 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Extreme Precipitation Seasonal Forecast Using a Transformer Neural Network
Jul 14, 2021
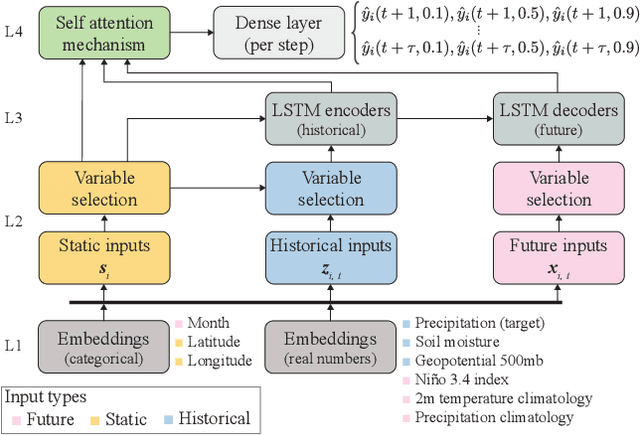
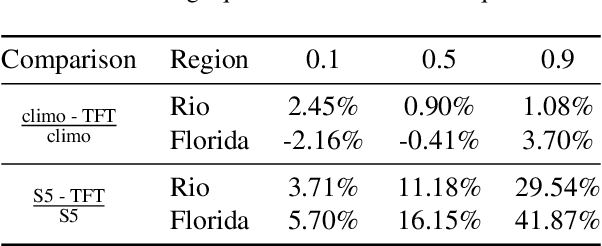
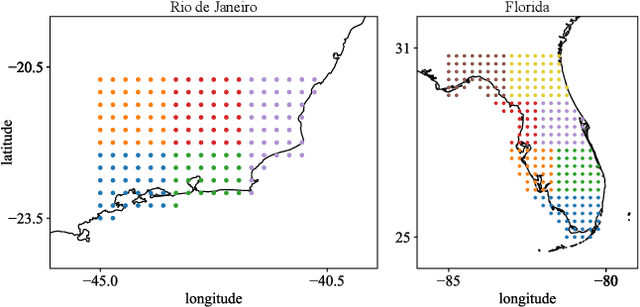
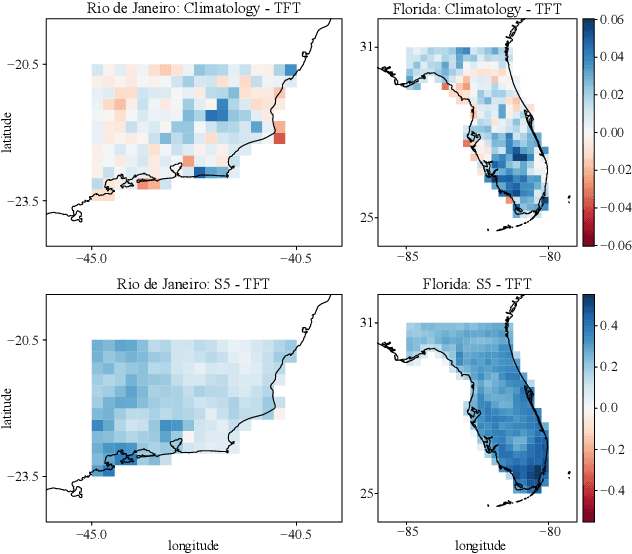
An impact of climate change is the increase in frequency and intensity of extreme precipitation events. However, confidently predicting the likelihood of extreme precipitation at seasonal scales remains an outstanding challenge. Here, we present an approach to forecasting the quantiles of the maximum daily precipitation in each week up to six months ahead using the temporal fusion transformer (TFT) model. Through experiments in two regions, we compare TFT predictions with those of two baselines: climatology and a calibrated ECMWF SEAS5 ensemble forecast (S5). Our results show that, in terms of quantile risk at six month lead time, the TFT predictions significantly outperform those from S5 and show an overall small improvement compared to climatology. The TFT also responds positively to departures from normal that climatology cannot.
