 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Rearrangement on Lattices with Pick-n-Swaps: Optimality Structures and Efficient Algorithms
May 27, 2021
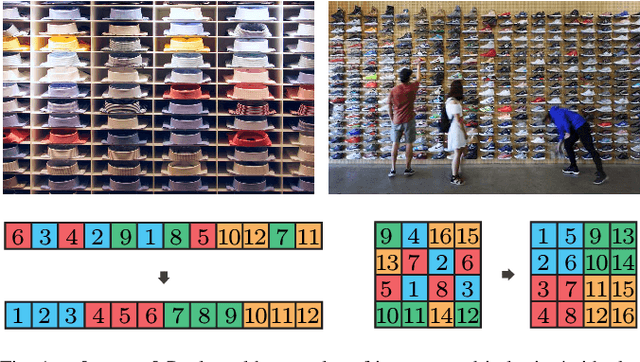
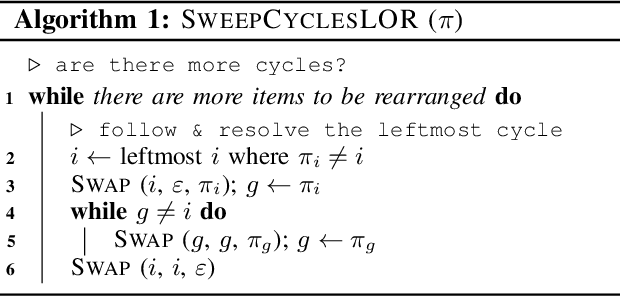
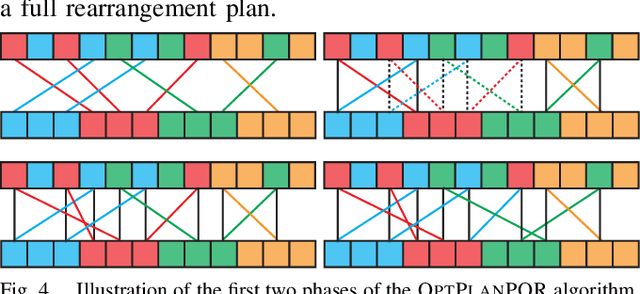

We investigate a class of multi-object rearrangement problems in which a robotic manipulator, capable of carrying an item and making item swaps, is tasked to sort items stored in lattices in a time-optimal manner. We systematically analyze the intrinsic optimality structure, which is fairly rich and intriguing, under different levels of item distinguishability (fully labeled or partially labeled) and different lattice dimensions. Focusing on the most practical setting of one and two dimensions, we develop efficient (low polynomial time) algorithms that optimally perform rearrangements on 1D lattices under both fully and partially labeled settings. On the other hand, we prove that rearrangement on 2D and higher dimensional lattices becomes computationally intractable to optimally solve. Despite their NP-hardness, we are able to again develop efficient algorithms for 2D fully and partially labeled settings that are asymptotically optimal, in expectation, assuming that the initial configuration is randomly selected. Simulation studies confirm the effectiveness of our algorithms in comparison to natural greedy best-first algorithms.
WiP Abstract : Robust Out-of-distribution Motion Detection and Localization in Autonomous CPS
Jul 25, 2021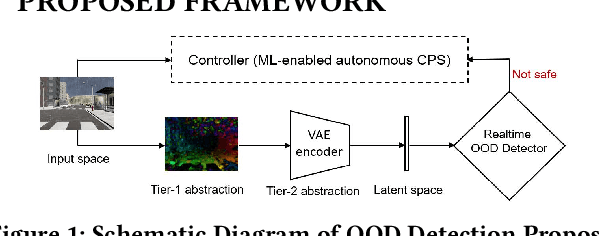
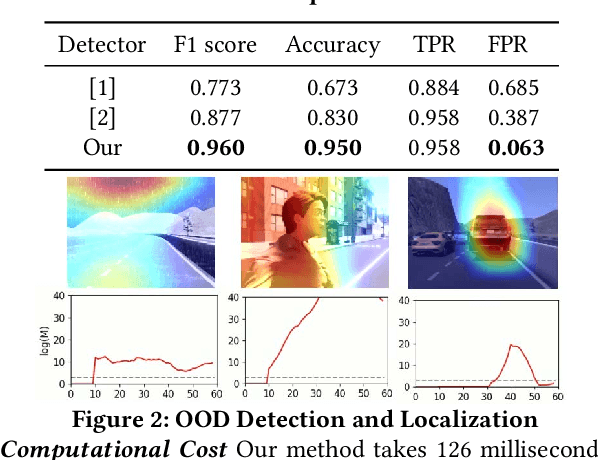
Highly complex deep learning models are increasingly integrated into modern cyber-physical systems (CPS), many of which have strict safety requirements. One problem arising from this is that deep learning lacks interpretability, operating as a black box. The reliability of deep learning is heavily impacted by how well the model training data represents runtime test data, especially when the input space dimension is high as natural images. In response, we propose a robust out-of-distribution (OOD) detection framework. Our approach detects unusual movements from driving video in real-time by combining classical optic flow operation with representation learning via variational autoencoder (VAE). We also design a method to locate OOD factors in images. Evaluation on a driving simulation data set shows that our approach is statistically more robust than related works.
