 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Safety Embedded Differential Dynamic Programming using Discrete Barrier States
May 30, 2021
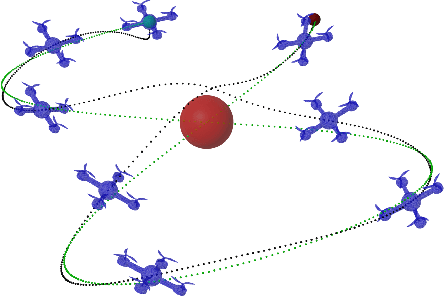
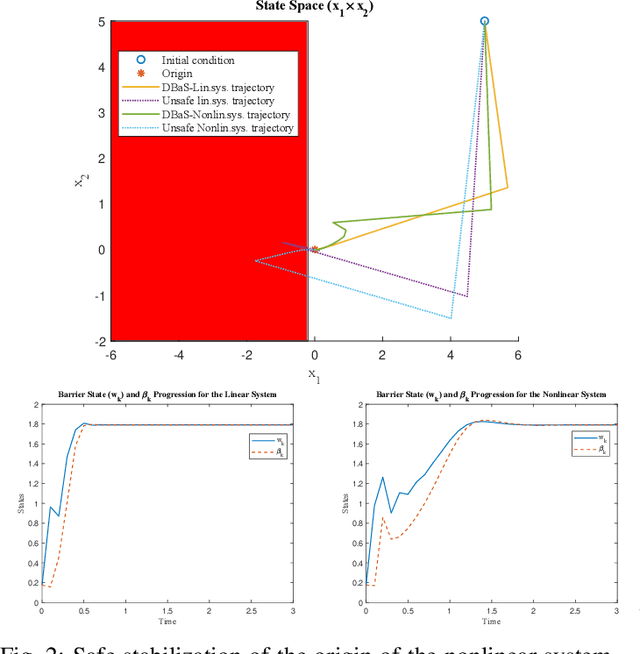
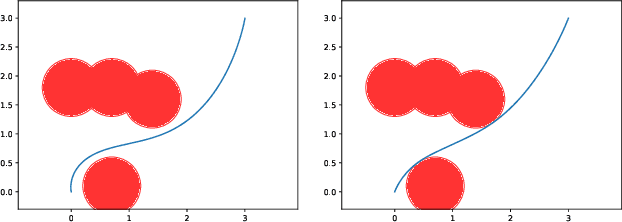
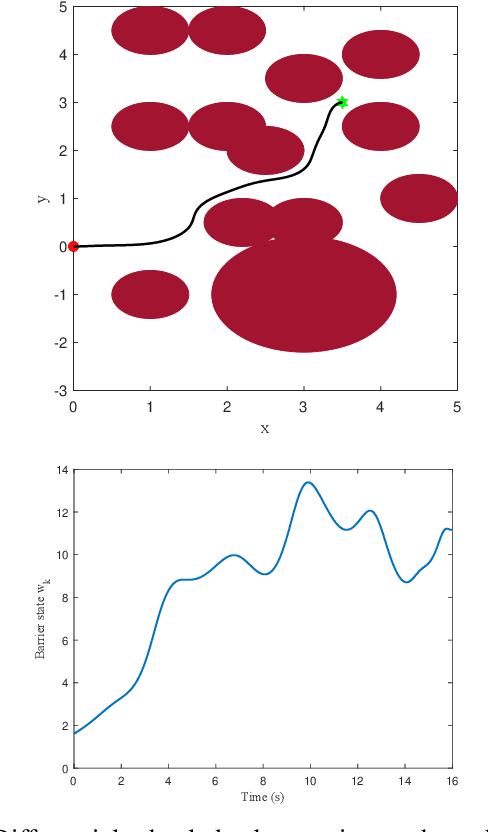
Certified safe control is a growing challenge in robotics, especially when performance and safety objectives are desired to be concurrently achieved. In this work, we extend the barrier state (BaS) concept, recently proposed for stabilization of continuous time systems, to enforce safety for discrete time systems by creating a discrete barrier state (DBaS). The constructed DBaS is embedded into the discrete model of the safety-critical system in order to integrate safety objectives into performance objectives. We subsequently use the proposed technique to implement a safety embedded stabilizing control for nonlinear discrete systems. Furthermore, we employ the DBaS method to develop a safety embedded differential dynamic programming (DDP) technique to plan and execute safe optimal trajectories. The proposed algorithm is leveraged on a differential wheeled robot and on a quadrotor to safely perform several tasks including reaching, tracking and safe multi-quadrotor movement. The DBaS-based DDP (DBaS-DDP) is compared to the penalty method used in constrained DDP problems where it is shown that the DBaS-DDP consistently outperforms the penalty method.
