 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Multi-Channel Automatic Music Transcription Using Tensor Algebra
Jul 23, 2021
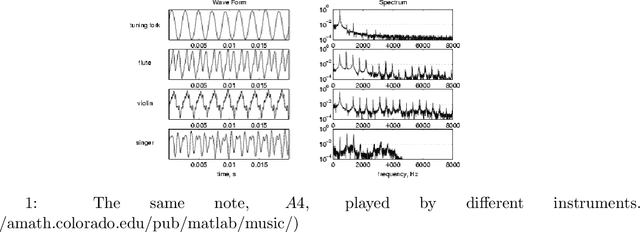
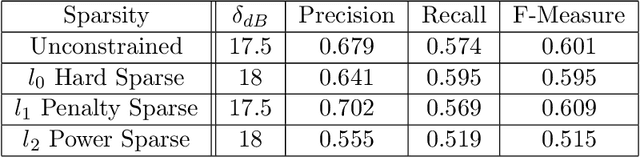

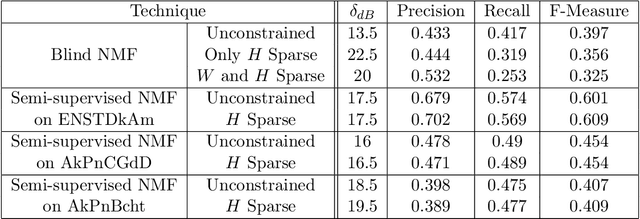
Music is an art, perceived in unique ways by every listener, coming from acoustic signals. In the meantime, standards as musical scores exist to describe it. Even if humans can make this transcription, it is costly in terms of time and efforts, even more with the explosion of information consecutively to the rise of the Internet. In that sense, researches are driven in the direction of Automatic Music Transcription. While this task is considered solved in the case of single notes, it is still open when notes superpose themselves, forming chords. This report aims at developing some of the existing techniques towards Music Transcription, particularly matrix factorization, and introducing the concept of multi-channel automatic music transcription. This concept will be explored with mathematical objects called tensors.
Applications of Artificial Neural Networks in Microorganism Image Analysis: A Comprehensive Review from Conventional Multilayer Perceptron to Popular Convolutional Neural Network and Potential Visual Transformer
Aug 01, 2021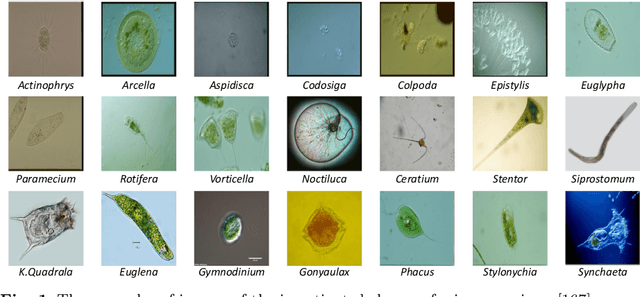
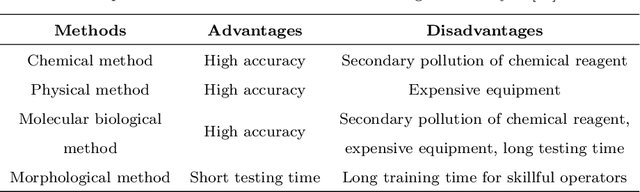
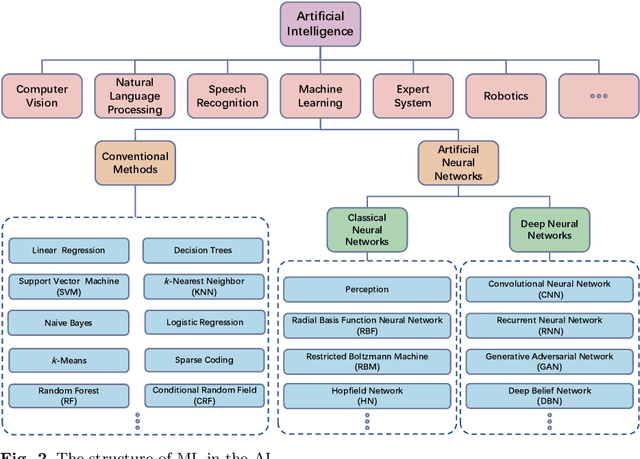
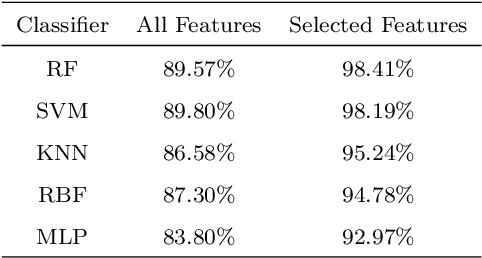
Microorganisms are widely distributed in the human daily living environment. They play an essential role in environmental pollution control, disease prevention and treatment, and food and drug production. The identification, counting, and detection are the basic steps for making full use of different microorganisms. However, the conventional analysis methods are expensive, laborious, and time-consuming. To overcome these limitations, artificial neural networks are applied for microorganism image analysis. We conduct this review to understand the development process of microorganism image analysis based on artificial neural networks. In this review, the background and motivation are introduced first. Then, the development of artificial neural networks and representative networks are introduced. After that, the papers related to microorganism image analysis based on classical and deep neural networks are reviewed from the perspectives of different tasks. In the end, the methodology analysis and potential direction are discussed.
