 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Scalable Certified Segmentation via Randomized Smoothing
Jul 01, 2021
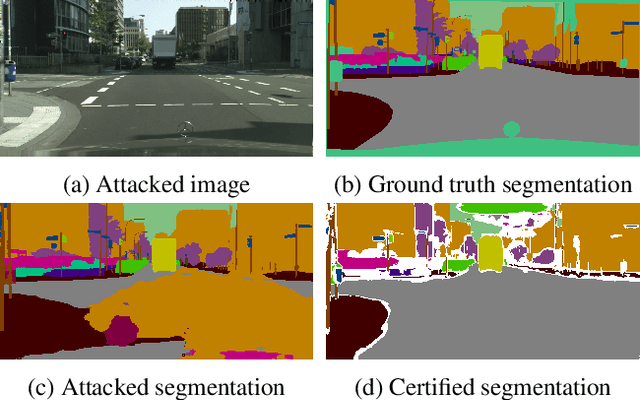
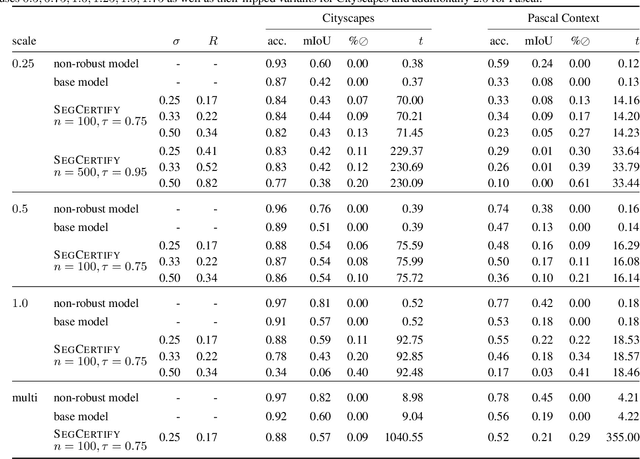
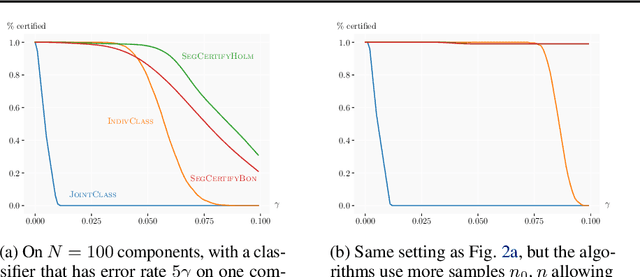
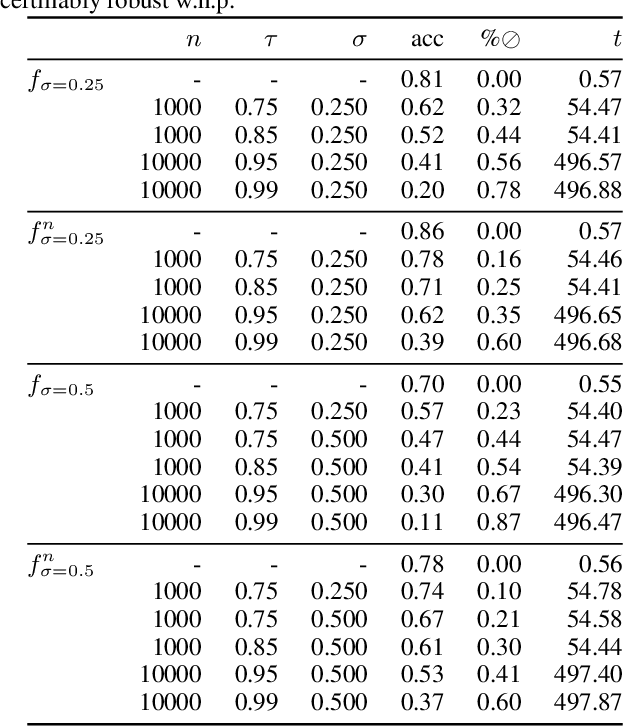
We present a new certification method for image and point cloud segmentation based on randomized smoothing. The method leverages a novel scalable algorithm for prediction and certification that correctly accounts for multiple testing, necessary for ensuring statistical guarantees. The key to our approach is reliance on established multiple-testing correction mechanisms as well as the ability to abstain from classifying single pixels or points while still robustly segmenting the overall input. Our experimental evaluation on synthetic data and challenging datasets, such as Pascal Context, Cityscapes, and ShapeNet, shows that our algorithm can achieve, for the first time, competitive accuracy and certification guarantees on real-world segmentation tasks. We provide an implementation at https://github.com/eth-sri/segmentation-smoothing.