Organization and Understanding of a Tactile Information Dataset TacAct For Physical Human-Robot Interaction
Aug 09, 2021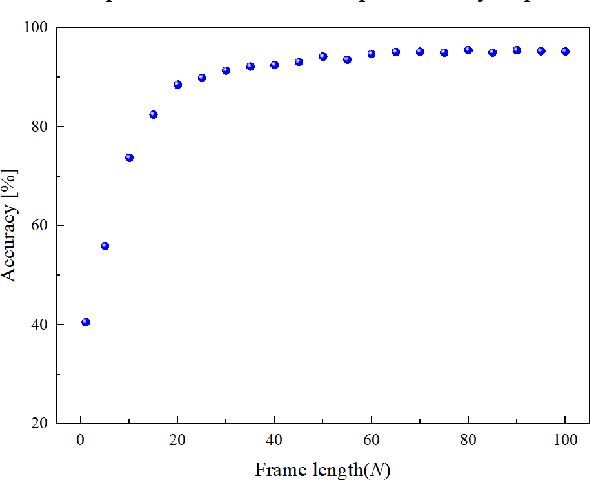

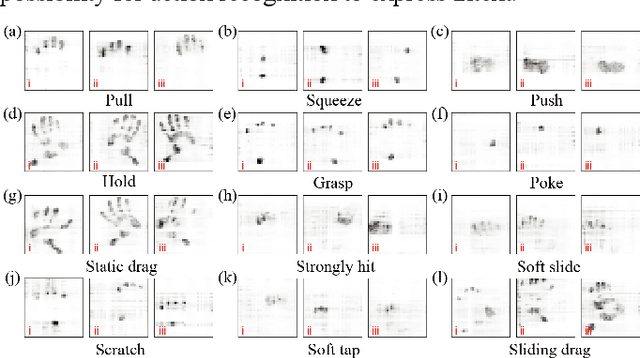
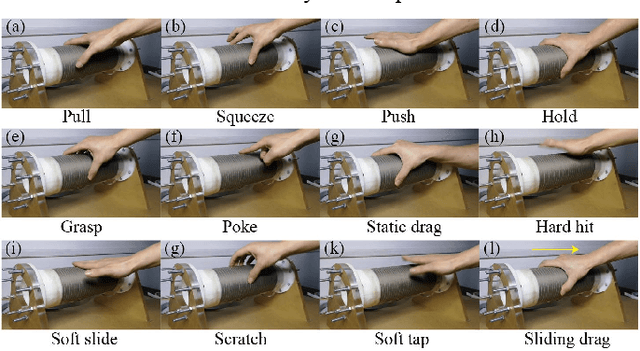
Human touching the robot to convey intentions or emotions is an essential communication pathway during physical Human-Robot Interaction (pHRI). Therefore, advanced service robots require superior tactile intelligence to guarantee naturalness and safety when making physical contact with human subjects. Tactile intelligence is the capability to percept and recognize tactile information from touch behaviors, in which understanding the physical meaning of touching actions is crucial. For this purpose, this report introduces a recently collected and organized dataset "TacAct" that encloses real-time tactile information when human subjects touched the test device mimicking a robot forearm. The dataset contains 12 types of 24,000 touch actions from 50 subjects. The dataset details are described, the data are preliminarily analyzed, and the validity of the dataset is tested through a convolutional neural network LeNet-5 which classifying different types of touch actions. We believe that the TacAct dataset would be beneficial for the community to understand the touch intention under various circumstances and to develop learning-based intelligent algorithms for different applications.
