 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Energy-Based Open-World Uncertainty Modeling for Confidence Calibration
Aug 16, 2021
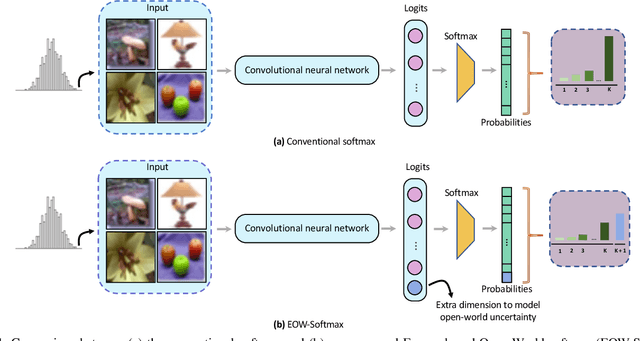
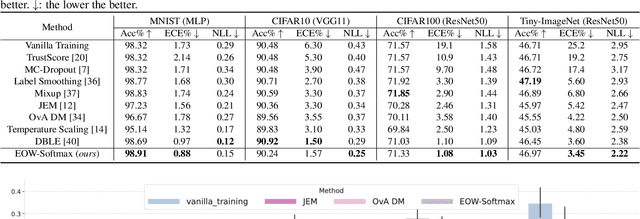
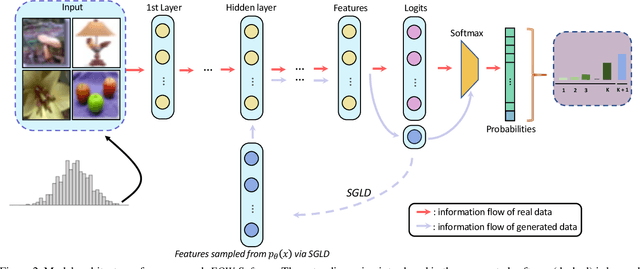
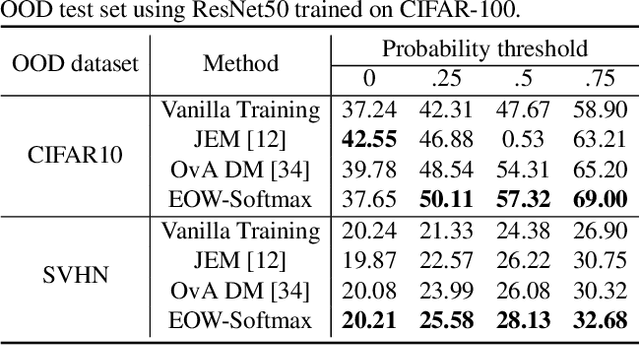
Confidence calibration is of great importance to the reliability of decisions made by machine learning systems. However, discriminative classifiers based on deep neural networks are often criticized for producing overconfident predictions that fail to reflect the true correctness likelihood of classification accuracy. We argue that such an inability to model uncertainty is mainly caused by the closed-world nature in softmax: a model trained by the cross-entropy loss will be forced to classify input into one of $K$ pre-defined categories with high probability. To address this problem, we for the first time propose a novel $K$+1-way softmax formulation, which incorporates the modeling of open-world uncertainty as the extra dimension. To unify the learning of the original $K$-way classification task and the extra dimension that models uncertainty, we propose a novel energy-based objective function, and moreover, theoretically prove that optimizing such an objective essentially forces the extra dimension to capture the marginal data distribution. Extensive experiments show that our approach, Energy-based Open-World Softmax (EOW-Softmax), is superior to existing state-of-the-art methods in improving confidence calibration.