Rearrangement on Lattices with Swaps: Optimality Structures and Efficient Algorithms
May 11, 2021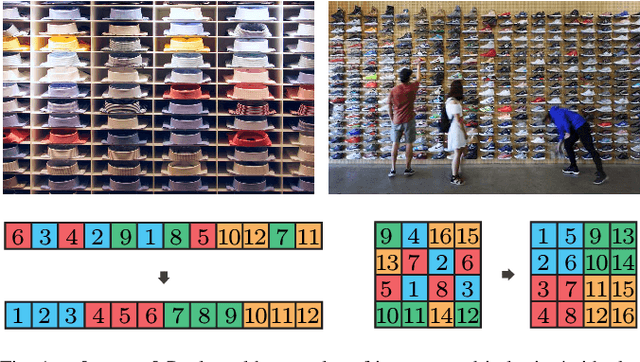
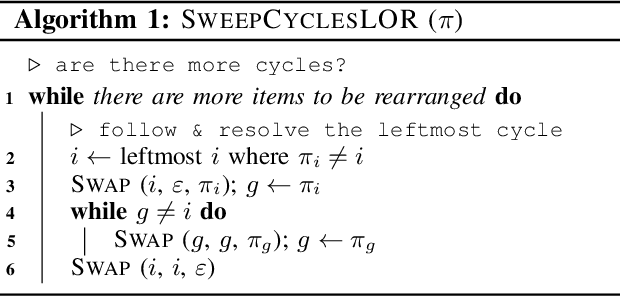
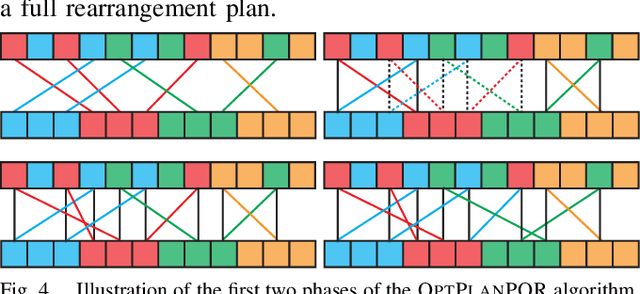

We investigate a class of multi-object rearrangement problems in which a robotic manipulator, capable of carrying an item and making item swaps, is tasked to sort items stored in lattices in a time-optimal manner. We systematically analyze the intrinsic optimality structure, which is fairly rich and intriguing, under different levels of item distinguishability (fully labeled or partially labeled) and different lattice dimensions. Focusing on the most practical setting of one and two dimensions, we develop efficient (low polynomial time) algorithms that optimally perform rearrangements on 1D lattices under both fully and partially labeled settings. On the other hand, we prove that rearrangement on 2D and higher dimensional lattices becomes computationally intractable to optimally solve. Despite their NP-hardness, we are able to again develop efficient algorithms for 2D fully and partially labeled settings that are asymptotically optimal, in expectation, assuming that the initial configuration is randomly selected. Simulation studies confirm the effectiveness of our algorithms in comparison to natural greedy best-first algorithms.