Reinforcement Learning for Optimal Stationary Control of Linear Stochastic Systems
Jul 16, 2021
This paper studies the optimal stationary control of continuous-time linear stochastic systems with both additive and multiplicative noises, using reinforcement learning techniques. Based on policy iteration, a novel off-policy reinforcement learning algorithm, named optimistic least-squares-based policy iteration, is proposed which is able to iteratively find near-optimal policies of the optimal stationary control problem directly from input/state data without explicitly identifying any system matrices, starting from an initial admissible control policy. The solutions given by the proposed optimistic least-squares-based policy iteration are proved to converge to a small neighborhood of the optimal solution with probability one, under mild conditions. The application of the proposed algorithm to a triple inverted pendulum example validates its feasibility and effectiveness.
Avalanche Photodetectors with Photon Trapping Structures for Biomedical Imaging Applications
Apr 27, 2021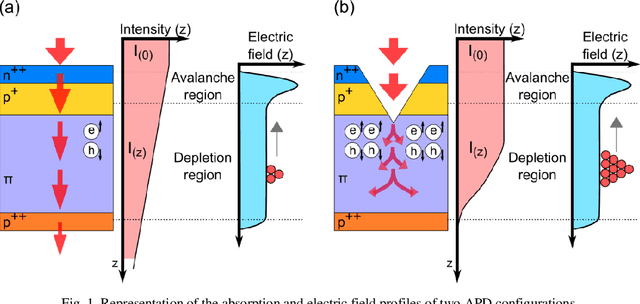
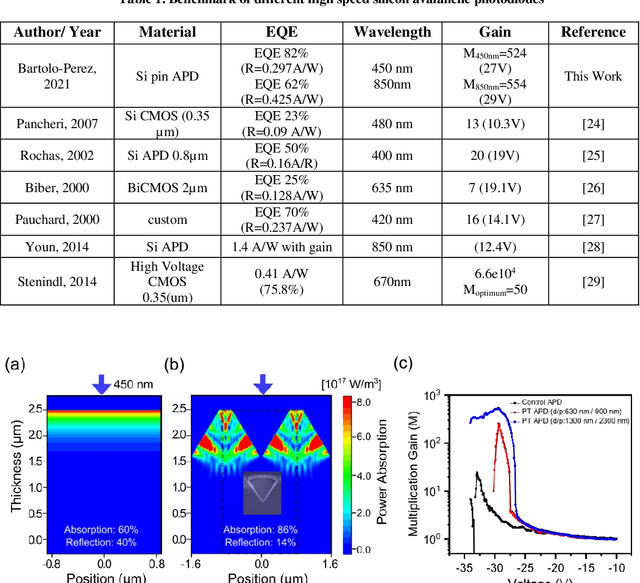
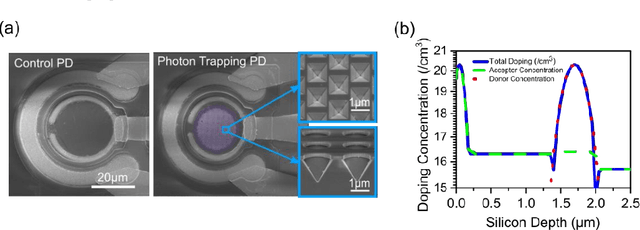
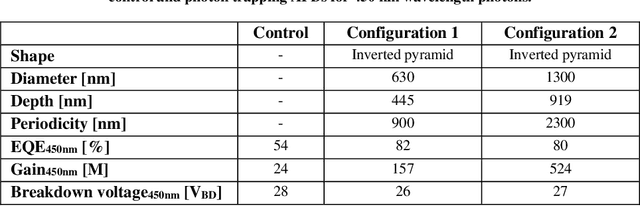
Enhancing photon detection efficiency and time resolution in photodetectors in the entire visible range is critical to improve the image quality of time-of-flight (TOF)-based imaging systems and fluorescence lifetime imaging (FLIM). In this work, we evaluate the gain, detection efficiency, and timing performance of avalanche photodiodes (APD) with photon trapping nanostructures for photons with 450 and 850 nm wavelengths. At 850 nm wavelength, our photon trapping avalanche photodiodes showed 30 times higher gain, an increase from 16% to >60% enhanced absorption efficiency, and a 50% reduction in the full width at half maximum (FWHM) pulse response time close to the breakdown voltage. At 450 nm wavelength, the external quantum efficiency increased from 54% to 82%, while the gain was enhanced more than 20-fold. Therefore, silicon APDs with photon trapping structures exhibited a dramatic increase in absorption