 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
RGB-D Salient Object Detection with Ubiquitous Target Awareness
Sep 08, 2021


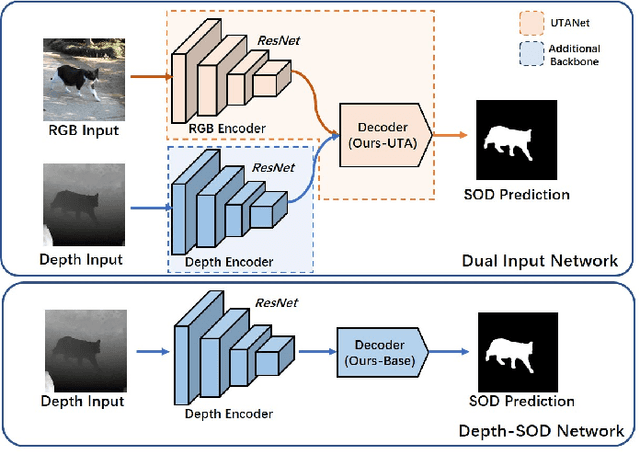

Conventional RGB-D salient object detection methods aim to leverage depth as complementary information to find the salient regions in both modalities. However, the salient object detection results heavily rely on the quality of captured depth data which sometimes are unavailable. In this work, we make the first attempt to solve the RGB-D salient object detection problem with a novel depth-awareness framework. This framework only relies on RGB data in the testing phase, utilizing captured depth data as supervision for representation learning. To construct our framework as well as achieving accurate salient detection results, we propose a Ubiquitous Target Awareness (UTA) network to solve three important challenges in RGB-D SOD task: 1) a depth awareness module to excavate depth information and to mine ambiguous regions via adaptive depth-error weights, 2) a spatial-aware cross-modal interaction and a channel-aware cross-level interaction, exploiting the low-level boundary cues and amplifying high-level salient channels, and 3) a gated multi-scale predictor module to perceive the object saliency in different contextual scales. Besides its high performance, our proposed UTA network is depth-free for inference and runs in real-time with 43 FPS. Experimental evidence demonstrates that our proposed network not only surpasses the state-of-the-art methods on five public RGB-D SOD benchmarks by a large margin, but also verifies its extensibility on five public RGB SOD benchmarks.
Fast Time-optimal Avoidance of Moving Obstacles for High-Speed MAV Flight
Aug 06, 2019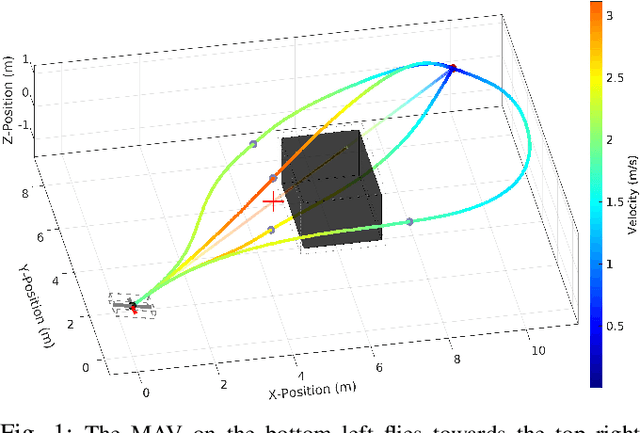
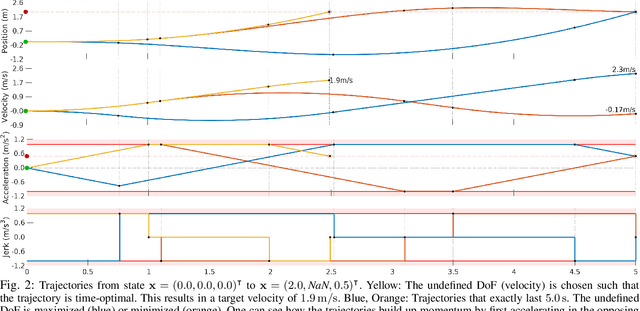
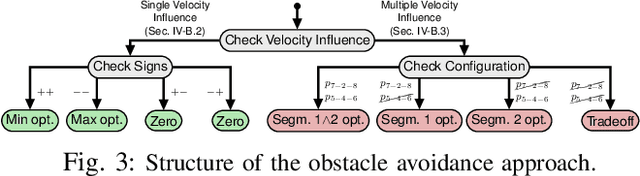
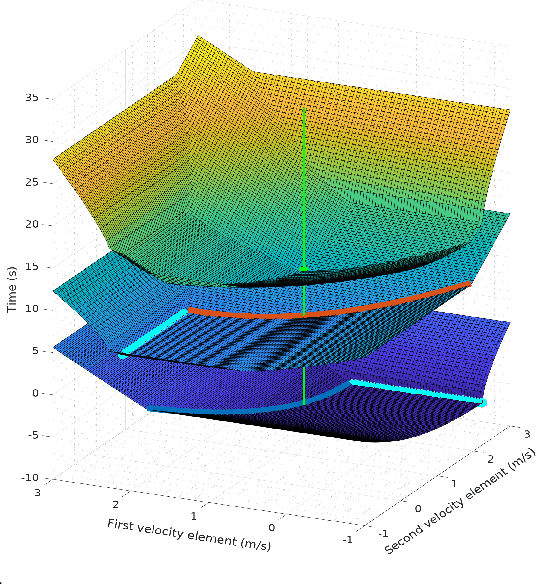
In this work, we propose a method to efficiently compute smooth, time-optimal trajectories for micro aerial vehicles (MAVs) evading a moving obstacle. Our approach first computes an n-dimensional trajectory from the start- to an arbitrary target state including position, velocity and acceleration. It respects input- and state-constraints and is thus