Deep Learning Radio Frequency Signal Classification with Hybrid Images
May 19, 2021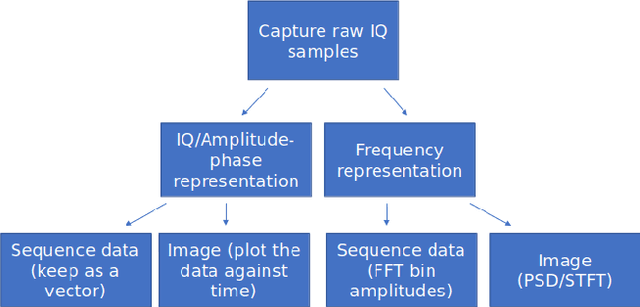
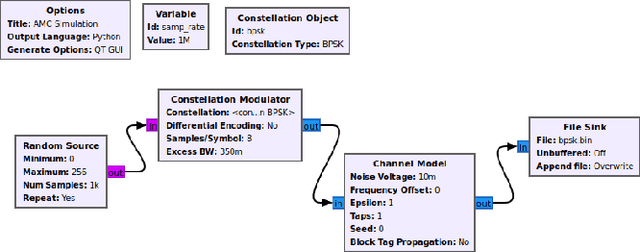
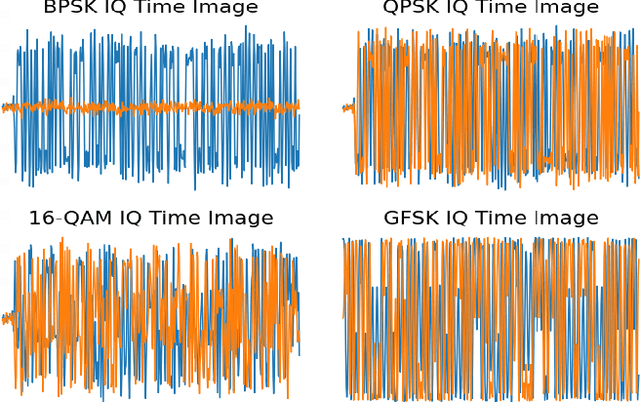
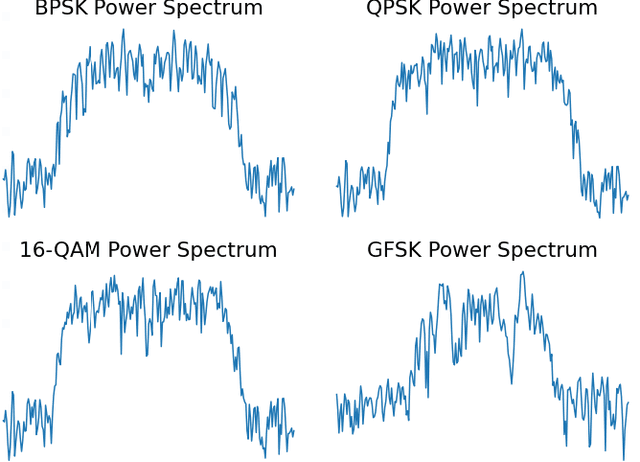
In recent years, Deep Learning (DL) has been successfully applied to detect and classify Radio Frequency (RF) Signals. A DL approach is especially useful since it identifies the presence of a signal without needing full protocol information, and can also detect and/or classify non-communication waveforms, such as radar signals. In this work, we focus on the different pre-processing steps that can be used on the input training data, and test the results on a fixed DL architecture. While previous works have mostly focused exclusively on either time-domain or frequency domain approaches, we propose a hybrid image that takes advantage of both time and frequency domain information, and tackles the classification as a Computer Vision problem. Our initial results point out limitations to classical pre-processing approaches while also showing that it's possible to build a classifier that can leverage the strengths of multiple signal representations.
TFRD: A Benchmark Dataset for Research on Temperature Field Reconstruction of Heat-Source Systems
Aug 28, 2021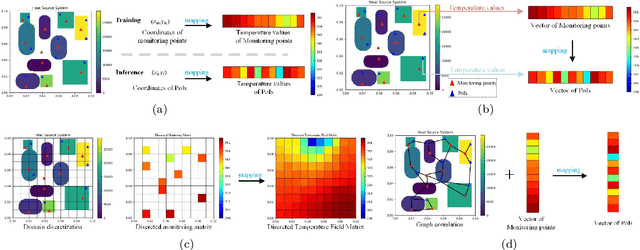
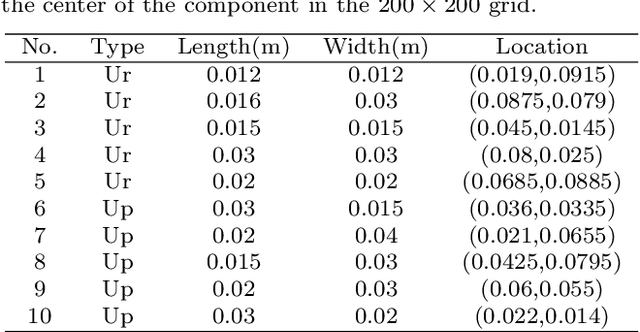
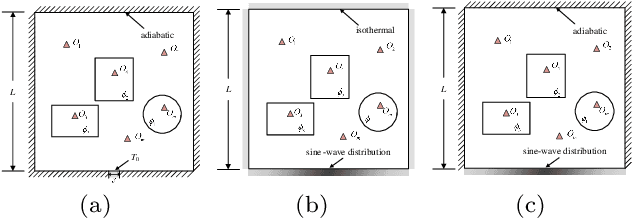
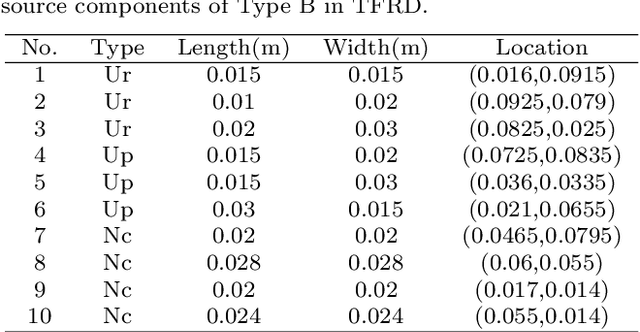
Temperature field reconstruction of heat source systems (TFR-HSS) with limited monitoring sensors occurred in thermal management plays an important role in real time health detection system of electronic equipment in engineering. However, prior methods with common interpolations usually cannot provide accurate reconstruction performance as needed. In addition, there exists no public dataset for widely research of reconstruction methods to further boost the reconstruction performance and engineering applications. To overcome this problem, this work constructs a novel dataset, namely Temperature Field Reconstruction Dataset (TFRD), for TFR-HSS task with commonly used methods, including the interpolation methods and the machine