 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Debiasing a First-order Heuristic for Approximate Bi-level Optimization
Jun 04, 2021
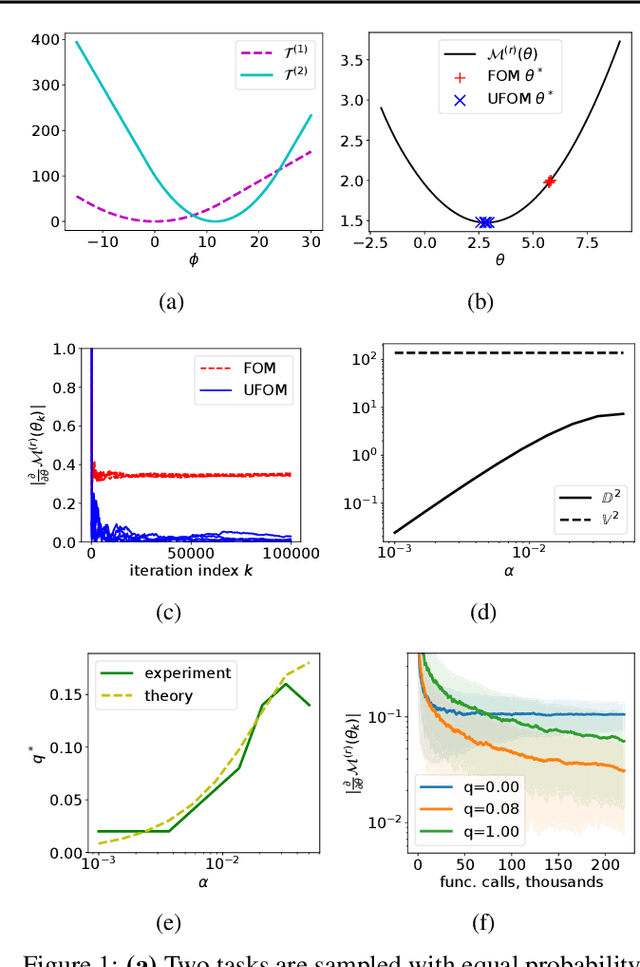
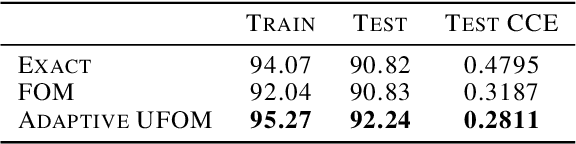
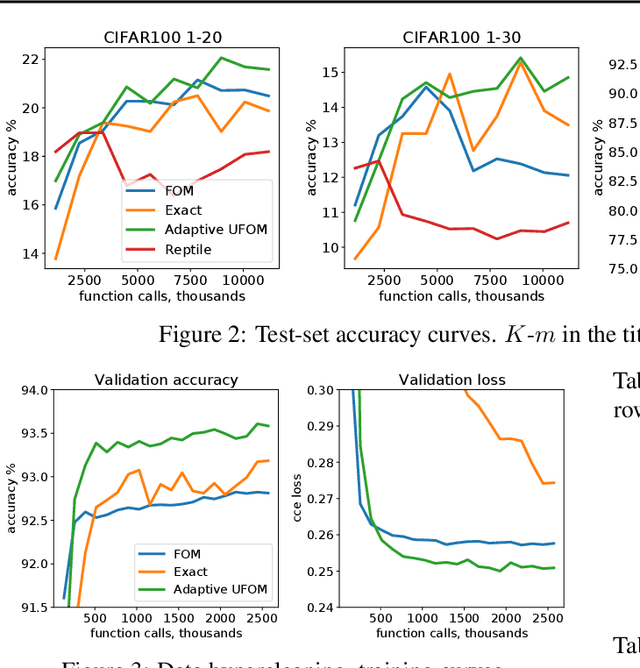
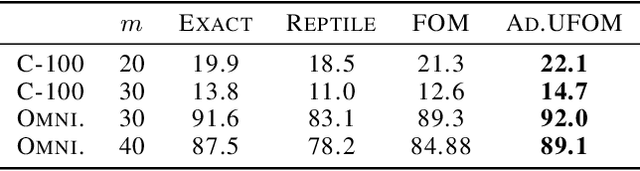
Approximate bi-level optimization (ABLO) consists of (outer-level) optimization problems, involving numerical (inner-level) optimization loops. While ABLO has many applications across deep learning, it suffers from time and memory complexity proportional to the length $r$ of its inner optimization loop. To address this complexity, an earlier first-order method (FOM) was proposed as a heuristic that omits second derivative terms, yielding significant speed gains and requiring only constant memory. Despite FOM's popularity, there is a lack of theoretical understanding of its convergence properties. We contribute by theoretically characterizing FOM's gradient bias under mild assumptions. We further demonstrate a rich family of examples where FOM-based SGD does not converge to a stationary point of the ABLO objective. We address this concern by proposing an unbiased FOM (UFOM) enjoying constant memory complexity as a function of $r$. We characterize the introduced time-variance tradeoff, demonstrate convergence bounds, and find an optimal UFOM for a given ABLO problem. Finally, we propose an efficient adaptive UFOM scheme.
