 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Context-Aware Task Handling in Resource-Constrained Robots with Virtualization
Apr 09, 2021
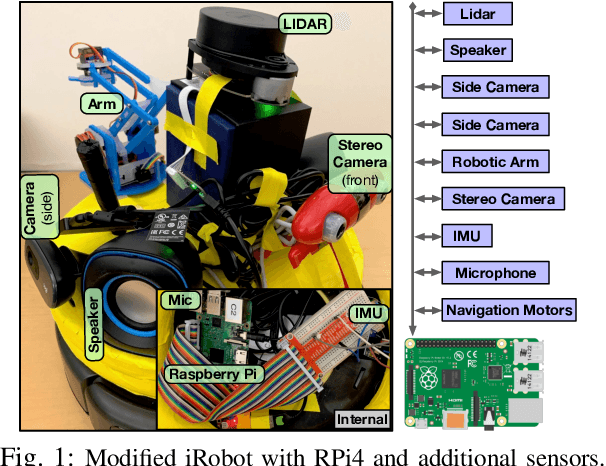
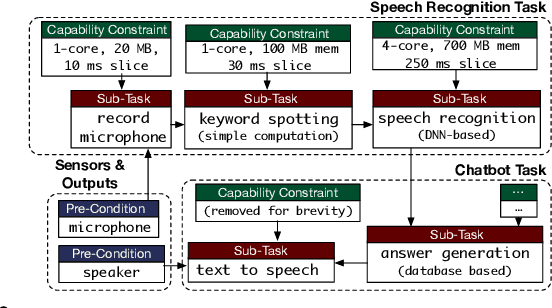
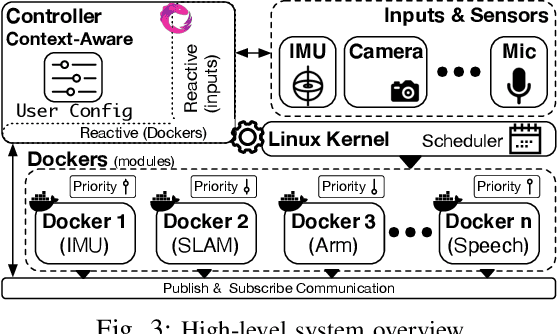
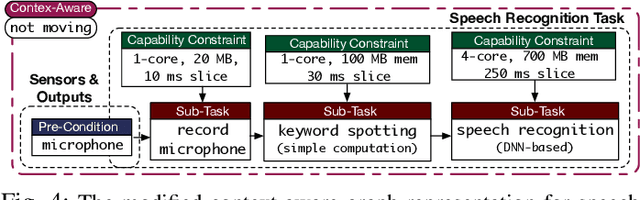
Intelligent mobile robots are critical in several scenarios. However, as their computational resources are limited, mobile robots struggle to handle several tasks concurrently and yet guaranteeing real-timeliness. To address this challenge and improve the real-timeliness of critical tasks under resource constraints, we propose a fast context-aware task handling technique. To effectively handling tasks in real-time, our proposed context-aware technique comprises of three main ingredients: (i) a dynamic time-sharing mechanism, coupled with (ii) an event-driven task scheduling using reactive programming paradigm to mindfully use the limited resources; and, (iii) a lightweight virtualized execution to easily integrate functionalities and their dependencies. We showcase our technique on a Raspberry-Pi-based robot with a variety of tasks such as Simultaneous localization and mapping (SLAM), sign detection, and speech recognition with a 42% speedup in total execution time compared to the common Linux scheduler.
