 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Adaptive Rate NOMA for Cellular IoT Networks
Aug 18, 2021
Internet-of-Things (IoT) technology is envisioned to enable a variety of real-time applications by interconnecting billions of sensors/devices deployed to observe some random physical processes. These IoT devices rely on low-power wide-area wireless connectivity for transmitting, mostly fixed- but small-size, status updates of their associated random processes. The cellular networks are seen as a natural candidate for providing reliable wireless connectivity to IoT devices. However, the conventional orthogonal multiple access (OMA) to these massive number of devices is expected to degrade the spectral efficiency. As a promising alternative to OMA, the cellular base stations (BSs) can employ non-orthogonal multiple access (NOMA) for the uplink transmissions of mobile users and IoT devices. In particular, the uplink NOMA can be configured such that the mobile user can adapt transmission rate based on its channel condition while the IoT device transmits at a fixed rate. For this setting, we analyze the ergodic capacity of mobile users and the mean local delay of IoT devices using stochastic geometry. Our analysis demonstrates that the above NOMA configuration can provide better ergodic capacity for mobile users compare to OMA when IoT devices' delay constraint is strict. Furthermore, we also show that NOMA can support a larger packet size for IoT devices than OMA under the same delay constraint.
Online Spatio-temporal Calibration of Tightly-coupled Ultrawideband-aided Inertial Localization
Jul 31, 2021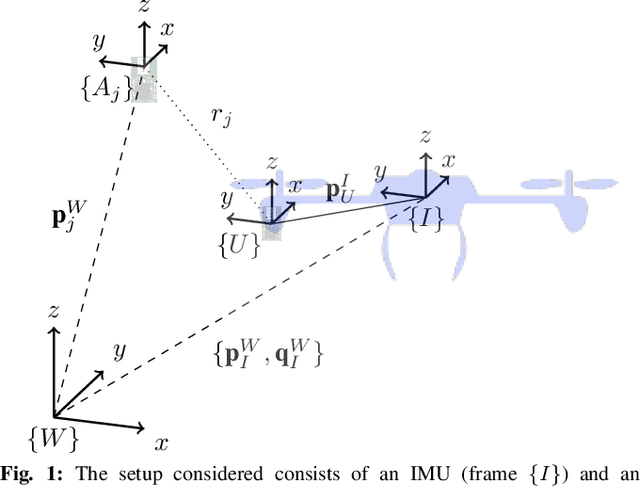
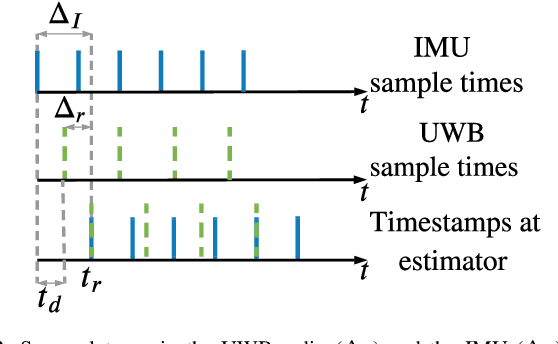
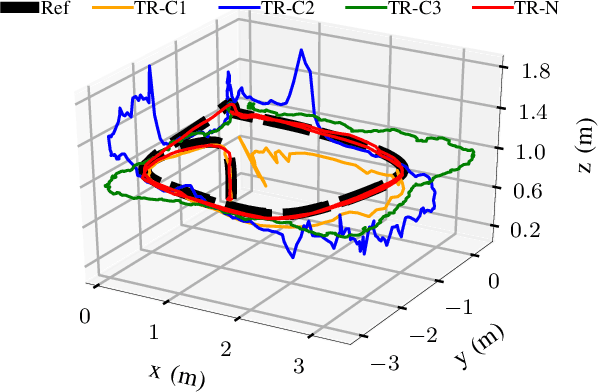
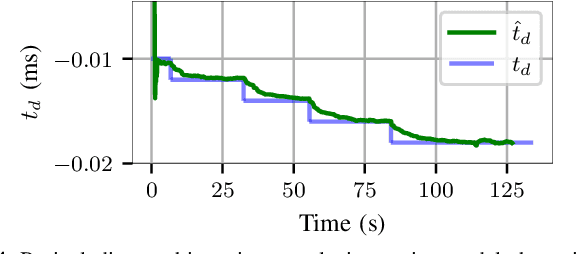
The combination of ultrawideband (UWB) radios and inertial measurement units (IMU) can provide accurate positioning in environments where the Global Positioning System (GPS) service is either unavailable or has unsatisfactory performance. The two sensors, IMU and UWB radio, are often not co-located on a moving system. The UWB radio is typically located at the extremities of the system to ensure reliable communication, whereas the IMUs are located closer to its center of gravity. Furthermore, without hardware or software synchronization, data from heterogeneous sensors can arrive at different time instants resulting in temporal offsets. If uncalibrated, these spatial and temporal offsets can degrade the positioning performance. In this paper, using observability and identifiability criteria, we derive the conditions required for successfully calibrating the spatial and the temporal offset parameters of a tightly-coupled UWB-IMU system. We also present an online method for jointly calibrating these offsets. The results show that our calibration approach results in improved positioning accuracy while simultaneously estimating (i) the spatial offset parameters to millimeter precision and (ii) the temporal offset parameter to millisecond precision.
