 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Can You Learn an Algorithm? Generalizing from Easy to Hard Problems with Recurrent Networks
Jun 08, 2021


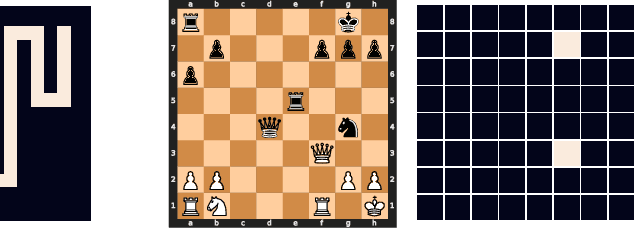

Deep neural networks are powerful machines for visual pattern recognition, but reasoning tasks that are easy for humans may still be difficult for neural models. Humans possess the ability to extrapolate reasoning strategies learned on simple problems to solve harder examples, often by thinking for longer. For example, a person who has learned to solve small mazes can easily extend the very same search techniques to solve much larger mazes by spending more time. In computers, this behavior is often achieved through the use of algorithms, which scale to arbitrarily hard problem instances at the cost of more computation. In contrast, the sequential computing budget of feed-forward neural networks is limited by their depth, and networks trained on simple problems have no way of extending their reasoning to accommodate harder problems. In this work, we show that recurrent networks trained to solve simple problems with few recurrent steps can indeed solve much more complex problems simply by performing additional recurrences during inference. We demonstrate this algorithmic behavior of recurrent networks on prefix sum computation, mazes, and chess. In all three domains, networks trained on simple problem instances are able to extend their reasoning abilities at test time simply by "thinking for longer."
Task-Specific Normalization for Continual Learning of Blind Image Quality Models
Jul 28, 2021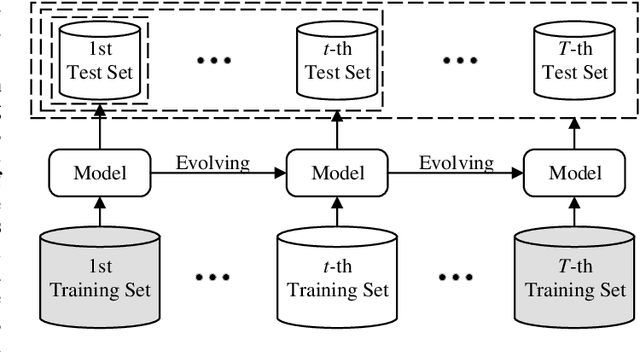
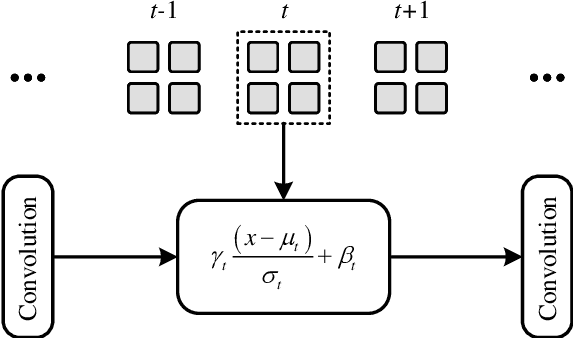
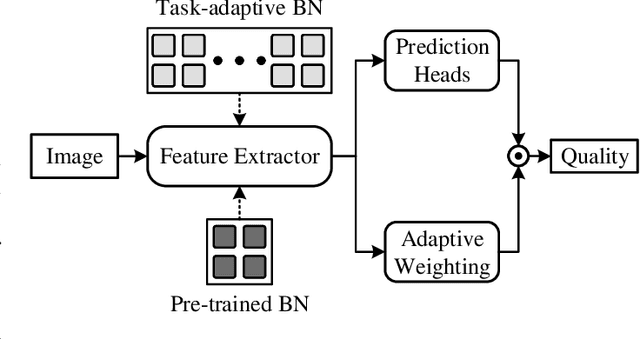
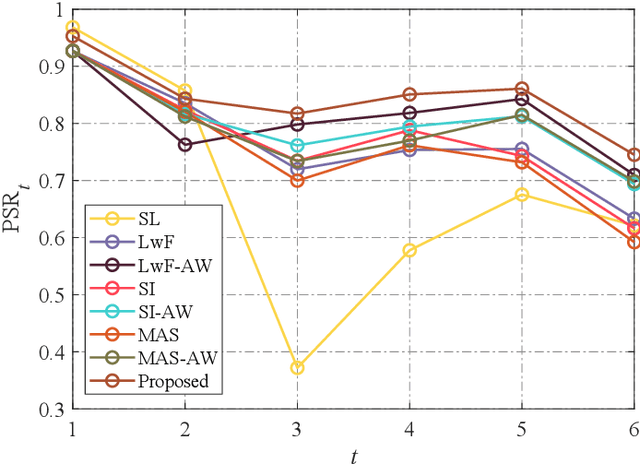