Towards a distributed and real-time framework for robots: Evaluation of ROS 2.0 communications for real-time robotic applications
Sep 07, 2018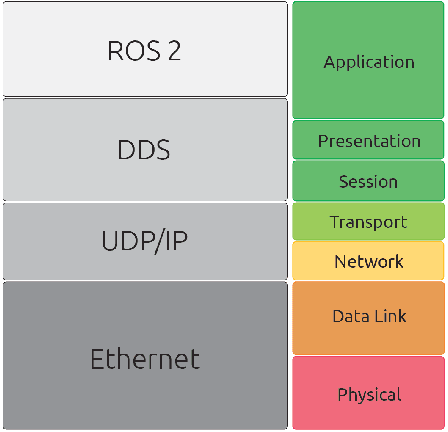
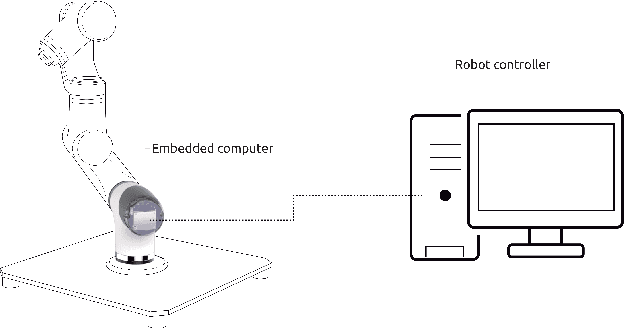
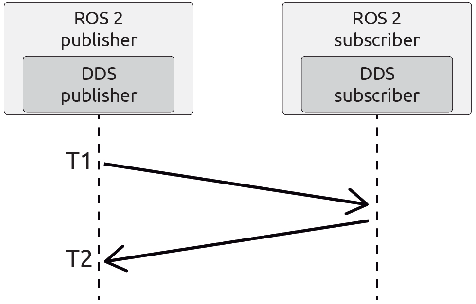
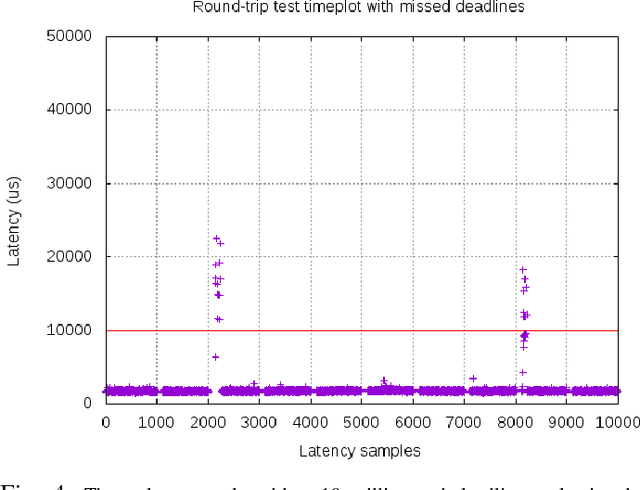
In this work we present an experimental setup to show the suitability of ROS 2.0 for real-time robotic applications. We disclose an evaluation of ROS 2.0 communications in a robotic inter-component (hardware) communication case on top of Linux. We benchmark and study the worst case latencies and missed deadlines to characterize ROS 2.0 communications for real-time applications. We demonstrate experimentally how computation and network congestion impacts the communication latencies and ultimately, propose a setup that, under certain conditions, mitigates these delays and obtains bounded traffic.
