 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Learning-Based UAV Trajectory Optimization with Collision Avoidance and Connectivity Constraints
Apr 15, 2021
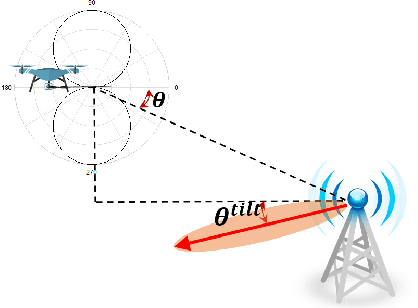
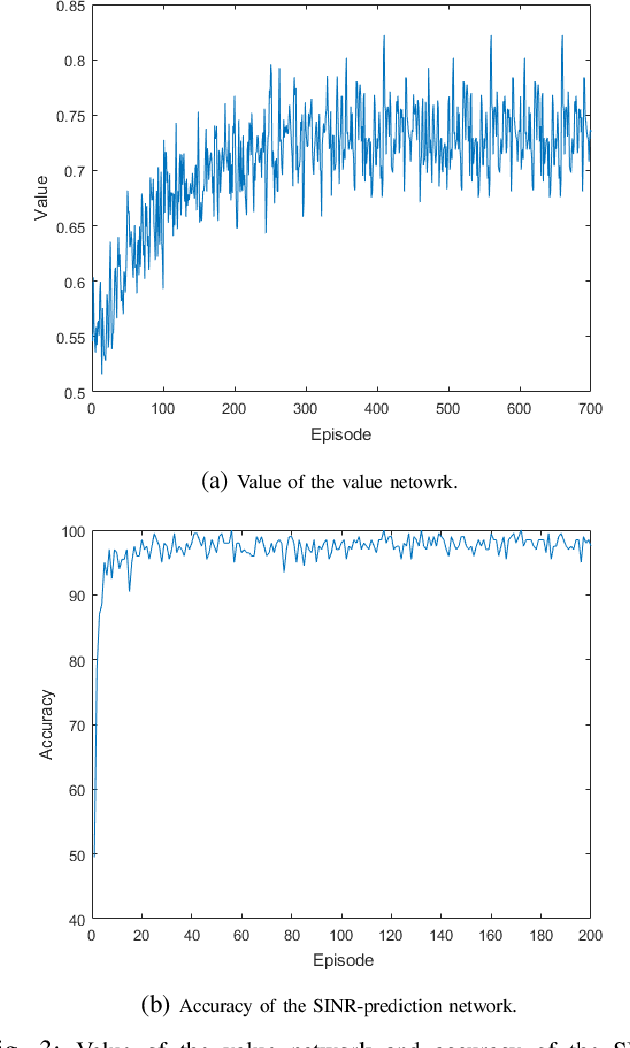
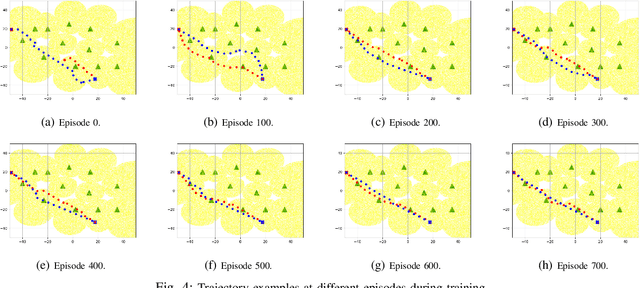
Unmanned aerial vehicles (UAVs) are expected to be an integral part of wireless networks, and determining collision-free trajectories for multiple UAVs while satisfying requirements of connectivity with ground base stations (GBSs) is a challenging task. In this paper, we first reformulate the multi-UAV trajectory optimization problem with collision avoidance and wireless connectivity constraints as a sequential decision making problem in the discrete time domain. We, then, propose a decentralized deep reinforcement learning approach to solve the problem. More specifically, a value network is developed to encode the expected time to destination given the agent's joint state (including the agent's information, the nearby agents' observable information, and the locations of the nearby GBSs). A signal-to-interference-plus-noise ratio (SINR)-prediction neural network is also designed, using accumulated SINR measurements obtained when interacting with the cellular network, to map the GBSs' locations into the SINR levels in order to predict the UAV's SINR. Numerical results show that with the value network and SINR-prediction network, real-time navigation for multi-UAVs can be efficiently performed in various environments with high success rate.