The computational vision community has recently paid attention to continual learning for blind image quality assessment (BIQA). The primary challenge is to combat catastrophic forgetting of previously-seen IQA datasets (i.e., tasks). In this paper, we present a simple yet effective continual learning method for BIQA with improved quality prediction accuracy, plasticity-stability trade-off, and task-order/length robustness. The key step in our approach is to freeze all convolution filters of a pre-trained deep neural network (DNN) for an explicit promise of stability, and learn task-specific normalization parameters for plasticity. We assign each new task a prediction head, and load the corresponding normalization parameters to produce a quality score. The final quality estimate is computed by feature fusion and adaptive weighting using hierarchical representations, without leveraging the test-time oracle. Extensive experiments on six IQA datasets demonstrate the advantages of the proposed method in comparison to previous training techniques for BIQA.
Temporal-Spatial Feature Pyramid for Video Saliency Detection
May 10, 2021
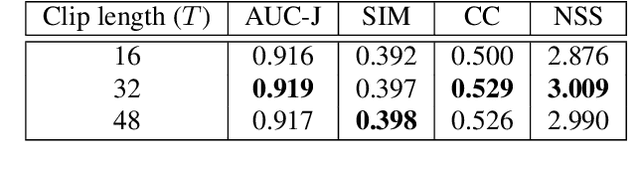
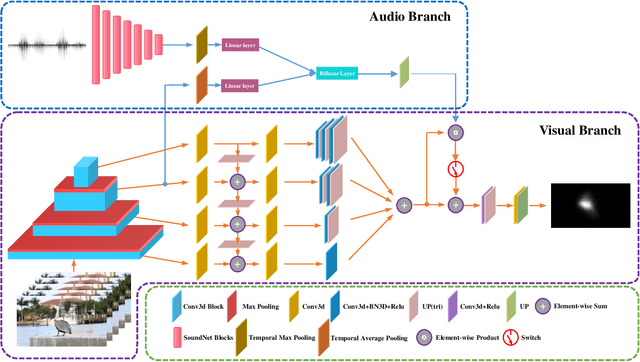
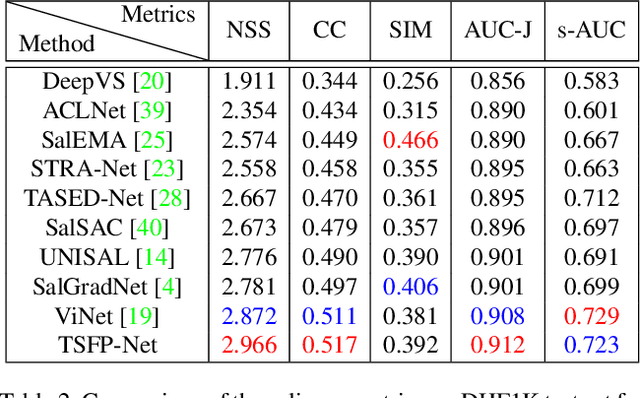
In this paper, we propose a 3D fully convolutional encoder-decoder architecture for video saliency detection, which combines scale, space and time information for video saliency modeling. The encoder extracts multi-scale temporal-spatial features from the input continuous video frames, and then constructs temporal-spatial feature pyramid through temporal-spatial convolution and top-down feature integration. The decoder performs hierarchical decoding of temporal-spatial features from different scales, and finally produces a saliency map from the integration of multiple video frames. Our model is simple yet effective, and can run in real time. We perform abundant experiments, and the results indicate that the well-designed structure can improve the precision of video saliency detection significantly. Experimental results on three purely visual video saliency benchmarks and six audio-video saliency benchmarks demonstrate that our method achieves state-of-theart performance.
