 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
One Chatbot Per Person: Creating Personalized Chatbots based on Implicit User Profiles
Aug 20, 2021

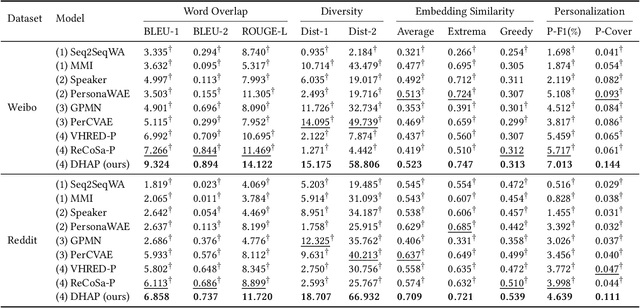
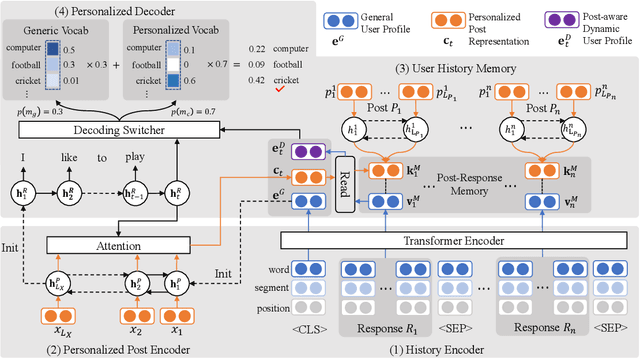
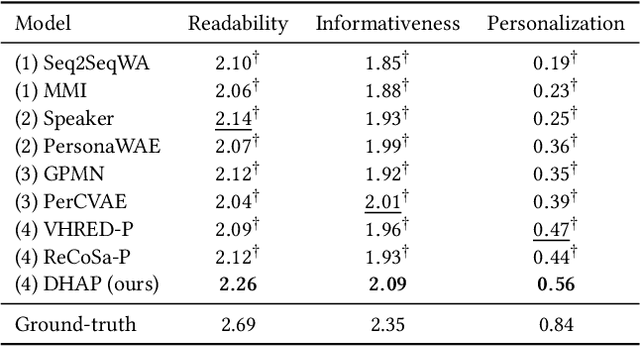
Personalized chatbots focus on endowing chatbots with a consistent personality to behave like real users, give more informative responses, and further act as personal assistants. Existing personalized approaches tried to incorporate several text descriptions as explicit user profiles. However, the acquisition of such explicit profiles is expensive and time-consuming, thus being impractical for large-scale real-world applications. Moreover, the restricted predefined profile neglects the language behavior of a real user and cannot be automatically updated together with the change of user interests. In this paper, we propose to learn implicit user profiles automatically from large-scale user dialogue history for building personalized chatbots. Specifically, leveraging the benefits of Transformer on language understanding, we train a personalized language model to construct a general user profile from the user's historical responses. To highlight the relevant historical responses to the input post, we further establish a key-value memory network of historical post-response pairs, and build a dynamic post-aware user profile. The dynamic profile mainly describes what and how the user has responded to similar posts in history. To explicitly utilize users' frequently used words, we design a personalized decoder to fuse two decoding strategies, including generating a word from the generic vocabulary and copying one word from the user's personalized vocabulary. Experiments on two real-world datasets show the significant improvement of our model compared with existing methods.