Updates of Equilibrium Prop Match Gradients of Backprop Through Time in an RNN with Static Input
May 31, 2019
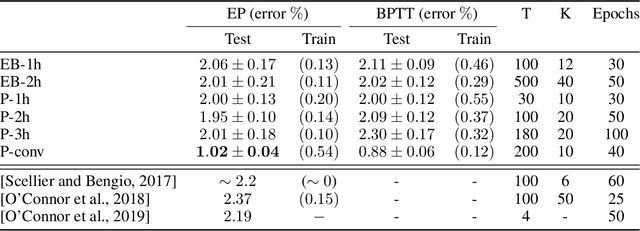
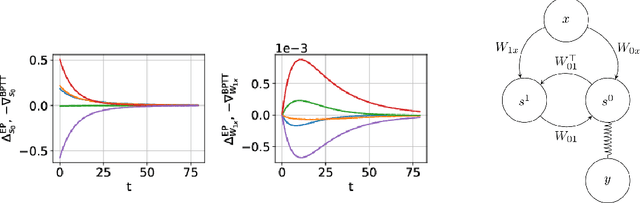
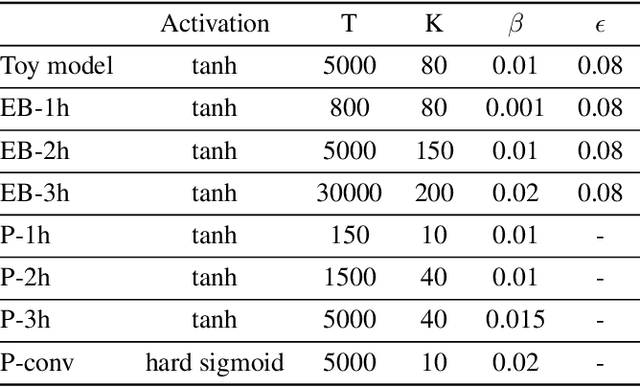
Equilibrium Propagation (EP) is a biologically inspired learning algorithm for convergent recurrent neural networks, i.e. RNNs that are fed by a static input x and settle to a steady state. Training convergent RNNs consists in adjusting the weights until the steady state of output neurons coincides with a target y. Convergent RNNs can also be trained with the more conventional Backpropagation Through Time (BPTT) algorithm. In its original formulation EP was described in the case of real-time neuronal dynamics, which is computationally costly. In this work, we introduce a discrete-time version of EP with simplified equations and with reduced simulation time, bringing EP closer to practical machine learning tasks. We first prove theoretically, as well as numerically that the neural and weight updates of EP, computed by forward-time dynamics, are step-by-step equal to the ones obtained by BPTT, with gradients computed backward in time. The equality is strict when the transition function of the dynamics derives from a primitive function and the steady state is maintained long enough. We then show for more standard discrete-time neural network dynamics that the same property is approximately respected and we subsequently demonstrate training with EP with equivalent performance to BPTT. In particular, we define the first convolutional architecture trained with EP achieving ~ 1% test error on MNIST, which is the lowest error reported with EP. These results can guide the development of deep neural networks trained with EP.
Unsupervised Path Representation Learning with Curriculum Negative Sampling
Jun 17, 2021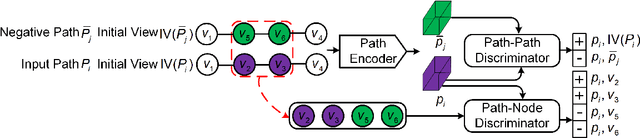
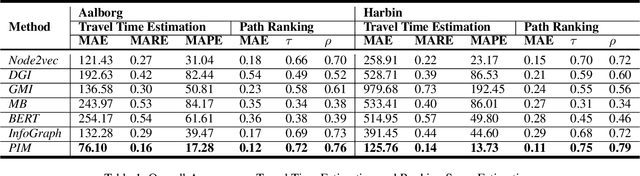
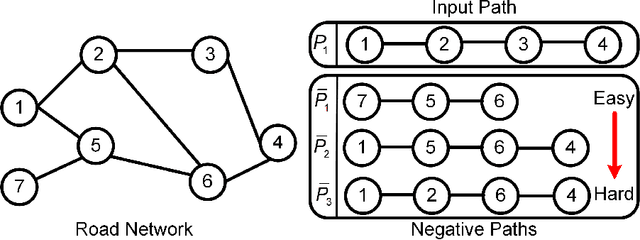
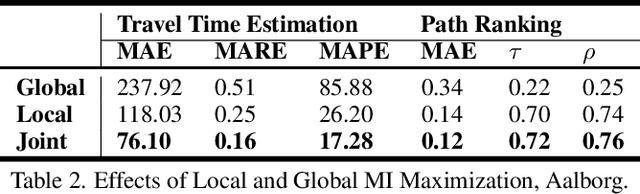
Path representations are critical in a variety of transportation applications, such as estimating path ranking in path recommendation systems and estimating path travel time in navigation systems. Existing studies often learn task-specific path representations in a supervised manner, which require a large amount of labeled training data and generalize poorly to other tasks. We propose an unsupervised learning framework Path InfoMax (PIM) to learn generic path representations that work for different