 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
MILIOM: Tightly Coupled Multi-Input Lidar-Inertia Odometry and Mapping
Apr 24, 2021

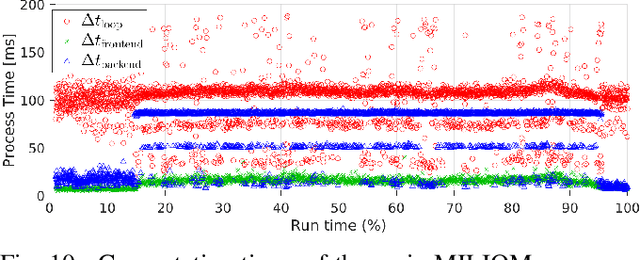
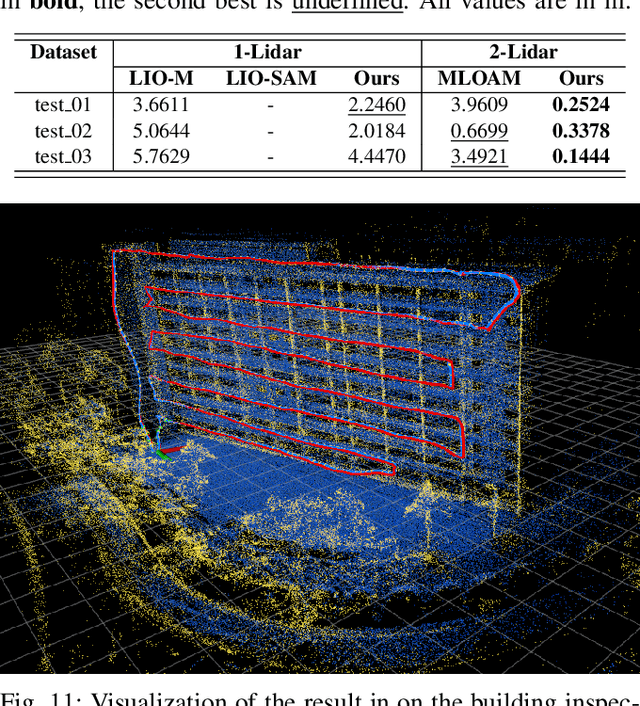
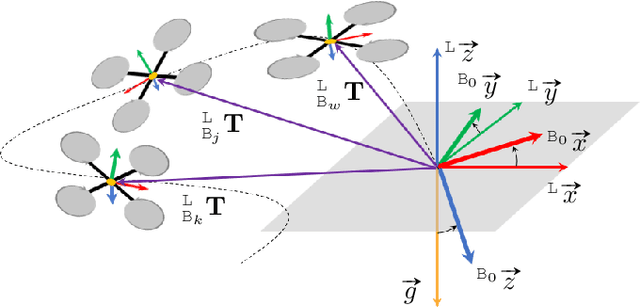
In this paper we investigate a tightly coupled Lidar-Inertia Odometry and Mapping (LIOM) scheme, with the capability to incorporate multiple lidars with complementary field of view (FOV). In essence, we devise a time-synchronized scheme to combine extracted features from separate lidars into a single pointcloud, which is then used to construct a local map and compute the feature-map matching (FMM) coefficients. These coefficients, along with the IMU preinteration observations, are then used to construct a factor graph that will be optimized to produce an estimate of the sliding window trajectory. We also propose a key frame-based map management strategy to marginalize certain poses and pointclouds in the sliding window to grow a global map, which is used to assemble the local map in the later stage. The use of multiple lidars with complementary FOV and the global map ensures that our estimate has low drift and can sustain good localization in situations where single lidar use gives poor result, or even fails to work. Multi-thread computation implementations are also adopted to fractionally cut down the computation time and ensure real-time performance. We demonstrate the efficacy of our system via a series of experiments on public datasets collected from an aerial vehicle.
