 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
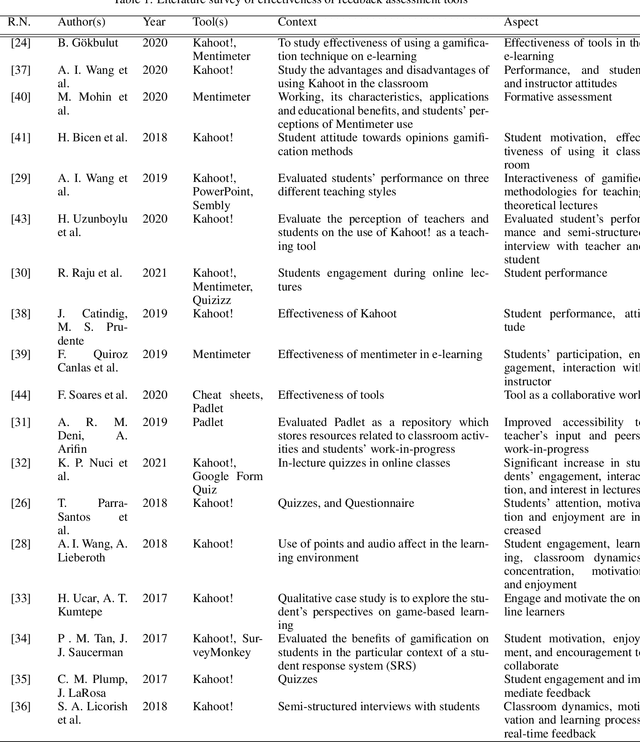
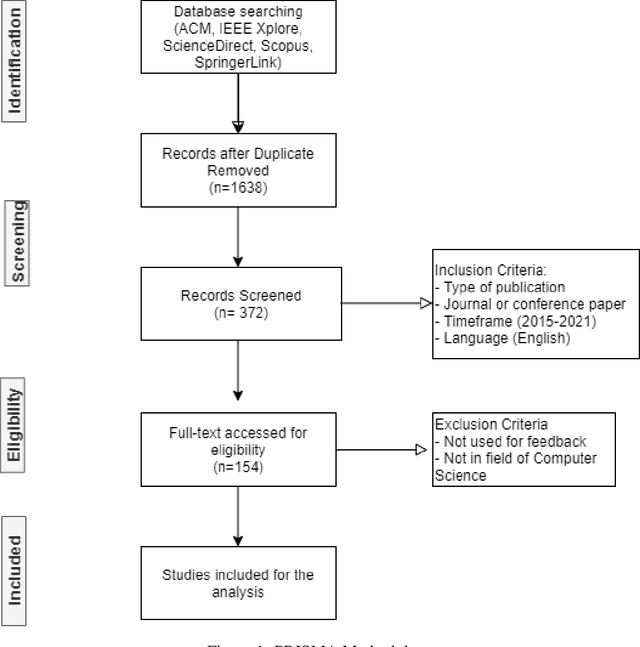
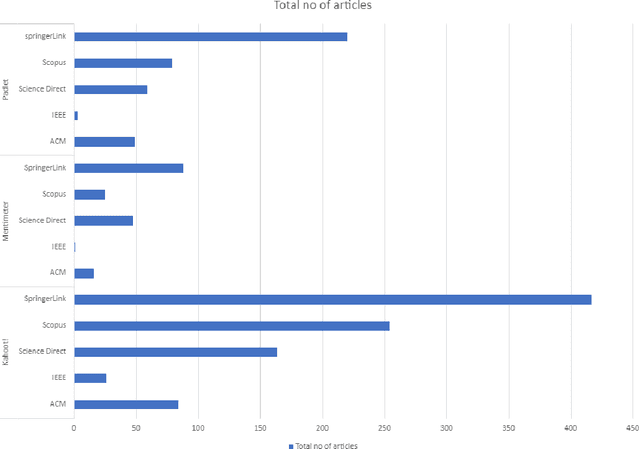
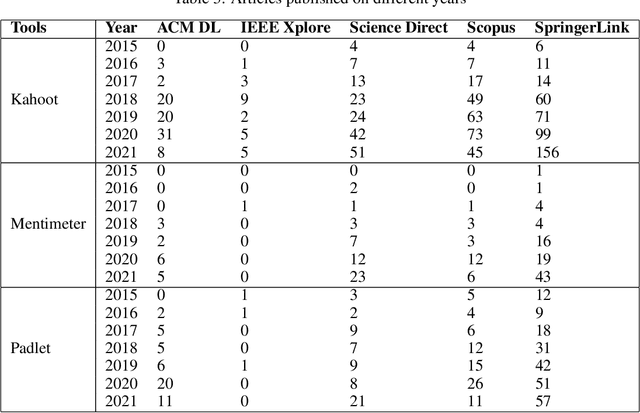
A literature survey on student feedback assessment tools and their usage in sentiment analysis
Sep 09, 2021
Online learning is becoming increasingly popular, whether for convenience, to accommodate work hours, or simply to have the freedom to study from anywhere. Especially, during the Covid-19 pandemic, it has become the only viable option for learning. The effectiveness of teaching various hard-core programming courses with a mix of theoretical content is determined by the student interaction and responses. In contrast to a digital lecture through Zoom or Teams, a lecturer may rapidly acquire such responses from students' facial expressions, behavior, and attitude in a physical session, even if the listener is largely idle and non-interactive. However, student assessment in virtual learning is a challenging task. Despite the challenges, different technologies are progressively being integrated into teaching environments to boost student engagement and motivation. In this paper, we evaluate the effectiveness of various in-class feedback assessment methods such as Kahoot!, Mentimeter, Padlet, and polling to assist a lecturer in obtaining real-time feedback from students throughout a session and adapting the teaching style accordingly. Furthermore, some of the topics covered by student suggestions include tutor suggestions, enhancing teaching style, course content, and other subjects. Any input gives the instructor valuable insight into how to improve the student's learning experience, however, manually going through all of the qualitative comments and extracting the ideas is tedious. Thus, in this paper, we propose a sentiment analysis model for extracting the explicit suggestions from the students' qualitative feedback comments.
