 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Joint Echo Cancellation and Noise Suppression based on Cascaded Magnitude and Complex Mask Estimation
Jul 20, 2021
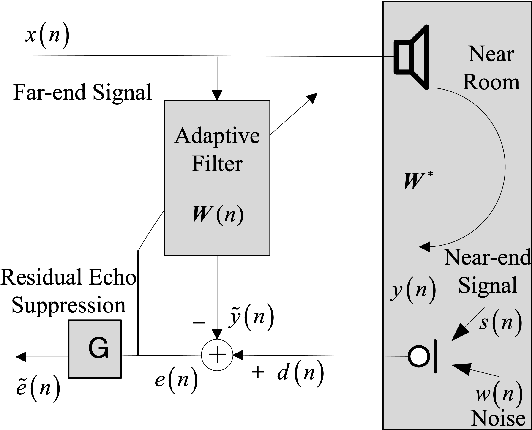
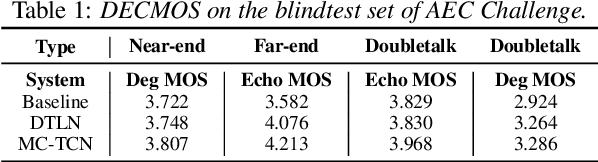
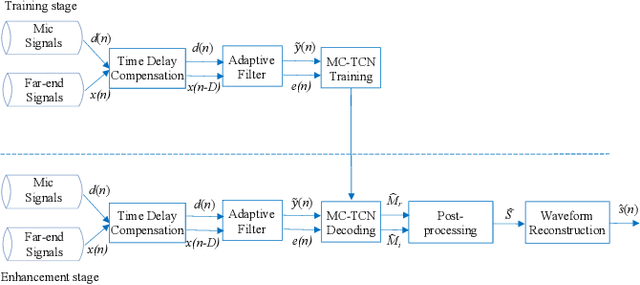
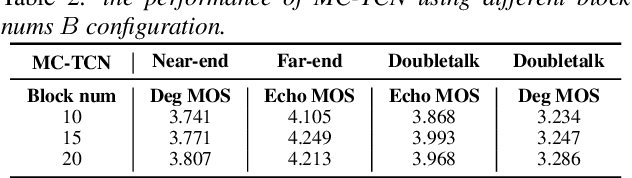
Acoustic echo and background noise can seriously degrade the intelligibility of speech. In practice, echo and noise suppression are usually treated as two separated tasks and can be removed with various digital signal processing (DSP) and deep learning techniques. In this paper, we propose a new cascaded model, magnitude and complex temporal convolutional neural network (MC-TCN), to jointly perform acoustic echo cancellation and noise suppression with the help of adaptive filters. The MC-TCN cascades two separation cores, which are used to extract robust magnitude spectra feature and to enhance magnitude and phase simultaneously. Experimental results reveal that the proposed method can achieve superior performance by removing both echo and noise in real-time. In terms of DECMOS, the subjective test shows our method achieves a mean score of 4.41 and outperforms the INTERSPEECH2021 AEC-Challenge baseline by 0.54.
