 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Detecting Drill Failure in the Small Short-sound Drill Dataset
Aug 25, 2021
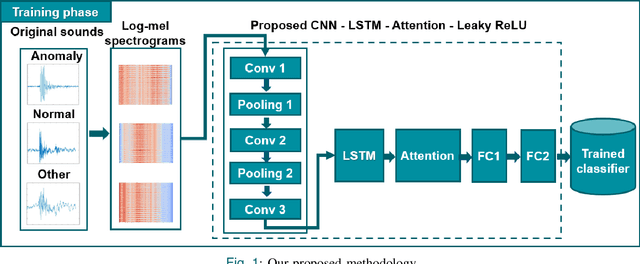
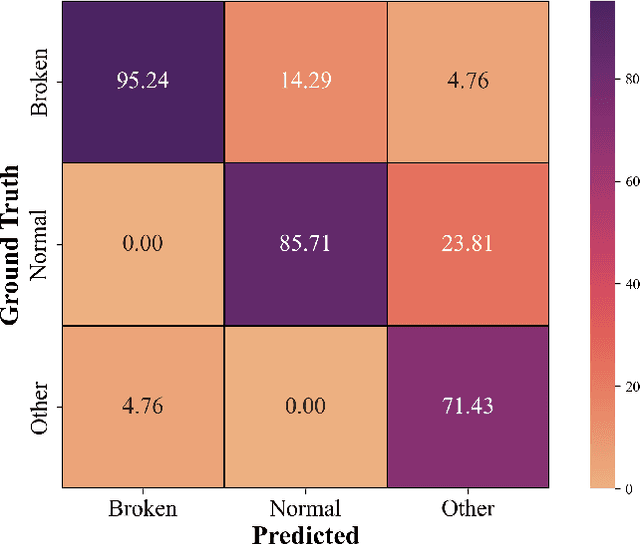

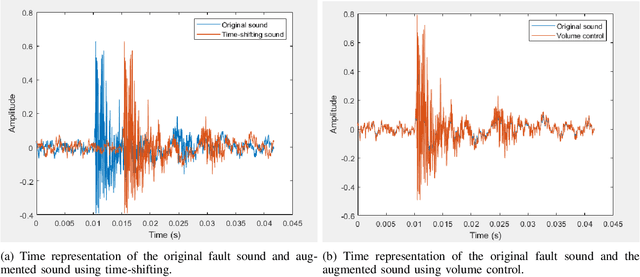
Monitoring the conditions of machines is vital in the manufacturing industry. Early detection of faulty components in machines for stopping and repairing the failed components can minimize the downtime of the machine. This article presents an approach to detect the failure occurring in drill machines based on drill sounds from Valmet AB. The drill dataset includes three classes: anomalous sounds, normal sounds, and irrelevant sounds, which are also labeled as ``Broken", ``Normal", and ``Other", respectively. Detecting drill failure effectively remains a challenge due to the following reasons. The waveform of drill sound is complex and short for detection. Additionally, in realistic soundscapes, there are sounds and noise in the context at the same time. Moreover, the balanced dataset is small to apply state-of-the-art deep learning techniques. To overcome these aforementioned difficulties, we augmented sounds to increase the number of sounds in the dataset. We then proposed a convolutional neural network (CNN) combined with a long short-term memory (LSTM) to extract features from log-Mel spectrograms and learn global high-level feature representation for the classification of three classes. A leaky rectified linear unit (Leaky ReLU) was utilized as the activation function for our proposed CNN instead of the rectified linear unit (ReLU). Moreover, we deployed an attention mechanism at the frame level after the LSTM layer to learn long-term global feature representations. As a result, the proposed method reached an overall accuracy of 92.35% for the drill failure detection system.
