 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
An Extensible Benchmark Suite for Learning to Simulate Physical Systems
Aug 09, 2021
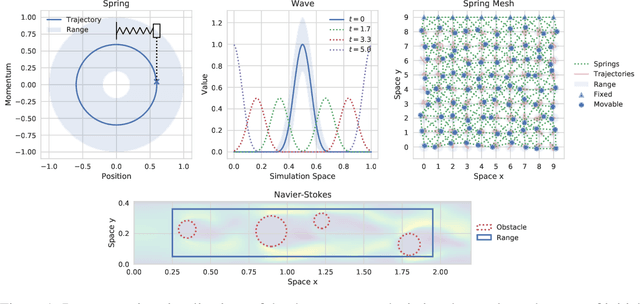

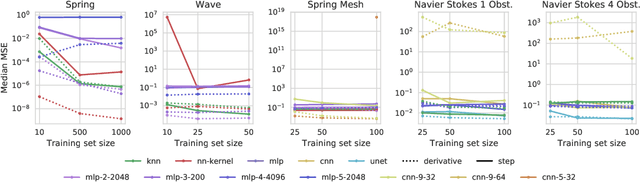
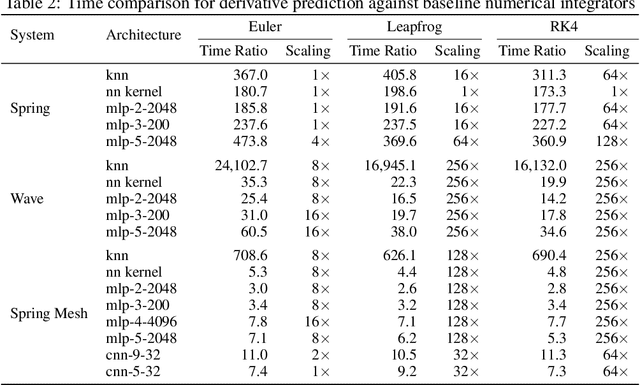
Simulating physical systems is a core component of scientific computing, encompassing a wide range of physical domains and applications. Recently, there has been a surge in data-driven methods to complement traditional numerical simulations methods, motivated by the opportunity to reduce computational costs and/or learn new physical models leveraging access to large collections of data. However, the diversity of problem settings and applications has led to a plethora of approaches, each one evaluated on a different setup and with different evaluation metrics. We introduce a set of benchmark problems to take a step towards unified benchmarks and evaluation protocols. We propose four representative physical systems, as well as a collection of both widely used classical time integrators and representative data-driven methods (kernel-based, MLP, CNN, nearest neighbors). Our framework allows evaluating objectively and systematically the stability, accuracy, and computational efficiency of data-driven methods. Additionally, it is configurable to permit adjustments for accommodating other learning tasks and for establishing a foundation for future developments in machine learning for scientific computing.
Scaling New Peaks: A Viewership-centric Approach to Automated Content Curation
Aug 09, 2021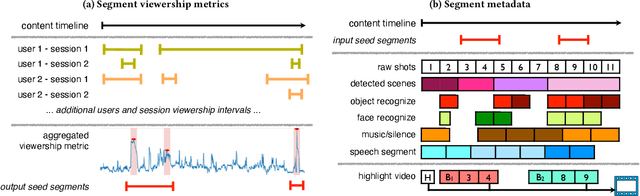
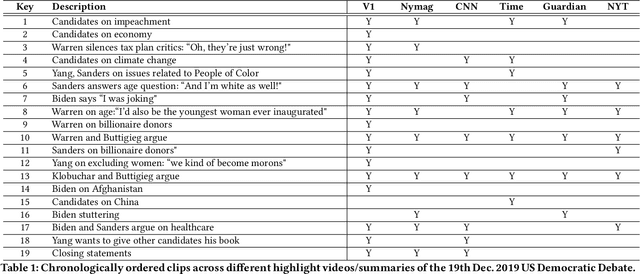
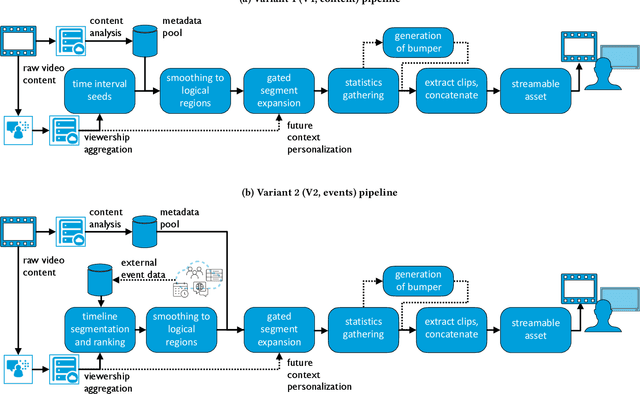
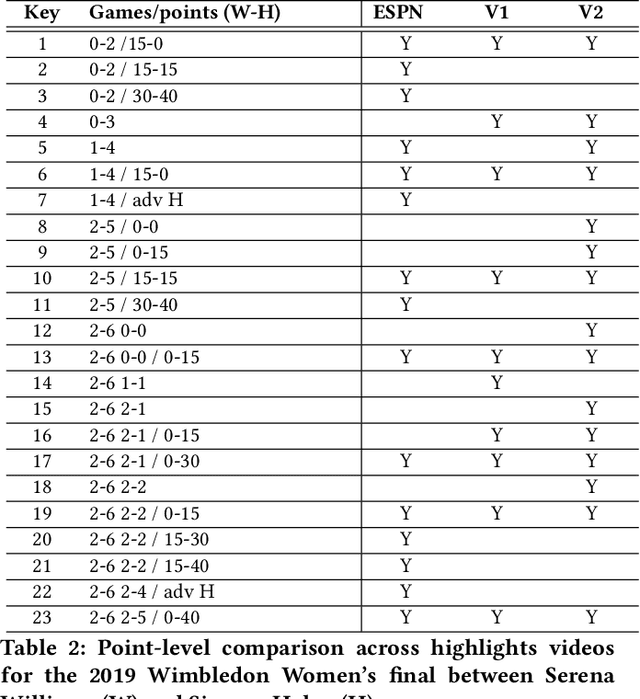