Does Form Follow Function? An Empirical Exploration of the Impact of Deep Neural Network Architecture Design on Hardware-Specific Acceleration
Jul 08, 2021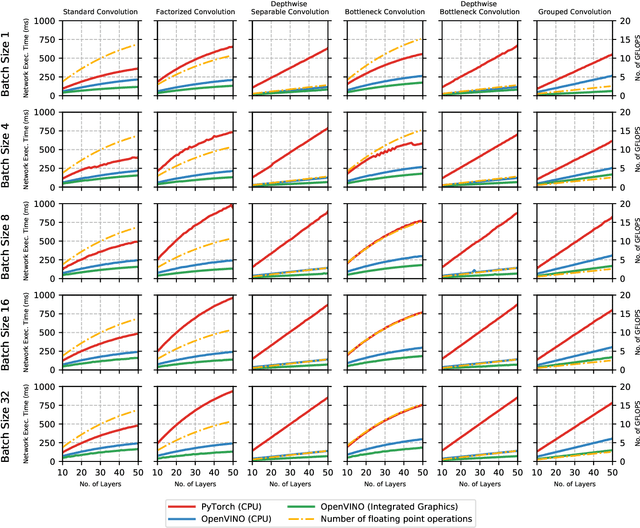
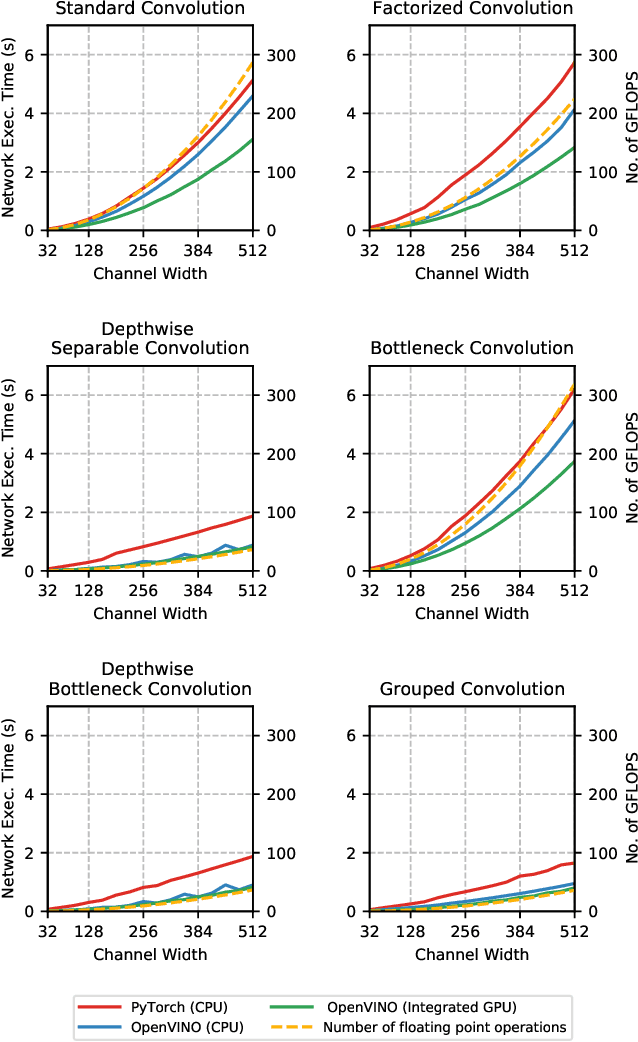
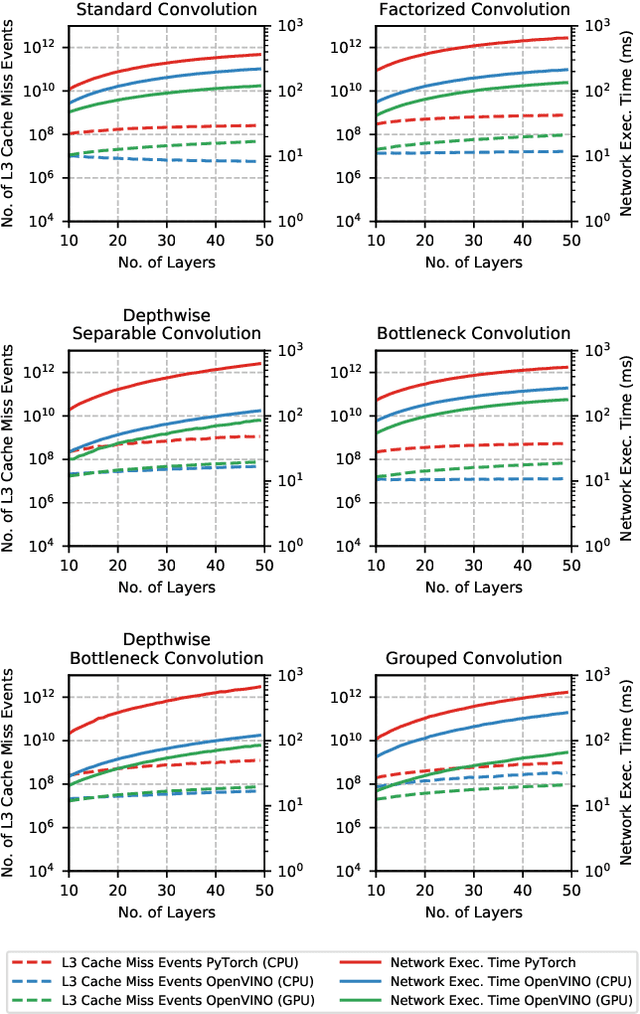
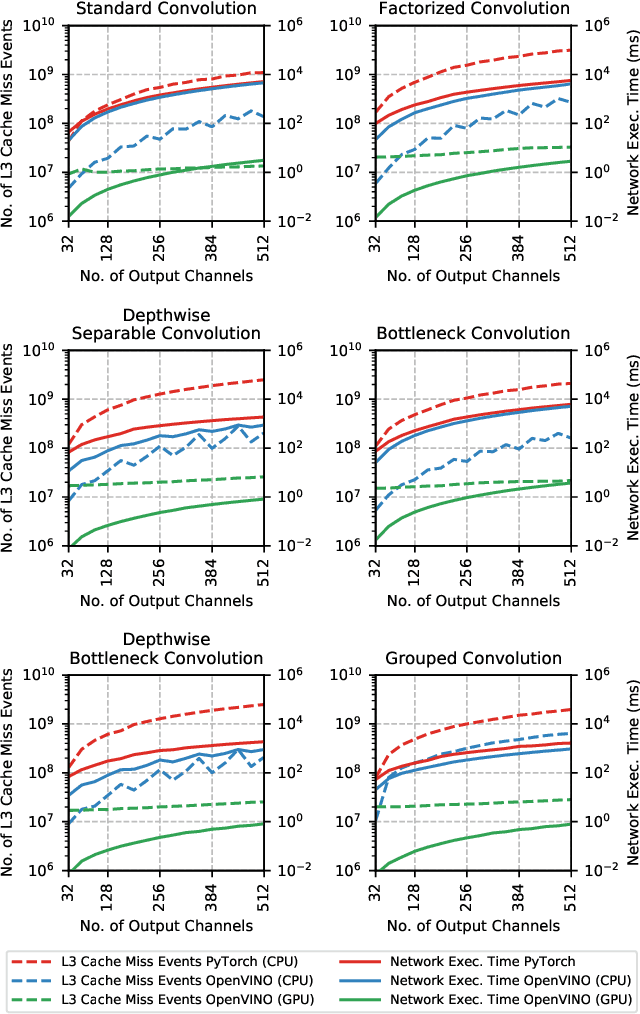
The fine-grained relationship between form and function with respect to deep neural network architecture design and hardware-specific acceleration is one area that is not well studied in the research literature, with form often dictated by accuracy as opposed to hardware function. In this study, a comprehensive empirical exploration is conducted to investigate the impact of deep neural network architecture design on the degree of inference speedup that can be achieved via hardware-specific acceleration. More specifically, we empirically study the impact of a variety of commonly used macro-architecture design patterns across different architectural depths through the lens of OpenVINO microprocessor-specific and GPU-specific acceleration. Experimental results showed that while leveraging hardware-specific acceleration achieved an average inference speed-up of 380%, the degree of inference speed-up varied drastically depending on the macro-architecture design pattern, with the greatest speedup achieved on the depthwise bottleneck convolution design pattern at 550%. Furthermore, we conduct an in-depth exploration of the correlation between FLOPs requirement, level 3 cache efficacy, and network latency with increasing architectural depth and width. Finally, we analyze the inference time reductions using hardware-specific acceleration when compared to native deep learning frameworks across a wide variety of hand-crafted deep convolutional neural network architecture designs as well as ones found via neural architecture search strategies. We found that the DARTS-derived architecture to benefit from the greatest improvement from hardware-specific software acceleration (1200%) while the depthwise bottleneck convolution-based MobileNet-V2 to have the lowest overall inference time of around 2.4 ms.