Thinkback: Task-SpecificOut-of-Distribution Detection
Jul 13, 2021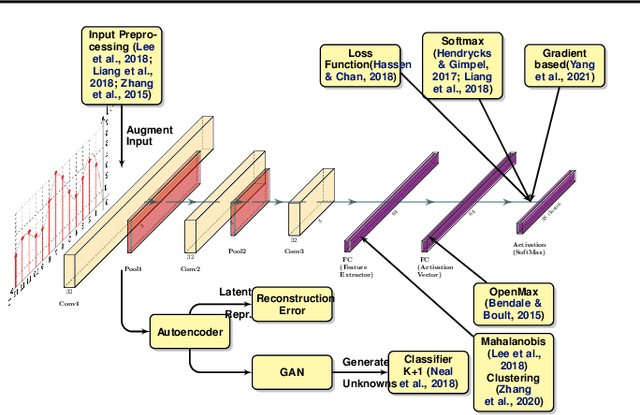
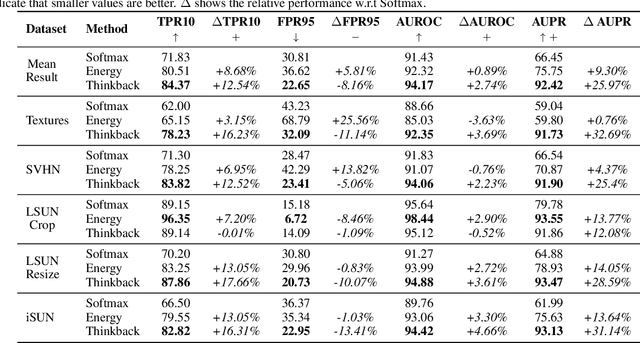
The increased success of Deep Learning (DL) has recently sparked large-scale deployment of DL models in many diverse industry segments. Yet, a crucial weakness of supervised model is the inherent difficulty in handling out-of-distribution samples, i.e., samples belonging to classes that were not presented to the model at training time. We propose in this paper a novel way to formulate the out-of-distribution detection problem, tailored for DL models. Our method does not require fine tuning process on training data, yet is significantly more accurate than the state of the art for out-of-distribution detection.
