 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Real-time Localization Using Radio Maps
Jun 09, 2020




This paper deals with the problem of localization in a cellular network in a dense urban scenario. Global Navigation Satellite System typically performs poorly in urban environments when there is no line-of-sight between the devices and the satellites, and thus alternative localization methods are often required. We present a simple yet effective method for localization based on pathloss. In our approach, the user to be localized reports the received signal strength from a set of base stations with known locations. For each base station we have a good approximation of the pathloss at each location in the map, provided by RadioUNet, an efficient deep learning-based simulator of pathloss functions in urban environment, akin to ray-tracing. Using the approximations of the pathloss functions of all base stations and the reported signal strengths, we are able to extract a very accurate approximation of the location of the user.
Continual learning under domain transfer with sparse synaptic bursting
Aug 26, 2021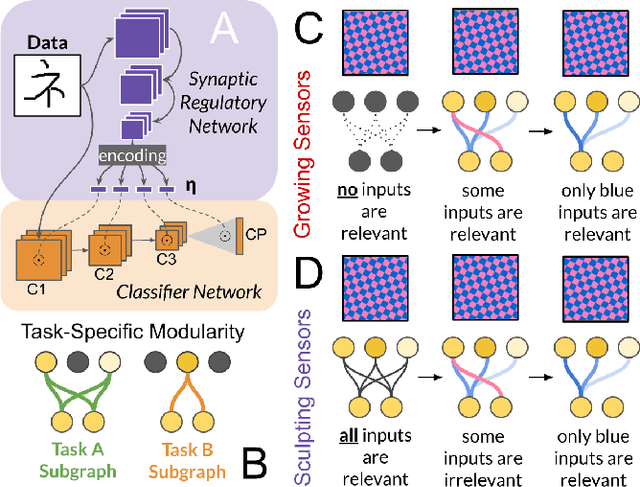
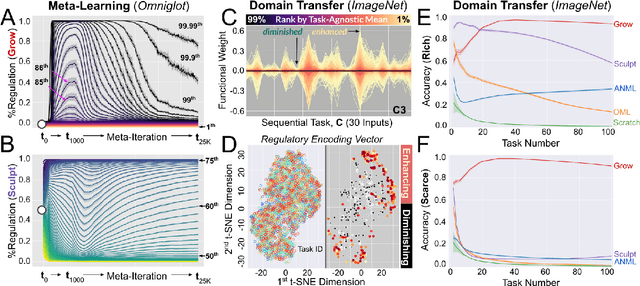
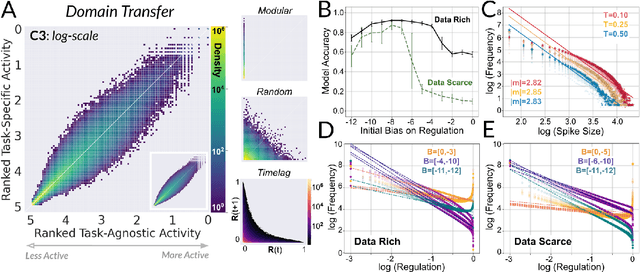
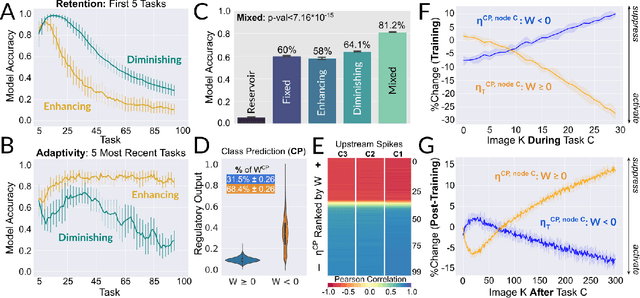
Existing machines are functionally specific tools that were made for easy prediction and control. Tomorrow's machines may be closer to biological systems in their mutability, resilience, and autonomy. But first they must be capable of learning, and retaining, new information without repeated exposure to it. Past efforts to engineer such systems have sought to build or regulate artificial neural networks using task-specific modules with constrained circumstances of application. This has not yet enabled continual learning over long sequences of previously unseen data without corrupting existing knowledge: a problem known as catastrophic forgetting. In this paper, we introduce a system that can learn sequentially over previously unseen datasets (ImageNet, CIFAR-100) with little forgetting over time. This is accomplished by regulating the activity of weights in a convolutional neural network on the basis of inputs using top-down modulation generated by a second feed-forward neural network. We find that our method learns continually under domain transfer with sparse bursts of activity in weights that are recycled across tasks, rather than by maintaining task-specific modules. Sparse synaptic bursting is found to balance enhanced and diminished activity in a way that facilitates adaptation to new inputs without corrupting previously acquired functions. This behavior emerges during a prior meta-learning phase in which regulated synapses are selectively disinhibited, or grown, from an initial state of uniform suppression.