Summarizing video content is important for video streaming services to engage the user in a limited time span. To this end, current methods involve manual curation or using passive interest cues to annotate potential high-interest segments to form the basis of summarized videos, and are costly and unreliable. We propose a viewership-driven, automated method that accommodates a range of segment identification goals. Using satellite television viewership data as a source of ground truth for viewer interest, we apply statistical anomaly detection on a timeline of viewership metrics to identify 'seed' segments of high viewer interest. These segments are post-processed using empirical rules and several sources of content metadata, e.g. shot boundaries, adding in personalization aspects to produce the final highlights video. To demonstrate the flexibility of our approach, we present two case studies, on the United States Democratic Presidential Debate on 19th December 2019, and Wimbledon Women's Final 2019. We perform qualitative comparisons with their publicly available highlights, as well as early vs. late viewership comparisons for insights into possible media and social influence on viewing behavior.
Novel scorpion detection system combining computer vision and fluorescence
Aug 09, 2021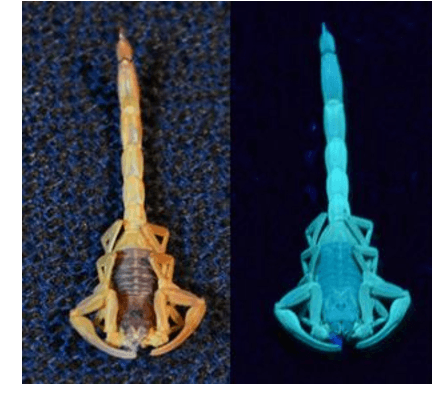
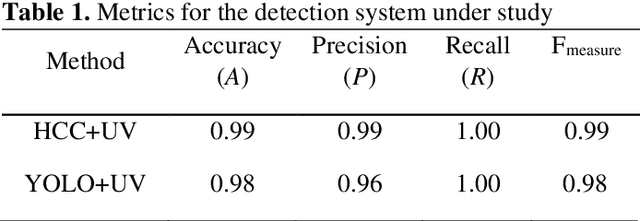
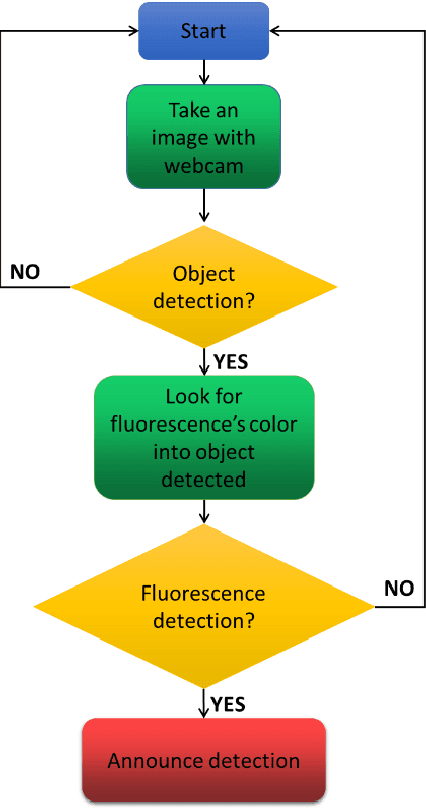

In this work, a fully automatic and real-time system for the detection of scorpions was developed using computer vision and deep learning techniques. This system is based on the implementation of a double validation process using the shape features and the fluorescent characteristics of scorpions when exposed to ultraviolet (UV) light. The Haar Cascade Classifier (HCC) and YOLO (You Only Look Once) models have been used and compared as the first mechanism for the scorpion shape detection. The detection of the fluorescence emitted by the scorpions under UV light has been used as a second detection mechanism in order to increase the accuracy and precision of the system. The results