 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
On the Enabling of Multi-user Communications with Reconfigurable Intelligent Surfaces
Jun 12, 2021

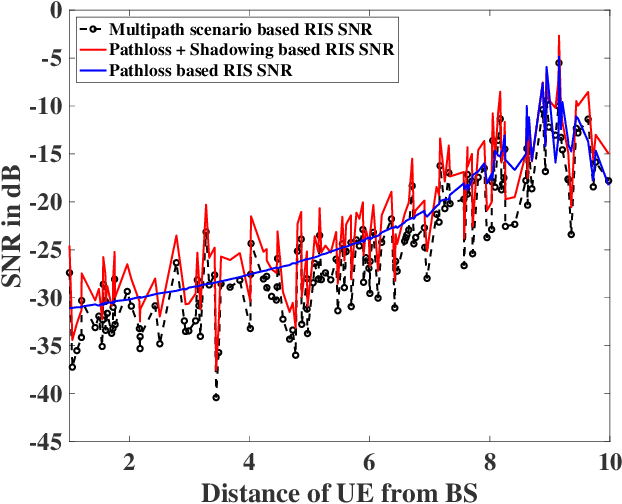
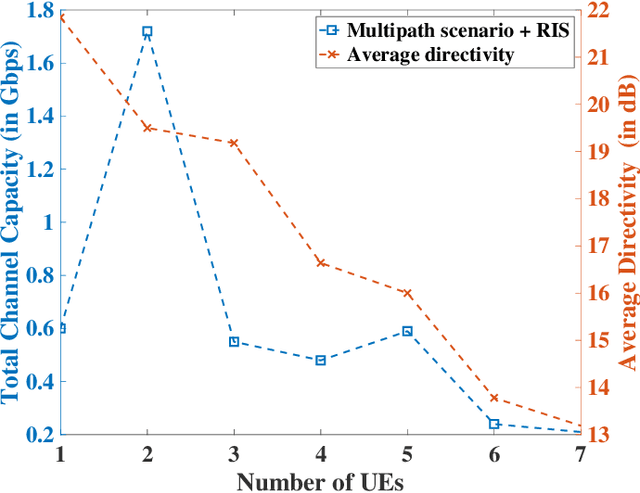
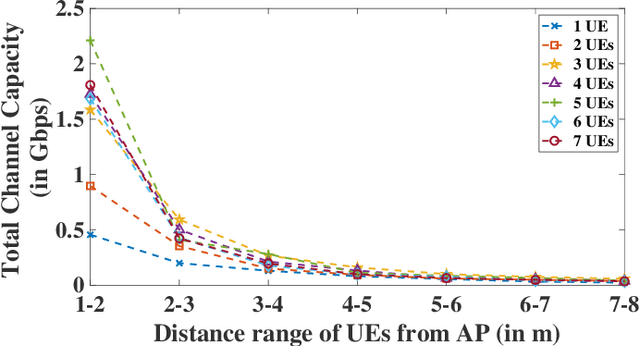
Reconfigurable Intelligent Surface (RIS) composed of programmable actuators is a promising technology, thanks to its capability in manipulating Electromagnetic (EM) wavefronts. In particular, RISs have the potential to provide significant performance improvements for wireless networks. However, to do so, a proper configuration of the reflection coefficients of the unit cells in the RIS is required. RISs are sophisticated platforms so the design and fabrication complexity might be uneconomical for single-user scenarios while a RIS that can service multi-users justifies the costs. For the first time, we propose an efficient reconfiguration technique providing the multi-beam radiation pattern. Thanks to the analytical model the reconfiguration profile is at hand compared to time-consuming optimization techniques. The outcome can pave the wave for commercial use of multi-user communication beyond 5G networks. We analyze the performance of our proposed RIS technology for indoor and outdoor scenarios, given the broadcast mode of operation. The aforesaid scenarios encompass some of the most challenging scenarios that wireless networks encounter. We show that our proposed technique provisions sufficient gains in the observed channel capacity when the users are close to the RIS in the indoor office environment scenario. Further, we report more than one order of magnitude increase in the system throughput given the outdoor environment. The results prove that RIS with the ability to communicate with multiple users can empower wireless networks with great capacity.
