 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Benchmark of visual and 3D lidar SLAM systems in simulation environment for vineyards
Jul 12, 2021
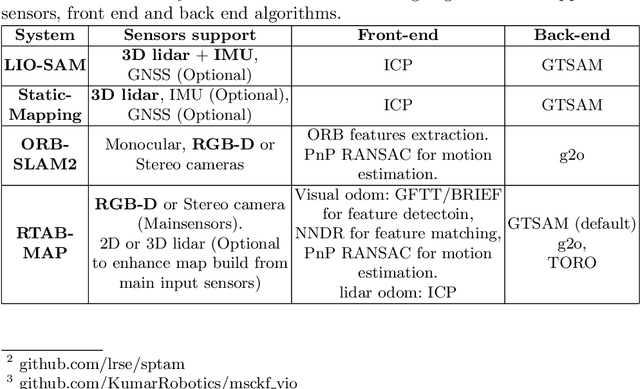


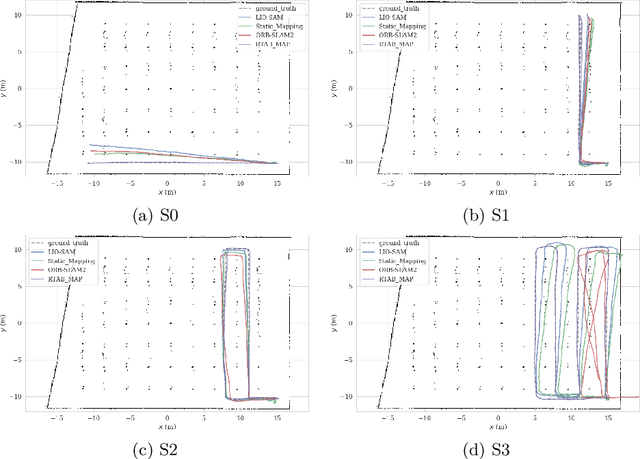
In this work, we present a comparative analysis of the trajectories estimated from various Simultaneous Localization and Mapping (SLAM) systems in a simulation environment for vineyards. Vineyard environment is challenging for SLAM methods, due to visual appearance changes over time, uneven terrain, and repeated visual patterns. For this reason, we created a simulation environment specifically for vineyards to help studying SLAM systems in such a challenging environment. We evaluated the following SLAM systems: LIO-SAM, StaticMapping, ORB-SLAM2, and RTAB-MAP in four different scenarios. The mobile robot used in this study equipped with 2D and 3D lidars, IMU, and RGB-D camera (Kinect v2). The results show good and encouraging performance of RTAB-MAP in such an environment.
Avalanche Photodetectors with Photon Trapping Structures for Biomedical Imaging Applications
Apr 27, 2021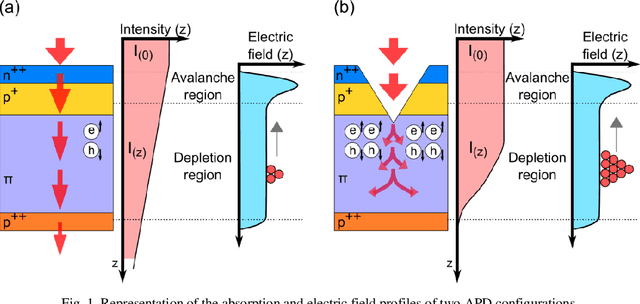
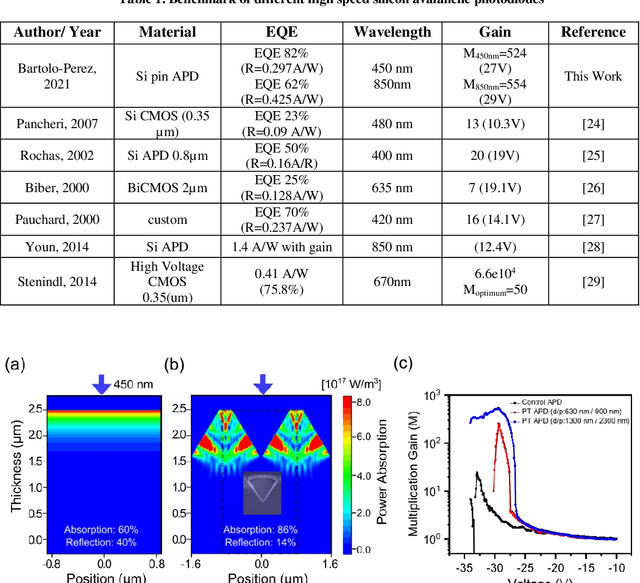
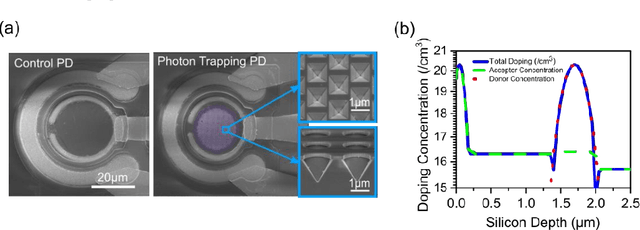
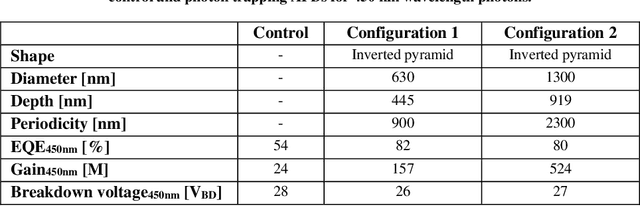
Enhancing photon detection efficiency and time resolution in photodetectors in the entire visible range is critical to improve the image quality of time-of-flight (TOF)-based imaging systems and fluorescence lifetime imaging (FLIM). In this work, we evaluate the gain, detection efficiency, and timing performance of avalanche photodiodes (APD) with