Unsupervised classification of acoustic emissions from catalogs and fault time-to-failure prediction
Dec 12, 2019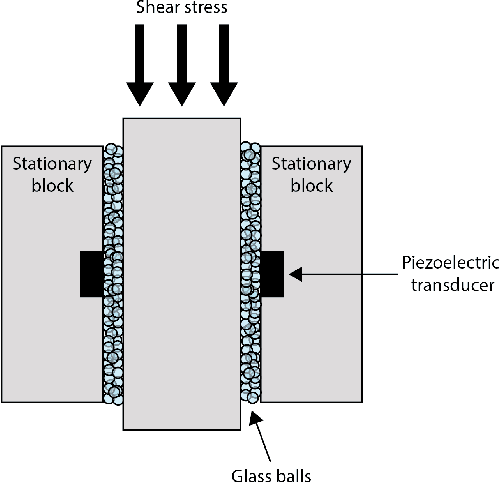
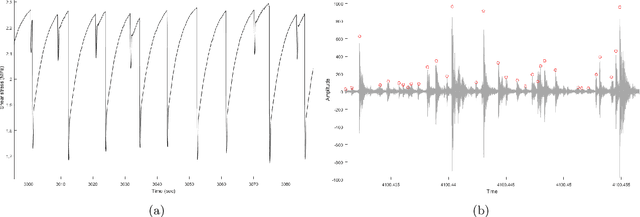
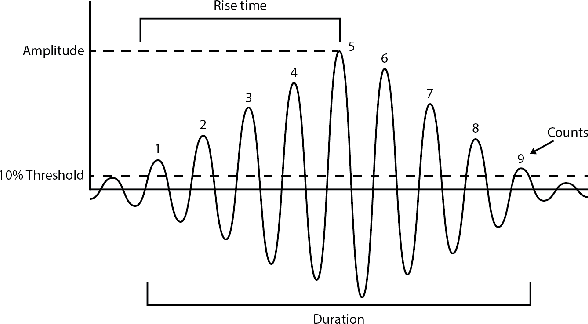

When a rock is subjected to stress it deforms by creep mechanisms that include formation and slip on small-scale internal cracks. Intragranular cracks and slip along grain contacts release energy as elastic waves called acoustic emissions (AE). Early research into AEs envisioned that these signals could be used in the future to predict rock falls, mine collapse, or even earthquakes. Today, nondestructive testing, a field of engineering, involves monitoring the spatio-temporal evolution of AEs with the goal of predicting time-to-failure for manufacturing tools and infrastructure. The monitoring process involves clustering AEs by damage mechanism (e.g. matrix cracking, delamination) to track changes within the material. In this study, we aim to adapt aspects of this process to the task of generalized earthquake prediction. Our data are generated in a laboratory setting using a biaxial shearing device and a granular fault gouge that mimics the conditions around tectonic faults. In particular, we analyze the temporal evolution of AEs generated throughout several hundred laboratory earthquake cycles. We use a Conscience Self-Organizing Map (CSOM) to perform topologically ordered vector quantization based on waveform properties. The resulting map is used to interactively cluster AEs according to damage mechanism. Finally, we use an event-based LSTM network to test the predictive power of each cluster. By tracking cumulative waveform features over the seismic cycle, the network is able to forecast the time-to-failure of the fault.