RSM-GAN: A Convolutional Recurrent GAN for Anomaly Detection in Contaminated Seasonal Multivariate Time Series
Nov 16, 2019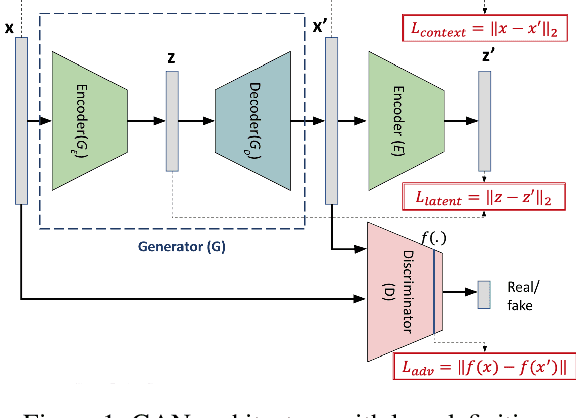
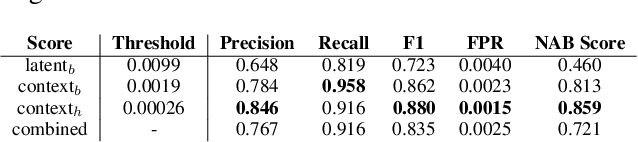
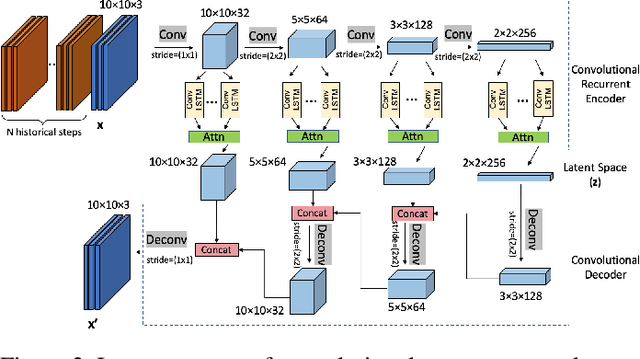
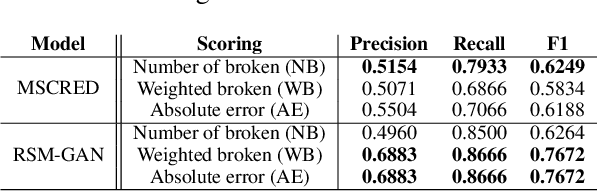
Robust anomaly detection is a requirement for monitoring complex modern systems with applications such as cyber-security, fraud prevention, and maintenance. These systems generate multiple correlated time series that are highly seasonal and noisy. This paper presents a novel unsupervised deep learning architecture for multivariate time series anomaly detection, called Robust Seasonal Multivariate Generative Adversarial Network (RSM-GAN). It extends recent advancements in GANs with adoption of convolutional-LSTM layers and an attention mechanism to produce state-of-the-art performance. We conduct extensive experiments to demonstrate the strength of our architecture in adjusting for complex seasonality patterns and handling severe levels of training data contamination. We also propose a novel anomaly score assignment and causal inference framework. We compare RSM-GAN with existing classical and deep-learning based anomaly detection models, and the results show that our architecture is associated with the lowest false positive rate and improves precision by 30% and 16% in real-world and synthetic data, respectively. Furthermore, we report the superiority of RSM-GAN regarding accurate root cause identification and NAB scores in all data settings.