Analysis of the Evolution of Parametric Drivers of High-End Sea-Level Hazards
Jun 11, 2021

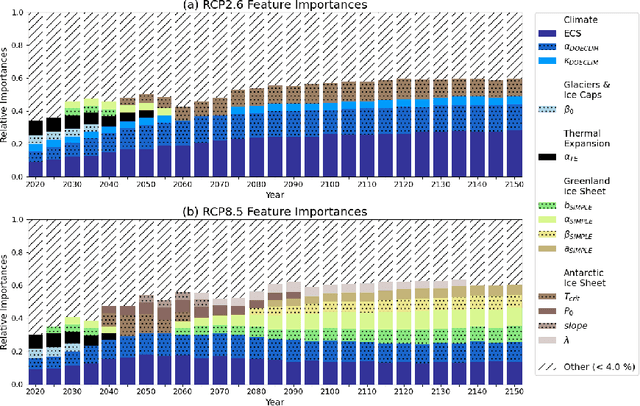
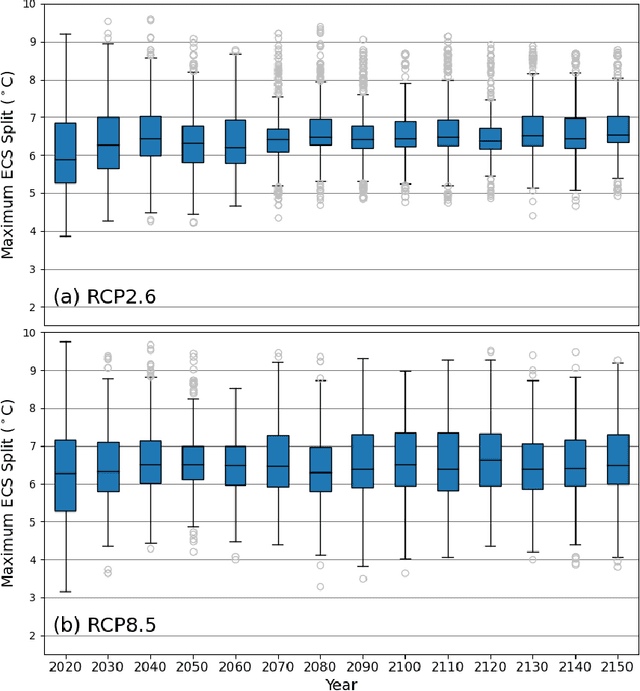
Climate models are critical tools for developing strategies to manage the risks posed by sea-level rise to coastal communities. While these models are necessary for understanding climate risks, there is a level of uncertainty inherent in each parameter in the models. This model parametric uncertainty leads to uncertainty in future climate risks. Consequently, there is a need to understand how those parameter uncertainties impact our assessment of future climate risks and the efficacy of strategies to manage them. Here, we use random forests to examine the parametric drivers of future climate risk and how the relative importances of those drivers change over time. We find that the equilibrium climate sensitivity and a factor that scales the effect of aerosols on radiative forcing are consistently the most important climate model parametric uncertainties throughout the 2020 to 2150 interval for both low and high radiative forcing scenarios. The near-term hazards of high-end sea-level rise are driven primarily by thermal expansion, while the longer-term hazards are associated with mass loss from the Antarctic and Greenland ice sheets. Our results highlight the practical importance of considering time-evolving parametric uncertainties when developing strategies to manage future climate risks.