The Ecosystem Path to General AI
Aug 17, 2021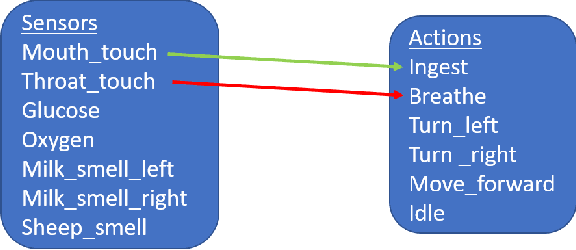
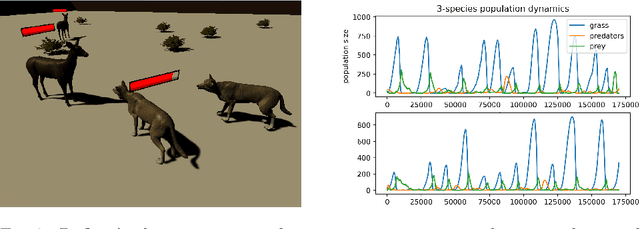
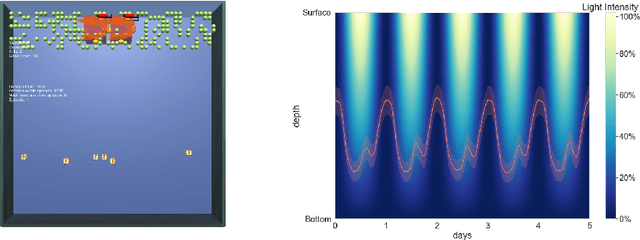
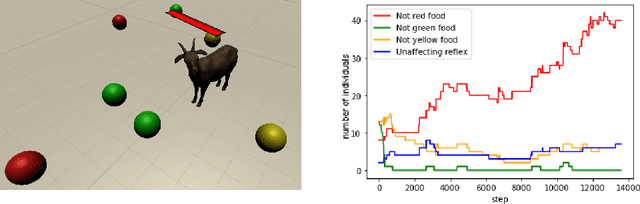
We start by discussing the link between ecosystem simulators and general AI. Then we present the open-source ecosystem simulator Ecotwin, which is based on the game engine Unity and operates on ecosystems containing inanimate objects like mountains and lakes, as well as organisms such as animals and plants. Animal cognition is modeled by integrating three separate networks: (i) a \textit{reflex network} for hard-wired reflexes; (ii) a \textit{happiness network} that maps sensory data such as oxygen, water, energy, and smells, to a scalar happiness value; and (iii) a \textit{policy network} for selecting actions. The policy network is trained with reinforcement learning (RL), where the reward signal is defined as the happiness difference from one time step to the next. All organisms are capable of either sexual or asexual reproduction, and they die if they run out of critical resources. We report results from three studies with Ecotwin, in which natural phenomena emerge in the models without being hardwired. First, we study a terrestrial ecosystem with wolves, deer, and grass, in which a Lotka-Volterra style population dynamics emerges. Second, we study a marine ecosystem with phytoplankton, copepods, and krill, in which a diel vertical migration behavior emerges. Third, we study an ecosystem involving lethal dangers, in which certain agents that combine RL with reflexes outperform pure RL agents.
Preliminary investigation into how limb choice affects kinesthetic perception
Jul 22, 2021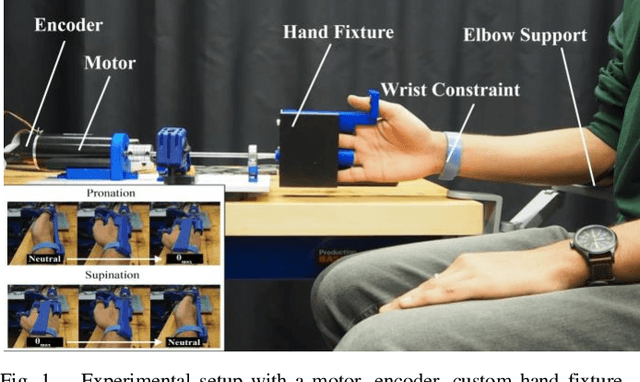
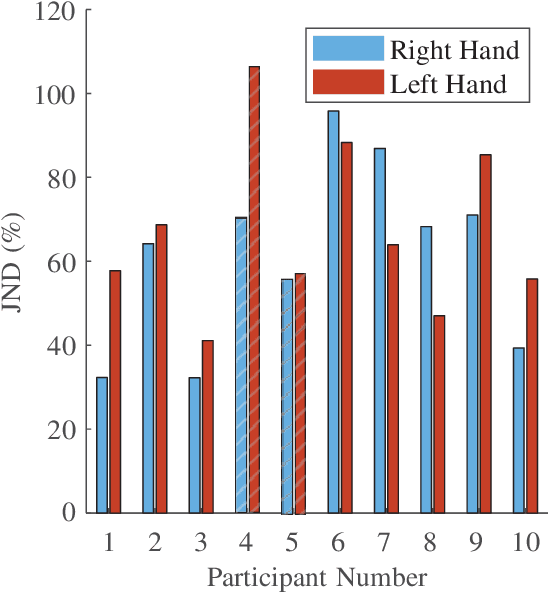
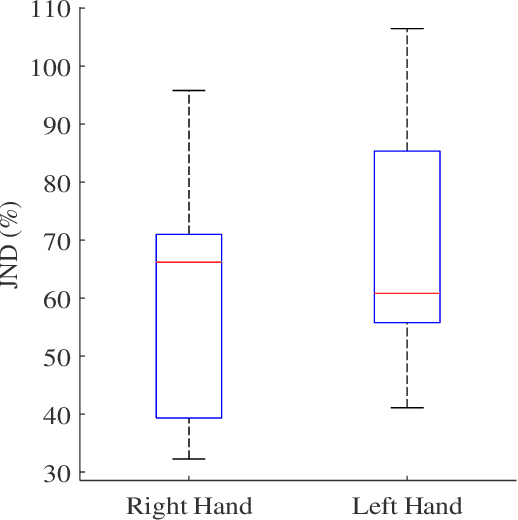
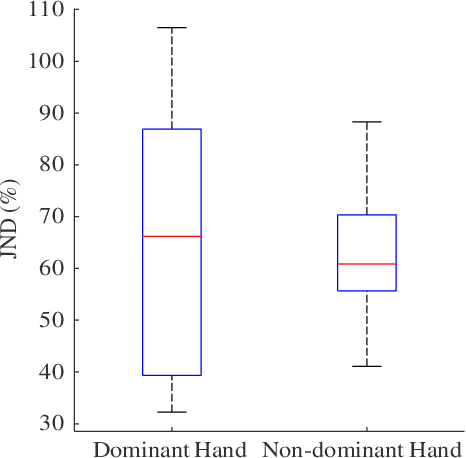