photon trapping nanostructures for photons with 450 and 850 nm wavelengths. At 850 nm wavelength, our photon trapping avalanche photodiodes showed 30 times higher gain, an increase from 16% to >60% enhanced absorption efficiency, and a 50% reduction in the full width at half maximum (FWHM) pulse response time close to the breakdown voltage. At 450 nm wavelength, the external quantum efficiency increased from 54% to 82%, while the gain was enhanced more than 20-fold. Therefore, silicon APDs with photon trapping structures exhibited a dramatic increase in absorption compared to control devices. Results suggest very thin devices with fast timing properties and high absorption between the near-ultraviolet and the near infrared region can be manufactured for high-speed applications in biomedical imaging. This study paves the way towards obtaining single photon detectors with photon trapping structures with gains above 10^6 for the entire visible range
FOGA: Flag Optimization with Genetic Algorithm
May 15, 2021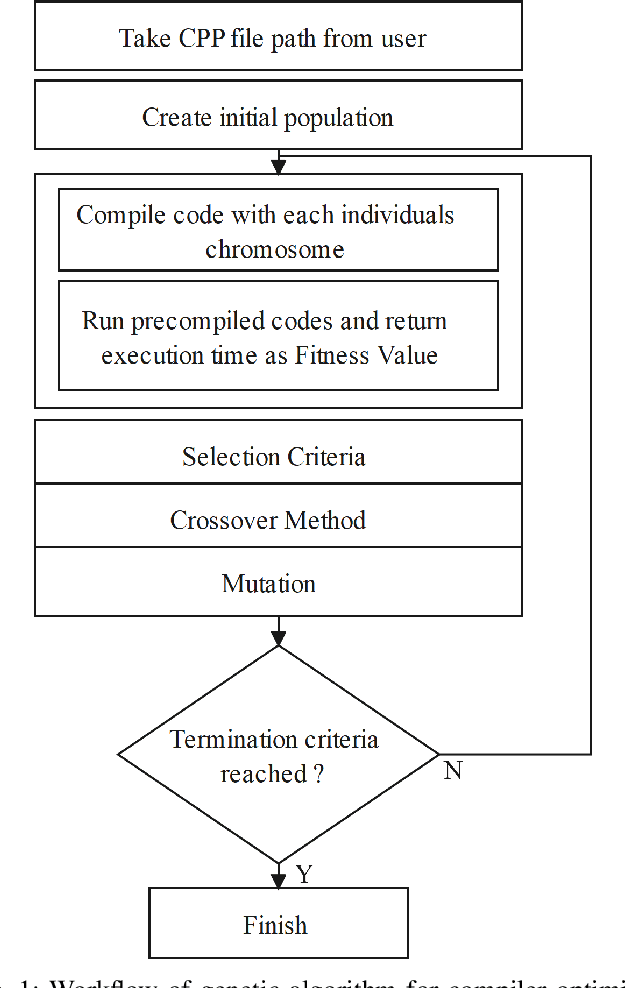
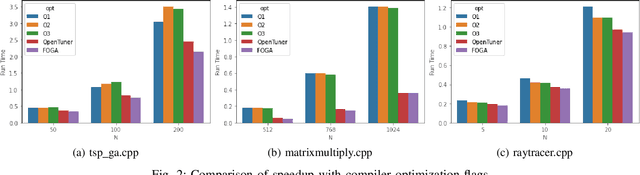
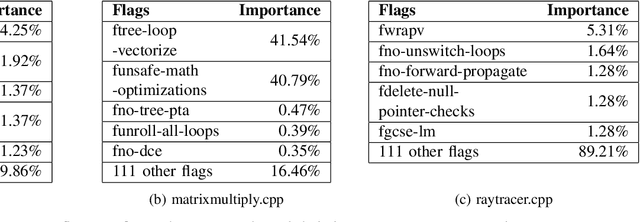
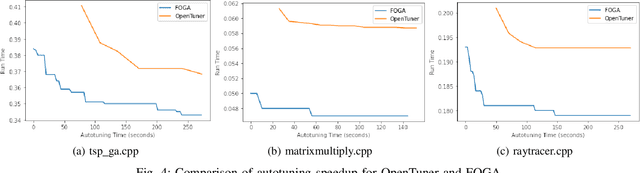
Recently, program autotuning has become very popular especially in embedded systems, when we have limited resources such as computing power and memory where these systems run generally time-critical applications. Compiler optimization space gradually expands with the renewed compiler options and inclusion of new architectures. These advancements bring autotuning even more important position. In this paper, we introduced Flag Optimization with Genetic