An Efficient Training Approach for Very Large Scale Face Recognition
May 21, 2021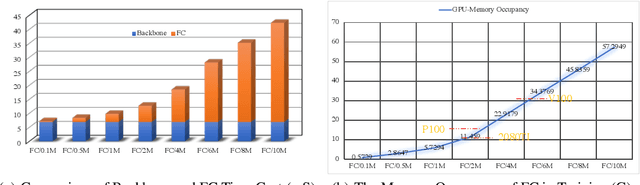
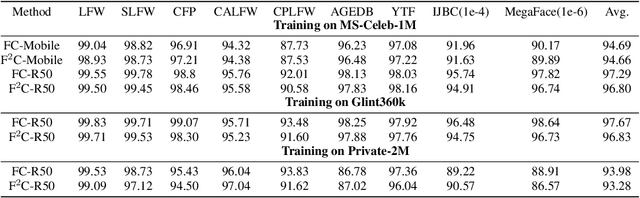
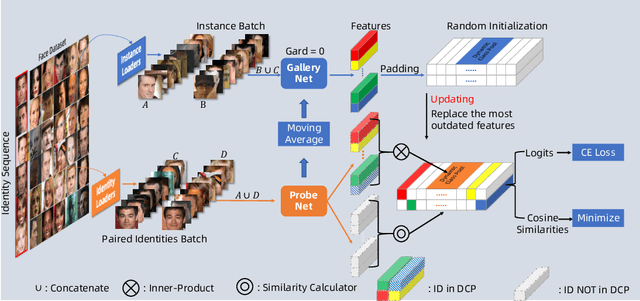
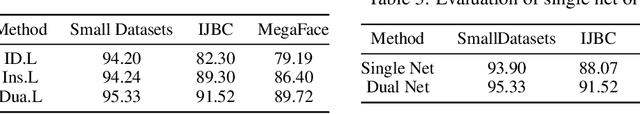
Face recognition has achieved significant progress in deep-learning era due to the ultra-large-scale and well-labeled datasets. However, training on ultra-large-scale datasets is time-consuming and takes up a lot of hardware resource. Therefore, how to design an appropriate training approach is very crucial and indispensable. The computational and hardware cost of training ultra-large-scale datasets mainly focuses on the Fully-Connected (FC) layer rather than convolutional layers. To this end, we propose a novel training approach for ultra-large-scale face datasets, termed Faster Face Classification (F$^2$C). In F$^2$C, we first define a Gallery Net and a Probe Net that are used to generate identities' centers and extract faces' features for face recognition, respectively. Gallery Net has the same structure as Probe Net and inherits the parameters from Probe Net with a moving average paradigm. After that, to reduce the training time and hardware resource occupancy of the FC layer, we propose the Dynamic Class Pool that stores the features from Gallery Net and calculates the inner product (logits) with positive samples (its identities appear in Dynamic Class Pool) in each mini-batch. Dynamic Class Pool can be regarded as a substitute for the FC layer and its size is much smaller than FC, which is the reason why Dynamic Class Pool can largely reduce the time and resource cost. For negative samples (its identities are not appear in the Dynamic Class Pool), we minimize the cosine similarities between negative samples and Dynamic Class Pool. Then, to improve the update efficiency and speed of Dynamic Class Pool's parameters, we design the Dual Loaders including Identity-based and Instance-based Loaders. Dual Loaders load images from given dataset by instances and identities to generate batches for training.