Pre-Clustering Point Clouds of Crop Fields Using Scalable Methods
Jul 22, 2021
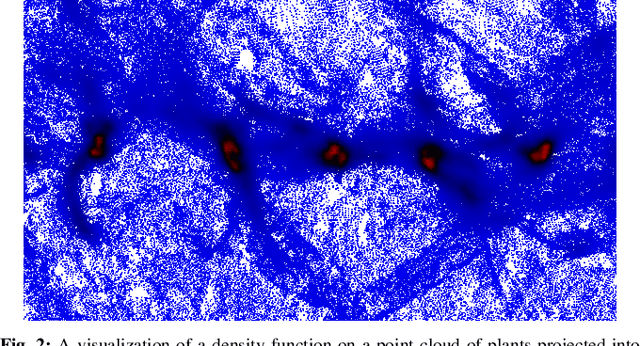


In order to apply the recent successes of automated plant phenotyping and machine learning on a large scale, efficient and general algorithms must be designed to intelligently split crop fields into small, yet actionable, portions that can then be processed by more complex algorithms. In this paper we notice a similarity between the current state-of-the-art for this problem and a commonly used density-based clustering algorithm, Quickshift. Exploiting this similarity we propose a number of novel, application specific algorithms with the goal of producing a general and scalable plant segmentation algorithm. The novel algorithms proposed in this work are shown to produce quantitatively better results than the current state-of-the-art while being less sensitive to input parameters and maintaining the same algorithmic time complexity. When incorporated into field-scale phenotyping systems, the proposed algorithms should work as a drop in replacement that can greatly improve the accuracy of results while ensuring that performance and scalability remain undiminished.
Context-aware demand prediction in bike sharing systems: incorporating spatial, meteorological and calendrical context
May 03, 2021
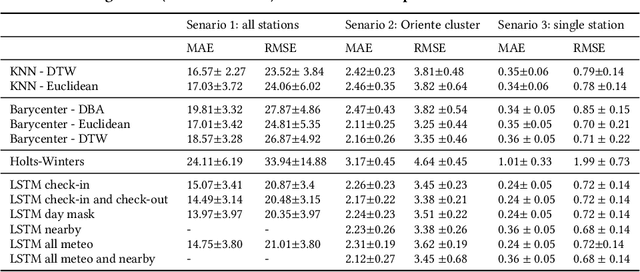
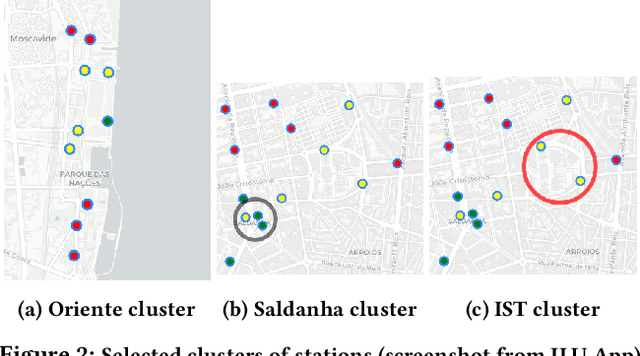
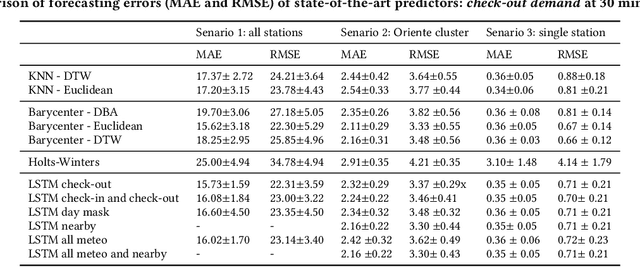
Bike sharing demand is increasing in large cities worldwide. The proper functioning of bike-sharing systems is, nevertheless, dependent on a balanced geographical distribution of bicycles throughout a day. In this context, understanding the spatiotemporal distribution of check-ins and check-outs is key for station balancing and bike relocation initiatives. Still, recent contributions from deep learning and distance-based predictors show limited success on forecasting bike sharing demand. This consistent observation is hypothesized to be driven by: i) the strong dependence between demand and the meteorological and situational context of stations; and ii) the absence of spatial awareness as most