dynamically feasible. The trajectory is then efficiently checked for collisions, exploiting the piecewise polynomial formulation. If collisions occur, viastates are inserted into the trajectory to circumvent the obstacle and still maintain time-optimality. These viastates are described by position, velocity, and acceleration. The evaluation shows that the computational demands of the proposed method are minimal such that obstacle avoidance can begin within few milliseconds. Optimality of generated trajectories, combined with the ability for frequent online re-planning from non-hover initial conditions, make the approach well suited for evasion of suddenly perceived obstacles during fast flight.
* For supplementary material and videos, see http://www.ais.uni-bonn.de/videos/IROS_2019_Beul/
Deep Bayesian Unsupervised Lifelong Learning
Jun 13, 2021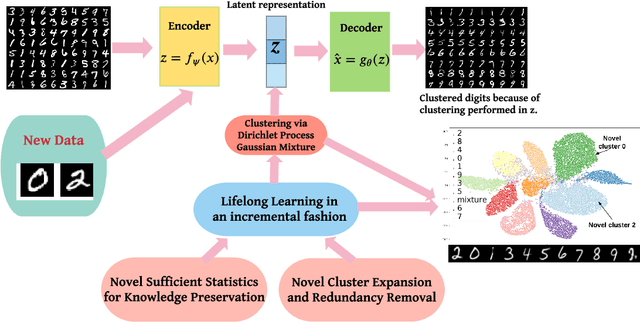

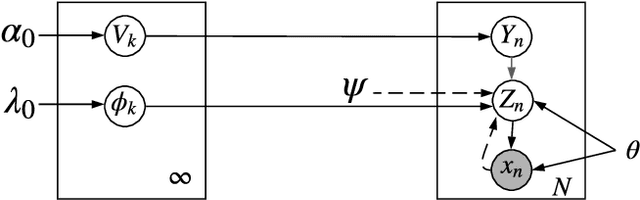
Lifelong Learning (LL) refers to the ability to continually learn and solve new problems with incremental available information over time while retaining previous knowledge. Much attention has been given lately to Supervised Lifelong Learning (SLL) with a stream of labelled data. In contrast, we focus on resolving challenges in Unsupervised Lifelong Learning (ULL) with streaming unlabelled data when the data distribution and the unknown class labels evolve over time. Bayesian framework is natural to incorporate past knowledge and sequentially update the belief with new data. We develop a fully Bayesian inference framework for ULL with a novel end-to-end Deep Bayesian Unsupervised Lifelong Learning (DBULL) algorithm, which can progressively discover new clusters without forgetting the past with unlabelled data while learning latent representations. To efficiently maintain past knowledge, we develop a novel knowledge preservation mechanism via sufficient statistics of the latent representation for raw data. To detect the potential new clusters on the fly, we develop an automatic cluster discovery and redundancy removal strategy in our inference inspired by Nonparametric Bayesian statistics techniques. We demonstrate the effectiveness of our approach using image and text corpora benchmark datasets in both LL and batch settings.