From Navigation to Racing: Reward Signal Design for Autonomous Racing
Mar 18, 2021
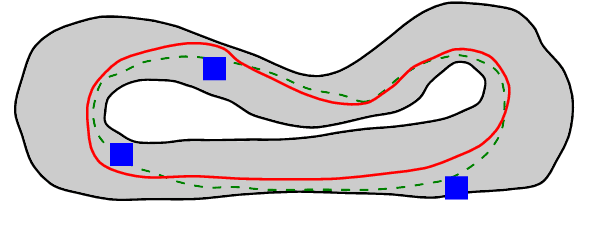
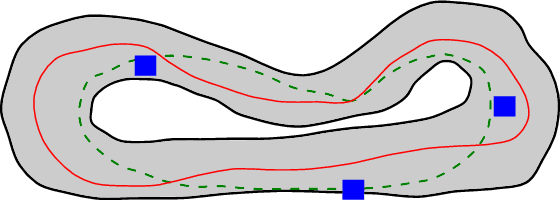
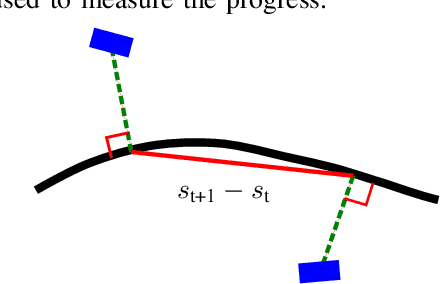
The problem of autonomous navigation is to generate a set of navigation references which when followed move the vehicle from a starting position to and end goal location while avoiding obstacles. Autonomous racing complicates the navigation problem by adding the objective of minimising the time to complete a track. Solutions aiming for a minimum time solution require that the planner is concerned with the optimality of the trajectory according to the vehicle dynamics. Neural networks, trained from experience with reinforcement learning, have shown to be effective local planners which generate navigation references to follow a global plan and avoid obstacles. We address the problem designing a reward signal which can be used to train neural network-based local planners to race in a time-efficient manner and avoid obstacles. The general challenge of reward signal design is to represent a desired behavior in an equation that can be calculated at each time step. The specific challenge of designing a reward signal for autonomous racing is to encode obstacle-free, time optimal racing trajectories in a clear signal We propose several methods of encoding ideal racing behavior based using a combination of the position and velocity of the vehicle and the actions taken by the network. The reward function candidates are expressed as equations and evaluated in the context of F1/10th autonomous racing. The results show that the best reward signal rewards velocity along, and punishes the lateral deviation from a precalculated, optimal reference trajectory.
Layer Flexible Adaptive Computational Time for Recurrent Neural Networks
Dec 14, 2018
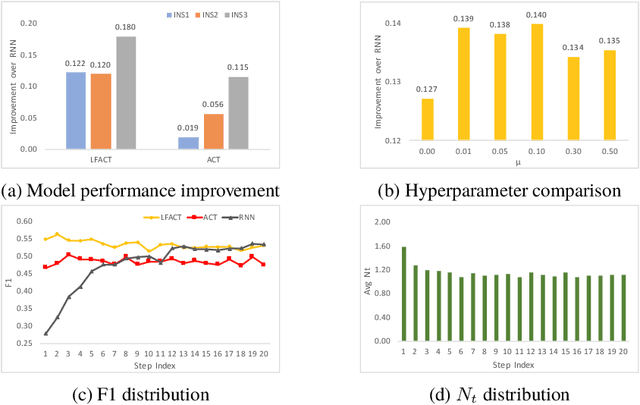
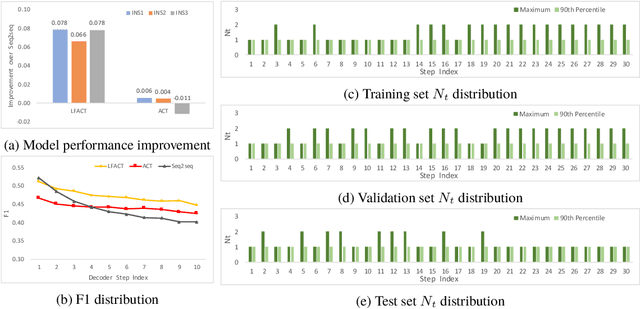
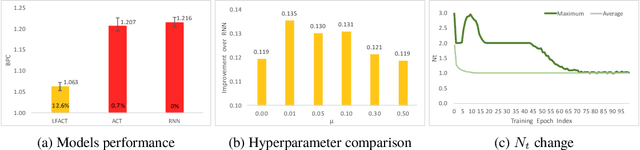
Deep recurrent neural networks perform well on sequence data and are the model of choice. It is a daunting task to decide the number of layers, especially considering different computational needs for tasks within a sequence of different difficulties. We propose a layer flexible recurrent neural network with adaptive computational time, and expand it to a sequence to sequence model. Contrary to the adaptive computational time model, our model has a dynamic number of transmission states which vary by step and sequence. We evaluate the model on a financial dataset. Experimental results show the performance improvement and indicate the model's ability to dynamically change the number of layers.