Path Planning With Naive-Valley-Path Obstacle Avoidance and Global Map-Free
Aug 20, 2021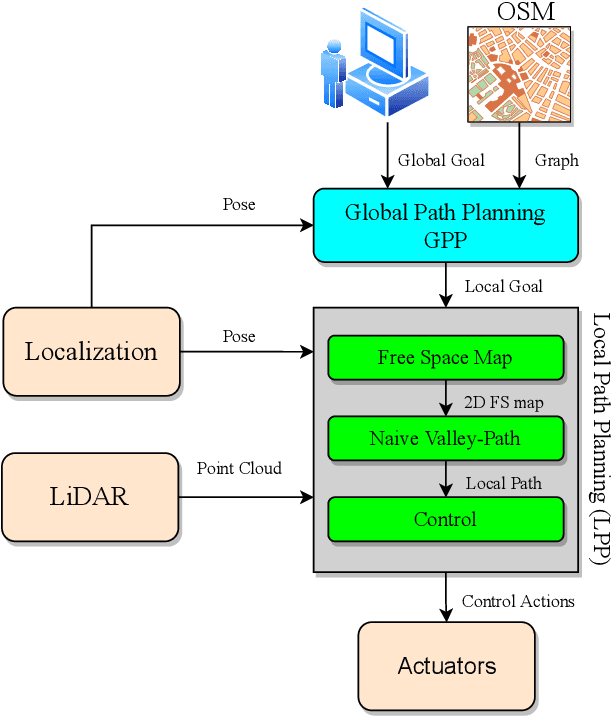
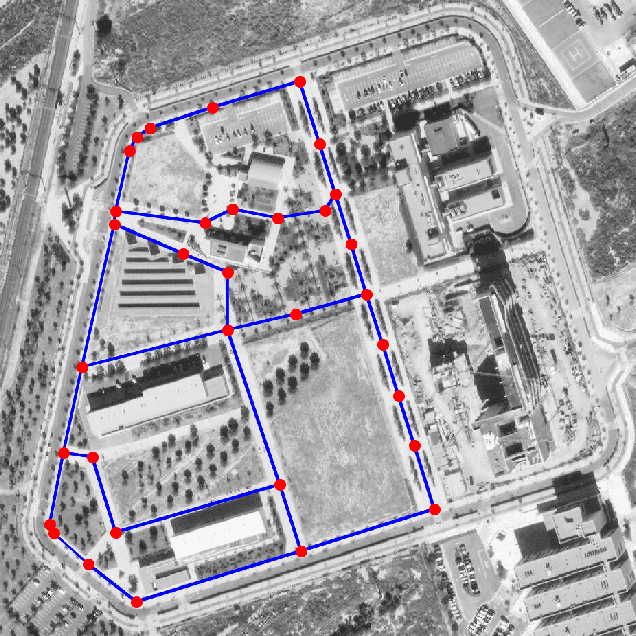
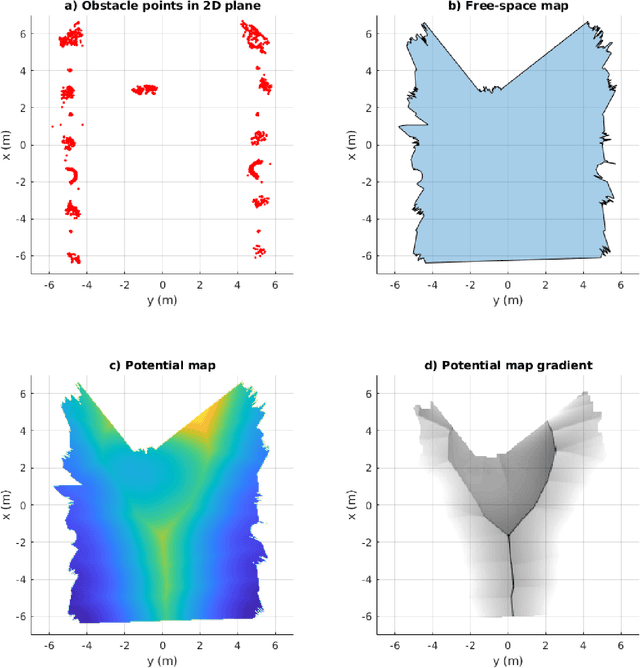
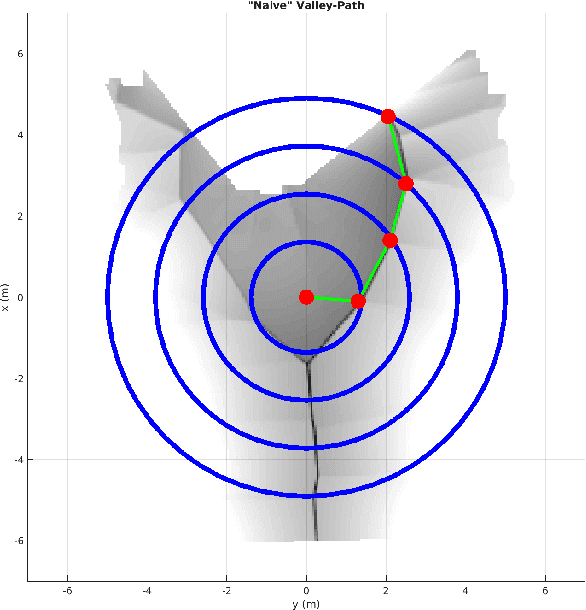
In this paper, we present a complete Path Planning approach divided into two main categories: Global Path Planning (GPP) and Local Path Planning (LPP). Unlike most other works, the GPP layer, instead of complex and heavy maps, uses road and intersections graphs obtained directly from internet applications like OpenStreetMaps (OSM). This map-free GPP frees us from the common area-size restrictions. In the LPP layer, we use a novel Naive-Valley-Path method (NVP) to generate a local path avoiding obstacles in the road in an extremely-low execution time period. This approach exploits the concept of valley areas around local minima, i.e., the ones always away from obstacles. We demonstrate the robustness of the system in our research platform BLUE, driving autonomously across the University of Alicante Scientific Park for more than 20 km in a 12.33 ha area. Our vehicle avoids different static persistent and non-persistent obstacles in the road and even dynamic ones, such as vehicles and pedestrians. Code is available at https://github.com/AUROVA-LAB/lib_planning.