Spatio-Temporal Graph Contrastive Learning
Aug 26, 2021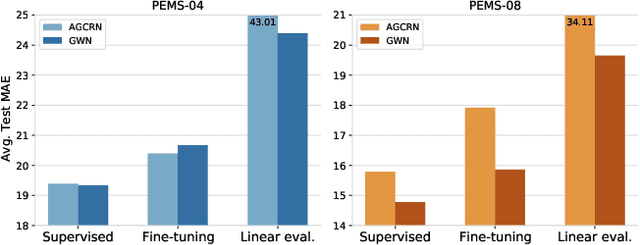
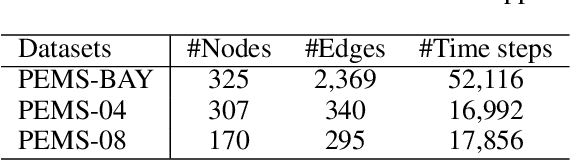
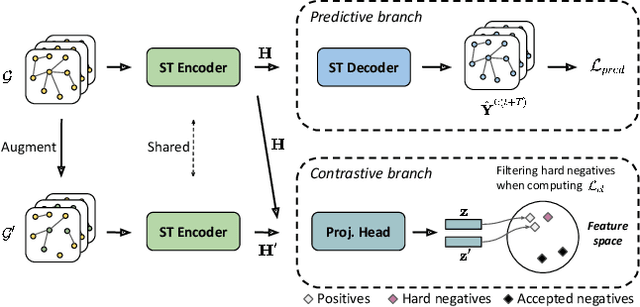
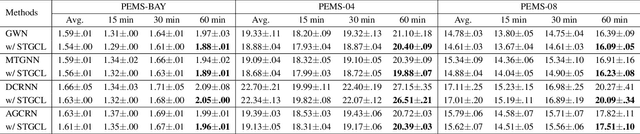
Deep learning models are modern tools for spatio-temporal graph (STG) forecasting. Despite their effectiveness, they require large-scale datasets to achieve better performance and are vulnerable to noise perturbation. To alleviate these limitations, an intuitive idea is to use the popular data augmentation and contrastive learning techniques. However, existing graph contrastive learning methods cannot be directly applied to STG forecasting due to three reasons. First, we empirically discover that the forecasting task is unable to benefit from the pretrained representations derived from contrastive learning. Second, data augmentations that are used for defeating noise are less explored for STG data. Third, the semantic similarity of samples has been overlooked. In this paper, we propose a Spatio-Temporal Graph Contrastive Learning framework (STGCL) to tackle these issues. Specifically, we improve the performance by integrating the forecasting loss with an auxiliary contrastive loss rather than using a pretrained paradigm. We elaborate on four types of data augmentations, which disturb data in terms of graph structure, time domain, and frequency domain. We also extend the classic contrastive loss through a rule-based strategy that filters out the most semantically similar negatives. Our framework is evaluated across three real-world datasets and four state-of-the-art models. The consistent improvements demonstrate that STGCL can be used as an off-the-shelf plug-in for existing deep models.
Embedding Information onto a Dynamical System
May 22, 2021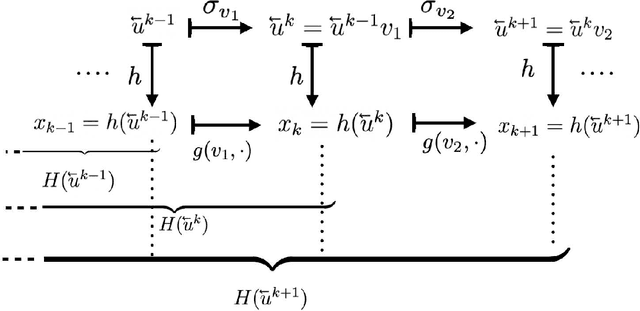