FNAS: Uncertainty-Aware Fast Neural Architecture Search
May 27, 2021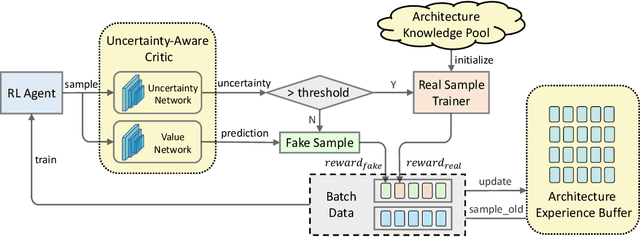
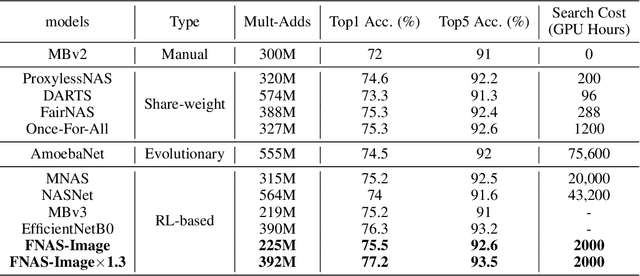
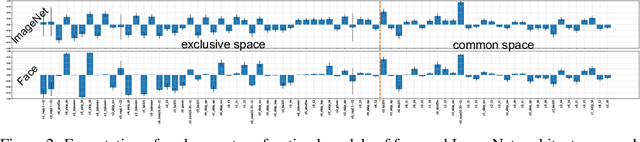
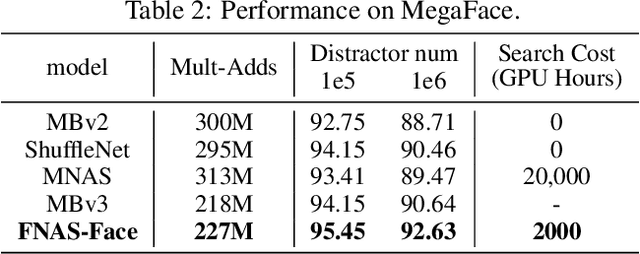
Reinforcement learning (RL)-based neural architecture search (NAS) generally guarantees better convergence yet suffers from the requirement of huge computational resources compared with gradient-based approaches, due to the rollout bottleneck -- exhaustive training for each sampled generation on proxy tasks. In this paper, we propose a general pipeline to accelerate the convergence of the rollout process as well as the RL process in NAS. It is motivated by the interesting observation that both the architecture and the parameter knowledge can be transferred between different experiments and even different tasks. We first introduce an uncertainty-aware critic (value function) in Proximal Policy Optimization (PPO) to utilize the architecture knowledge in previous experiments, which stabilizes the training process and reduces the searching time by 4 times. Further, an architecture knowledge pool together with a block similarity function is proposed to utilize parameter knowledge and reduces the searching time by 2 times. It is the first to introduce block-level weight sharing in RLbased NAS. The block similarity function guarantees a 100% hitting ratio with strict fairness. Besides, we show that a simply designed off-policy correction factor used in "replay buffer" in RL optimization can further reduce half of the searching time. Experiments on the Mobile Neural Architecture Search (MNAS) search space show the proposed Fast Neural Architecture Search (FNAS) accelerates standard RL-based NAS process by ~10x (e.g. ~256 2x2 TPUv2 x days / 20,000 GPU x hour -> 2,000 GPU x hour for MNAS), and guarantees better performance on various vision tasks.