$β$-Annealed Variational Autoencoder for glitches
Jul 20, 2021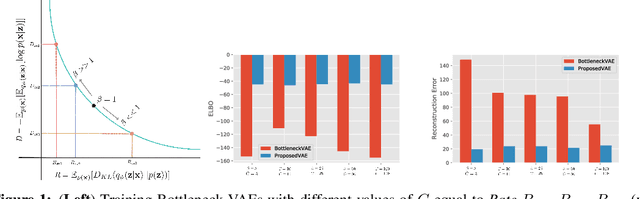
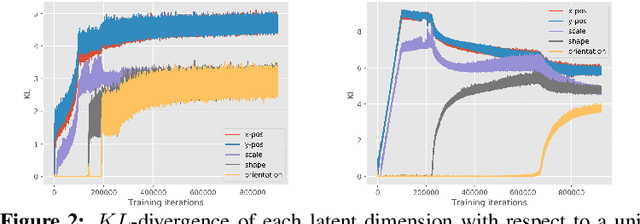
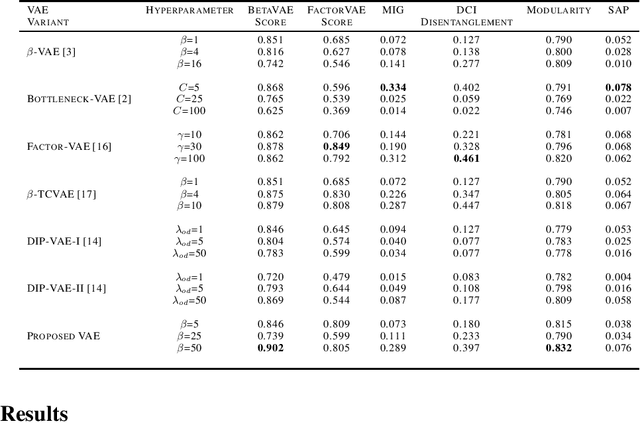
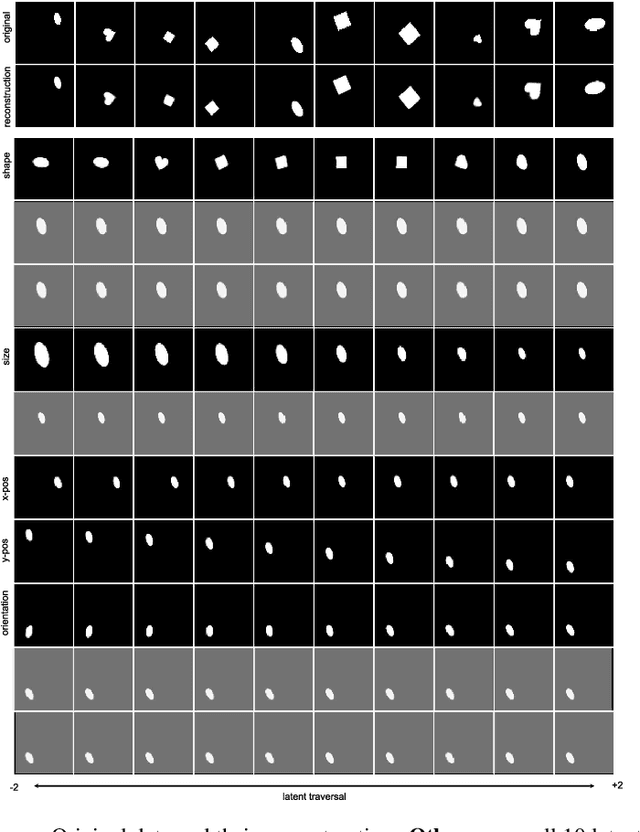
Gravitational wave detectors such as LIGO and Virgo are susceptible to various types of instrumental and environmental disturbances known as glitches which can mask and mimic gravitational waves. While there are 22 classes of non-Gaussian noise gradients currently identified, the number of classes is likely to increase as these detectors go through commissioning between observation runs. Since identification and labelling new noise gradients can be arduous and time-consuming, we propose $\beta$-Annelead VAEs to learn representations from spectograms in an unsupervised way. Using the same formulation as \cite{alemi2017fixing}, we view Bottleneck-VAEs~cite{burgess2018understanding} through the lens of information theory and connect them to $\beta$-VAEs~cite{higgins2017beta}. Motivated by this connection, we propose an annealing schedule for the hyperparameter $\beta$ in $\beta$-VAEs which has advantages of: 1) One fewer hyperparameter to tune, 2) Better reconstruction quality, while producing similar levels of disentanglement.