Algorithm (FOGA) as an autotuning solution for GCC flag optimization. FOGA has two main advantages over the other autotuning approaches: the first one is the hyperparameter tuning of the genetic algorithm (GA), the second one is the maximum iteration parameter to stop when no further improvement occurs. We demonstrated remarkable speedup in the execution time of C++ source codes with the help of optimization flags provided by FOGA when compared to the state of the art framework OpenTuner.
UltraBot: Autonomous Mobile Robot for Indoor UV-C Disinfection with Non-trivial Shape of Disinfection Zone
Aug 22, 2021
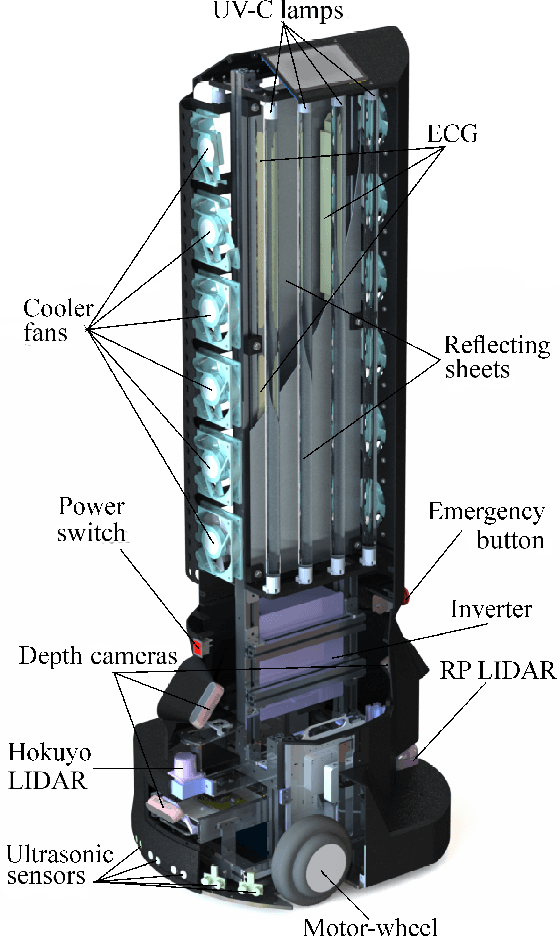
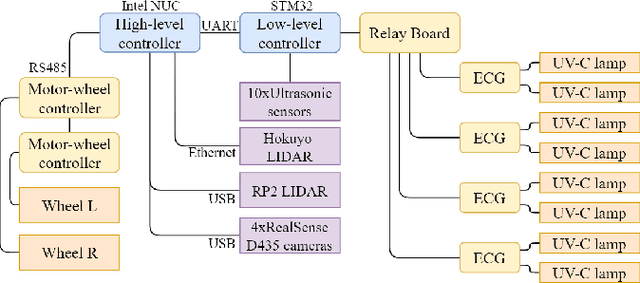
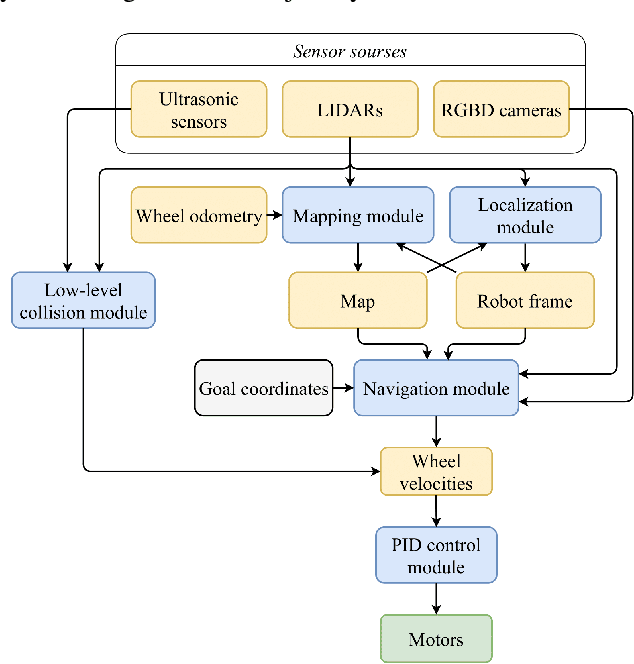
The paper focuses on the development of an autonomous disinfection robot UltraBot to reduce COVID-19 transmission along with other harmful bacteria and viruses. The motivation behind the research is to develop such a robot that is capable of performing disinfection tasks without the use of harmful sprays and chemicals that can leave residues and require airing the room afterward for a long time. UltraBot technology has the potential to offer the most optimal autonomous disinfection performance along with taking care of people, keeping them from getting under the UV-C radiation. The paper highlights UltraBot's mechanical and electrical design as well as disinfection performance. The conducted experiments demonstrate the effectiveness of robot disinfection ability and actual disinfection area per each side with UV-C lamp array. The disinfection effectiveness results show actual performance for