3D UAV Trajectory and Data Collection Optimisation via Deep Reinforcement Learning
Jun 06, 2021
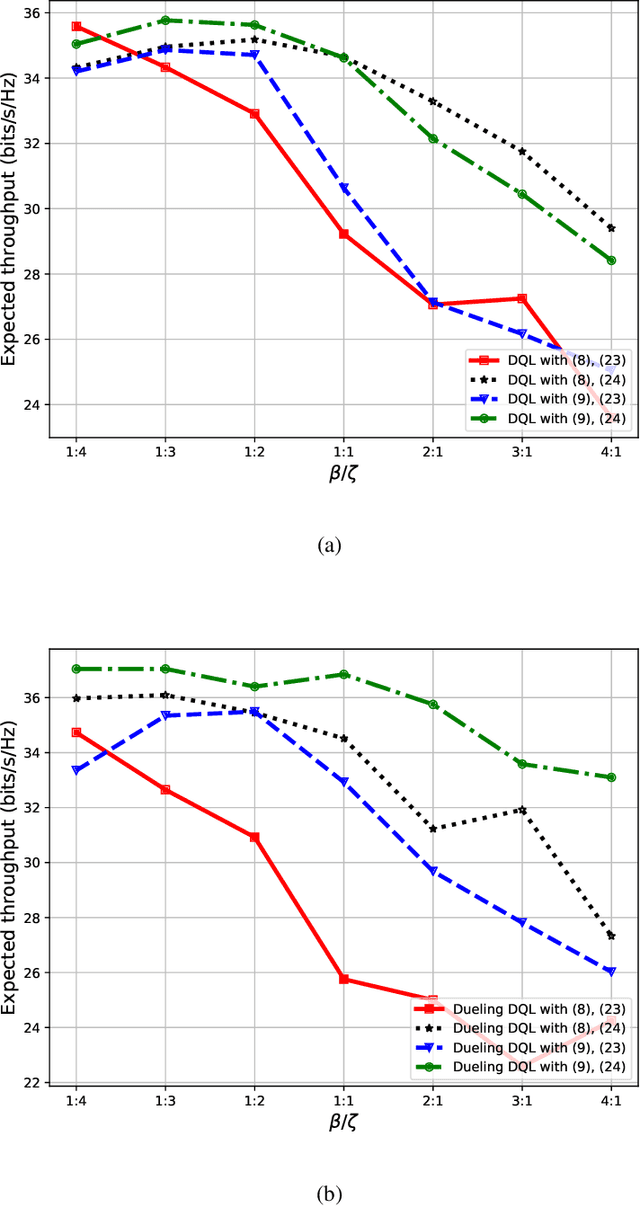
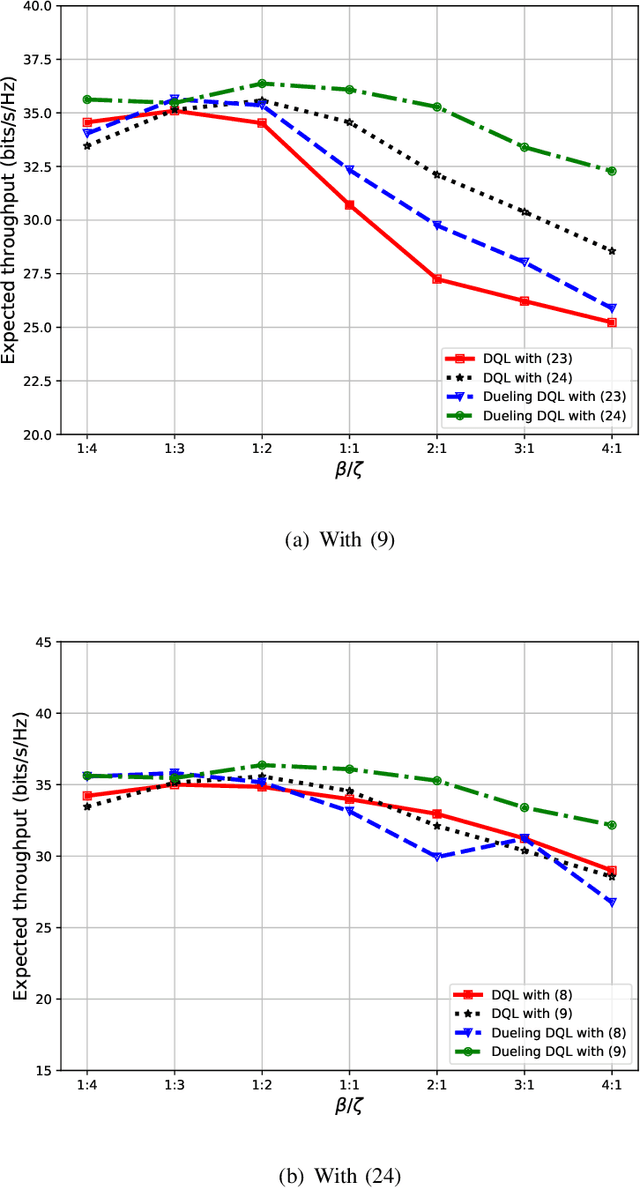
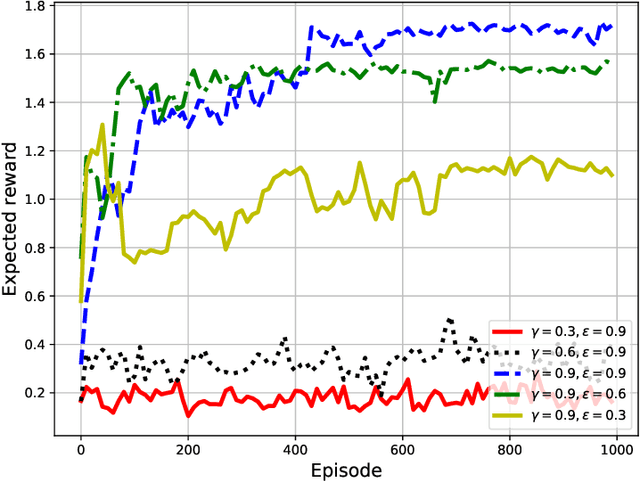
Unmanned aerial vehicles (UAVs) are now beginning to be deployed for enhancing the network performance and coverage in wireless communication. However, due to the limitation of their on-board power and flight time, it is challenging to obtain an optimal resource allocation scheme for the UAV-assisted Internet of Things (IoT). In this paper, we design a new UAV-assisted IoT systems relying on the shortest flight path of the UAVs while maximising the amount of data collected from IoT devices. Then, a deep reinforcement learning-based technique is conceived for finding the optimal trajectory and throughput in a specific coverage area. After training, the UAV has the ability to autonomously collect all the data from user nodes at a significant total sum-rate improvement while minimising the associated resources used. Numerical results are provided to highlight how our techniques strike a balance between the throughput attained, trajectory, and the time spent. More explicitly, we characterise the attainable performance in terms of the UAV trajectory, the expected reward and the total sum-rate.