Multi-dataset Pretraining: A Unified Model for Semantic Segmentation
Jun 08, 2021
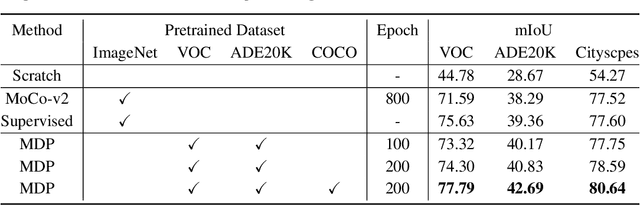
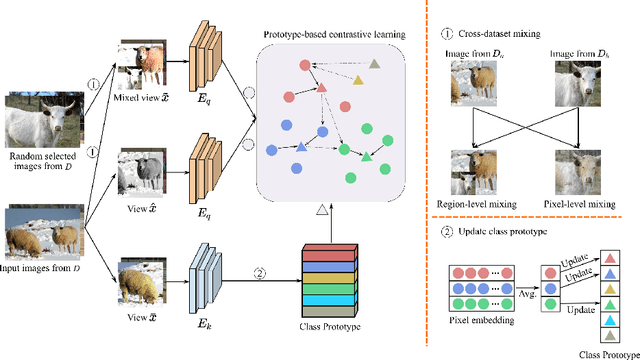
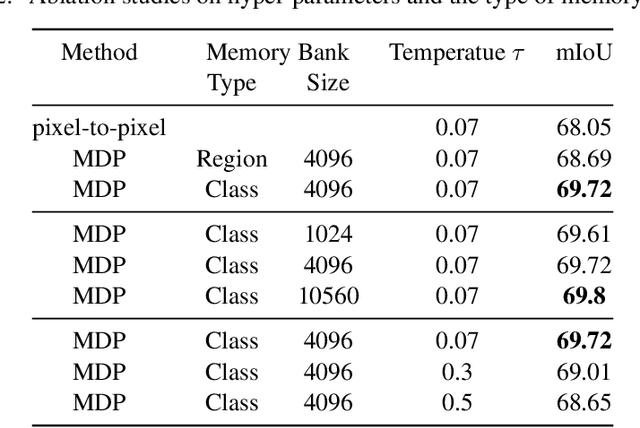
Collecting annotated data for semantic segmentation is time-consuming and hard to scale up. In this paper, we for the first time propose a unified framework, termed as Multi-Dataset Pretraining, to take full advantage of the fragmented annotations of different datasets. The highlight is that the annotations from different domains can be efficiently reused and consistently boost performance for each specific domain. This is achieved by first pretraining the network via the proposed pixel-to-prototype contrastive loss over multiple datasets regardless of their taxonomy labels, and followed by fine-tuning the pretrained model over specific dataset as usual. In order to better model the relationship among images and classes from different datasets, we extend the pixel level embeddings via cross dataset mixing and propose a pixel-to-class sparse coding strategy that explicitly models the pixel-class similarity over the manifold embedding space. In this way, we are able to increase intra-class compactness and inter-class separability, as well as considering inter-class similarity across different datasets for better transferability. Experiments conducted on several benchmarks demonstrate its superior performance. Notably, MDP consistently outperforms the pretrained models over ImageNet by a considerable margin, while only using less than 10% samples for pretraining.
SOTR: Segmenting Objects with Transformers
Aug 17, 2021

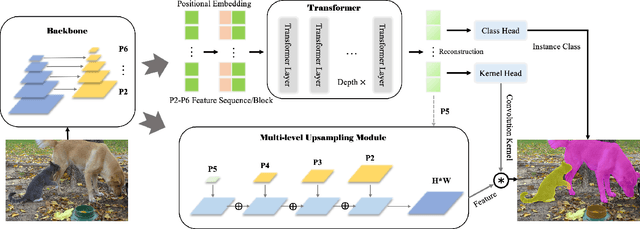
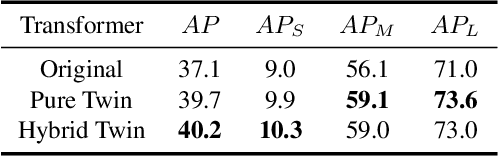
Most recent transformer-based models show impressive performance on vision tasks, even better than Convolution Neural Networks (CNN). In this work, we present a novel, flexible, and effective transformer-based model for high-quality instance segmentation. The proposed method, Segmenting Objects with TRansformers (SOTR), simplifies the segmentation pipeline, building on an alternative CNN backbone appended with two parallel subtasks: (1) predicting per-instance category via transformer and (2) dynamically generating segmentation mask with the multi-level upsampling module. SOTR can effectively extract lower-level feature representations and capture long-range context dependencies by Feature Pyramid Network (FPN) and twin transformer, respectively. Meanwhile, compared with the original transformer, the proposed twin transformer is time- and resource-efficient since only a row and a column attention are involved to encode pixels. Moreover, SOTR is easy to be incorporated with various CNN backbones and transformer model variants to make considerable improvements for the segmentation accuracy and training convergence. Extensive experiments show that our SOTR performs well on the MS COCO dataset and surpasses state-of-the-art instance segmentation approaches. We hope our simple but strong framework could serve as a preferment baseline for instance-level recognition. Our code is available at https://github.com/easton-cau/SOTR.