SALADnet: Self-Attentive multisource Localization in the Ambisonics Domain
Jul 23, 2021
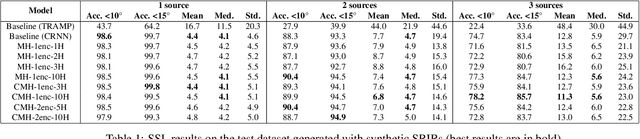
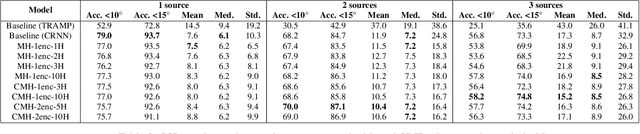
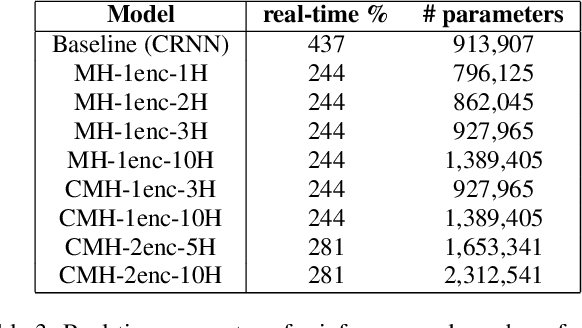
In this work, we propose a novel self-attention based neural network for robust multi-speaker localization from Ambisonics recordings. Starting from a state-of-the-art convolutional recurrent neural network, we investigate the benefit of replacing the recurrent layers by self-attention encoders, inherited from the Transformer architecture. We evaluate these models on synthetic and real-world data, with up to 3 simultaneous speakers. The obtained results indicate that the majority of the proposed architectures either perform on par, or outperform the CRNN baseline, especially in the multisource scenario. Moreover, by avoiding the recurrent layers, the proposed models lend themselves to parallel computing, which is shown to produce considerable savings in execution time.
Deep Reinforcement Learning for Dynamic Band Switch in Cellular-Connected UAV
Aug 26, 2021The choice of the transmitting frequency to provide cellular-connected Unmanned Aerial Vehicle (UAV) reliable connectivity and mobility support introduce several challenges. Conventional sub-6 GHz networks are optimized for ground Users (UEs). Operating at the millimeter Wave (mmWave) band would provide high-capacity but highly intermittent links. To reach the destination while minimizing a weighted function of traveling time and number of radio failures, we propose in this paper a UAV joint trajectory and band switch approach. By leveraging Double Deep Q-Learning we develop two different approaches to learn a trajectory besides managing the band switch. A first blind approach switches the band along the trajectory anytime the UAV-UE throughput is below a predefined threshold. In addition, we propose a smart approach for simultaneous learning-based path planning of UAV and band switch. The two approaches are compared with an optimal band switch strategy in terms of radio failure and band switches for different thresholds. Results reveal that the smart approach is able in a high threshold regime to reduce the number of radio failures and band switches while reaching the desired destination.