A Periodicity-based Parallel Time Series Prediction Algorithm in Cloud Computing Environments
Oct 17, 2018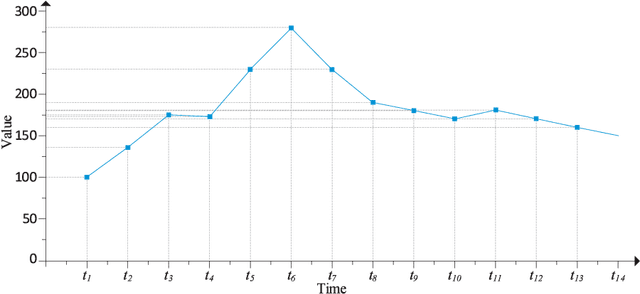

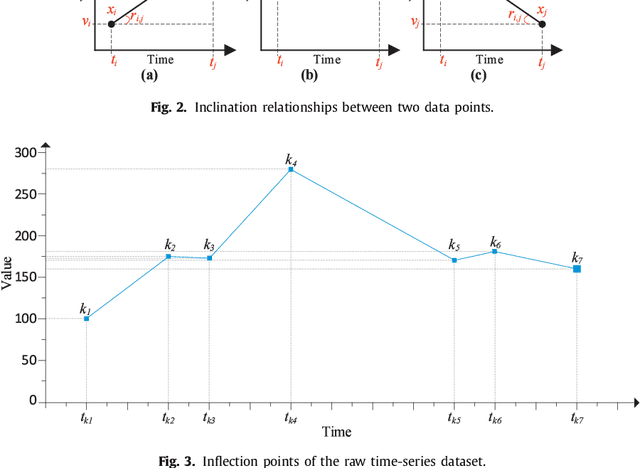
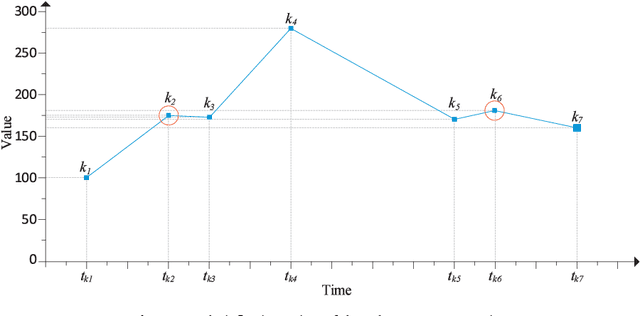
In the era of big data, practical applications in various domains continually generate large-scale time-series data. Among them, some data show significant or potential periodicity characteristics, such as meteorological and financial data. It is critical to efficiently identify the potential periodic patterns from massive time-series data and provide accurate predictions. In this paper, a Periodicity-based Parallel Time Series Prediction (PPTSP) algorithm for large-scale time-series data is proposed and implemented in the Apache Spark cloud computing environment. To effectively handle the massive historical datasets, a Time Series Data Compression and Abstraction (TSDCA) algorithm is presented, which can reduce the data scale as well as accurately extracting the characteristics. Based on this, we propose a Multi-layer Time Series Periodic Pattern Recognition (MTSPPR) algorithm using the Fourier Spectrum Analysis (FSA) method. In addition, a Periodicity-based Time Series Prediction (PTSP) algorithm is proposed. Data in the subsequent period are predicted based on all previous period models, in which a time attenuation factor is introduced to control the impact of different periods on the prediction results. Moreover, to improve the performance of the proposed algorithms, we propose a parallel solution on the Apache Spark platform, using the Streaming real-time computing module. To efficiently process the large-scale time-series datasets in distributed computing environments, Distributed Streams (DStreams) and Resilient Distributed Datasets (RDDs) are used to store and calculate these datasets. Extensive experimental results show that our PPTSP algorithm has significant advantages compared with other algorithms in terms of prediction accuracy and performance.