Joint Optimization in Edge-Cloud Continuum for Federated Unsupervised Person Re-identification
Aug 14, 2021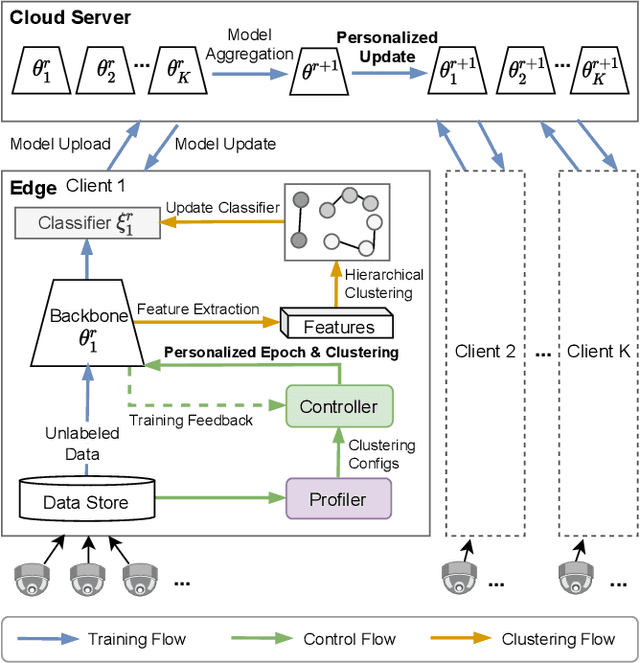
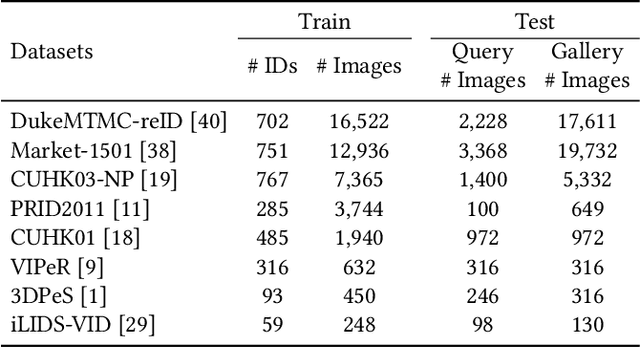
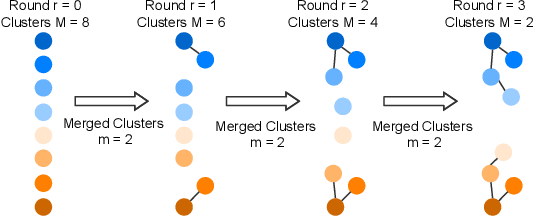
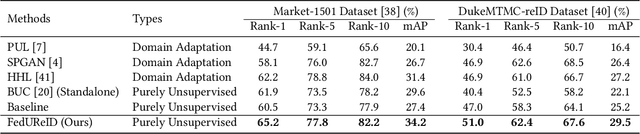
Person re-identification (ReID) aims to re-identify a person from non-overlapping camera views. Since person ReID data contains sensitive personal information, researchers have adopted federated learning, an emerging distributed training method, to mitigate the privacy leakage risks. However, existing studies rely on data labels that are laborious and time-consuming to obtain. We present FedUReID, a federated unsupervised person ReID system to learn person ReID models without any labels while preserving privacy. FedUReID enables in-situ model training on edges with unlabeled data. A cloud server aggregates models from edges instead of centralizing raw data to preserve data privacy. Moreover, to tackle the problem that edges vary in data volumes and distributions, we personalize training in edges with joint optimization of cloud and edge. Specifically, we propose personalized epoch to reassign computation throughout training, personalized clustering to iteratively predict suitable labels for unlabeled data, and personalized update to adapt the server aggregated model to each edge. Extensive experiments on eight person ReID datasets demonstrate that FedUReID not only achieves higher accuracy but also reduces computation cost by 29%. Our FedUReID system with the joint optimization will shed light on implementing federated learning to more multimedia tasks without data labels.