BezierSeg: Parametric Shape Representation for Fast Object Segmentation in Medical Images
Aug 02, 2021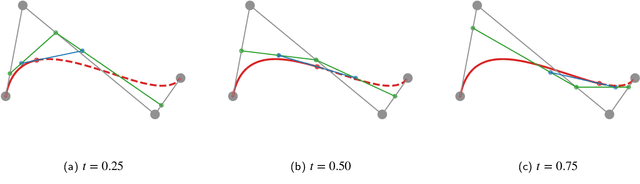
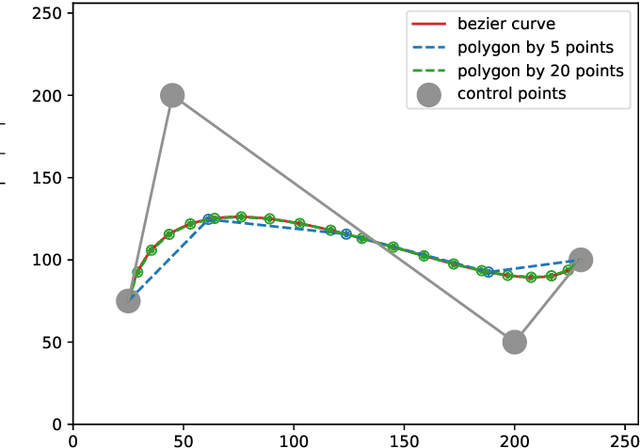
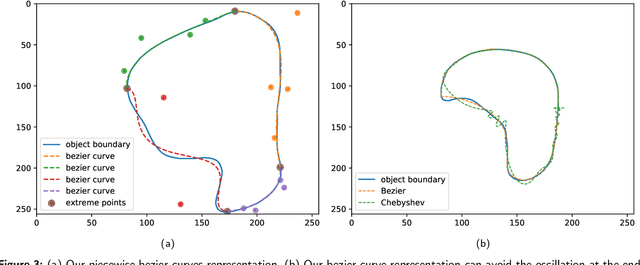
Delineating the lesion area is an important task in image-based diagnosis. Pixel-wise classification is a popular approach to segmenting the region of interest. However, at fuzzy boundaries such methods usually result in glitches, discontinuity, or disconnection, inconsistent with the fact that lesions are solid and smooth. To overcome these undesirable artifacts, we propose the BezierSeg model which outputs bezier curves encompassing the region of interest. Directly modelling the contour with analytic equations ensures that the segmentation is connected, continuous, and the boundary is smooth. In addition, it offers sub-pixel accuracy. Without loss of accuracy, the bezier contour can be resampled and overlaid with images of any resolution. Moreover, a doctor can conveniently adjust the curve's control points to refine the result. Our experiments show that the proposed method runs in real time and achieves accuracy competitive with pixel-wise segmentation models.
A comparison of LSTM and GRU networks for learning symbolic sequences
Jul 05, 2021
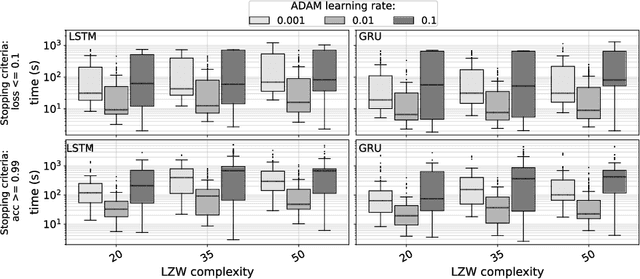
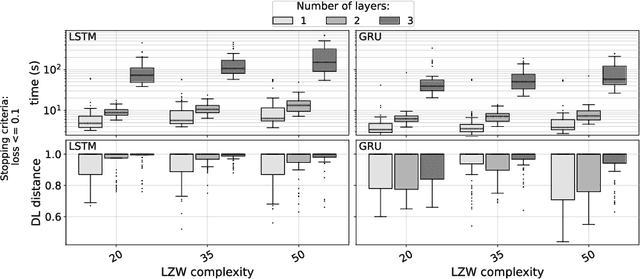
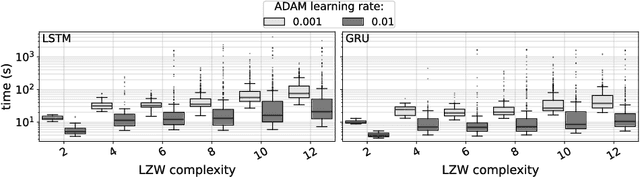
We explore relations between the hyper-parameters of a recurrent neural network (RNN) and the complexity of string sequences it is able to memorize. We compare long short-term memory (LSTM) networks and gated recurrent units (GRUs). We find that an increase of RNN depth does not necessarily result in better memorization capability when the training time is constrained. Our results also indicate that the learning rate and the number of units per layer are among the most important hyper-parameters to be tuned. Generally, GRUs outperform LSTM networks on low complexity sequences while on high complexity sequences LSTMs perform better.