Asynchronous Federated Learning for Sensor Data with Concept Drift
Sep 01, 2021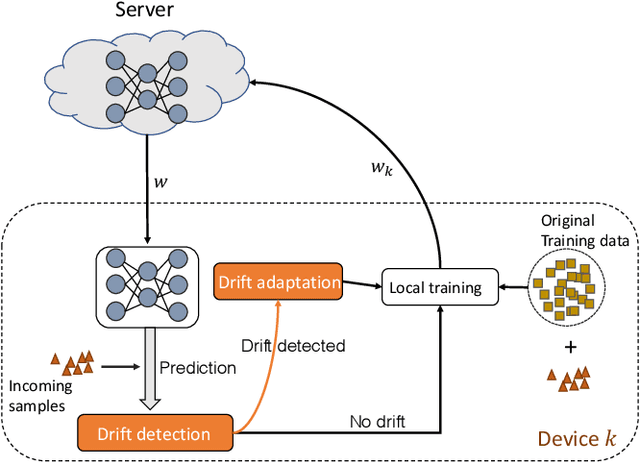
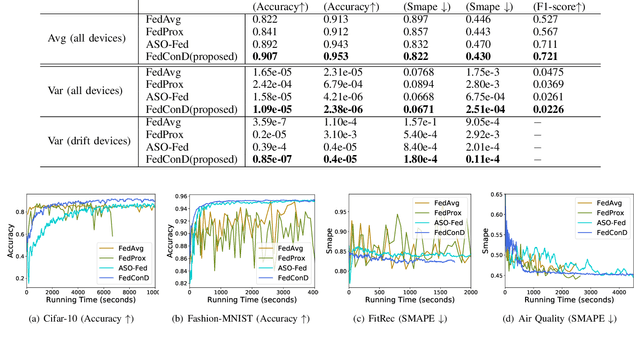
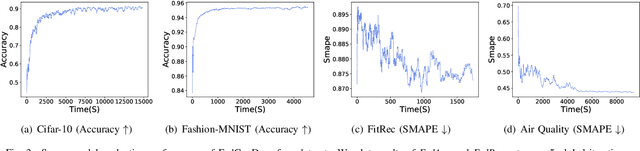
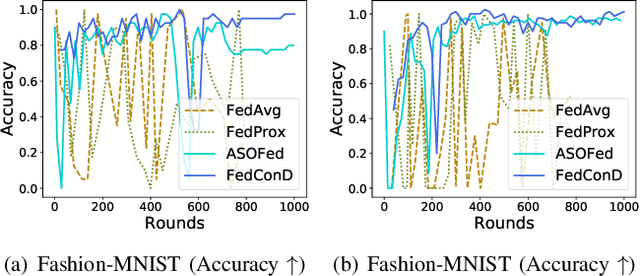
Federated learning (FL) involves multiple distributed devices jointly training a shared model without any of the participants having to reveal their local data to a centralized server. Most of previous FL approaches assume that data on devices are fixed and stationary during the training process. However, this assumption is unrealistic because these devices usually have varying sampling rates and different system configurations. In addition, the underlying distribution of the device data can change dynamically over time, which is known as concept drift. Concept drift makes the learning process complicated because of the inconsistency between existing and upcoming data. Traditional concept drift handling techniques such as chunk based and ensemble learning-based methods are not suitable in the federated learning frameworks due to the heterogeneity of local devices. We propose a novel approach, FedConD, to detect and deal with the concept drift on local devices and minimize the effect on the performance of models in asynchronous FL. The drift detection strategy is based on an adaptive mechanism which uses the historical performance of the local models. The drift adaptation is realized by adjusting the regularization parameter of objective function on each local device. Additionally, we design a communication strategy on the server side to select local updates in a prudent fashion and speed up model convergence. Experimental evaluations on three evolving data streams and two image datasets show that \model~detects and handles concept drift, and also reduces the overall communication cost compared to other baseline methods.