A Sensor Fusion-based GNSS Spoofing Attack Detection Framework for Autonomous Vehicles
Aug 19, 2021



This paper presents a sensor fusion based Global Navigation Satellite System (GNSS) spoofing attack detection framework for autonomous vehicles (AV) that consists of two concurrent strategies: (i) detection of vehicle state using predicted location shift -- i.e., distance traveled between two consecutive timestamps -- and monitoring of vehicle motion state -- i.e., standstill/ in motion; and (ii) detection and classification of turns (i.e., left or right). Data from multiple low-cost in-vehicle sensors (i.e., accelerometer, steering angle sensor, speed sensor, and GNSS) are fused and fed into a recurrent neural network model, which is a long short-term memory (LSTM) network for predicting the location shift, i.e., the distance that an AV travels between two consecutive timestamps. This location shift is then compared with the GNSS-based location shift to detect an attack. We have then combined k-Nearest Neighbors (k-NN) and Dynamic Time Warping (DTW) algorithms to detect and classify left and right turns using data from the steering angle sensor. To prove the efficacy of the sensor fusion-based attack detection framework, attack datasets are created for four unique and sophisticated spoofing attacks-turn-by-turn, overshoot, wrong turn, and stop, using the publicly available real-world Honda Research Institute Driving Dataset (HDD). Our analysis reveals that the sensor fusion-based detection framework successfully detects all four types of spoofing attacks within the required computational latency threshold.
Lessons on Parameter Sharing across Layers in Transformers
Apr 13, 2021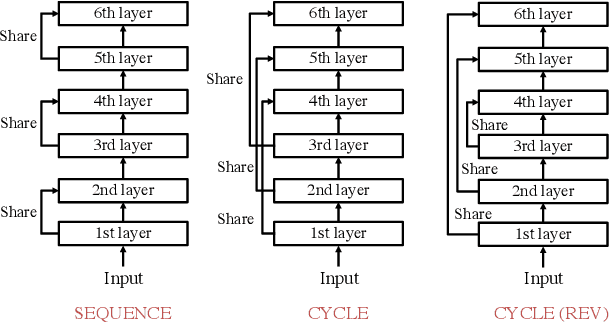
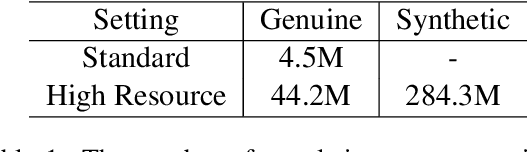

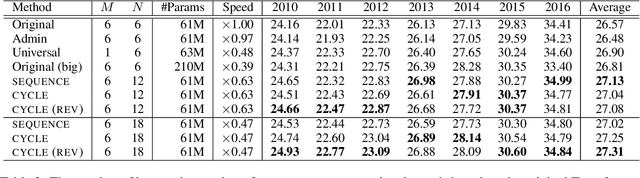
We propose a parameter sharing method for Transformers (Vaswani et al., 2017). The proposed approach relaxes a widely used technique, which shares parameters for one layer with all layers such as Universal Transformers (Dehghani et al., 2019), to increase the efficiency in the computational time. We propose three strategies: Sequence, Cycle, and Cycle (rev) to assign parameters to each layer. Experimental results show that the proposed strategies are efficient in the parameter size and computational time. Moreover, we indicate that the proposed strategies are also effective in the configuration where we use many training data such as the recent WMT competition.
