a modified objective function, the proposed algorithm can accommodate the frequently observed imbalanced data distribution problem. Experiments on a large-scale Limit Order Book dataset demonstrate that the proposed algorithm outperforms related algorithms, including tensor-based methods which have access to a broader set of input information.
Scalable Inference of Sparsely-changing Markov Random Fields with Strong Statistical Guarantees
Feb 06, 2021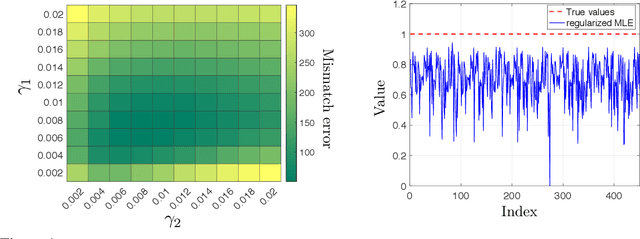
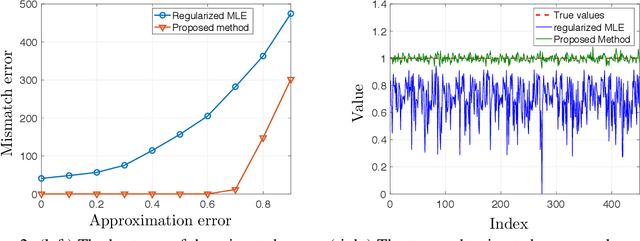
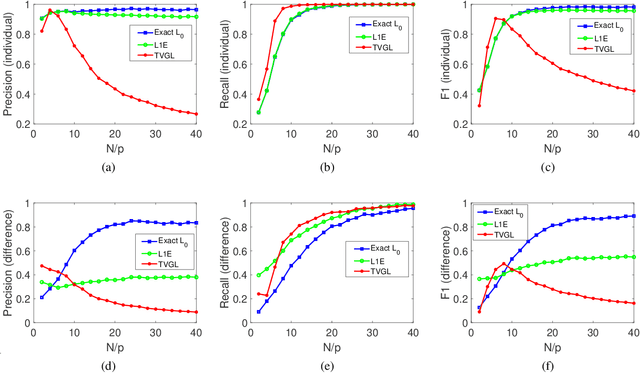
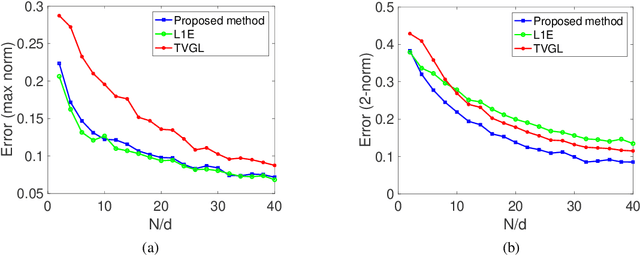
In this paper, we study the problem of inferring time-varying Markov random fields (MRF), where the underlying graphical model is both sparse and changes sparsely over time. Most of the existing methods for the inference of time-varying MRFs rely on the regularized maximum likelihood estimation (MLE), that typically suffer from weak statistical guarantees and high computational time. Instead, we introduce a new class of constrained optimization problems for the inference of sparsely-changing MRFs. The proposed optimization problem is formulated based on the exact $\ell_0$ regularization, and can be solved in near-linear time and memory. Moreover, we show that the proposed estimator enjoys a provably small estimation error. As a special case, we derive sharp statistical guarantees for the inference of sparsely-changing Gaussian MRFs (GMRF) in the high-dimensional regime, showing that such problems can be learned with as few as one sample per time. Our proposed method is extremely efficient in practice: it can accurately estimate sparsely-changing graphical models with more than 500 million variables in less than one hour.