DQN Control Solution for KDD Cup 2021 City Brain Challenge
Aug 14, 2021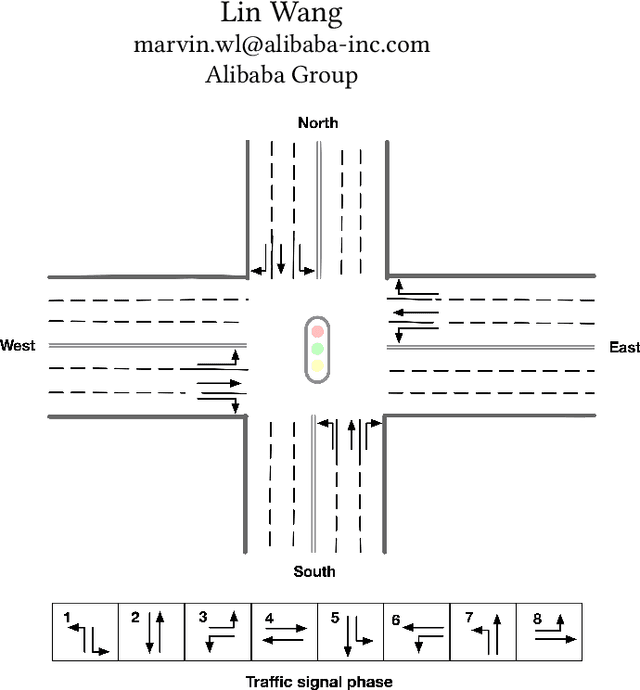

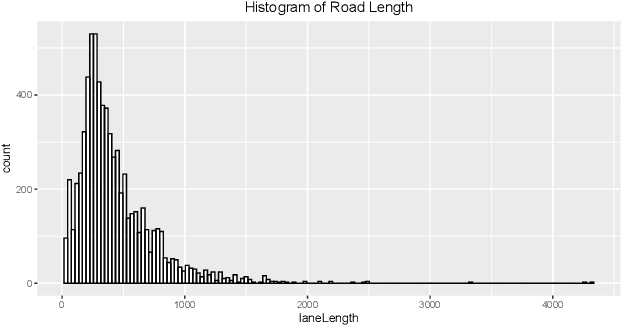
We took part in the city brain challenge competition and achieved the 8th place. In this competition, the players are provided with a real-world city-scale road network and its traffic demand derived from real traffic data. The players are asked to coordinate the traffic signals with a self-designed agent to maximize the number of vehicles served while maintaining an acceptable delay. In this abstract paper, we present an overall analysis and our detailed solution to this competition. Our approach is mainly based on the adaptation of the deep Q-network (DQN) for real-time traffic signal control. From our perspective, the major challenge of this competition is how to extend the classical DQN framework to traffic signals control in real-world complex road network and traffic flow situation. After trying and implementing several classical reward functions, we finally chose to apply our newly-designed reward in our agent. By applying our newly-proposed reward function and carefully tuning the control scheme, an agent based on a single DQN model can rank among the top 15 teams. We hope this paper could serve, to some extent, as a baseline solution to traffic signal control of real-world road network and inspire further attempts and researches.
Approximating Pandora's Box with Correlations
Aug 30, 2021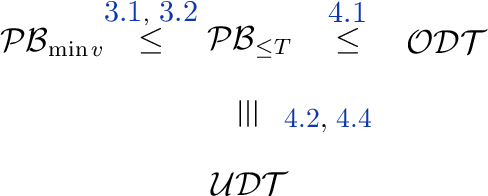
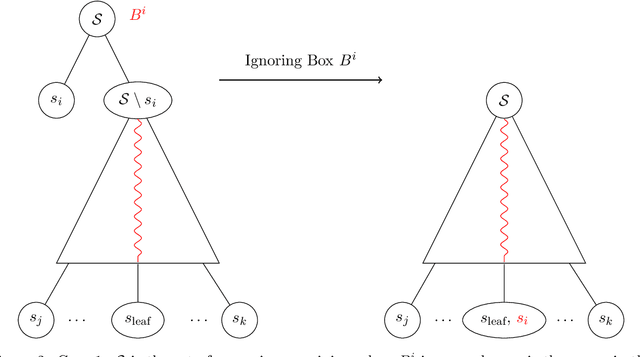
The Pandora's Box problem asks to find a search strategy over $n$ alternatives given stochastic information about their values, aiming to minimize the sum of the search cost and the value of the chosen alternative. Even though the case of independently distributed values is well understood, our algorithmic understanding of the problem is very limited once the independence assumption is dropped. Our work aims to characterize the complexity of approximating the Pandora's Box problem under correlated value distributions. To that end, we present a general reduction to a simpler version of Pandora's Box, that only asks to find a value below a certain threshold, and eliminates the need to reason about future values that will arise during the search. Using this general tool, we study two cases of correlation; the case of explicitly given distributions of support $m$ and the case of mixtures of $m$ product distributions. $\bullet$ In the first case, we connect Pandora's Box to the well studied problem of Optimal Decision Tree, obtaining an $O(\log m)$ approximation but also showing that the problem is strictly easier as it is equivalent (up to constant factors) to the Uniform Decision Tree problem. $\bullet$ In the case of mixtures of product distributions, the problem is again related to the noisy variant of Optimal Decision Tree which is significantly more challenging. We give a constant-factor approximation that runs in time $n^{ \tilde O( m^2/\varepsilon^2 ) }$ for $m$ mixture components whose marginals on every alternative are either identical or separated in TV distance by $\varepsilon$.