compared to control devices. Results suggest very thin devices with fast timing properties and high absorption between the near-ultraviolet and the near infrared region can be manufactured for high-speed applications in biomedical imaging. This study paves the way towards obtaining single photon detectors with photon trapping structures with gains above 10^6 for the entire visible range
TIE: A Framework for Embedding-based Incremental Temporal Knowledge Graph Completion
Apr 17, 2021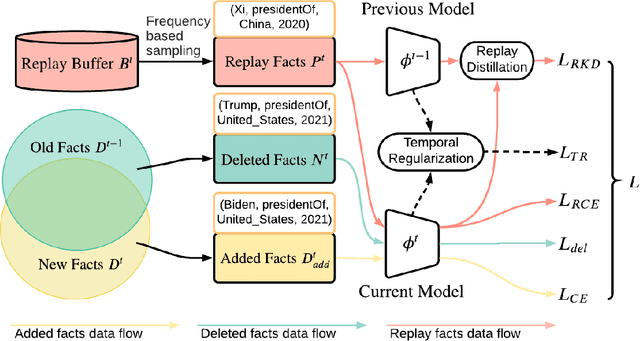

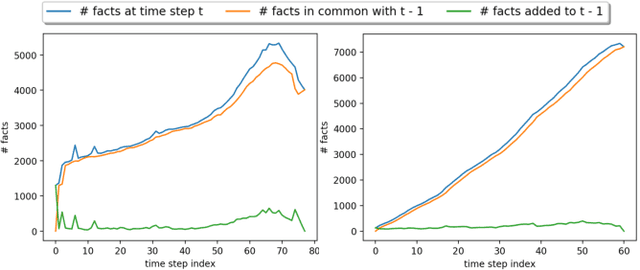
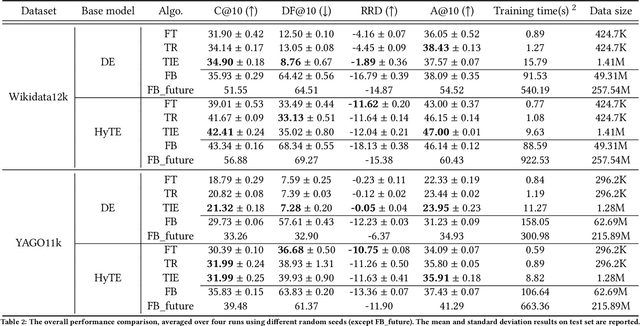
Reasoning in a temporal knowledge graph (TKG) is a critical task for information retrieval and semantic search. It is particularly challenging when the TKG is updated frequently. The model has to adapt to changes in the TKG for efficient training and inference while preserving its performance on historical knowledge. Recent work approaches TKG completion (TKGC) by augmenting the encoder-decoder framework with a time-aware encoding function. However, naively fine-tuning the model at every time step using these methods does not address the problems of 1) catastrophic forgetting, 2) the model's inability to identify the change of facts (e.g., the change of the political affiliation and end of a marriage), and 3) the lack of training efficiency. To address these challenges, we present the Time-aware Incremental Embedding (TIE) framework, which combines TKG representation learning, experience replay, and temporal regularization. We introduce a set of metrics that characterizes the intransigence of the model and propose a constraint that associates the deleted facts with negative labels. Experimental results on Wikidata12k and YAGO11k datasets demonstrate that the proposed TIE framework reduces training time by about ten times and improves on the proposed metrics compared to vanilla full-batch training. It comes without a significant loss in performance for any traditional measures. Extensive ablation studies reveal performance trade-offs among different evaluation metrics, which is essential for decision-making around real-world TKG applications.