predictors are unable to model the effects of high-low station load on nearby stations. This work proposes a comprehensive set of new principles to incorporate both historical and prospective sources of spatial, meteorological, situational and calendrical context in predictive models of station demand. To this end, a new recurrent neural network layering composed by serial long-short term memory (LSTM) components is proposed with two major contributions: i) the feeding of multivariate time series masks produced from historical context data at the input layer, and ii) the time-dependent regularization of the forecasted time series using prospective context data. This work further assesses the impact of incorporating different sources of context, showing the relevance of the proposed principles for the community even though not all improvements from the context-aware predictors yield statistical significance.
Avaya Conversational Intelligence: A Real-Time System for Spoken Language Understanding in Human-Human Call Center Conversations
Sep 02, 2019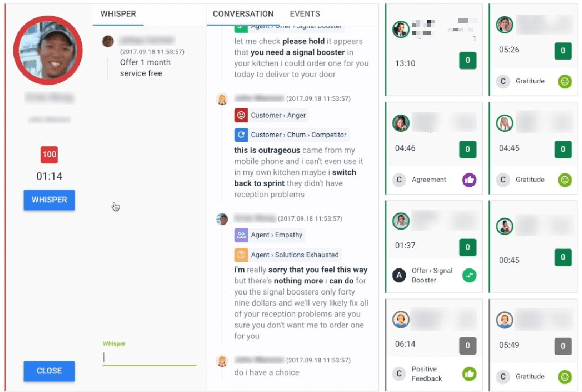
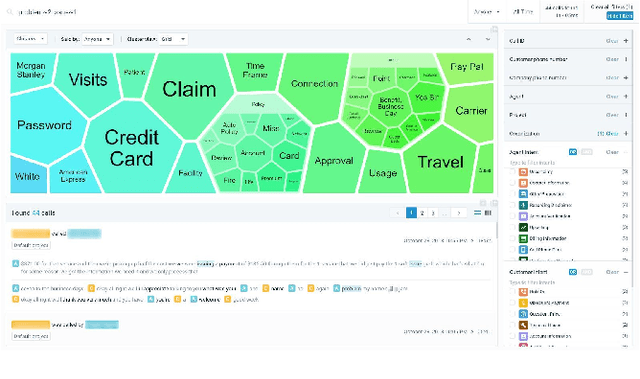
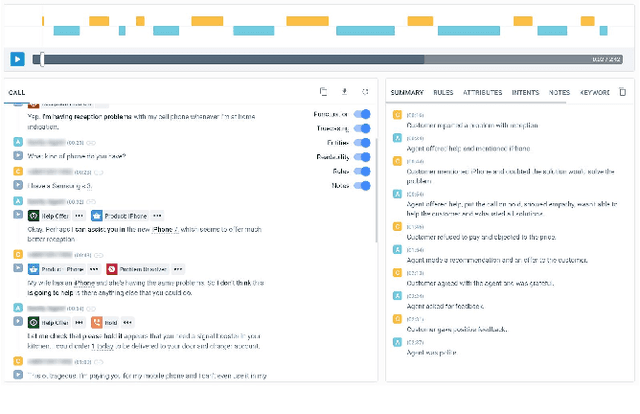
Avaya Conversational Intelligence(ACI) is an end-to-end, cloud-based solution for real-time Spoken Language Understanding for call centers. It combines large vocabulary, real-time speech recognition, transcript refinement, and entity and intent recognition in order to convert live audio into a rich, actionable stream of structured events. These events can be further leveraged with a business rules engine, thus serving as a foundation for real-time supervision and assistance applications. After the ingestion, calls are enriched with unsupervised keyword extraction, abstractive summarization, and business-defined attributes, enabling offline use cases, such as business intelligence, topic mining, full-text search, quality assurance, and agent training. ACI comes with a pretrained, configurable library of hundreds of intents and a robust intent training environment that allows for efficient, cost-effective creation and customization of customer-specific intents.
