 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Very Power Efficient Neural Time-of-Flight
Dec 19, 2018


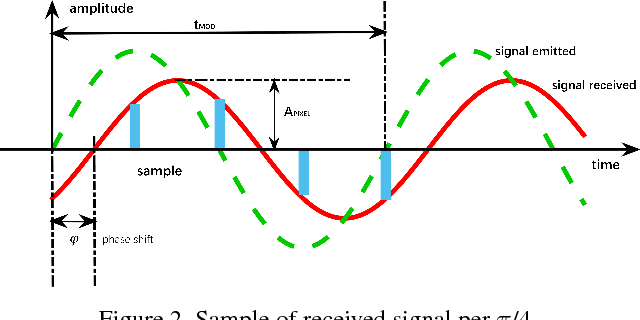
Time-of-Flight (ToF) cameras require active illumination to obtain depth information thus the power of illumination directly affects the performance of ToF cameras. Traditional ToF imaging algorithms is very sensitive to illumination and the depth accuracy degenerates rapidly with the power of it. Therefore, the design of a power efficient ToF camera always creates a painful dilemma for the illumination and the performance trade-off. In this paper, we show that despite the weak signals in many areas under extreme short exposure setting, these signals as a whole can be well utilized through a learning process which directly translates the weak and noisy ToF camera raw to depth map. This creates an opportunity to tackle the aforementioned dilemma and make a very power efficient ToF camera possible. To enable the learning, we collect a comprehensive dataset under a variety of scenes and photographic conditions by a specialized ToF camera. Experiments show that our method is able to robustly process ToF camera raw with the exposure time of one order of magnitude shorter than that used in conventional ToF cameras. In addition to evaluating our approach both quantitatively and qualitatively, we also discuss its implication to designing the next generation power efficient ToF cameras. We will make our dataset and code publicly available.
MSU-Net: Multiscale Statistical U-Net for Real-time 3D Cardiac MRI Video Segmentation
Sep 15, 2019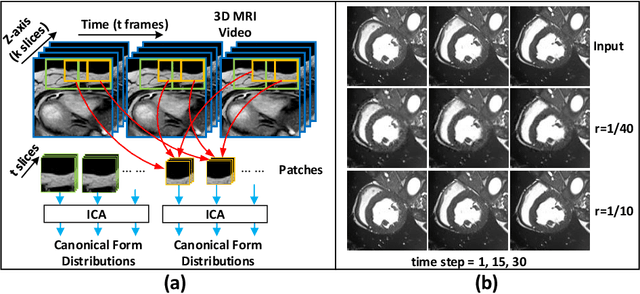
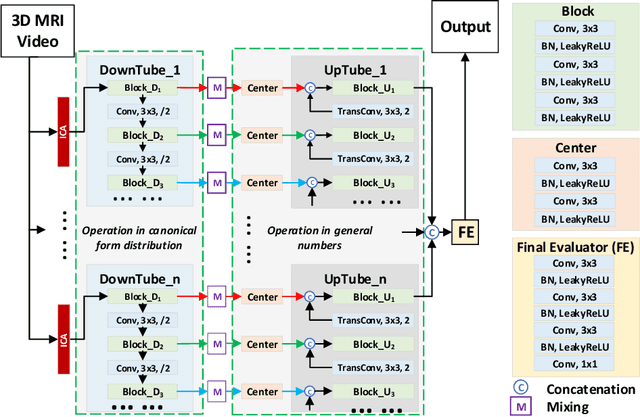
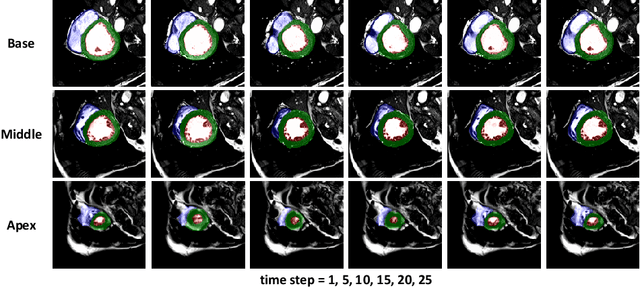
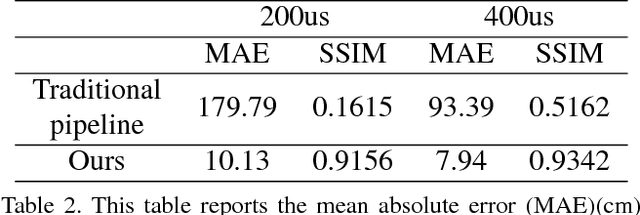
Cardiac magnetic resonance imaging (MRI) is an essential tool for MRI-guided surgery and real-time intervention. The MRI videos are expected to be segmented on-the-fly in real practice. However, existing segmentation methods would suffer from drastic accuracy loss when modified for speedup. In this work, we propose Multiscale Statistical U-Net (MSU-Net) for real-time 3D MRI video segmentation in cardiac surgical guidance. Our idea is to model the input samples as multiscale canonical form distributions for speedup, while the spatio-temporal correlation is still fully utilized. A parallel statistical U-Net is then designed to efficiently process these distributions. The fast data sampling and efficient parallel structure of MSU-Net endorse the fast and accurate inference. Compared with vanilla U-Net and a modified state-of-the-art method GridNet, our method achieves up to 268% and 237% speedup with 1.6% and 3.6% increased Dice scores.