AgentFormer: Agent-Aware Transformers for Socio-Temporal Multi-Agent Forecasting
Mar 25, 2021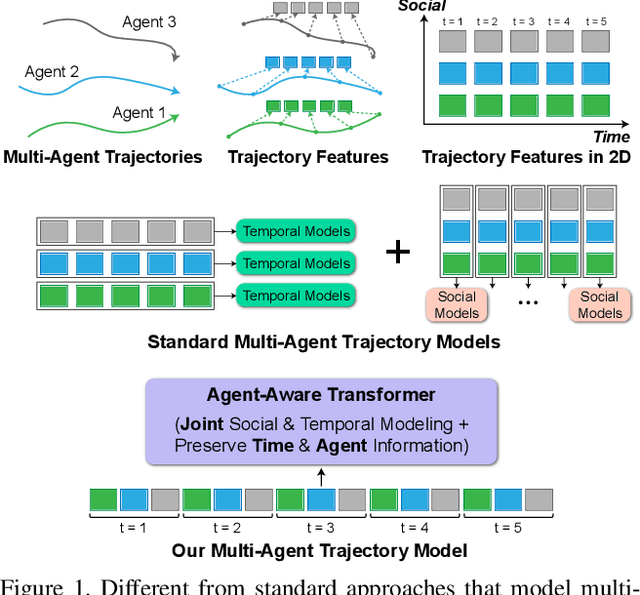

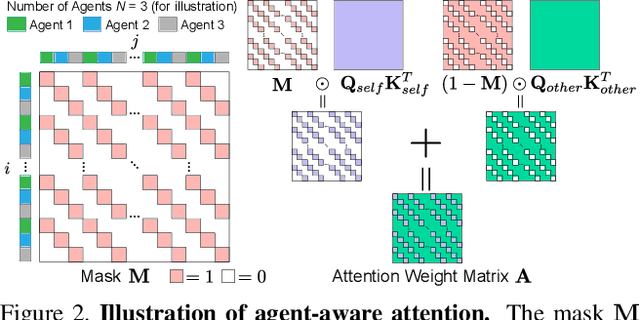

Predicting accurate future trajectories of multiple agents is essential for autonomous systems, but is challenging due to the complex agent interaction and the uncertainty in each agent's future behavior. Forecasting multi-agent trajectories requires modeling two key dimensions: (1) time dimension, where we model the influence of past agent states over future states; (2) social dimension, where we model how the state of each agent affects others. Most prior methods model these two dimensions separately; e.g., first using a temporal model to summarize features over time for each agent independently and then modeling the interaction of the summarized features with a social model. This approach is suboptimal since independent feature encoding over either the time or social dimension can result in a loss of information. Instead, we would prefer a method that allows an agent's state at one time to directly affect another agent's state at a future time. To this end, we propose a new Transformer, AgentFormer, that jointly models the time and social dimensions. The model leverages a sequence representation of multi-agent trajectories by flattening trajectory features across time and agents. Since standard attention operations disregard the agent identity of each element in the sequence, AgentFormer uses a novel agent-aware attention mechanism that preserves agent identities by attending to elements of the same agent differently than elements of other agents. Based on AgentFormer, we propose a stochastic multi-agent trajectory prediction model that can attend to features of any agent at any previous timestep when inferring an agent's future position. The latent intent of all agents is also jointly modeled, allowing the stochasticity in one agent's behavior to affect other agents. Our method significantly improves the state of the art on well-established pedestrian and autonomous driving datasets.