We have a limited understanding of how we integrate haptic information in real-time from our upper limbs to perform complex bimanual tasks, an ability that humans routinely employ to perform tasks of varying levels of difficulty. In order to understand how information from both limbs is used to create a unified percept, it is important to study both the limbs separately first. Prevalent theories highlighting the role of central nervous system (CNS) in accounting for internal body dynamics seem to suggest that both upper limbs should be equally sensitive to external stimuli. However, there is empirical proof demonstrating a perceptual difference in our upper limbs for tasks like shape discrimination, prompting the need to study effects of limb choice on kinesthetic perception. In this manuscript, we start evaluating Just Noticeable Difference (JND) for stiffness for both forearms separately. Early results validate the need for a more thorough investigation of limb choice on kinesthetic perception.
Feature Importance in a Deep Learning Climate Emulator
Aug 27, 2021
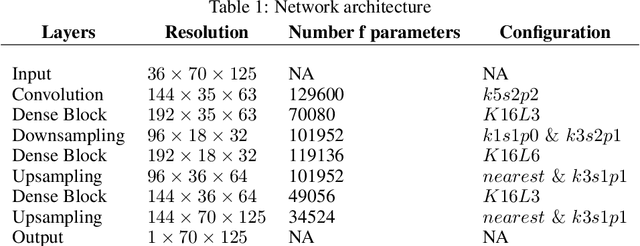
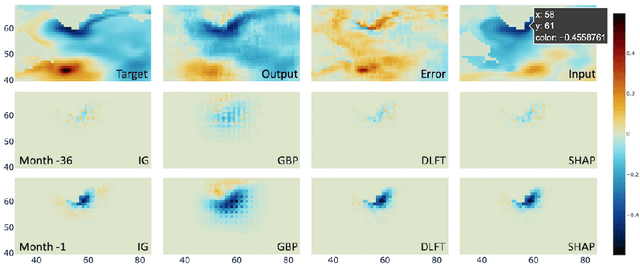
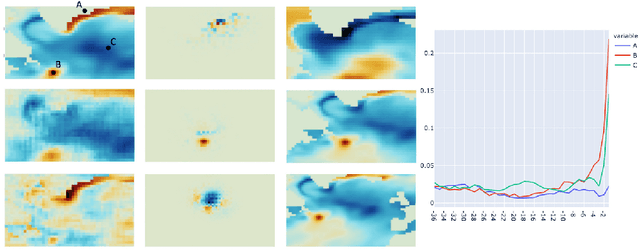
We present a study using a class of post-hoc local explanation methods i.e., feature importance methods for "understanding" a deep learning (DL) emulator of climate. Specifically, we consider a multiple-input-single-output emulator that uses a DenseNet encoder-decoder architecture and is trained to predict interannual variations of sea surface temperature (SST) at 1, 6, and 9 month lead times using the preceding 36 months of (appropriately filtered) SST data. First, feature importance methods are employed for individual predictions to spatio-temporally identify input features that are important for model prediction at chosen geographical regions and chosen prediction lead times. In a second step, we also examine the behavior of feature importance in a generalized sense by considering an aggregation of the importance heatmaps over training samples. We find that: 1) the climate emulator's prediction at any geographical location depends dominantly on a small neighborhood around it; 2) the longer the prediction lead time, the further back the "importance" extends; and 3) to leading order, the temporal decay of "importance" is independent of geographical location. An ablation experiment is