Retinal-inspired Filtering for Dynamic Image Coding
Mar 22, 2021
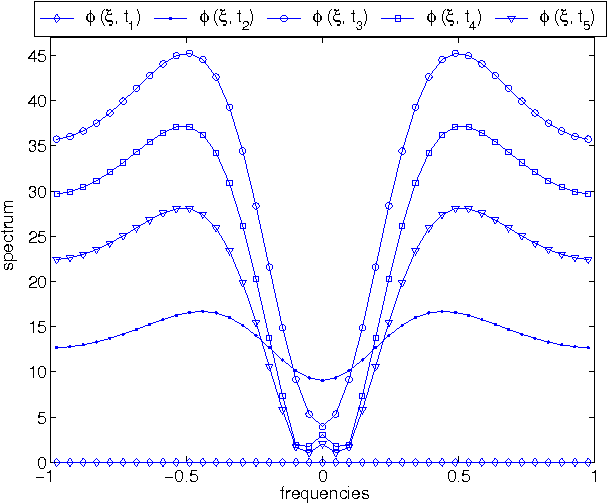


This paper introduces a novel non-Separable sPAtioteMporal filter (non-SPAM) which enables the spatiotemporal decomposition of a still-image. The construction of this filter is inspired by the model of the retina which is able to selectively transmit information to the brain. The non-SPAM filter mimics the retinal-way to extract necessary information for a dynamic encoding/decoding system. We applied the non-SPAM filter on a still image which is flashed for a long time. We prove that the non-SPAM filter decomposes the still image over a set of time-varying difference of Gaussians, which form a frame. We simulate the analysis and synthesis system based on this frame. This system results in a progressive reconstruction of the input image. Both the theoretical and numerical results show that the quality of the reconstruction improves while the time increases.
A Real-Time Cross-modality Correlation Filtering Method for Referring Expression Comprehension
Sep 16, 2019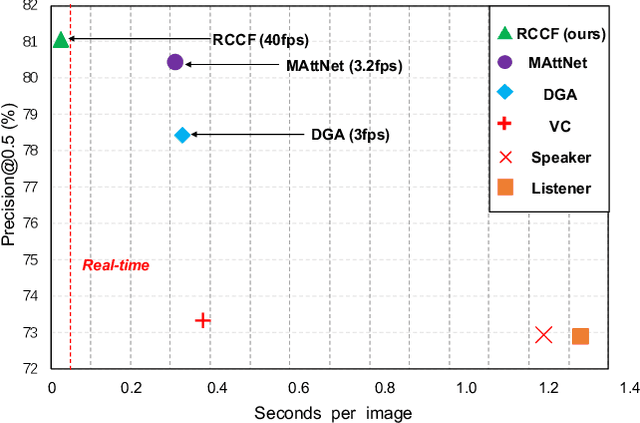
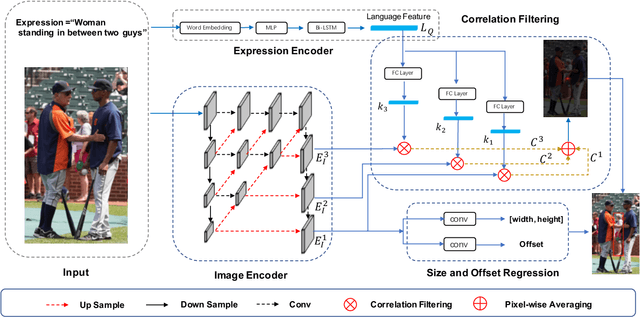
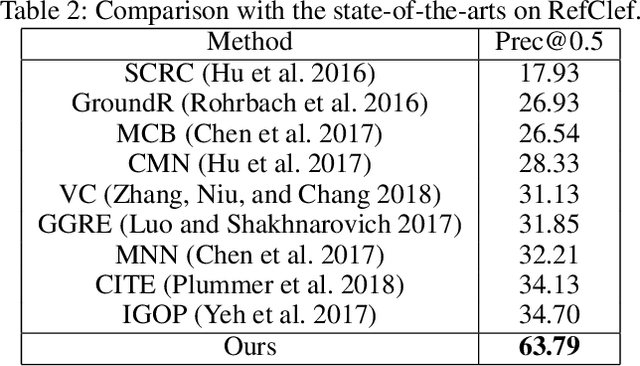
Referring expression comprehension aims to localize the object instance described by a natural language expression. Current referring expression methods have achieved pretty-well performance. However, none of them is able to achieve real-time inference without accuracy drop. The reason for the relatively slow inference speed is that these methods artificially split the referring expression comprehension into two sequential stages including proposal generation and proposal ranking. It does not exactly conform to the habit of human cognition. To this end, we propose a novel Real-time Cross-modality Correlation Filtering method (RCCF). RCCF reformulates the referring expression as a correlation filtering process. The expression is first mapped from the language domain to the visual domain and then treated as a template (kernel) to perform correlation filtering on the image feature map. The peak value in the correlation heatmap indicates the center points of the target box. In addition, RCCF also regresses a 2-D object size and 2-D offset. The center point coordinates, object size and center point offset together form the target bounding-box. Our method runs at 40 FPS while achieves leading performance in RefClef, RefCOCO, RefCOCO+, and RefCOCOg benchmarks. In the challenge RefClef dataset, our methods almost double the state-of-the-art performance(34.70% increased to 63.79%). We hope this work can arouse more attention and studies to the new cross-modality correlation filtering framework as well as the one-stage framework for referring expression comprehension.