Large-vocabulary Audio-visual Speech Recognition in Noisy Environments
Sep 10, 2021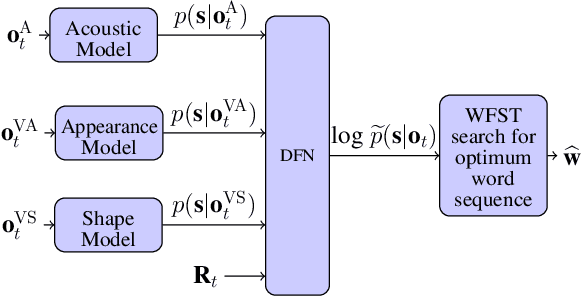
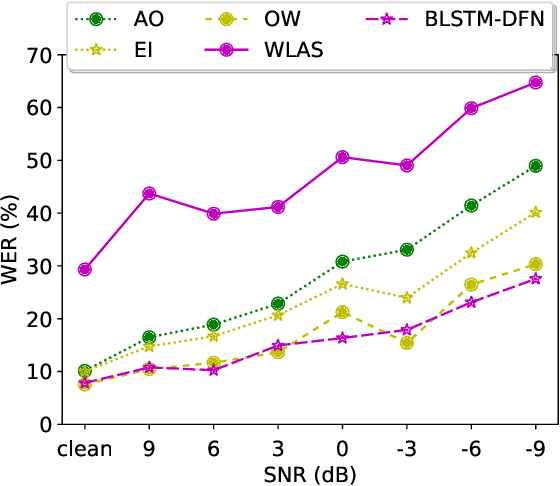

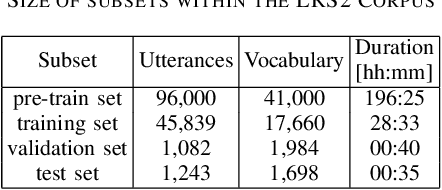
Audio-visual speech recognition (AVSR) can effectively and significantly improve the recognition rates of small-vocabulary systems, compared to their audio-only counterparts. For large-vocabulary systems, however, there are still many difficulties, such as unsatisfactory video recognition accuracies, that make it hard to improve over audio-only baselines. In this paper, we specifically consider such scenarios, focusing on the large-vocabulary task of the LRS2 database, where audio-only performance is far superior to video-only accuracies, making this an interesting and challenging setup for multi-modal integration. To address the inherent difficulties, we propose a new fusion strategy: a recurrent integration network is trained to fuse the state posteriors of multiple single-modality models, guided by a set of model-based and signal-based stream reliability measures. During decoding, this network is used for stream integration within a hybrid recognizer, where it can thus cope with the time-variant reliability and information content of its multiple feature inputs. We compare the results with end-to-end AVSR systems as well as with competitive hybrid baseline models, finding that the new fusion strategy shows superior results, on average even outperforming oracle dynamic stream weighting, which has so far marked the -- realistically unachievable -- upper bound for standard stream weighting. Even though the pure lipreading performance is low, audio-visual integration is helpful under all -- clean, noisy, and reverberant -- conditions. On average, the new system achieves a relative word error rate reduction of 42.18\% compared to the audio-only model, pointing at a high effectiveness of the proposed integration approach.