adopted to verify the findings. From the perspective of climate dynamics, these findings suggest a dominant role for local processes and a negligible role for remote teleconnections at the spatial and temporal scales we consider. From the perspective of network architecture, the spatio-temporal relations between the inputs and outputs we find suggest potential model refinements. We discuss further extensions of our methods, some of which we are considering in ongoing work.
PatDNN: Achieving Real-Time DNN Execution on Mobile Devices with Pattern-based Weight Pruning
Jan 01, 2020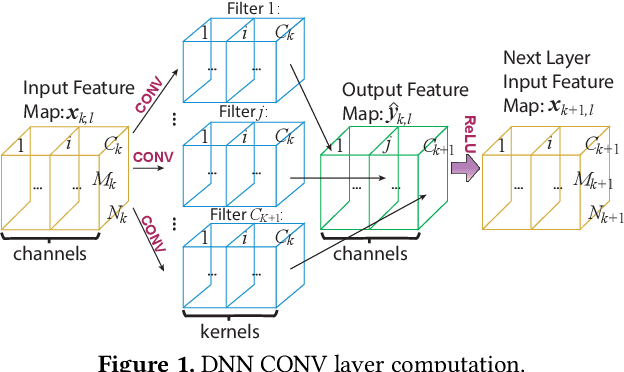
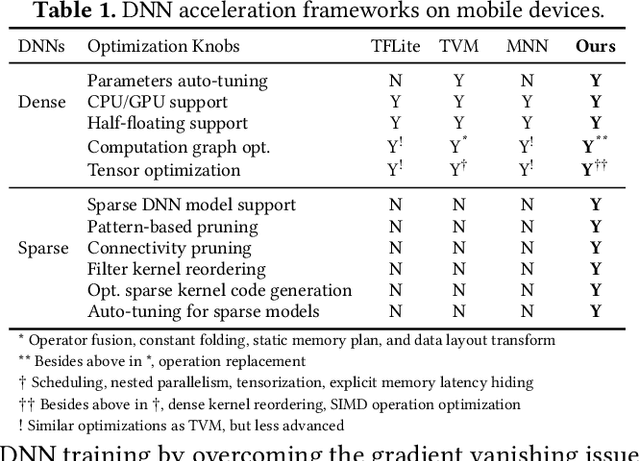
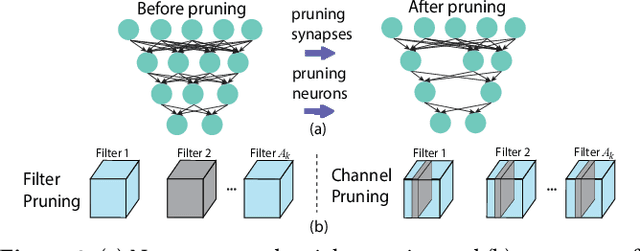
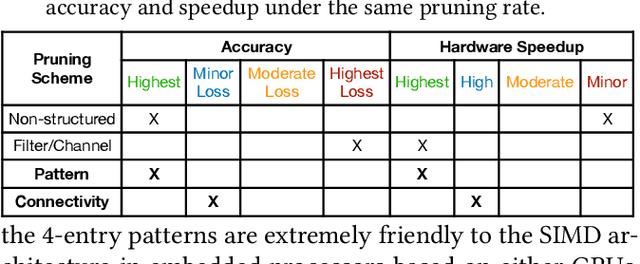
With the emergence of a spectrum of high-end mobile devices, many applications that formerly required desktop-level computation capability are being transferred to these devices. However, executing the inference of Deep Neural Networks (DNNs) is still challenging considering high computation and storage demands, specifically, if real-time performance with high accuracy is needed. Weight pruning of DNNs is proposed, but existing schemes represent two extremes in the design space: non-structured pruning is fine-grained, accurate, but not hardware friendly; structured pruning is coarse-grained, hardware-efficient, but with higher accuracy loss. In this paper, we introduce a new dimension, fine-grained pruning patterns inside the coarse-grained structures, revealing a previously unknown point in design space. With the higher accuracy enabled by fine-grained pruning patterns, the unique insight is to use the compiler to re-gain and guarantee high hardware efficiency. In other words, our method achieves the best of both worlds, and is desirable across theory/algorithm, compiler, and hardware levels. The proposed PatDNN is an end-to-end framework to efficiently execute DNN on mobile devices with the help of a novel model compression technique (pattern-based pruning based on extended ADMM solution framework) and a set of thorough architecture-aware compiler- and code generation-based