downstream tasks. We first propose a curriculum negative sampling method, for each input path, to generate a small amount of negative paths, by following the principles of curriculum learning. Next, \emph{PIM} employs mutual information maximization to learn path representations from both a global and a local view. In the global view, PIM distinguishes the representations of the input paths from those of the negative paths. In the local view, \emph{PIM} distinguishes the input path representations from the representations of the nodes that appear only in the negative paths. This enables the learned path representations to encode both global and local information at different scales. Extensive experiments on two downstream tasks, ranking score estimation and travel time estimation, using two road network datasets suggest that PIM significantly outperforms other unsupervised methods and is also able to be used as a pre-training method to enhance supervised path representation learning.
Approximate Fixed-Points in Recurrent Neural Networks
Jun 04, 2021
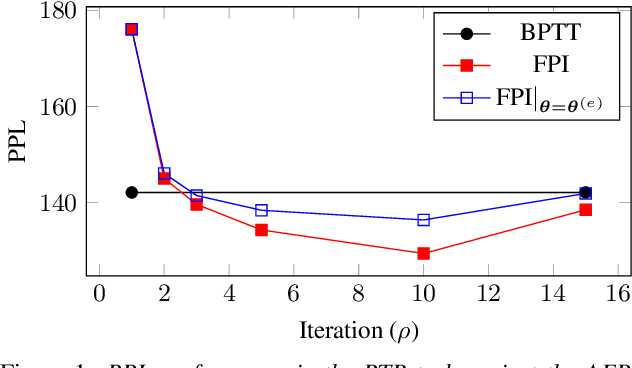
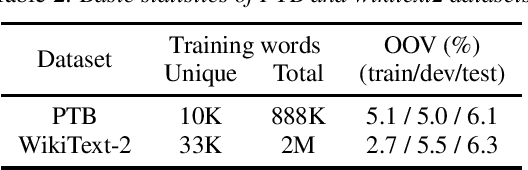
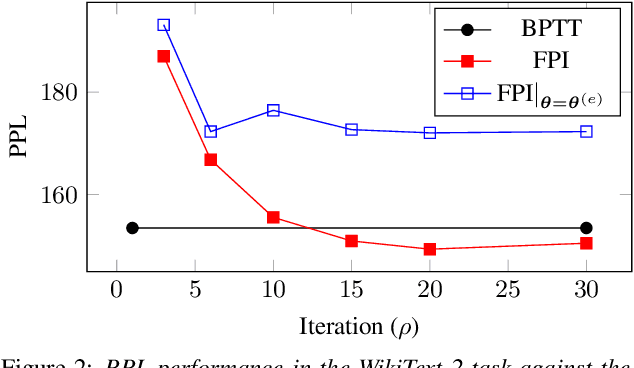
Recurrent neural networks are widely used in speech and language processing. Due to dependency on the past, standard algorithms for training these models, such as back-propagation through time (BPTT), cannot be efficiently parallelised. Furthermore, applying these models to more complex structures than sequences requires inference time approximations, which introduce inconsistency between inference and training. This paper shows that recurrent neural networks can be reformulated as fixed-points of non-linear equation systems. These fixed-points can be computed using an iterative algorithm exactly and in as many iterations as the length of any given sequence. Each iteration of this algorithm adds one additional Markovian-like order of dependencies such that upon termination all dependencies modelled by the recurrent neural networks have been incorporated. Although exact fixed-points inherit the same parallelization and inconsistency issues, this paper shows that approximate fixed-points can be computed in parallel and used consistently in training and inference including tasks such as lattice rescoring. Experimental validation is performed in two tasks, Penn Tree Bank and WikiText-2, and shows that approximate fixed-points yield competitive prediction performance to recurrent neural networks trained using the BPTT algorithm.
