 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
FDDWNet: A Lightweight Convolutional Neural Network for Real-time Sementic Segmentation
Nov 08, 2019
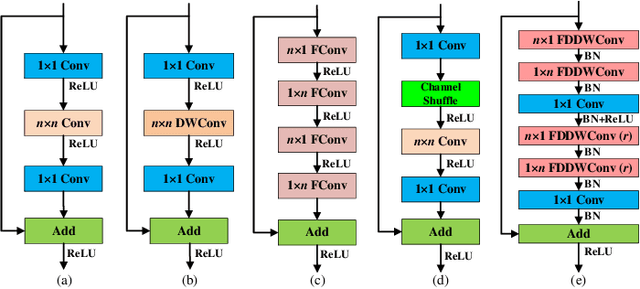
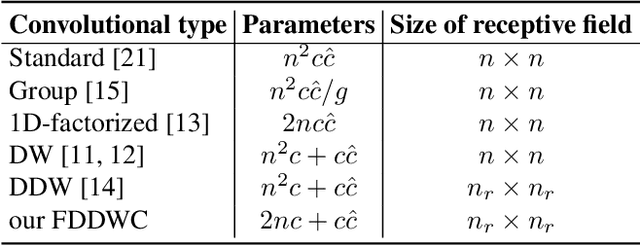
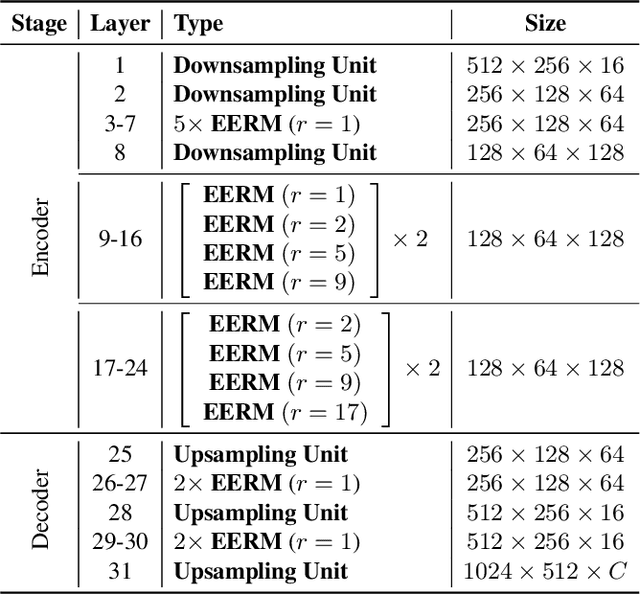

This paper introduces a lightweight convolutional neural network, called FDDWNet, for real-time accurate semantic segmentation. In contrast to recent advances of lightweight networks that prefer to utilize shallow structure, FDDWNet makes an effort to design more deeper network architecture, while maintains faster inference speed and higher segmentation accuracy. Our network uses factorized dilated depth-wise separable convolutions (FDDWC) to learn feature representations from different scale receptive fields with fewer model parameters. Additionally, FDDWNet has multiple branches of skipped connections to gather context cues from intermediate convolution layers. The experiments show that FDDWNet only has 0.8M model size, while achieves 60 FPS running speed on a single RTX 2080Ti GPU with a 1024x512 input image. The comprehensive experiments demonstrate that our model achieves state-of-the-art results in terms of available speed and accuracy trade-off on CityScapes and CamVid datasets.
DeepPlastic: A Novel Approach to Detecting Epipelagic Bound Plastic Using Deep Visual Models
May 05, 2021

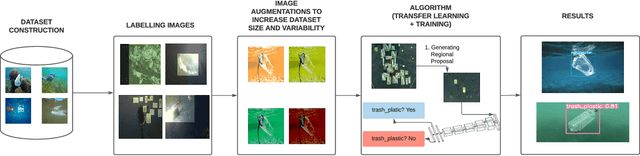

The quantification of positively buoyant marine plastic debris is critical to understanding how concentrations of trash from across the world's ocean and identifying high concentration garbage hotspots in dire need of trash removal. Currently, the most common monitoring method to quantify floating plastic requires the use of a manta trawl. Techniques requiring manta trawls (or similar surface collection devices) utilize physical removal of marine plastic debris as the first step and then analyze collected samples as a second step. The need for physical removal before analysis incurs high costs and requires intensive labor preventing scalable deployment of a real-time marine plastic monitoring service across the entirety of Earth's ocean bodies. Without better monitoring and sampling methods, the total impact of plastic pollution on the environment as a whole, and details of impact within specific oceanic regions, will remain unknown. This study presents a highly scalable workflow that utilizes images captured within the epipelagic layer of the ocean as an input. It produces real-time quantification of marine plastic debris for accurate quantification and physical removal. The workflow includes creating and preprocessing a domain-specific dataset, building an object detection model utilizing a deep neural network, and evaluating the model's performance. YOLOv5-S was the best performing model, which operates at a Mean Average Precision (mAP) of 0.851 and an F1-Score of 0.89 while maintaining near-real-time speed.