optimizations (filter kernel reordering, compressed weight storage, register load redundancy elimination, and parameter auto-tuning). Evaluation results demonstrate that PatDNN outperforms three state-of-the-art end-to-end DNN frameworks, TensorFlow Lite, TVM, and Alibaba Mobile Neural Network with speedup up to 44.5x, 11.4x, and 7.1x, respectively, with no accuracy compromise. Real-time inference of representative large-scale DNNs (e.g., VGG-16, ResNet-50) can be achieved using mobile devices.
A Boosting Approach to Reinforcement Learning
Aug 22, 2021
We study efficient algorithms for reinforcement learning in Markov decision processes whose complexity is independent of the number of states. This formulation succinctly captures large scale problems, but is also known to be computationally hard in its general form. Previous approaches attempt to circumvent the computational hardness by assuming structure in either transition function or the value function, or by relaxing the solution guarantee to a local optimality condition. We consider the methodology of boosting, borrowed from supervised learning, for converting weak learners into an accurate policy. The notion of weak learning we study is that of sampled-based approximate optimization of linear functions over policies. Under this assumption of weak learnability, we give an efficient algorithm that is capable of improving the accuracy of such weak learning methods, till global optimality is reached. We prove sample complexity and running time bounds on our method, that are polynomial in the natural parameters of the problem: approximation guarantee, discount factor, distribution mismatch and number of actions. In particular, our bound does not depend on the number of states. A technical difficulty in applying previous boosting results, is that the value function over policy space is not convex. We show how to use a non-convex variant of the Frank-Wolfe method, coupled with recent advances in gradient boosting that allow incorporating a weak learner with multiplicative approximation guarantee, to overcome the non-convexity and attain global convergence.