A Multi-Sensor Interface to Improve the Teaching and Learning Experience in Arc Welding Training Tasks
Sep 10, 2021

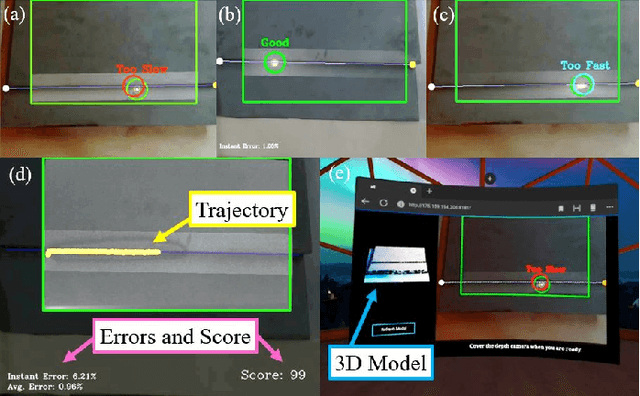

This paper presents the development of a multi-sensor extended reality platform to improve the teaching and learning experience of arc welding tasks. Traditional methods to acquire hand-eye welding coordination skills are typically conducted through one-to-one instruction where trainees/trainers must wear protective helmets and conduct several hands-on tests with metal workpieces. This approach is inefficient as the harmful light emitted from the electric arc impedes the close monitoring of the welding process (practitioners can only observe a small bright spot and most geometric information cannot be perceived). To tackle these problems, some recent training approaches have leveraged on virtual reality (VR) as a way to safely simulate the process and visualize the geometry of the workpieces. However, the synthetic nature of the virtual simulation reduces the effectiveness of the platform; It fails to comprise actual interactions with the welding environment, which may hinder the learning process of a trainee. To incorporate a real welding experience, in this work we present a new automated multi-sensor extended reality platform for arc welding training. It consists of three components: (1) An HDR camera, monitoring the real welding spot in real-time; (2) A depth sensor, capturing the 3D geometry of the scene; and (3) A head-mounted VR display, visualizing the process safely. Our innovative platform provides trainees with a "bot trainer", virtual cues of the seam geometry, automatic spot tracking, and a performance score. To validate the platform's feasibility, we conduct extensive experiments with several welding training tasks. We show that compared with the traditional training practice and recent virtual reality approaches, our automated method achieves better performances in terms of accuracy, learning curve, and effectiveness.
With One Voice: Composing a Travel Voice Assistant from Re-purposed Models
Aug 04, 2021
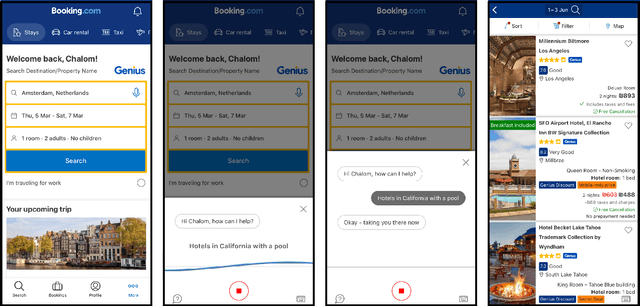

Voice assistants provide users a new way of interacting with digital products, allowing them to retrieve information and complete tasks with an increased sense of control and flexibility. Such products are comprised of several machine learning models, like Speech-to-Text transcription, Named Entity Recognition and Resolution, and Text Classification. Building a voice assistant from scratch takes the prolonged efforts of several teams constructing numerous models and orchestrating between components. Alternatives such as using third-party vendors or re-purposing existing models may be considered to shorten time-to-market and development costs. However, each option has its benefits and drawbacks. We present key insights from building a voice search assistant for Booking.com search and recommendation system. Our paper compares the achieved performance and development efforts in dedicated tailor-made solutions against existing re-purposed models. We share and discuss our data-driven decisions about implementation trade-offs and their estimated outcomes in hindsight, showing that a fully functional machine learning product can be built from existing models.