Learning-Based UAV Trajectory Optimization with Collision Avoidance and Connectivity Constraints
Apr 15, 2021
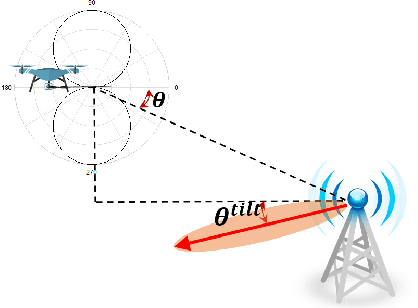
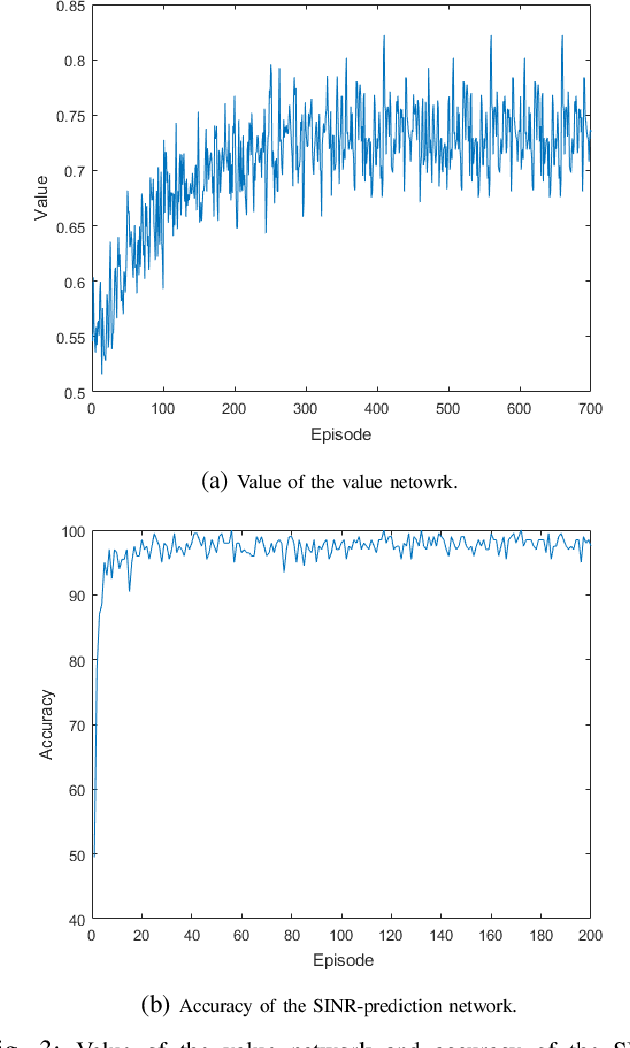
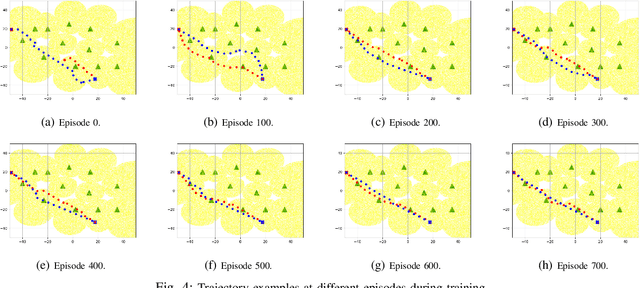
Unmanned aerial vehicles (UAVs) are expected to be an integral part of wireless networks, and determining collision-free trajectories for multiple UAVs while satisfying requirements of connectivity with ground base stations (GBSs) is a challenging task. In this paper, we first reformulate the multi-UAV trajectory optimization problem with collision avoidance and wireless connectivity constraints as a sequential decision making problem in the discrete time domain. We, then, propose a decentralized deep reinforcement learning approach to solve the problem. More specifically, a value network is developed to encode the expected time to destination given the agent's joint state (including the agent's information, the nearby agents' observable information, and the locations of the nearby GBSs). A signal-to-interference-plus-noise ratio (SINR)-prediction neural network is also designed, using accumulated SINR measurements obtained when interacting with the cellular network, to map the GBSs' locations into the SINR levels in order to predict the UAV's SINR. Numerical results show that with the value network and SINR-prediction network, real-time navigation for multi-UAVs can be efficiently performed in various environments with high success rate.