A Computer Vision-Based Approach for Driver Distraction Recognition using Deep Learning and Genetic Algorithm Based Ensemble
Jul 28, 2021
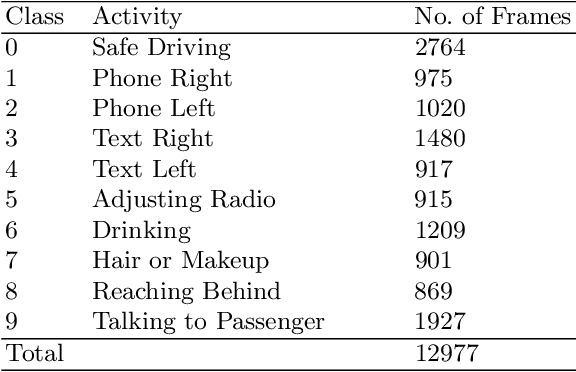
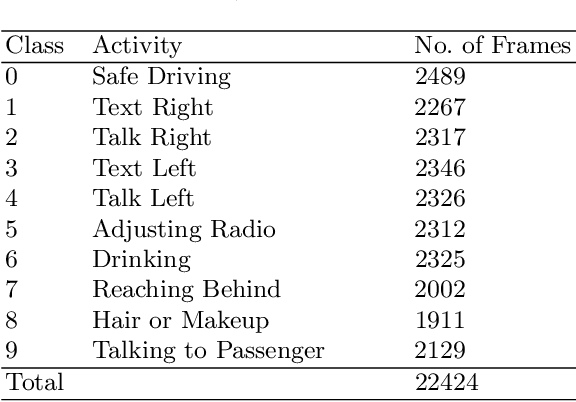
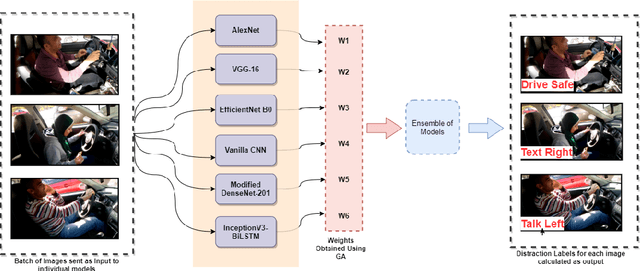
As the proportion of road accidents increases each year, driver distraction continues to be an important risk component in road traffic injuries and deaths. The distractions caused by the increasing use of mobile phones and other wireless devices pose a potential risk to road safety. Our current study aims to aid the already existing techniques in driver posture recognition by improving the performance in the driver distraction classification problem. We present an approach using a genetic algorithm-based ensemble of six independent deep neural architectures, namely, AlexNet, VGG-16, EfficientNet B0, Vanilla CNN, Modified DenseNet, and InceptionV3 + BiLSTM. We test it on two comprehensive datasets, the AUC Distracted Driver Dataset, on which our technique achieves an accuracy of 96.37%, surpassing the previously obtained 95.98%, and on the State Farm Driver Distraction Dataset, on which we attain an accuracy of 99.75%. The 6-Model Ensemble gave an inference time of 0.024 seconds as measured on our machine with Ubuntu 20.04(64-bit) and GPU as GeForce GTX 1080.