Faster Learning by Reduction of Data Access Time
Jul 25, 2018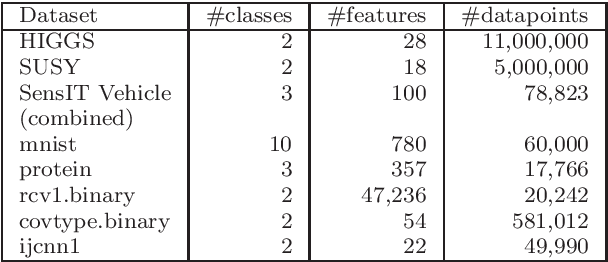
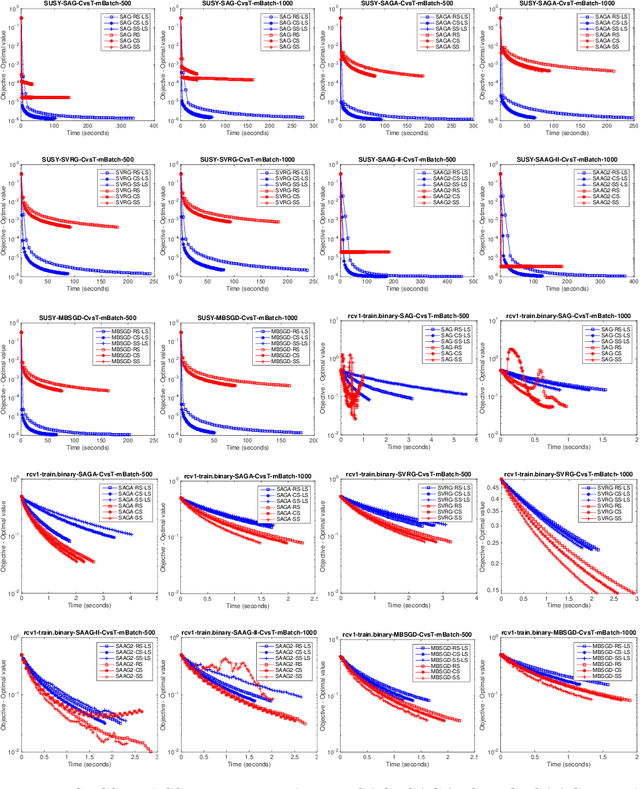
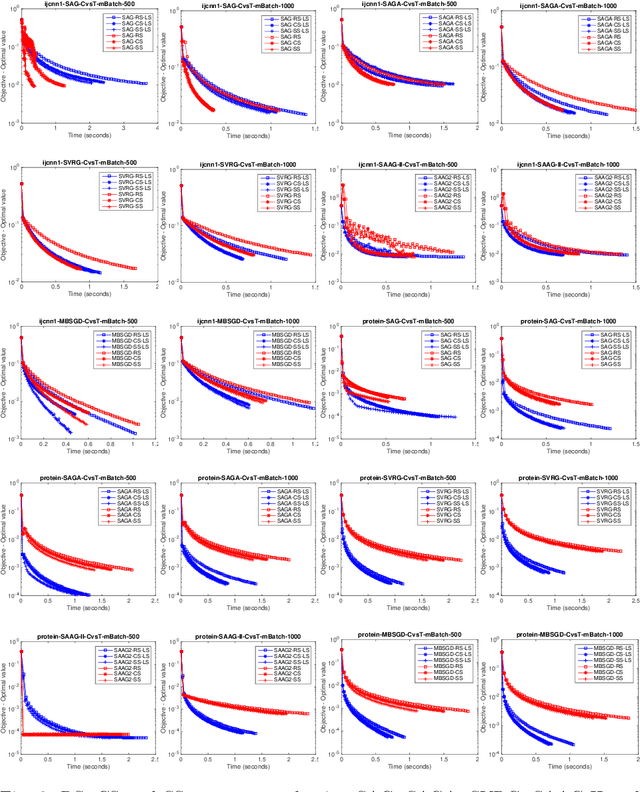
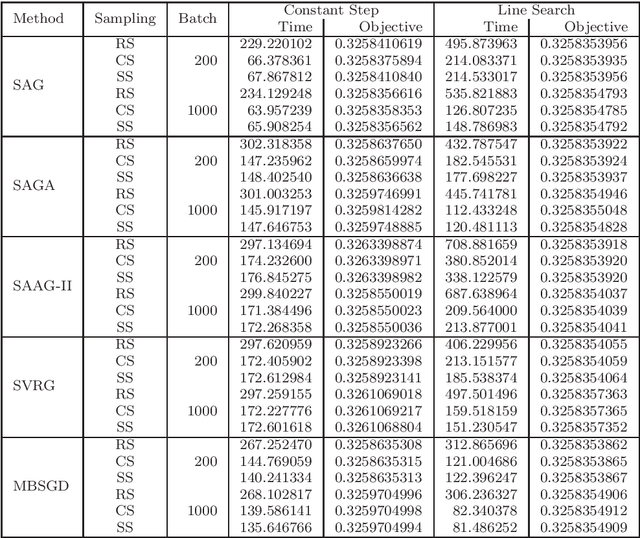
Nowadays, the major challenge in machine learning is the Big Data challenge. The big data problems due to large number of data points or large number of features in each data point, or both, the training of models have become very slow. The training time has two major components: Time to access the data and time to process (learn from) the data. So far, the research has focused only on the second part, i.e., learning from the data. In this paper, we have proposed one possible solution to handle the big data problems in machine learning. The idea is to reduce the training time through reducing data access time by proposing systematic sampling and cyclic/sequential sampling to select mini-batches from the dataset. To prove the effectiveness of proposed sampling techniques, we have used Empirical Risk Minimization, which is commonly used machine learning problem, for strongly convex and smooth case. The problem has been solved using SAG, SAGA, SVRG, SAAG-II and MBSGD (Mini-batched SGD), each using two step determination techniques, namely, constant step size and backtracking line search method. Theoretical results prove the same convergence for systematic