Robust Model-based Reinforcement Learning for Autonomous Greenhouse Control
Aug 26, 2021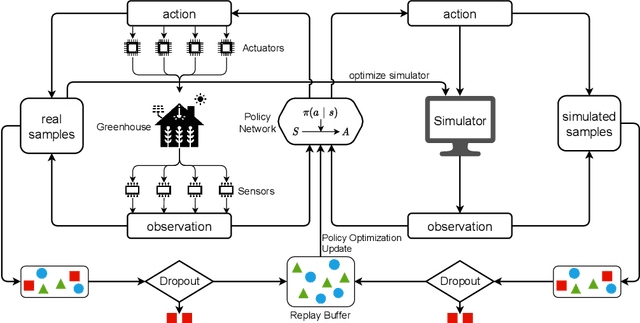
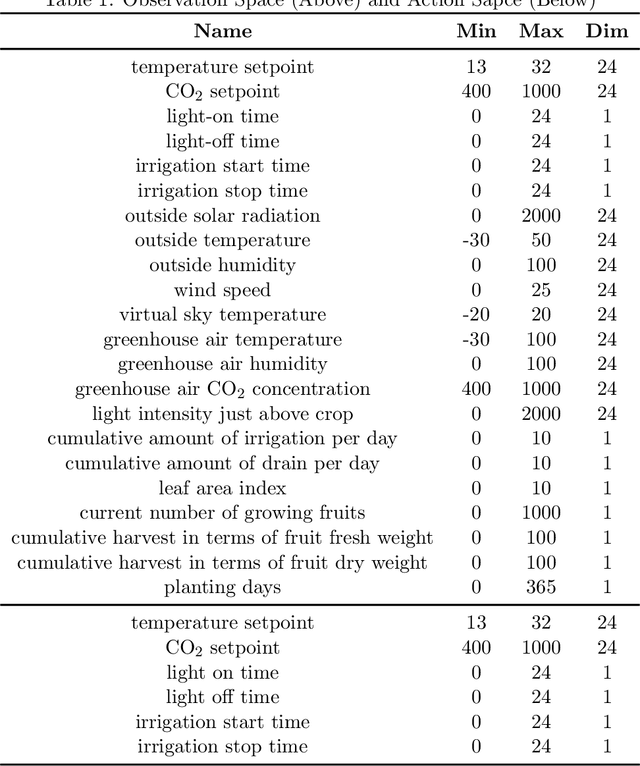

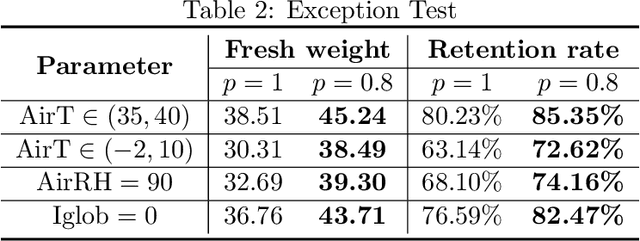
Due to the high efficiency and less weather dependency, autonomous greenhouses provide an ideal solution to meet the increasing demand for fresh food. However, managers are faced with some challenges in finding appropriate control strategies for crop growth, since the decision space of the greenhouse control problem is an astronomical number. Therefore, an intelligent closed-loop control framework is highly desired to generate an automatic control policy. As a powerful tool for optimal control, reinforcement learning (RL) algorithms can surpass human beings' decision-making and can also be seamlessly integrated into the closed-loop control framework. However, in complex real-world scenarios such as agricultural automation control, where the interaction with the environment is time-consuming and expensive, the application of RL algorithms encounters two main challenges, i.e., sample efficiency and safety. Although model-based RL methods can greatly mitigate the efficiency problem of greenhouse control, the safety problem has not got too much attention. In this paper, we present a model-based robust RL framework for autonomous greenhouse control to meet the sample efficiency and safety challenges. Specifically, our framework introduces an ensemble of environment models to work as a simulator and assist in policy optimization, thereby addressing the low sample efficiency problem. As for the safety concern, we propose a sample dropout module to focus more on worst-case samples, which can help improve the adaptability of the greenhouse planting policy in extreme cases. Experimental results demonstrate that our approach can learn a more effective greenhouse planting policy with better robustness than existing methods.