Joint estimation of multiple Granger causal networks: Inference of group-level brain connectivity
May 15, 2021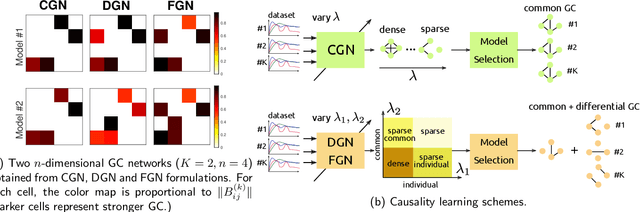
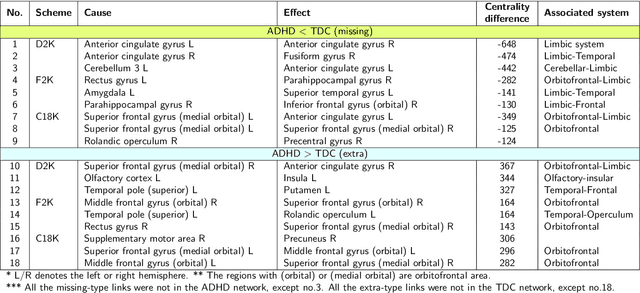
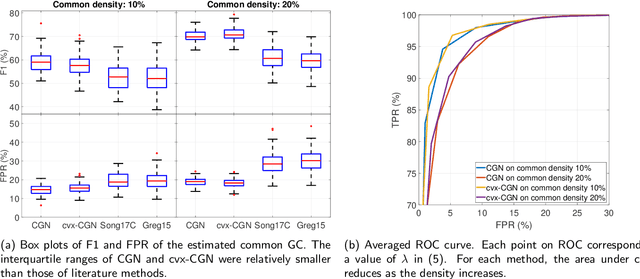
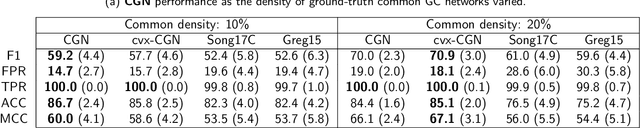
This paper considers joint learning of multiple sparse Granger graphical models to discover underlying common and differential Granger causality (GC) structures across multiple time series. This can be applied to drawing group-level brain connectivity inferences from a homogeneous group of subjects or discovering network differences among groups of signals collected under heterogeneous conditions. By recognizing that the GC of a single multivariate time series can be characterized by common zeros of vector autoregressive (VAR) lag coefficients, a group sparse prior is included in joint regularized least-squares estimations of multiple VAR models. Group-norm regularizations based on group- and fused-lasso penalties encourage a decomposition of multiple networks into a common GC structure, with other remaining parts defined in individual-specific networks. Prior information about sparseness and sparsity patterns of desired GC networks are incorporated as relative weights, while a non-convex group norm in the penalty is proposed to enhance the accuracy of network estimation in low-sample settings. Extensive numerical results on simulations illustrated our method's improvements over existing sparse estimation approaches on GC network sparsity recovery. Our methods were also applied to available resting-state fMRI time series from the ADHD-200 data sets to learn the differences of causality mechanisms, called effective brain connectivity, between adolescents with ADHD and typically developing children. Our analysis revealed that parts of the causality differences between the two groups often resided in the orbitofrontal region and areas associated with the limbic system, which agreed with clinical findings and data-driven results in previous studies.