sampling, cyclic sampling and the widely used random sampling technique, in expectation. Experimental results with bench marked datasets prove the efficacy of the proposed sampling techniques and show up to six times faster training.
* 80 figures, final journal version
Machine Learning Framework for Sensing and Modeling Interference in IoT Frequency Bands
Jun 10, 2021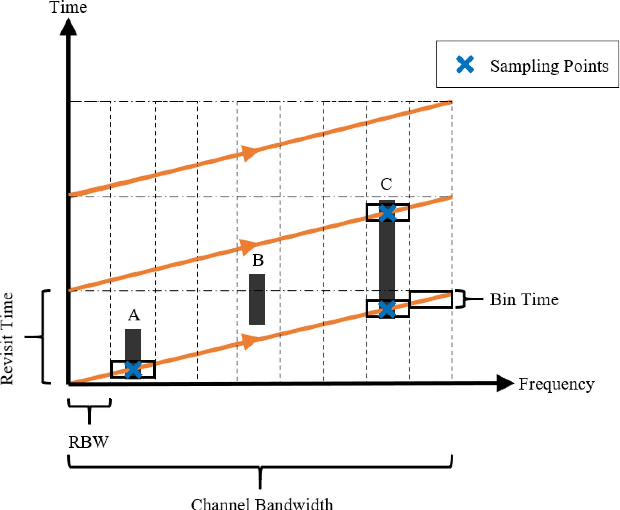
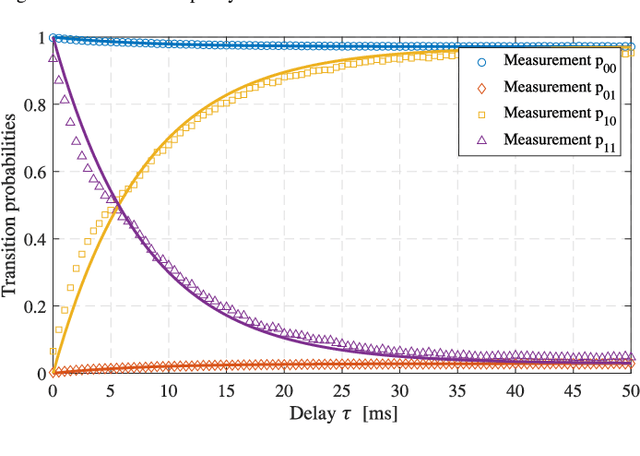
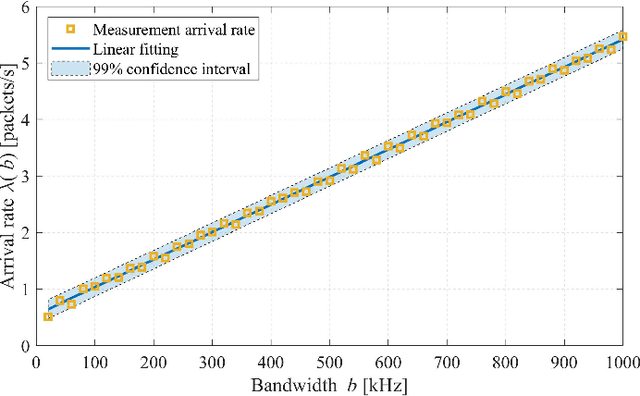
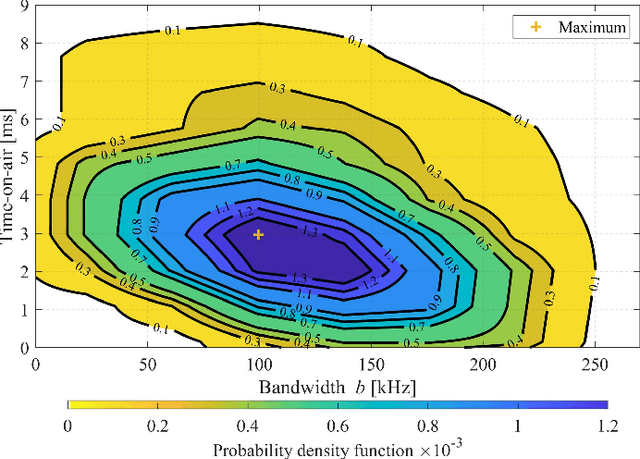
Spectrum scarcity has surfaced as a prominent concern in wireless radio communications with the emergence of new technologies over the past few years. As a result, there is growing need for better understanding of the spectrum occupancy with newly emerging access technologies supporting the Internet of Things. In this paper, we present a framework to capture and model the traffic behavior of short-time spectrum occupancy for IoT applications in the shared bands to determine the existing interference. The proposed capturing method utilizes a software defined radio to monitor the short bursts of IoT transmissions by capturing the time series data which is converted to power spectral density to extract the observed occupancy. Furthermore, we propose the use of an unsupervised machine learning technique to enhance conventionally implemented energy detection methods. Our experimental results show that the temporal and frequency behavior of the spectrum can be well-captured using the combination of two models, namely, semi-Markov chains and a Poisson-distribution arrival rate. We conduct an extensive measurement campaign in different urban environments and incorporate the spatial effect on the IoT shared spectrum.
Creating and Querying Personalized Versions ofWikidata on a Laptop
Aug 06, 2021



Application developers today have three choices for exploiting the knowledge present in Wikidata: they can download the Wikidata dumps in JSON or RDF format, they can use the Wikidata API to get data about individual entities, or they can use the Wikidata SPARQL endpoint. None of these methods can support complex, yet common, query use cases, such as retrieval of large amounts of data or aggregations over large fractions of Wikidata. This paper introduces KGTK Kypher, a query language and processor that allows users to create personalized variants of Wikidata on a laptop. We present several use cases that illustrate the types of analyses that Kypher enables users to run on the full Wikidata KG on a laptop, combining data from external resources such as DBpedia. The Kypher queries for these use cases run much faster on a laptop than the equivalent SPARQL queries on a Wikidata clone running on a powerful server with 24h time-out limits.