Deep Sensor Fusion for Real-Time Odometry Estimation
Jul 31, 2019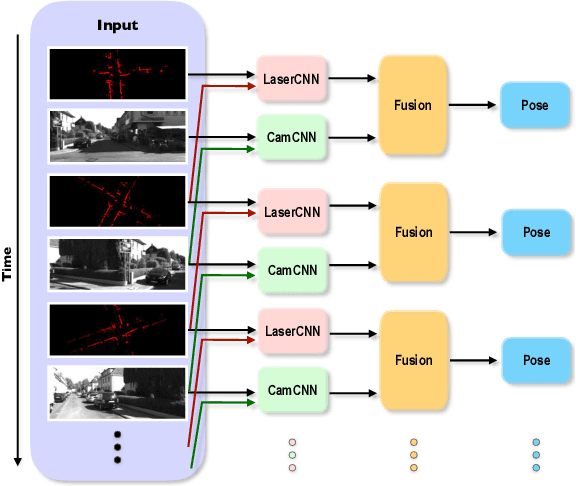
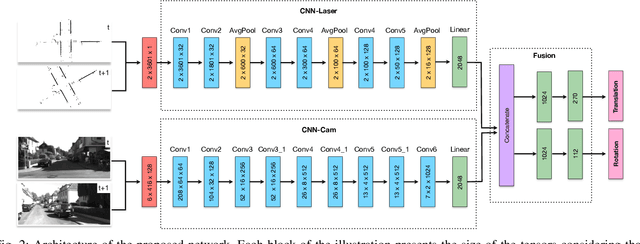
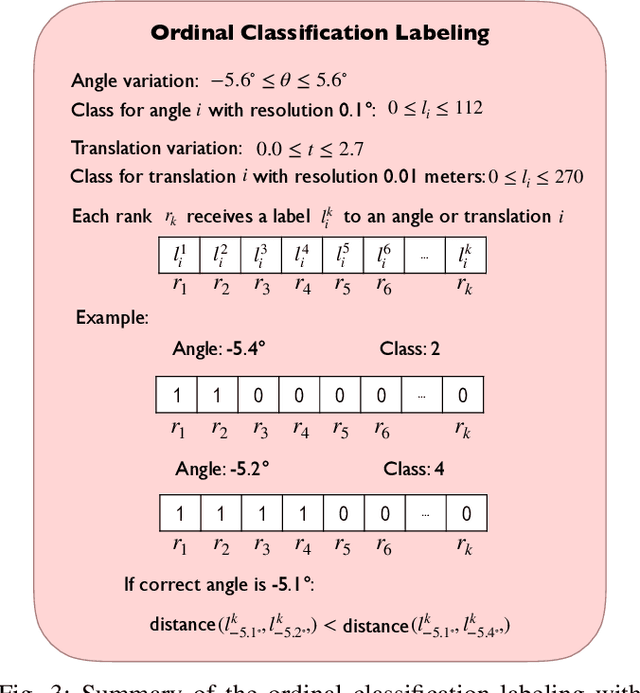
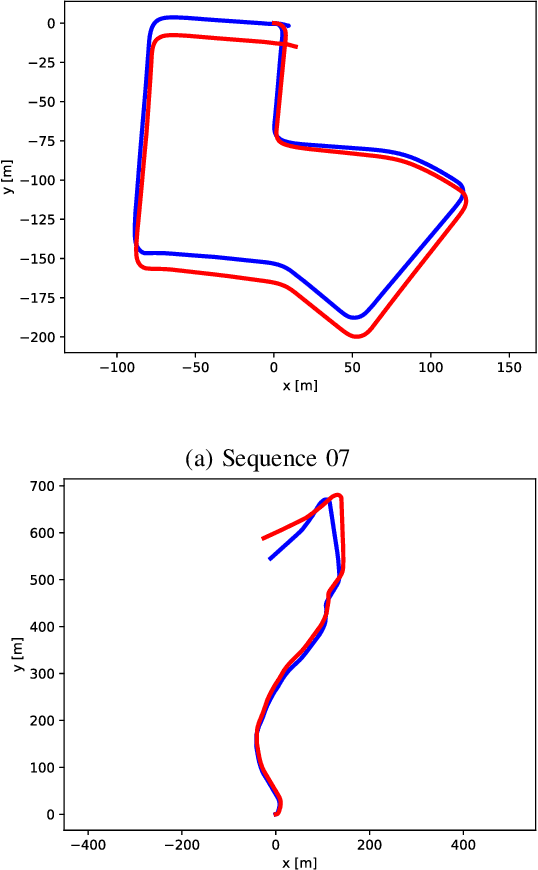
Cameras and 2D laser scanners, in combination, are able to provide low-cost, light-weight and accurate solutions, which make their fusion well-suited for many robot navigation tasks. However, correct data fusion depends on precise calibration of the rigid body transform between the sensors. In this paper we present the first framework that makes use of Convolutional Neural Networks (CNNs) for odometry estimation fusing 2D laser scanners and mono-cameras. The use of CNNs provides the tools to not only extract the features from the two sensors, but also to fuse and match them without needing a calibration between the sensors. We transform the odometry estimation into an ordinal classification problem in order to find accurate rotation and translation values between consecutive frames. Results on a real road dataset show that the fusion network runs in real-time and is able to improve the odometry estimation of a single sensor alone by learning how to fuse two different types of data information.
A new semi-supervised inductive transfer learning framework: Co-Transfer
Aug 21, 2021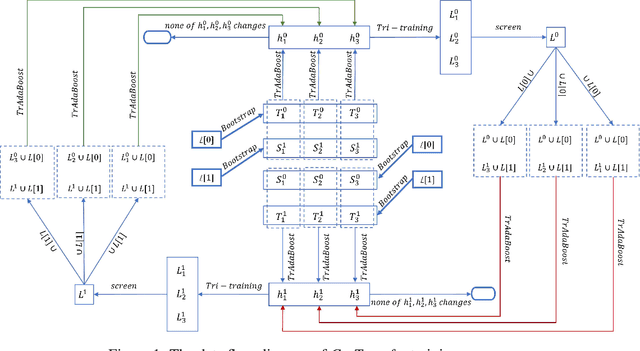
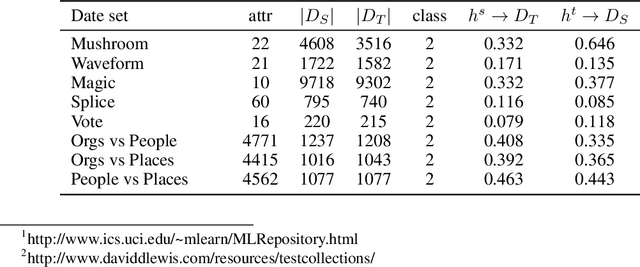
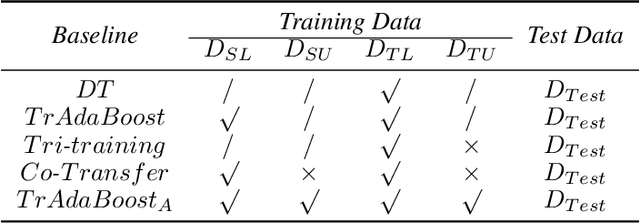