Decentralized Multi-AGV Task Allocation based on Multi-Agent Reinforcement Learning with Information Potential Field Rewards
Aug 16, 2021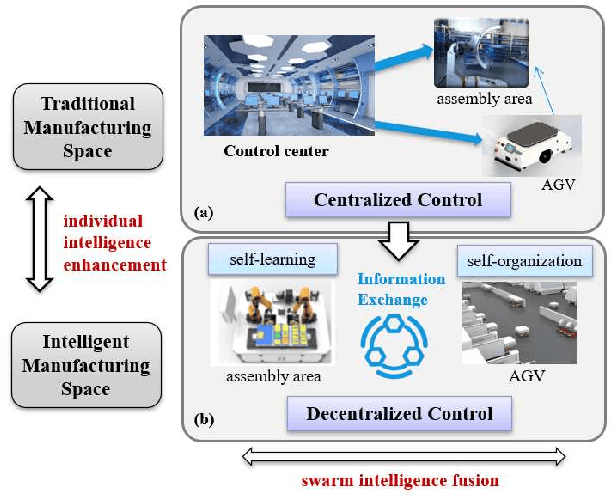
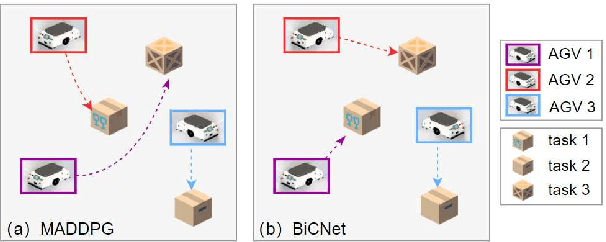
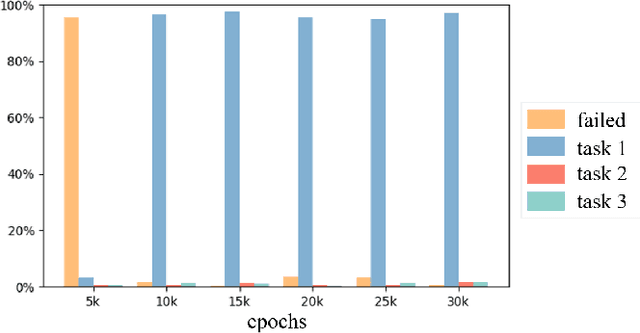
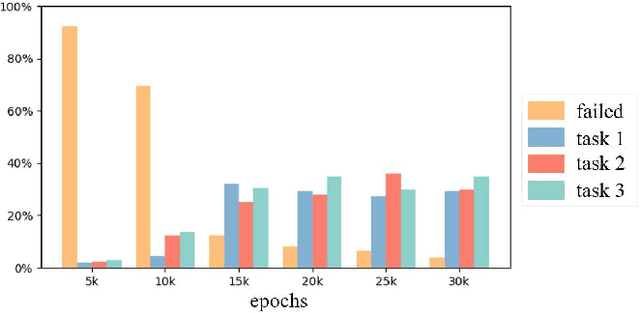
Automated Guided Vehicles (AGVs) have been widely used for material handling in flexible shop floors. Each product requires various raw materials to complete the assembly in production process. AGVs are used to realize the automatic handling of raw materials in different locations. Efficient AGVs task allocation strategy can reduce transportation costs and improve distribution efficiency. However, the traditional centralized approaches make high demands on the control center's computing power and real-time capability. In this paper, we present decentralized solutions to achieve flexible and self-organized AGVs task allocation. In particular, we propose two improved multi-agent reinforcement learning algorithms, MADDPG-IPF (Information Potential Field) and BiCNet-IPF, to realize the coordination among AGVs adapting to different scenarios. To address the reward-sparsity issue, we propose a reward shaping strategy based on information potential field, which provides stepwise rewards and implicitly guides the AGVs to different material targets. We conduct experiments under different settings (3 AGVs and 6 AGVs), and the experiment results indicate that, compared with baseline methods, our work obtains up to 47\% task response improvement and 22\% training iterations reduction.