On the Real-time Vehicle Placement Problem
Dec 04, 2017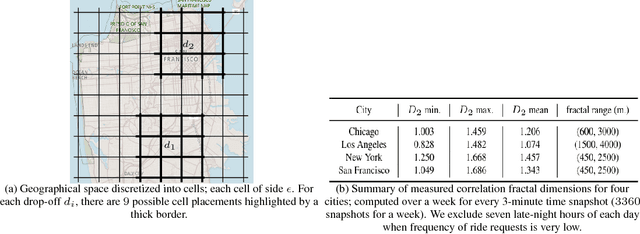
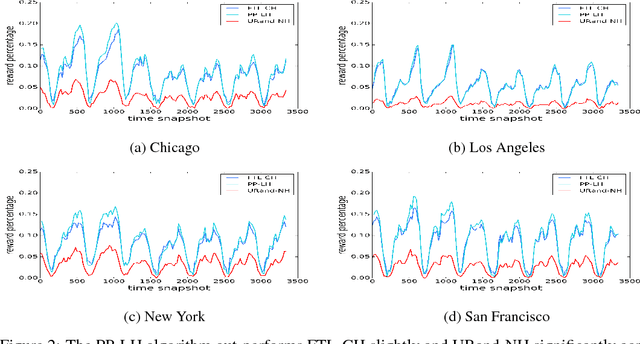
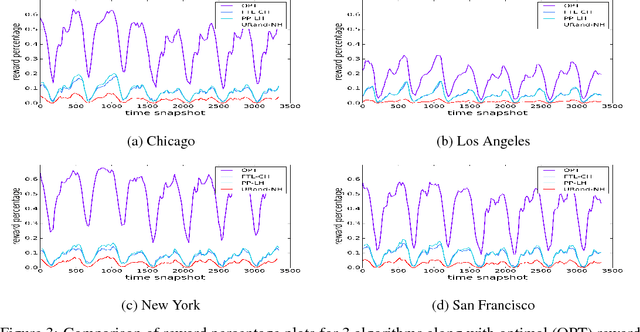
Motivated by ride-sharing platforms' efforts to reduce their riders' wait times for a vehicle, this paper introduces a novel problem of placing vehicles to fulfill real-time pickup requests in a spatially and temporally changing environment. The real-time nature of this problem makes it fundamentally different from other placement and scheduling problems, as it requires not only real-time placement decisions but also handling real-time request dynamics, which are influenced by human mobility patterns. We use a dataset of ten million ride requests from four major U.S. cities to show that the requests exhibit significant self-similarity. We then propose distributed online learning algorithms for the real-time vehicle placement problem and bound their expected performance under this observed self-similarity.