3D Human Reconstruction in the Wild with Collaborative Aerial Cameras
Aug 09, 2021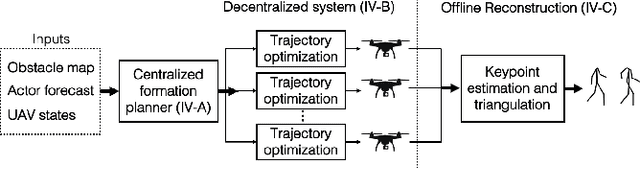
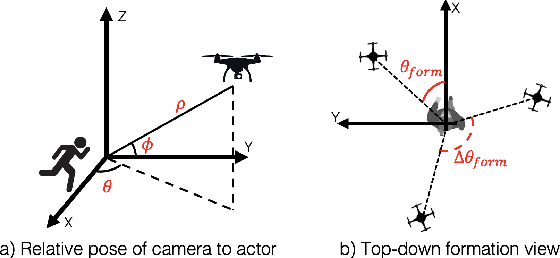
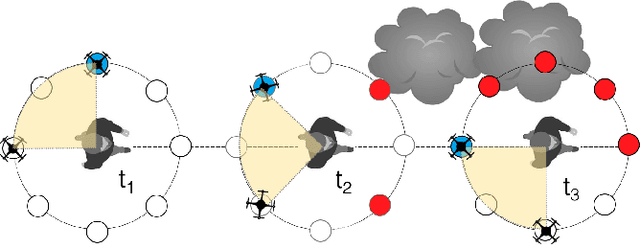
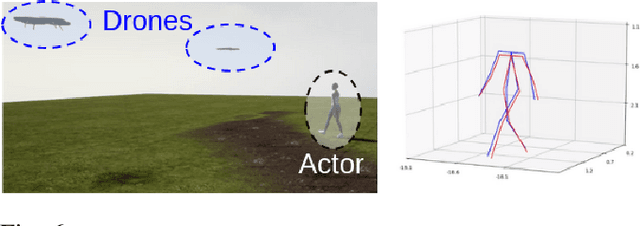
Aerial vehicles are revolutionizing applications that require capturing the 3D structure of dynamic targets in the wild, such as sports, medicine, and entertainment. The core challenges in developing a motion-capture system that operates in outdoors environments are: (1) 3D inference requires multiple simultaneous viewpoints of the target, (2) occlusion caused by obstacles is frequent when tracking moving targets, and (3) the camera and vehicle state estimation is noisy. We present a real-time aerial system for multi-camera control that can reconstruct human motions in natural environments without the use of special-purpose markers. We develop a multi-robot coordination scheme that maintains the optimal flight formation for target reconstruction quality amongst obstacles. We provide studies evaluating system performance in simulation, and validate real-world performance using two drones while a target performs activities such as jogging and playing soccer. Supplementary video: https://youtu.be/jxt91vx0cns
Point-of-Interest Type Prediction using Text and Images
Sep 01, 2021
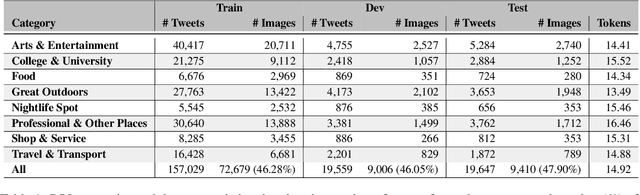
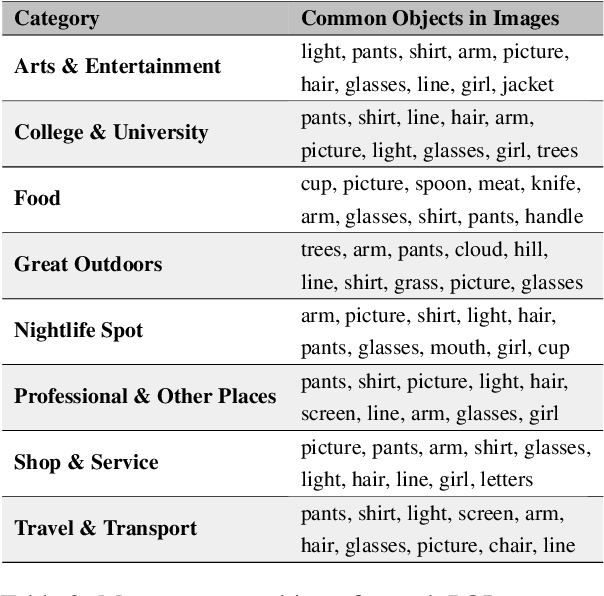
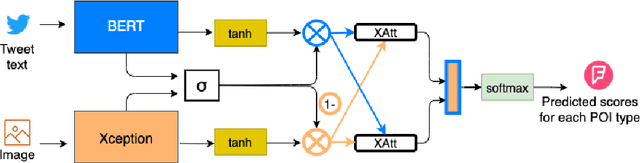
Point-of-interest (POI) type prediction is the task of inferring the type of a place from where a social media post was shared. Inferring a POI's type is useful for studies in computational social science including sociolinguistics, geosemiotics, and cultural geography, and has applications in geosocial networking technologies such as recommendation and visualization systems. Prior efforts in POI type prediction focus solely on text, without taking visual information into account. However in reality, the variety of modalities, as well as their semiotic relationships with one another, shape communication and interactions in social media. This paper presents a study on POI type prediction using multimodal information from text and images available at posting time. For that purpose, we enrich a currently available data set for POI type prediction with the images that accompany the text messages. Our proposed method extracts relevant information from each modality to effectively capture interactions between text and image achieving a macro F1 of 47.21 across eight categories significantly outperforming the state-of-the-art method for POI type prediction based on text-only methods. Finally, we provide a detailed analysis to shed light on cross-modal interactions and the limitations of our best performing model.