Time-Series Analysis via Low-Rank Matrix Factorization Applied to Infant-Sleep Data
Apr 10, 2019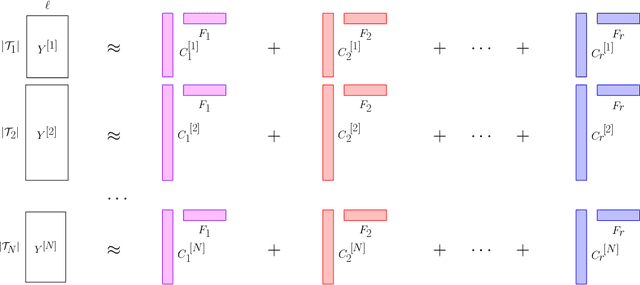
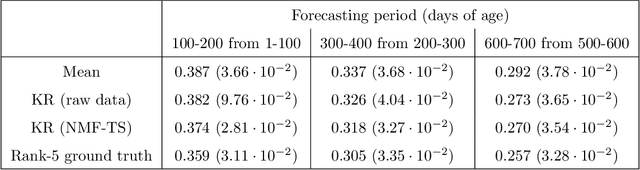
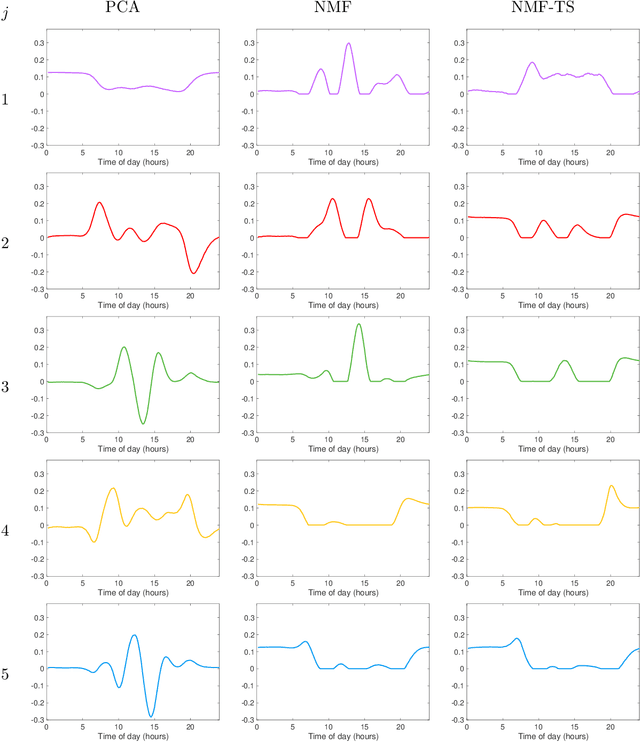
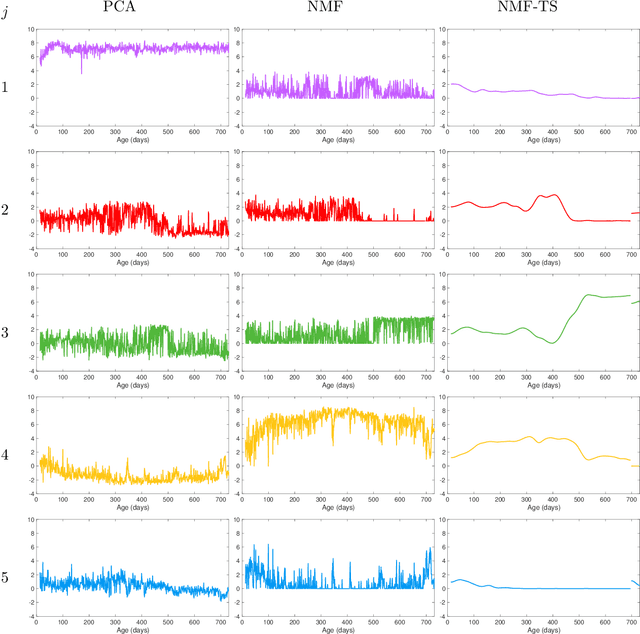
We propose a nonparametric model for time series with missing data based on low-rank matrix factorization. The model expresses each instance in a set of time series as a linear combination of a small number of shared basis functions. Constraining the functions and the corresponding coefficients to be nonnegative yields an interpretable low-dimensional representation of the data. A time-smoothing regularization term ensures that the model captures meaningful trends in the data, instead of overfitting short-term fluctuations. The low-dimensional representation makes it possible to detect outliers and cluster the time series according to the interpretable features extracted by the model, and also to perform forecasting via kernel regression. We apply our methodology to a large real-world dataset of infant-sleep data gathered by caregivers with a mobile-phone app. Our analysis automatically extracts daily-sleep patterns consistent with the existing literature. This allows us to compute sleep-development trends for the cohort, which characterize the emergence of circadian sleep and different napping habits. We apply our methodology to detect anomalous individuals, to cluster the cohort into groups with different sleeping tendencies, and to obtain improved predictions of future sleep behavior.
Finite-Time Error Bounds For Linear Stochastic Approximation and TD Learning
Mar 07, 2019We consider the dynamics of a linear stochastic approximation algorithm driven by Markovian noise, and derive finite-time bounds on the moments of the error, i.e., deviation of the output of the algorithm from the equilibrium point of an associated ordinary differential equation (ODE). We obtain finite-time bounds on the mean-square error in the case of constant step-size algorithms by considering the drift of an appropriately chosen Lyapunov function. The Lyapunov function can be interpreted either in terms of Stein's method to obtain bounds on steady-state performance or in terms of Lyapunov stability theory for linear ODEs. We also provide a comprehensive treatment of the moments of the square of the 2-norm of the approximation error. Our analysis yields the following results: (i) for a given step-size, we show that the lower-order moments can be made small as a function of the step-size and can be upper-bounded by the moments of a Gaussian random variable; (ii) we show that the higher-order moments beyond a threshold may be infinite in steady-state; and (iii) we characterize the number of samples needed for the finite-time bounds to be of the same order as the steady-state bounds. As a by-product of our analysis, we also solve the open problem of obtaining finite-time bounds for the performance of temporal difference learning algorithms with linear function approximation and a constant step-size, without requiring a projection step or an i.i.d. noise assumption.