Robust Factorization of Real-world Tensor Streams with Patterns, Missing Values, and Outliers
Feb 16, 2021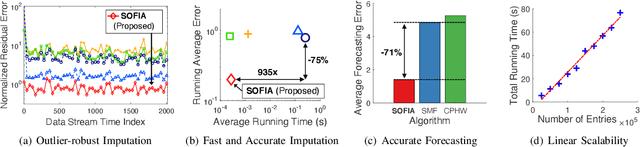
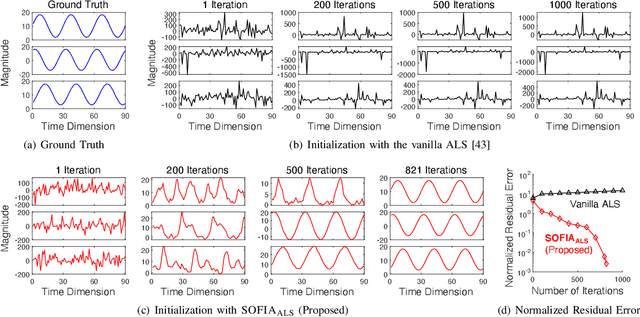
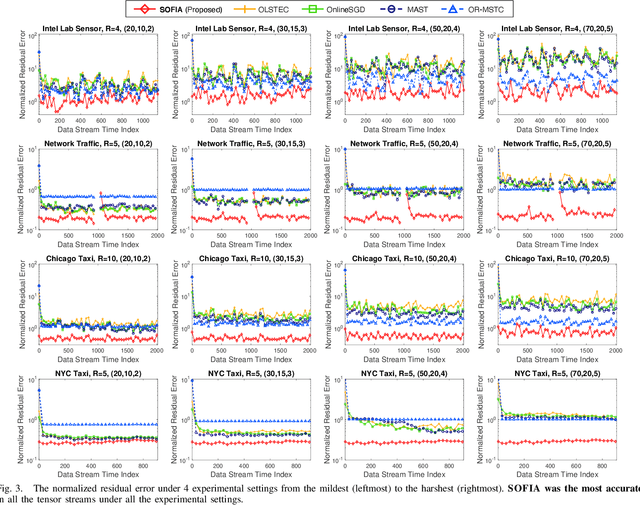
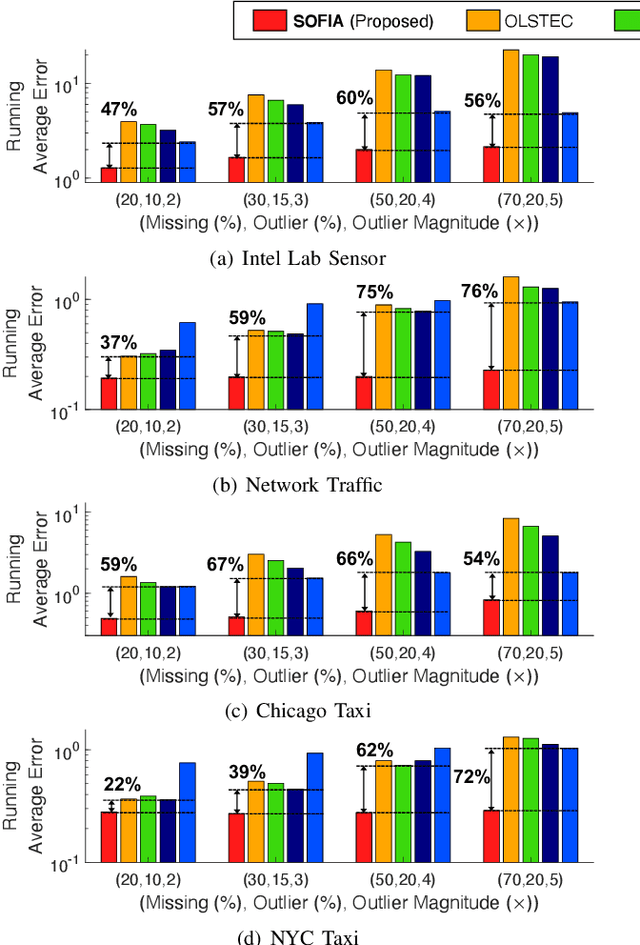
Consider multiple seasonal time series being collected in real-time, in the form of a tensor stream. Real-world tensor streams often include missing entries (e.g., due to network disconnection) and at the same time unexpected outliers (e.g., due to system errors). Given such a real-world tensor stream, how can we estimate missing entries and predict future evolution accurately in real-time? In this work, we answer this question by introducing SOFIA, a robust factorization method for real-world tensor streams. In a nutshell, SOFIA smoothly and tightly integrates tensor factorization, outlier removal, and temporal-pattern detection, which naturally reinforce each other. Moreover, SOFIA integrates them in linear time, in an online manner, despite the presence of missing entries. We experimentally show that SOFIA is (a) robust and accurate: yielding up to 76% lower imputation error and 71% lower forecasting error; (b) fast: up to 935X faster than the second-most accurate competitor; and (c) scalable: scaling linearly with the number of new entries per time step.
GDP: Stabilized Neural Network Pruning via Gates with Differentiable Polarization
Sep 08, 2021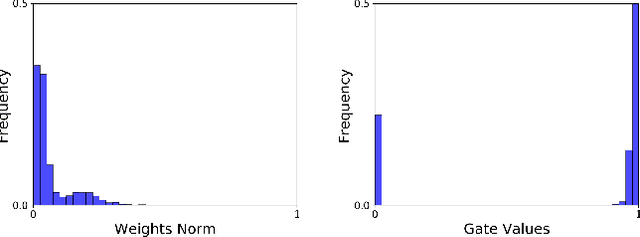

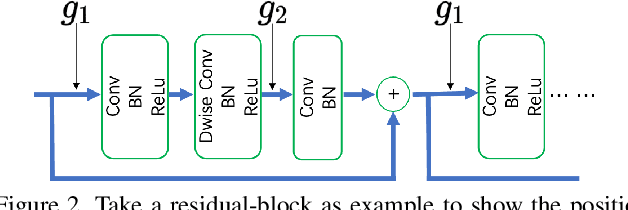
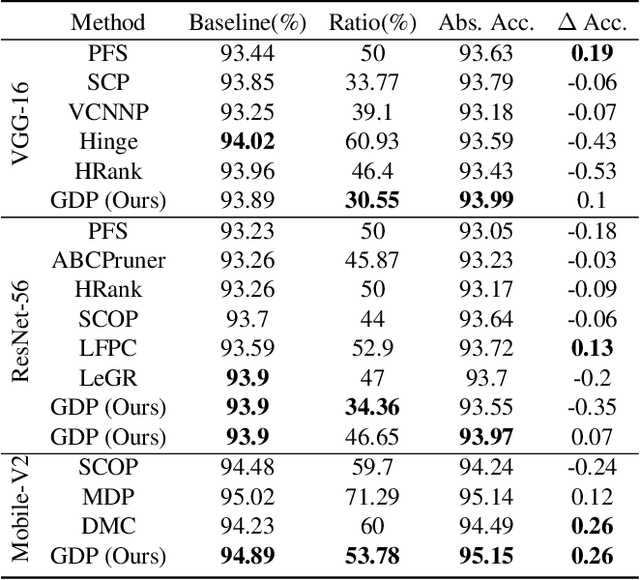