Connect the Dots: In Situ 4D Seismic Monitoring of CO$_2$ Storage with Spatio-temporal CNNs
May 25, 2021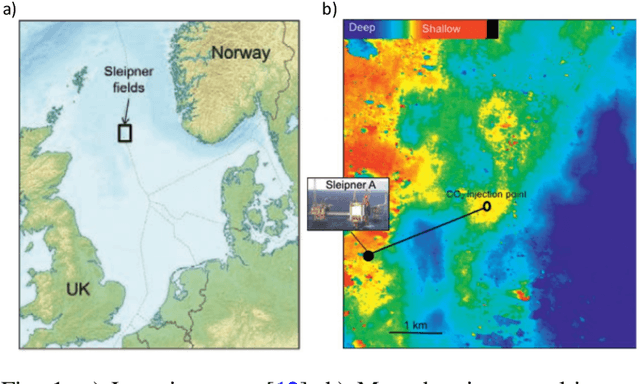

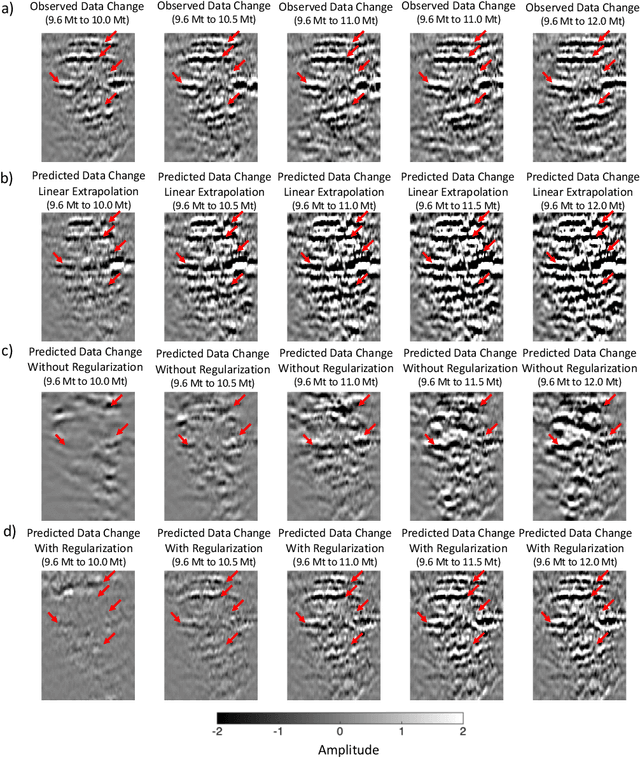
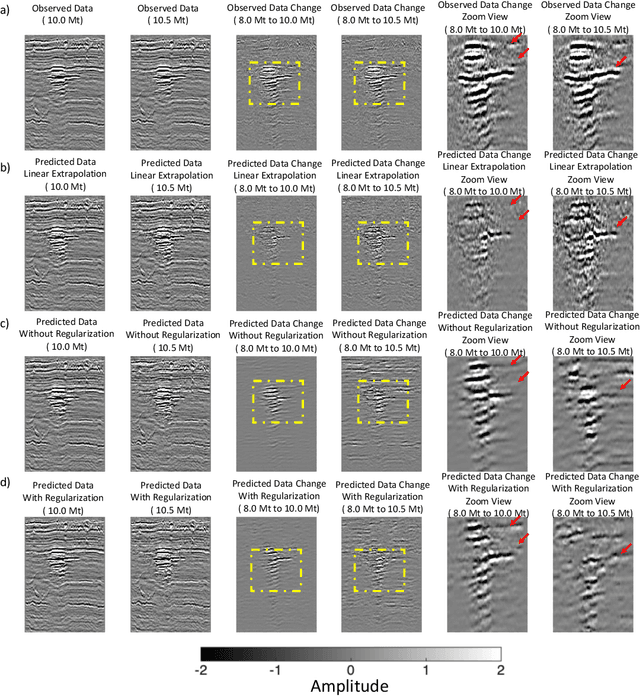
4D seismic imaging has been widely used in CO$_2$ sequestration projects to monitor the fluid flow in the volumetric subsurface region that is not sampled by wells. Ideally, real-time monitoring and near-future forecasting would provide site operators with great insights to understand the dynamics of the subsurface reservoir and assess any potential risks. However, due to obstacles such as high deployment cost, availability of acquisition equipment, exclusion zones around surface structures, only very sparse seismic imaging data can be obtained during monitoring. That leads to an unavoidable and growing knowledge gap over time. The operator needs to understand the fluid flow throughout the project lifetime and the seismic data are only available at a limited number of times, this is insufficient for understanding the reservoir behavior. To overcome those challenges, we have developed spatio-temporal neural-network-based models that can produce high-fidelity interpolated or extrapolated images effectively and efficiently. Specifically, our models are built on an autoencoder, and incorporate the long short-term memory (LSTM) structure with a new loss function regularized by optical flow. We validate the performance of our models using real 4D post-stack seismic imaging data acquired at the Sleipner CO$_2$ sequestration field. We employ two different strategies in evaluating our models. Numerically, we compare our models with different baseline approaches using classic pixel-based metrics. We also conduct a blind survey and collect a total of 20 responses from domain experts to evaluate the quality of data generated by our models. Via both numerical and expert evaluation, we conclude that our models can produce high-quality 2D/3D seismic imaging data at a reasonable cost, offering the possibility of real-time monitoring or even near-future forecasting of the CO$_2$ storage reservoir.