Covariance-Free Sparse Bayesian Learning
May 21, 2021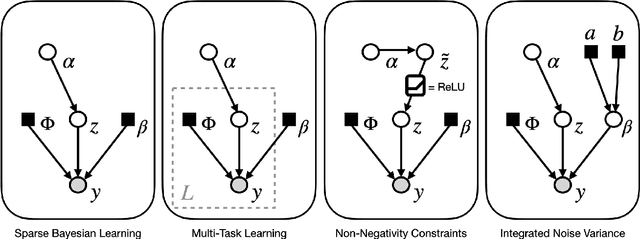
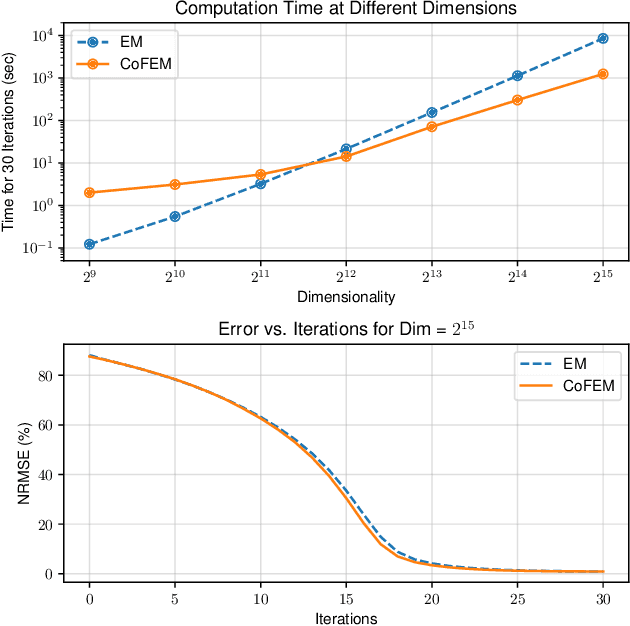
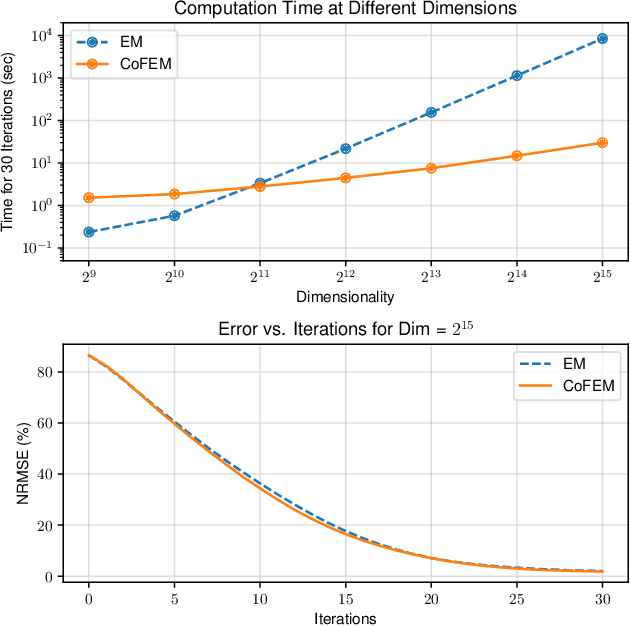
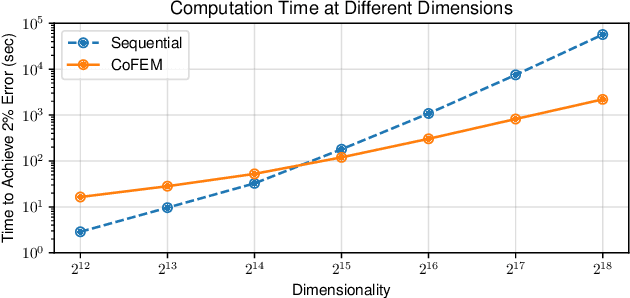
Sparse Bayesian learning (SBL) is a powerful framework for tackling the sparse coding problem while also providing uncertainty quantification. However, the most popular inference algorithms for SBL become too expensive for high-dimensional problems due to the need to maintain a large covariance matrix. To resolve this issue, we introduce a new SBL inference algorithm that avoids explicit computation of the covariance matrix, thereby saving significant time and space. Instead of performing costly matrix inversions, our covariance-free method solves multiple linear systems to obtain provably unbiased estimates of the posterior statistics needed by SBL. These systems can be solved in parallel, enabling further acceleration of the algorithm via graphics processing units. In practice, our method can be up to thousands of times faster than existing baselines, reducing hours of computation time to seconds. We showcase how our new algorithm enables SBL to tractably tackle high-dimensional signal recovery problems, such as deconvolution of calcium imaging data and multi-contrast reconstruction of magnetic resonance images. Finally, we open-source a toolbox containing all of our implementations to drive future research in SBL.
Certifiable Outlier-Robust Geometric Perception: Exact Semidefinite Relaxations and Scalable Global Optimization
Sep 07, 2021
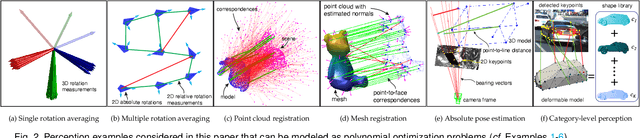

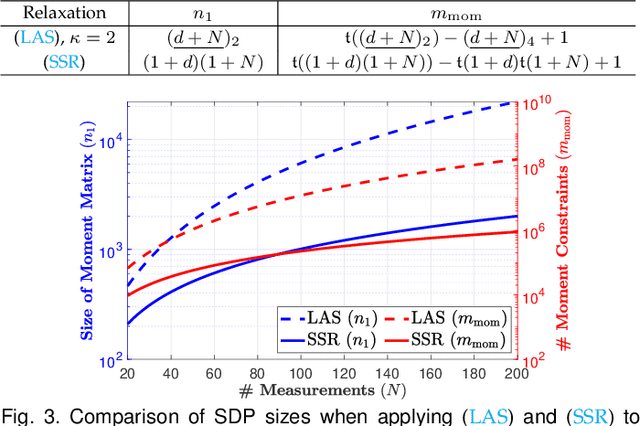
