 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Airplane Type Identification Based on Mask RCNN and Drone Images
Aug 29, 2021
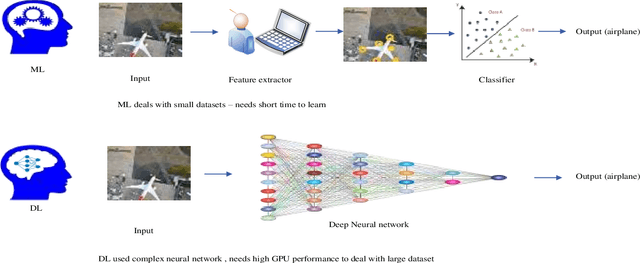
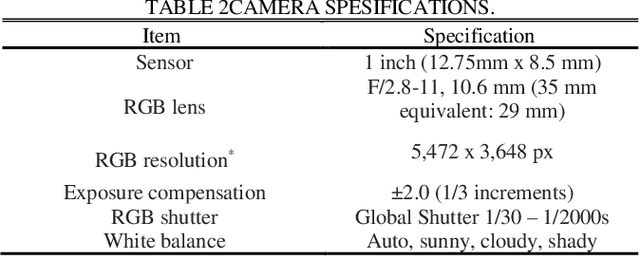
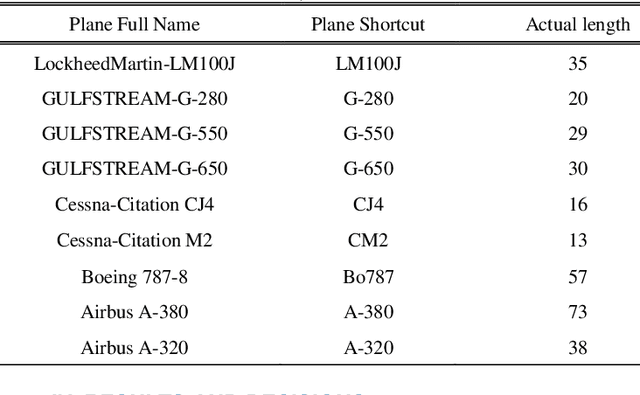
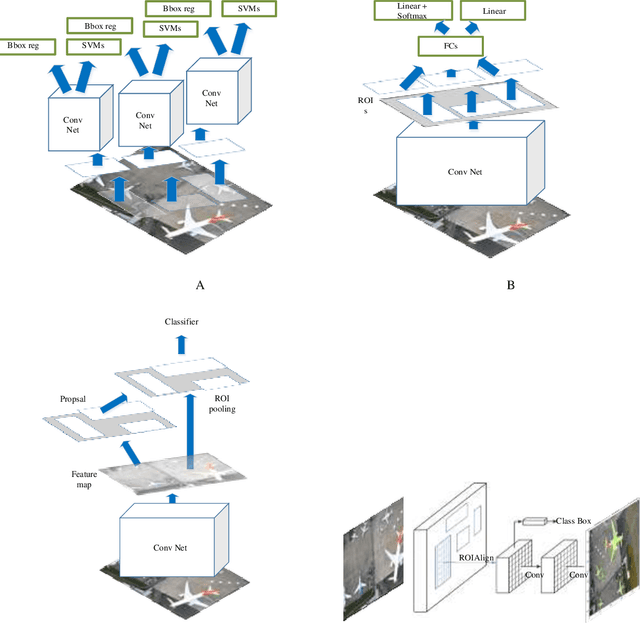
For dealing with traffic bottlenecks at airports, aircraft object detection is insufficient. Every airport generally has a variety of planes with various physical and technological requirements as well as diverse service requirements. Detecting the presence of new planes will not address all traffic congestion issues. Identifying the type of airplane, on the other hand, will entirely fix the problem because it will offer important information about the plane's technical specifications (i.e., the time it needs to be served and its appropriate place in the airport). Several studies have provided various contributions to address airport traffic jams; however, their ultimate goal was to determine the existence of airplane objects. This paper provides a practical approach to identify the type of airplane in airports depending on the results provided by the airplane detection process using mask region convolution neural network. The key feature employed to identify the type of airplane is the surface area calculated based on the results of airplane detection. The surface area is used to assess the estimated cabin length which is considered as an additional key feature for identifying the airplane type. The length of any detected plane may be calculated by measuring the distance between the detected plane's two furthest points. The suggested approach's performance is assessed using average accuracies and a confusion matrix. The findings show that this method is dependable. This method will greatly aid in the management of airport traffic congestion.