Efficient Federated Meta-Learning over Multi-Access Wireless Networks
Aug 17, 2021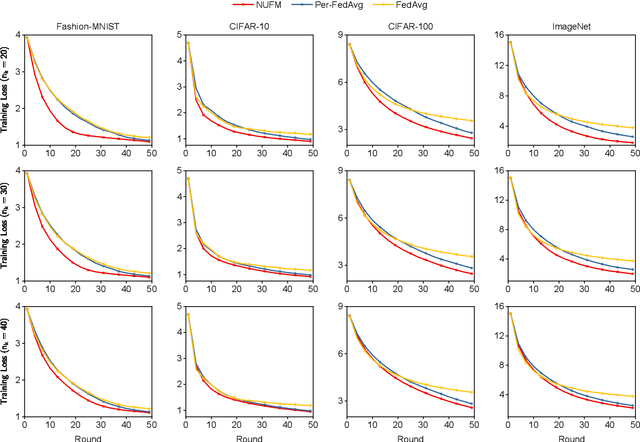
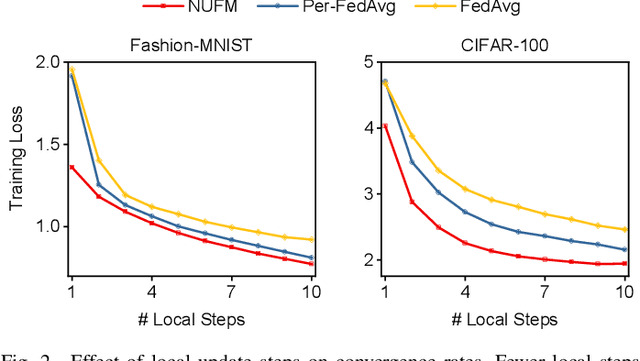
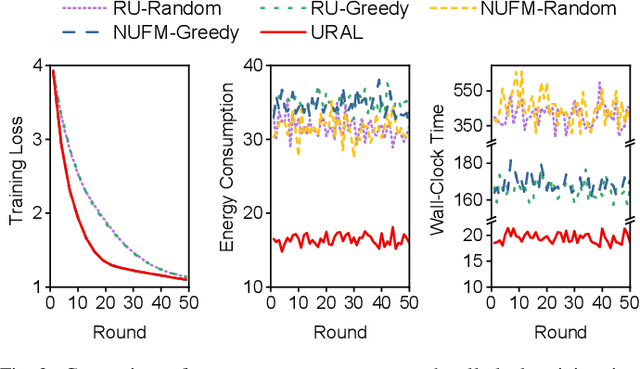
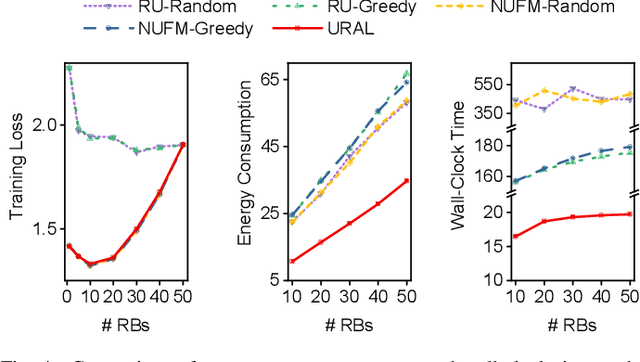
Federated meta-learning (FML) has emerged as a promising paradigm to cope with the data limitation and heterogeneity challenges in today's edge learning arena. However, its performance is often limited by slow convergence and corresponding low communication efficiency. In addition, since the available radio spectrum and IoT devices' energy capacity are usually insufficient, it is crucial to control the resource allocation and energy consumption when deploying FML in practical wireless networks. To overcome the challenges, in this paper, we rigorously analyze each device's contribution to the global loss reduction in each round and develop an FML algorithm (called NUFM) with a non-uniform device selection scheme to accelerate the convergence. After that, we formulate a resource allocation problem integrating NUFM in multi-access wireless systems to jointly improve the convergence rate and minimize the wall-clock time along with energy cost. By deconstructing the original problem step by step, we devise a joint device selection and resource allocation strategy to solve the problem with theoretical guarantees. Further, we show that the computational complexity of NUFM can be reduced from $O(d^2)$ to $O(d)$ (with the model dimension $d$) via combining two first-order approximation techniques. Extensive simulation results demonstrate the effectiveness and superiority of the proposed methods in comparison with existing baselines.