A 1d convolutional network for leaf and time series classification
Jun 28, 2019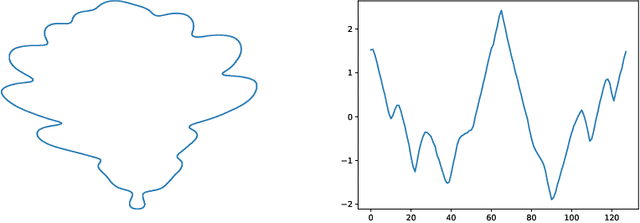
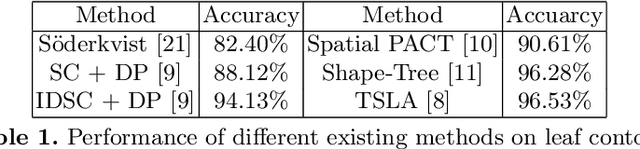
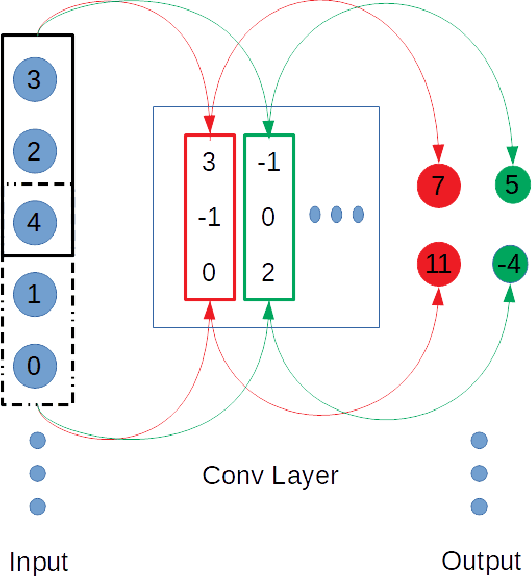
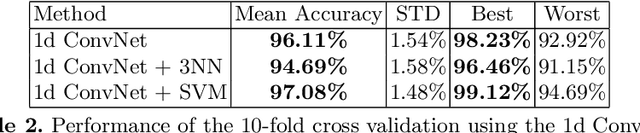
In this paper, a 1d convolutional neural network is designed for classification tasks of leaves with centroid contour distance curve (CCDC) as the single feature. With this classifier, simple feature as CCDC shows more discriminating power than people thought previously. The same architecture can also be applied for classifying 1 dimensional time series with little changes. Experiments on some benchmark datasets shows this architecture can provide classification accuracies that are higher than some existing methods. Code for the paper is available at https://github.com/dykuang/Leaf Project.
Opening the Blackbox: Accelerating Neural Differential Equations by Regularizing Internal Solver Heuristics
May 09, 2021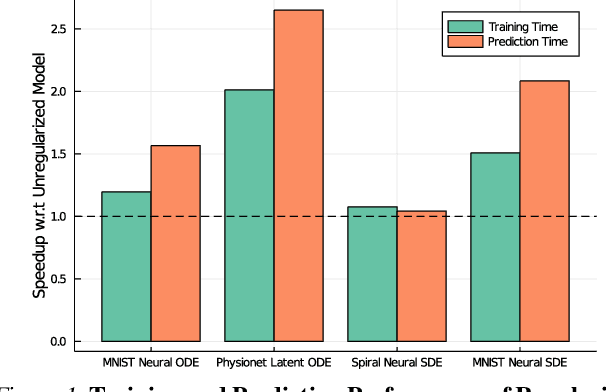
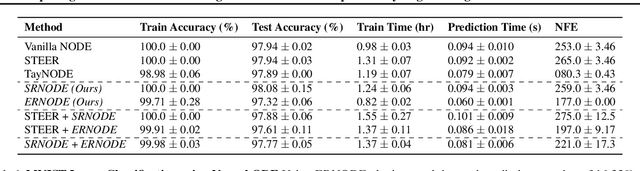
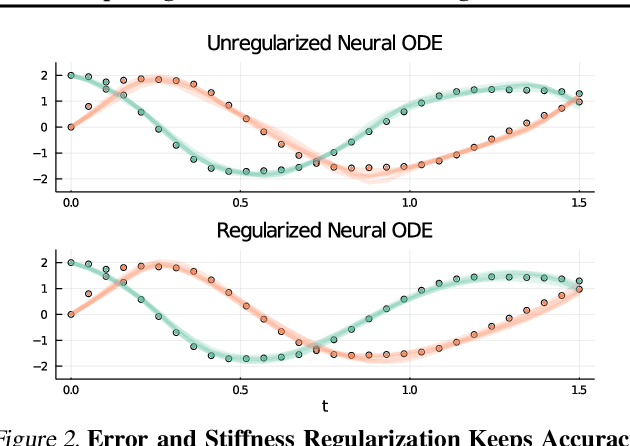
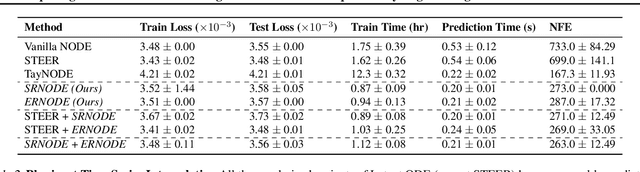
Democratization of machine learning requires architectures that automatically adapt to new problems. Neural Differential Equations (NDEs) have emerged as a popular modeling framework by removing the need for ML practitioners to choose the number of layers in a recurrent model. While we can control the computational cost by choosing the number of layers in standard architectures, in NDEs the number of neural network evaluations for a forward pass can depend on the number of steps of the adaptive ODE solver. But, can we force the NDE to learn the version with the least steps while not increasing the training cost? Current strategies to overcome slow prediction require high order automatic differentiation, leading to significantly higher training time. We describe a novel regularization method that uses the internal cost heuristics of adaptive differential equation solvers combined with discrete adjoint sensitivities to guide the training process towards learning NDEs that are easier to solve. This approach opens up the blackbox numerical analysis behind the differential equation solver's algorithm and directly uses its local error estimates and stiffness heuristics as cheap and accurate cost estimates. We incorporate our method without any change in the underlying NDE framework and show that our method extends beyond Ordinary Differential Equations to accommodate Neural Stochastic Differential Equations. We demonstrate how our approach can halve the prediction time and, unlike other methods which can increase the training time by an order of magnitude, we demonstrate similar reduction in training times. Together this showcases how the knowledge embedded within state-of-the-art equation solvers can be used to enhance machine learning.