obtained show that the system can accurately and reliably detect the presence of scorpions. In addition, values obtained of recall of 100% is essential with the purpose of providing a health security tool. Although the developed system can only be used at night or in dark environment, where the fluorescence emitted by the scorpions can be visualized, the nocturnal activity of scorpions justifies the incorporation of this second validation mechanism.
MARViN -- Multiple Arithmetic Resolutions Vacillating in Neural Networks
Aug 09, 2021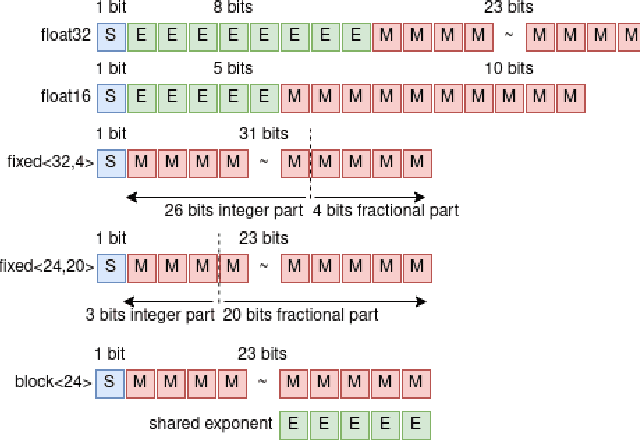
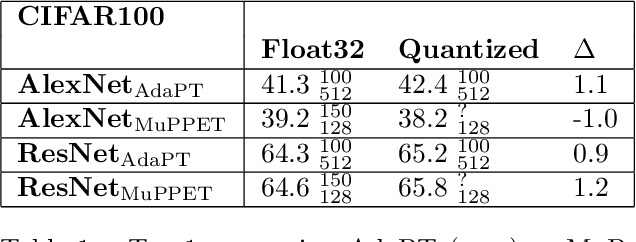

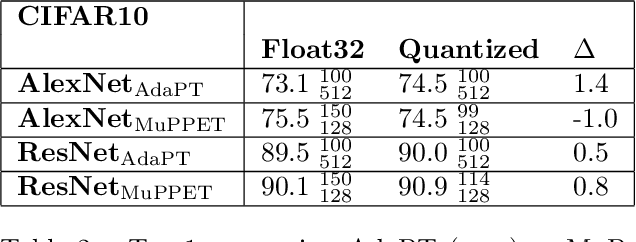
Quantization is a technique for reducing deep neural networks (DNNs) training and inference times, which is crucial for training in resource constrained environments or time critical inference applications. State-of-the-art (SOTA) quantization approaches focus on post-training quantization, i.e. quantization of pre-trained DNNs for speeding up inference. Very little work on quantized training exists, which neither al-lows dynamic intra-epoch precision switches nor em-ploys an information theory based switching heuristic. Usually, existing approaches require full precision refinement afterwards and enforce a global word length across the whole DNN. This leads to suboptimal quantization mappings and resource usage. Recognizing these limits, we introduce MARViN, a new quantized training strategy using information theory-based intra-epoch precision switching, which decides on a per-layer basis which precision should be used in order to minimize quantization-induced information loss. Note that any quantization must leave enough precision such that future learning steps do not suffer from vanishing gradients. We achieve an average speedup of 1.86 compared to a float32 basis while limiting mean accuracy degradation on AlexNet/ResNet to only -0.075%.