Federated Reconnaissance: Efficient, Distributed, Class-Incremental Learning
Sep 01, 2021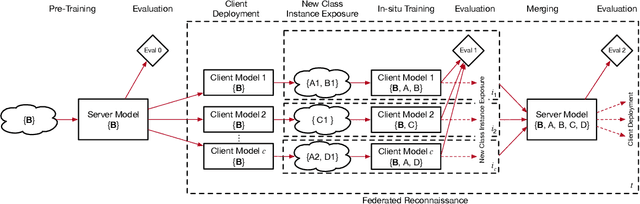
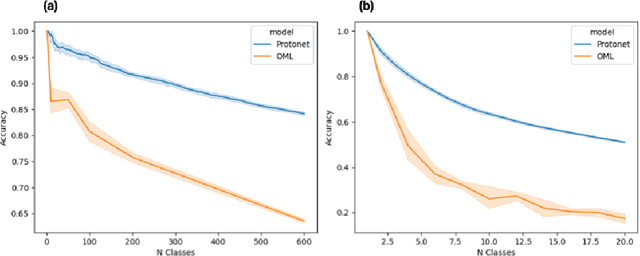
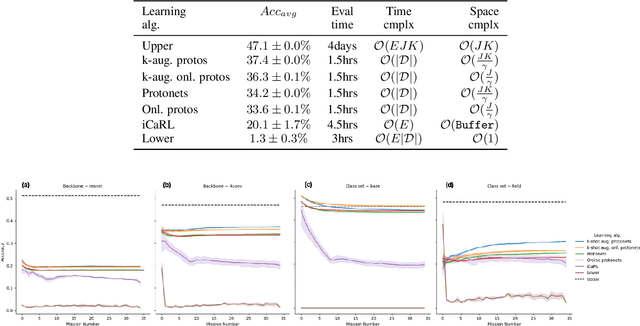
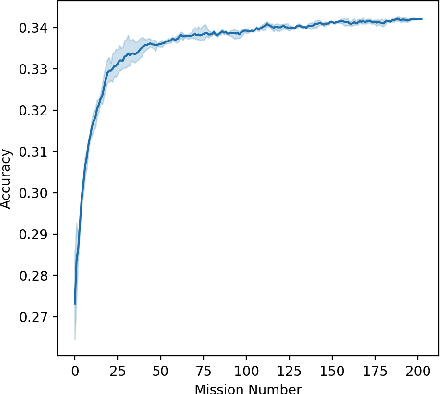
We describe federated reconnaissance, a class of learning problems in which distributed clients learn new concepts independently and communicate that knowledge efficiently. In particular, we propose an evaluation framework and methodological baseline for a system in which each client is expected to learn a growing set of classes and communicate knowledge of those classes efficiently with other clients, such that, after knowledge merging, the clients should be able to accurately discriminate between classes in the superset of classes observed by the set of clients. We compare a range of learning algorithms for this problem and find that prototypical networks are a strong approach in that they are robust to catastrophic forgetting while incorporating new information efficiently. Furthermore, we show that the online averaging of prototype vectors is effective for client model merging and requires only a small amount of communication overhead, memory, and update time per class with no gradient-based learning or hyperparameter tuning. Additionally, to put our results in context, we find that a simple, prototypical network with four convolutional layers significantly outperforms complex, state of the art continual learning algorithms, increasing the accuracy by over 22% after learning 600 Omniglot classes and over 33% after learning 20 mini-ImageNet classes incrementally. These results have important implications for federated reconnaissance and continual learning more generally by demonstrating that communicating feature vectors is an efficient, robust, and effective means for distributed, continual learning.