Early fault detection with multi-target neural networks
Jun 12, 2021
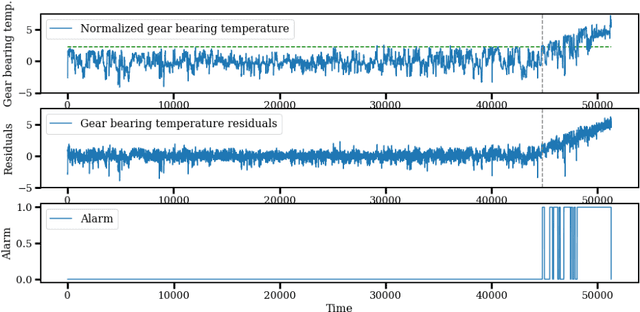
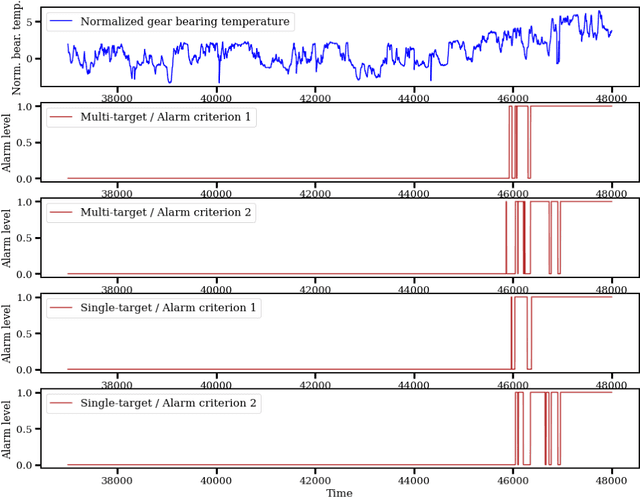
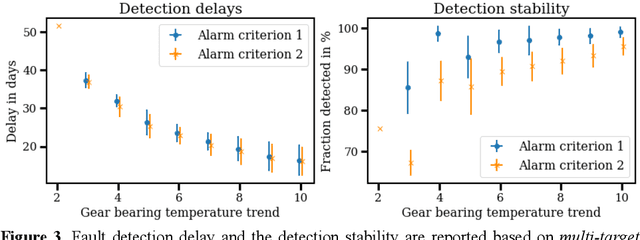
Wind power is seeing a strong growth around the world. At the same time, shrinking profit margins in the energy markets let wind farm managers explore options for cost reductions in the turbine operation and maintenance. Sensor-based condition monitoring facilitates remote diagnostics of turbine subsystems, enabling faster responses when unforeseen maintenance is required. Condition monitoring with data from the turbines' supervisory control and data acquisition (SCADA) systems was proposed and SCADA-based fault detection and diagnosis approaches introduced based on single-task normal operation models of turbine state variables. As the number of SCADA channels has grown strongly, thousands of independent single-target models are in place today for monitoring a single turbine. Multi-target learning was recently proposed to limit the number of models. This study applied multi-target neural networks to the task of early fault detection in drive-train components. The accuracy and delay of detecting gear bearing faults were compared to state-of-the-art single-target approaches. We found that multi-target multi-layer perceptrons (MLPs) detected faults at least as early and in many cases earlier than single-target MLPs. The multi-target MLPs could detect faults up to several days earlier than the single-target models. This can deliver a significant advantage in the planning and performance of maintenance work. At the same time, the multi-target MLPs achieved the same level of prediction stability.