learning based methods, as baselines to advance the research over temperature field reconstruction. First, the TFR-HSS task is mathematically modelled from real-world engineering problem and four types of numerically modellings have been constructed to transform the problem into discrete mapping forms. Besides, this work selects three typical reconstruction problem over heat-source systems with different heat-source information and boundary conditions, and generate the training and testing samples for further research. Finally, a comprehensive review of the prior methods for TFR-HSS task as well as recent widely used deep learning methods is given and a performance analysis of typical methods is provided on TFRD, which can be served as the baseline results on this benchmark.
An Extensible Benchmark Suite for Learning to Simulate Physical Systems
Aug 09, 2021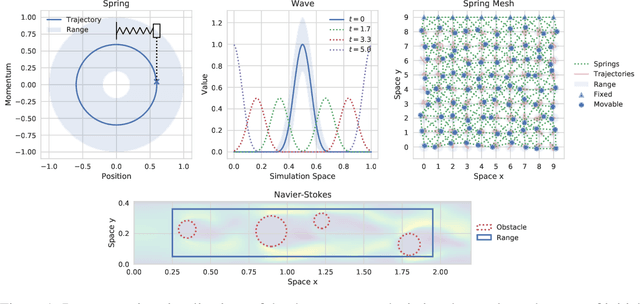

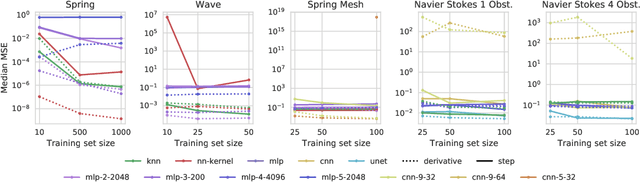
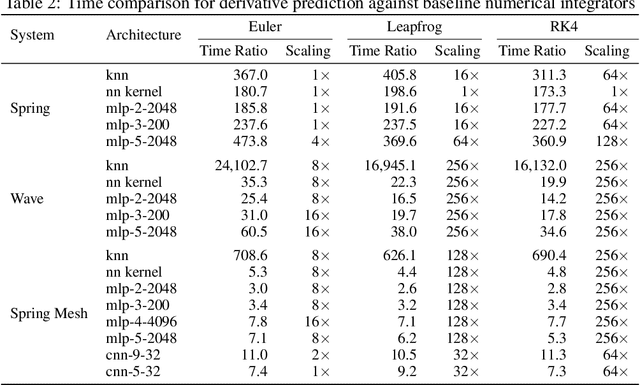
Simulating physical systems is a core component of scientific computing, encompassing a wide range of physical domains and applications. Recently, there has been a surge in data-driven methods to complement traditional numerical simulations methods, motivated by the opportunity to reduce computational costs and/or learn new physical models leveraging access to large collections of data. However, the diversity of problem settings and applications has led to a plethora of approaches, each one evaluated on a different setup and with different evaluation metrics. We introduce a set of benchmark problems to take a step towards unified benchmarks and evaluation protocols. We propose four representative physical systems, as well as a collection of both widely used classical time integrators and representative data-driven methods (kernel-based, MLP, CNN, nearest neighbors). Our framework allows evaluating objectively and systematically the stability, accuracy, and computational efficiency of data-driven methods. Additionally, it is configurable to permit adjustments for accommodating other learning tasks and for establishing a foundation for future developments in machine learning for scientific computing.