Model compression techniques are recently gaining explosive attention for obtaining efficient AI models for various real-time applications. Channel pruning is one important compression strategy and is widely used in slimming various DNNs. Previous gate-based or importance-based pruning methods aim to remove channels whose importance is smallest. However, it remains unclear what criteria the channel importance should be measured on, leading to various channel selection heuristics. Some other sampling-based pruning methods deploy sampling strategies to train sub-nets, which often causes the training instability and the compressed model's degraded performance. In view of the research gaps, we present a new module named Gates with Differentiable Polarization (GDP), inspired by principled optimization ideas. GDP can be plugged before convolutional layers without bells and whistles, to control the on-and-off of each channel or whole layer block. During the training process, the polarization effect will drive a subset of gates to smoothly decrease to exact zero, while other gates gradually stay away from zero by a large margin. When training terminates, those zero-gated channels can be painlessly removed, while other non-zero gates can be absorbed into the succeeding convolution kernel, causing completely no interruption to training nor damage to the trained model. Experiments conducted over CIFAR-10 and ImageNet datasets show that the proposed GDP algorithm achieves the state-of-the-art performance on various benchmark DNNs at a broad range of pruning ratios. We also apply GDP to DeepLabV3Plus-ResNet50 on the challenging Pascal VOC segmentation task, whose test performance sees no drop (even slightly improved) with over 60% FLOPs saving.