Think Globally, Act Locally: A Deep Neural Network Approach to High-Dimensional Time Series Forecasting
May 09, 2019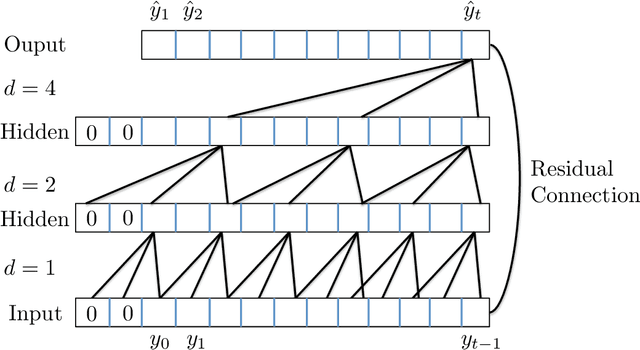
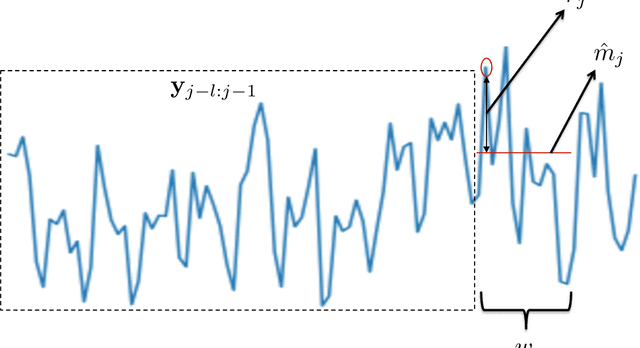

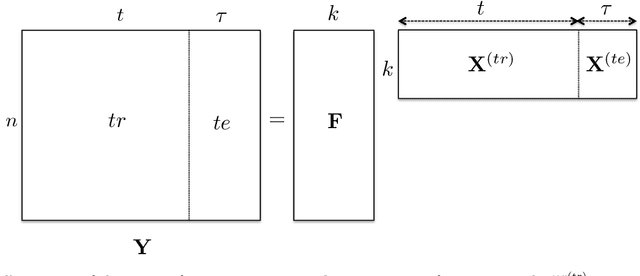
Forecasting high-dimensional time series plays a crucial role in many applications such as demand forecasting and financial predictions. Modern real-world datasets can have millions of correlated time-series that evolve together, i.e they are extremely high dimensional (one dimension for each individual time-series). Thus there is need for exploiting these global patterns and coupling them with local calibration for better prediction. However, most recent deep learning approaches in the literature are one-dimensional, i.e, even though they are trained on the whole dataset, during prediction, the future forecast for a single dimension mainly depends on past values from the same dimension. In this paper, we seek to correct this deficiency and propose DeepGLO, a deep forecasting model which thinks globally and acts locally. In particular, DeepGLO is a hybrid model that combines a global matrix factorization model regularized by a temporal deep network with a local deep temporal model that captures patterns specific to each dimension. The global and local models are combined via a data-driven attention mechanism for each dimension. The proposed deep architecture used is a variation of temporal convolution termed as leveled network which can be trained effectively on high-dimensional but diverse time series, where different time series can have vastly different scales, without a priori normalization or rescaling. Empirical results demonstrate that DeepGLO outperforms state-of-the-art approaches on various datasets; for example, we see more than 30% improvement in WAPE over other methods on a real-world dataset that contains more than 100K-dimensional time series.