Modeling Performance and Energy trade-offs in Online Data-Intensive Applications
Aug 18, 2021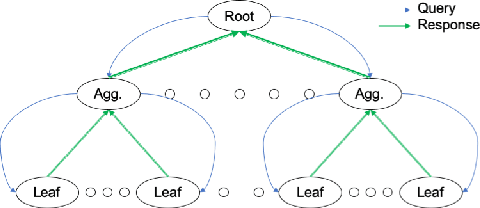
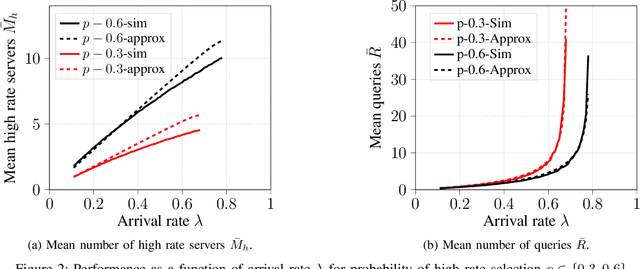
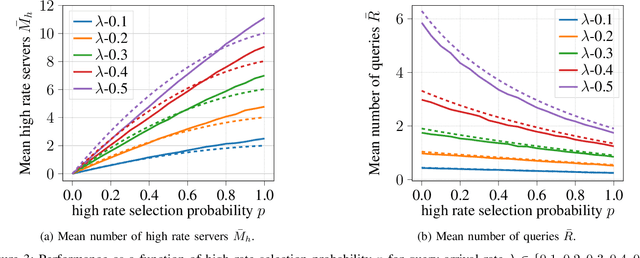
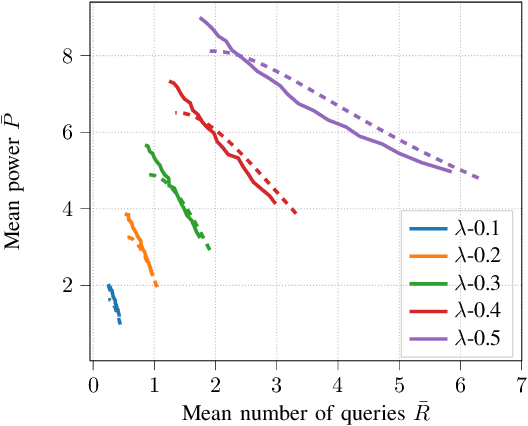
We consider energy minimization for data-intensive applications run on large number of servers, for given performance guarantees. We consider a system, where each incoming application is sent to a set of servers, and is considered to be completed if a subset of them finish serving it. We consider a simple case when each server core has two speed levels, where the higher speed can be achieved by higher power for each core independently. The core selects one of the two speeds probabilistically for each incoming application request. We model arrival of application requests by a Poisson process, and random service time at the server with independent exponential random variables. Our model and analysis generalizes to today's state-of-the-art in CPU energy management where each core can independently select a speed level from a set of supported speeds and corresponding voltages. The performance metrics under consideration are the mean number of applications in the system and the average energy expenditure. We first provide a tight approximation to study this previously intractable problem and derive closed form approximate expressions for the performance metrics when service times are exponentially distributed. Next, we study the trade-off between the approximate mean number of applications and energy expenditure in terms of the switching probability.