Dual-Tuning: Joint Prototype Transfer and Structure Regularization for Compatible Feature Learning
Aug 06, 2021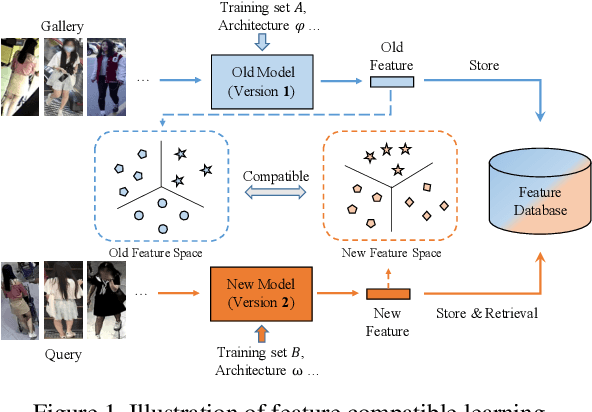
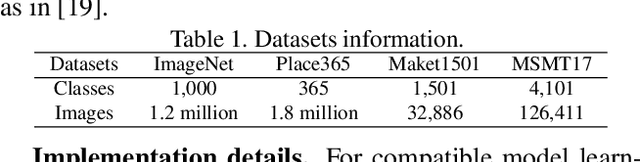
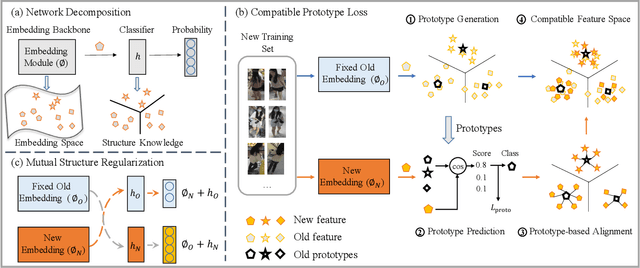
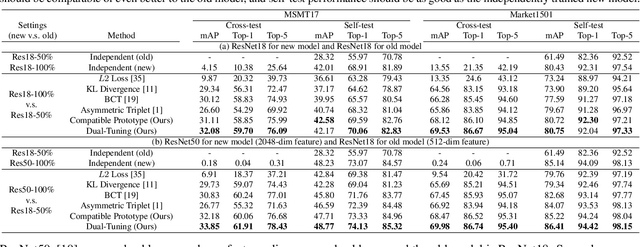
Visual retrieval system faces frequent model update and deployment. It is a heavy workload to re-extract features of the whole database every time.Feature compatibility enables the learned new visual features to be directly compared with the old features stored in the database. In this way, when updating the deployed model, we can bypass the inflexible and time-consuming feature re-extraction process. However, the old feature space that needs to be compatible is not ideal and faces the distribution discrepancy problem with the new space caused by different supervision losses. In this work, we propose a global optimization Dual-Tuning method to obtain feature compatibility against different networks and losses. A feature-level prototype loss is proposed to explicitly align two types of embedding features, by transferring global prototype information. Furthermore, we design a component-level mutual structural regularization to implicitly optimize the feature intrinsic structure. Experimental results on million-scale datasets demonstrate that our Dual-Tuning is able to obtain feature compatibility without sacrificing performance. (Our code will be avaliable at https://github.com/yanbai1993/Dual-Tuning)
Efficient Active Search for Combinatorial Optimization Problems