Confident Head Circumference Measurement from Ultrasound with Real-time Feedback for Sonographers
Aug 07, 2019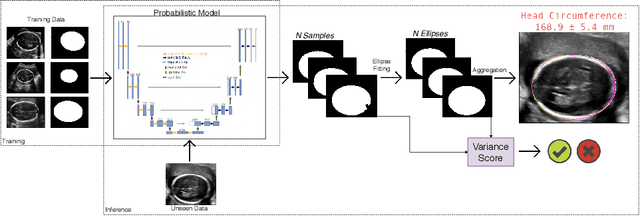

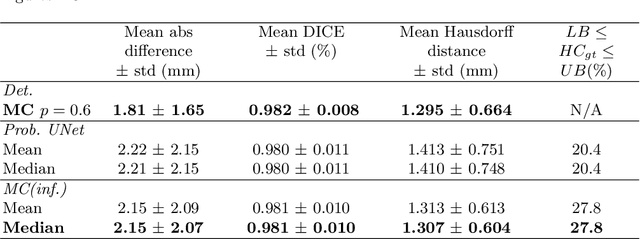
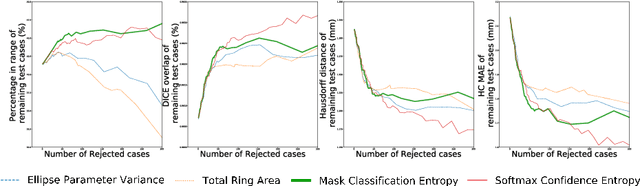
Manual estimation of fetal Head Circumference (HC) from Ultrasound (US) is a key biometric for monitoring the healthy development of fetuses. Unfortunately, such measurements are subject to large inter-observer variability, resulting in low early-detection rates of fetal abnormalities. To address this issue, we propose a novel probabilistic Deep Learning approach for real-time automated estimation of fetal HC. This system feeds back statistics on measurement robustness to inform users how confident a deep neural network is in evaluating suitable views acquired during free-hand ultrasound examination. In real-time scenarios, this approach may be exploited to guide operators to scan planes that are as close as possible to the underlying distribution of training images, for the purpose of improving inter-operator consistency. We train on free-hand ultrasound data from over 2000 subjects (2848 training/540 test) and show that our method is able to predict HC measurements within 1.81$\pm$1.65mm deviation from the ground truth, with 50% of the test images fully contained within the predicted confidence margins, and an average of 1.82$\pm$1.78mm deviation from the margin for the remaining cases that are not fully contained.
Sliding Spectrum Decomposition for Diversified Recommendation
Jul 12, 2021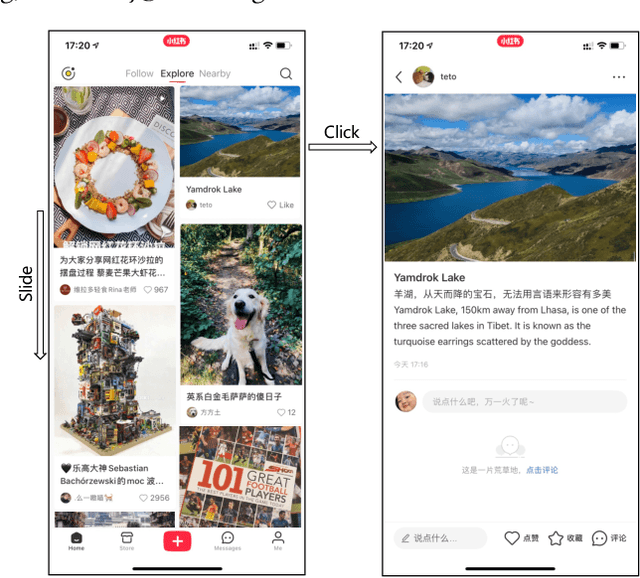
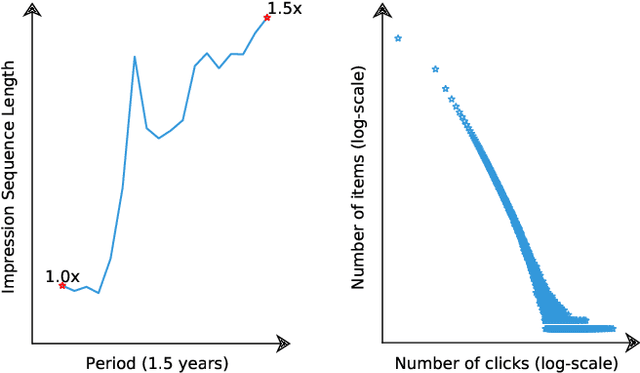
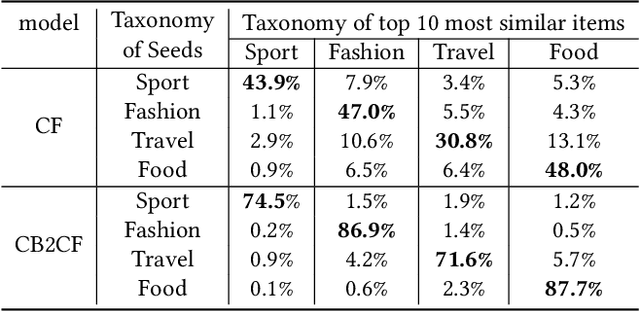

Content feed, a type of product that recommends a sequence of items for users to browse and engage with, has gained tremendous popularity among social media platforms. In this paper, we propose to study the diversity problem in such a scenario from an item sequence perspective using time series analysis techniques. We derive a method called sliding spectrum decomposition (SSD) that captures users' perception of diversity in