Multi-rate attention architecture for fast streamable Text-to-speech spectrum modeling
Apr 01, 2021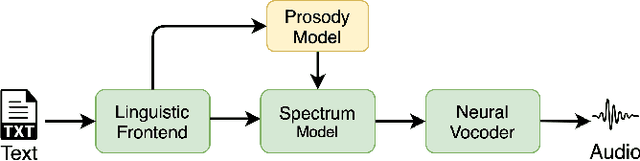
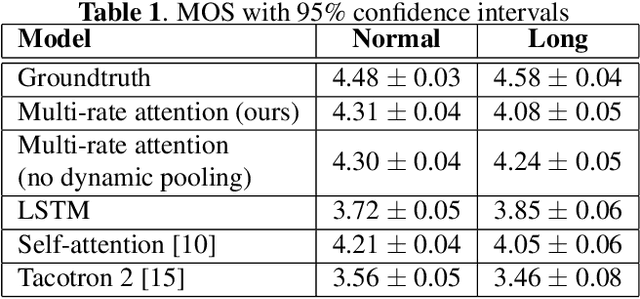
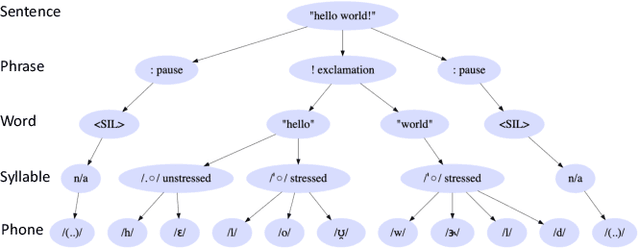
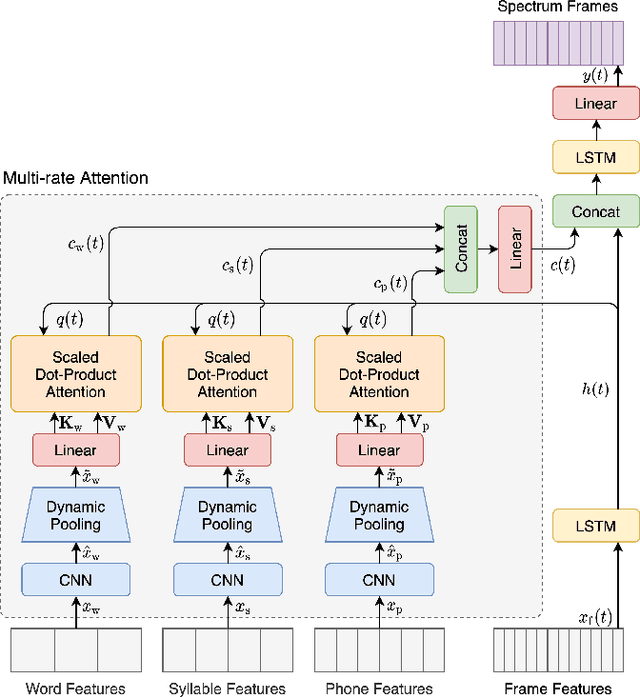
Typical high quality text-to-speech (TTS) systems today use a two-stage architecture, with a spectrum model stage that generates spectral frames and a vocoder stage that generates the actual audio. High-quality spectrum models usually incorporate the encoder-decoder architecture with self-attention or bi-directional long short-term (BLSTM) units. While these models can produce high quality speech, they often incur O($L$) increase in both latency and real-time factor (RTF) with respect to input length $L$. In other words, longer inputs leads to longer delay and slower synthesis speed, limiting its use in real-time applications. In this paper, we propose a multi-rate attention architecture that breaks the latency and RTF bottlenecks by computing a compact representation during encoding and recurrently generating the attention vector in a streaming manner during decoding. The proposed architecture achieves high audio quality (MOS of 4.31 compared to groundtruth 4.48), low latency, and low RTF at the same time. Meanwhile, both latency and RTF of the proposed system stay constant regardless of input lengths, making it ideal for real-time applications.
A Novel Low Complexity Faster-than-Nyquist (FTN) Signaling Detector for Ultra High-Order QAM
Jul 02, 2021



Faster-than-Nyquist (FTN) signaling is a promising non-orthogonal pulse modulation technique that can improve the spectral efficiency (SE) of next generation communication systems at the expense of higher detection complexity to remove the introduced inter-symbol interference (ISI). In this paper, we investigate the detection problem of ultra high-order quadrature-amplitude modulation (QAM) FTN signaling where we exploit a mathematical programming technique based on the alternating directions multiplier method (ADMM). The proposed ADMM sequence estimation (ADMMSE) FTN signaling detector demonstrates an excellent trade-off between performance and computational effort enabling, for the first time in the FTN signaling literature, successful detection and SE gains for QAM modulation orders as high as 64K (65,536). The complexity of the proposed ADMMSE detector is polynomial in the length of the transmit symbols sequence and its sensitivity to the modulation order increases only logarithmically. Simulation results show that for 16-QAM, the proposed ADMMSE FTN signaling detector achieves comparable SE gains to the generalized approach semidefinite relaxation-based sequence estimation (GASDRSE) FTN signaling detector, but at an experimentally evaluated much lower computational time. Simulation results additionally show SE gains for modulation orders starting from 4-QAM, or quadrature phase shift keying (QPSK), up to and including 64K-QAM when compared to conventional Nyquist signaling. The very low computational effort required makes the proposed ADMMSE detector a practically promising FTN signaling detector for both low order and ultra high-order QAM FTN signaling systems.