The celebrated Takens' embedding theorem concerns embedding an attractor of a dynamical system in a Euclidean space of appropriate dimension through a generic delay-observation map. The embedding also establishes a topological conjugacy. In this paper, we show how an arbitrary sequence can be mapped into another space as an attractive solution of a nonautonomous dynamical system. Such mapping also entails a topological conjugacy and an embedding between the sequence and the attractive solution spaces. This result is not a generalization of Takens embedding theorem but helps us understand what exactly is required by discrete-time state space models widely used in applications to embed an external stimulus onto its solution space. Our results settle another basic problem concerning the perturbation of an autonomous dynamical system. We describe what exactly happens to the dynamics when exogenous noise perturbs continuously a local irreducible attracting set (such as a stable fixed point) of a discrete-time autonomous dynamical system.
FoleyGAN: Visually Guided Generative Adversarial Network-Based Synchronous Sound Generation in Silent Videos
Jul 20, 2021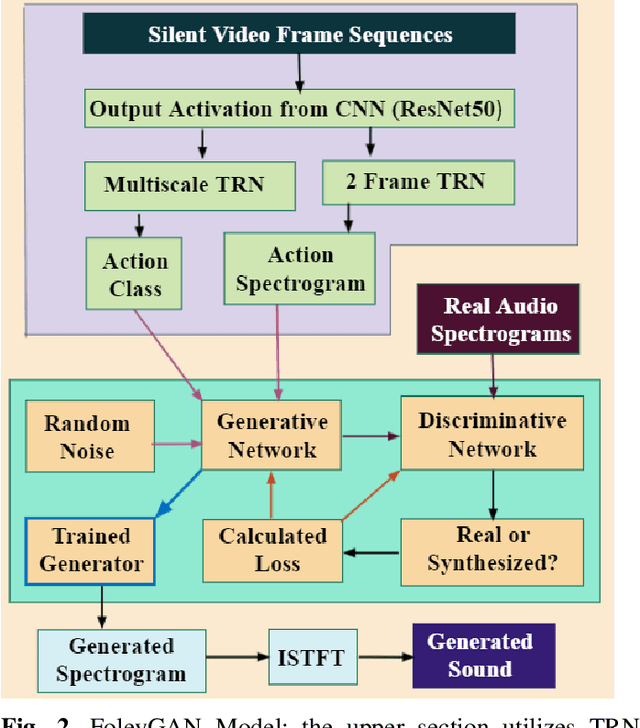
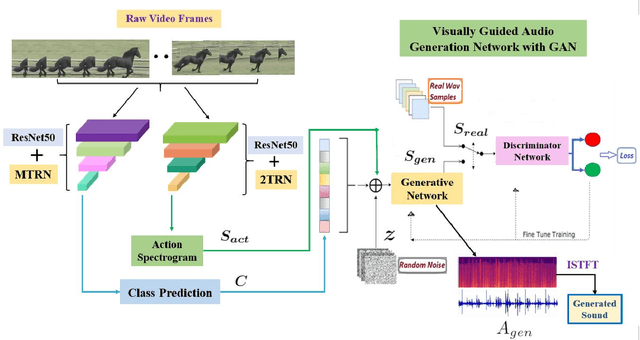
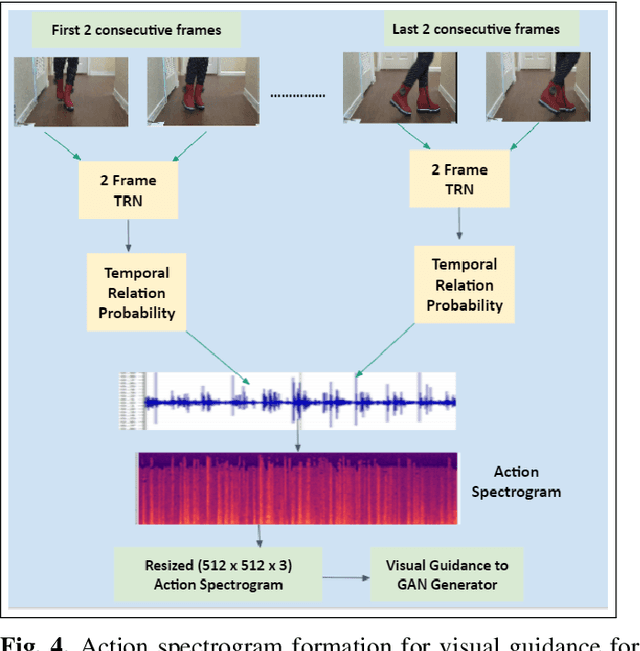
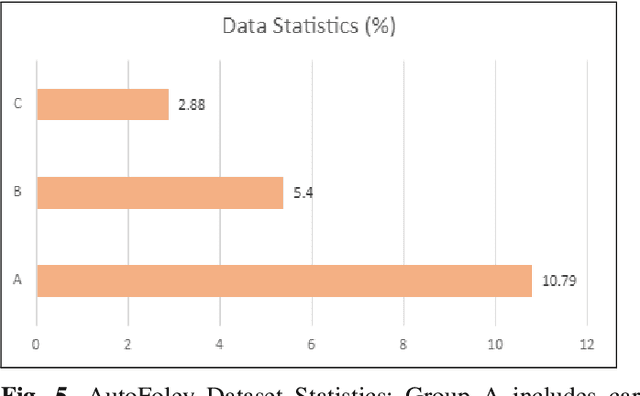
Deep learning based visual to sound generation systems essentially need to be developed particularly considering the synchronicity aspects of visual and audio features with time. In this research we introduce a novel task of guiding a class conditioned generative adversarial network with the temporal visual information of a video input for visual to sound generation task adapting the synchronicity traits between audio-visual modalities. Our proposed FoleyGAN model is capable of conditioning action sequences of visual events leading towards generating visually aligned realistic sound tracks. We expand our previously proposed Automatic Foley dataset to train with FoleyGAN and evaluate our synthesized sound through human survey that shows noteworthy (on average 81\%) audio-visual synchronicity performance. Our approach also outperforms in statistical experiments compared with other baseline models and audio-visual datasets.