AirNet: Neural Network Transmission over the Air
May 26, 2021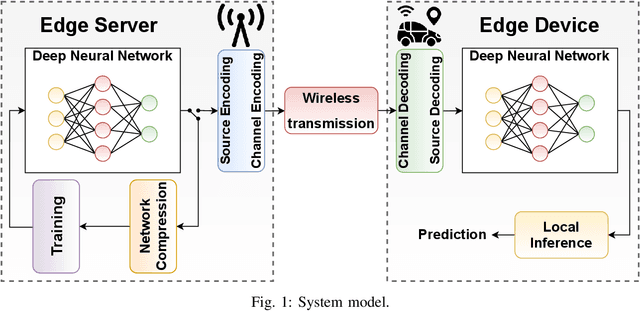
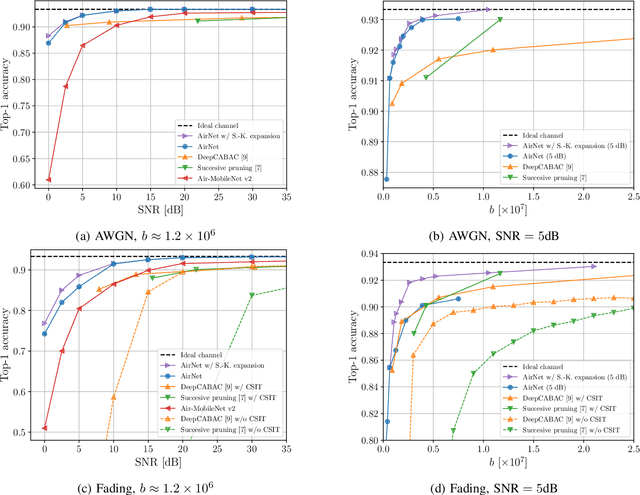
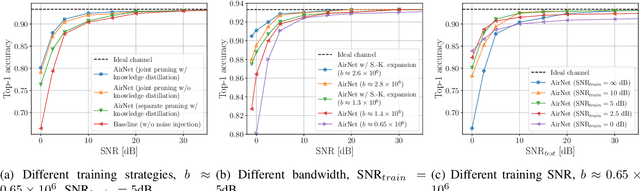
State-of-the-art performance for many emerging edge applications is achieved by deep neural networks (DNNs). Often, these DNNs are location and time sensitive, and the parameters of a specific DNN must be delivered from an edge server to the edge device rapidly and efficiently to carry out time-sensitive inference tasks. We introduce AirNet, a novel training and analog transmission method that allows efficient wireless delivery of DNNs. We first train the DNN with noise injection to counter the wireless channel noise. We also employ pruning to reduce the channel bandwidth necessary for transmission, and perform knowledge distillation from a larger model to achieve satisfactory performance, despite the channel perturbations. We show that AirNet achieves significantly higher test accuracy compared to digital alternatives under the same bandwidth and power constraints. It also exhibits graceful degradation with channel quality, which reduces the requirement for accurate channel estimation.