SinGAN-Seg: Synthetic Training Data Generation for Medical Image Segmentation
Jun 29, 2021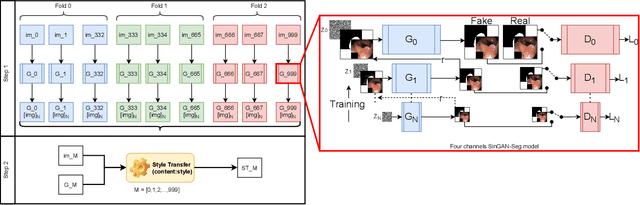
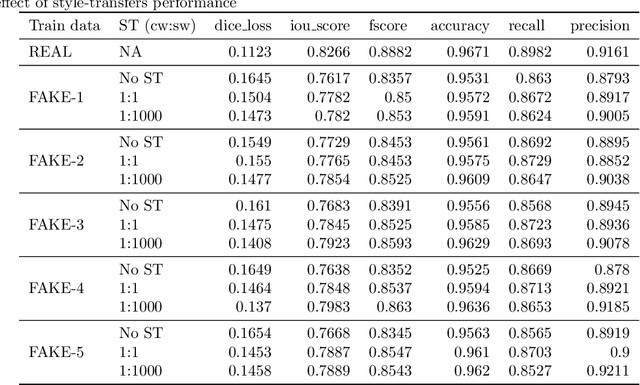
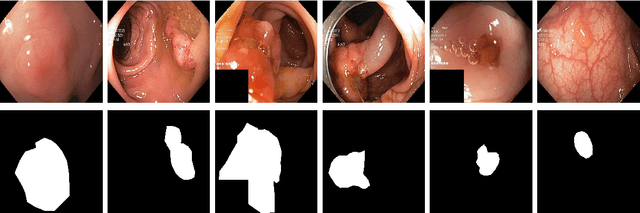
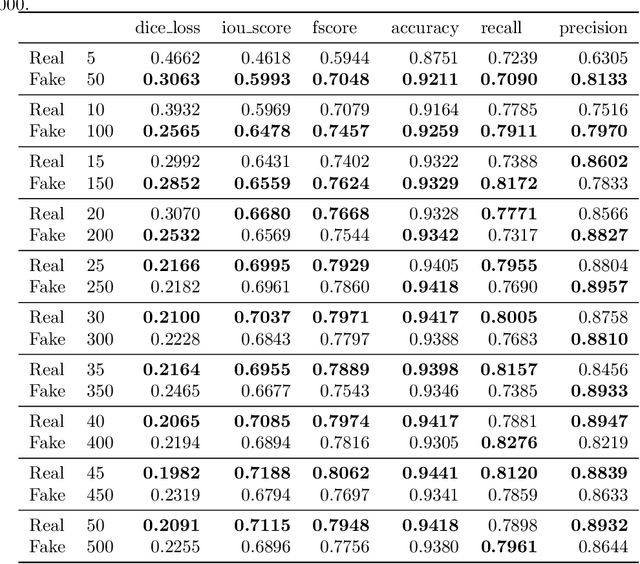
Processing medical data to find abnormalities is a time-consuming and costly task, requiring tremendous efforts from medical experts. Therefore, Ai has become a popular tool for the automatic processing of medical data, acting as a supportive tool for doctors. AI tools highly depend on data for training the models. However, there are several constraints to access to large amounts of medical data to train machine learning algorithms in the medical domain, e.g., due to privacy concerns and the costly, time-consuming medical data annotation process. To address this, in this paper we present a novel synthetic data generation pipeline called SinGAN-Seg to produce synthetic medical data with the corresponding annotated ground truth masks. We show that these synthetic data generation pipelines can be used as an alternative to bypass privacy concerns and as an alternative way to produce artificial segmentation datasets with corresponding ground truth masks to avoid the tedious medical data annotation process. As a proof of concept, we used an open polyp segmentation dataset. By training UNet++ using both the real polyp segmentation dataset and the corresponding synthetic dataset generated from the SinGAN-Seg pipeline, we show that the synthetic data can achieve a very close performance to the real data when the real segmentation datasets are large enough. In addition, we show that synthetic data generated from the SinGAN-Seg pipeline improving the performance of segmentation algorithms when the training dataset is very small. Since our SinGAN-Seg pipeline is applicable for any medical dataset, this pipeline can be used with any other segmentation datasets.