Exploration and preference satisfaction trade-off in reward-free learning
Jun 08, 2021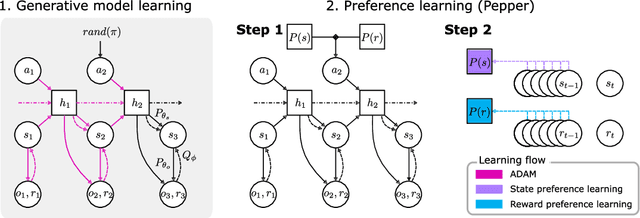

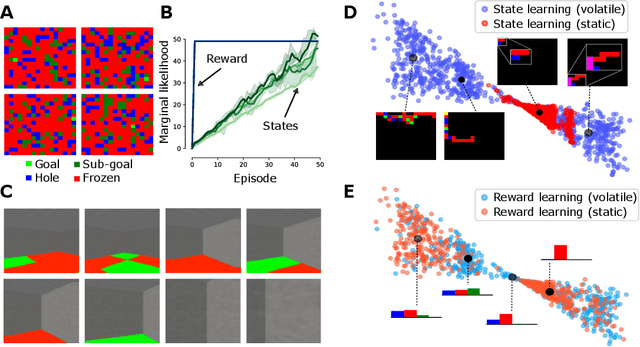

Biological agents have meaningful interactions with their environment despite the absence of a reward signal. In such instances, the agent can learn preferred modes of behaviour that lead to predictable states -- necessary for survival. In this paper, we pursue the notion that this learnt behaviour can be a consequence of reward-free preference learning that ensures an appropriate trade-off between exploration and preference satisfaction. For this, we introduce a model-based Bayesian agent equipped with a preference learning mechanism (pepper) using conjugate priors. These conjugate priors are used to augment the expected free energy planner for learning preferences over states (or outcomes) across time. Importantly, our approach enables the agent to learn preferences that encourage adaptive behaviour at test time. We illustrate this in the OpenAI Gym FrozenLake and the 3D mini-world environments -- with and without volatility. Given a constant environment, these agents learn confident (i.e., precise) preferences and act to satisfy them. Conversely, in a volatile setting, perpetual preference uncertainty maintains exploratory behaviour. Our experiments suggest that learnable (reward-free) preferences entail a trade-off between exploration and preference satisfaction. Pepper offers a straightforward framework suitable for designing adaptive agents when reward functions cannot be predefined as in real environments.
Continuous Prediction of Lower-Limb Kinematics From Multi-Modal Biomedical Signals
Mar 22, 2021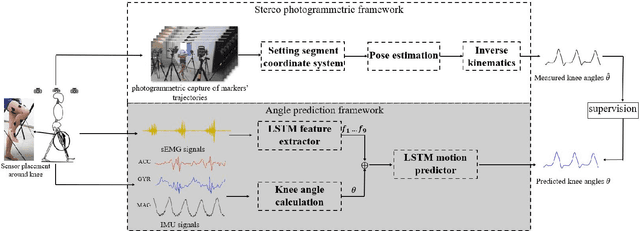
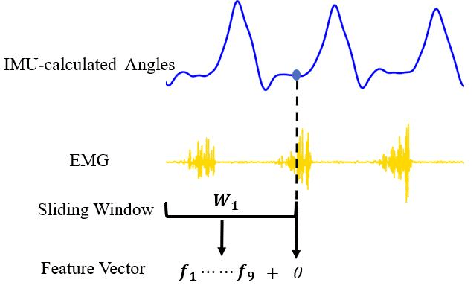
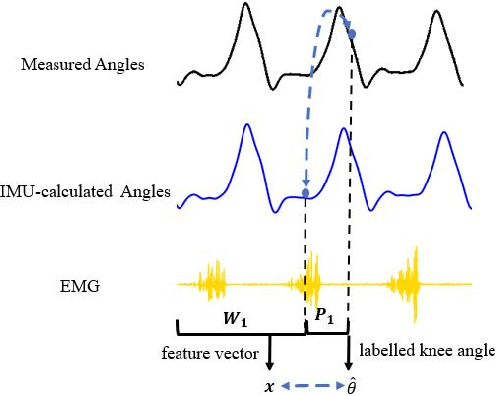
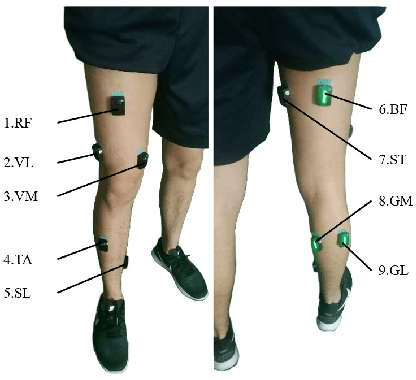
The fast-growing techniques of measuring and fusing multi-modal biomedical signals enable advanced motor intent decoding schemes of lowerlimb exoskeletons, meeting the increasing demand for rehabilitative or assistive applications of take-home healthcare. Challenges of exoskeletons motor intent decoding schemes remain in making a continuous prediction to compensate for the hysteretic response caused by mechanical transmission. In this paper, we solve this problem by proposing an ahead of time continuous prediction of lower limb kinematics, with the prediction of knee angles during level walking as a case study. Firstly, an end-to-end kinematics prediction network(KinPreNet), consisting of a feature extractor and an angle predictor, is proposed and experimentally compared with features and methods traditionally used in ahead-of-time prediction of gait phases. Secondly, inspired by the electromechanical delay(EMD), we further explore our algorithm's capability of compensating response delay of mechanical transmission by validating the performance of the different sections of prediction time. And we experimentally reveal the time boundary of compensating the hysteretic response. Thirdly, a comparison of employing EMG signals or not is performed to reveal the EMG and kinematic signals collaborated contributions to the continuous prediction. During the experiments, EMG signals of nine muscles and knee angles calculated from inertial measurement unit (IMU) signals are recorded from ten healthy subjects. To the best of our knowledge, this is the first study of continuously predicting lower-limb kinematics in an ahead-of-time manner based on the electromechanical delay (EMD).