We propose the first general and scalable framework to design certifiable algorithms for robust geometric perception in the presence of outliers. Our first contribution is to show that estimation using common robust costs, such as truncated least squares (TLS), maximum consensus, Geman-McClure, Tukey's biweight, among others, can be reformulated as polynomial optimization problems (POPs). By focusing on the TLS cost, our second contribution is to exploit sparsity in the POP and propose a sparse semidefinite programming (SDP) relaxation that is much smaller than the standard Lasserre's hierarchy while preserving exactness, i.e., the SDP recovers the optimizer of the nonconvex POP with an optimality certificate. Our third contribution is to solve the SDP relaxations at an unprecedented scale and accuracy by presenting STRIDE, a solver that blends global descent on the convex SDP with fast local search on the nonconvex POP. Our fourth contribution is an evaluation of the proposed framework on six geometric perception problems including single and multiple rotation averaging, point cloud and mesh registration, absolute pose estimation, and category-level object pose and shape estimation. Our experiments demonstrate that (i) our sparse SDP relaxation is exact with up to 60%-90% outliers across applications; (ii) while still being far from real-time, STRIDE is up to 100 times faster than existing SDP solvers on medium-scale problems, and is the only solver that can solve large-scale SDPs with hundreds of thousands of constraints to high accuracy; (iii) STRIDE provides a safeguard to existing fast heuristics for robust estimation (e.g., RANSAC or Graduated Non-Convexity), i.e., it certifies global optimality if the heuristic estimates are optimal, or detects and allows escaping local optima when the heuristic estimates are suboptimal.