Generating Adversarial Examples with Graph Neural Networks
May 30, 2021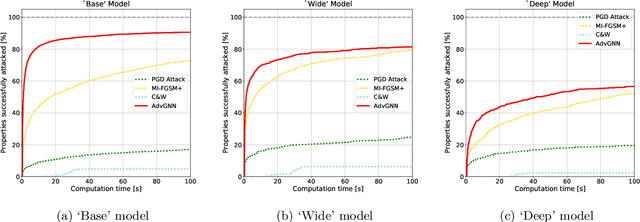
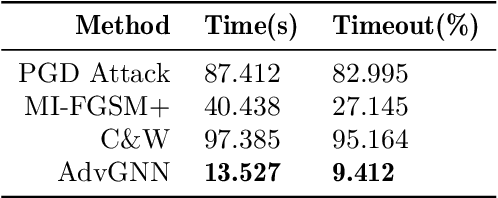
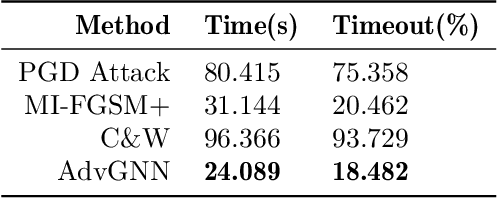
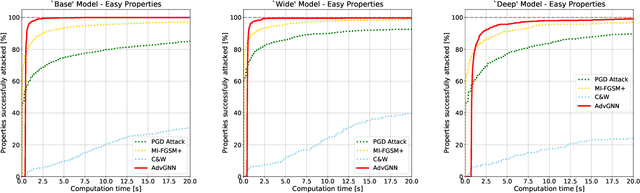
Recent years have witnessed the deployment of adversarial attacks to evaluate the robustness of Neural Networks. Past work in this field has relied on traditional optimization algorithms that ignore the inherent structure of the problem and data, or generative methods that rely purely on learning and often fail to generate adversarial examples where they are hard to find. To alleviate these deficiencies, we propose a novel attack based on a graph neural network (GNN) that takes advantage of the strengths of both approaches; we call it AdvGNN. Our GNN architecture closely resembles the network we wish to attack. During inference, we perform forward-backward passes through the GNN layers to guide an iterative procedure towards adversarial examples. During training, its parameters are estimated via a loss function that encourages the efficient computation of adversarial examples over a time horizon. We show that our method beats state-of-the-art adversarial attacks, including PGD-attack, MI-FGSM, and Carlini and Wagner attack, reducing the time required to generate adversarial examples with small perturbation norms by over 65\%. Moreover, AdvGNN achieves good generalization performance on unseen networks. Finally, we provide a new challenging dataset specifically designed to allow for a more illustrative comparison of adversarial attacks.
Derivative Based Proportionate Approach for Sparse Impulse Response Identification
Jul 08, 2021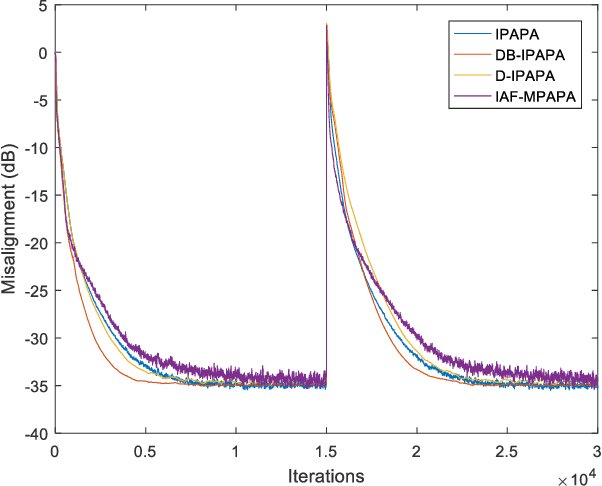
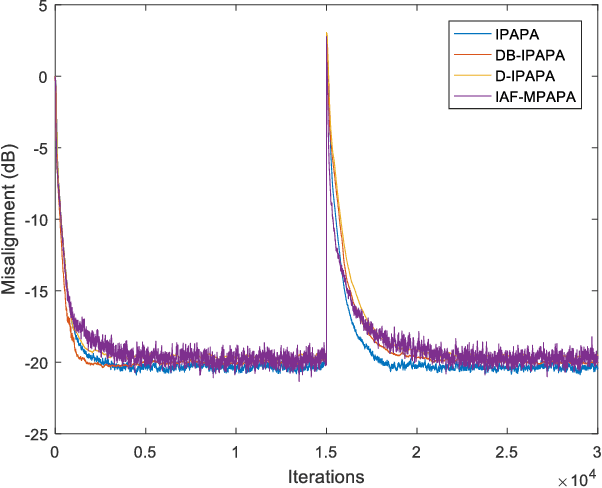
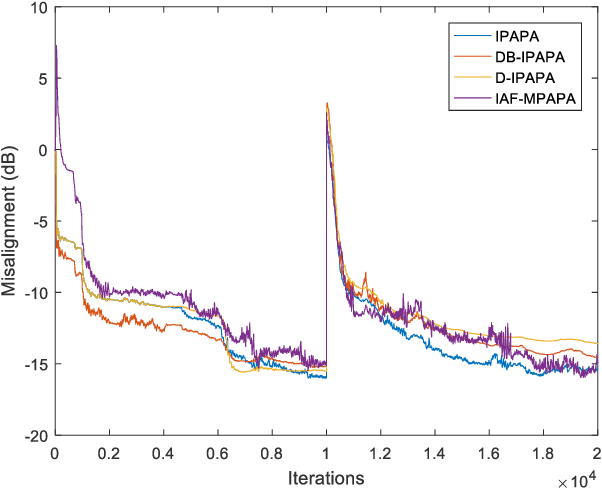
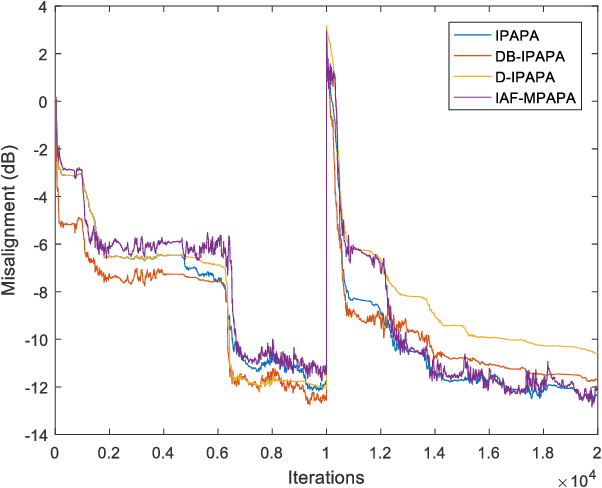