Impact of Data Normalization on Deep Neural Network for Time Series Forecasting
Jan 07, 2019
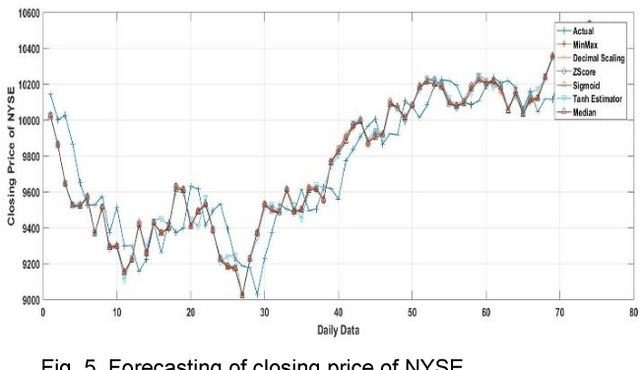
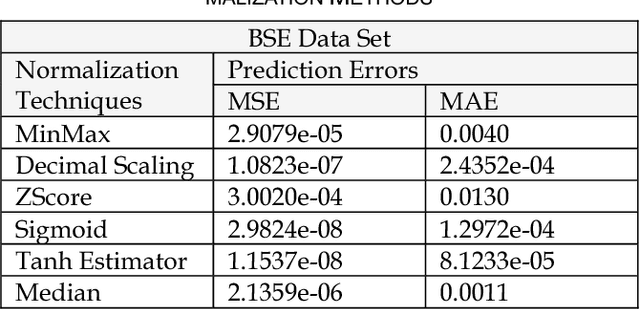
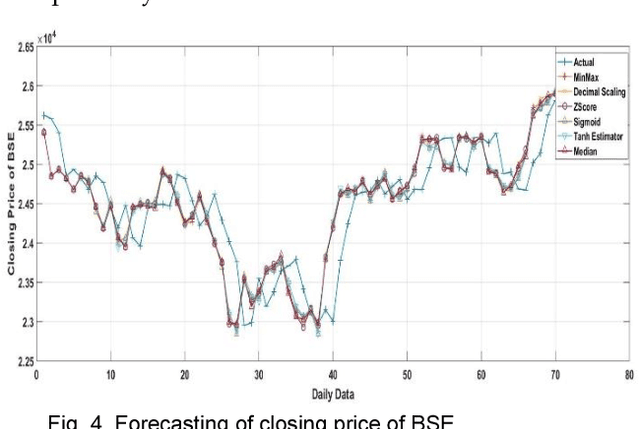
For the last few years it has been observed that the Deep Neural Networks (DNNs) has achieved an excellent success in image classification, speech recognition. But DNNs are suffer great deal of challenges for time series forecasting because most of the time series data are nonlinear in nature and highly dynamic in behaviour. The time series forecasting has a great impact on our socio-economic environment. Hence, to deal with these challenges its need to be redefined the DNN model and keeping this in mind, data pre-processing, network architecture and network parameters are need to be consider before feeding the data into DNN models. Data normalization is the basic data pre-processing technique form which learning is to be done. The effectiveness of time series forecasting is heavily depend on the data normalization technique. In this paper, different normalization methods are used on time series data before feeding the data into the DNN model and we try to find out the impact of each normalization technique on DNN to forecast the time series. Here the Deep Recurrent Neural Network (DRNN) is used to predict the closing index of Bombay Stock Exchange (BSE) and New York Stock Exchange (NYSE) by using BSE and NYSE time series data.
Extractive and Abstractive Sentence Labelling of Sentiment-bearing Topics
Aug 29, 2021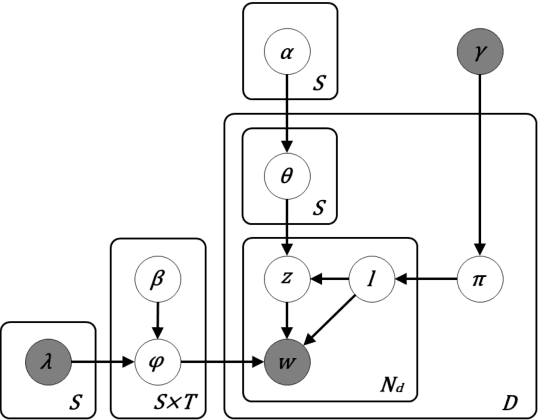
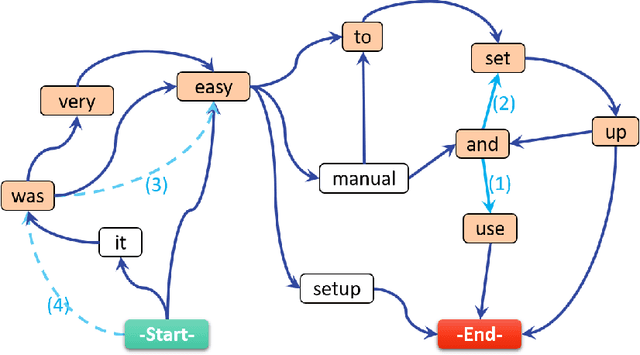

This paper tackles the problem of automatically labelling sentiment-bearing topics with descriptive sentence labels. We propose two approaches to the problem, one extractive and the other abstractive. Both approaches rely on a novel mechanism to automatically learn the relevance of each sentence in a corpus to sentiment-bearing topics extracted from that corpus. The extractive approach uses a sentence ranking algorithm for label selection which for the first time jointly optimises topic--sentence relevance as well as aspect--sentiment co-coverage. The abstractive approach instead addresses aspect--sentiment co-coverage by using sentence fusion to generate a sentential label that includes relevant content from multiple sentences. To our knowledge, we are the first to study the problem of labelling sentiment-bearing topics. Our experimental results on three real-world datasets show that both the extractive and abstractive approaches outperform four strong baselines in terms of facilitating topic understanding and interpretation. In addition, when comparing extractive and abstractive labels, our evaluation shows that our best performing abstractive method is able to provide more topic information coverage in fewer words, at the cost of generating less grammatical labels than the extractive method. We conclude that abstractive methods can effectively synthesise the rich information contained in sentiment-bearing topics.