Learning Local-Global Contextual Adaptation for Fully End-to-End Bottom-Up Human Pose Estimation
Sep 08, 2021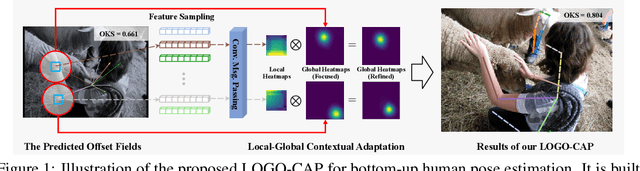
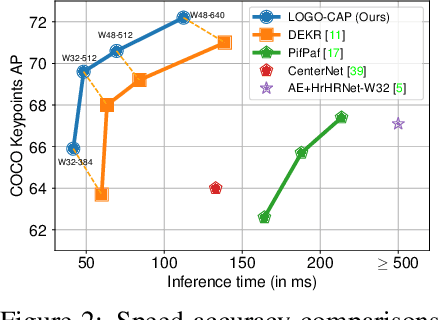
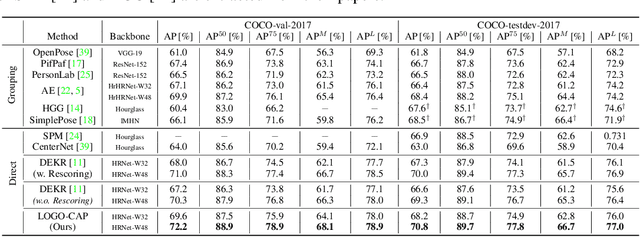
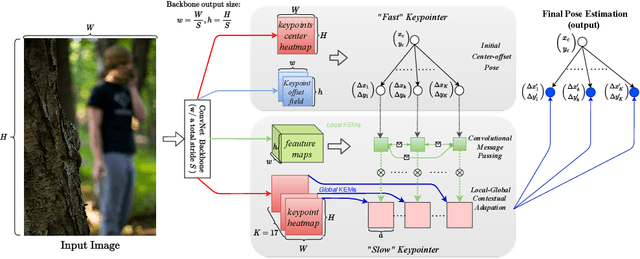
This paper presents a method of learning Local-GlObal Contextual Adaptation for fully end-to-end and fast bottom-up human Pose estimation, dubbed as LOGO-CAP. It is built on the conceptually simple center-offset formulation that lacks inaccuracy for pose estimation. When revisiting the bottom-up human pose estimation with the thought of "thinking, fast and slow" by D. Kahneman, we introduce a "slow keypointer" to remedy the lack of sufficient accuracy of the "fast keypointer". In learning the "slow keypointer", the proposed LOGO-CAP lifts the initial "fast" keypoints by offset predictions to keypoint expansion maps (KEMs) to counter their uncertainty in two modules. Firstly, the local KEMs (e.g., 11x11) are extracted from a low-dimensional feature map. A proposed convolutional message passing module learns to "re-focus" the local KEMs to the keypoint attraction maps (KAMs) by accounting for the structured output prediction nature of human pose estimation, which is directly supervised by the object keypoint similarity (OKS) loss in training. Secondly, the global KEMs are extracted, with a sufficiently large region-of-interest (e.g., 97x97), from the keypoint heatmaps that are computed by a direct map-to-map regression. Then, a local-global contextual adaptation module is proposed to convolve the global KEMs using the learned KAMs as the kernels. This convolution can be understood as the learnable offsets guided deformable and dynamic convolution in a pose-sensitive way. The proposed method is end-to-end trainable with near real-time inference speed, obtaining state-of-the-art performance on the COCO keypoint benchmark for bottom-up human pose estimation. With the COCO trained model, our LOGO-CAP also outperforms prior arts by a large margin on the challenging OCHuman dataset.