The Application of Active Query K-Means in Text Classification
Jul 16, 2021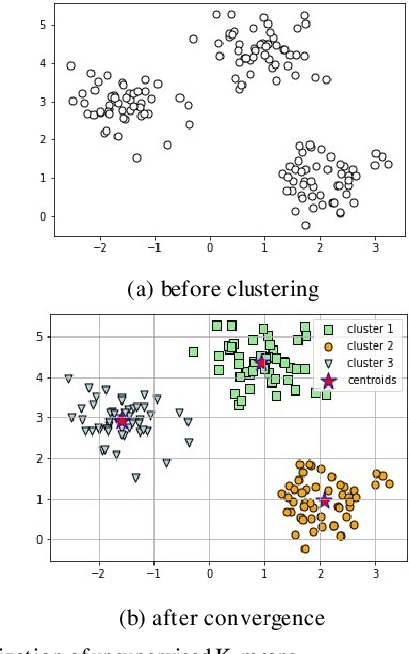
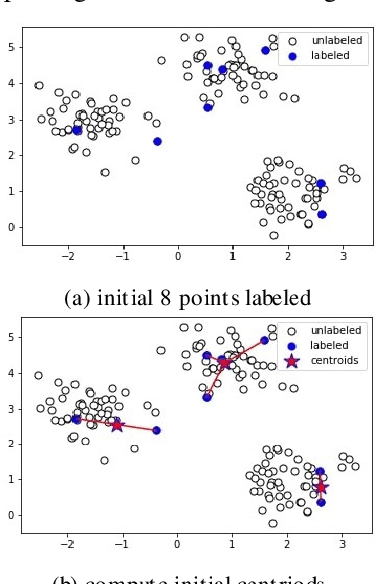
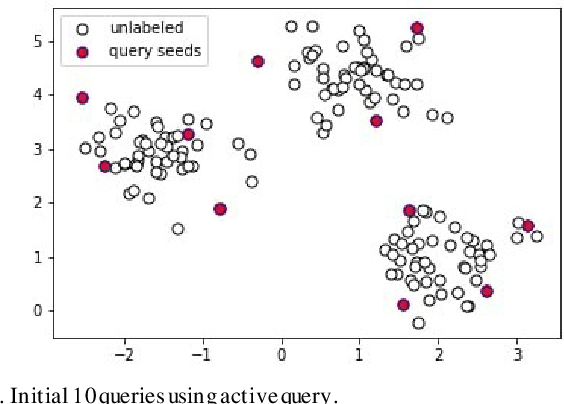

Active learning is a state-of-art machine learning approach to deal with an abundance of unlabeled data. In the field of Natural Language Processing, typically it is costly and time-consuming to have all the data annotated. This inefficiency inspires out our application of active learning in text classification. Traditional unsupervised k-means clustering is first modified into a semi-supervised version in this research. Then, a novel attempt is applied to further extend the algorithm into active learning scenario with Penalized Min-Max-selection, so as to make limited queries that yield more stable initial centroids. This method utilizes both the interactive query results from users and the underlying distance representation. After tested on a Chinese news dataset, it shows a consistent increase in accuracy while lowering the cost in training.