Time series model selection with a meta-learning approach; evidence from a pool of forecasting algorithms
Aug 22, 2019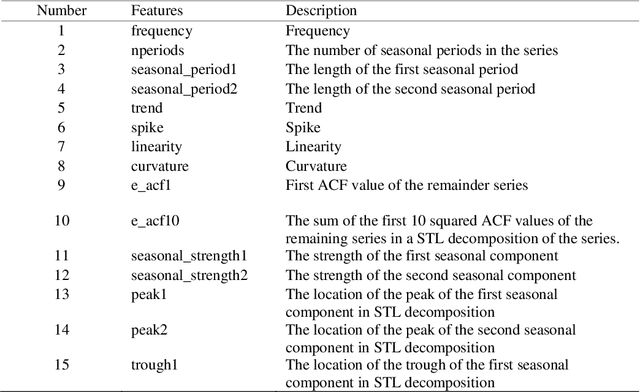
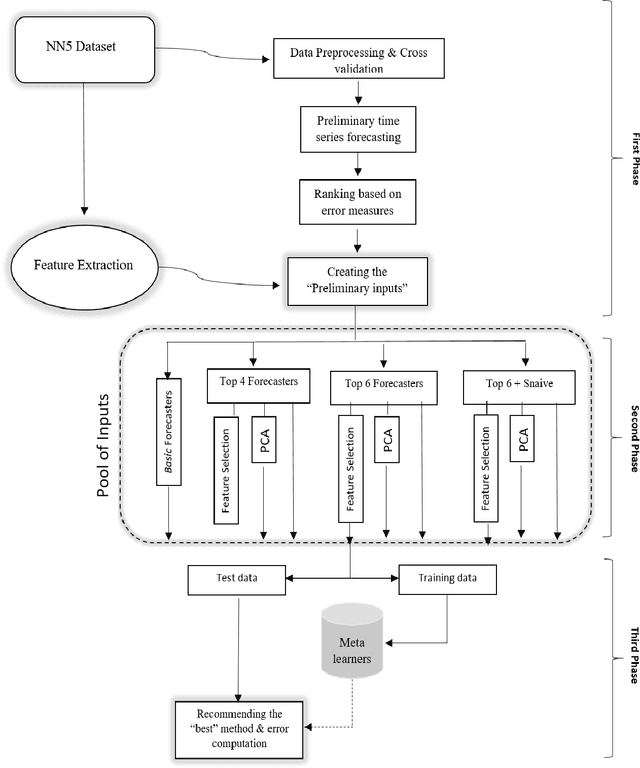
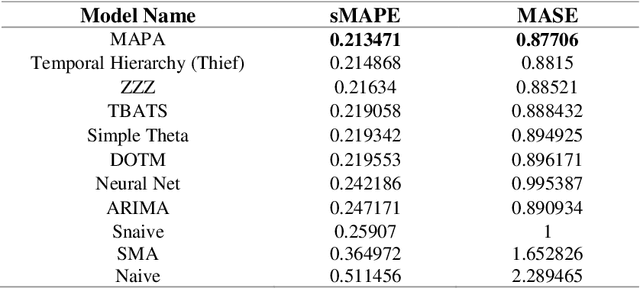
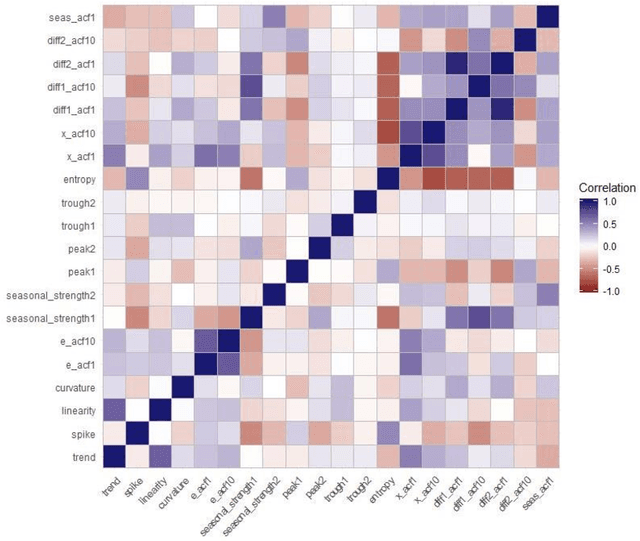
One of the challenging questions in time series forecasting is how to find the best algorithm. In recent years, a recommender system scheme has been developed for time series analysis using a meta-learning approach. This system selects the best forecasting method with consideration of the time series characteristics. In this paper, we propose a novel approach to focusing on some of the unanswered questions resulting from the use of meta-learning in time series forecasting. Therefore, three main gaps in previous works are addressed including, analyzing various subsets of top forecasters as inputs for meta-learners; evaluating the effect of forecasting error measures; and assessing the role of the dimensionality of the feature space on the forecasting errors of meta-learners. All of these objectives are achieved with the help of a diverse state-of-the-art pool of forecasters and meta-learners. For this purpose, first, a pool of forecasting algorithms is implemented on the NN5 competition dataset and ranked based on the two error measures. Then, six machine-learning classifiers known as meta-learners, are trained on the extracted features of the time series in order to assign the most suitable forecasting method for the various subsets of the pool of forecasters. Furthermore, two-dimensionality reduction methods are implemented in order to investigate the role of feature space dimension on the performance of meta-learners. In general, it was found that meta-learners were able to defeat all of the individual benchmark forecasters; this performance was improved even after applying the feature selection method.