Cross-Sentence Temporal and Semantic Relations in Video Activity Localisation
Aug 17, 2021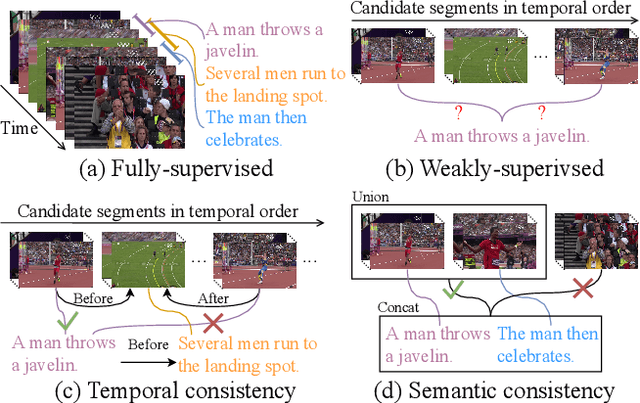
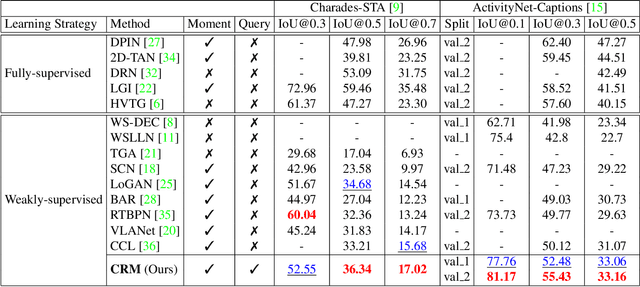
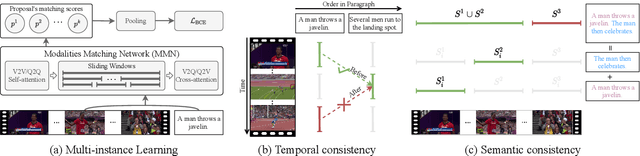
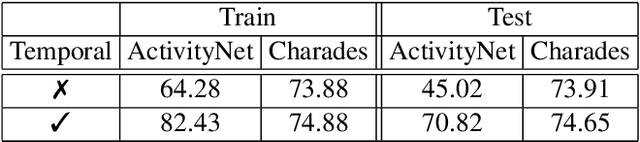
Video activity localisation has recently attained increasing attention due to its practical values in automatically localising the most salient visual segments corresponding to their language descriptions (sentences) from untrimmed and unstructured videos. For supervised model training, a temporal annotation of both the start and end time index of each video segment for a sentence (a video moment) must be given. This is not only very expensive but also sensitive to ambiguity and subjective annotation bias, a much harder task than image labelling. In this work, we develop a more accurate weakly-supervised solution by introducing Cross-Sentence Relations Mining (CRM) in video moment proposal generation and matching when only a paragraph description of activities without per-sentence temporal annotation is available. Specifically, we explore two cross-sentence relational constraints: (1) Temporal ordering and (2) semantic consistency among sentences in a paragraph description of video activities. Existing weakly-supervised techniques only consider within-sentence video segment correlations in training without considering cross-sentence paragraph context. This can mislead due to ambiguous expressions of individual sentences with visually indiscriminate video moment proposals in isolation. Experiments on two publicly available activity localisation datasets show the advantages of our approach over the state-of-the-art weakly supervised methods, especially so when the video activity descriptions become more complex.