Memory-efficient Learning for High-Dimensional MRI Reconstruction
Mar 06, 2021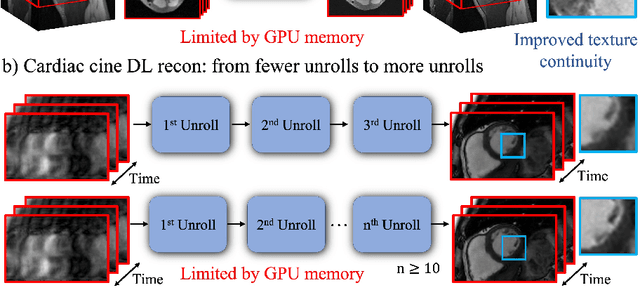

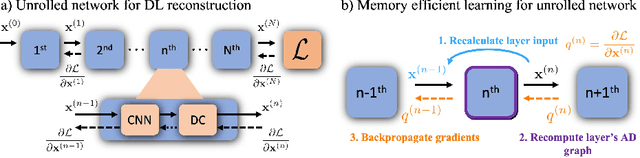
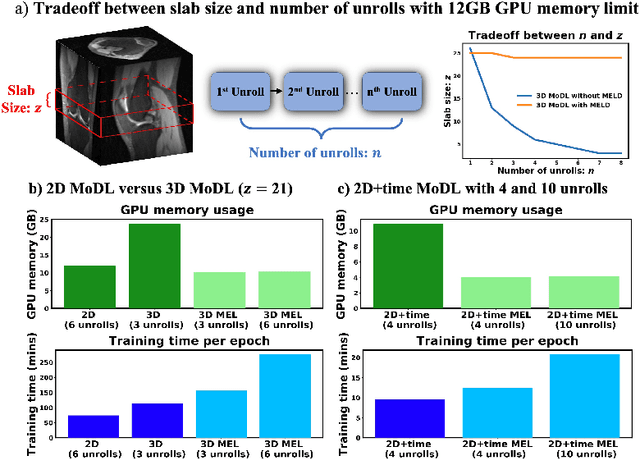
Deep learning (DL) based unrolled reconstructions have shown state-of-the-art performance for under-sampled magnetic resonance imaging (MRI). Similar to compressed sensing, DL can leverage high-dimensional data (e.g. 3D, 2D+time, 3D+time) to further improve performance. However, network size and depth are currently limited by the GPU memory required for backpropagation. Here we use a memory-efficient learning (MEL) framework which favorably trades off storage with a manageable increase in computation during training. Using MEL with multi-dimensional data, we demonstrate improved image reconstruction performance for in-vivo 3D MRI and 2D+time cardiac cine MRI. MEL uses far less GPU memory while marginally increasing the training time, which enables new applications of DL to high-dimensional MRI.
Magnetic Field Sensing for Pedestrian and Robot Indoor Positioning
Aug 26, 2021
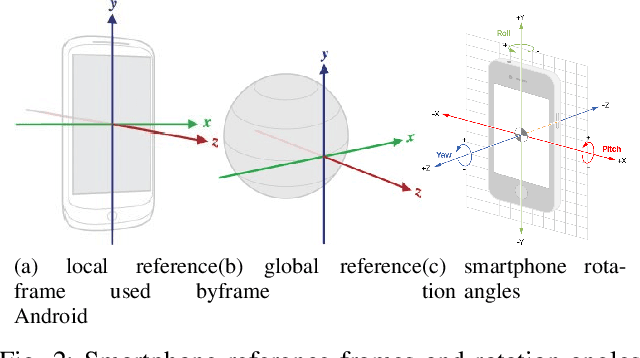
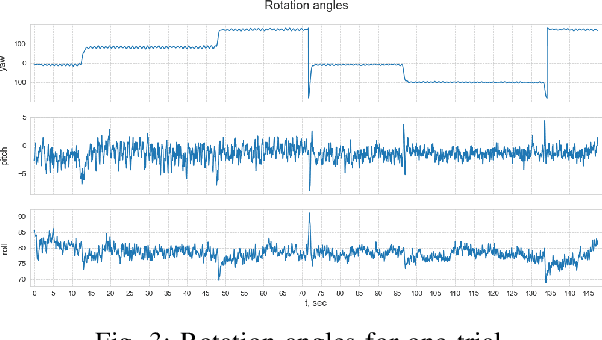
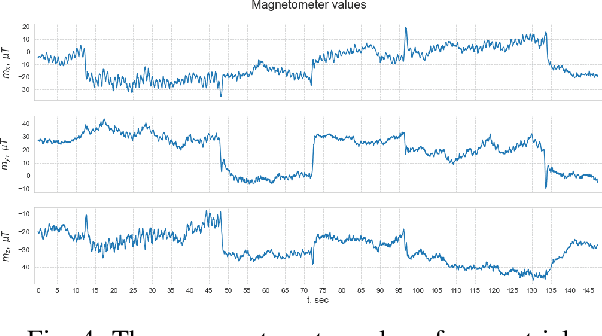
In this paper we address the problem of indoor localization using magnetic field data in two setups, when data is collected by (i) human-held mobile phone and (ii) by localization robots that perturb magnetic data with their own electromagnetic field. For the first setup, we revise the state of the art approaches and propose a novel extended pipeline to benefit from the presence of magnetic anomalies in indoor environment created by different ferromagnetic objects. We capture changes of the Earth's magnetic field due to indoor magnetic anomalies and transform them in multi-variate times series. We then convert temporal patterns into visual ones. We use methods of Recurrence Plots, Gramian Angular Fields and Markov Transition Fields to represent magnetic field time series as image sequences. We regress the continuous values of user position in a deep neural network that combines convolutional and recurrent layers. For the second setup, we analyze how magnetic field data get perturbed by robots' electromagnetic field. We add an alignment step to the main pipeline, in order to compensate the mismatch between train and test sets obtained by different robots. We test our methods on two public (MagPie and IPIN'20) and one proprietary (Hyundai department store) datasets. We report evaluation results and show that our methods outperform the state of the art methods by a large margin.