Program-to-Circuit: Exploiting GNNs for Program Representation and Circuit Translation
Sep 13, 2021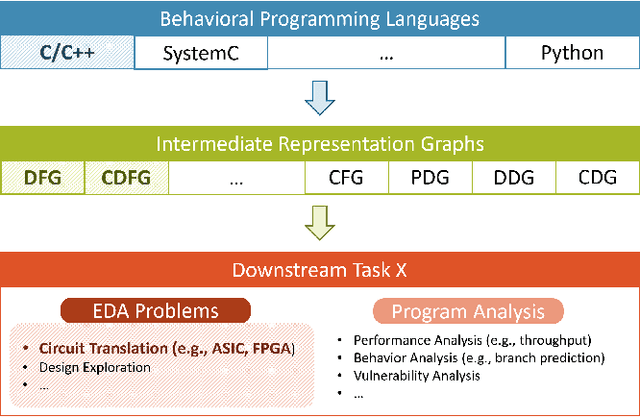

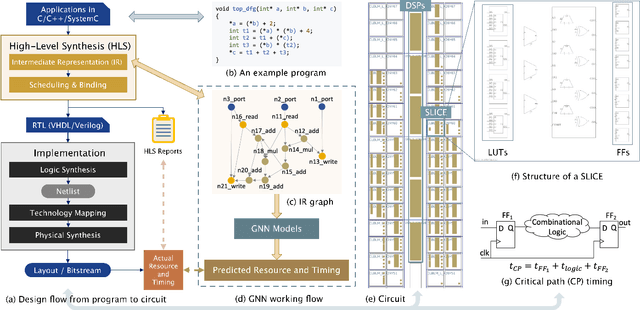

Circuit design is complicated and requires extensive domain-specific expertise. One major obstacle stuck on the way to hardware agile development is the considerably time-consuming process of accurate circuit quality evaluation. To significantly expedite the circuit evaluation during the translation from behavioral languages to circuit designs, we formulate it as a Program-to-Circuit problem, aiming to exploit the representation power of graph neural networks (GNNs) by representing C/C++ programs as graphs. The goal of this work is four-fold. First, we build a standard benchmark containing 40k C/C++ programs, each of which is translated to a circuit design with actual hardware quality metrics, aiming to facilitate the development of effective GNNs targeting this high-demand circuit design area. Second, 14 state-of-the-art GNN models are analyzed on the Program-to-Circuit problem. We identify key design challenges of this problem, which should be carefully handled but not yet solved by existing GNNs. The goal is to provide domain-specific knowledge for designing GNNs with suitable inductive biases. Third, we discuss three sets of real-world benchmarks for GNN generalization evaluation, and analyze the performance gap between standard programs and the real-case ones. The goal is to enable transfer learning from limited training data to real-world large-scale circuit design problems. Fourth, the Program-to-Circuit problem is a representative within the Program-to-X framework, a set of program-based analysis problems with various downstream tasks. The in-depth understanding of strength and weaknesses in applying GNNs on Program-to-Circuit could largely benefit the entire family of Program-to-X. Pioneering in this direction, we expect more GNN endeavors to revolutionize this high-demand Program-to-Circuit problem and to enrich the expressiveness of GNNs on programs.