Video-Streaming Biomedical Implants using Ultrasonic Waves for Communication
Jun 25, 2021
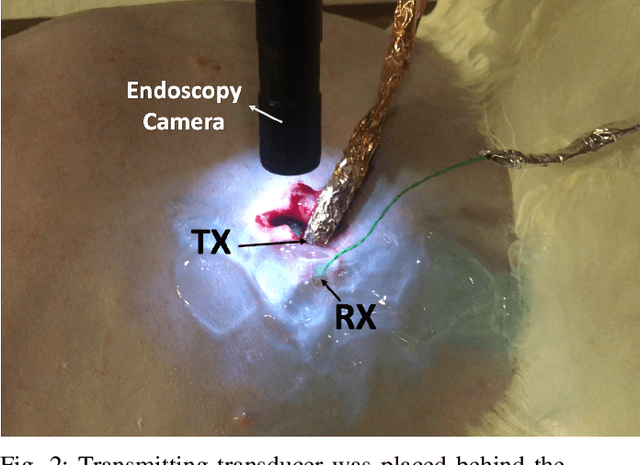


The use of wireless implanted medical devices (IMDs) is growing because they facilitate continuous monitoring of patients during normal activities, simplify medical procedures required for data retrieval and reduce the likelihood of infection associated with trailing wires. However, most of the state-of-the-art IMDs are passive and offline devices. One of the key obstacles to an active and online IMD is the infeasibility of real-time, high-quality video broadcast from the IMD. Such broadcast would help develop innovative devices such as a video-streaming capsule endoscopy (CE) pill with therapeutic intervention capabilities. State-of-the-art IMDs employ radio-frequency electromagnetic waves for information transmission. However, high attenuation of RF-EM waves in tissues and federal restrictions on the transmit power and operable bandwidth lead to fundamental performance constraints for IMDs employing RF links, and prevent achieving high data rates that could accomodate video broadcast. In this work, ultrasonic waves were used for video transmission and broadcast through biological tissues. The proposed proof-of-concept system was tested on a porcine intestine ex vivo and a rabbit in vivo. It was demonstrated that using a millimeter-sized, implanted biocompatible transducer operating at 1.1-1.2 MHz, it was possible to transmit endoscopic video with high resolution (1280 pixels by 720 pixels) through porcine intestine wrapped with bacon, and to broadcast standard definition (640 pixels by 480 pixels) video near real-time through rabbit abdomen in vivo. A media repository that includes experimental demonstrations and media files accompanies this paper. The accompanying media repository can be found at this link: https://bit.ly/3wuc7tk.
Simulated Adversarial Testing of Face Recognition Models
Jun 08, 2021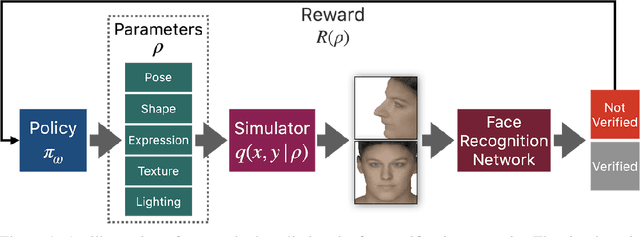

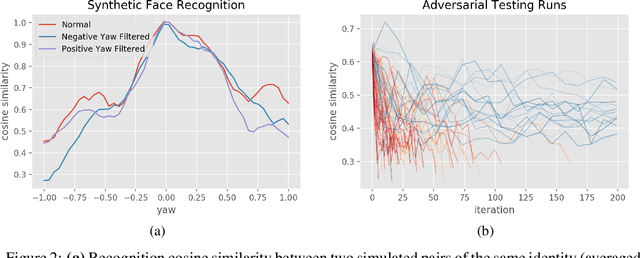
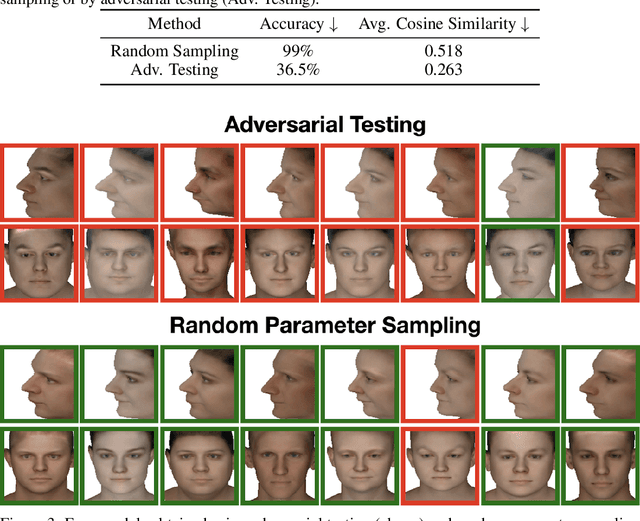
Most machine learning models are validated and tested on fixed datasets. This can give an incomplete picture of the capabilities and weaknesses of the model. Such weaknesses can be revealed at test time in the real world. The risks involved in such failures can be loss of profits, loss of time or even loss of life in certain critical applications. In order to alleviate this issue, simulators can be controlled in a fine-grained manner using interpretable parameters to explore the semantic image manifold. In this work, we propose a framework for learning how to test machine learning algorithms using simulators in an adversarial manner in order to find weaknesses in the model before deploying it in critical scenarios. We apply this model in a face recognition scenario. We are the first to show that weaknesses of models trained on real data can be discovered using simulated samples. Using our proposed method, we can find adversarial synthetic faces that fool contemporary face recognition models. This demonstrates the fact that these models have weaknesses that are not measured by commonly used validation datasets. We hypothesize that this type of adversarial examples are not isolated, but usually lie in connected components in the latent space of the simulator. We present a method to find these adversarial regions as opposed to the typical adversarial points found in the adversarial example literature.