Machine learning moment closure models for the radiative transfer equation II: enforcing global hyperbolicity in gradient based closures
May 30, 2021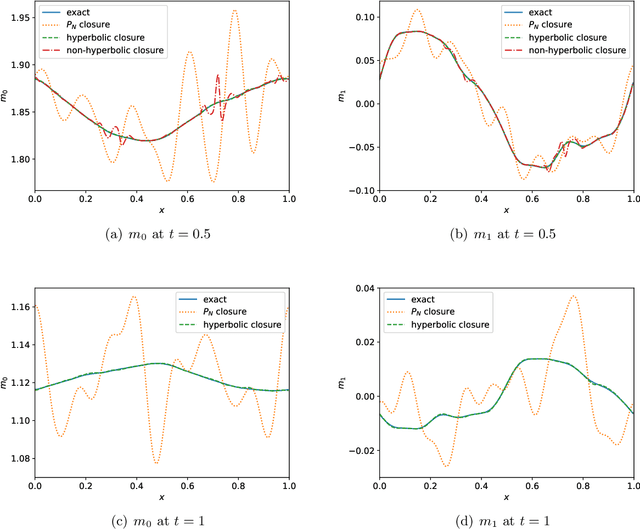
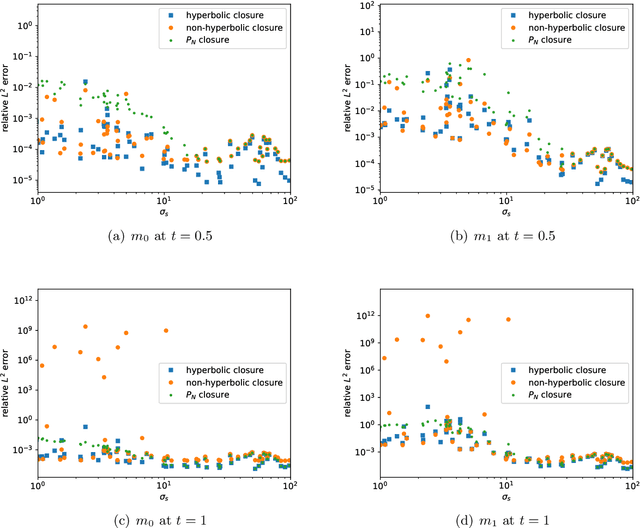
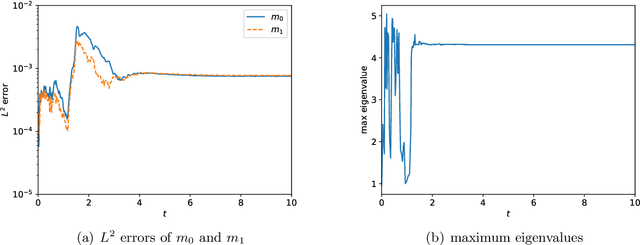
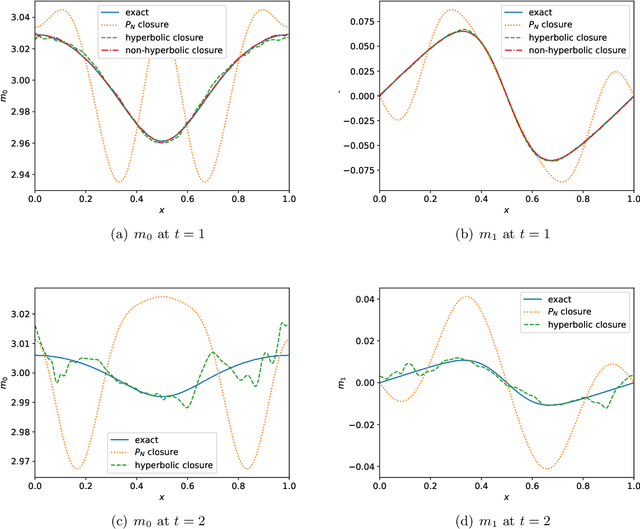
This is the second paper in a series in which we develop machine learning (ML) moment closure models for the radiative transfer equation (RTE). In our previous work \cite{huang2021gradient}, we proposed an approach to directly learn the gradient of the unclosed high order moment, which performs much better than learning the moment itself and the conventional $P_N$ closure. However, the ML moment closure model in \cite{huang2021gradient} is not able to guarantee hyperbolicity and long time stability. We propose in this paper a method to enforce the global hyperbolicity of the ML closure model. The main idea is to seek a symmetrizer (a symmetric positive definite matrix) for the closure system, and derive constraints such that the system is globally symmetrizable hyperbolic. It is shown that the new ML closure system inherits the dissipativeness of the RTE and preserves the correct diffusion limit as the Knunsden number goes to zero. Several benchmark tests including the Gaussian source problem and the two-material problem show the good accuracy, long time stability and generalizability of our globally hyperbolic ML closure model.