Biomedical Entity Linking with Contrastive Context Matching
Jun 15, 2021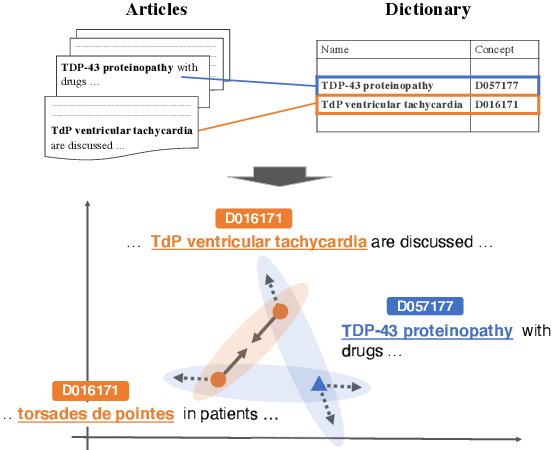
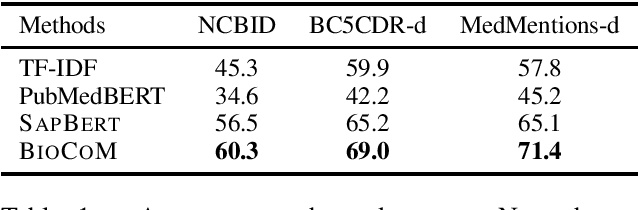
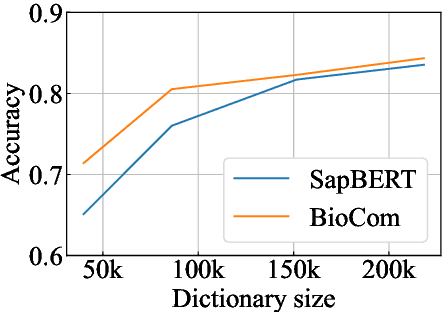
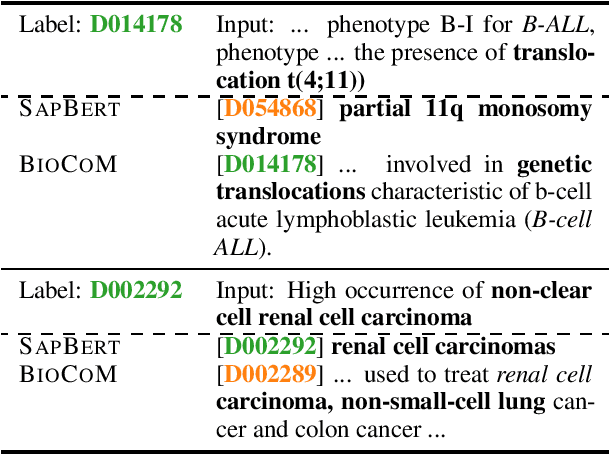
We introduce BioCoM, a contrastive learning framework for biomedical entity linking that uses only two resources: a small-sized dictionary and a large number of raw biomedical articles. Specifically, we build the training instances from raw PubMed articles by dictionary matching and use them to train a context-aware entity linking model with contrastive learning. We predict the normalized biomedical entity at inference time through a nearest-neighbor search. Results found that BioCoM substantially outperforms state-of-the-art models, especially in low-resource settings, by effectively using the context of the entities.
Incremental Few-Shot Instance Segmentation
May 11, 2021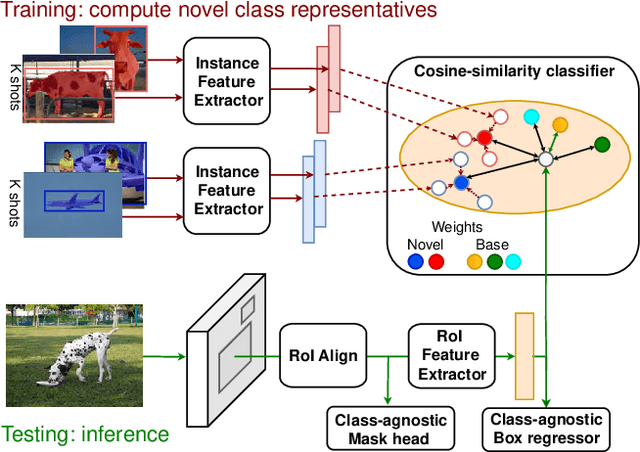
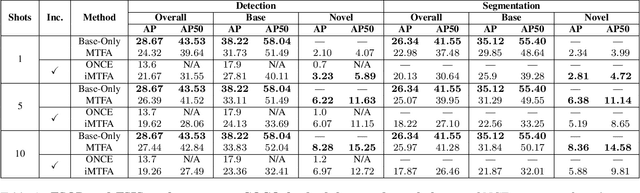
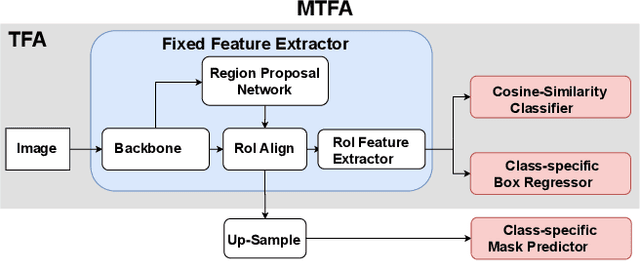
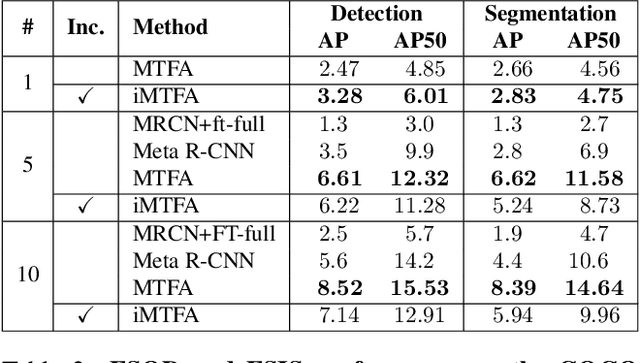
Few-shot instance segmentation methods are promising when labeled training data for novel classes is scarce. However, current approaches do not facilitate flexible addition of novel classes. They also require that examples of each class are provided at train and test time, which is memory intensive. In this paper, we address these limitations by presenting the first incremental approach to few-shot instance segmentation: iMTFA. We learn discriminative embeddings for object instances that are merged into class representatives. Storing embedding vectors rather than images effectively solves the memory overhead problem. We match these class embeddings at the RoI-level using cosine