Robust low-rank covariance matrix estimation with a general pattern of missing values
Jul 22, 2021
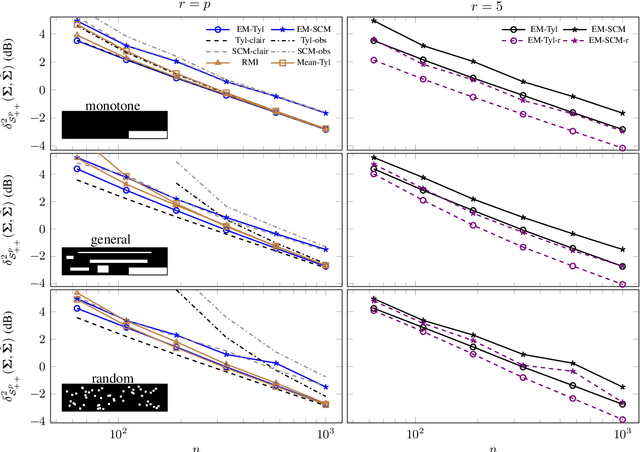
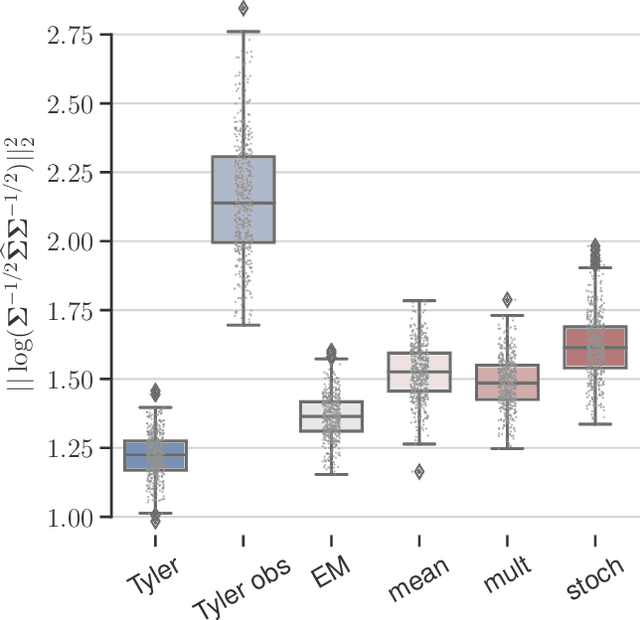
This paper tackles the problem of robust covariance matrix estimation when the data is incomplete. Classical statistical estimation methodologies are usually built upon the Gaussian assumption, whereas existing robust estimation ones assume unstructured signal models. The former can be inaccurate in real-world data sets in which heterogeneity causes heavy-tail distributions, while the latter does not profit from the usual low-rank structure of the signal. Taking advantage of both worlds, a covariance matrix estimation procedure is designed on a robust (compound Gaussian) low-rank model by leveraging the observed-data likelihood function within an expectation-maximization algorithm. It is also designed to handle general pattern of missing values. The proposed procedure is first validated on simulated data sets. Then, its interest for classification and clustering applications is assessed on two real data sets with missing values, which include multispectral and hyperspectral time series.
Partially Hidden Markov Chain Linear Autoregressive model: inference and forecasting
Feb 24, 2021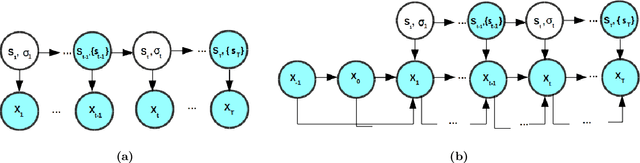
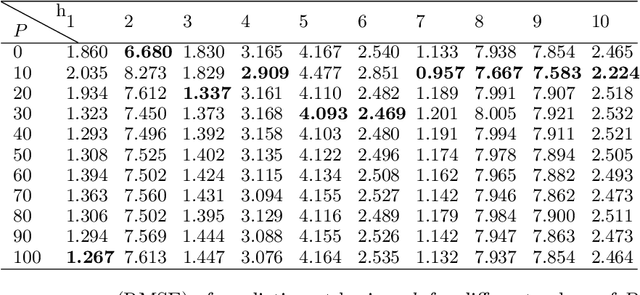
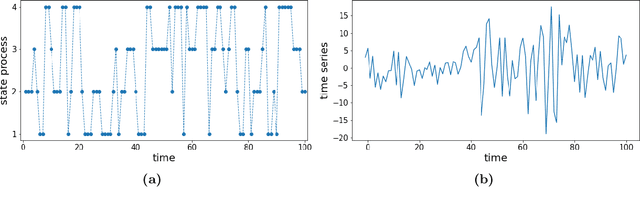
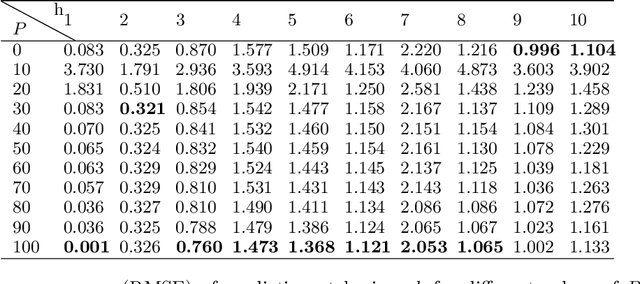
Time series subject to change in regime have attracted much interest in domains such as econometry, finance or meteorology. For discrete-valued regimes, some models such as the popular Hidden Markov Chain (HMC) describe time series whose state process is unknown at all time-steps. Sometimes, time series are firstly labelled thanks to some annotation function. Thus, another category of models handles the case with regimes observed at all time-steps. We present a novel model which addresses the intermediate case: (i) state processes associated to such time series are modelled by