Jun 09, 2021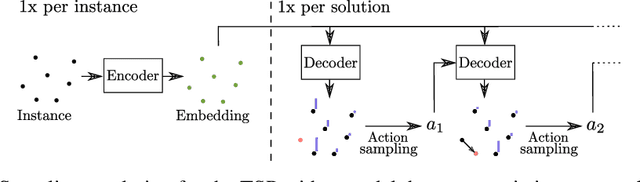
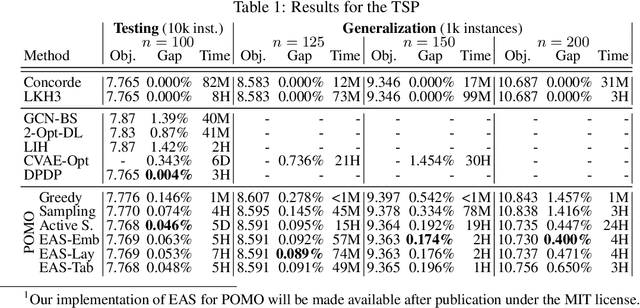
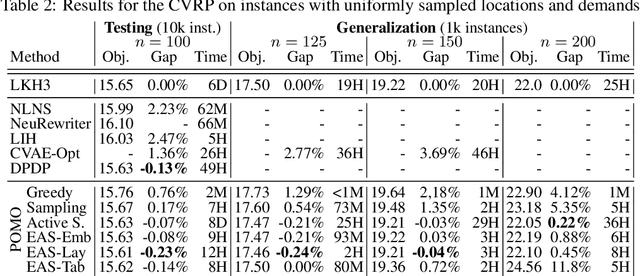
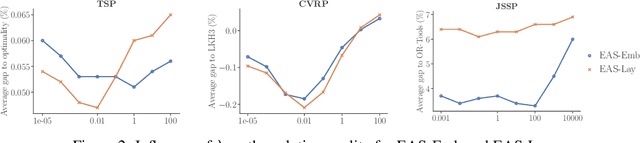
Recently numerous machine learning based methods for combinatorial optimization problems have been proposed that learn to construct solutions in a sequential decision process via reinforcement learning. While these methods can be easily combined with search strategies like sampling and beam search, it is not straightforward to integrate them into a high-level search procedure offering strong search guidance. Bello et al. (2016) propose active search, which adjusts the weights of a (trained) model with respect to a single instance at test time using reinforcement learning. While active search is simple to implement, it is not competitive with state-of-the-art methods because adjusting all model weights for each test instance is very time and memory intensive. Instead of updating all model weights, we propose and evaluate three efficient active search strategies that only update a subset of parameters during the search. The proposed methods offer a simple way to significantly improve the search performance of a given model and outperform state-of-the-art machine learning based methods on combinatorial problems, even surpassing the well-known heuristic solver LKH3 on the capacitated vehicle routing problem. Finally, we show that (efficient) active search enables learned models to effectively solve instances that are much larger than those seen during training.