browsing a long item sequence. We also share our experiences in designing and implementing a suitable item embedding method for accurate similarity measurement under long tail effect. Combined together, they are now fully implemented and deployed in Xiaohongshu App's production recommender system that serves the main Explore Feed product for tens of millions of users every day. We demonstrate the effectiveness and efficiency of the method through theoretical analysis, offline experiments and online A/B tests.
"What makes my queries slow?": Subgroup Discovery for SQL Workload Analysis
Aug 09, 2021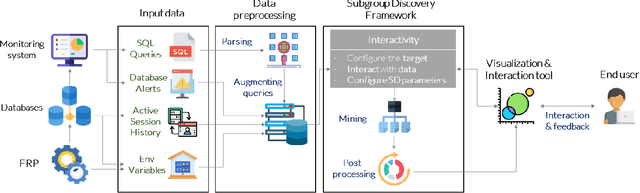

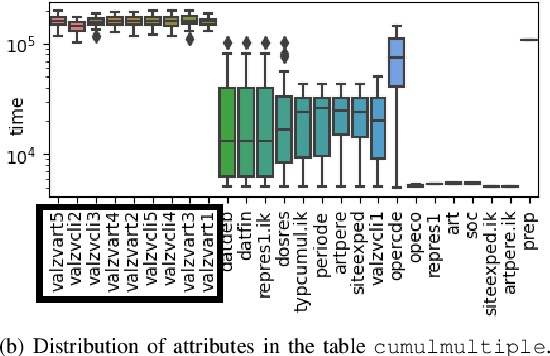
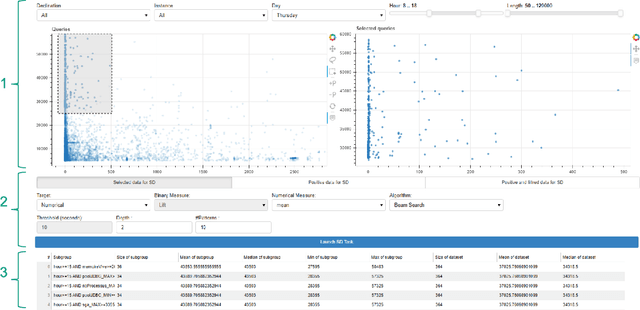
Among daily tasks of database administrators (DBAs), the analysis of query workloads to identify schema issues and improving performances is crucial. Although DBAs can easily pinpoint queries repeatedly causing performance issues, it remains challenging to automatically identify subsets of queries that share some properties only (a pattern) and simultaneously foster some target measures, such as execution time. Patterns are defined on combinations of query clauses, environment variables, database alerts and metrics and help answer questions like what makes SQL queries slow? What makes I/O communications high? Automatically discovering these patterns in a huge search space and providing them as hypotheses for helping to localize issues and root-causes is important in the context of explainable AI. To tackle it, we introduce an original approach rooted on Subgroup Discovery. We show how to instantiate and develop this generic data-mining framework to identify potential causes of SQL workloads issues. We believe that such data-mining technique is not trivial to apply for DBAs. As such, we also provide a visualization tool for interactive knowledge discovery. We analyse a one week workload from hundreds of databases from our company, make both the dataset and source code available, and experimentally show that insightful hypotheses can be discovered.