Sensor-invariant Fingerprint ROI Segmentation Using Recurrent Adversarial Learning
Jul 03, 2021
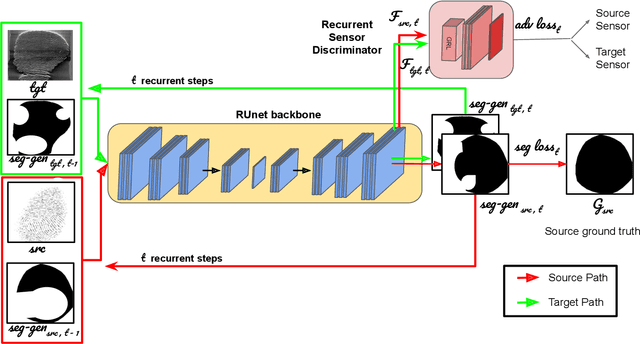

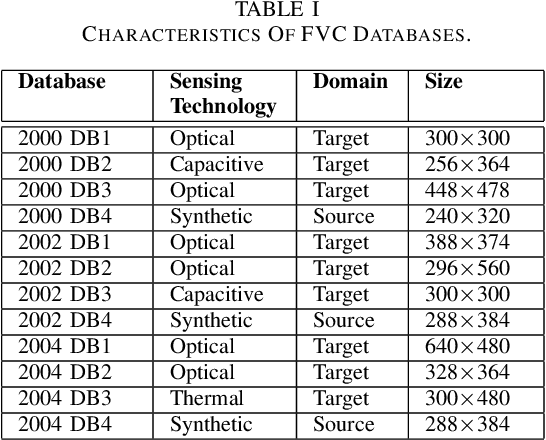
A fingerprint region of interest (roi) segmentation algorithm is designed to separate the foreground fingerprint from the background noise. All the learning based state-of-the-art fingerprint roi segmentation algorithms proposed in the literature are benchmarked on scenarios when both training and testing databases consist of fingerprint images acquired from the same sensors. However, when testing is conducted on a different sensor, the segmentation performance obtained is often unsatisfactory. As a result, every time a new fingerprint sensor is used for testing, the fingerprint roi segmentation model needs to be re-trained with the fingerprint image acquired from the new sensor and its corresponding manually marked ROI. Manually marking fingerprint ROI is expensive because firstly, it is time consuming and more importantly, requires domain expertise. In order to save the human effort in generating annotations required by state-of-the-art, we propose a fingerprint roi segmentation model which aligns the features of fingerprint images derived from the unseen sensor such that they are similar to the ones obtained from the fingerprints whose ground truth roi masks are available for training. Specifically, we propose a recurrent adversarial learning based feature alignment network that helps the fingerprint roi segmentation model to learn sensor-invariant features. Consequently, sensor-invariant features learnt by the proposed roi segmentation model help it to achieve improved segmentation performance on fingerprints acquired from the new sensor. Experiments on publicly available FVC databases demonstrate the efficacy of the proposed work.
* IJCNN 2021 (Accepted)
A deep neural network for multi-species fish detection using multiple acoustic cameras
Sep 22, 2021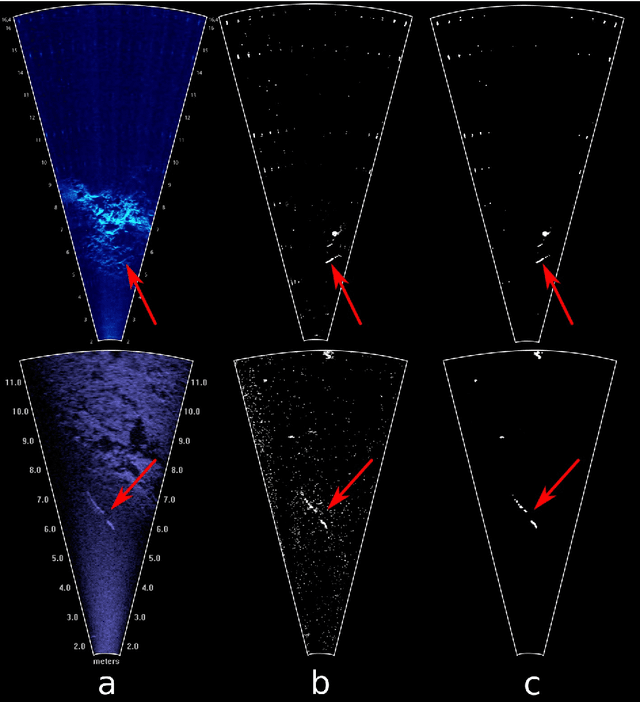
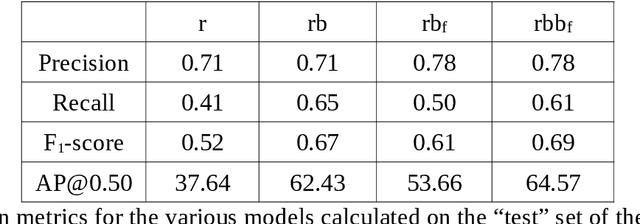
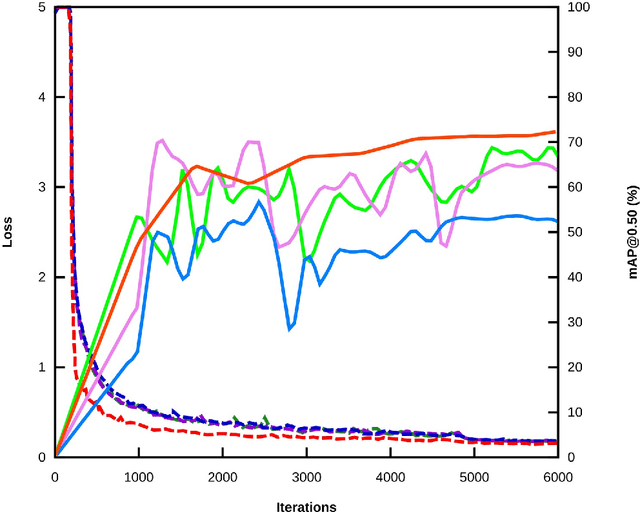
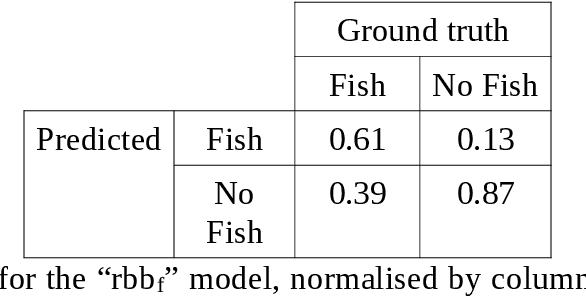
Underwater acoustic cameras are high potential devices for many applications in ecology, notably for fisheries management and monitoring. However how to extract such data into high value information without a time-consuming entire dataset reading by an operator is still a challenge. Moreover the analysis of acoustic imaging, due to its low signal-to-noise ratio, is a perfect training ground for experimenting with new approaches, especially concerning Deep Learning techniques. We present hereby a novel approach that takes advantage of both CNN (Convolutional Neural Network) and classical CV (Computer Vision) techniques, able to detect a generic class ''fish'' in acoustic video streams. The pipeline pre-treats the acoustic images to extract 2 features, in order to localise the signals and improve the detection performances. To ensure the performances from an ecological point of view, we propose also a two-step validation, one to validate the results of the trainings and one to test the method on a real-world scenario. The YOLOv3-based model was trained with data of fish from multiple species recorded by the two common acoustic cameras, DIDSON and ARIS, including species of high ecological interest, as Atlantic salmon or European eels. The model we developed provides satisfying results detecting almost 80% of fish and minimizing the false positive rate, however the model is much less efficient for eel detections on ARIS videos. The first CNN pipeline for fish monitoring exploiting video data from two models of acoustic cameras satisfies most of the required features. Many challenges are still present, such as the automation of fish species identification through a multiclass model. 1 However the results point a new solution for dealing with complex data, such as sonar data, which can also be reapplied in other cases where the signal-to-noise ratio is a challenge.
Training very large scale nonlinear SVMs using Alternating Direction Method of Multipliers coupled with the Hierarchically Semi-Separable kernel approximations
Aug 09, 2021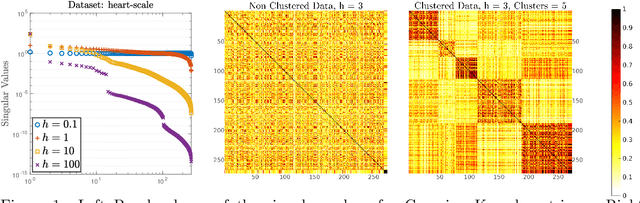
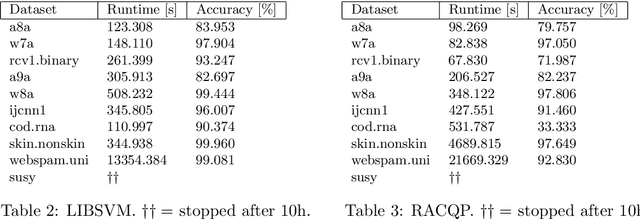
Typically, nonlinear Support Vector Machines (SVMs) produce significantly higher classification quality when compared to linear ones but, at the same time, their computational complexity is prohibitive for large-scale datasets: this drawback is essentially related to the necessity to store and manipulate large, dense and unstructured kernel matrices. Despite the fact that at the core of training a SVM there is a \textit{simple} convex optimization problem, the presence of kernel matrices is responsible for dramatic performance reduction, making SVMs unworkably slow for large problems. Aiming to an efficient solution of large-scale nonlinear SVM problems, we propose the use of the \textit{Alternating Direction Method of Multipliers} coupled with \textit{Hierarchically Semi-Separable} (HSS) kernel approximations. As shown in this work, the detailed analysis of the interaction among their algorithmic components unveils a particularly efficient framework and indeed, the presented experimental results demonstrate a significant speed-up when compared to the \textit{state-of-the-art} nonlinear SVM libraries (without significantly affecting the classification accuracy).