* 6 pages, 3 algorithms, 4 tables, 8 figures For source code and questions, please email Yukun Jiang at jy2363@nyu.edu Reply would follow shortly
Come back when you are charged! Self-Organized Charging for Electric Vehicles
Jun 08, 2021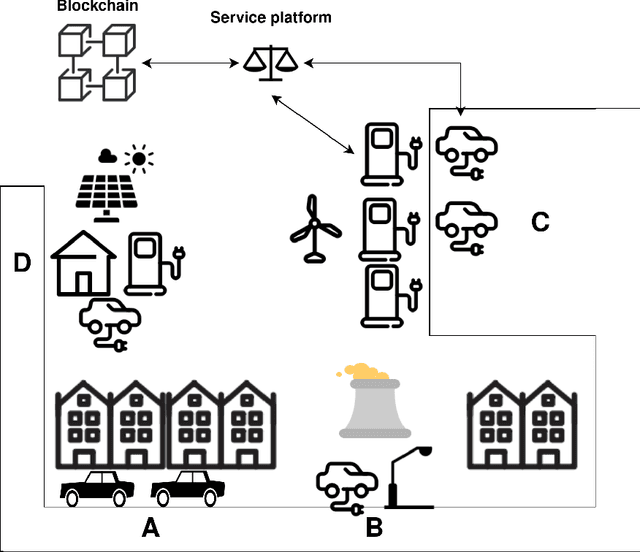
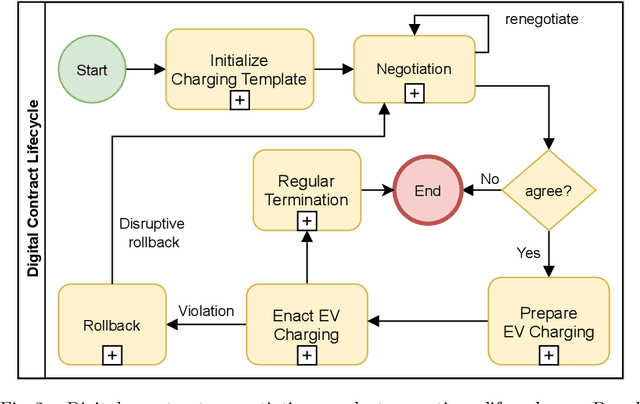
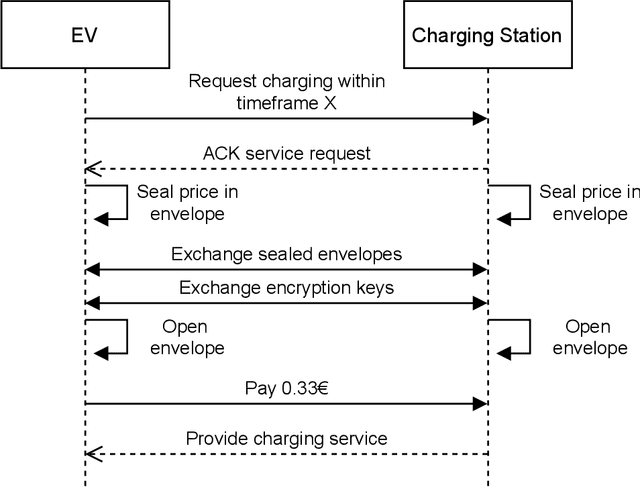
Dwindling nonrenewable fuel reserves, progressing severe environmental pollution, and accelerating climate change require society to reevaluate existing transportation concepts. While electric vehicles (EVs) have become more popular and slowly gain widespread adoption, the corresponding battery charging infrastructures still limits EVs' use in our everyday life. This is especially true for EV owners that do not have the option to operate charging hardware, such as wall boxes, at their premises. Charging an EV without an at-home wall box is time-consuming since the owner has to drive to the charger, charge the vehicle while waiting nearby, and finally drive back home. Thus, a convenient and easy-to-use solution is required to overcome the issue and incentivize EVs for daily commuters. Therefore, we propose an ecosystem and a service platform for (semi-)autonomous electric vehicles that allow them to utilize their "free"-time, e.g., at night, to access public and private charging infrastructure, charge their batteries, and get back home before the owner needs the car again. To do so, we utilize the concept of the Machine-to-Everything Economy (M2X Economy) and outline a decentralized ecosystem for smart machines that transact, interact and collaborate via blockchain-based smart contracts to enable a convenient battery charging marketplace for (semi-)autonomous EVs.