the multi-pass technique that provides 1-log reduction with combined direct UV-C exposure and ozone-based air purification after two robot passes at a speed of 0.14 m/s. This technique has the same performance as ten minutes static disinfection. Finally, we have calculated the non-trivial form of the robot disinfection zone by two consecutive experiment to produce optimal path planning and to provide full disinfection in selected areas.
Batch Normalization Preconditioning for Neural Network Training
Aug 02, 2021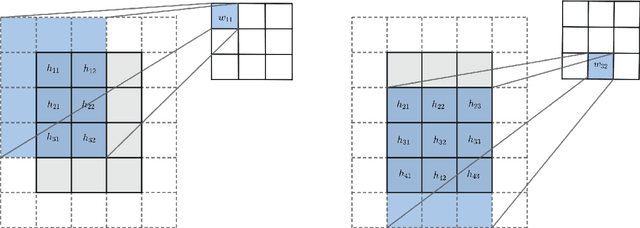
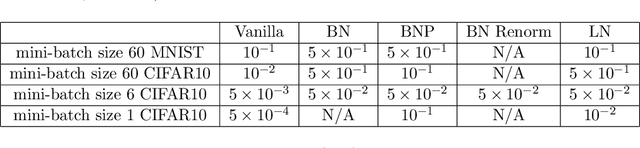
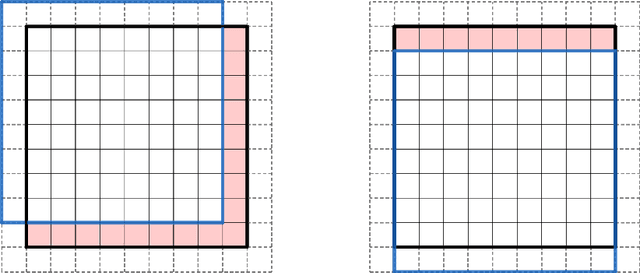

Batch normalization (BN) is a popular and ubiquitous method in deep learning that has been shown to decrease training time and improve generalization performance of neural networks. Despite its success, BN is not theoretically well understood. It is not suitable for use with very small mini-batch sizes or online learning. In this paper, we propose a new method called Batch Normalization Preconditioning (BNP). Instead of applying normalization explicitly through a batch normalization layer as is done in BN, BNP applies normalization by conditioning the parameter gradients directly during training. This is designed to improve the Hessian matrix of the loss function and hence convergence during training. One benefit is that BNP is not constrained on the mini-batch size and works in the online learning setting. Furthermore, its connection to BN provides theoretical insights on how BN improves training and how BN is applied to special architectures such as convolutional neural networks.