Stability & Generalisation of Gradient Descent for Shallow Neural Networks without the Neural Tangent Kernel
Jul 27, 2021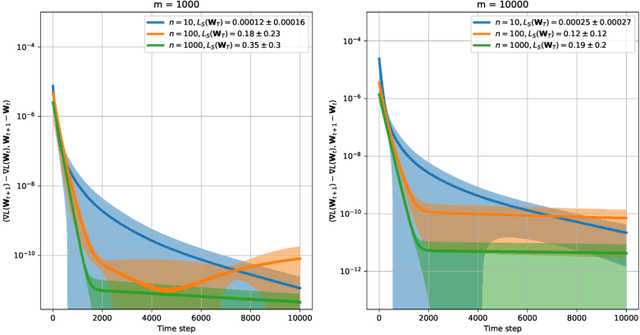
We revisit on-average algorithmic stability of Gradient Descent (GD) for training overparameterised shallow neural networks and prove new generalisation and excess risk bounds without the Neural Tangent Kernel (NTK) or Polyak-{\L}ojasiewicz (PL) assumptions. In particular, we show oracle type bounds which reveal that the generalisation and excess risk of GD is controlled by an interpolating network with the shortest GD path from initialisation (in a sense, an interpolating network with the smallest relative norm). While this was known for kernelised interpolants, our proof applies directly to networks trained by GD without intermediate kernelisation. At the same time, by relaxing oracle inequalities developed here we recover existing NTK-based risk bounds in a straightforward way, which demonstrates that our analysis is tighter. Finally, unlike most of the NTK-based analyses we focus on regression with label noise and show that GD with early stopping is consistent.
DVMN: Dense Validity Mask Network for Depth Completion
Jul 14, 2021
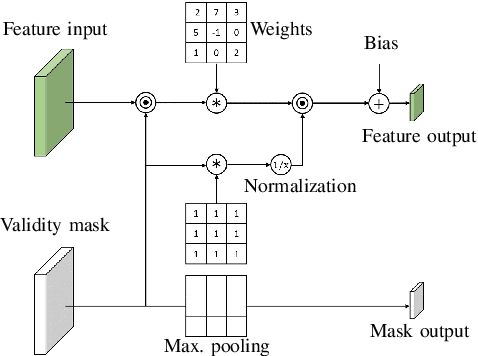
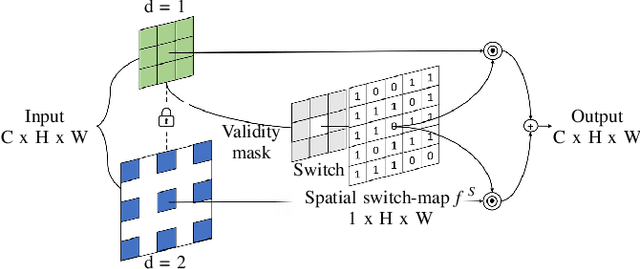
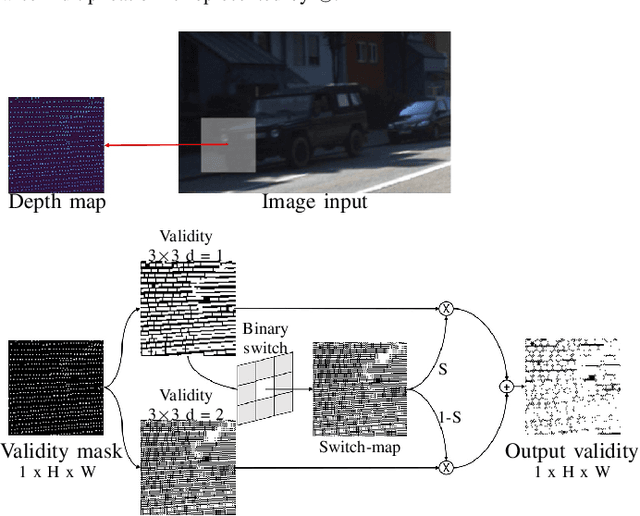
LiDAR depth maps provide environmental guidance in a variety of applications. However, such depth maps are typically sparse and insufficient for complex tasks such as autonomous navigation. State of the art methods use image guided neural networks for dense depth completion. We develop a guided convolutional neural network focusing on gathering dense and valid information from sparse depth maps. To this end, we introduce a novel layer with spatially variant and content-depended dilation to include additional data from sparse input. Furthermore, we propose a sparsity invariant residual bottleneck block. We evaluate our Dense Validity Mask Network (DVMN) on the KITTI depth completion benchmark and achieve state of the art results. At the time of submission, our network is the leading method using sparsity invariant convolution.