FBCNN: A Deep Neural Network Architecture for Portable and Fast Brain-Computer Interfaces
Sep 05, 2021
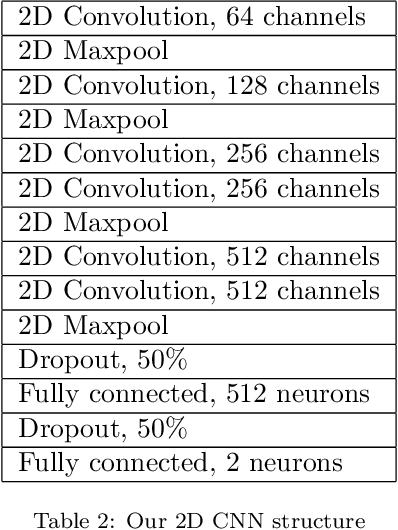

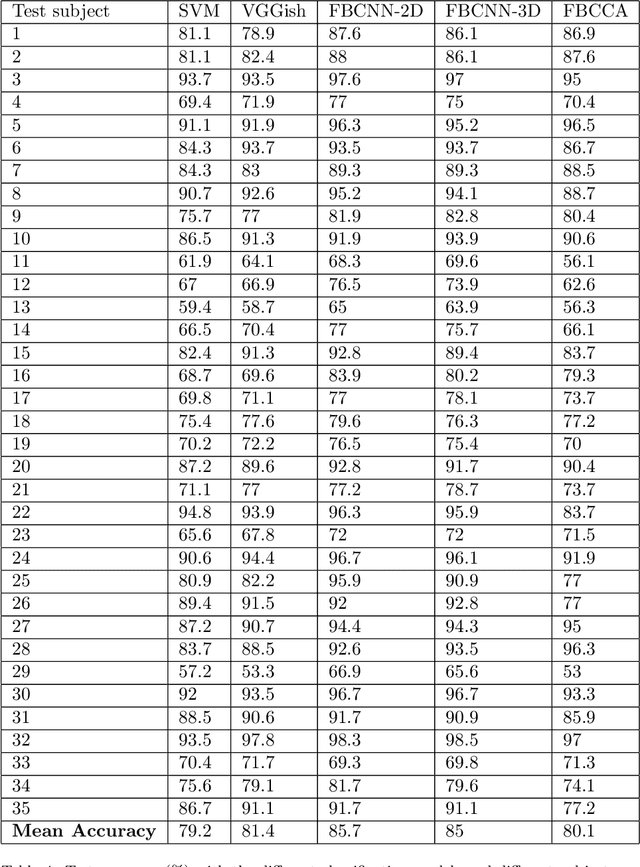
Objective: To propose a novel deep neural network (DNN) architecture -- the filter bank convolutional neural network (FBCNN) -- to improve SSVEP classification in single-channel BCIs with small data lengths. Methods: We propose two models: the FBCNN-2D and the FBCNN-3D. The FBCNN-2D utilizes a filter bank to create sub-band components of the electroencephalography (EEG) signal, which it transforms using the fast Fourier transform (FFT) and analyzes with a 2D CNN. The FBCNN-3D utilizes the same filter bank, but it transforms the sub-band components into spectrograms via short-time Fourier transform (STFT), and analyzes them with a 3D CNN. We made use of transfer learning. To train the FBCNN-3D, we proposed a new technique, called inter-dimensional transfer learning, to transfer knowledge from a 2D DNN to a 3D DNN. Our BCI was conceived so as not to require calibration from the final user: therefore, the test subject data was separated from training and validation. Results: The mean test accuracy was 85.7% for the FBCCA-2D and 85% for the FBCCA-3D. Mean F1-Scores were 0.858 and 0.853. Alternative classification methods, SVM, FBCCA and a CNN, had mean accuracy of 79.2%, 80.1% and 81.4%, respectively. Conclusion: The FBCNNs surpassed traditional SSVEP classification methods in our simulated BCI, by a considerable margin (about 5% higher accuracy). Transfer learning and inter-dimensional transfer learning made training much faster and more predictable. Significance: We proposed a new and flexible type of DNN, which had a better performance than standard methods in SSVEP classification for portable and fast BCIs.