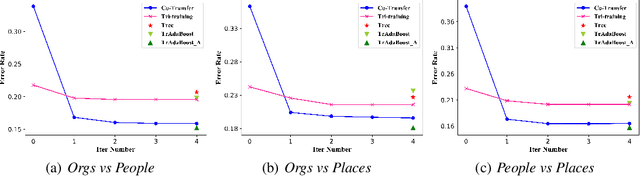
In many practical data mining scenarios, such as network intrusion detection, Twitter spam detection, and computer-aided diagnosis, a source domain that is different from but related to a target domain is very common. In addition, a large amount of unlabeled data is available in both source and target domains, but labeling each of them is difficult, expensive, time-consuming, and sometime unnecessary. Therefore, it is very important and worthwhile to fully explore the labeled and unlabeled data in source and target domains to settle the task in target domain. In this paper, a new semi-supervised inductive transfer learning framework, named Co-Transfer is proposed. Co-Transfer first generates three TrAdaBoost classifiers for transfer learning from the source domain to the target domain, and meanwhile another three TrAdaBoost classifiers are generated for transfer learning from the target domain to the source domain, using bootstraped samples from the original labeled data. In each round of co-transfer, each group of TrAdaBoost classifiers are refined using the carefully labeled data. Finally, the group of TrAdaBoost classifiers learned to transfer from the source domain to the target domain produce the final hypothesis. Experiments results illustrate Co-Transfer can effectively exploit and reuse the labeled and unlabeled data in source and target domains.