Segmentation-free Heart Pathology Detection Using Deep Learning
Aug 09, 2021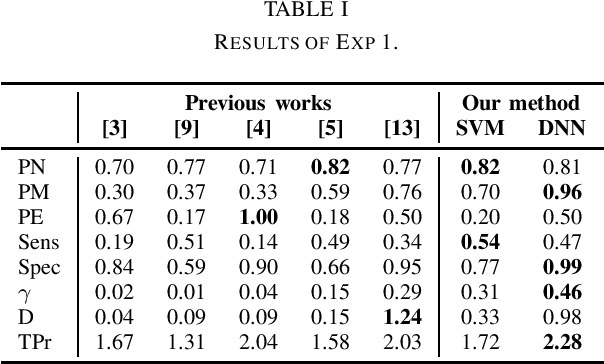
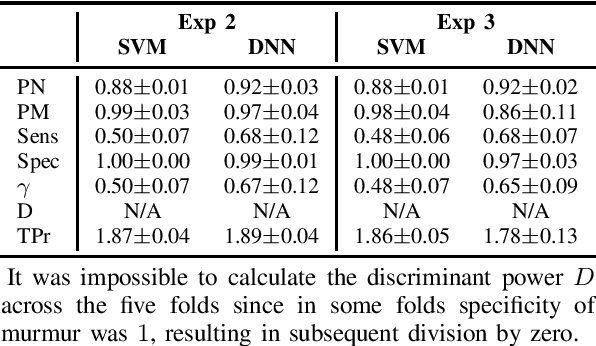
Cardiovascular (CV) diseases are the leading cause of death in the world, and auscultation is typically an essential part of a cardiovascular examination. The ability to diagnose a patient based on their heart sounds is a rather difficult skill to master. Thus, many approaches for automated heart auscultation have been explored. However, most of the previously proposed methods involve a segmentation step, the performance of which drops significantly for high pulse rates or noisy signals. In this work, we propose a novel segmentation-free heart sound classification method. Specifically, we apply discrete wavelet transform to denoise the signal, followed by feature extraction and feature reduction. Then, Support Vector Machines and Deep Neural Networks are utilised for classification. On the PASCAL heart sound dataset our approach showed superior performance compared to others, achieving 81% and 96% precision on normal and murmur classes, respectively. In addition, for the first time, the data were further explored under a user-independent setting, where the proposed method achieved 92% and 86% precision on normal and murmur, demonstrating the potential of enabling automatic murmur detection for practical use.