Example-Driven Model-Based Reinforcement Learning for Solving Long-Horizon Visuomotor Tasks
Sep 21, 2021
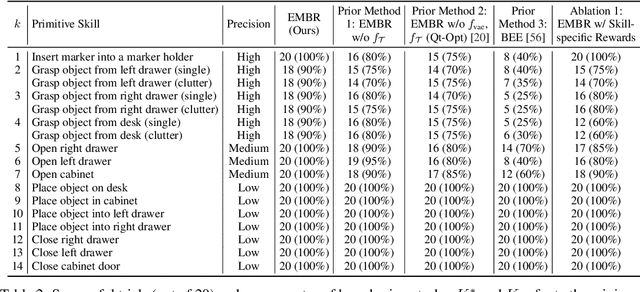
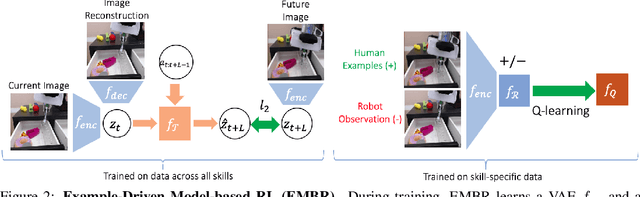

In this paper, we study the problem of learning a repertoire of low-level skills from raw images that can be sequenced to complete long-horizon visuomotor tasks. Reinforcement learning (RL) is a promising approach for acquiring short-horizon skills autonomously. However, the focus of RL algorithms has largely been on the success of those individual skills, more so than learning and grounding a large repertoire of skills that can be sequenced to complete extended multi-stage tasks. The latter demands robustness and persistence, as errors in skills can compound over time, and may require the robot to have a number of primitive skills in its repertoire, rather than just one. To this end, we introduce EMBR, a model-based RL method for learning primitive skills that are suitable for completing long-horizon visuomotor tasks. EMBR learns and plans using a learned model, critic, and success classifier, where the success classifier serves both as a reward function for RL and as a grounding mechanism to continuously detect if the robot should retry a skill when unsuccessful or under perturbations. Further, the learned model is task-agnostic and trained using data from all skills, enabling the robot to efficiently learn a number of distinct primitives. These visuomotor primitive skills and their associated pre- and post-conditions can then be directly combined with off-the-shelf symbolic planners to complete long-horizon tasks. On a Franka Emika robot arm, we find that EMBR enables the robot to complete three long-horizon visuomotor tasks at 85% success rate, such as organizing an office desk, a file cabinet, and drawers, which require sequencing up to 12 skills, involve 14 unique learned primitives, and demand generalization to novel objects.
Fast Time-optimal Avoidance of Moving Obstacles for High-Speed MAV Flight