Dynamic and Static Object Detection Considering Fusion Regions and Point-wise Features
Jul 27, 2021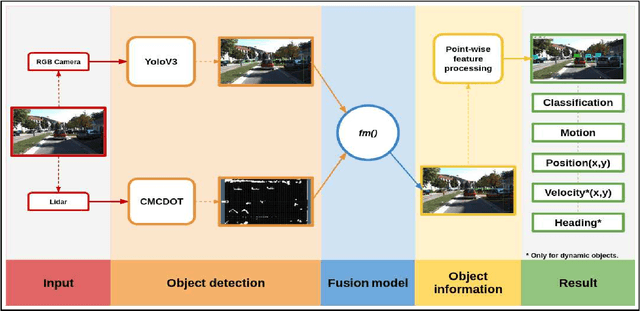
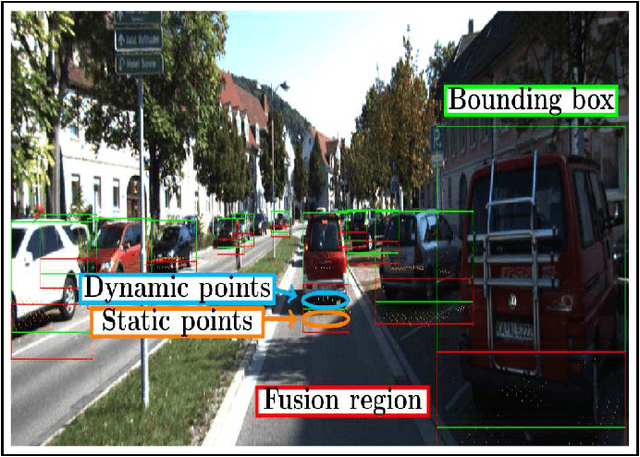
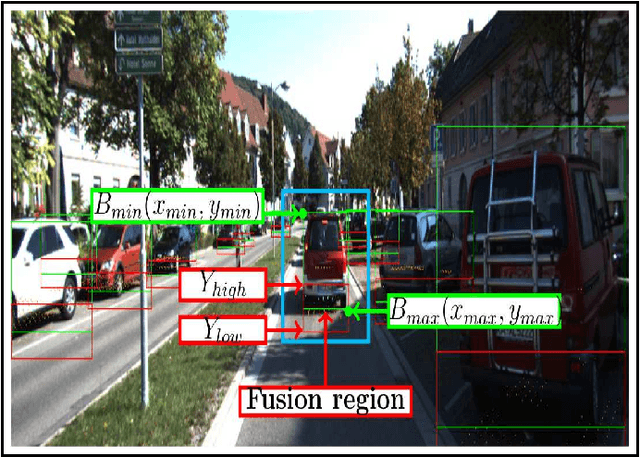
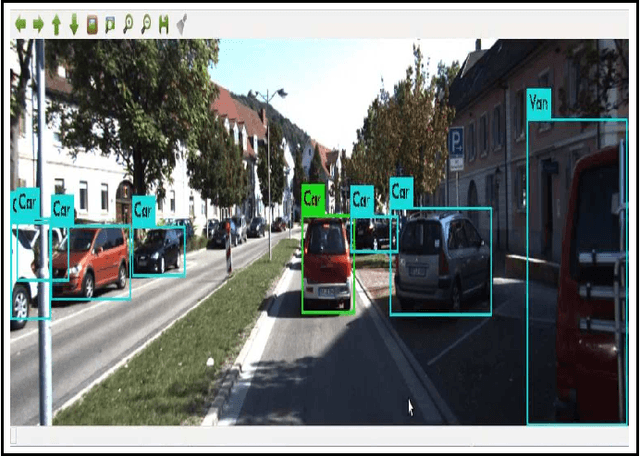
Object detection is a critical problem for the safe interaction between autonomous vehicles and road users. Deep-learning methodologies allowed the development of object detection approaches with better performance. However, there is still the challenge to obtain more characteristics from the objects detected in real-time. The main reason is that more information from the environment's objects can improve the autonomous vehicle capacity to face different urban situations. This paper proposes a new approach to detect static and dynamic objects in front of an autonomous vehicle. Our approach can also get other characteristics from the objects detected, like their position, velocity, and heading. We develop our proposal fusing results of the environment's interpretations achieved of YoloV3 and a Bayesian filter. To demonstrate our proposal's performance, we asses it through a benchmark dataset and real-world data obtained from an autonomous platform. We compared the results achieved with another approach.