Scaling New Peaks: A Viewership-centric Approach to Automated Content Curation
Aug 09, 2021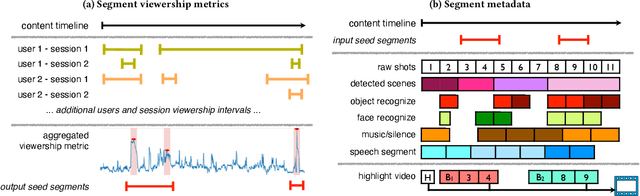
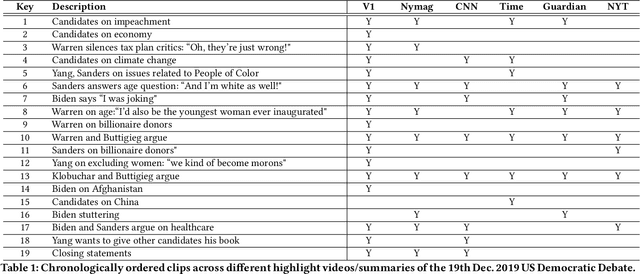
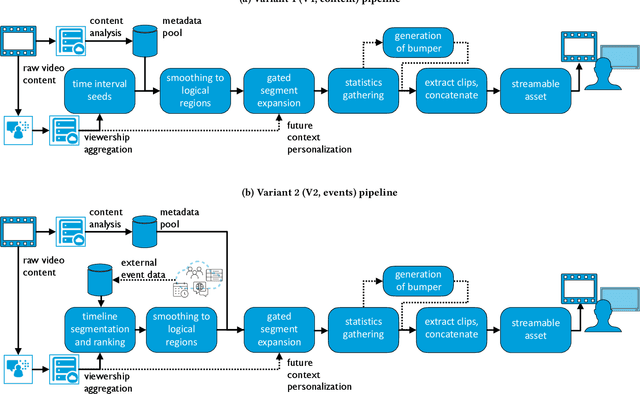
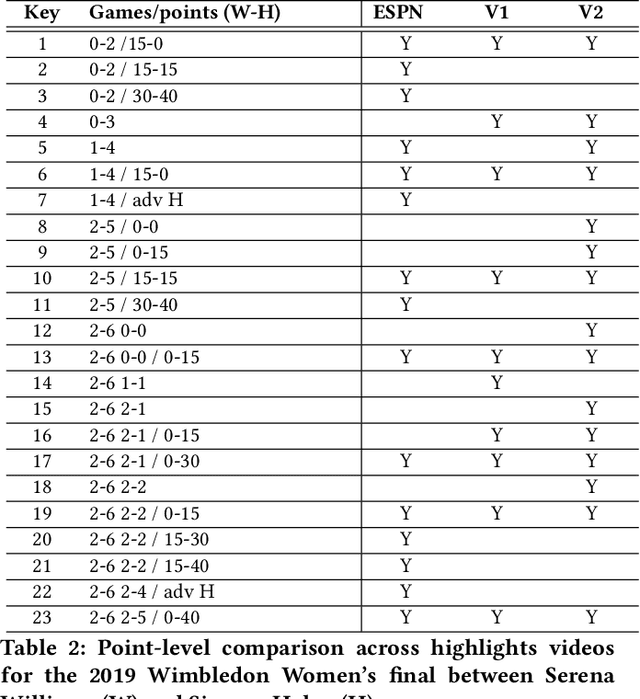
Summarizing video content is important for video streaming services to engage the user in a limited time span. To this end, current methods involve manual curation or using passive interest cues to annotate potential high-interest segments to form the basis of summarized videos, and are costly and unreliable. We propose a viewership-driven, automated method that accommodates a range of segment identification goals. Using satellite television viewership data as a source of ground truth for viewer interest, we apply statistical anomaly detection on a timeline of viewership metrics to identify 'seed' segments of high viewer interest. These segments are post-processed using empirical rules and several sources of content metadata, e.g. shot boundaries, adding in personalization aspects to produce the final highlights video. To demonstrate the flexibility of our approach, we present two case studies, on the United States Democratic Presidential Debate on 19th December 2019, and Wimbledon Women's Final 2019. We perform qualitative comparisons with their publicly available highlights, as well as early vs. late viewership comparisons for insights into possible media and social influence on viewing behavior.