Pseudo Relevance Feedback with Deep Language Models and Dense Retrievers: Successes and Pitfalls
Aug 25, 2021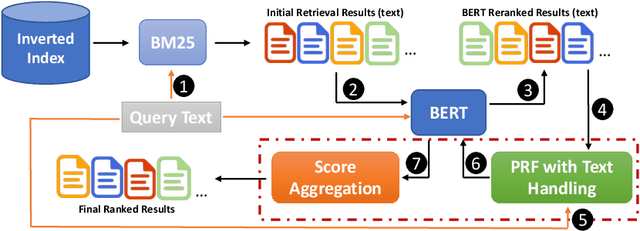
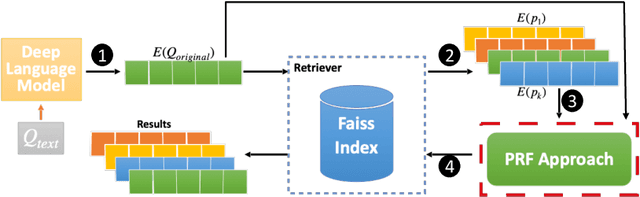
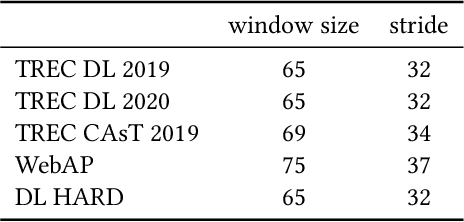
Pseudo Relevance Feedback (PRF) is known to improve the effectiveness of bag-of-words retrievers. At the same time, deep language models have been shown to outperform traditional bag-of-words rerankers. However, it is unclear how to integrate PRF directly with emergent deep language models. In this article, we address this gap by investigating methods for integrating PRF signals into rerankers and dense retrievers based on deep language models. We consider text-based and vector-based PRF approaches, and investigate different ways of combining and scoring relevance signals. An extensive empirical evaluation was conducted across four different datasets and two task settings (retrieval and ranking). Text-based PRF results show that the use of PRF had a mixed effect on deep rerankers across different datasets. We found that the best effectiveness was achieved when (i) directly concatenating each PRF passage with the query, searching with the new set of queries, and then aggregating the scores; (ii) using Borda to aggregate scores from PRF runs. Vector-based PRF results show that the use of PRF enhanced the effectiveness of deep rerankers and dense retrievers over several evaluation metrics. We found that higher effectiveness was achieved when (i) the query retains either the majority or the same weight within the PRF mechanism, and (ii) a shallower PRF signal (i.e., a smaller number of top-ranked passages) was employed, rather than a deeper signal. Our vector-based PRF method is computationally efficient; thus this represents a general PRF method others can use with deep rerankers and dense retrievers.