Proportionate type algorithms were developed and excessively used in the echo cancellation problems due to sparse characteristics of the echo channels. In the past, most of the attention was paid to a particular type of proportionate approach, which assigns step-sizes to filter coefficients proportional to the magnitude of the corresponding coefficient. In this letter, we propose a new proportionate type algorithm, which takes dynamic behavior of the estimated filter coefficient into account while assigning individual step-sizes to each coefficient. Proposed algorithm introduces an effective way to assign individual step-sizes using the time derivatives of the filter coefficients. Computational complexity of the proposed algorithm is similar to those of previously proposed algorithms. Simulation results have shown the improvements in the convergence rate achieved by the proposed algorithm.
Neural Scene Decoration from a Single Photograph
Aug 04, 2021
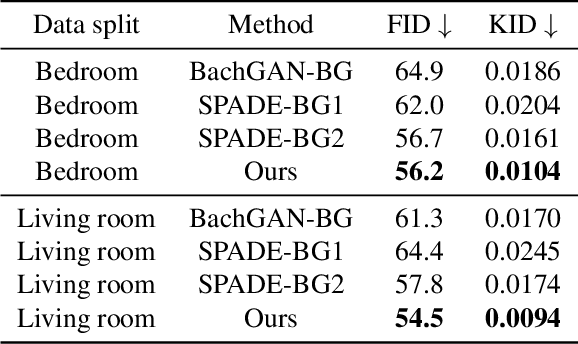
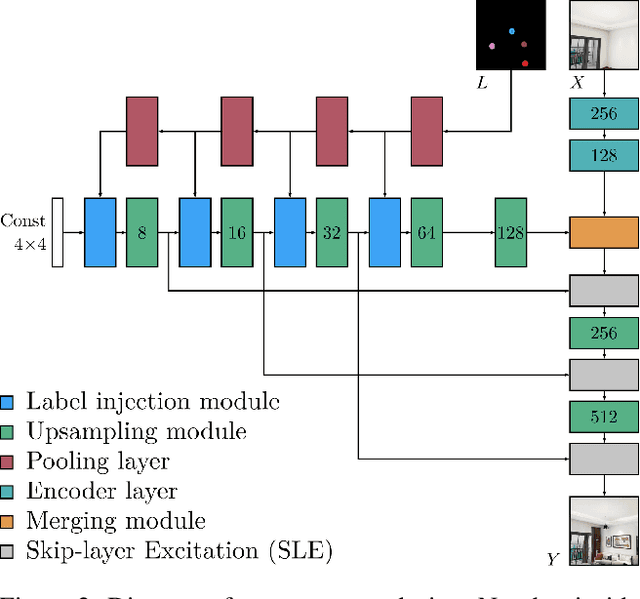
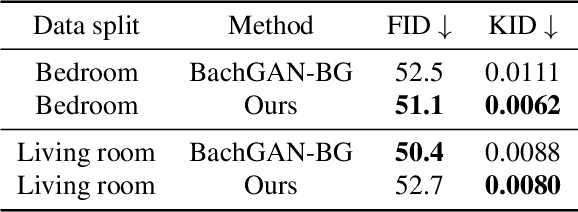
Furnishing and rendering an indoor scene is a common but tedious task for interior design: an artist needs to observe the space, create a conceptual design, build a 3D model, and perform rendering. In this paper, we introduce a new problem of domain-specific image synthesis using generative modeling, namely neural scene decoration. Given a photograph of an empty indoor space, we aim to synthesize a new image of the same space that is fully furnished and decorated. Neural scene decoration can be applied in practice to efficiently generate conceptual but realistic interior designs, bypassing the traditional multi-step and time-consuming pipeline. Our attempt to neural scene decoration in this paper is a generative adversarial neural network that takes the input photograph and directly produce the image of the desired furnishing and decorations. Our network contains a novel image generator that transforms an initial point-based object layout into a realistic photograph. We demonstrate the performance of our proposed method by showing that it outperforms the baselines built upon previous works on image translations both qualitatively and quantitatively. Our user study further validates the plausibility and aesthetics in the generated designs.