Online Multi-Granularity Distillation for GAN Compression
Aug 16, 2021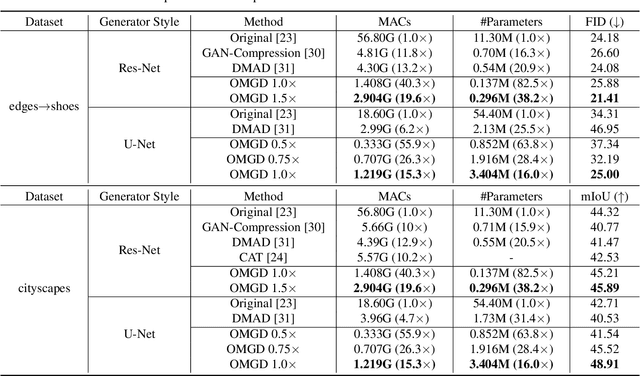
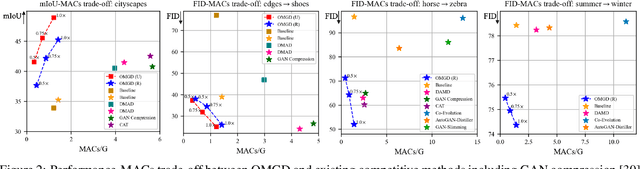
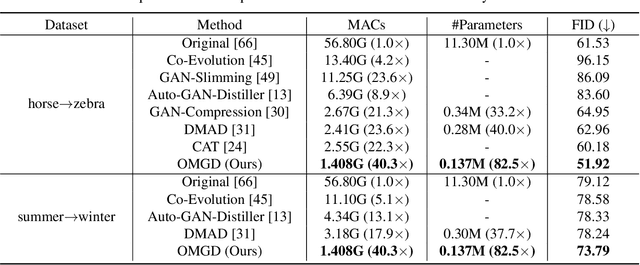
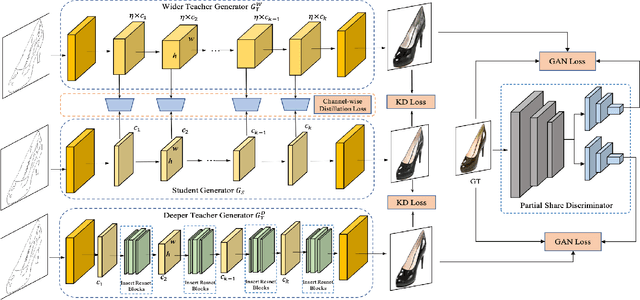
Generative Adversarial Networks (GANs) have witnessed prevailing success in yielding outstanding images, however, they are burdensome to deploy on resource-constrained devices due to ponderous computational costs and hulking memory usage. Although recent efforts on compressing GANs have acquired remarkable results, they still exist potential model redundancies and can be further compressed. To solve this issue, we propose a novel online multi-granularity distillation (OMGD) scheme to obtain lightweight GANs, which contributes to generating high-fidelity images with low computational demands. We offer the first attempt to popularize single-stage online distillation for GAN-oriented compression, where the progressively promoted teacher generator helps to refine the discriminator-free based student generator. Complementary teacher generators and network layers provide comprehensive and multi-granularity concepts to enhance visual fidelity from diverse dimensions. Experimental results on four benchmark datasets demonstrate that OMGD successes to compress 40x MACs and 82.5X parameters on Pix2Pix and CycleGAN, without loss of image quality. It reveals that OMGD provides a feasible solution for the deployment of real-time image translation on resource-constrained devices. Our code and models are made public at: https://github.com/bytedance/OMGD.
A Survey on Deep Domain Adaptation for LiDAR Perception
Jun 07, 2021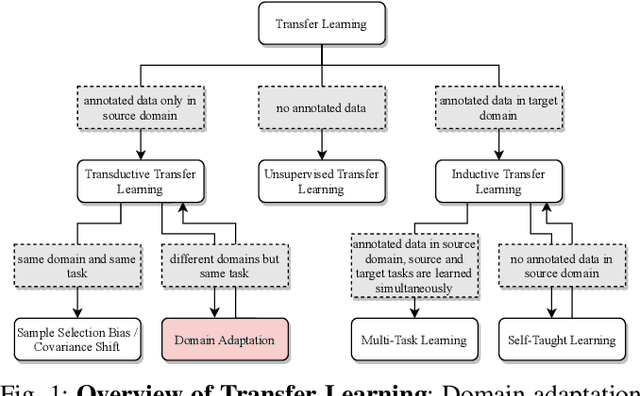
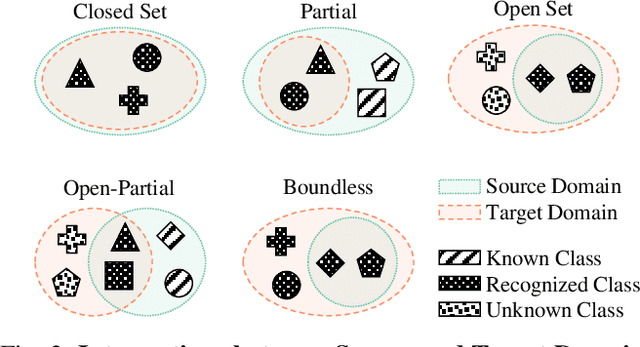
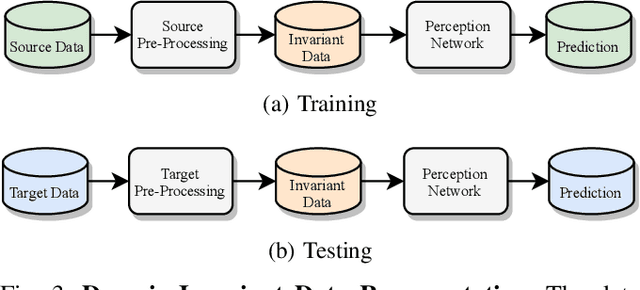
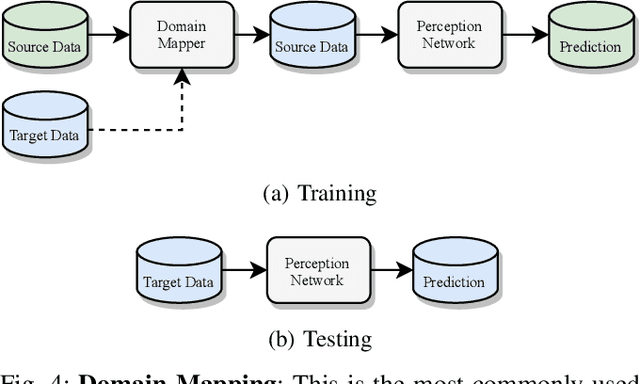