Partially Hidden Markov Chains (PHMCs); (ii) a linear autoregressive (LAR) model drives the dynamics of the time series, within each regime. We describe a variant of the expection maximization (EM) algorithm devoted to PHMC-LAR model learning. We propose a hidden state inference procedure and a forecasting function that take into account the observed states when existing. We assess inference and prediction performances, and analyze EM convergence times for the new model, using simulated data. We show the benefits of using partially observed states to decrease EM convergence times. A fully labelled scheme with unreliable labels also speeds up EM. This offers promising prospects to enhance PHMC-LAR model selection. We also point out the robustness of PHMC-LAR to labelling errors in inference task, when large training datasets and moderate labelling error rates are considered. Finally, we highlight the remarkable robustness to error labelling in the prediction task, over the whole range of error rates.
Feature Pyramid Network for Multi-task Affective Analysis
Jul 09, 2021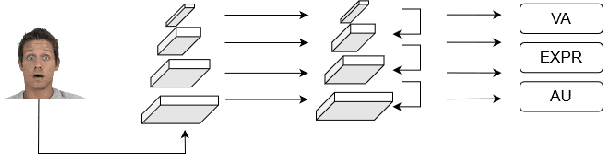
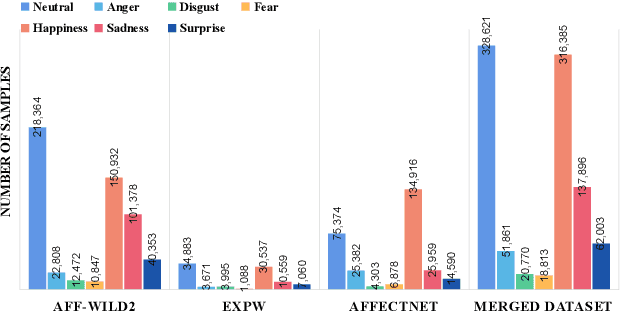
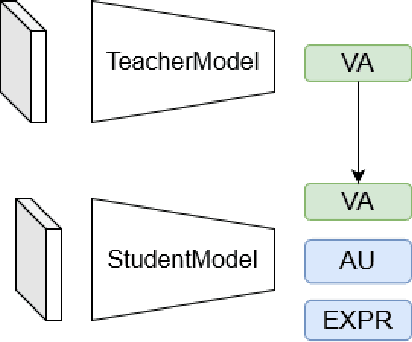
Affective Analysis is not a single task, and the valence-arousal value, expression class and action unit can be predicted at the same time. Previous researches failed to take them as a whole task or ignore the entanglement and hierarchical relation of this three facial attributes. We propose a novel model named feature pyramid networks for multi-task affect analysis. The hierarchical features are extracted to predict three labels and we apply teacher-student training strategy to learn from pretrained single-task models. Extensive experiment results demonstrate the proposed model outperform other models.This is a submission to The 2nd Workshop and Competition on Affective Behavior Analysis in-the-wild (ABAW). The code and model are available for research purposes at https://github.com/ryanhe312/ABAW2-FPNMAA.