Task-Specific Normalization for Continual Learning of Blind Image Quality Models
Jul 28, 2021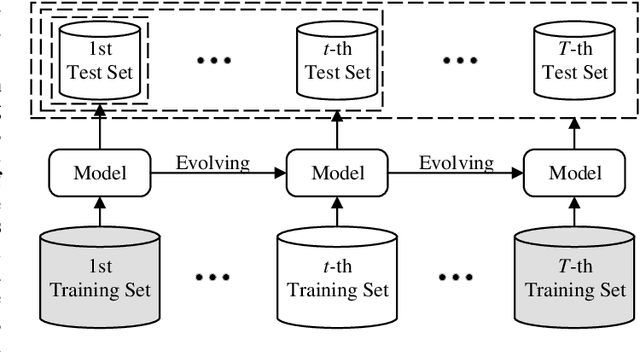
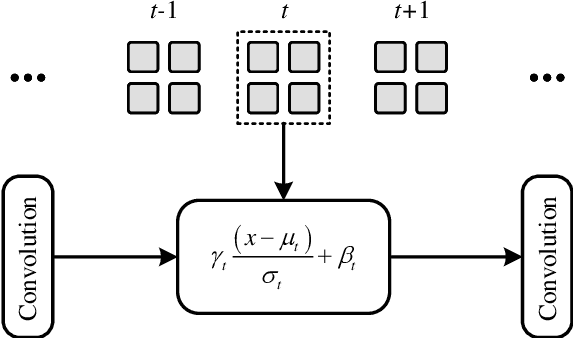
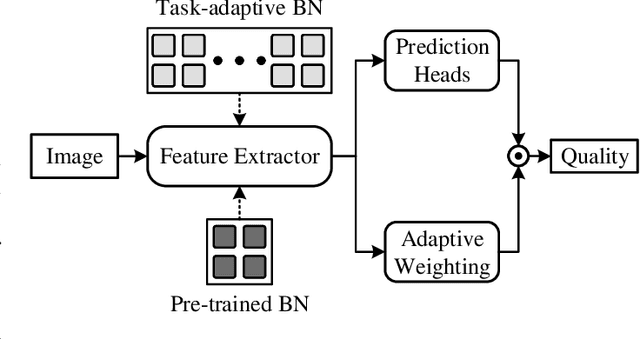
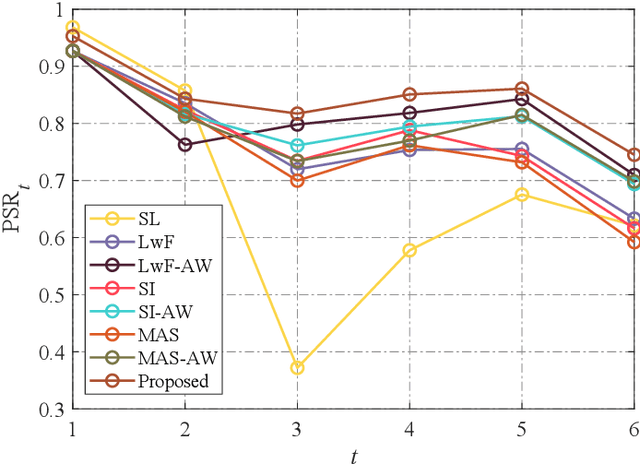
The computational vision community has recently paid attention to continual learning for blind image quality assessment (BIQA). The primary challenge is to combat catastrophic forgetting of previously-seen IQA datasets (i.e., tasks). In this paper, we present a simple yet effective continual learning method for BIQA with improved quality prediction accuracy, plasticity-stability trade-off, and task-order/length robustness. The key step in our approach is to freeze all convolution filters of a pre-trained deep neural network (DNN) for an explicit promise of stability, and learn task-specific normalization parameters for plasticity. We assign each new task a prediction head, and load the corresponding normalization parameters to produce a quality score. The final quality estimate is computed by feature fusion and adaptive weighting using hierarchical representations, without leveraging the test-time oracle. Extensive experiments on six IQA datasets demonstrate the advantages of the proposed method in comparison to previous training techniques for BIQA.
Deep Learning Classification of Lake Zooplankton
Aug 11, 2021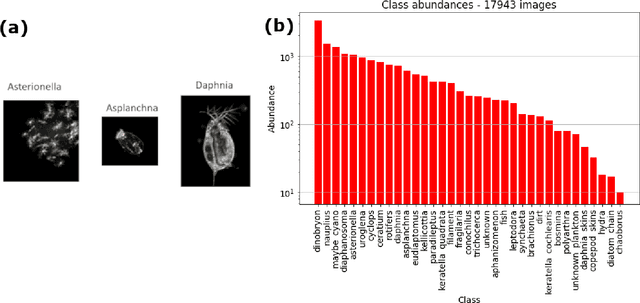
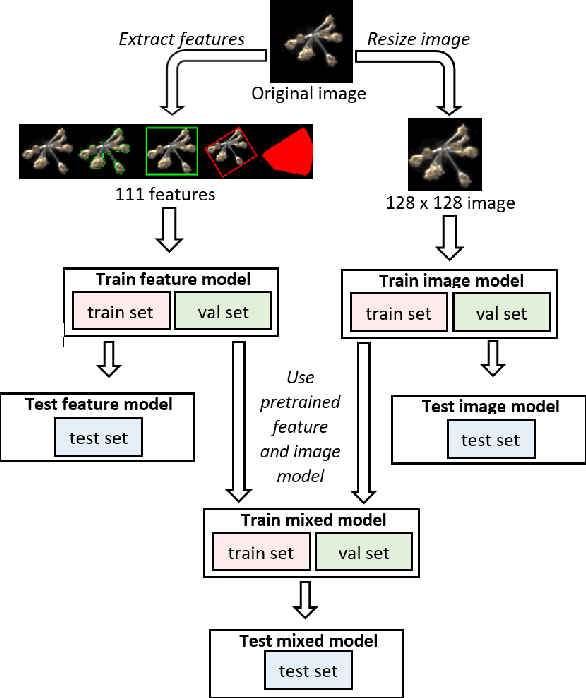