Improved Speech Emotion Recognition using Transfer Learning and Spectrogram Augmentation
Aug 16, 2021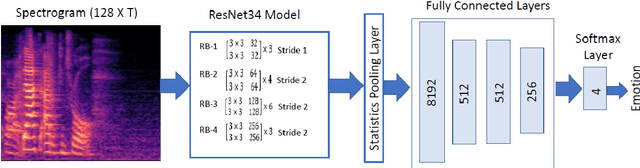
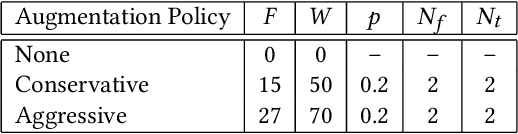
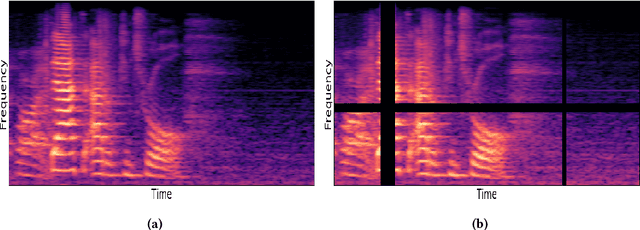
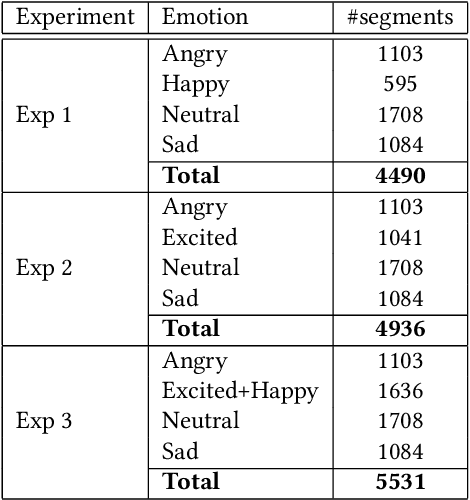
Automatic speech emotion recognition (SER) is a challenging task that plays a crucial role in natural human-computer interaction. One of the main challenges in SER is data scarcity, i.e., insufficient amounts of carefully labeled data to build and fully explore complex deep learning models for emotion classification. This paper aims to address this challenge using a transfer learning strategy combined with spectrogram augmentation. Specifically, we propose a transfer learning approach that leverages a pre-trained residual network (ResNet) model including a statistics pooling layer from speaker recognition trained using large amounts of speaker-labeled data. The statistics pooling layer enables the model to efficiently process variable-length input, thereby eliminating the need for sequence truncation which is commonly used in SER systems. In addition, we adopt a spectrogram augmentation technique to generate additional training data samples by applying random time-frequency masks to log-mel spectrograms to mitigate overfitting and improve the generalization of emotion recognition models. We evaluate the effectiveness of our proposed approach on the interactive emotional dyadic motion capture (IEMOCAP) dataset. Experimental results indicate that the transfer learning and spectrogram augmentation approaches improve the SER performance, and when combined achieve state-of-the-art results.