Scalable systems for automated driving have to reliably cope with an open-world setting. This means, the perception systems are exposed to drastic domain shifts, like changes in weather conditions, time-dependent aspects, or geographic regions. Covering all domains with annotated data is impossible because of the endless variations of domains and the time-consuming and expensive annotation process. Furthermore, fast development cycles of the system additionally introduce hardware changes, such as sensor types and vehicle setups, and the required knowledge transfer from simulation. To enable scalable automated driving, it is therefore crucial to address these domain shifts in a robust and efficient manner. Over the last years, a vast amount of different domain adaptation techniques evolved. There already exists a number of survey papers for domain adaptation on camera images, however, a survey for LiDAR perception is absent. Nevertheless, LiDAR is a vital sensor for automated driving that provides detailed 3D scans of the vehicle's surroundings. To stimulate future research, this paper presents a comprehensive review of recent progress in domain adaptation methods and formulates interesting research questions specifically targeted towards LiDAR perception.
Semantics of European poetry is shaped by conservative forces: The relationship between poetic meter and meaning in accentual-syllabic verse
Sep 15, 2021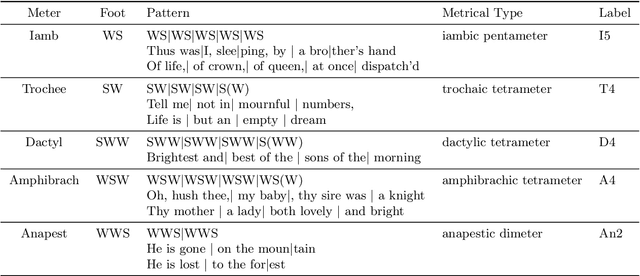

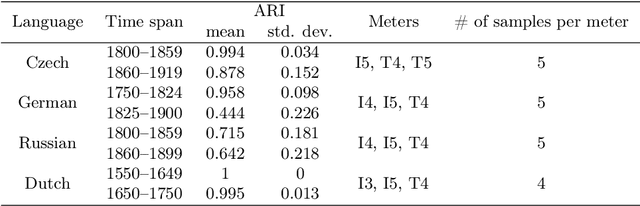
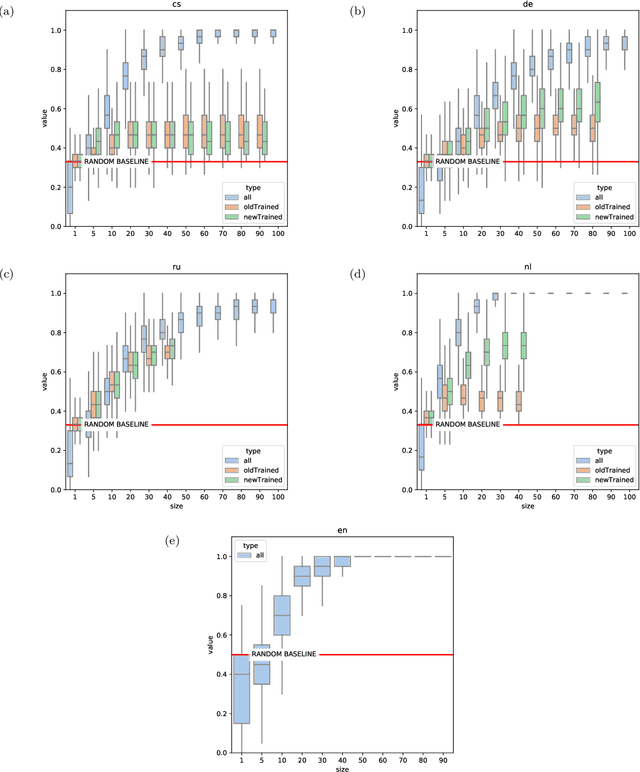
Recent advances in cultural analytics and large-scale computational studies of art, literature and film often show that long-term change in the features of artistic works happens gradually. These findings suggest that conservative forces that shape creative domains might be underestimated. To this end, we provide the first large-scale formal evidence of the persistent association between poetic meter and semantics in 18-19th European literatures, using Czech, German and Russian collections with additional data from English poetry and early modern Dutch songs. Our study traces this association through a series of clustering experiments using the abstracted semantic features of 150,000 poems. With the aid of topic modeling we infer semantic features for individual poems. Texts were also lexically simplified across collections to increase generalizability and decrease the sparseness of word frequency