Aug 06, 2019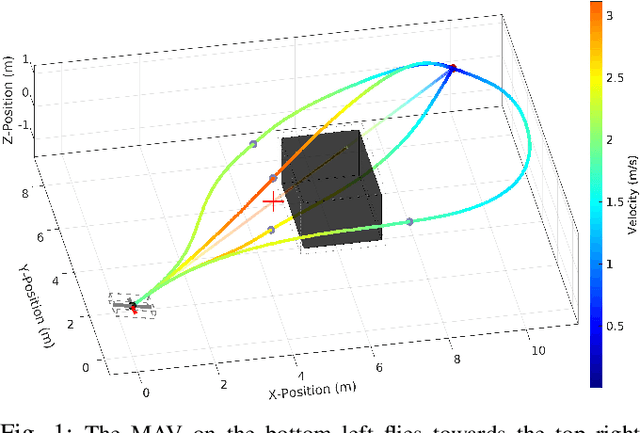
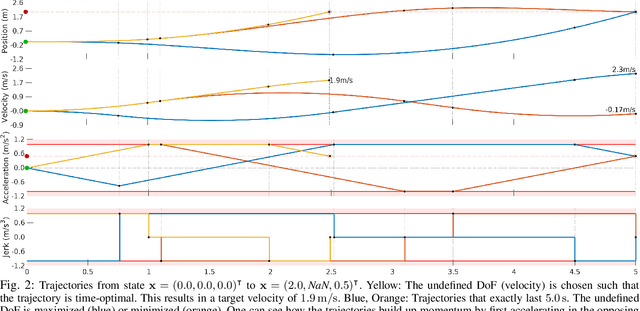
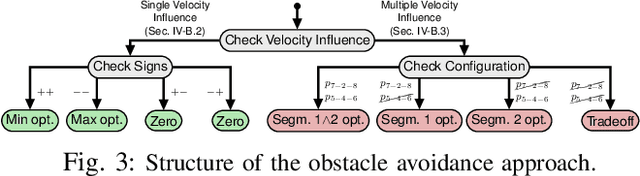
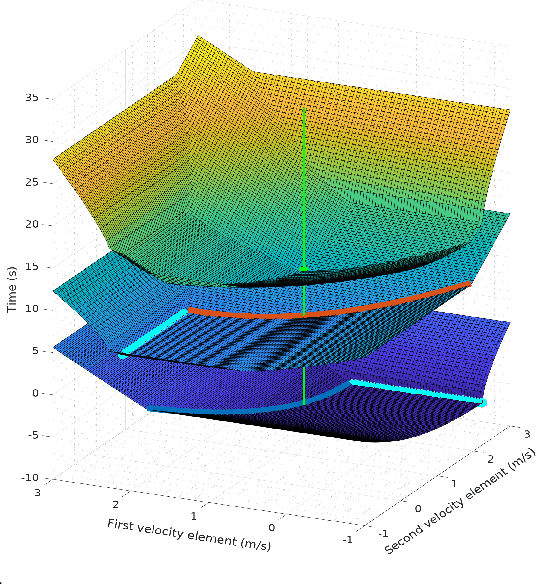
In this work, we propose a method to efficiently compute smooth, time-optimal trajectories for micro aerial vehicles (MAVs) evading a moving obstacle. Our approach first computes an n-dimensional trajectory from the start- to an arbitrary target state including position, velocity and acceleration. It respects input- and state-constraints and is thus dynamically feasible. The trajectory is then efficiently checked for collisions, exploiting the piecewise polynomial formulation. If collisions occur, viastates are inserted into the trajectory to circumvent the obstacle and still maintain time-optimality. These viastates are described by position, velocity, and acceleration. The evaluation shows that the computational demands of the proposed method are minimal such that obstacle avoidance can begin within few milliseconds. Optimality of generated trajectories, combined with the ability for frequent online re-planning from non-hover initial conditions, make the approach well suited for evasion of suddenly perceived obstacles during fast flight.
* For supplementary material and videos, see http://www.ais.uni-bonn.de/videos/IROS_2019_Beul/
Partial Symbol Recovery for Interference Resilience in Low-Power Wide Area Networks
Sep 08, 2021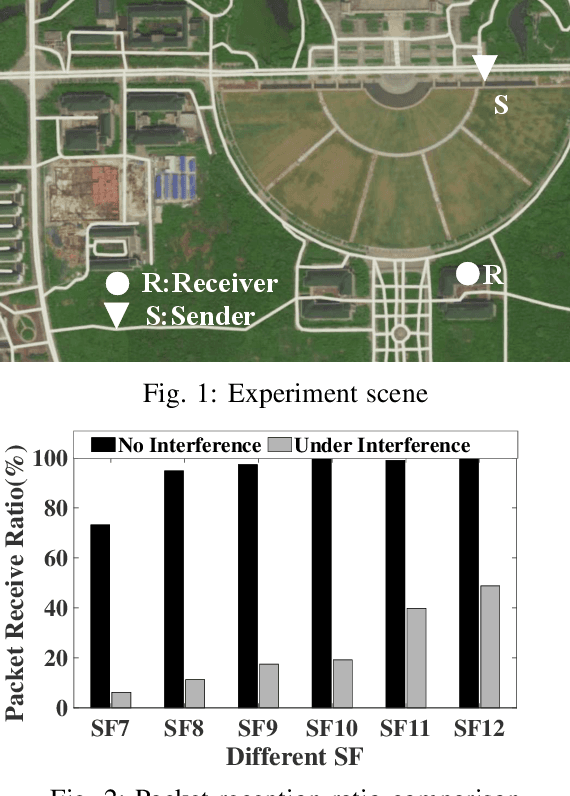
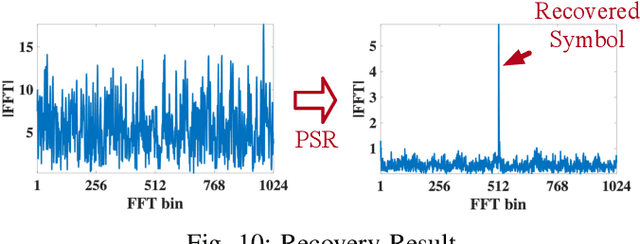

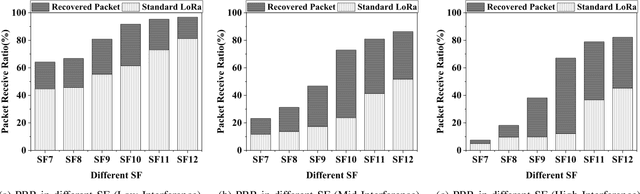
Recent years have witnessed the proliferation of Low-power Wide Area Networks (LPWANs) in the unlicensed band for various Internet-of-Things (IoT) applications. Due to the ultra-low transmission power and long transmission duration, LPWAN devices inevitably suffer from high power Cross Technology Interference (CTI), such as interference from Wi-Fi, coexisting in the same spectrum. To alleviate this issue, this paper introduces the