TFRD: A Benchmark Dataset for Research on Temperature Field Reconstruction of Heat-Source Systems
Aug 20, 2021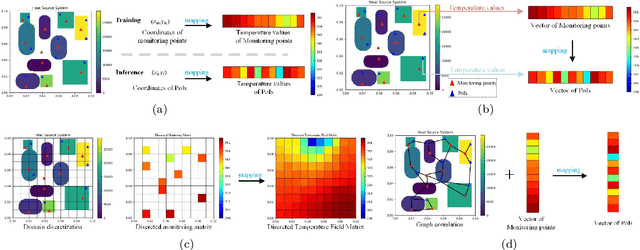
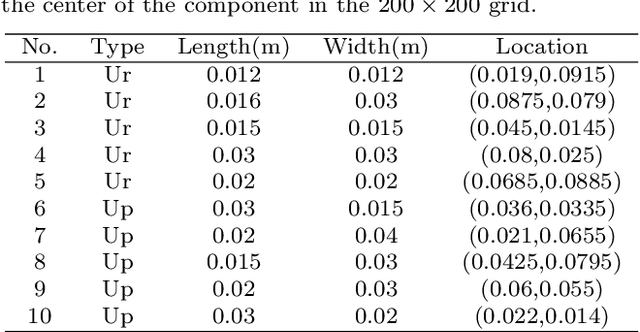
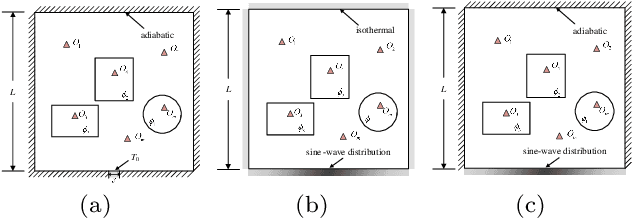
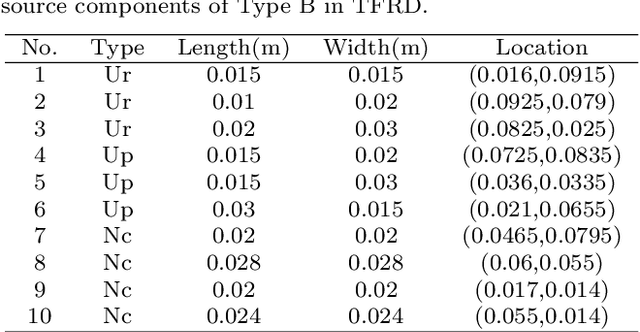
Temperature field reconstruction of heat source systems (TFR-HSS) with limited monitoring sensors occurred in thermal management plays an important role in real time health detection system of electronic equipment in engineering. However, prior methods with common interpolations usually cannot provide accurate reconstruction. In addition, there exists no public dataset for widely research of reconstruction methods to further boost the field reconstruction in engineering. To overcome this problem, this work constructs a specific dataset, namely Temperature Field Reconstruction Dataset (TFRD), for TFR-HSS task with commonly used methods, including the interpolation methods and the machine learning based methods, as baselines to advance the research over temperature field reconstruction. First, the TFR-HSS task is mathematically modelled from real-world engineering problem and four types of numerically modellings have been constructed to transform the problem into discrete mapping forms. Besides, this work selects three typical reconstruction problem over heat-source systems with different heat-source information and boundary conditions, and generate the training and testing samples for further research. Finally, a comprehensive review of the prior methods for TFR-HSS task as well as recent widely used deep learning methods is given and we provide a performance analysis of typical methods on TFRD, which can be served as the baseline results on this benchmark.