Unsupervised Depth Completion with Calibrated Backprojection Layers
Aug 24, 2021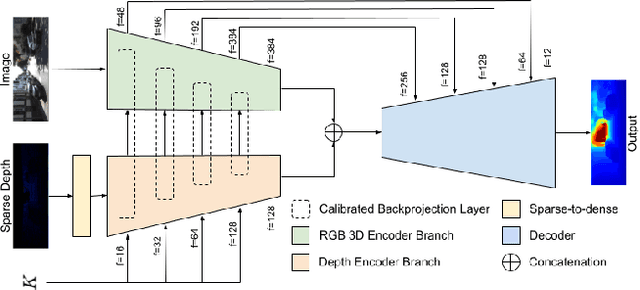

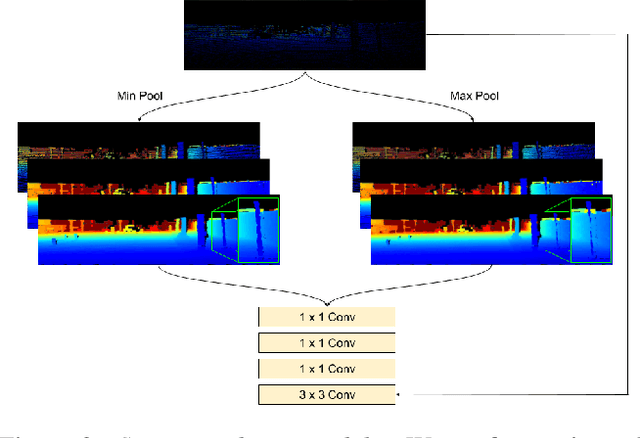
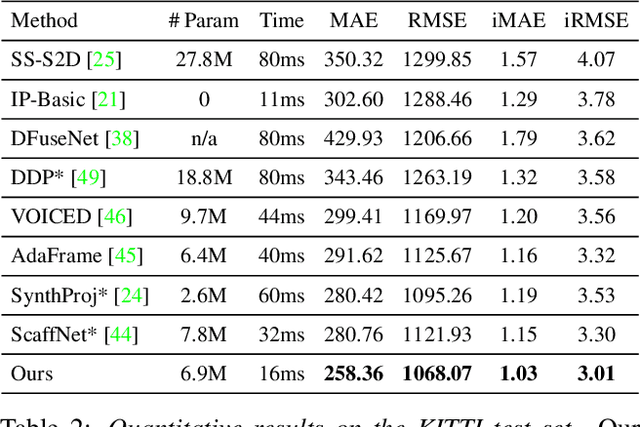
We propose a deep neural network architecture to infer dense depth from an image and a sparse point cloud. It is trained using a video stream and corresponding synchronized sparse point cloud, as obtained from a LIDAR or other range sensor, along with the intrinsic calibration parameters of the camera. At inference time, the calibration of the camera, which can be different than the one used for training, is fed as an input to the network along with the sparse point cloud and a single image. A Calibrated Backprojection Layer backprojects each pixel in the image to three-dimensional space using the calibration matrix and a depth feature descriptor. The resulting 3D positional encoding is concatenated with the image descriptor and the previous layer output to yield the input to the next layer of the encoder. A decoder, exploiting skip-connections, produces a dense depth map. The resulting Calibrated Backprojection Network, or KBNet, is trained without supervision by minimizing the photometric reprojection error. KBNet imputes missing depth value based on the training set, rather than on generic regularization. We test KBNet on public depth completion benchmarks, where it outperforms the state of the art by 30% indoor and 8% outdoor when the same camera is used for training and testing. When the test camera is different, the improvement reaches 62%. Code available at: https://github.com/alexklwong/calibrated-backprojection-network.