Emotion Stimulus Detection in German News Headlines
Jul 28, 2021
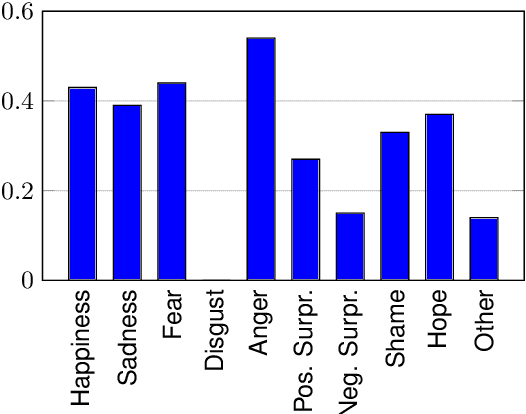
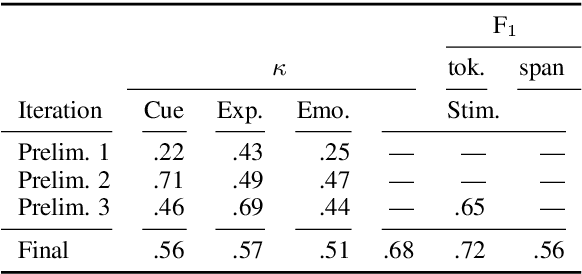
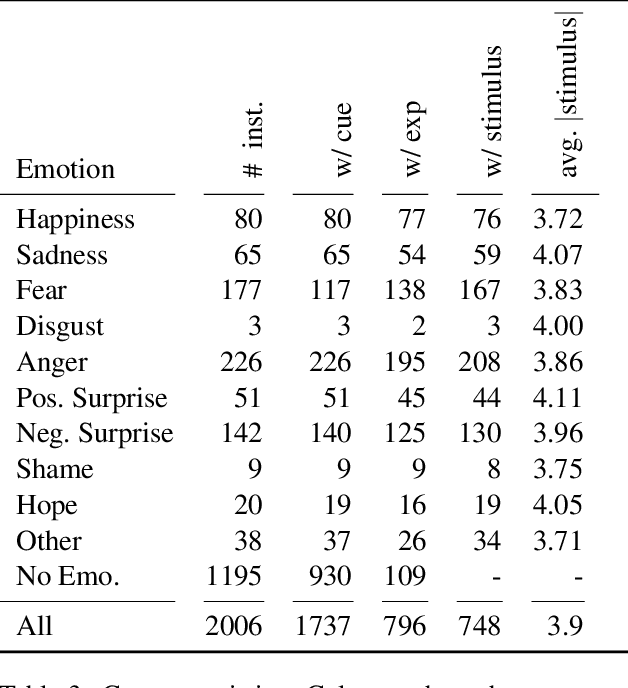
Emotion stimulus extraction is a fine-grained subtask of emotion analysis that focuses on identifying the description of the cause behind an emotion expression from a text passage (e.g., in the sentence "I am happy that I passed my exam" the phrase "passed my exam" corresponds to the stimulus.). Previous work mainly focused on Mandarin and English, with no resources or models for German. We fill this research gap by developing a corpus of 2006 German news headlines annotated with emotions and 811 instances with annotations of stimulus phrases. Given that such corpus creation efforts are time-consuming and expensive, we additionally work on an approach for projecting the existing English GoodNewsEveryone (GNE) corpus to a machine-translated German version. We compare the performance of a conditional random field (CRF) model (trained monolingually on German and cross-lingually via projection) with a multilingual XLM-RoBERTa (XLM-R) model. Our results show that training with the German corpus achieves higher F1 scores than projection. Experiments with XLM-R outperform their respective CRF counterparts.