Fog Simulation on Real LiDAR Point Clouds for 3D Object Detection in Adverse Weather
Aug 16, 2021
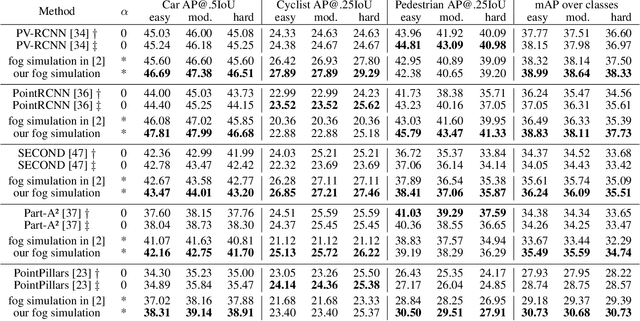

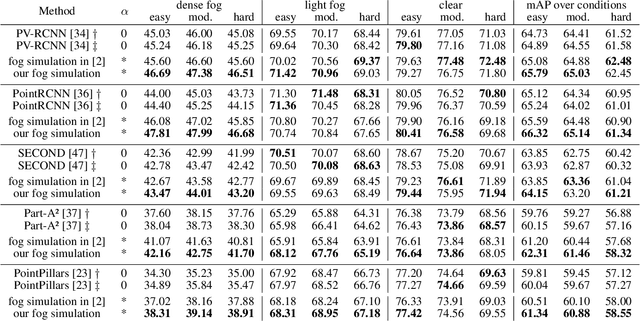
This work addresses the challenging task of LiDAR-based 3D object detection in foggy weather. Collecting and annotating data in such a scenario is very time, labor and cost intensive. In this paper, we tackle this problem by simulating physically accurate fog into clear-weather scenes, so that the abundant existing real datasets captured in clear weather can be repurposed for our task. Our contributions are twofold: 1) We develop a physically valid fog simulation method that is applicable to any LiDAR dataset. This unleashes the acquisition of large-scale foggy training data at no extra cost. These partially synthetic data can be used to improve the robustness of several perception methods, such as 3D object detection and tracking or simultaneous localization and mapping, on real foggy data. 2) Through extensive experiments with several state-of-the-art detection approaches, we show that our fog simulation can be leveraged to significantly improve the performance for 3D object detection in the presence of fog. Thus, we are the first to provide strong 3D object detection baselines on the Seeing Through Fog dataset. Our code is available at www.trace.ethz.ch/lidar_fog_simulation.
Deep Learning Radio Frequency Signal Classification with Hybrid Images
May 19, 2021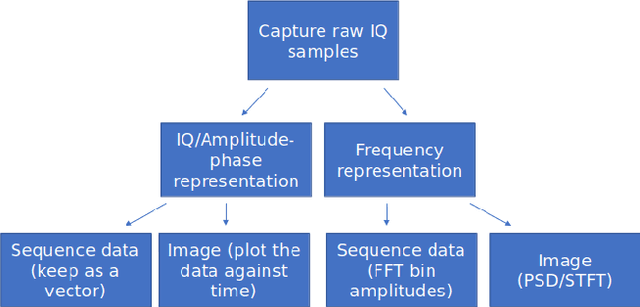
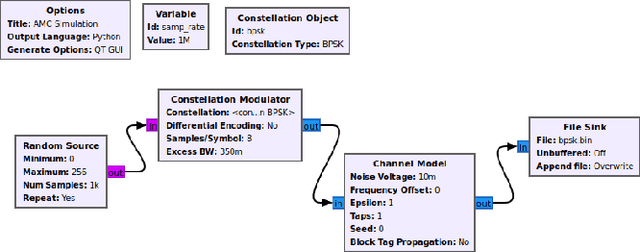
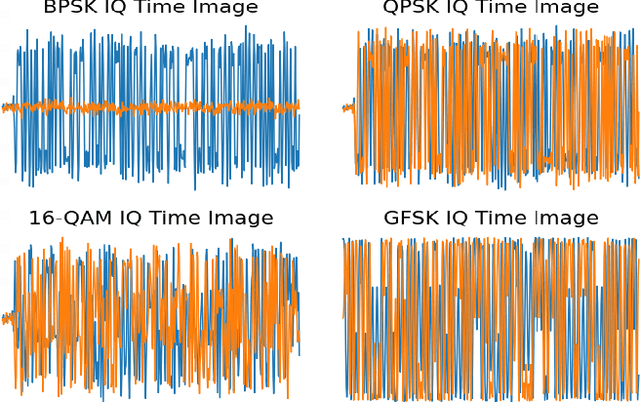
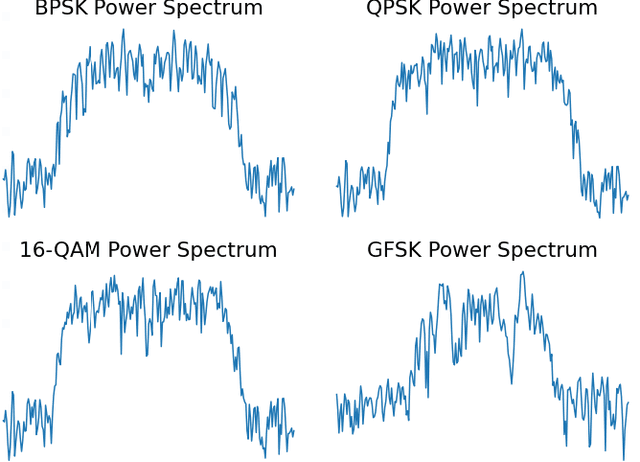
In recent years, Deep Learning (DL) has been successfully applied to detect and classify Radio Frequency (RF) Signals. A DL approach is especially useful since it identifies the presence of a signal without needing full protocol information, and can also detect and/or classify non-communication waveforms, such as radar