* 2nd International Workshop on Industrial Recommendation Systems @ KDD 2021
Memory-Efficient Factorization Machines via Binarizing both Data and Model Coefficients
Aug 17, 2021
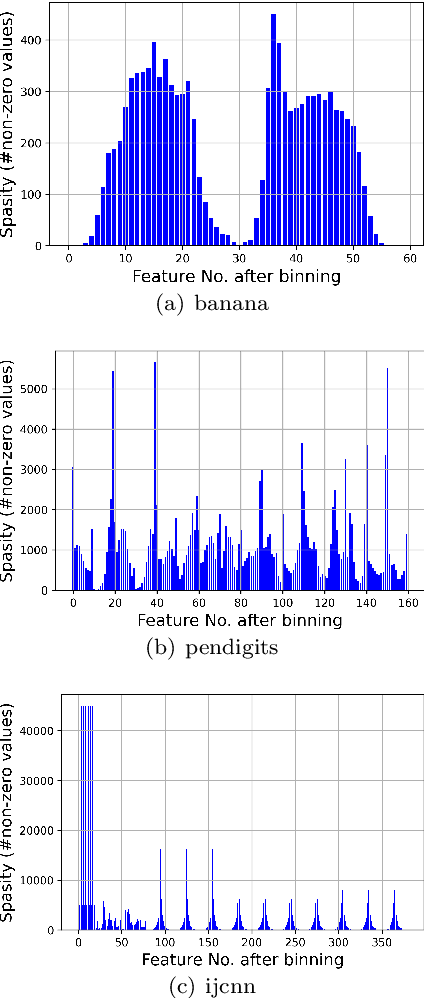
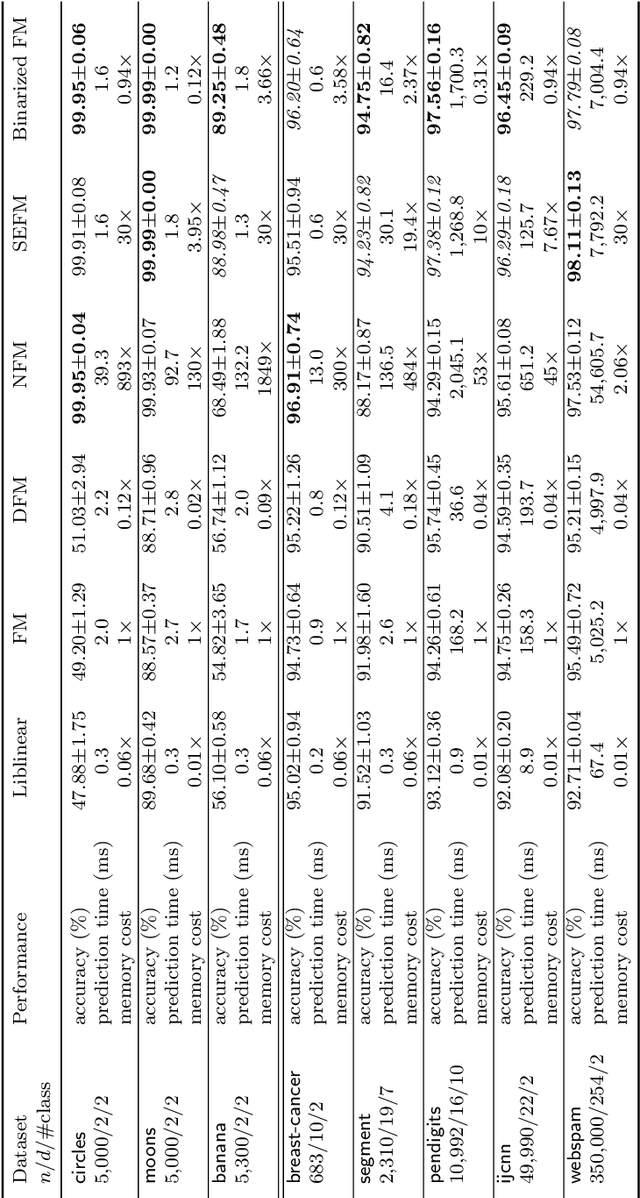
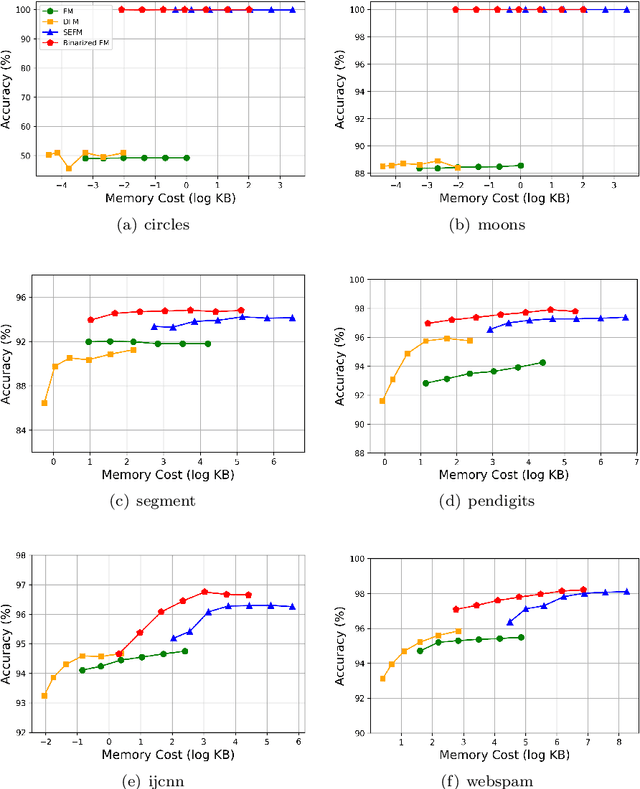
Factorization Machines (FM), a general predictor that can efficiently model feature interactions in linear time, was primarily proposed for collaborative recommendation and have been broadly used for regression, classification and ranking tasks. Subspace Encoding Factorization Machine (SEFM) has been proposed recently to overcome the expressiveness limitation of Factorization Machines (FM) by applying explicit nonlinear feature mapping for both individual features and feature interactions through one-hot encoding to each input feature. Despite the effectiveness of SEFM, it increases the memory cost of FM by $b$ times, where $b$ is the number of bins when applying one-hot encoding on each input feature. To reduce the memory cost of SEFM, we propose a new method called Binarized FM which constraints the model parameters to be binary values (i.e., 1 or $-1$). Then each parameter value can be efficiently stored in one bit. Our proposed method can significantly reduce the memory cost of SEFM model. In addition, we propose a new algorithm to effectively and efficiently learn proposed FM with binary constraints using Straight Through Estimator (STE) with Adaptive Gradient Descent (Adagrad). Finally, we evaluate the performance of our proposed method on eight different classification datasets. Our experimental results have demonstrated that our proposed method achieves comparable accuracy with SEFM but with much less memory cost.