PatDNN: Achieving Real-Time DNN Execution on Mobile Devices with Pattern-based Weight Pruning
Jan 22, 2020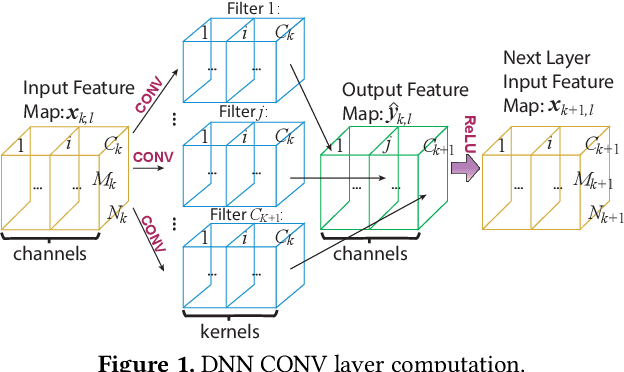
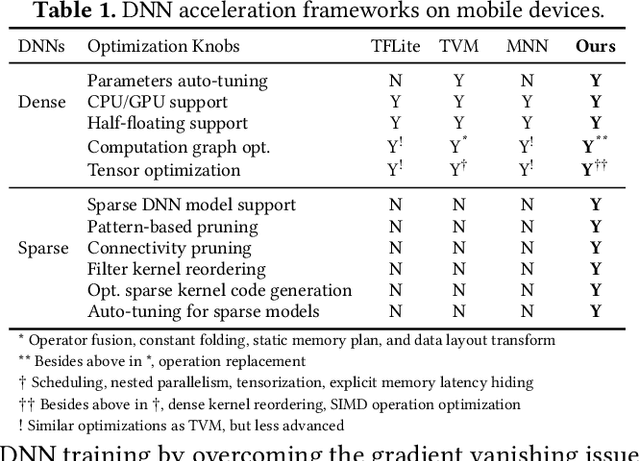
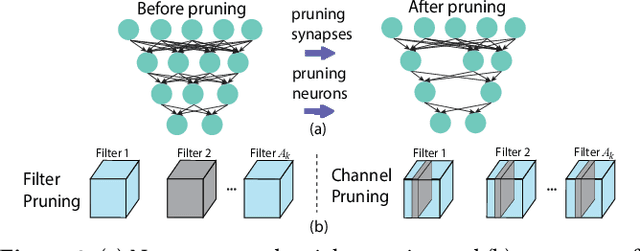
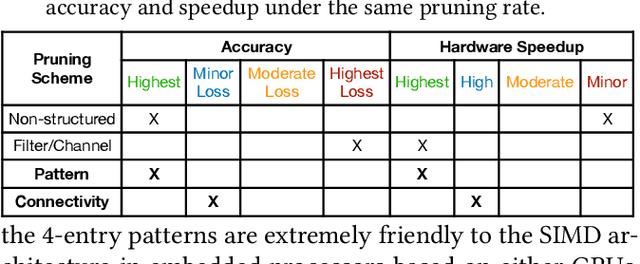
With the emergence of a spectrum of high-end mobile devices, many applications that formerly required desktop-level computation capability are being transferred to these devices. However, executing the inference of Deep Neural Networks (DNNs) is still challenging considering high computation and storage demands, specifically, if real-time performance with high accuracy is needed. Weight pruning of DNNs is proposed, but existing schemes represent two extremes in the design space: non-structured pruning is fine-grained, accurate, but not hardware friendly; structured pruning is coarse-grained, hardware-efficient, but with higher accuracy loss. In this paper, we introduce a new dimension, fine-grained pruning patterns inside the coarse-grained structures, revealing a previously unknown point in design space. With the higher accuracy enabled by fine-grained pruning patterns, the unique insight is to use the compiler to re-gain and guarantee high hardware efficiency. In other words, our method achieves the best of both worlds, and is desirable across theory/algorithm, compiler, and hardware levels. The proposed PatDNN is an end-to-end framework to efficiently execute DNN on mobile devices with the help of a novel model compression technique (pattern-based pruning based on extended ADMM solution framework) and a set of thorough architecture-aware compiler- and code generation-based optimizations (filter kernel reordering, compressed weight storage, register load redundancy elimination, and parameter auto-tuning). Evaluation results demonstrate that PatDNN outperforms three state-of-the-art end-to-end DNN frameworks, TensorFlow Lite, TVM, and Alibaba Mobile Neural Network with speedup up to 44.5x, 11.4x, and 7.1x, respectively, with no accuracy compromise. Real-time inference of representative large-scale DNNs (e.g., VGG-16, ResNet-50) can be achieved using mobile devices.