Novel scorpion detection system combining computer vision and fluorescence
Aug 09, 2021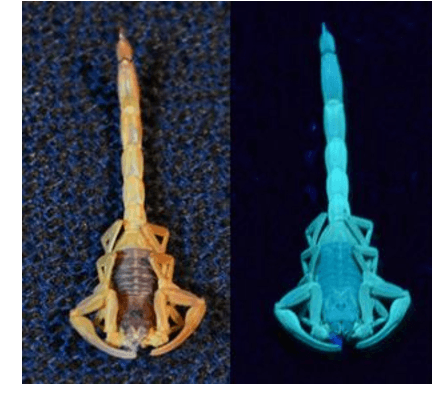
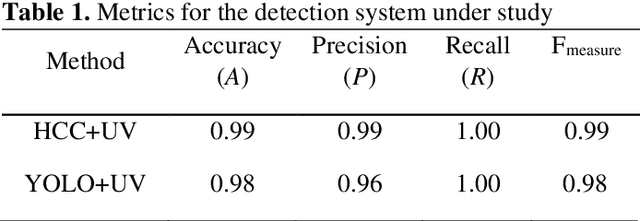
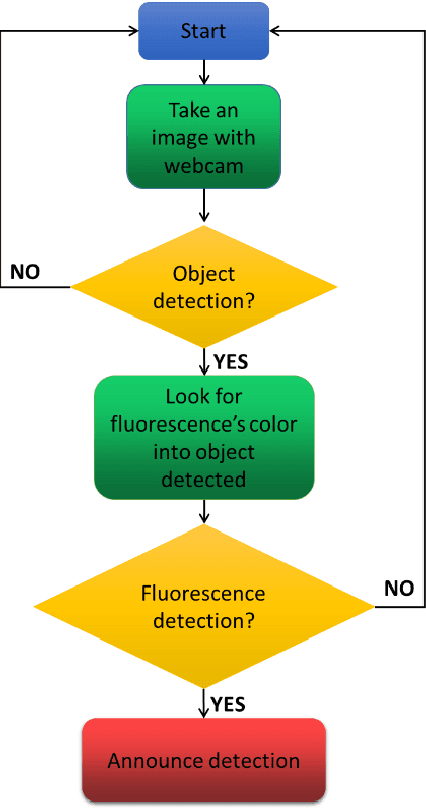

In this work, a fully automatic and real-time system for the detection of scorpions was developed using computer vision and deep learning techniques. This system is based on the implementation of a double validation process using the shape features and the fluorescent characteristics of scorpions when exposed to ultraviolet (UV) light. The Haar Cascade Classifier (HCC) and YOLO (You Only Look Once) models have been used and compared as the first mechanism for the scorpion shape detection. The detection of the fluorescence emitted by the scorpions under UV light has been used as a second detection mechanism in order to increase the accuracy and precision of the system. The results obtained show that the system can accurately and reliably detect the presence of scorpions. In addition, values obtained of recall of 100% is essential with the purpose of providing a health security tool. Although the developed system can only be used at night or in dark environment, where the fluorescence emitted by the scorpions can be visualized, the nocturnal activity of scorpions justifies the incorporation of this second validation mechanism.