similarity. This allows us to add new classes without the need for further training or access to previous training data. In a series of experiments, we consistently outperform the current state-of-the-art. Moreover, the reduced memory requirements allow us to evaluate, for the first time, few-shot instance segmentation performance on all classes in COCO jointly.
Adaptive Dynamic Programming for Model-free Tracking of Trajectories with Time-varying Parameters
Sep 16, 2019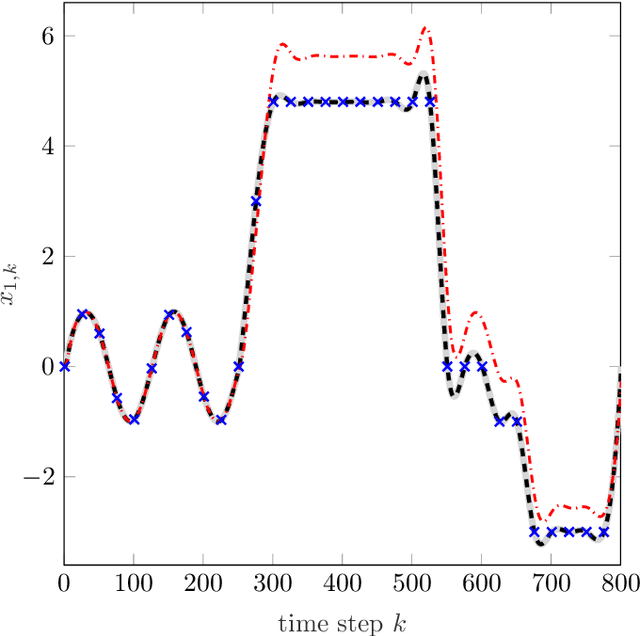
In order to autonomously learn to control unknown systems optimally w.r.t. an objective function, Adaptive Dynamic Programming (ADP) is well-suited to adapt controllers based on experience from interaction with the system. In recent years, many researchers focused on the tracking case, where the aim is to follow a desired trajectory. So far, ADP tracking controllers assume that the reference trajectory follows time-invariant exo-system dynamics-an assumption that does not hold for many applications. In order to overcome this limitation, we propose a new Q-function which explicitly incorporates a parametrized approximation of the reference trajectory. This allows to learn to track a general class of trajectories by means of ADP. Once our Q-function has been learned, the associated controller copes with time-varying reference trajectories without need of further training and independent of exo-system dynamics. After proposing our general model-free off-policy tracking method, we provide analysis of the important special case of linear quadratic tracking. We conclude our paper with an example which demonstrates that our new method successfully learns the optimal tracking controller and outperforms existing approaches in terms of tracking error and cost.