The Ecosystem Path to General AI
Aug 17, 2021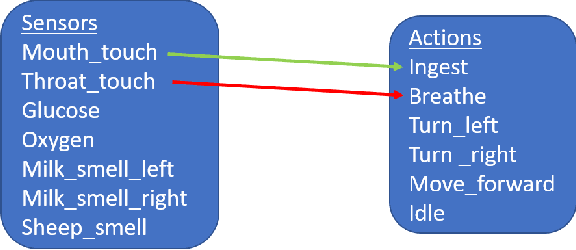
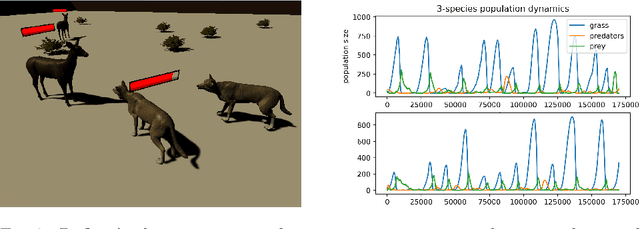
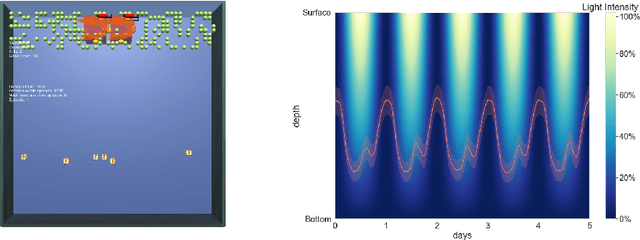
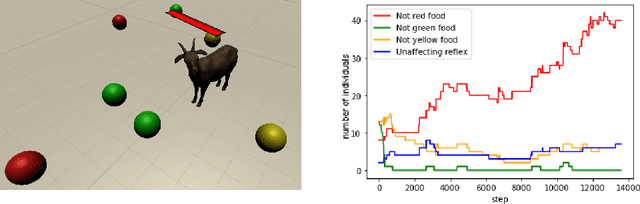
We start by discussing the link between ecosystem simulators and general AI. Then we present the open-source ecosystem simulator Ecotwin, which is based on the game engine Unity and operates on ecosystems containing inanimate objects like mountains and lakes, as well as organisms such as animals and plants. Animal cognition is modeled by integrating three separate networks: (i) a \textit{reflex network} for hard-wired reflexes; (ii) a \textit{happiness network} that maps sensory data such as oxygen, water, energy, and smells, to a scalar happiness value; and (iii) a \textit{policy network} for selecting actions. The policy network is trained with reinforcement learning (RL), where the reward signal is defined as the happiness difference from one time step to the next. All organisms are capable of either sexual or asexual reproduction, and they die if they run out of critical resources. We report results from three studies with Ecotwin, in which natural phenomena emerge in the models without being hardwired. First, we study a terrestrial ecosystem with wolves, deer, and grass, in which a Lotka-Volterra style population dynamics emerges. Second, we study a marine ecosystem with phytoplankton, copepods, and krill, in which a diel vertical migration behavior emerges. Third, we study an ecosystem involving lethal dangers, in which certain agents that combine RL with reflexes outperform pure RL agents.