Hierarchical RNNs-Based Transformers MADDPG for Mixed Cooperative-Competitive Environments
May 11, 2021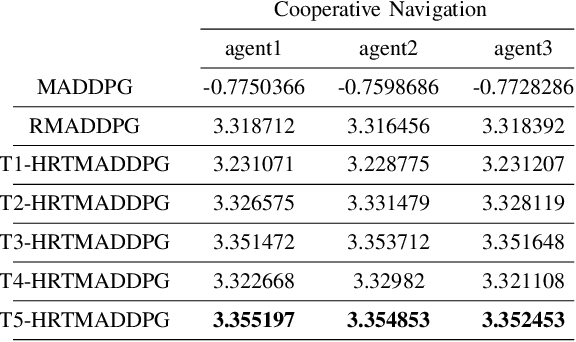
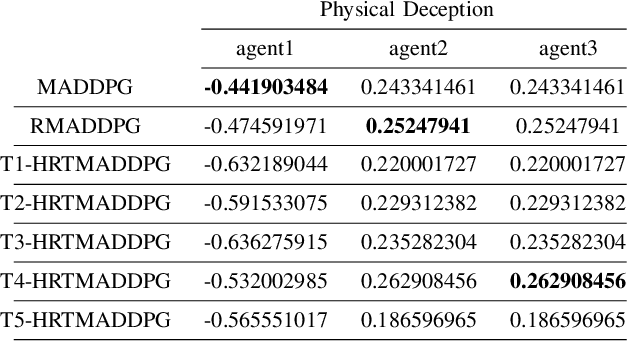
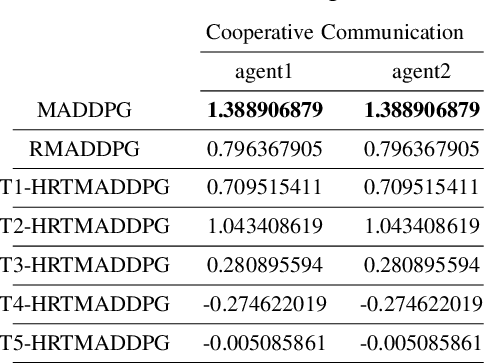
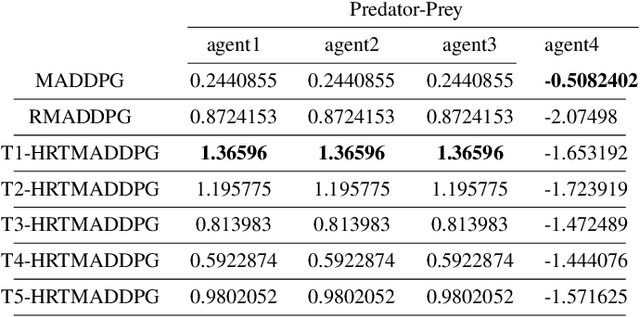
At present, attention mechanism has been widely applied to the fields of deep learning models. Structural models that based on attention mechanism can not only record the relationships between features position, but also can measure the importance of different features based on their weights. By establishing dynamically weighted parameters for choosing relevant and irrelevant features, the key information can be strengthened, and the irrelevant information can be weakened. Therefore, the efficiency of deep learning algorithms can be significantly elevated and improved. Although transformers have been performed very well in many fields including reinforcement learning, there are still many problems and applications can be solved and made with transformers within this area. MARL (known as Multi-Agent Reinforcement Learning) can be recognized as a set of independent agents trying to adapt and learn through their way to reach the goal. In order to emphasize the relationship between each MDP decision in a certain time period, we applied the hierarchical coding method and validated the effectiveness of this method. This paper proposed a hierarchical transformers MADDPG based on RNN which we call it Hierarchical RNNs-Based Transformers MADDPG(HRTMADDPG). It consists of a lower level encoder based on RNNs that encodes multiple step sizes in each time sequence, and it also consists of an upper sequence level encoder based on transformer for learning the correlations between multiple sequences so that we can capture the causal relationship between sub-time sequences and make HRTMADDPG more efficient.