Flip Learning: Erase to Segment
Aug 02, 2021
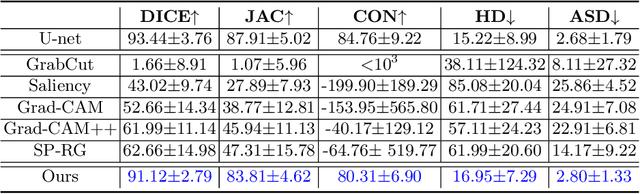
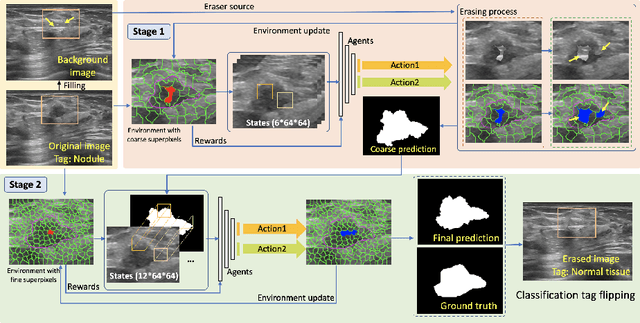
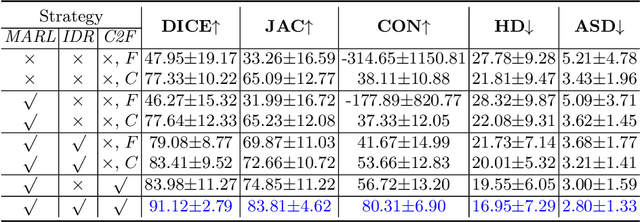
Nodule segmentation from breast ultrasound images is challenging yet essential for the diagnosis. Weakly-supervised segmentation (WSS) can help reduce time-consuming and cumbersome manual annotation. Unlike existing weakly-supervised approaches, in this study, we propose a novel and general WSS framework called Flip Learning, which only needs the box annotation. Specifically, the target in the label box will be erased gradually to flip the classification tag, and the erased region will be considered as the segmentation result finally. Our contribution is three-fold. First, our proposed approach erases on superpixel level using a Multi-agent Reinforcement Learning framework to exploit the prior boundary knowledge and accelerate the learning process. Second, we design two rewards: classification score and intensity distribution reward, to avoid under- and over-segmentation, respectively. Third, we adopt a coarse-to-fine learning strategy to reduce the residual errors and improve the segmentation performance. Extensively validated on a large dataset, our proposed approach achieves competitive performance and shows great potential to narrow the gap between fully-supervised and weakly-supervised learning.
ATTACC the Quadratic Bottleneck of Attention Layers
Jul 13, 2021



Attention mechanisms form the backbone of state-of-the-art machine learning models for a variety of tasks. Deploying them on deep neural network (DNN) accelerators, however, is prohibitively challenging especially under long sequences. Operators in attention layers exhibit limited reuse and quadratic growth in memory footprint, leading to severe memory-boundedness. This paper introduces a new attention-tailored dataflow, termed FLAT, which leverages operator fusion, loop-nest optimizations, and interleaved execution. It increases the effective memory bandwidth by efficiently utilizing the high-bandwidth, low-capacity on-chip buffer and thus achieves better run time and compute resource utilization. We term FLAT-compatible accelerators ATTACC. In our evaluation, ATTACC achieves 1.94x and 1.76x speedup and 49% and 42% of energy reduction comparing to state-of-the-art edge and cloud accelerators.