MARViN -- Multiple Arithmetic Resolutions Vacillating in Neural Networks
Aug 09, 2021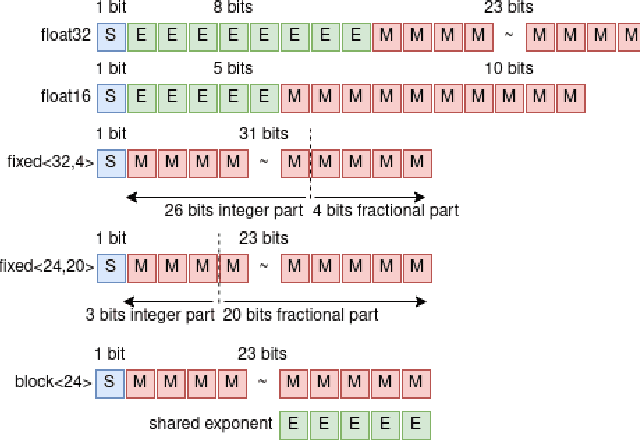
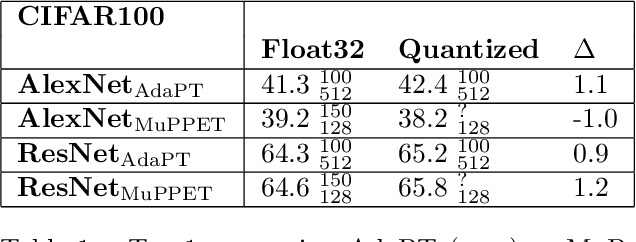

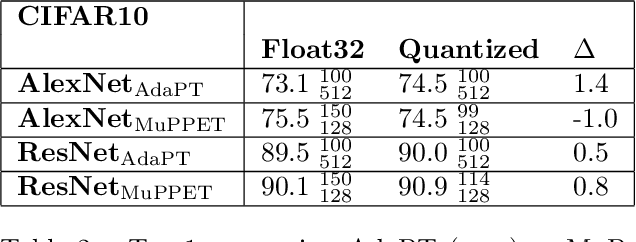
Quantization is a technique for reducing deep neural networks (DNNs) training and inference times, which is crucial for training in resource constrained environments or time critical inference applications. State-of-the-art (SOTA) quantization approaches focus on post-training quantization, i.e. quantization of pre-trained DNNs for speeding up inference. Very little work on quantized training exists, which neither al-lows dynamic intra-epoch precision switches nor em-ploys an information theory based switching heuristic. Usually, existing approaches require full precision refinement afterwards and enforce a global word length across the whole DNN. This leads to suboptimal quantization mappings and resource usage. Recognizing these limits, we introduce MARViN, a new quantized training strategy using information theory-based intra-epoch precision switching, which decides on a per-layer basis which precision should be used in order to minimize quantization-induced information loss. Note that any quantization must leave enough precision such that future learning steps do not suffer from vanishing gradients. We achieve an average speedup of 1.86 compared to a float32 basis while limiting mean accuracy degradation on AlexNet/ResNet to only -0.075%.
A rasterized ray-tracer pipeline for real-time, multi-device sonar simulation
Jan 08, 2020
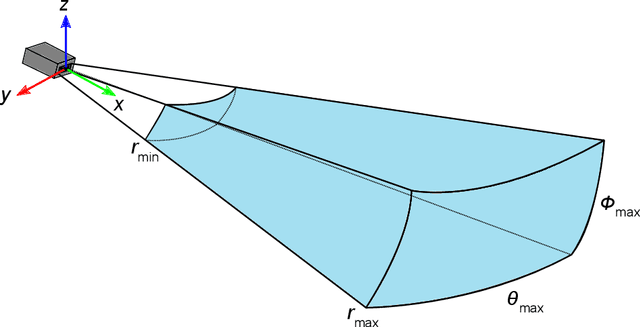
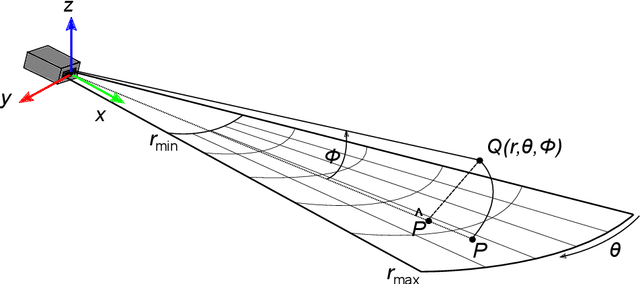

Simulating sonar devices requires modeling complex underwater acoustics, simultaneously rendering time-efficient data. Existing methods focus on basic implementation of one sonar type, where most of sound properties are disregarded. In this context, this work presents a multi-device sonar simulator capable of processing an underwater scene by a hybrid pipeline on GPU: Rasterization computes the primary intersections, while only the reflective areas are ray-traced. Our proposed system launches few rays when compared to a full ray-tracing based method, achieving a significant performance gain without quality loss in the final rendering. Resulting reflections are then characterized as two sonar parameters: Echo intensity and pulse distance. Underwater acoustic features, such as speckle noise, transmission loss, reverberation and material properties of observable objects are also computed in the final generated acoustic image. Visual and numerical performance assessments demonstrated the effectiveness of the proposed simulator to render underwater scenes in comparison to real-world sonar devices.