Channel masking for multivariate time series shapelets
Nov 02, 2017
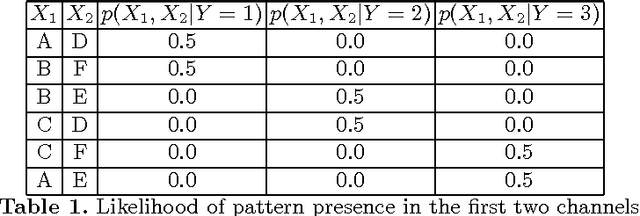
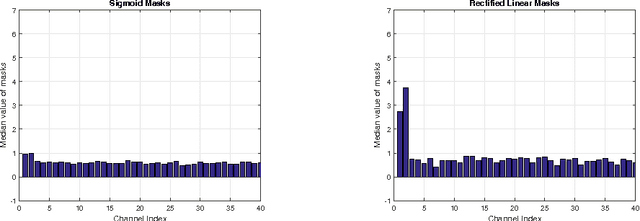
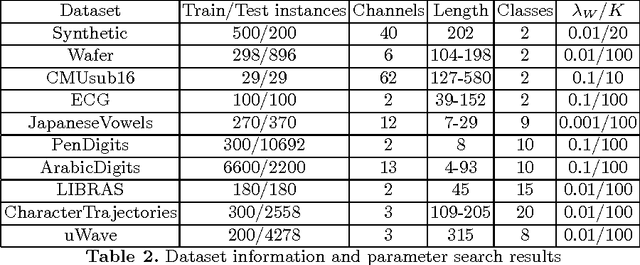
Time series shapelets are discriminative sub-sequences and their similarity to time series can be used for time series classification. Initial shapelet extraction algorithms searched shapelets by complete enumeration of all possible data sub-sequences. Research on shapelets for univariate time series proposed a mechanism called shapelet learning which parameterizes the shapelets and learns them jointly with a prediction model in an optimization procedure. Trivial extension of this method to multivariate time series does not yield very good results due to the presence of noisy channels which lead to overfitting. In this paper we propose a shapelet learning scheme for multivariate time series in which we introduce channel masks to discount noisy channels and serve as an implicit regularization.