Partial Symbol Recovery (PSR) scheme for improving the CTI resilience of LPWAN. We verify our idea on LoRa, a widely adopted LPWAN technique, as a proof of concept. At the PHY layer, although CTI has much higher power, its duration is relatively shorter compared with LoRa symbols, leaving part of a LoRa symbol uncorrupted. Moreover, due to its high redundancy, LoRa chips within a symbol are highly correlated. This opens the possibility of detecting a LoRa symbol with only part of the chips. By examining the unique frequency patterns in LoRa symbols with time-frequency analysis, our design effectively detects the clean LoRa chips that are free of CTI. This enables PSR to only rely on clean LoRa chips for successfully recovering from communication failures. We evaluate our PSR design with real-world testbeds, including SX1280 LoRa chips and USRP B210, under Wi-Fi interference in various scenarios. Extensive experiments demonstrate that our design offers reliable packet recovery performance, successfully boosting the LoRa packet reception ratio from 45.2% to 82.2% with a performance gain of 1.8 times.
Image-guided Breast Biopsy of MRI-visible Lesions with a Hand-mounted Motorised Needle Steering Tool
Jun 20, 2021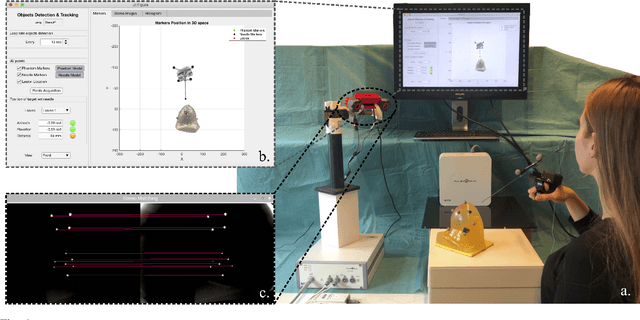
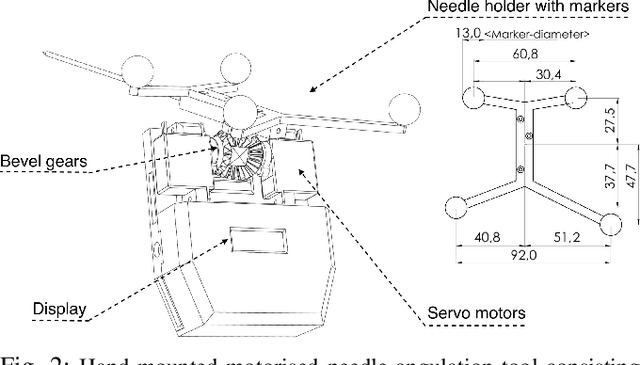
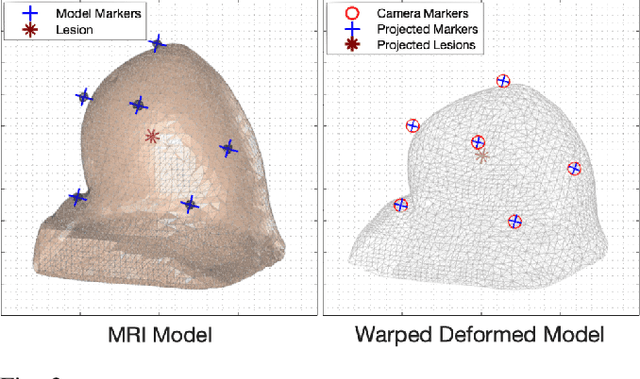
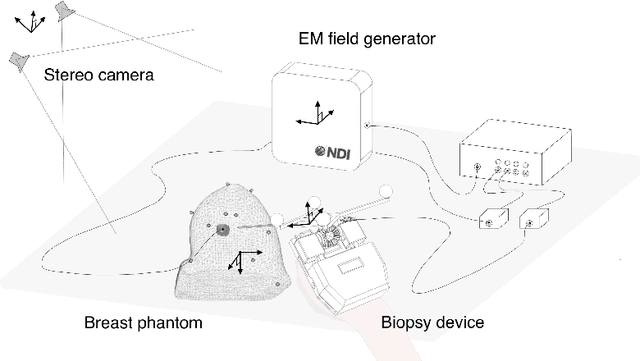
A biopsy is the only diagnostic procedure for accurate histological confirmation of breast cancer. When sonographic placement is not feasible, a Magnetic Resonance Imaging(MRI)-guided biopsy is often preferred. The lack of real-time imaging information and the deformations of the breast make it challenging to bring the needle precisely towards the tumour detected in pre-interventional Magnetic Resonance (MR) images. The current manual MRI-guided biopsy workflow is inaccurate and would benefit from a technique that allows real-time tracking and localisation of the tumour lesion during needle insertion. This