Off-line approximate dynamic programming for the vehicle routing problem with stochastic customers and demands via decentralized decision-making
Sep 21, 2021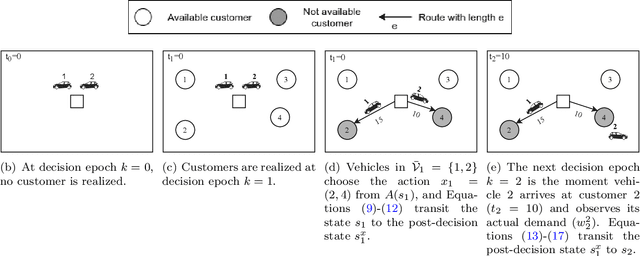
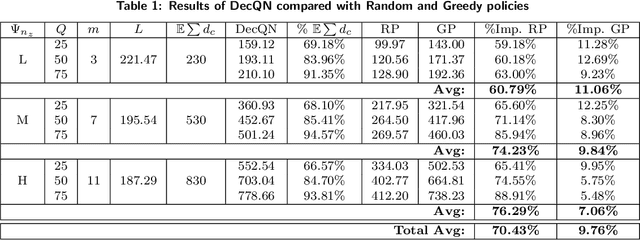
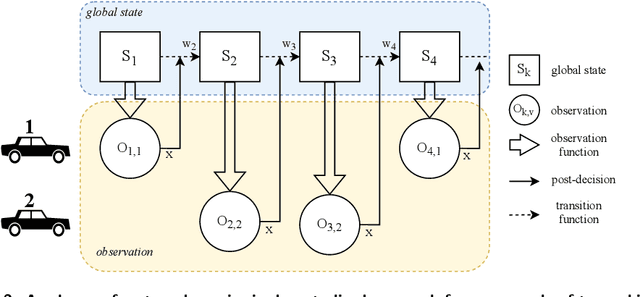

This paper studies a stochastic variant of the vehicle routing problem (VRP) where both customer locations and demands are uncertain. In particular, potential customers are not restricted to a predefined customer set but are continuously spatially distributed in a given service area. The objective is to maximize the served demands while fulfilling vehicle capacities and time restrictions. We call this problem the VRP with stochastic customers and demands (VRPSCD). For this problem, we first propose a Markov Decision Process (MDP) formulation representing the classical centralized decision-making perspective where one decision-maker establishes the routes of all vehicles. While the resulting formulation turns out to be intractable, it provides us with the ground to develop a new MDP formulation of the VRPSCD representing a decentralized decision-making framework, where vehicles autonomously establish their own routes. This new formulation allows us to develop several strategies to reduce the dimension of the state and action spaces, resulting in a considerably more tractable problem. We solve the decentralized problem via Reinforcement Learning, and in particular, we develop a Q-learning algorithm featuring state-of-the-art acceleration techniques such as Replay Memory and Double Q Network. Computational results show that our method considerably outperforms two commonly adopted benchmark policies (random and heuristic). Moreover, when comparing with existing literature, we show that our approach can compete with specialized methods developed for the particular case of the VRPSCD where customer locations and expected demands are known in advance. Finally, we show that the value functions and policies obtained by our algorithm can be easily embedded in Rollout algorithms, thus further improving their performances.