Safety Embedded Differential Dynamic Programming using Discrete Barrier States
May 30, 2021
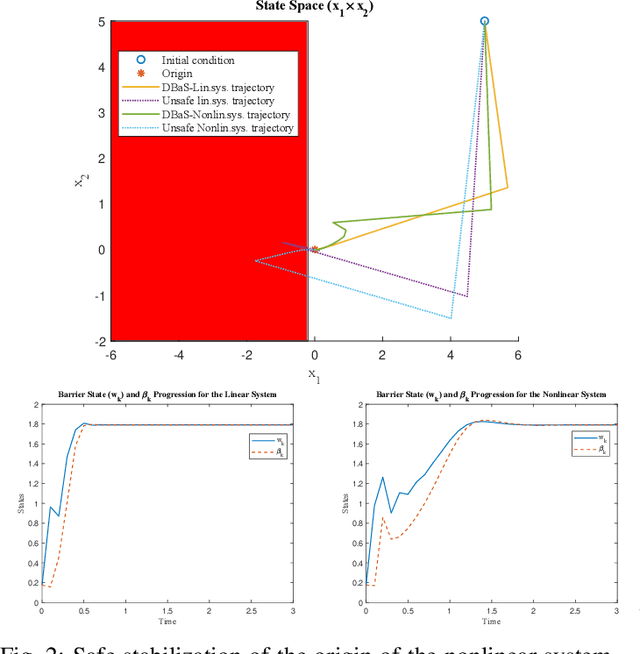
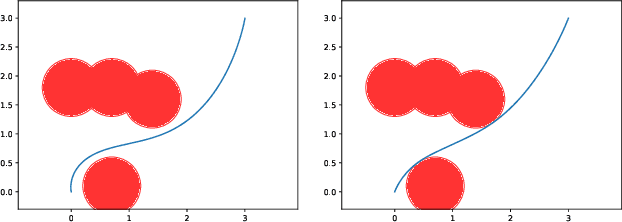
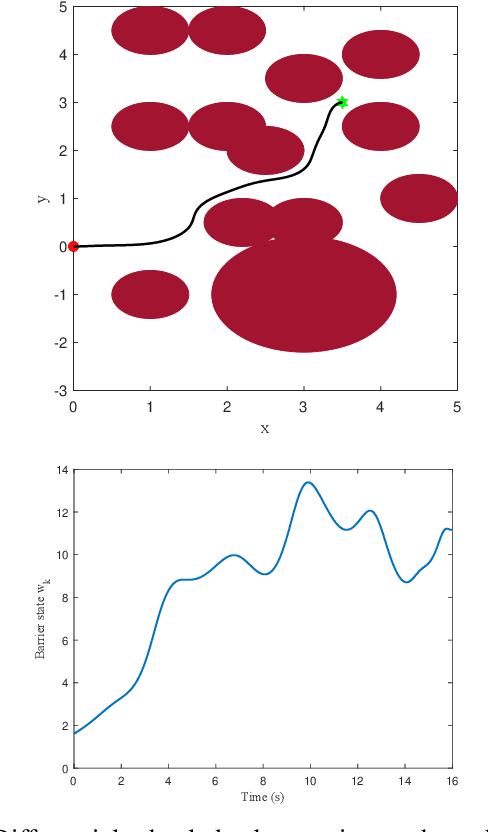
Certified safe control is a growing challenge in robotics, especially when performance and safety objectives are desired to be concurrently achieved. In this work, we extend the barrier state (BaS) concept, recently proposed for stabilization of continuous time systems, to enforce safety for discrete time systems by creating a discrete barrier state (DBaS). The constructed DBaS is embedded into the discrete model of the safety-critical system in order to integrate safety objectives into performance objectives. We subsequently use the proposed technique to implement a safety embedded stabilizing control for nonlinear discrete systems. Furthermore, we employ the DBaS method to develop a safety embedded differential dynamic programming (DDP) technique to plan and execute safe optimal trajectories. The proposed algorithm is leveraged on a differential wheeled robot and on a quadrotor to safely perform several tasks including reaching, tracking and safe multi-quadrotor movement. The DBaS-based DDP (DBaS-DDP) is compared to the penalty method used in constrained DDP problems where it is shown that the DBaS-DDP consistently outperforms the penalty method.