Generating Concurrent Programs From Sequential Data Structure Knowledge Using Answer Set Programming
Sep 17, 2021


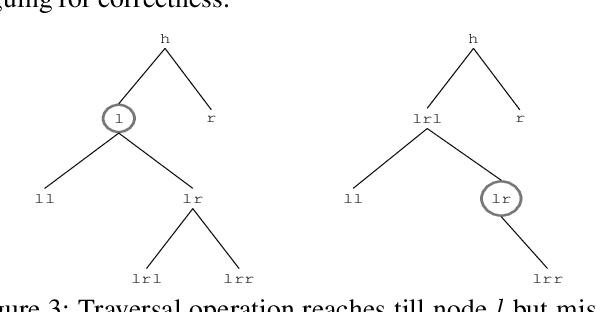
We tackle the problem of automatically designing concurrent data structure operations given a sequential data structure specification and knowledge about concurrent behavior. Designing concurrent code is a non-trivial task even in simplest of cases. Humans often design concurrent data structure operations by transforming sequential versions into their respective concurrent versions. This requires an understanding of the data structure, its sequential behavior, thread interactions during concurrent execution and shared memory synchronization primitives. We mechanize this design process using automated commonsense reasoning. We assume that the data structure description is provided as axioms alongside the sequential code of its algebraic operations. This information is used to automatically derive concurrent code for that data structure, such as dictionary operations for linked lists and binary search trees. Knowledge in our case is expressed using Answer Set Programming (ASP), and we employ deduction and abduction -- just as humans do -- in the reasoning involved. ASP allows for succinct modeling of first order theories of pointer data structures, run-time thread interactions and shared memory synchronization. Our reasoner can systematically make the same judgments as a human reasoner, while constructing provably safe concurrent code. We present several reasoning challenges involved in transforming the sequential data structure into its equivalent concurrent version. All the reasoning tasks are encoded in ASP and our reasoner can make sound judgments to transform sequential code into concurrent code. To the best of our knowledge, our work is the first one to use commonsense reasoning to automatically transform sequential programs into concurrent code. We also have developed a tool that we describe that relies on state-of-the-art ASP solvers and performs the reasoning tasks involved to generate concurrent code.
* In Proceedings ICLP 2021, arXiv:2109.07914. arXiv admin note: substantial text overlap with arXiv:2011.04045
Refining the Semantics of Epistemic Specifications
Sep 17, 2021
Answer set programming (ASP) is an efficient problem-solving approach, which has been strongly supported both scientifically and technologically by several solvers, ongoing active research, and implementations in many different fields. However, although researchers acknowledged long ago the necessity of epistemic operators in the language of ASP for better introspective reasoning, this research venue did not attract much attention until recently. Moreover, the existing epistemic extensions of ASP in the literature are not widely approved either, due to the fact that some propose unintended results even for some simple acyclic epistemic programs, new unexpected results may possibly be found, and more importantly, researchers have different reasonings for some critical programs. To that end, Cabalar et al. have recently identified some structural properties of epistemic programs to formally support a possible semantics proposal of such programs and standardise their results. Nonetheless, the soundness of these properties is still under debate, and they are not widely accepted either by the ASP community. Thus, it seems that there is still time to really understand the paradigm, have a mature formalism, and determine the principles providing formal justification of their understandable models. In this paper, we mainly focus on the existing semantics approaches, the criteria that a satisfactory semantics is supposed to satisfy, and the ways to improve them. We also extend some well-known propositions of here-and-there logic (HT) into epistemic HT so as to reveal the real behaviour of programs. Finally, we propose a slightly novel semantics for epistemic ASP, which can be considered as a reflexive extension of Cabalar et al.'s recent formalism called autoepistemic ASP.