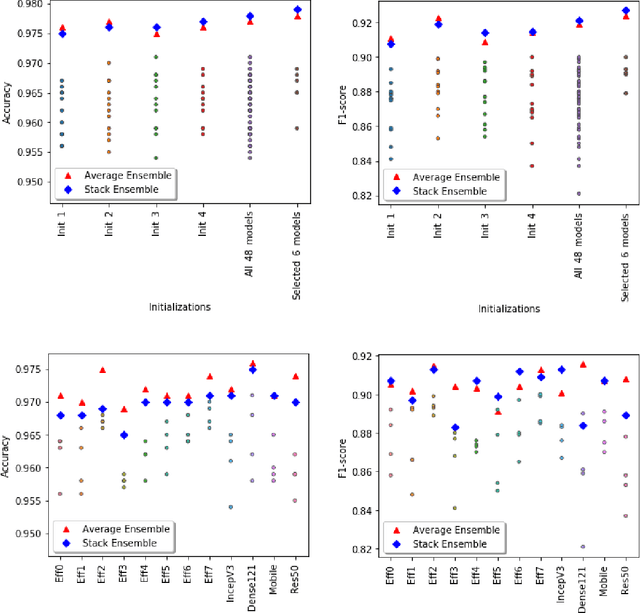
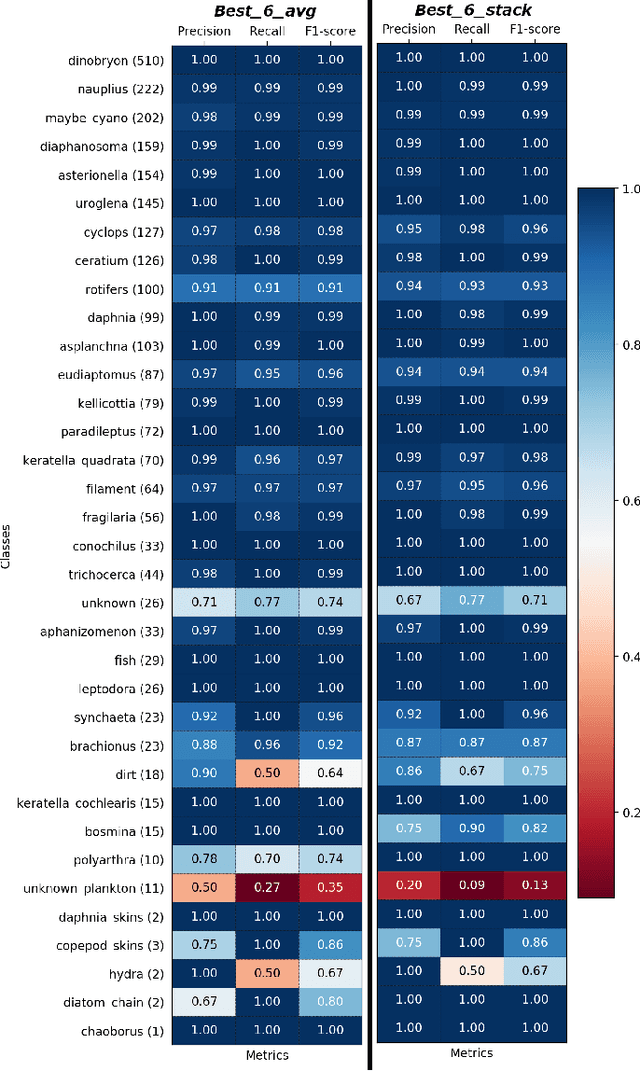
Plankton are effective indicators of environmental change and ecosystem health in freshwater habitats, but collection of plankton data using manual microscopic methods is extremely labor-intensive and expensive. Automated plankton imaging offers a promising way forward to monitor plankton communities with high frequency and accuracy in real-time. Yet, manual annotation of millions of images proposes a serious challenge to taxonomists. Deep learning classifiers have been successfully applied in various fields and provided encouraging results when used to categorize marine plankton images. Here, we present a set of deep learning models developed for the identification of lake plankton, and study several strategies to obtain optimal performances,which lead to operational prescriptions for users. To this aim, we annotated into 35 classes over 17900 images of zooplankton and large phytoplankton colonies, detected in Lake Greifensee (Switzerland) with the Dual Scripps Plankton Camera. Our best models were based on transfer learning and ensembling, which classified plankton images with 98% accuracy and 93% F1 score. When tested on freely available plankton datasets produced by other automated imaging tools (ZooScan, FlowCytobot and ISIIS), our models performed better than previously used models. Our annotated data, code and classification models are freely available online.