RCURRENCY: Live Digital Asset Trading Using a Recurrent Neural Network-based Forecasting System
Jun 13, 2021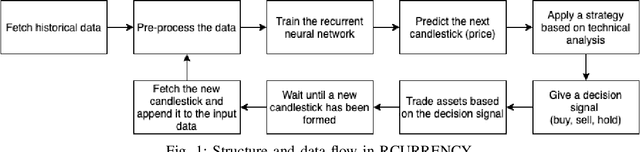
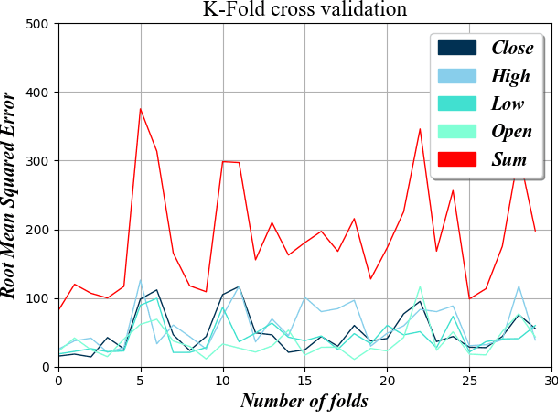
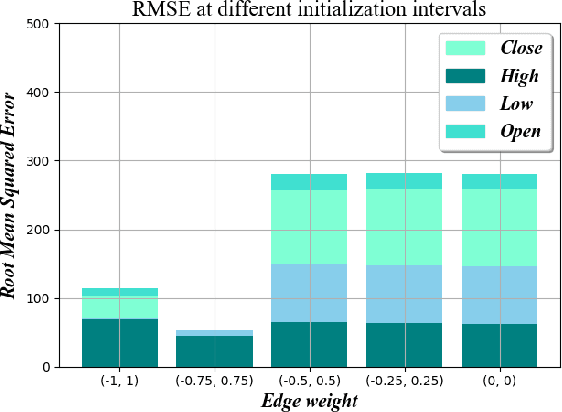
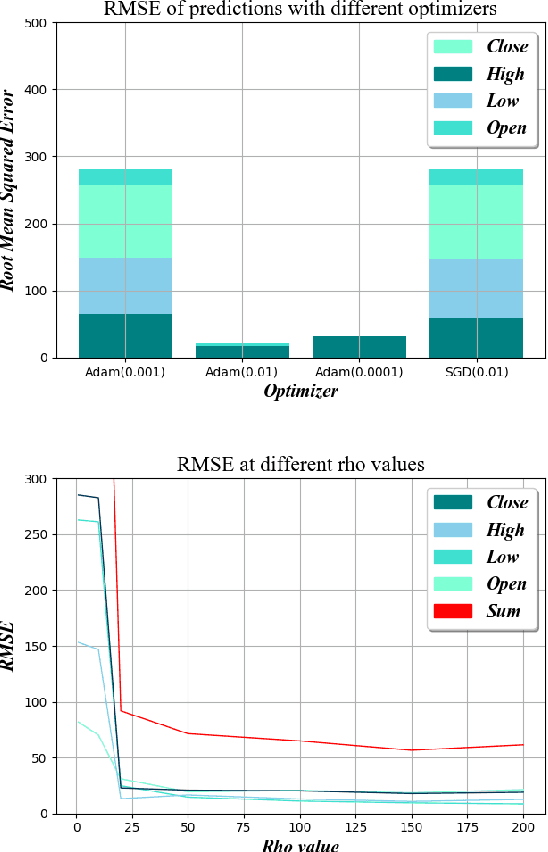
Consistent alpha generation, i.e., maintaining an edge over the market, underpins the ability of asset traders to reliably generate profits. Technical indicators and trading strategies are commonly used tools to determine when to buy/hold/sell assets, yet these are limited by the fact that they operate on known values. Over the past decades, multiple studies have investigated the potential of artificial intelligence in stock trading in conventional markets, with some success. In this paper, we present RCURRENCY, an RNN-based trading engine to predict data in the highly volatile digital asset market which is able to successfully manage an asset portfolio in a live environment. By combining asset value prediction and conventional trading tools, RCURRENCY determines whether to buy, hold or sell digital currencies at a given point in time. Experimental results show that, given the data of an interval $t$, a prediction with an error of less than 0.5\% of the data at the subsequent interval $t+1$ can be obtained. Evaluation of the system through backtesting shows that RCURRENCY can be used to successfully not only maintain a stable portfolio of digital assets in a simulated live environment using real historical trading data but even increase the portfolio value over time.