Improving Accuracy of Permutation DAG Search using Best Order Score Search
Sep 01, 2021The Sparsest Permutation (SP) algorithm is accurate but limited to about 9 variables in practice; the Greedy Sparest Permutation (GSP) algorithm is faster but less weak theoretically. A compromise can be given, the Best Order Score Search, which gives results as accurate as SP but for much larger and denser graphs. BOSS (Best Order Score Search) is more accurate for two reason: (a) It assumes the "brute faithfuness" assumption, which is weaker than faithfulness, and (b) it uses a different traversal of permutations than the depth first traversal used by GSP, obtained by taking each variable in turn and moving it to the position in the permutation that optimizes the model score. Results are given comparing BOSS to several related papers in the literature in terms of performance, for linear, Gaussian data. In all cases, with the proper parameter settings, accuracy of BOSS is lifted considerably with respect to competing approaches. In configurations tested, models with 60 variables are feasible with large samples out to about an average degree of 12 in reasonable time, with near-perfect accuracy, and sparse models with an average degree of 4 are feasible out to about 300 variables on a laptop, again with near-perfect accuracy. Mixed continuous discrete and all-discrete datasets were also tested. The mixed data analysis showed advantage for BOSS over GES more apparent at higher depths with the same score; the discrete data analysis showed a very small advantage for BOSS over GES with the same score, perhaps not enough to prefer it.