MLDemon: Deployment Monitoring for Machine Learning Systems
May 05, 2021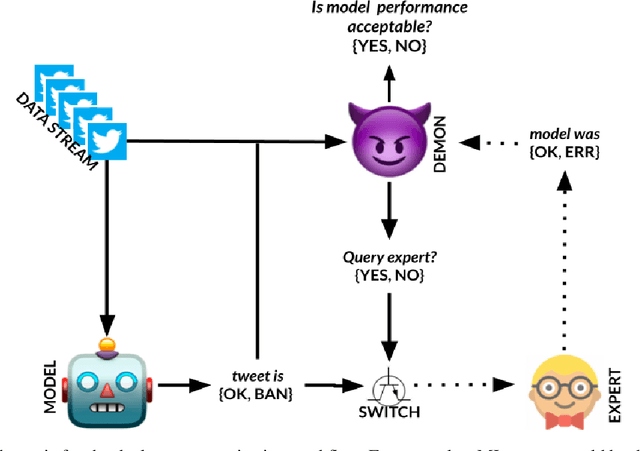
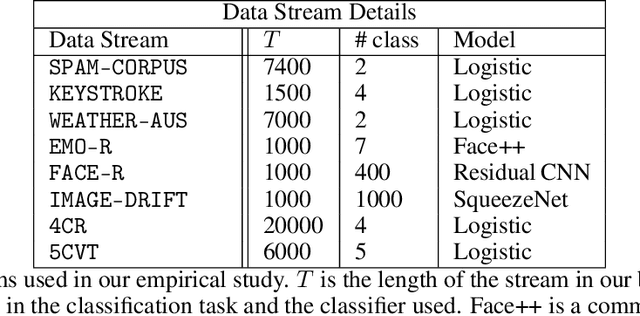
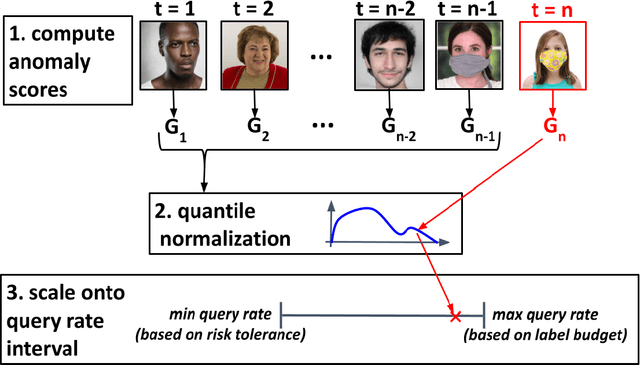
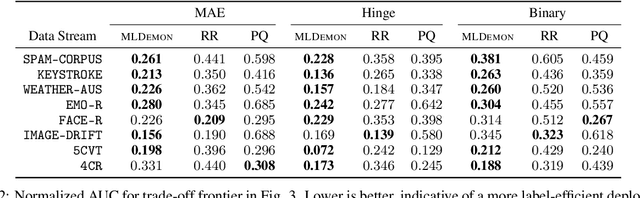
Post-deployment monitoring of the performance of ML systems is critical for ensuring reliability, especially as new user inputs can differ from the training distribution. Here we propose a novel approach, MLDemon, for ML DEployment MONitoring. MLDemon integrates both unlabeled features and a small amount of on-demand labeled examples over time to produce a real-time estimate of the ML model's current performance on a given data stream. Subject to budget constraints, MLDemon decides when to acquire additional, potentially costly, supervised labels to verify the model. On temporal datasets with diverse distribution drifts and models, MLDemon substantially outperforms existing monitoring approaches. Moreover, we provide theoretical analysis to show that MLDemon is minimax rate optimal up to logarithmic factors and is provably robust against broad distribution drifts whereas prior approaches are not.