Scalable Distributed Planning for Multi-Robot, Multi-Target Tracking
Jul 18, 2021
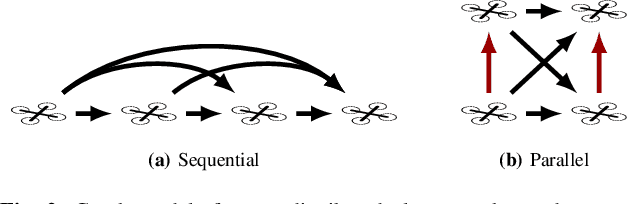
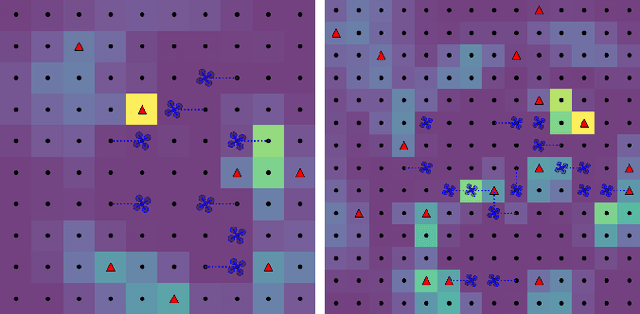
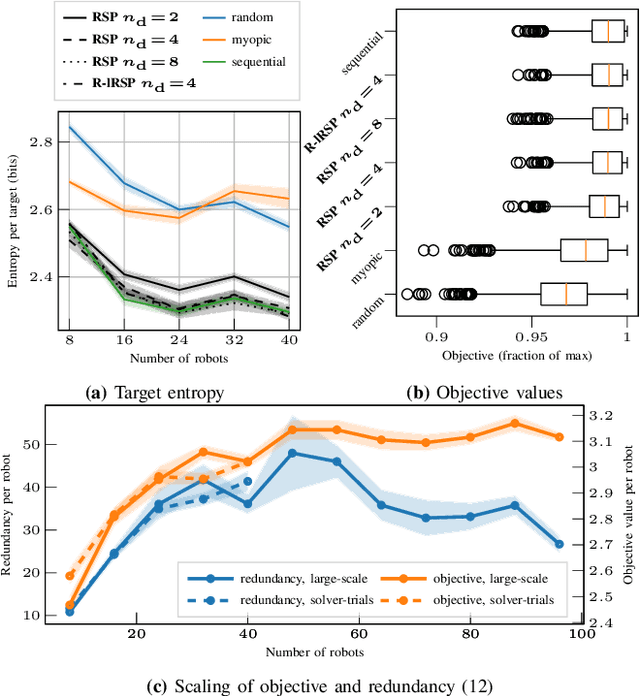
In multi-robot multi-target tracking, robots coordinate to monitor groups of targets moving about an environment. We approach planning for such scenarios by formulating a receding-horizon, multi-robot sensing problem with a mutual information objective. Such problems are NP-Hard in general. Yet, our objective is submodular which enables certain greedy planners to guarantee constant-factor suboptimality. However, these greedy planners require robots to plan their actions in sequence, one robot at a time, so planning time is at least proportional to the number of robots. Solving these problems becomes intractable for large teams, even for distributed implementations. Our prior work proposed a distributed planner (RSP) which reduces this number of sequential steps to a constant, even for large numbers of robots, by allowing robots to plan in parallel while ignoring some of each others' decisions. Although that analysis is not applicable to target tracking, we prove a similar guarantee, that RSP planning approaches performance guarantees for fully sequential planners, by employing a novel bound which takes advantage of the independence of target motions to quantify effective redundancy between robots' observations and actions. Further, we present analysis that explicitly accounts for features of practical implementations including approximations to the objective and anytime planning. Simulation results -- available via open source release -- for target tracking with ranging sensors demonstrate that our planners consistently approach the performance of sequential planning (in terms of position uncertainty) given only 2--8 planning steps and for as many as 96 robots with a 24x reduction in the number of sequential steps in planning. Thus, this work makes planning for multi-robot target tracking tractable at much larger scales than before, for practical planners and general tracking problems.
The effect of phased recurrent units in the classification of multiple catalogs of astronomical lightcurves
Jun 07, 2021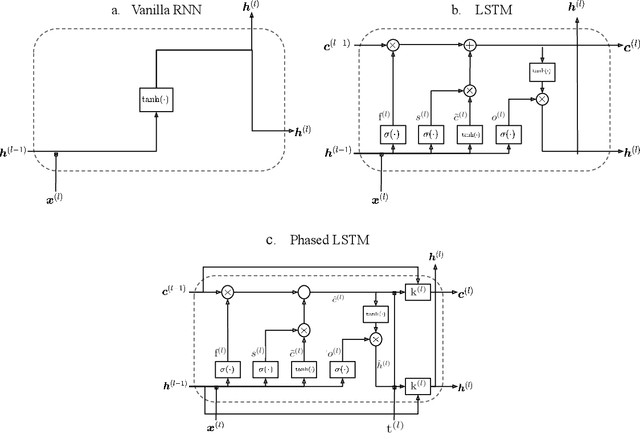
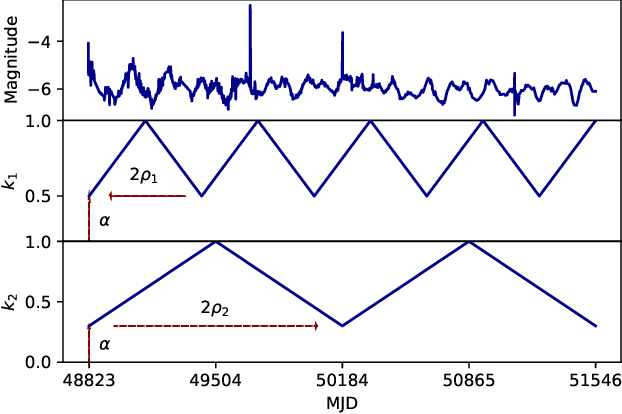
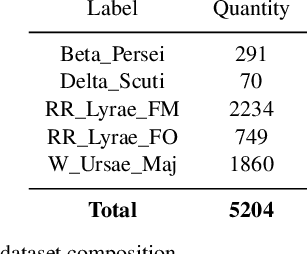
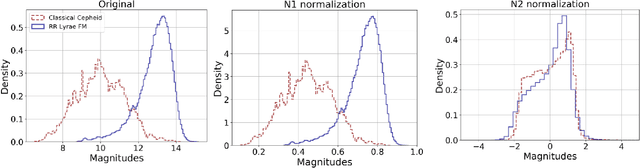