Layer Flexible Adaptive Computational Time for Recurrent Neural Networks
Dec 14, 2018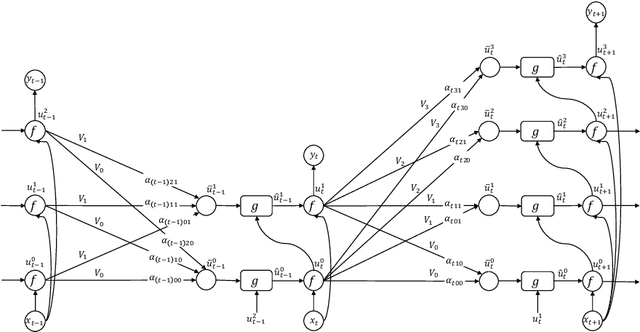
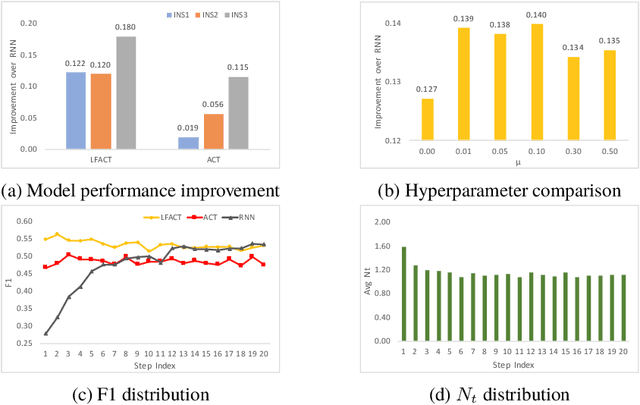
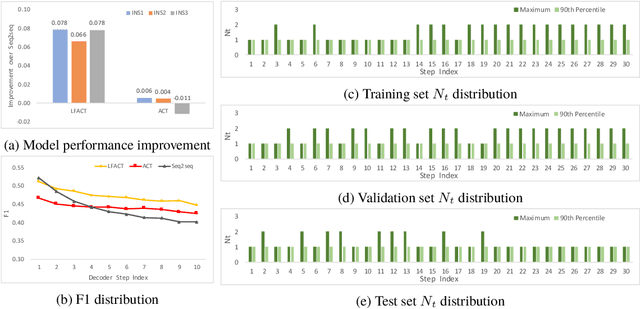
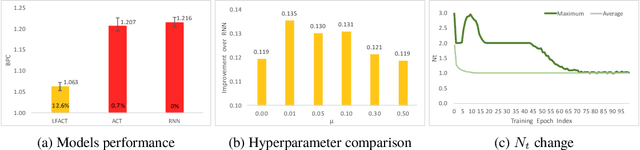
Deep recurrent neural networks perform well on sequence data and are the model of choice. It is a daunting task to decide the number of layers, especially considering different computational needs for tasks within a sequence of different difficulties. We propose a layer flexible recurrent neural network with adaptive computational time, and expand it to a sequence to sequence model. Contrary to the adaptive computational time model, our model has a dynamic number of transmission states which vary by step and sequence. We evaluate the model on a financial dataset. Experimental results show the performance improvement and indicate the model's ability to dynamically change the number of layers.
Improved Speech Emotion Recognition using Transfer Learning and Spectrogram Augmentation
Aug 11, 2021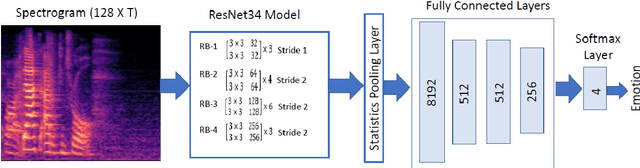
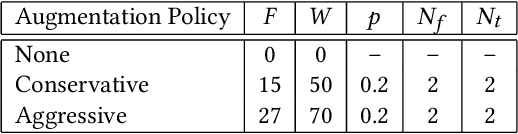
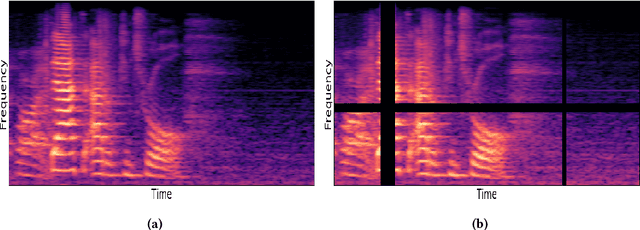
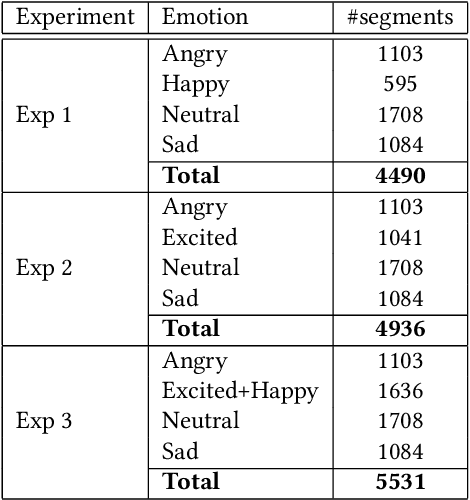
Automatic speech emotion recognition (SER) is a challenging task that plays a crucial role in natural human-computer interaction. One of the main challenges in SER is data scarcity, i.e., insufficient amounts of carefully labeled data to build and fully explore complex deep learning models for emotion classification. This paper aims to address this challenge using a transfer learning strategy combined with spectrogram augmentation. Specifically, we propose a transfer learning approach that leverages a pre-trained residual network (ResNet) model including a statistics pooling layer from speaker recognition trained using large amounts of speaker-labeled data. The statistics pooling layer enables the model to efficiently process variable-length input, thereby eliminating the need for sequence truncation which is commonly used in SER systems. In addition, we adopt a spectrogram augmentation technique to generate additional training data samples by applying random time-frequency masks to log-mel spectrograms to mitigate overfitting and improve the generalization of emotion recognition models. We evaluate the effectiveness of our proposed approach on the interactive emotional dyadic motion capture (IEMOCAP) dataset. Experimental results indicate that the transfer learning and spectrogram augmentation approaches improve the SER performance, and when combined achieve state-of-the-art results.