Exploring the Properties and Evolution of Neural Network Eigenspaces during Training
Jun 18, 2021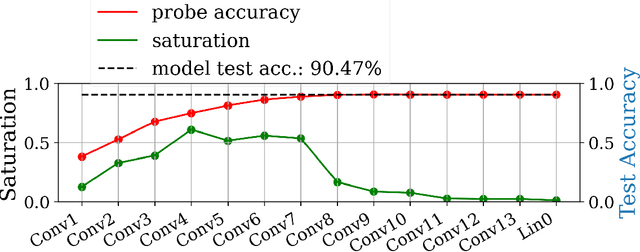
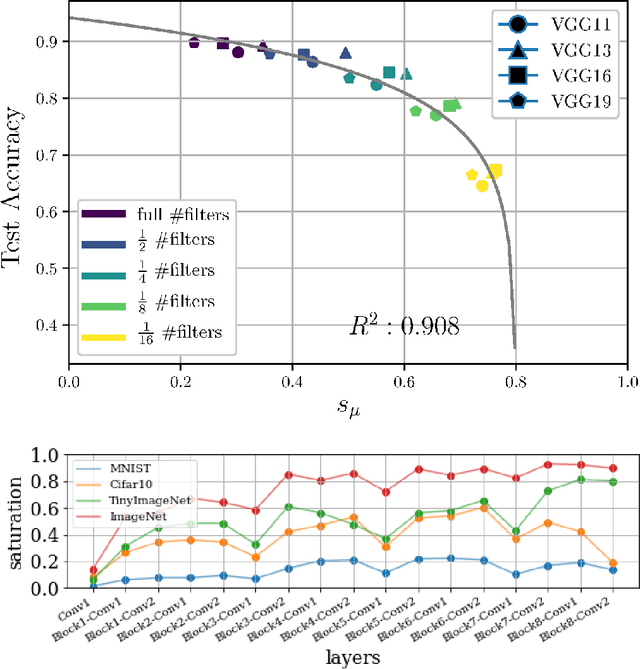
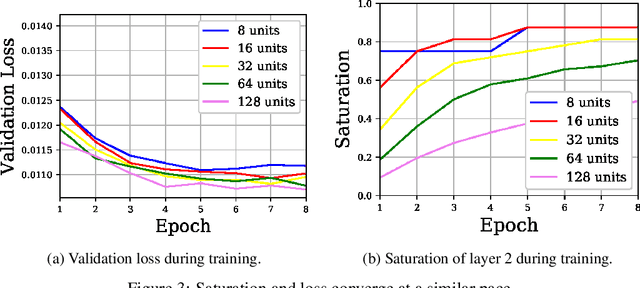
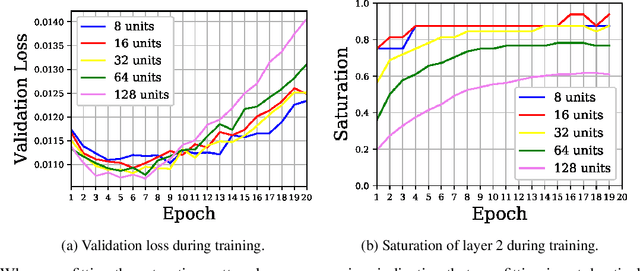
In this work we explore the information processing inside neural networks using logistic regression probes \cite{probes} and the saturation metric \cite{featurespace_saturation}. We show that problem difficulty and neural network capacity affect the predictive performance in an antagonistic manner, opening the possibility of detecting over- and under-parameterization of neural networks for a given task. We further show that the observed effects are independent from previously reported pathological patterns like the ``tail pattern'' described in \cite{featurespace_saturation}. Finally we are able to show that saturation patterns converge early during training, allowing for a quicker cycle time during analysis
Segmenting Hybrid Trajectories using Latent ODEs
May 09, 2021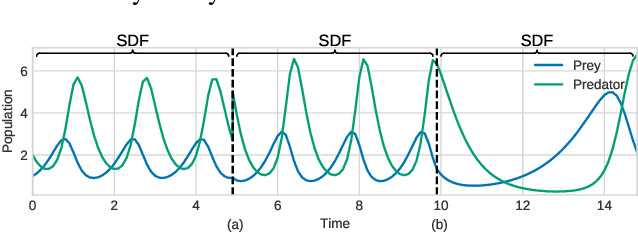
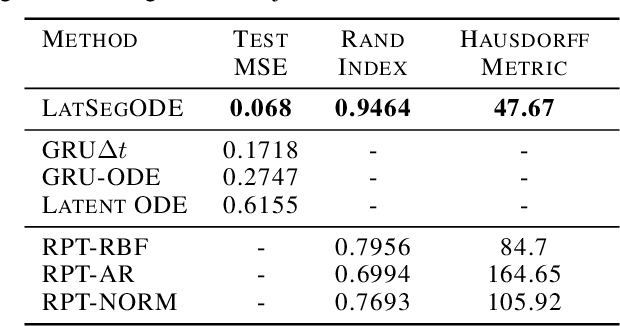
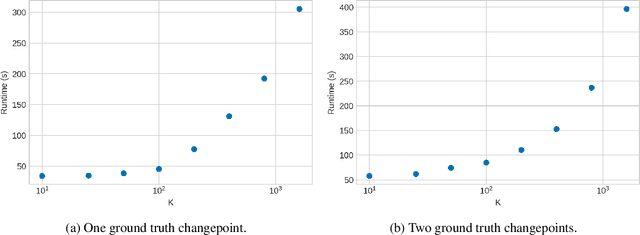
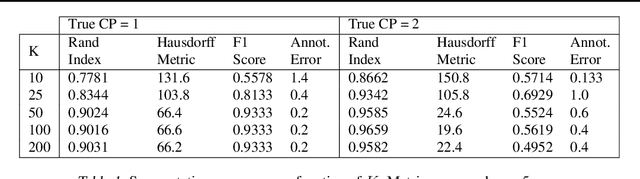
Smooth dynamics interrupted by discontinuities are known as hybrid systems and arise commonly in nature. Latent ODEs allow for powerful representation of irregularly sampled time series but are not designed to capture trajectories arising from hybrid systems. Here, we propose the Latent Segmented ODE (LatSegODE), which uses Latent ODEs to perform reconstruction and changepoint detection within hybrid trajectories featuring jump discontinuities and switching dynamical modes. Where it is possible to train a Latent ODE on the smooth dynamical flows between discontinuities, we apply the pruned exact linear time (PELT) algorithm to detect changepoints where latent dynamics restart, thereby maximizing the joint probability of a piece-wise continuous latent dynamical representation. We propose usage of the marginal likelihood as a score function for PELT, circumventing the need for model complexity-based penalization. The LatSegODE outperforms baselines in reconstructive and segmentation tasks including synthetic data sets of sine waves, Lotka Volterra dynamics, and UCI Character Trajectories.
CrowdExpress: A Probabilistic Framework for On-Time Crowdsourced Package Deliveries
Sep 08, 2018
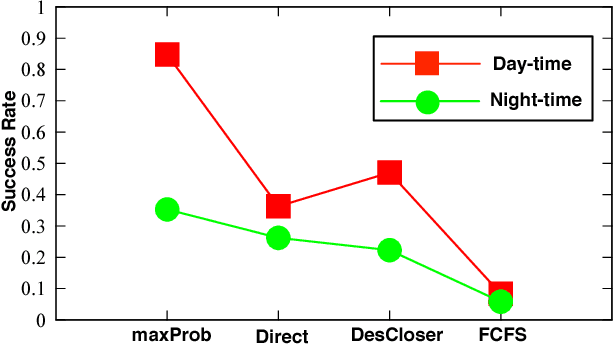
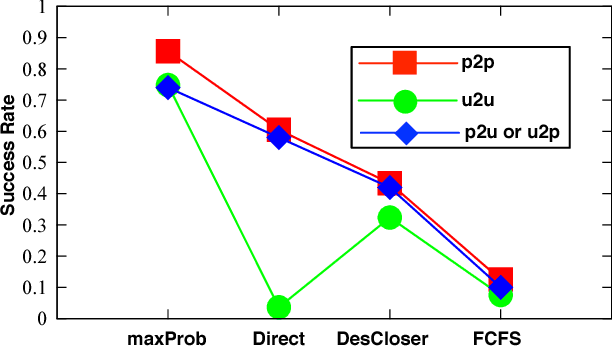
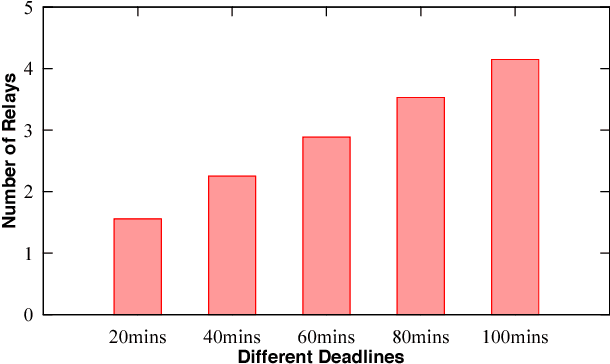
Speed and cost of logistics are two major concerns to on-line shoppers, but they generally conflict with each other in nature. To alleviate the contradiction, we propose to exploit existing taxis that are transporting passengers on the street to relay packages collaboratively, which can simultaneously lower the cost and accelerate the speed. Specifically, we propose a probabilistic framework containing two phases called CrowdExpress for the on-time package express deliveries. In the first phase, we mine the historical taxi GPS trajectory data offline to build the package transport network. In the second phase, we develop an online adaptive taxi scheduling algorithm to find the path with the maximum arriving-on-time probability "on-the-fly" upon real- time requests, and direct the package routing accordingly. Finally, we evaluate the system using the real-world taxi data generated by over 19,000 taxis in a month in the city of New York, US. Results show that around 9,500 packages can be delivered successfully on time per day with the success rate over 94%, moreover, the average computation time is within 25 milliseconds.