distributions. Topics alone enable recognition of the meters in each observed language, as may be seen from highly robust clustering of same-meter samples (median Adjusted Rand Index between 0.48 and 1). In addition, this study shows that the strength of the association between form and meaning tends to decrease over time. This may reflect a shift in aesthetic conventions between the 18th and 19th centuries as individual innovation was increasingly favored in literature. Despite this decline, it remains possible to recognize semantics of the meters from past or future, which suggests the continuity of semantic traditions while also revealing the historical variability of conditions across languages. This paper argues that distinct metrical forms, which are often copied in a language over centuries, also maintain long-term semantic inertia in poetry. Our findings, thus, highlight the role of the formal features of cultural items in influencing the pace and shape of cultural evolution.
Why You Should Try the Real Data for the Scene Text Recognition
Jul 29, 2021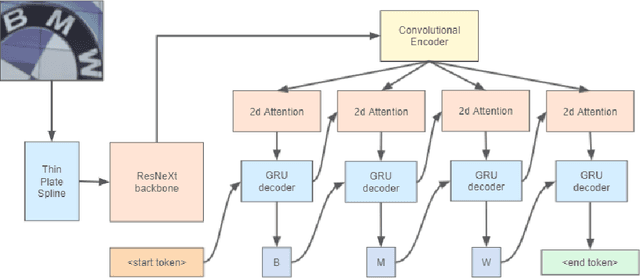
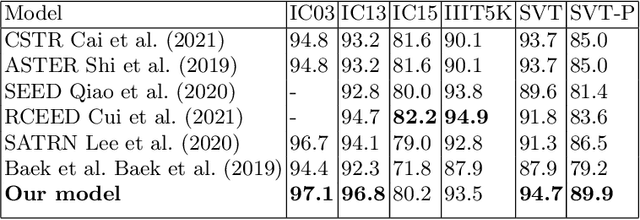


Recent works in the text recognition area have pushed forward the recognition results to the new horizons. But for a long time a lack of large human-labeled natural text recognition datasets has been forcing researchers to use synthetic data for training text recognition models. Even though synthetic datasets are very large (MJSynth and SynthTest, two most famous synthetic datasets, have several million images each), their diversity could be insufficient, compared to natural datasets like ICDAR and others. Fortunately, the recently released text-recognition annotation for OpenImages V5 dataset has comparable with synthetic dataset number of instances and more diverse examples. We have used this annotation with a Text Recognition head architecture from the Yet Another Mask Text Spotter and got comparable to the SOTA results. On some datasets we have even outperformed previous SOTA models. In this paper we also introduce a text recognition model. The model's code is available.