Disentangling What and Where for 3D Object-Centric Representations Through Active Inference
Aug 26, 2021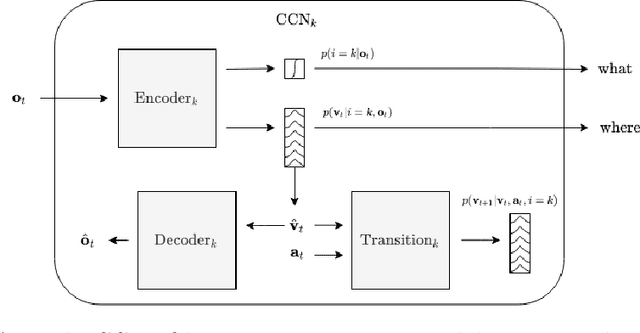
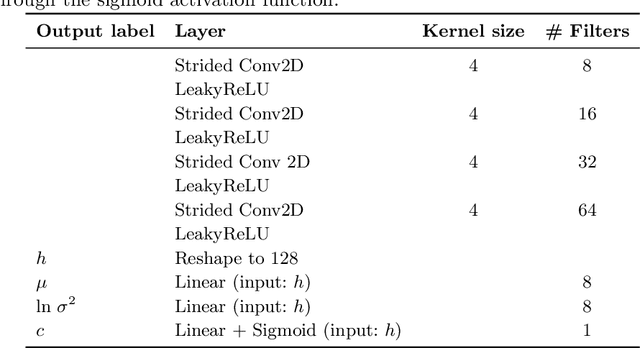
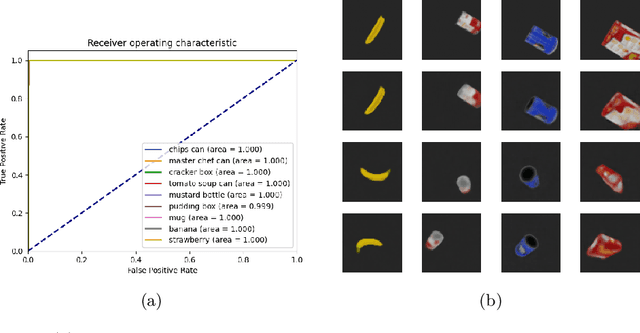
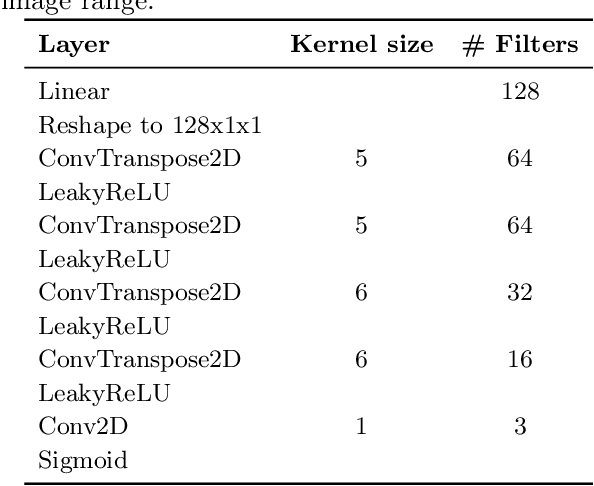
Although modern object detection and classification models achieve high accuracy, these are typically constrained in advance on a fixed train set and are therefore not flexible to deal with novel, unseen object categories. Moreover, these models most often operate on a single frame, which may yield incorrect classifications in case of ambiguous viewpoints. In this paper, we propose an active inference agent that actively gathers evidence for object classifications, and can learn novel object categories over time. Drawing inspiration from the human brain, we build object-centric generative models composed of two information streams, a what- and a where-stream. The what-stream predicts whether the observed object belongs to a specific category, while the where-stream is responsible for representing the object in its internal 3D reference frame. We show that our agent (i) is able to learn representations for many object categories in an unsupervised way, (ii) achieves state-of-the-art classification accuracies, actively resolving ambiguity when required and (iii) identifies novel object categories. Furthermore, we validate our system in an end-to-end fashion where the agent is able to search for an object at a given pose from a pixel-based rendering. We believe that this is a first step towards building modular, intelligent systems that can be used for a wide range of tasks involving three dimensional objects.