Experimental Study of Outdoor UAV Localization and Tracking using Passive RF Sensing
Sep 03, 2021

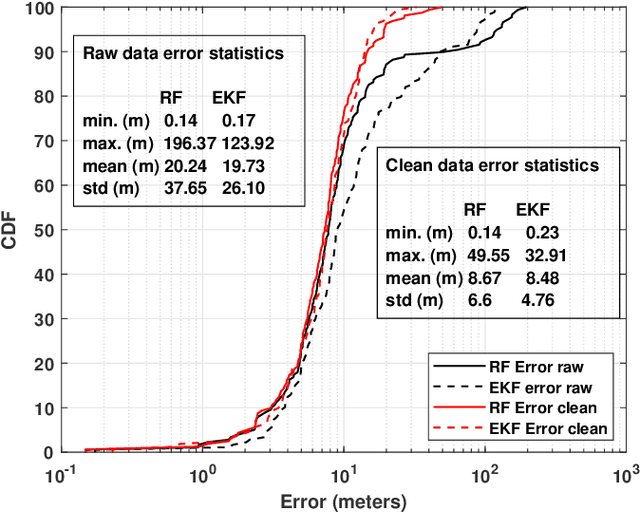
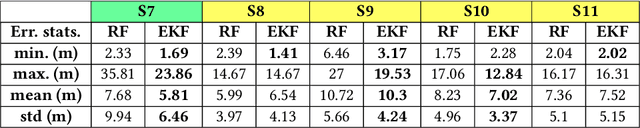
Extensive use of unmanned aerial vehicles (UAVs) is expected to raise privacy and security concerns among individuals and communities. In this context, the detection and localization of UAVs will be critical for maintaining safe and secure airspace in the future. In this work, Keysight N6854A radio frequency (RF) sensors are used to detect and locate a UAV by passively monitoring the signals emitted from the UAV. First, the Keysight sensor detects the UAV by comparing the received RF signature with various other UAVs' RF signatures in the Keysight database using an envelope detection algorithm. Afterward, time difference of arrival (TDoA) based localization is performed by a central controller using the sensor data, and the drone is localized with some error. To mitigate the localization error, implementation of an extended Kalman filter~(EKF) is proposed in this study. The performance of the proposed approach is evaluated on a realistic experimental dataset. EKF requires basic assumptions on the type of motion throughout the trajectory, i.e., the movement of the object is assumed to fit some motion model~(MM) such as constant velocity (CV), constant acceleration (CA), and constant turn (CT). In the experiments, an arbitrary trajectory is followed, therefore it is not feasible to fit the whole trajectory into a single MM. Consequently, the trajectory is segmented into sub-parts and a different MM is assumed in each segment while building the EKF model. Simulation results demonstrate an improvement in error statistics when EKF is used if the MM assumption aligns with the real motion.
Feature Pyramid Network for Multi-task Affective Analysis
Jul 08, 2021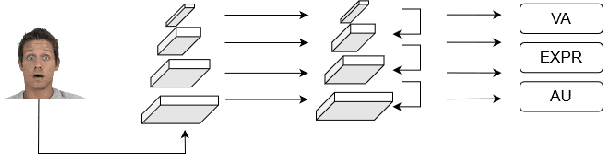
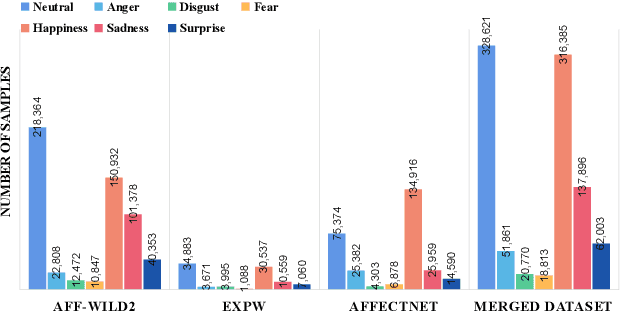
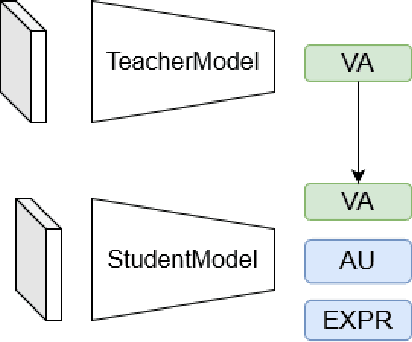
Affective Analysis is not a single task, and the valence-arousal value, expression class and action unit can be predicted at the same time. Previous researches failed to take them as a whole task or ignore the entanglement and hierarchical relation of this three facial attributes. We propose a novel model named feature pyramid networks for multi-task affect analysis. The hierarchical features are extracted to predict three labels and we apply teacher-student training strategy to learn from pretrained single-task models. Extensive experiment results demonstrate the proposed model outperform other models. The code and model are available for research purposes at $\href{https://github.com/ryanhe312/ABAW2-FPNMAA}{\text{this link}}$.