TimeLens: Event-based Video Frame Interpolation
Jun 14, 2021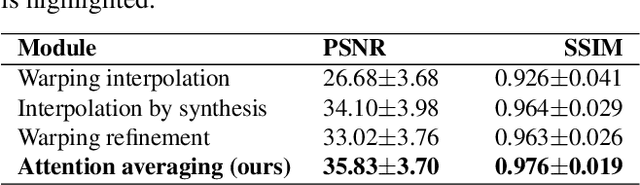
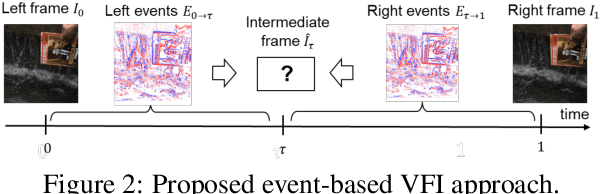
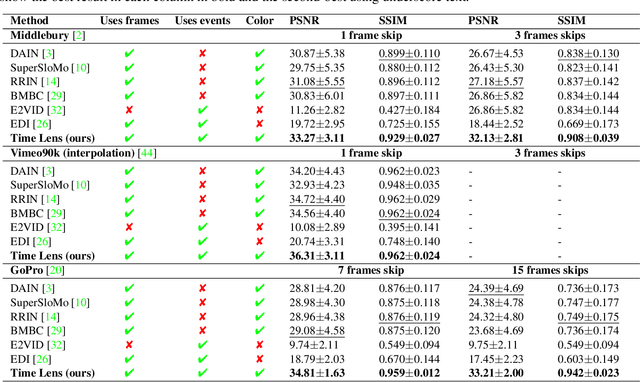
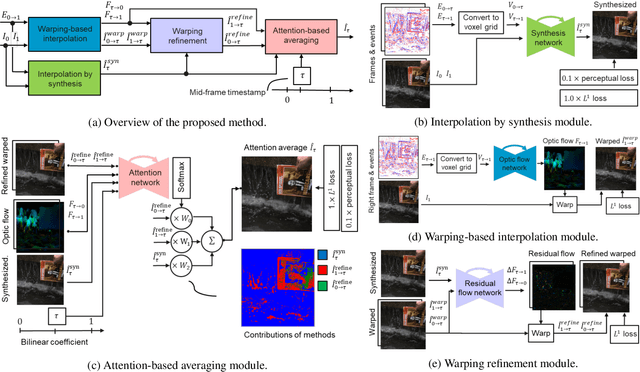
State-of-the-art frame interpolation methods generate intermediate frames by inferring object motions in the image from consecutive key-frames. In the absence of additional information, first-order approximations, i.e. optical flow, must be used, but this choice restricts the types of motions that can be modeled, leading to errors in highly dynamic scenarios. Event cameras are novel sensors that address this limitation by providing auxiliary visual information in the blind-time between frames. They asynchronously measure per-pixel brightness changes and do this with high temporal resolution and low latency. Event-based frame interpolation methods typically adopt a synthesis-based approach, where predicted frame residuals are directly applied to the key-frames. However, while these approaches can capture non-linear motions they suffer from ghosting and perform poorly in low-texture regions with few events. Thus, synthesis-based and flow-based approaches are complementary. In this work, we introduce Time Lens, a novel indicates equal contribution method that leverages the advantages of both. We extensively evaluate our method on three synthetic and two real benchmarks where we show an up to 5.21 dB improvement in terms of PSNR over state-of-the-art frame-based and event-based methods. Finally, we release a new large-scale dataset in highly dynamic scenarios, aimed at pushing the limits of existing methods.