Oriented R-CNN for Object Detection
Aug 12, 2021
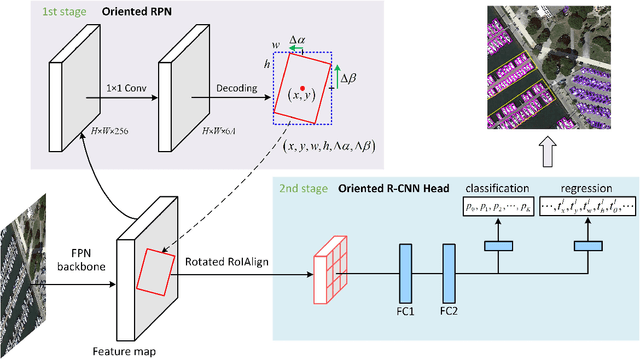
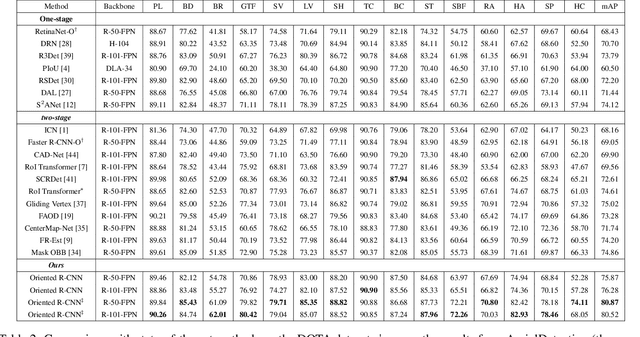
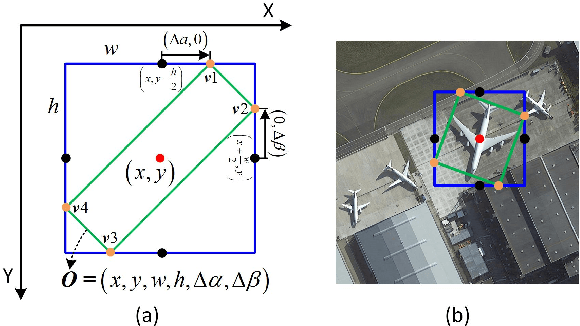
Current state-of-the-art two-stage detectors generate oriented proposals through time-consuming schemes. This diminishes the detectors' speed, thereby becoming the computational bottleneck in advanced oriented object detection systems. This work proposes an effective and simple oriented object detection framework, termed Oriented R-CNN, which is a general two-stage oriented detector with promising accuracy and efficiency. To be specific, in the first stage, we propose an oriented Region Proposal Network (oriented RPN) that directly generates high-quality oriented proposals in a nearly cost-free manner. The second stage is oriented R-CNN head for refining oriented Regions of Interest (oriented RoIs) and recognizing them. Without tricks, oriented R-CNN with ResNet50 achieves state-of-the-art detection accuracy on two commonly-used datasets for oriented object detection including DOTA (75.87% mAP) and HRSC2016 (96.50% mAP), while having a speed of 15.1 FPS with the image size of 1024$\times$1024 on a single RTX 2080Ti. We hope our work could inspire rethinking the design of oriented detectors and serve as a baseline for oriented object detection. Code is available at https://github.com/jbwang1997/OBBDetection.