* In Proceedings ICLP 2021, arXiv:2109.07914
SketchHairSalon: Deep Sketch-based Hair Image Synthesis
Sep 21, 2021
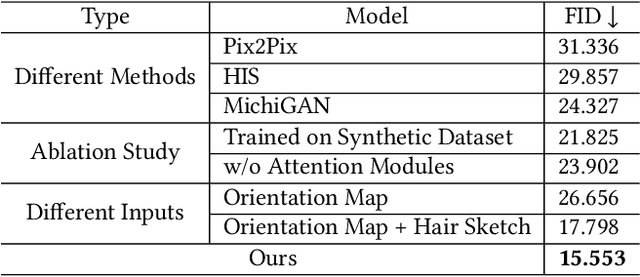
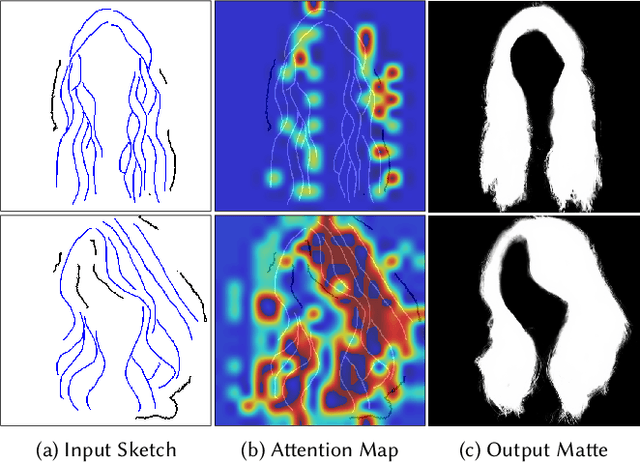
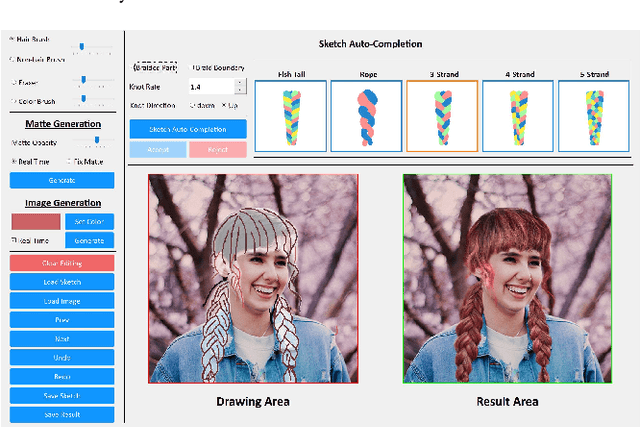
Recent deep generative models allow real-time generation of hair images from sketch inputs. Existing solutions often require a user-provided binary mask to specify a target hair shape. This not only costs users extra labor but also fails to capture complicated hair boundaries. Those solutions usually encode hair structures via orientation maps, which, however, are not very effective to encode complex structures. We observe that colored hair sketches already implicitly define target hair shapes as well as hair appearance and are more flexible to depict hair structures than orientation maps. Based on these observations, we present SketchHairSalon, a two-stage framework for generating realistic hair images directly from freehand sketches depicting desired hair structure and appearance. At the first stage, we train a network to predict a hair matte from an input hair sketch, with an optional set of non-hair strokes. At the second stage, another network is trained to synthesize the structure and appearance of hair images from the input sketch and the generated matte. To make the networks in the two stages aware of long-term dependency of strokes, we apply self-attention modules to them. To train these networks, we present a new dataset containing thousands of annotated hair sketch-image pairs and corresponding hair mattes. Two efficient methods for sketch completion are proposed to automatically complete repetitive braided parts and hair strokes, respectively, thus reducing the workload of users. Based on the trained networks and the two sketch completion strategies, we build an intuitive interface to allow even novice users to design visually pleasing hair images exhibiting various hair structures and appearance via freehand sketches. The qualitative and quantitative evaluations show the advantages of the proposed system over the existing or alternative solutions.