Adaptive Anomaly Detection for Internet of Things in Hierarchical Edge Computing: A Contextual-Bandit Approach
Aug 09, 2021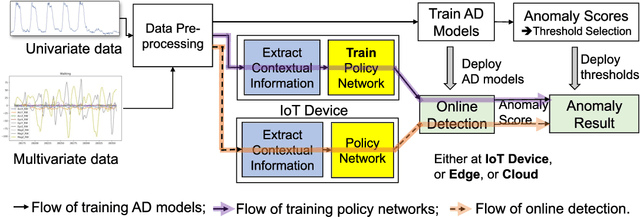
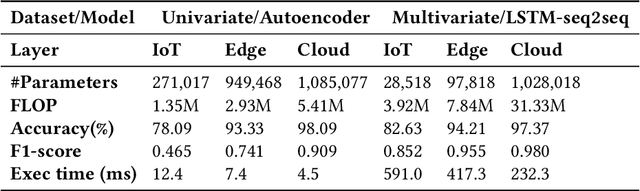
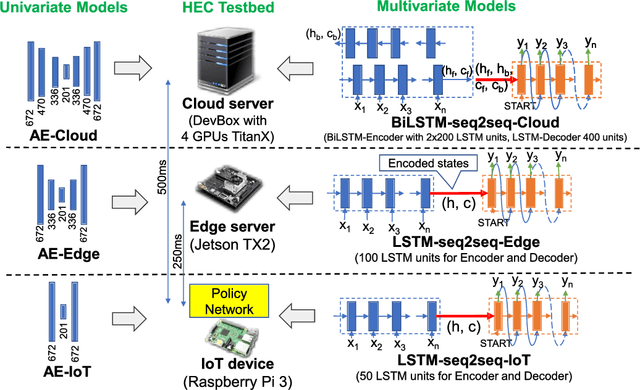
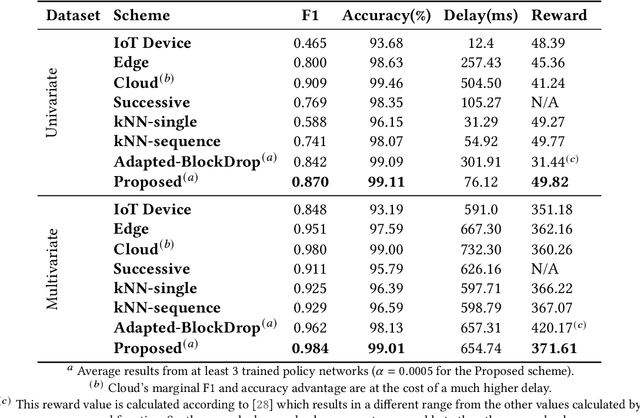
The advances in deep neural networks (DNN) have significantly enhanced real-time detection of anomalous data in IoT applications. However, the complexity-accuracy-delay dilemma persists: complex DNN models offer higher accuracy, but typical IoT devices can barely afford the computation load, and the remedy of offloading the load to the cloud incurs long delay. In this paper, we address this challenge by proposing an adaptive anomaly detection scheme with hierarchical edge computing (HEC). Specifically, we first construct multiple anomaly detection DNN models with increasing complexity, and associate each of them to a corresponding HEC layer. Then, we design an adaptive model selection scheme that is formulated as a contextual-bandit problem and solved by using a reinforcement learning policy network. We also incorporate a parallelism policy training method to accelerate the training process by taking advantage of distributed models. We build an HEC testbed using real IoT devices, implement and evaluate our contextual-bandit approach with both univariate and multivariate IoT datasets. In comparison with both baseline and state-of-the-art schemes, our adaptive approach strikes the best accuracy-delay tradeoff on the univariate dataset, and achieves the best accuracy and F1-score on the multivariate dataset with only negligibly longer delay than the best (but inflexible) scheme.