Deep Fake Detection: Survey of Facial Manipulation Detection Solutions
Jun 23, 2021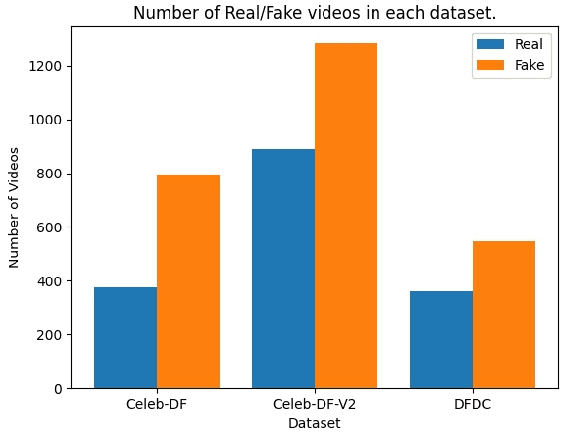
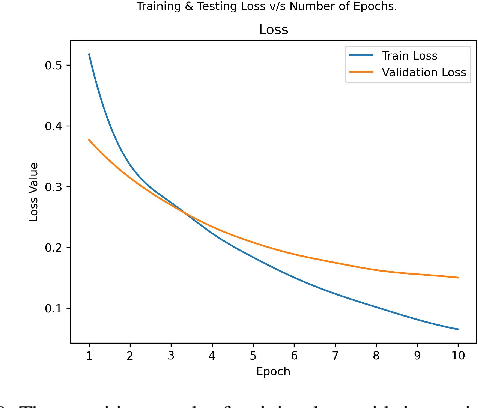
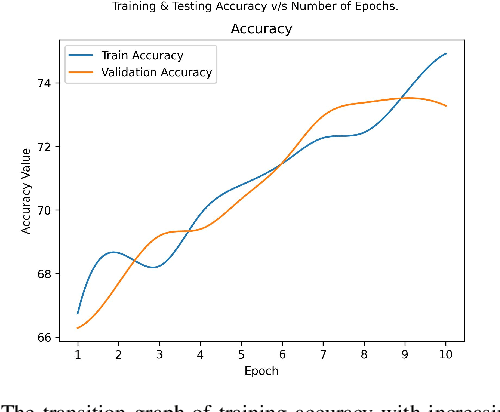
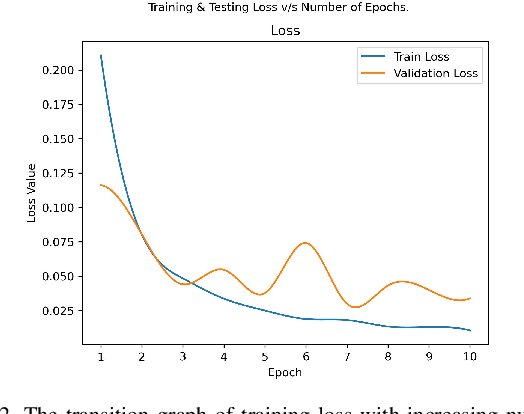
Deep Learning as a field has been successfully used to solve a plethora of complex problems, the likes of which we could not have imagined a few decades back. But as many benefits as it brings, there are still ways in which it can be used to bring harm to our society. Deep fakes have been proven to be one such problem, and now more than ever, when any individual can create a fake image or video simply using an application on the smartphone, there need to be some countermeasures, with which we can detect if the image or video is a fake or real and dispose of the problem threatening the trustworthiness of online information. Although the Deep fakes created by neural networks, may seem to be as real as a real image or video, it still leaves behind spatial and temporal traces or signatures after moderation, these signatures while being invisible to a human eye can be detected with the help of a neural network trained to specialize in Deep fake detection. In this paper, we analyze several such states of the art neural networks (MesoNet, ResNet-50, VGG-19, and Xception Net) and compare them against each other, to find an optimal solution for various scenarios like real-time deep fake detection to be deployed in online social media platforms where the classification should be made as fast as possible or for a small news agency where the classification need not be in real-time but requires utmost accuracy.