An Efficient Network for Predicting Time-Varying Distributions
Nov 05, 2018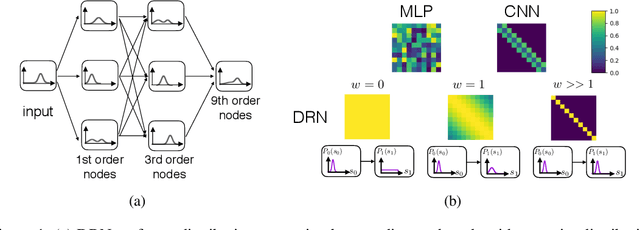
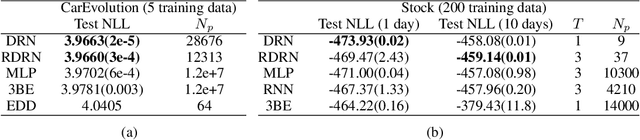
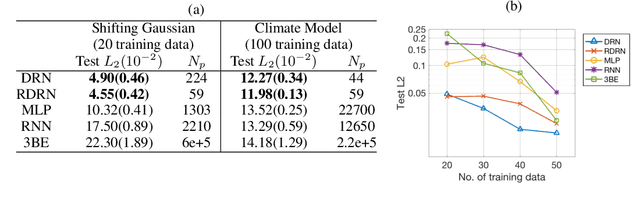

While deep neural networks have achieved groundbreaking prediction results in many tasks, there is a class of data where existing architectures are not optimal -- sequences of probability distributions. Performing forward prediction on sequences of distributions has many important applications. However, there are two main challenges in designing a network model for this task. First, neural networks are unable to encode distributions compactly as each node encodes just a real value. A recent work of Distribution Regression Network (DRN) solved this problem with a novel network that encodes an entire distribution in a single node, resulting in improved accuracies while using much fewer parameters than neural networks. However, despite its compact distribution representation, DRN does not address the second challenge, which is the need to model time dependencies in a sequence of distributions. In this paper, we propose our Recurrent Distribution Regression Network (RDRN) which adopts a recurrent architecture for DRN. The combination of compact distribution representation and shared weights architecture across time steps makes RDRN suitable for modeling the time dependencies in a distribution sequence. Compared to neural networks and DRN, RDRN achieves the best prediction performance while keeping the network compact.
The Fine-Grained Hardness of Sparse Linear Regression
Jun 06, 2021Sparse linear regression is the well-studied inference problem where one is given a design matrix $\mathbf{A} \in \mathbb{R}^{M\times N}$ and a response vector $\mathbf{b} \in \mathbb{R}^M$, and the goal is to find a solution $\mathbf{x} \in \mathbb{R}^{N}$ which is $k$-sparse (that is, it has at most $k$ non-zero coordinates) and minimizes the prediction error $||\mathbf{A} \mathbf{x} - \mathbf{b}||_2$. On the one hand, the problem is known to be $\mathcal{NP}$-hard which tells us that no polynomial-time algorithm exists unless $\mathcal{P} = \mathcal{NP}$. On the other hand, the best known algorithms for the problem do a brute-force search among $N^k$ possibilities. In this work, we show that there are no better-than-brute-force algorithms, assuming any one of a variety of popular conjectures including the weighted $k$-clique conjecture from the area of fine-grained complexity, or the hardness of the closest vector problem from the geometry of numbers. We also show the impossibility of better-than-brute-force algorithms when the prediction error is measured in other $\ell_p$ norms, assuming the strong exponential-time hypothesis.