Know Thyself: Transferable Visuomotor Control Through Robot-Awareness
Jul 28, 2021

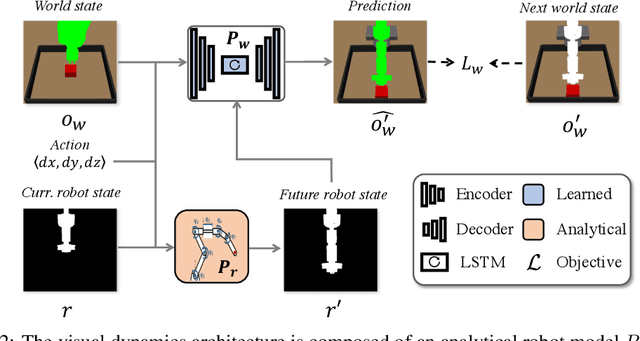
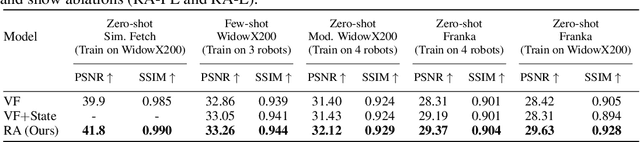
Training visuomotor robot controllers from scratch on a new robot typically requires generating large amounts of robot-specific data. Could we leverage data previously collected on another robot to reduce or even completely remove this need for robot-specific data? We propose a "robot-aware" solution paradigm that exploits readily available robot "self-knowledge" such as proprioception, kinematics, and camera calibration to achieve this. First, we learn modular dynamics models that pair a transferable, robot-agnostic world dynamics module with a robot-specific, analytical robot dynamics module. Next, we set up visual planning costs that draw a distinction between the robot self and the world. Our experiments on tabletop manipulation tasks in simulation and on real robots demonstrate that these plug-in improvements dramatically boost the transferability of visuomotor controllers, even permitting zero-shot transfer onto new robots for the very first time. Project website: https://hueds.github.io/rac/
Spatio-Temporal Graph Contrastive Learning
Aug 26, 2021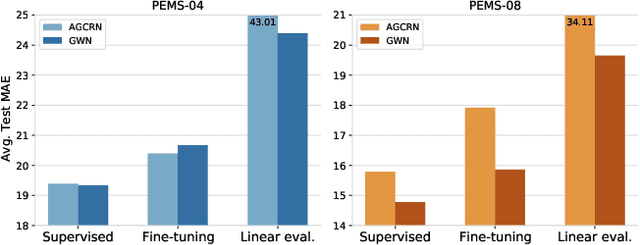
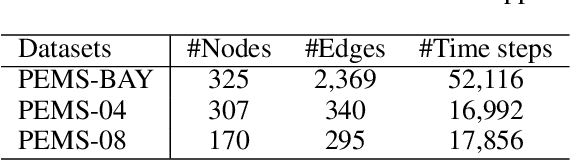
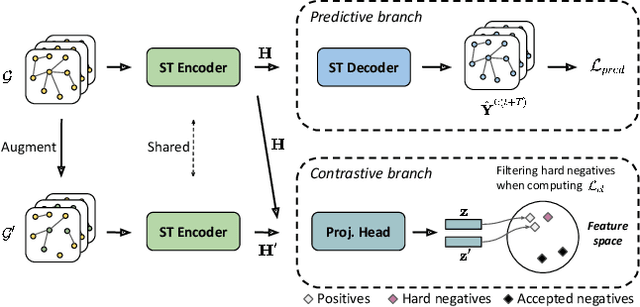
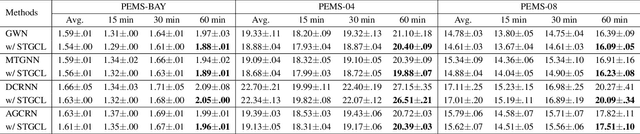
Deep learning models are modern tools for spatio-temporal graph (STG) forecasting. Despite their effectiveness, they require large-scale datasets to achieve better performance and are vulnerable to noise perturbation. To alleviate these limitations, an intuitive idea is to use the popular data augmentation and contrastive learning techniques. However, existing graph contrastive learning methods cannot be directly applied to STG forecasting due to three reasons. First, we empirically discover that the forecasting task is unable to benefit from the pretrained representations derived from contrastive learning. Second, data augmentations that are used for defeating noise are less explored for STG data. Third, the semantic similarity of samples has been overlooked. In this paper, we propose a Spatio-Temporal Graph Contrastive Learning framework (STGCL) to tackle these issues. Specifically, we improve the performance by integrating the forecasting loss with an auxiliary contrastive loss rather than using a pretrained paradigm. We elaborate on four types of data augmentations, which disturb data in terms of graph structure, time domain, and frequency domain. We also extend the classic contrastive loss through a rule-based strategy that filters out the most semantically similar negatives. Our framework is evaluated across three real-world datasets and four state-of-the-art models. The consistent improvements demonstrate that STGCL can be used as an off-the-shelf plug-in for existing deep models.