Continuous Herded Gibbs Sampling
Jun 11, 2021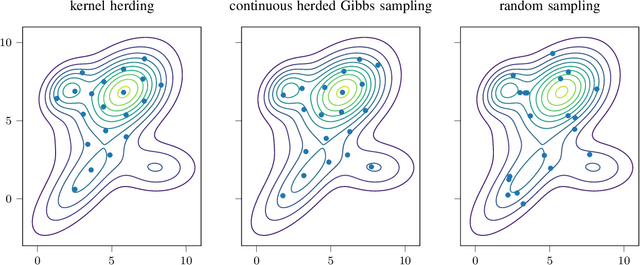
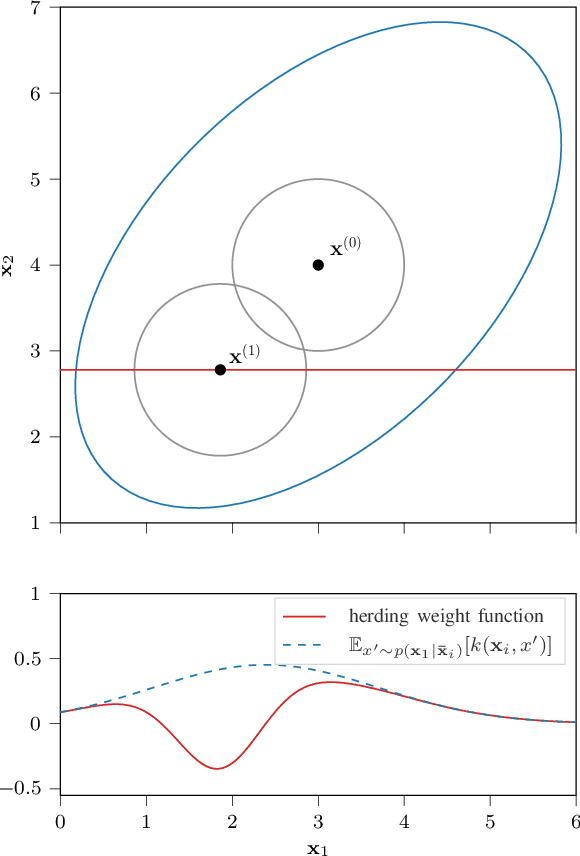
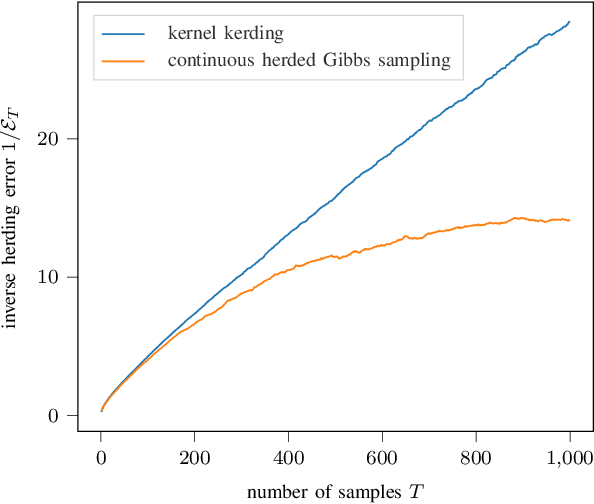
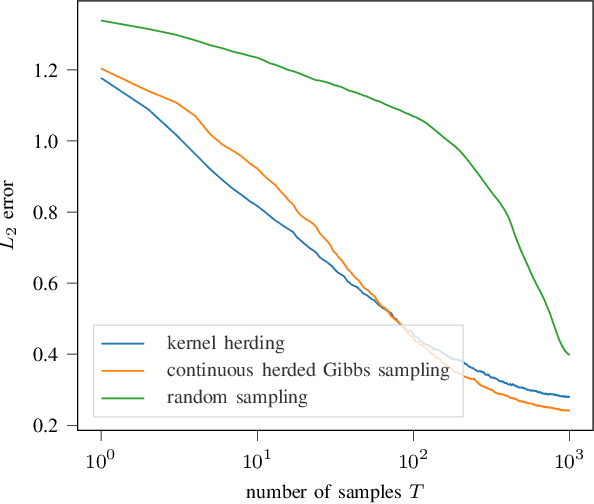
Herding is a technique to sequentially generate deterministic samples from a probability distribution. In this work, we propose a continuous herded Gibbs sampler, that combines kernel herding on continuous densities with Gibbs sampling. Our algorithm allows for deterministically sampling from high-dimensional multivariate probability densities, without directly sampling from the joint density. Experiments with Gaussian mixture densities indicate that the L2 error decreases similarly to kernel herding, while the computation time is significantly lower, i.e., linear in the number of dimensions.