FDDWNet: A Lightweight Convolutional Neural Network for Real-time Sementic Segmentation
Nov 02, 2019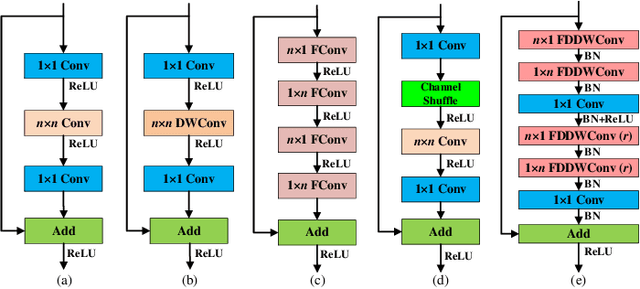
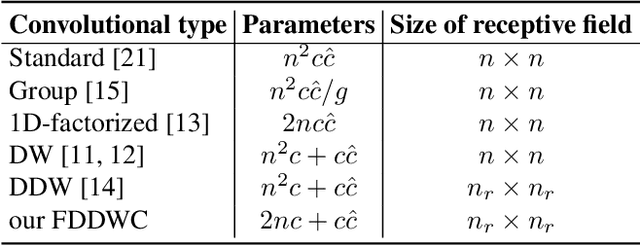
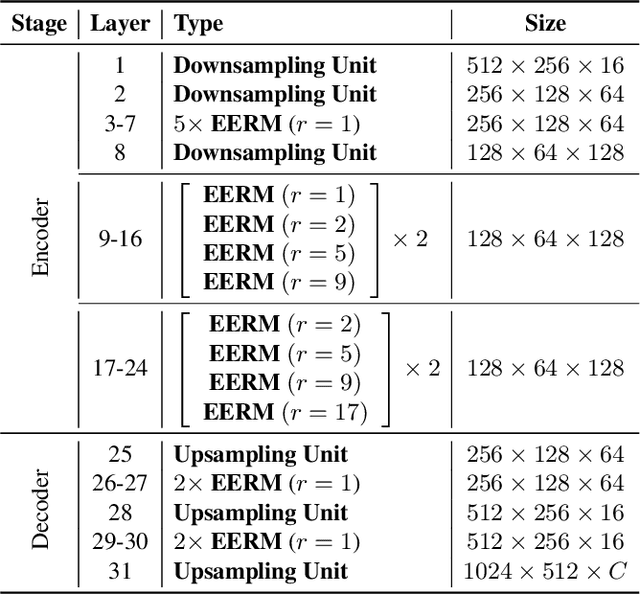

This paper introduces a lightweight convolutional neural network, called FDDWNet, for real-time accurate semantic segmentation. In contrast to recent advances of lightweight networks that prefer to utilize shallow structure, FDDWNet makes an effort to design more deeper network architecture, while maintains faster inference speed and higher segmentation accuracy. Our network uses factorized dilated depth-wise separable convolutions (FDDWC) to learn feature representations from different scale receptive fields with fewer model parameters. Additionally, FDDWNet has multiple branches of skipped connections to gather context cues from intermediate convolution layers. The experiments show that FDDWNet only has 0.8M model size, while achieves 60 FPS running speed on a single GTX 2080Ti GPU with a 1024x512 input image. The comprehensive experiments demonstrate that our model achieves state-of-the-art results in terms of available speed and accuracy trade-off on CityScapes and CamVid datasets.