signals. In this work, we focus on the different pre-processing steps that can be used on the input training data, and test the results on a fixed DL architecture. While previous works have mostly focused exclusively on either time-domain or frequency domain approaches, we propose a hybrid image that takes advantage of both time and frequency domain information, and tackles the classification as a Computer Vision problem. Our initial results point out limitations to classical pre-processing approaches while also showing that it's possible to build a classifier that can leverage the strengths of multiple signal representations.
Large-scale quantum machine learning
Aug 02, 2021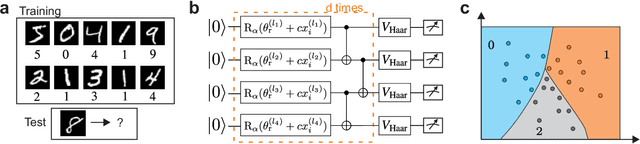
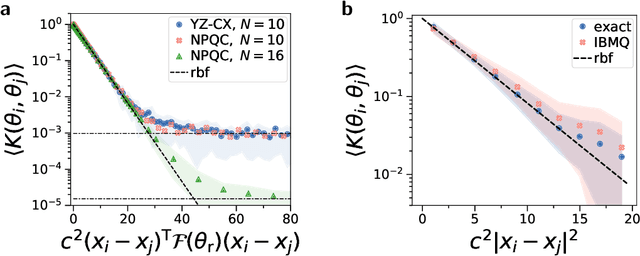
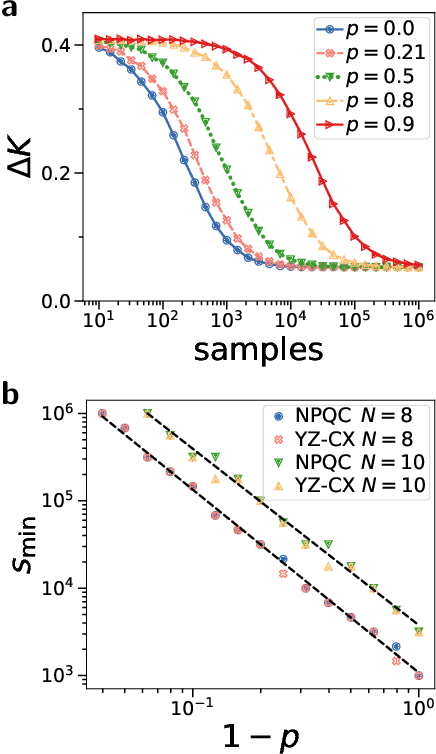
Quantum computers promise to enhance machine learning for practical applications. Quantum machine learning for real-world data has to handle extensive amounts of high-dimensional data. However, conventional methods for measuring quantum kernels are impractical for large datasets as they scale with the square of the dataset size. Here, we measure quantum kernels using randomized measurements to gain a quadratic speedup in computation time and quickly process large datasets. Further, we efficiently encode high-dimensional data into quantum computers with the number of features scaling linearly with the circuit depth. The encoding is characterized by the quantum Fisher information metric and is related to the radial basis function kernel. We demonstrate the advantages and speedups of our methods by classifying images with the IBM quantum computer. Our approach is exceptionally robust to noise via a complementary error mitigation scheme. Using currently available quantum computers, the MNIST database can be processed within 220 hours instead of 10 years which opens up industrial applications of quantum machine learning.