Overfitting the Data: Compact Neural Video Delivery via Content-aware Feature Modulation
Aug 18, 2021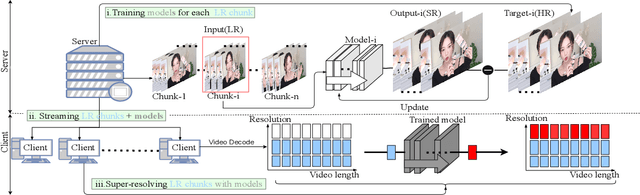
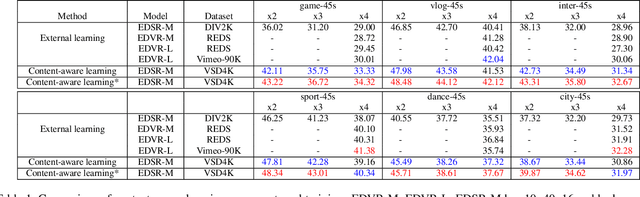

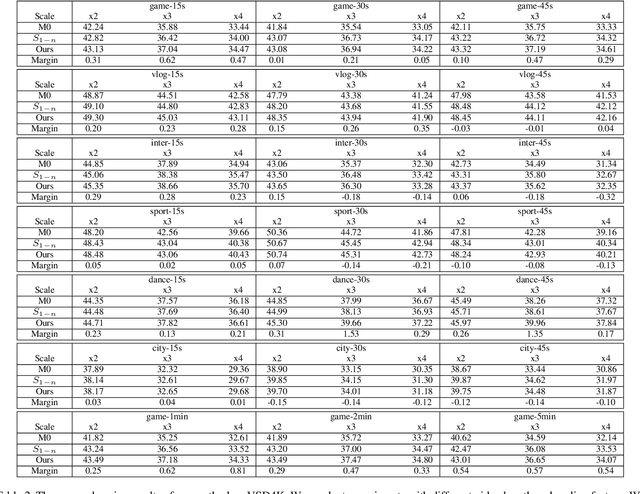
Internet video delivery has undergone a tremendous explosion of growth over the past few years. However, the quality of video delivery system greatly depends on the Internet bandwidth. Deep Neural Networks (DNNs) are utilized to improve the quality of video delivery recently. These methods divide a video into chunks, and stream LR video chunks and corresponding content-aware models to the client. The client runs the inference of models to super-resolve the LR chunks. Consequently, a large number of models are streamed in order to deliver a video. In this paper, we first carefully study the relation between models of different chunks, then we tactfully design a joint training framework along with the Content-aware Feature Modulation (CaFM) layer to compress these models for neural video delivery. {\bf With our method, each video chunk only requires less than $1\% $ of original parameters to be streamed, achieving even better SR performance.} We conduct extensive experiments across various SR backbones, video time length, and scaling factors to demonstrate the advantages of our method. Besides, our method can be also viewed as a new approach of video coding. Our primary experiments achieve better video quality compared with the commercial H.264 and H.265 standard under the same storage cost, showing the great potential of the proposed method. Code is available at:\url{https://github.com/Neural-video-delivery/CaFM-Pytorch-ICCV2021}