Continuous Herded Gibbs Sampling
Jun 11, 2021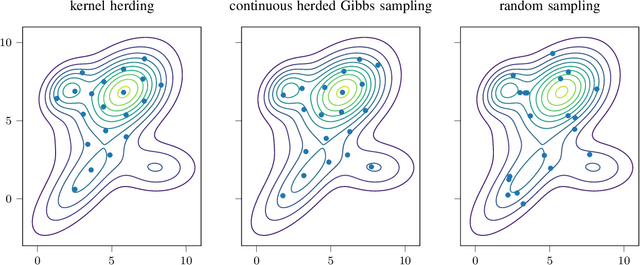
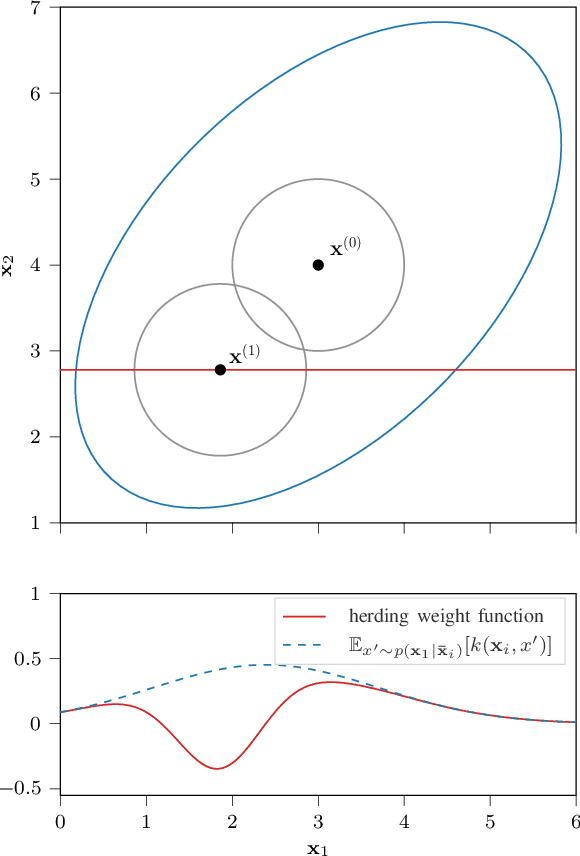
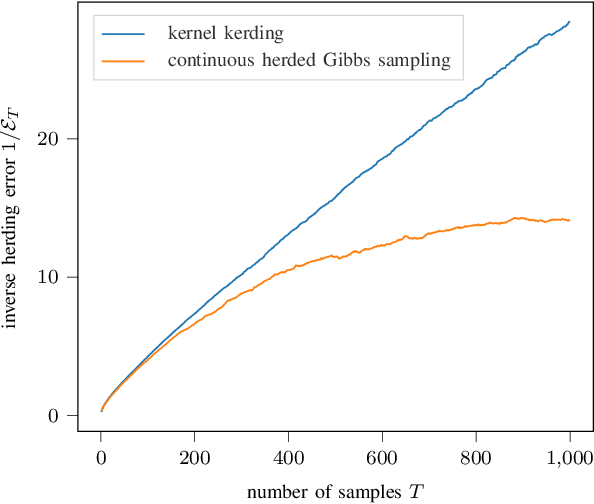
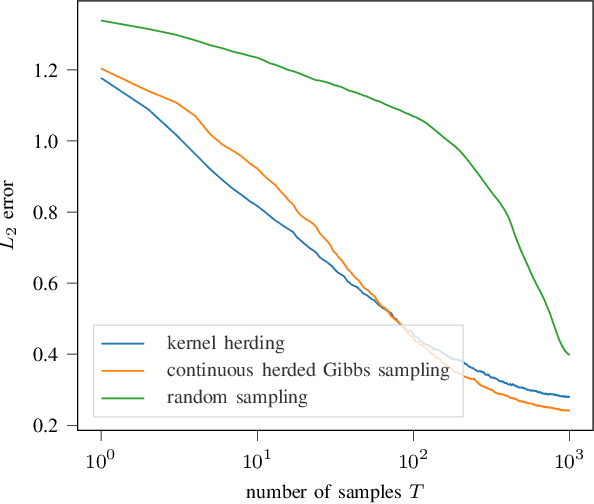
Herding is a technique to sequentially generate deterministic samples from a probability distribution. In this work, we propose a continuous herded Gibbs sampler, that combines kernel herding on continuous densities with Gibbs sampling. Our algorithm allows for deterministically sampling from high-dimensional multivariate probability densities, without directly sampling from the joint density. Experiments with Gaussian mixture densities indicate that the L2 error decreases similarly to kernel herding, while the computation time is significantly lower, i.e., linear in the number of dimensions.