paper proposes a robotic setup and software architecture to assist the radiologist in targeting MR-detected suspicious tumours. The approach benefits from image fusion of preoperative images with intraoperative optical tracking of markers attached to the patient's skin. A hand-mounted biopsy device has been constructed with an actuated needle base to drive the tip toward the desired direction. The steering commands may be provided both by user input and by computer guidance. The workflow is validated through phantom experiments. On average, the suspicious breast lesion is targeted with a radius down to 2.3 mm. The results suggest that robotic systems taking into account breast deformations have the potentials to tackle this clinical challenge.
Leveraging Commonsense Knowledge on Classifying False News and Determining Checkworthiness of Claims
Aug 08, 2021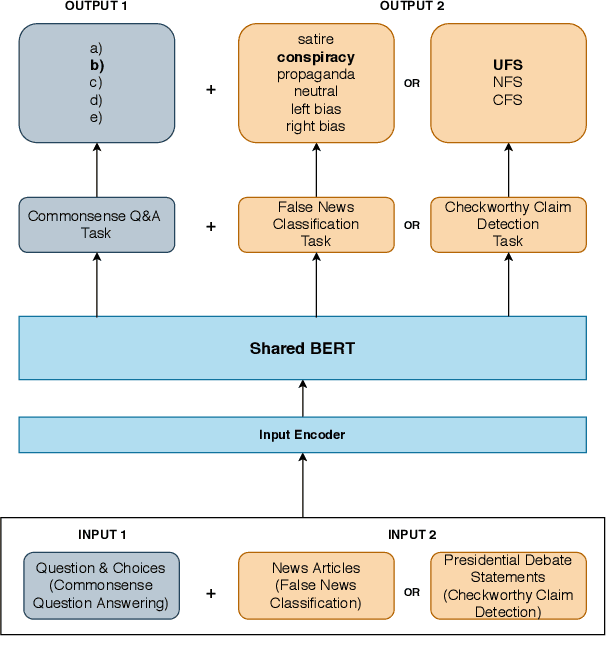

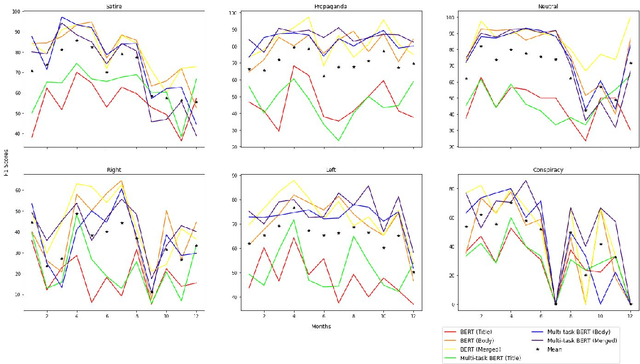

Widespread and rapid dissemination of false news has made fact-checking an indispensable requirement. Given its time-consuming and labor-intensive nature, the task calls for an automated support to meet the demand. In this paper, we propose to leverage commonsense knowledge for the tasks of false news classification and check-worthy claim detection. Arguing that commonsense knowledge is a factor in human believability, we fine-tune the BERT language model with a commonsense question answering task and the aforementioned tasks in a multi-task learning environment. For predicting fine-grained false news types, we compare the proposed fine-tuned model's performance with the false news classification models on a public dataset as well as a newly collected dataset. We compare the model's performance with the single-task BERT model and a state-of-the-art check-worthy claim detection tool to evaluate the check-worthy claim detection. Our experimental analysis demonstrates that commonsense knowledge can improve performance in both tasks.