Automated Pest Detection with DNN on the Edge for Precision Agriculture
Aug 01, 2021
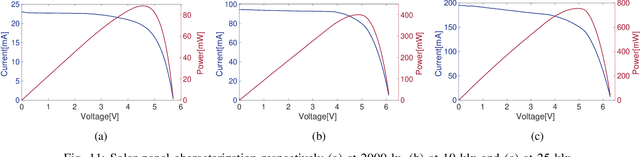
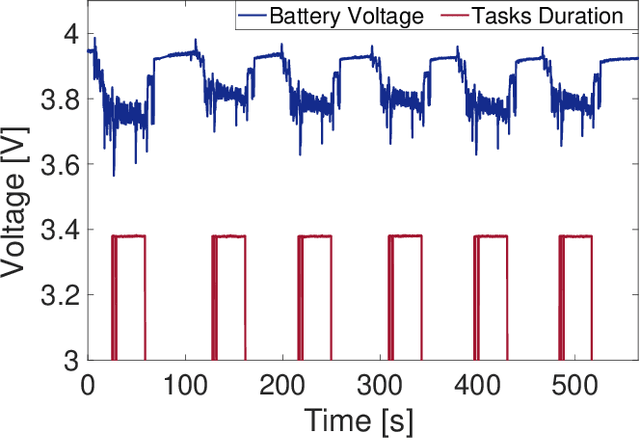
Artificial intelligence has smoothly penetrated several economic activities, especially monitoring and control applications, including the agriculture sector. However, research efforts toward low-power sensing devices with fully functional machine learning (ML) on-board are still fragmented and limited in smart farming. Biotic stress is one of the primary causes of crop yield reduction. With the development of deep learning in computer vision technology, autonomous detection of pest infestation through images has become an important research direction for timely crop disease diagnosis. This paper presents an embedded system enhanced with ML functionalities, ensuring continuous detection of pest infestation inside fruit orchards. The embedded solution is based on a low-power embedded sensing system along with a Neural Accelerator able to capture and process images inside common pheromone-based traps. Three different ML algorithms have been trained and deployed, highlighting the capabilities of the platform. Moreover, the proposed approach guarantees an extended battery life thanks to the integration of energy harvesting functionalities. Results show how it is possible to automate the task of pest infestation for unlimited time without the farmer's intervention.
Using Topological Framework for the Design of Activation Function and Model Pruning in Deep Neural Networks
Sep 03, 2021

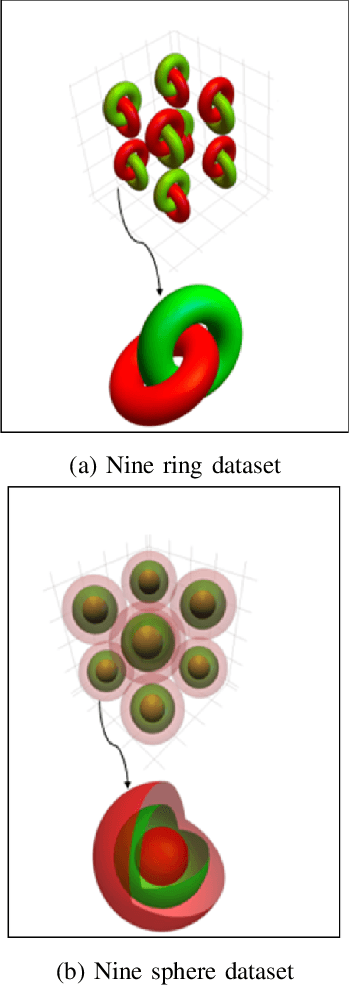
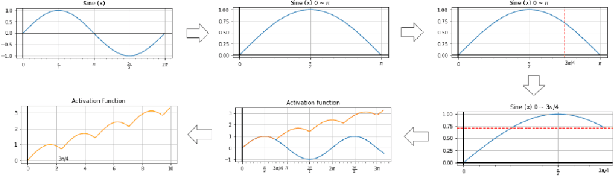
Success of deep neural networks in diverse tasks across domains of computer vision, speech recognition and natural language processing, has necessitated understanding the dynamics of training process and also working of trained models. Two independent contributions of this paper are 1) Novel activation function for faster training convergence 2) Systematic pruning of filters of models trained irrespective of activation function. We analyze the topological transformation of the space of training samples as it gets transformed by each successive layer during training, by changing the activation function. The