Smart Pointers and Shared Memory Synchronisation for Efficient Inter-process Communication in ROS on an Autonomous Vehicle
Aug 16, 2021
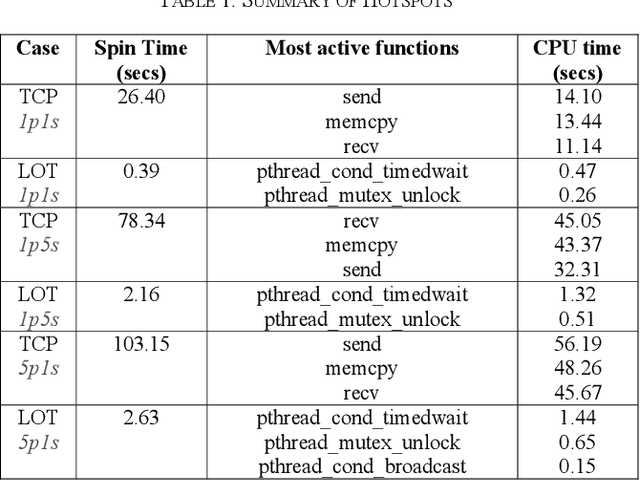
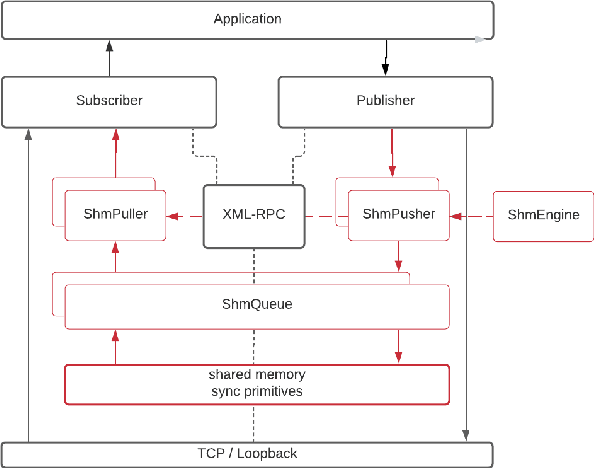
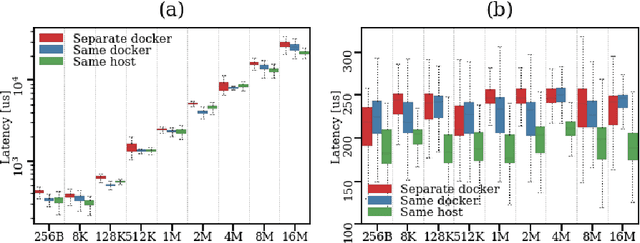
Despite the stringent requirements of a real-time system, the reliance of the Robot Operating System (ROS) on the loopback network interface imposes a considerable overhead on the transport of high bandwidth data, while the nodelet package, which is an efficient mechanism for intra-process communication, does not address the problem of efficient local inter-process communication (IPC). To remedy this, we propose a novel integration into ROS of smart pointers and synchronisation primitives stored in shared memory. These obey the same semantics and, more importantly, exhibit the same performance as their C++ standard library counterparts, making them preferable to other local IPC mechanisms. We present a series of benchmarks for our mechanism - which we call LOT (Low Overhead Transport) - and use them to assess its performance on realistic data loads based on Five's Autonomous Vehicle (AV) system, and extend our analysis to the case where multiple ROS nodes are running in Docker containers. We find that our mechanism performs up to two orders of magnitude better than the standard IPC via local loopback. Finally, we apply industry-standard profiling techniques to explore the hotspots of code running in both user and kernel space, comparing our implementation against alternatives.