In the new era of very large telescopes, where data is crucial to expand scientific knowledge, we have witnessed many deep learning applications for the automatic classification of lightcurves. Recurrent neural networks (RNNs) are one of the models used for these applications, and the LSTM unit stands out for being an excellent choice for the representation of long time series. In general, RNNs assume observations at discrete times, which may not suit the irregular sampling of lightcurves. A traditional technique to address irregular sequences consists of adding the sampling time to the network's input, but this is not guaranteed to capture sampling irregularities during training. Alternatively, the Phased LSTM unit has been created to address this problem by updating its state using the sampling times explicitly. In this work, we study the effectiveness of the LSTM and Phased LSTM based architectures for the classification of astronomical lightcurves. We use seven catalogs containing periodic and nonperiodic astronomical objects. Our findings show that LSTM outperformed PLSTM on 6/7 datasets. However, the combination of both units enhances the results in all datasets.
Learned Image Coding for Machines: A Content-Adaptive Approach
Aug 23, 2021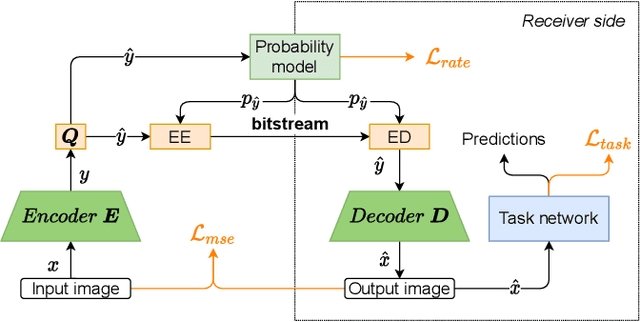

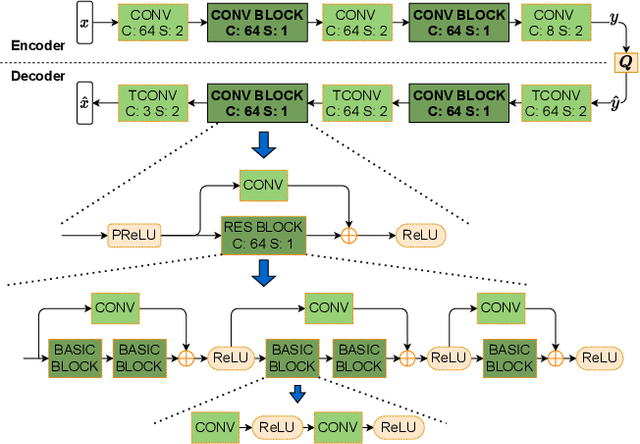
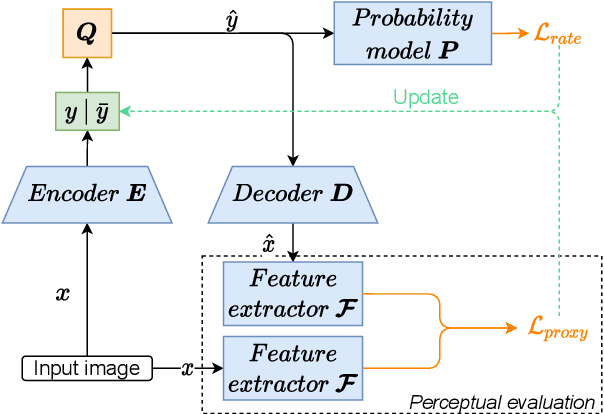
Today, according to the Cisco Annual Internet Report (2018-2023), the fastest-growing category of Internet traffic is machine-to-machine communication. In particular, machine-to-machine communication of images and videos represents a new challenge and opens up new perspectives in the context of data compression. One possible solution approach consists of adapting current human-targeted image and video coding standards to the use case of machine consumption. Another approach consists of developing completely new compression paradigms and architectures for machine-to-machine communications. In this paper, we focus on image compression and present an inference-time content-adaptive finetuning scheme that optimizes the latent representation of an end-to-end learned image codec, aimed at improving the compression efficiency for machine-consumption. The conducted experiments show that our online finetuning brings an average bitrate saving (BD-rate) of -3.66% with respect to our pretrained image codec. In particular, at low bitrate points, our proposed method results in a significant bitrate saving of -9.85%. Overall, our pretrained-and-then-finetuned system achieves -30.54% BD-rate over the state-of-the-art image/video codec Versatile Video Coding (VVC).
* Added some typo fixes since the accepted version in ICME2021