Fog Simulation on Real LiDAR Point Clouds for 3D Object Detection in Adverse Weather
Aug 12, 2021
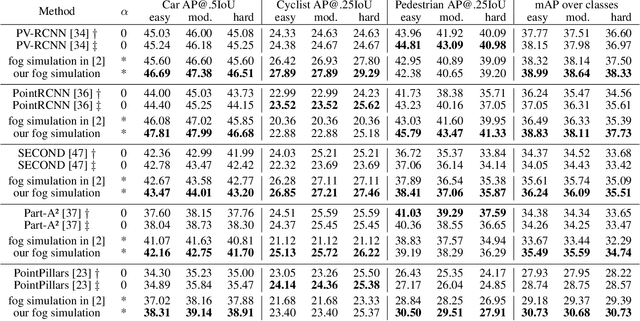

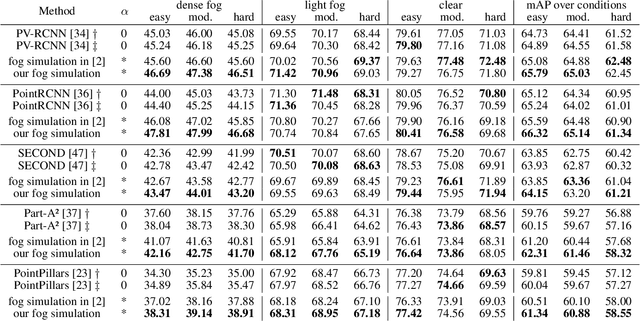
This work addresses the challenging task of LiDAR-based 3D object detection in foggy weather. Collecting and annotating data in such a scenario is very time, labor and cost intensive. In this paper, we tackle this problem by simulating physically accurate fog into clear-weather scenes, so that the abundant existing real datasets captured in clear weather can be repurposed for our task. Our contributions are twofold: 1) We develop a physically valid fog simulation method that is applicable to any LiDAR dataset. This unleashes the acquisition of large-scale foggy training data at no extra cost. These partially synthetic data can be used to improve the robustness of several perception methods, such as 3D object detection and tracking or simultaneous localization and mapping, on real foggy data. 2) Through extensive experiments with several state-of-the-art detection approaches, we show that our fog simulation can be leveraged to significantly improve the performance for 3D object detection in the presence of fog. Thus, we are the first to provide strong 3D object detection baselines on the Seeing Through Fog dataset. Our code is available at www.trace.ethz.ch/lidar_fog_simulation.
Finite-Time Error Bounds For Linear Stochastic Approximation and TD Learning
Feb 06, 2019We consider the dynamics of a linear stochastic approximation algorithm driven by Markovian noise, and derive finite-time bounds on the moments of the error, i.e., deviation of the output of the algorithm from the equilibrium point of an associated ordinary differential equation (ODE). To obtain finite-time bounds on the mean-square error in the case of constant step-size algorithms, our analysis uses Stein's method to identify a Lyapunov function that can potentially yield good steady-state bounds, and uses this Lyapunov function to obtain finite-time bounds by mimicking the corresponding steps in the analysis of the associated ODE. We also provide a comprehensive treatment of the moments of the square of the 2-norm of the approximation error. Our analysis yields the following results: (i) for a given step-size, we show that the lower-order moments can be made small as a function of the step-size and can be upper-bounded by the moments of a Gaussian random variable; (ii) we show that the higher-order moments beyond a threshold may be infinite in steady-state; and (iii) we characterize the number of samples needed for the finite-time bounds to be of the same order as the steady-state bounds. As a by-product of our analysis, we also solve the open problem of obtaining finite-time bounds for the performance of temporal difference learning algorithms with linear function approximation and a constant step-size, without requiring a projection step or an i.i.d. noise assumption.