Kimera: an Open-Source Library for Real-Time Metric-Semantic Localization and Mapping
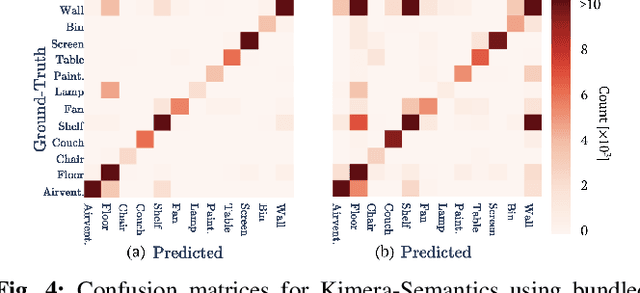
Oct 06, 2019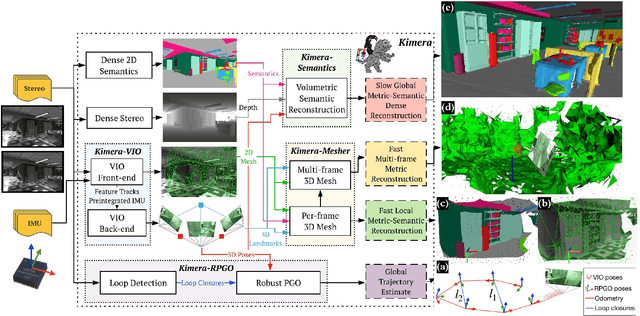

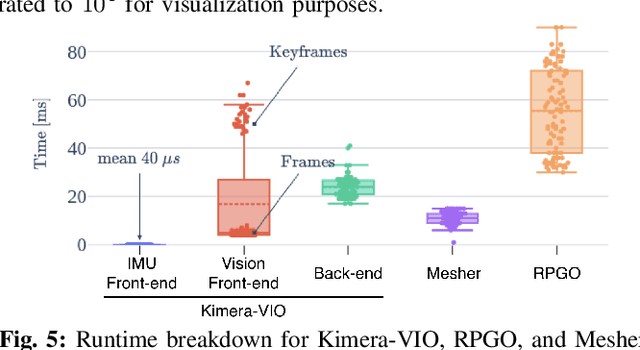
We provide an open-source C++ library for real-time metric-semantic visual-inertial Simultaneous Localization And Mapping (SLAM). The library goes beyond existing visual and visual-inertial SLAM libraries (e.g., ORB-SLAM, VINS- Mono, OKVIS, ROVIO) by enabling mesh reconstruction and semantic labeling in 3D. Kimera is designed with modularity in mind and has four key components: a visual-inertial odometry (VIO) module for fast and accurate state estimation, a robust pose graph optimizer for global trajectory estimation, a lightweight 3D mesher module for fast mesh reconstruction, and a dense 3D metric-semantic reconstruction module. The modules can be run in isolation or in combination, hence Kimera can easily fall back to a state-of-the-art VIO or a full SLAM system. Kimera runs in real-time on a CPU and produces a 3D metric-semantic mesh from semantically labeled images, which can be obtained by modern deep learning methods. We hope that the flexibility, computational efficiency, robustness, and accuracy afforded by Kimera will build a solid basis for future metric-semantic SLAM and perception research, and will allow researchers across multiple areas (e.g., VIO, SLAM, 3D reconstruction, segmentation) to benchmark and prototype their own efforts without having to start from scratch.