NeoUNet: Towards accurate colon polyp segmentation and neoplasm detection
Jul 11, 2021
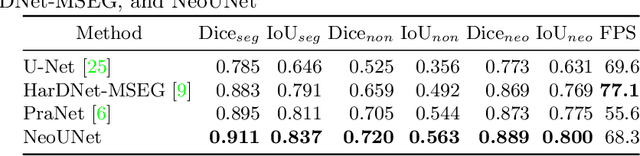
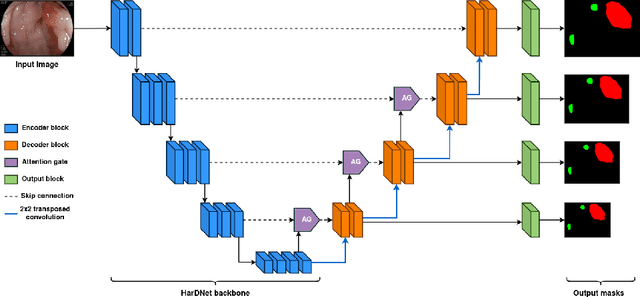

Automatic polyp segmentation has proven to be immensely helpful for endoscopy procedures, reducing the missing rate of adenoma detection for endoscopists while increasing efficiency. However, classifying a polyp as being neoplasm or not and segmenting it at the pixel level is still a challenging task for doctors to perform in a limited time. In this work, we propose a fine-grained formulation for the polyp segmentation problem. Our formulation aims to not only segment polyp regions, but also identify those at high risk of malignancy with high accuracy. In addition, we present a UNet-based neural network architecture called NeoUNet, along with a hybrid loss function to solve this problem. Experiments show highly competitive results for NeoUNet on our benchmark dataset compared to existing polyp segmentation models.
Dynamic Event Camera Calibration
Jul 28, 2021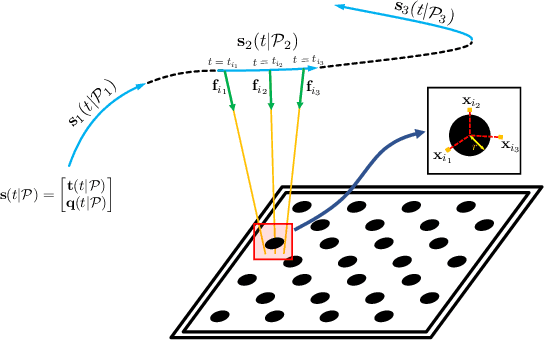
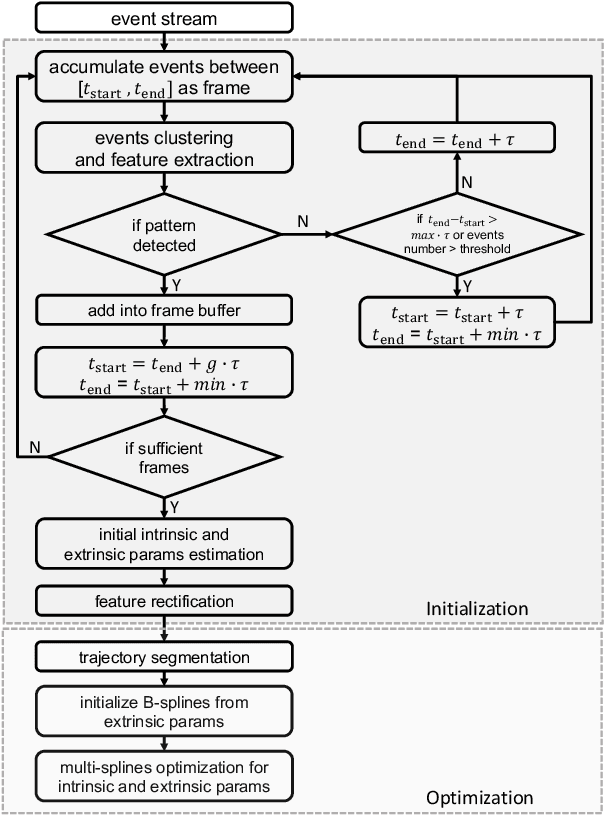


Camera calibration is an important prerequisite towards the solution of 3D computer vision problems. Traditional methods rely on static images of a calibration pattern. This raises interesting challenges towards the practical usage of event cameras, which notably require image change to produce sufficient measurements. The current standard for event camera calibration therefore consists of using flashing patterns. They have the advantage of simultaneously triggering events in all reprojected pattern feature locations, but it is difficult to construct or use such patterns in the field. We present the first dynamic event camera calibration algorithm. It calibrates directly from events captured during relative motion between camera and calibration pattern. The method is propelled by a novel feature extraction mechanism for calibration patterns, and leverages existing calibration tools before optimizing all parameters through a multi-segment continuous-time formulation. As demonstrated through our results on real data, the obtained calibration method is highly convenient and reliably calibrates from data sequences spanning less than 10 seconds.