Score-Based Point Cloud Denoising
Aug 15, 2021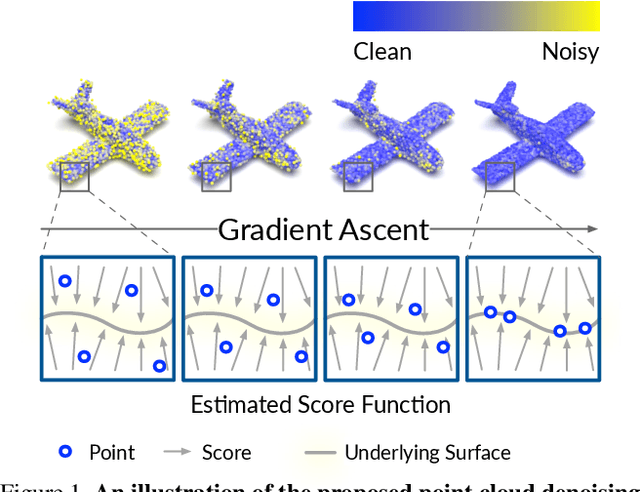
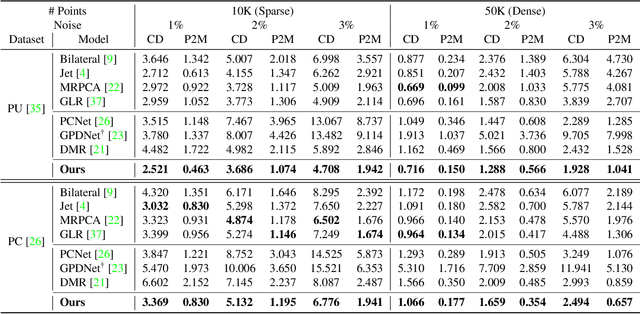
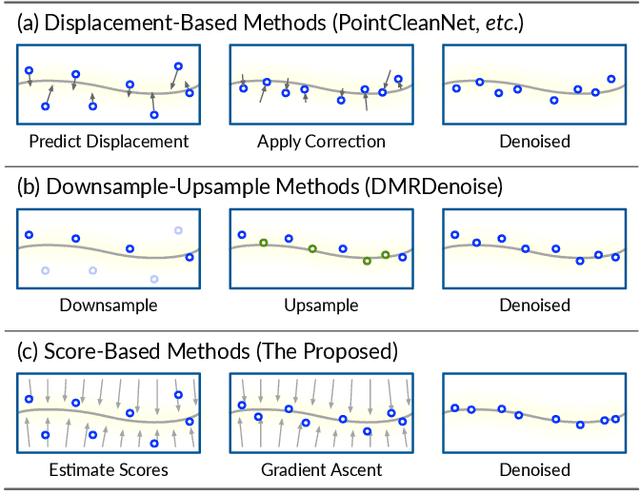
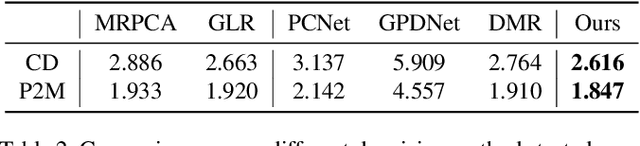
Point clouds acquired from scanning devices are often perturbed by noise, which affects downstream tasks such as surface reconstruction and analysis. The distribution of a noisy point cloud can be viewed as the distribution of a set of noise-free samples $p(x)$ convolved with some noise model $n$, leading to $(p * n)(x)$ whose mode is the underlying clean surface. To denoise a noisy point cloud, we propose to increase the log-likelihood of each point from $p * n$ via gradient ascent -- iteratively updating each point's position. Since $p * n$ is unknown at test-time, and we only need the score (i.e., the gradient of the log-probability function) to perform gradient ascent, we propose a neural network architecture to estimate the score of $p * n$ given only noisy point clouds as input. We derive objective functions for training the network and develop a denoising algorithm leveraging on the estimated scores. Experiments demonstrate that the proposed model outperforms state-of-the-art methods under a variety of noise models, and shows the potential to be applied in other tasks such as point cloud upsampling. The code is available at \url{https://github.com/luost26/score-denoise}.