Real-time policy generation and its application to robot grasping
Aug 23, 2018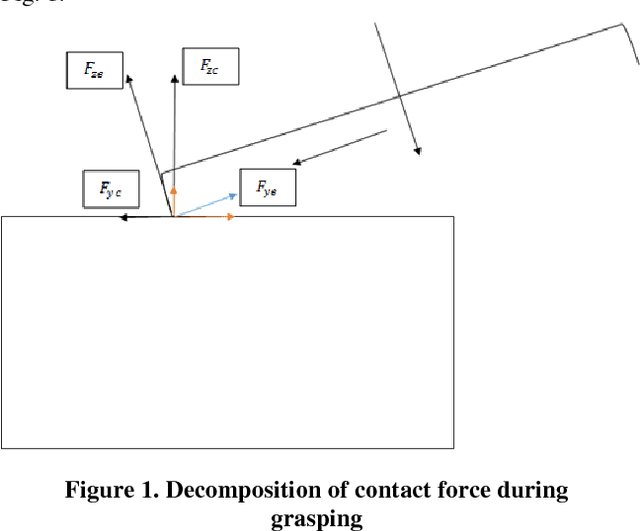
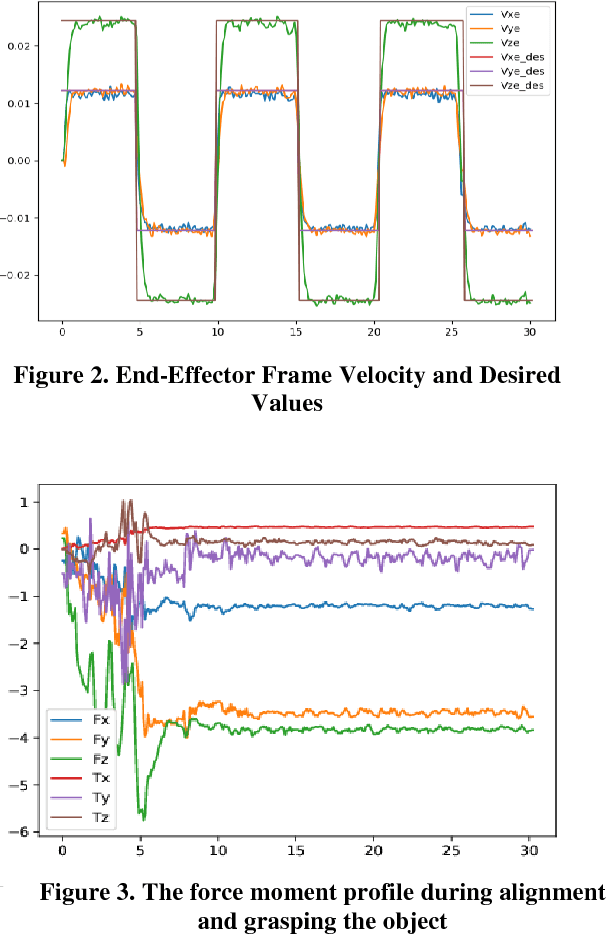
Real time applications such as robotic require real time actions based on the immediate available data. Machine learning and artificial intelligence rely on high volume of training informative data set to propose a comprehensive and useful model for later real time action. Our goal in this paper is to provide a solution for robot grasping as a real time application without the time and memory consuming pertaining phase. Grasping as one of the most important ability of human being is defined as a suitable configuration which depends on the perceived information from the object. For human being, the best results obtain when one incorporates the vision data such as the extracted edges and shape from the object into grasping task. Nevertheless, in robotics, vision will not suite for every situation. Another possibility to grasping is using the object shape information from its vicinity. Based on these Haptic information, similar to human being, one can propose different approaches to grasping which are called grasping policies. In this work, we are trying to introduce a real time policy which aims at keeping contact with the object during movement and alignment on it. First we state problem by system dynamic equation incorporated by the object constraint surface into dynamic equation. In next step, the suggested policy to accomplish the task in real time based on the available sensor information will be presented. The effectiveness of proposed approach will be evaluated by demonstration results.