On Observability and Identifiability of Tightly-coupled Ultrawideband-aided Inertial Localization
Jul 29, 2021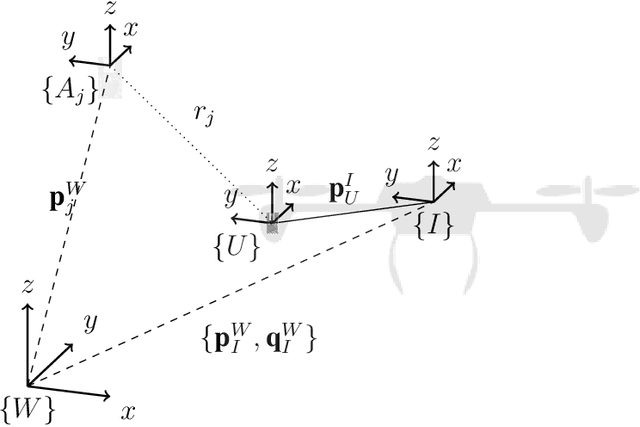
The combination of ultrawideband (UWB) radios and inertial measurement units (IMU) can provide accurate positioning. To ensure reliable communication, the radios are generally mounted at the extremities of a mobile system whereas the IMUs are located closer to the center of gravity for use in control, resulting in a spatial offset between the IMU and the UWB radio. Additionally, data from heterogeneous sensors can arrive at different time instants. The systematic fusion of data from multiple sources requires the temporal offset and spatial offset between the sensors to be known. An important aspect of calibration is the observability of the system state and identifiability of the system parameters. Estimating the state or parameters of a system that is otherwise unobservable or unidentifiable, can result in poor estimates. In this report, the local weak observability of the state and the identifiability of the temporal offset for a tightly-coupled UWB-aided inertial localization system is studied.
A good body is all you need: avoiding catastrophic interference via agent architecture search
Aug 18, 2021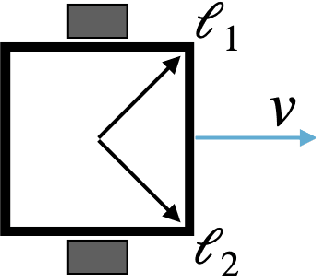
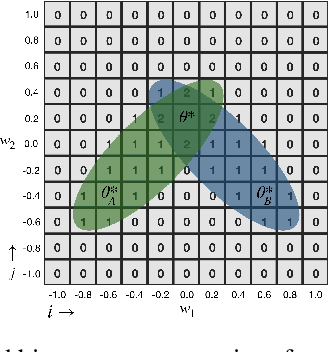
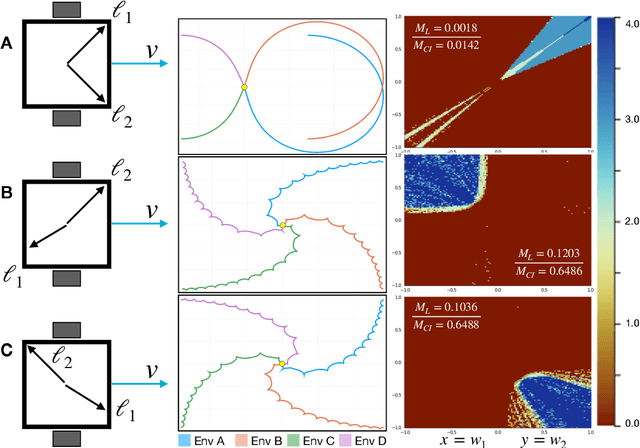
In robotics, catastrophic interference continues to restrain policy training across environments. Efforts to combat catastrophic interference to date focus on novel neural architectures or training methods, with a recent emphasis on policies with good initial settings that facilitate training in new environments. However, none of these methods to date have taken into account how the physical architecture of the robot can obstruct or facilitate catastrophic interference, just as the choice of neural architecture can. In previous work we have shown how aspects of a robot's physical structure (specifically, sensor placement) can facilitate policy learning by increasing the fraction of optimal policies for a given physical structure. Here we show for the first time that this proxy measure of catastrophic interference correlates with sample efficiency across several search methods, proving that favorable loss landscapes can be induced by the correct choice of physical structure. We show that such structures can be found via co-optimization -- optimization of a robot's structure and control policy simultaneously -- yielding catastrophic interference resistant robot structures and policies, and that this is more efficient than control policy optimization alone. Finally, we show that such structures exhibit sensor homeostasis across environments and introduce this as the mechanism by which certain robots overcome catastrophic interference.