Data Driven VRP: A Neural Network Model to Learn Hidden Preferences for VRP
Aug 27, 2021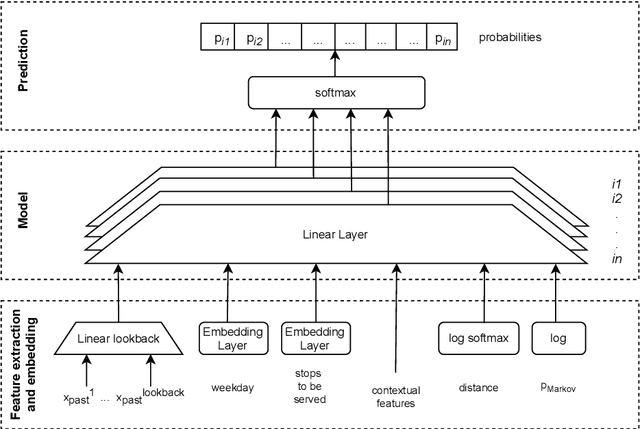
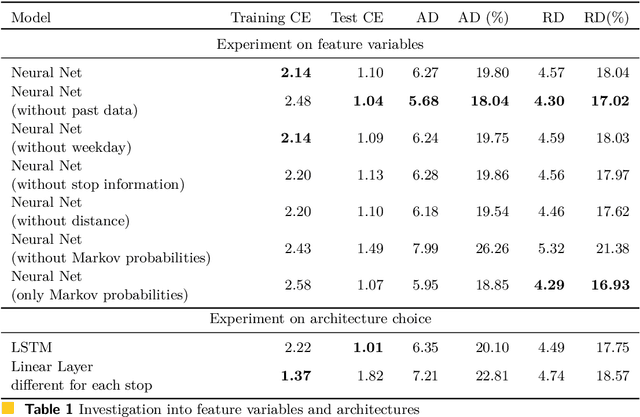
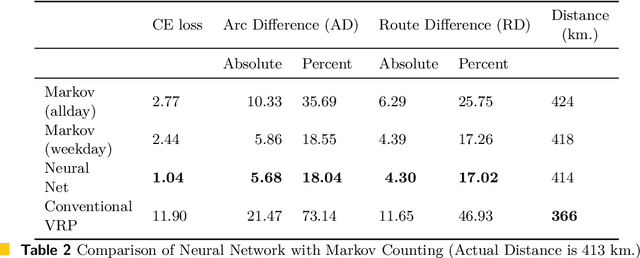
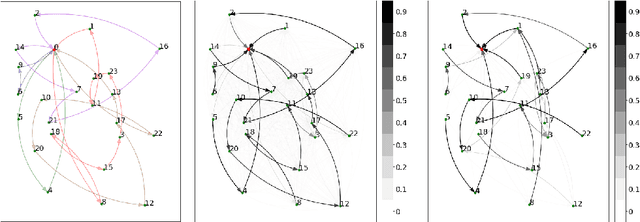
The traditional Capacitated Vehicle Routing Problem (CVRP) minimizes the total distance of the routes under the capacity constraints of the vehicles. But more often, the objective involves multiple criteria including not only the total distance of the tour but also other factors such as travel costs, travel time, and fuel consumption.Moreover, in reality, there are numerous implicit preferences ingrained in the minds of the route planners and the drivers. Drivers, for instance, have familiarity with certain neighborhoods and knowledge of the state of roads, and often consider the best places for rest and lunch breaks. This knowledge is difficult to formulate and balance when operational routing decisions have to be made. This motivates us to learn the implicit preferences from past solutions and to incorporate these learned preferences in the optimization process. These preferences are in the form of arc probabilities, i.e., the more preferred a route is, the higher is the joint probability. The novelty of this work is the use of a neural network model to estimate the arc probabilities, which allows for additional features and automatic parameter estimation. This first requires identifying suitable features, neural architectures and loss functions, taking into account that there is typically few data available. We investigate the difference with a prior weighted Markov counting approach, and study the applicability of neural networks in this setting.