Scalable Certified Segmentation via Randomized Smoothing
Jul 01, 2021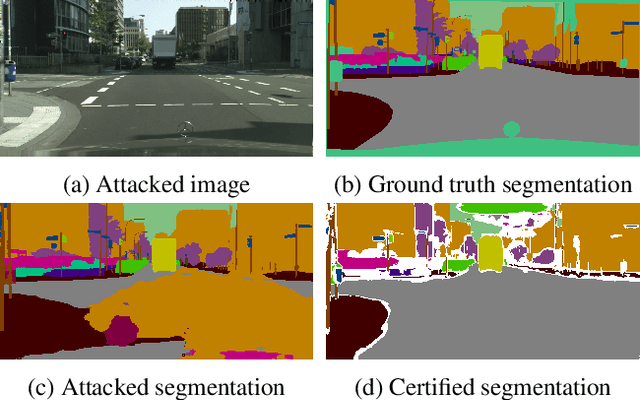
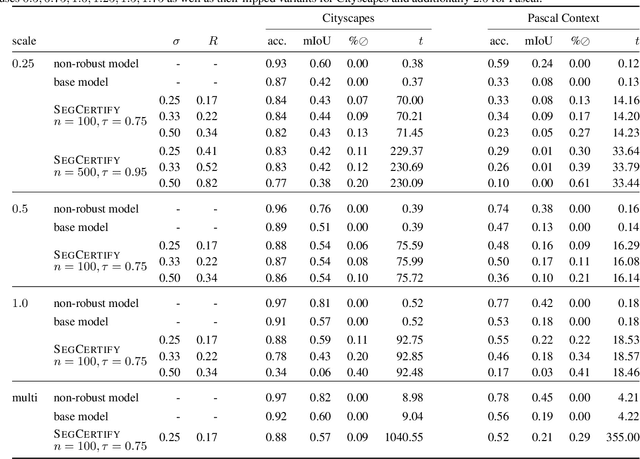
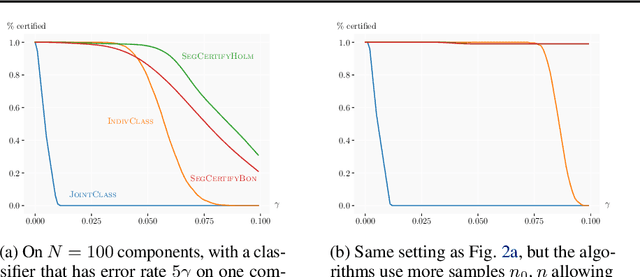
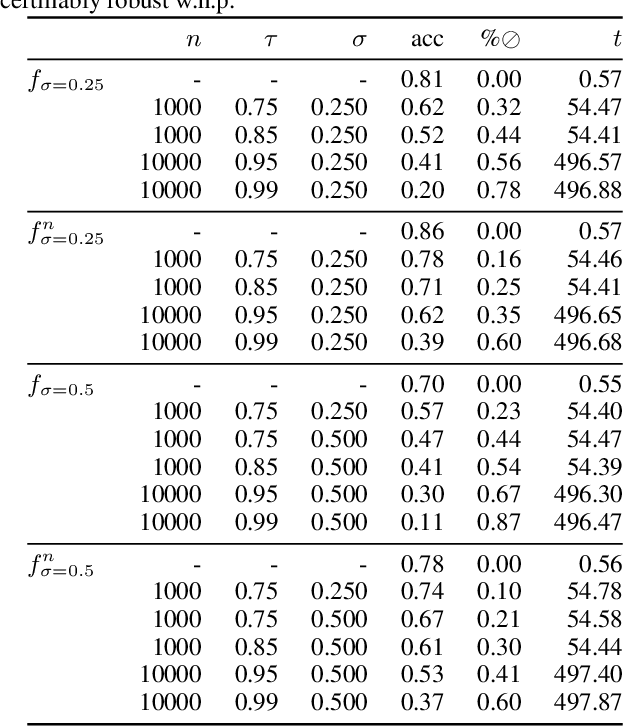
We present a new certification method for image and point cloud segmentation based on randomized smoothing. The method leverages a novel scalable algorithm for prediction and certification that correctly accounts for multiple testing, necessary for ensuring statistical guarantees. The key to our approach is reliance on established multiple-testing correction mechanisms as well as the ability to abstain from classifying single pixels or points while still robustly segmenting the overall input. Our experimental evaluation on synthetic data and challenging datasets, such as Pascal Context, Cityscapes, and ShapeNet, shows that our algorithm can achieve, for the first time, competitive accuracy and certification guarantees on real-world segmentation tasks. We provide an implementation at https://github.com/eth-sri/segmentation-smoothing.