Position-based Dynamics Simulator of Brain Deformations for Path Planning and Intra-Operative Control in Keyhole Neurosurgery
Jun 18, 2021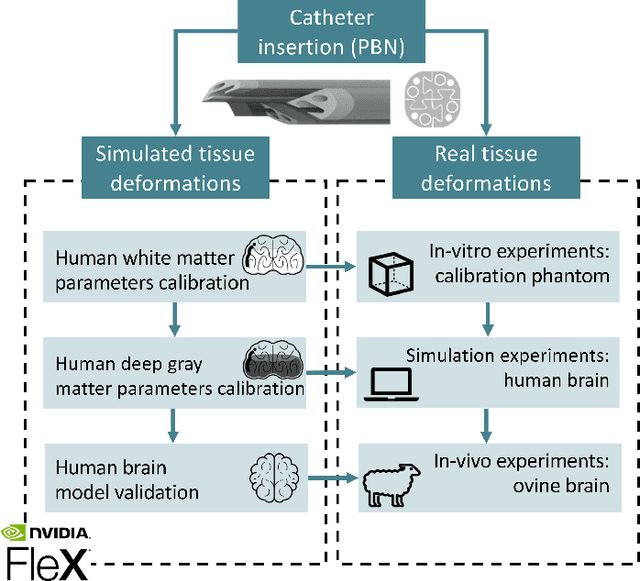
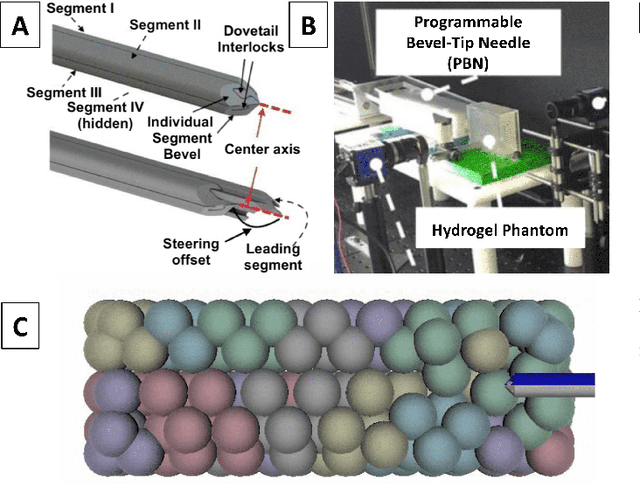
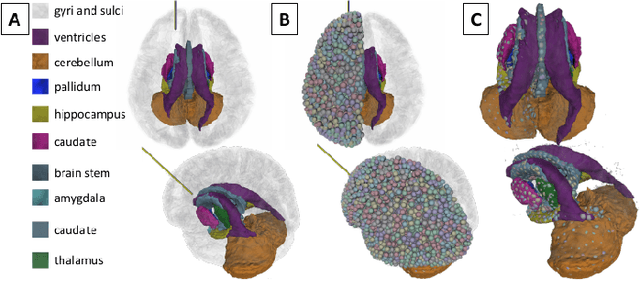
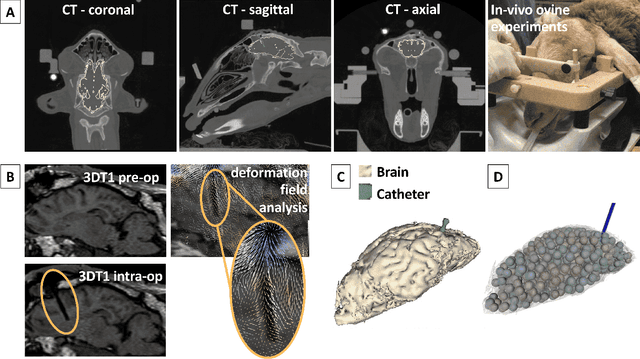
Many tasks in robot-assisted surgery require planning and controlling manipulators' motions that interact with highly deformable objects. This study proposes a realistic, time-bounded simulator based on Position-based Dynamics (PBD) simulation that mocks brain deformations due to catheter insertion for pre-operative path planning and intra-operative guidance in keyhole surgical procedures. It maximizes the probability of success by accounting for uncertainty in deformation models, noisy sensing, and unpredictable actuation. The PBD deformation parameters were initialized on a parallelepiped-shaped simulated phantom to obtain a reasonable starting guess for the brain white matter. They were calibrated by comparing the obtained displacements with deformation data for catheter insertion in a composite hydrogel phantom. Knowing the gray matter brain structures' different behaviors, the parameters were fine-tuned to obtain a generalized human brain model. The brain structures' average displacement was compared with values in the literature. The simulator's numerical model uses a novel approach with respect to the literature, and it has proved to be a close match with real brain deformations through validation using recorded deformation data of in-vivo animal trials with a mean mismatch of 4.73$\pm$2.15%. The stability, accuracy, and real-time performance make this model suitable for creating a dynamic environment for KN path planning, pre-operative path planning, and intra-operative guidance.