* 7 Pages, 14 figures, and 1 table
PoseDet: Fast Multi-Person Pose Estimation Using Pose Embedding
Jul 22, 2021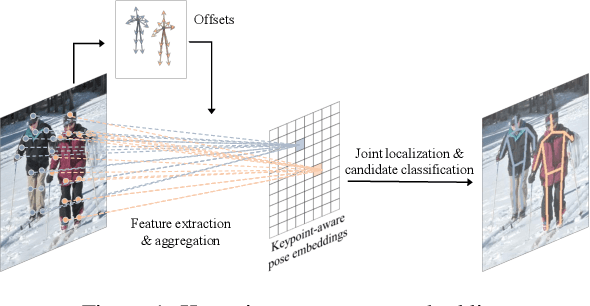
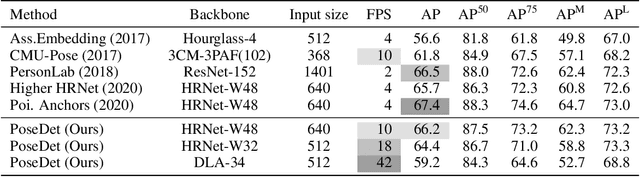
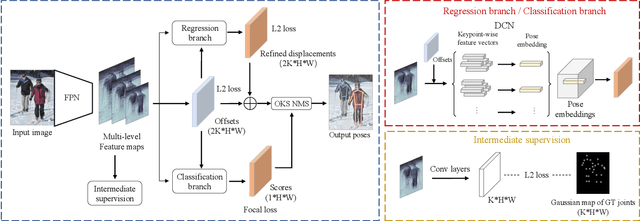
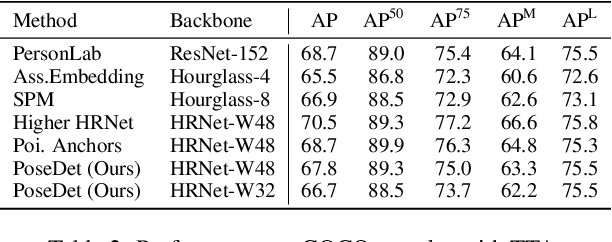
Current methods of multi-person pose estimation typically treat the localization and the association of body joints separately. It is convenient but inefficient, leading to additional computation and a waste of time. This paper, however, presents a novel framework PoseDet (Estimating Pose by Detection) to localize and associate body joints simultaneously at higher inference speed. Moreover, we propose the keypoint-aware pose embedding to represent an object in terms of the locations of its keypoints. The proposed pose embedding contains semantic and geometric information, allowing us to access discriminative and informative features efficiently. It is utilized for candidate classification and body joint localization in PoseDet, leading to robust predictions of various poses. This simple framework achieves an unprecedented speed and a competitive accuracy on the COCO benchmark compared with state-of-the-art methods. Extensive experiments on the CrowdPose benchmark show the robustness in the crowd scenes. Source code is available.
Enlisting 3D Crop Models and GANs for More Data Efficient and Generalizable Fruit Detection
Aug 30, 2021


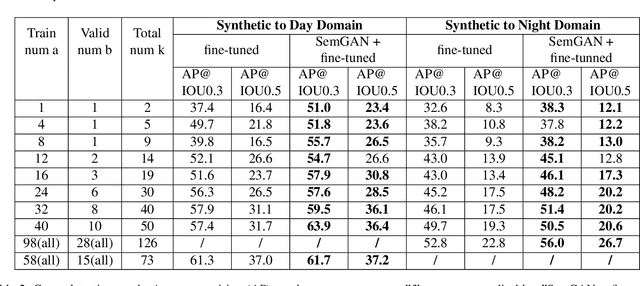
Training real-world neural network models to achieve high performance and generalizability typically requires a substantial amount of labeled data, spanning a broad range of variation. This data-labeling process can be both labor and cost intensive. To achieve desirable predictive performance, a trained model is typically applied into a domain where the data distribution is similar to the training dataset. However, for many agricultural machine learning problems, training datasets are collected at a specific location, during a specific period in time of the growing season. Since agricultural systems exhibit substantial variability in terms of crop type, cultivar, management, seasonal growth dynamics, lighting condition, sensor type, etc, a model trained from one dataset often does not generalize well across domains. To enable more data efficient and generalizable neural network models in agriculture, we propose a method that generates photorealistic agricultural images from a synthetic 3D crop model domain into real world crop domains. The method uses a semantically constrained GAN (generative adversarial network) to preserve the fruit position and geometry. We observe that a baseline CycleGAN method generates visually realistic target domain images but does not preserve fruit position information while our method maintains fruit positions well. Image generation results in vineyard grape day and night images show the visual outputs of our network are much better compared to a baseline network. Incremental training experiments in vineyard grape detection tasks show that the images generated from our method can significantly speed the domain adaption process, increase performance for a given number of labeled images (i.e. data efficiency), and decrease labeling requirements.