Study of the impact of climate change on precipitation in Paris area using method based on iterative multiscale dynamic time warping (IMS-DTW)
Oct 22, 2019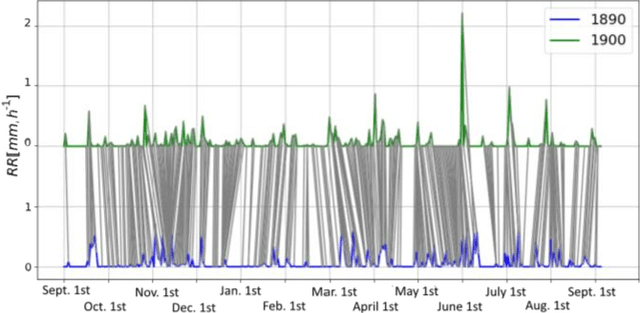
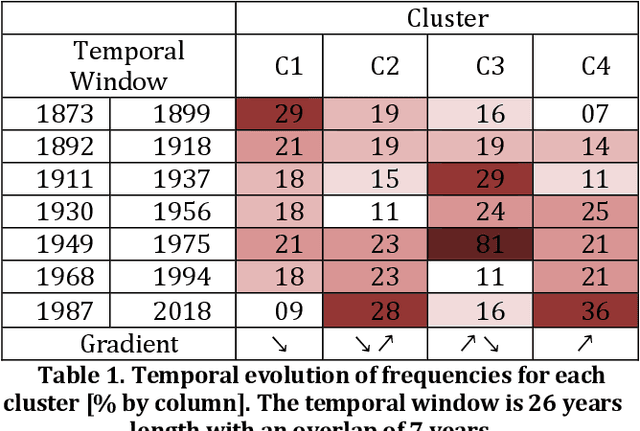
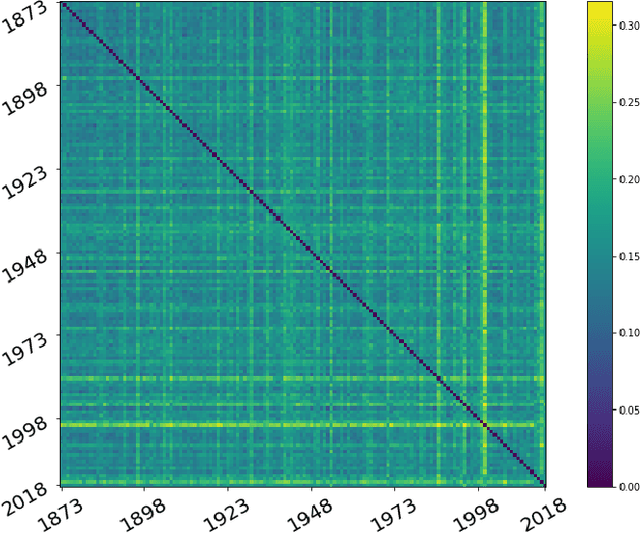
Studying the impact of climate change on precipitation is constrained by finding a way to evaluate the evolution of precipitation variability over time. Classical approaches (feature-based) have shown their limitations for this issue due to the intermittent and irregular nature of precipitation. In this study, we present a novel variant of the Dynamic time warping method quantifying the dissimilarity between two rainfall time series based on shapes comparisons, for clustering annual time series recorded at daily scale. This shape based approach considers the whole information (variability, trends and intermittency). We further labeled each cluster using a feature-based approach. While testing the proposed approach on the time series of Paris Montsouris, we found that the precipitation variability increased over the years in Paris area.
Spectrum Learning-Aided Reconfigurable Intelligent Surfaces for 'Green' 6G Networks
Sep 03, 2021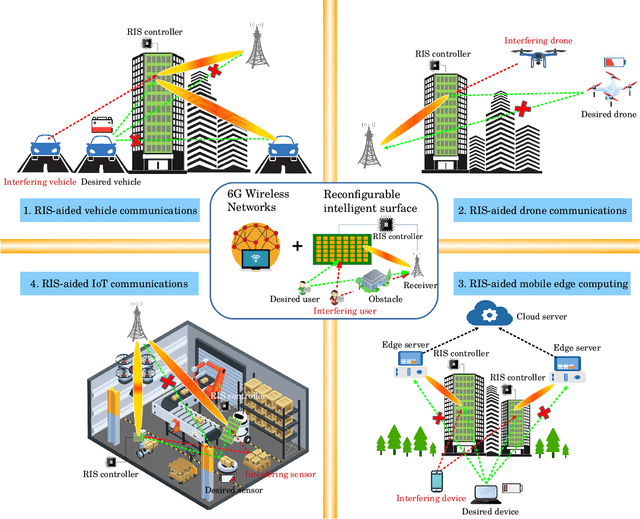
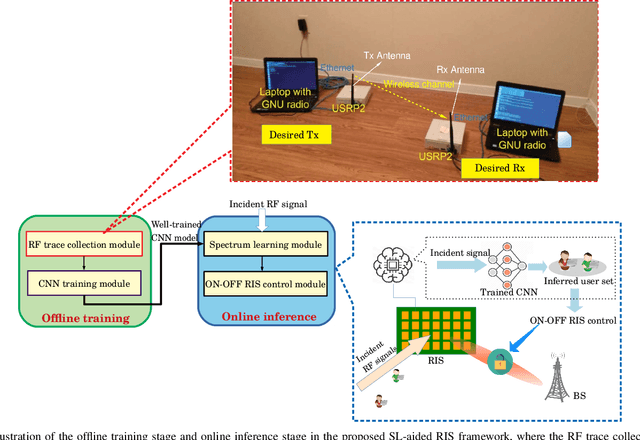
In the sixth-generation (6G) era, emerging large-scale computing based applications (for example processing enormous amounts of images in real-time in autonomous driving) tend to lead to excessive energy consumption for the end users, whose devices are usually energy-constrained. In this context, energy-efficiency becomes a critical challenge to be solved for harnessing these promising applications to realize 'green' 6G networks. As a remedy, reconfigurable intelligent surfaces (RIS) have been proposed for improving the energy efficiency by beneficially reconfiguring the wireless propagation environment. In conventional RIS solutions, however, the received signal-to-interference-plus-noise ratio (SINR) sometimes may even become degraded. This is