A Targeted Assessment of Incremental Processing in Neural LanguageModels and Humans
Jun 06, 2021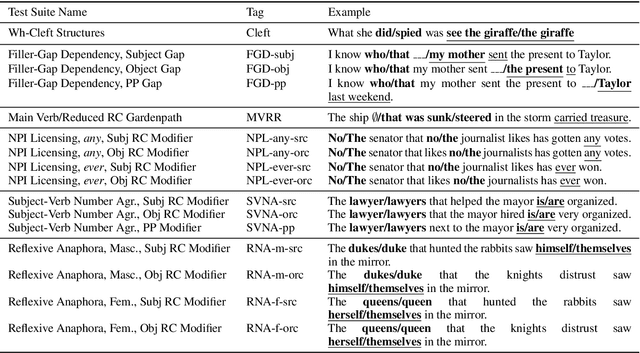
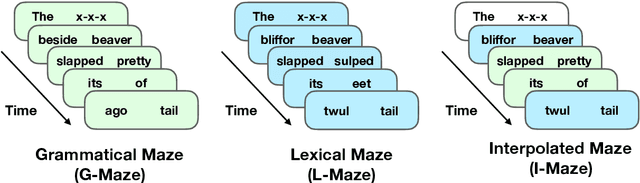
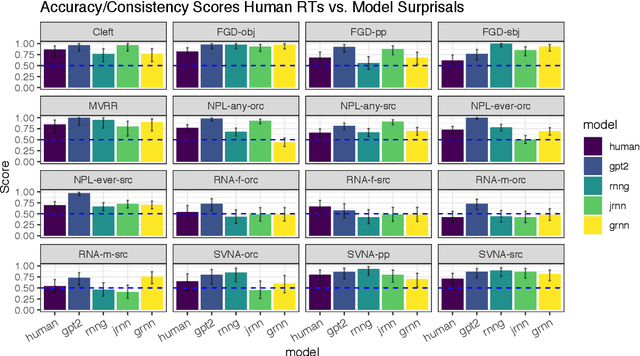
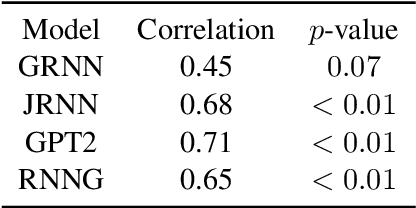
We present a targeted, scaled-up comparison of incremental processing in humans and neural language models by collecting by-word reaction time data for sixteen different syntactic test suites across a range of structural phenomena. Human reaction time data comes from a novel online experimental paradigm called the Interpolated Maze task. We compare human reaction times to by-word probabilities for four contemporary language models, with different architectures and trained on a range of data set sizes. We find that across many phenomena, both humans and language models show increased processing difficulty in ungrammatical sentence regions with human and model `accuracy' scores (a la Marvin and Linzen(2018)) about equal. However, although language model outputs match humans in direction, we show that models systematically under-predict the difference in magnitude of incremental processing difficulty between grammatical and ungrammatical sentences. Specifically, when models encounter syntactic violations they fail to accurately predict the longer reaction times observed in the human data. These results call into question whether contemporary language models are approaching human-like performance for sensitivity to syntactic violations.