impact of changing activation function on the convergence during training is reported for the task of binary classification. A novel activation function aimed at faster convergence for classification tasks is proposed. Here, Betti numbers are used to quantify topological complexity of data. Results of experiments on popular synthetic binary classification datasets with large Betti numbers(>150) using MLPs are reported. Results show that the proposed activation function results in faster convergence requiring fewer epochs by a factor of 1.5 to 2, since Betti numbers reduce faster across layers with the proposed activation function. The proposed methodology was verified on benchmark image datasets: fashion MNIST, CIFAR-10 and cat-vs-dog images, using CNNs. Based on empirical results, we propose a novel method for pruning a trained model. The trained model was pruned by eliminating filters that transform data to a topological space with large Betti numbers. All filters with Betti numbers greater than 300 were removed from each layer without significant reduction in accuracy. This resulted in faster prediction time and reduced memory size of the model.
Self-Supervised Multi-Frame Monocular Scene Flow
May 05, 2021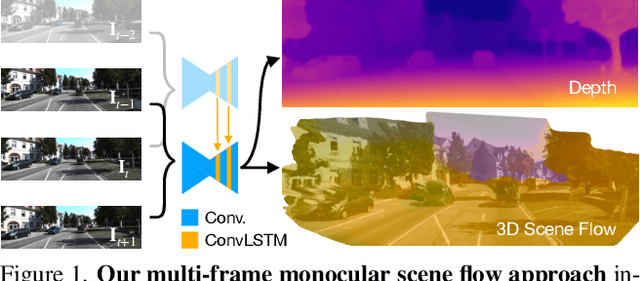

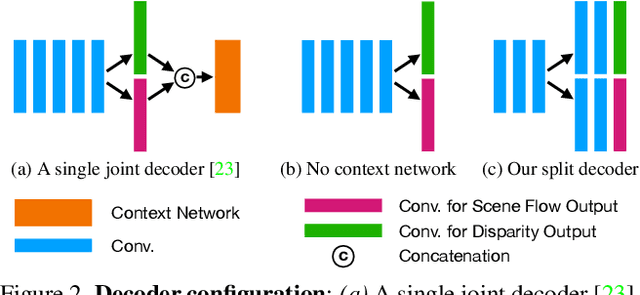
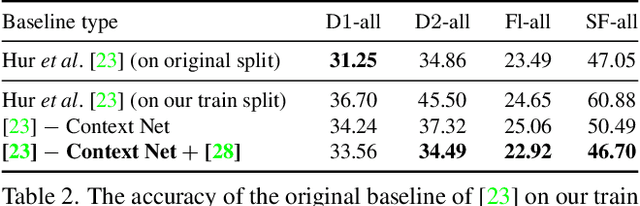
Estimating 3D scene flow from a sequence of monocular images has been gaining increased attention due to the simple, economical capture setup. Owing to the severe ill-posedness of the problem, the accuracy of current methods has been limited, especially that of efficient, real-time approaches. In this paper, we introduce a multi-frame monocular scene flow network based on self-supervised learning, improving the accuracy over previous networks while retaining real-time efficiency. Based on an advanced two-frame baseline with a split-decoder design, we propose (i) a multi-frame model using a triple frame input and convolutional LSTM connections, (ii) an occlusion-aware census loss for better accuracy, and (iii) a gradient detaching strategy to improve training stability. On the KITTI dataset, we observe state-of-the-art accuracy among monocular scene flow methods based on self-supervised learning.