TimeLens: Event-based Video Frame Interpolation
Jun 14, 2021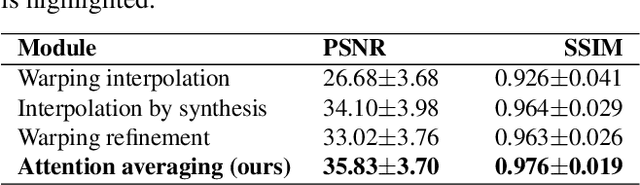
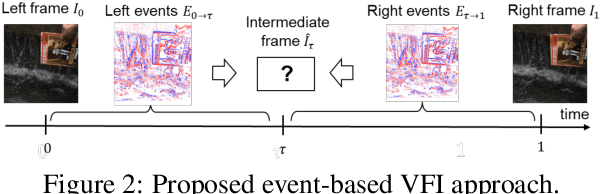
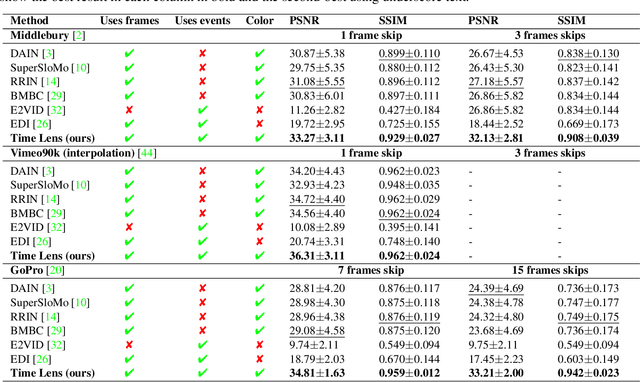
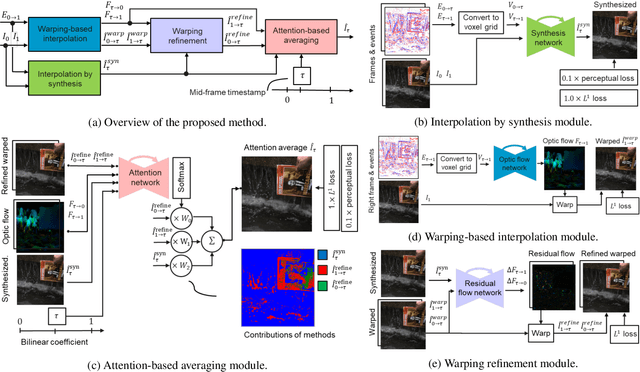
State-of-the-art frame interpolation methods generate intermediate frames by inferring object motions in the image from consecutive key-frames. In the absence of additional information, first-order approximations, i.e. optical flow, must be used, but this choice restricts the types of motions that can be modeled, leading to errors in highly dynamic scenarios. Event cameras are novel sensors that address this limitation by providing auxiliary visual information in the blind-time between frames. They asynchronously measure per-pixel brightness changes and do this with high temporal resolution and low latency. Event-based frame interpolation methods typically adopt a synthesis-based approach, where predicted frame residuals are directly applied to the key-frames. However, while these approaches can capture non-linear motions they suffer from ghosting and perform poorly in low-texture regions with few events. Thus, synthesis-based and flow-based approaches are complementary. In this work, we introduce Time Lens, a novel indicates equal contribution method that leverages the advantages of both. We extensively evaluate our method on three synthetic and two real benchmarks where we show an up to 5.21 dB improvement in terms of PSNR over state-of-the-art frame-based and event-based methods. Finally, we release a new large-scale dataset in highly dynamic scenarios, aimed at pushing the limits of existing methods.