because the signals impinging upon an RIS are typically contaminated by interfering signals which are usually dynamic and unknown. To address this issue, `learning' the properties of the surrounding spectral environment is a promising solution, motivating the convergence of artificial intelligence and spectrum sensing, termed here as spectrum learning (SL). Inspired by this, we develop an SL-aided RIS framework for intelligently exploiting the inherent characteristics of the radio frequency (RF) spectrum for green 6G networks. Given the proposed framework, the RIS controller becomes capable of intelligently `{think-and-decide}' whether to reflect or not the incident signals. Therefore, the received SINR can be improved by dynamically configuring the binary ON-OFF status of the RIS elements. The energy-efficiency benefits attained are validated with the aid of a specific case study. Finally, we conclude with a list of promising future research directions.
Neural Fixed-Point Acceleration for Convex Optimization
Jul 21, 2021

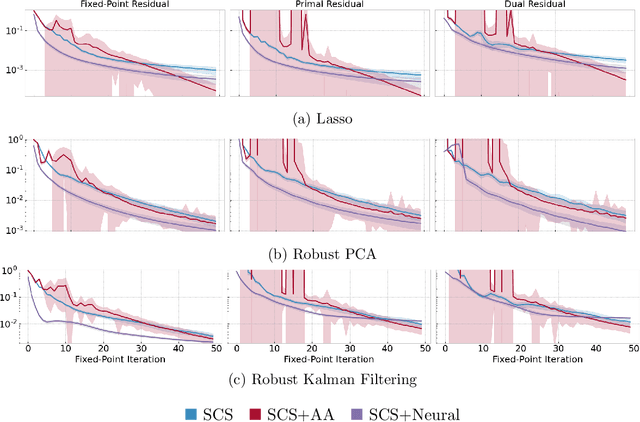

Fixed-point iterations are at the heart of numerical computing and are often a computational bottleneck in real-time applications, which typically instead need a fast solution of moderate accuracy. Classical acceleration methods for fixed-point problems focus on designing algorithms with theoretical guarantees that apply to any fixed-point problem. We present neural fixed-point acceleration, a framework to automatically learn to accelerate convex fixed-point problems that are drawn from a distribution, using ideas from meta-learning and classical acceleration algorithms. We apply our framework to SCS, the state-of-the-art solver for convex cone programming, and design models and loss functions to overcome the challenges of learning over unrolled optimization and acceleration instabilities. Our work brings neural acceleration into any optimization problem expressible with CVXPY. The source code behind this paper is available at https://github.com/facebookresearch/neural-scs