Feature Importance in a Deep Learning Climate Emulator
Aug 27, 2021
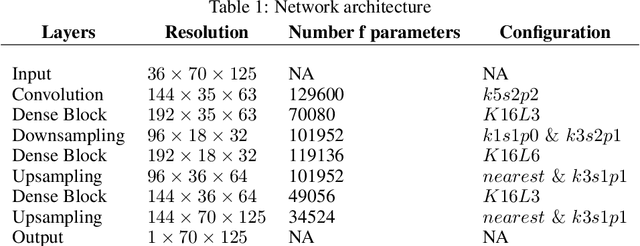
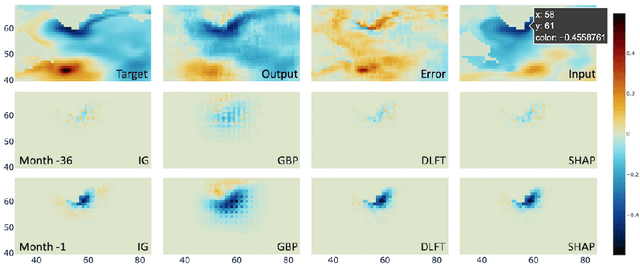
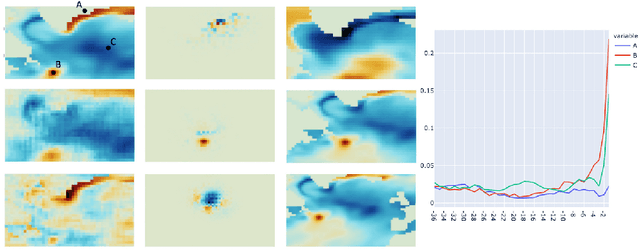
We present a study using a class of post-hoc local explanation methods i.e., feature importance methods for "understanding" a deep learning (DL) emulator of climate. Specifically, we consider a multiple-input-single-output emulator that uses a DenseNet encoder-decoder architecture and is trained to predict interannual variations of sea surface temperature (SST) at 1, 6, and 9 month lead times using the preceding 36 months of (appropriately filtered) SST data. First, feature importance methods are employed for individual predictions to spatio-temporally identify input features that are important for model prediction at chosen geographical regions and chosen prediction lead times. In a second step, we also examine the behavior of feature importance in a generalized sense by considering an aggregation of the importance heatmaps over training samples. We find that: 1) the climate emulator's prediction at any geographical location depends dominantly on a small neighborhood around it; 2) the longer the prediction lead time, the further back the "importance" extends; and 3) to leading order, the temporal decay of "importance" is independent of geographical location. An ablation experiment is adopted to verify the findings. From the perspective of climate dynamics, these findings suggest a dominant role for local processes and a negligible role for remote teleconnections at the spatial and temporal scales we consider. From the perspective of network architecture, the spatio-temporal relations between the inputs and outputs we find suggest potential model refinements. We discuss further extensions of our methods, some of which we are considering in ongoing work.