 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Distilling Privileged Multimodal Information for Expression Recognition using Optimal Transport
Jan 27, 2024
Multimodal affect recognition models have reached remarkable performance in the lab environment due to their ability to model complementary and redundant semantic information. However, these models struggle in the wild, mainly because of the unavailability or quality of modalities used for training. In practice, only a subset of the training-time modalities may be available at test time. Learning with privileged information (PI) enables deep learning models (DL) to exploit data from additional modalities only available during training. State-of-the-art knowledge distillation (KD) methods have been proposed to distill multiple teacher models (each trained on a modality) to a common student model. These privileged KD methods typically utilize point-to-point matching and have no explicit mechanism to capture the structural information in the teacher representation space formed by introducing the privileged modality. We argue that encoding this same structure in the student space may lead to enhanced student performance. This paper introduces a new structural KD mechanism based on optimal transport (OT), where entropy-regularized OT distills the structural dark knowledge. Privileged KD with OT (PKDOT) method captures the local structures in the multimodal teacher representation by calculating a cosine similarity matrix and selects the top-k anchors to allow for sparse OT solutions, resulting in a more stable distillation process. Experiments were performed on two different problems: pain estimation on the Biovid dataset (ordinal classification) and arousal-valance prediction on the Affwild2 dataset (regression). Results show that the proposed method can outperform state-of-the-art privileged KD methods on these problems. The diversity of different modalities and fusion architectures indicates that the proposed PKDOT method is modality and model-agnostic.
Towards Optimal Pilot Spacing and Power Control in Multi-Antenna Systems Operating Over Non-Stationary Rician Aging Channels
Jan 24, 2024Several previous works have addressed the inherent trade-off between allocating resources in the power and time domains to pilot and data signals in multiple input multiple output systems over block-fading channels. In particular, when the channel changes rapidly in time, channel aging degrades the performance in terms of spectral efficiency without proper pilot spacing and power control. Despite recognizing non-stationary stochastic processes as more accurate models for time-varying wireless channels, the problem of pilot spacing and power control in multi-antenna systems operating over non-stationary channels is not addressed in the literature. In this paper, we address this gap by introducing a refined first-order autoregressive model that exploits the inherent temporal correlations over non-stationary Rician aging channels. We design a multi-frame structure for data transmission that better reflects the non-stationary fading environment than previously developed single-frame structures. Subsequently, to determine optimal pilot spacing and power control within this multi-frame structure, we develop an optimization framework and an efficient algorithm based on maximizing a deterministic equivalent expression for the spectral efficiency, demonstrating its generality by encompassing previous channel aging results. Our numerical results indicate the efficacy of the proposed method in terms of spectral efficiency gains over the single frame structure.
Capturing Pertinent Symbolic Features for Enhanced Content-Based Misinformation Detection
Jan 29, 2024Preventing the spread of misinformation is challenging. The detection of misleading content presents a significant hurdle due to its extreme linguistic and domain variability. Content-based models have managed to identify deceptive language by learning representations from textual data such as social media posts and web articles. However, aggregating representative samples of this heterogeneous phenomenon and implementing effective real-world applications is still elusive. Based on analytical work on the language of misinformation, this paper analyzes the linguistic attributes that characterize this phenomenon and how representative of such features some of the most popular misinformation datasets are. We demonstrate that the appropriate use of pertinent symbolic knowledge in combination with neural language models is helpful in detecting misleading content. Our results achieve state-of-the-art performance in misinformation datasets across the board, showing that our approach offers a valid and robust alternative to multi-task transfer learning without requiring any additional training data. Furthermore, our results show evidence that structured knowledge can provide the extra boost required to address a complex and unpredictable real-world problem like misinformation detection, not only in terms of accuracy but also time efficiency and resource utilization.
Multi-BD Symbiotic Radio-Aided 6G IoT Network: Energy Consumption Optimization with QoS Constraint Approach
Jan 29, 2024The commensal symbiotic radio (CSR) system is proposed as a novel solution for connecting systems through green communication networks. This system enables us to establish secure, ubiquitous, and unlimited connectivity, which is a goal of 6G. The base station uses MIMO antennas to transmit its signal. Passive IoT devices, called symbiotic backscatter devices (SBDs), receive the signal and use it to charge their power supply. When the SBDs have data to transmit, they modulate the information onto the received ambient RF signal and send it to the symbiotic user equipment, which is a typical active device. The main purpose is to enhance energy efficiency in this network by minimizing energy consumption (EC) while ensuring the minimum required throughput for SBDs. To achieve this, we propose a new scheduling scheme called Timing-SR that optimally allocates resources to SBDs. The main optimization problem involves non-convex objective functions and constraints. To solve this, we use mathematical techniques and introduce a new approach called sequential quadratic and conic quadratic representation to relax and discipline the problem, leading to reducing its complexity and convergence time. The simulation results demonstrate that the proposed approach outperforms other outlined schemes in reducing EC.
ReGAL: Refactoring Programs to Discover Generalizable Abstractions
Jan 29, 2024While large language models (LLMs) are increasingly being used for program synthesis, they lack the global view needed to develop useful abstractions; they generally predict programs one at a time, often repeating the same functionality. Generating redundant code from scratch is both inefficient and error-prone. To address this, we propose Refactoring for Generalizable Abstraction Learning (ReGAL), a gradient-free method for learning a library of reusable functions via code refactorization, i.e. restructuring code without changing its execution output. ReGAL learns from a small set of existing programs, iteratively verifying and refining its abstractions via execution. We find that the shared function libraries discovered by ReGAL make programs easier to predict across diverse domains. On three datasets (LOGO graphics generation, Date reasoning, and TextCraft, a Minecraft-based text game), both open-source and proprietary LLMs improve in accuracy when predicting programs with ReGAL functions. For CodeLlama-13B, ReGAL results in absolute accuracy increases of 11.5% on graphics, 26.1% on date understanding, and 8.1% on TextCraft, outperforming GPT-3.5 in two of three domains. Our analysis reveals ReGAL's abstractions encapsulate frequently-used subroutines as well as environment dynamics.
S$^3$M-Net: Joint Learning of Semantic Segmentation and Stereo Matching for Autonomous Driving
Jan 29, 2024Semantic segmentation and stereo matching are two essential components of 3D environmental perception systems for autonomous driving. Nevertheless, conventional approaches often address these two problems independently, employing separate models for each task. This approach poses practical limitations in real-world scenarios, particularly when computational resources are scarce or real-time performance is imperative. Hence, in this article, we introduce S$^3$M-Net, a novel joint learning framework developed to perform semantic segmentation and stereo matching simultaneously. Specifically, S$^3$M-Net shares the features extracted from RGB images between both tasks, resulting in an improved overall scene understanding capability. This feature sharing process is realized using a feature fusion adaption (FFA) module, which effectively transforms the shared features into semantic space and subsequently fuses them with the encoded disparity features. The entire joint learning framework is trained by minimizing a novel semantic consistency-guided (SCG) loss, which places emphasis on the structural consistency in both tasks. Extensive experimental results conducted on the vKITTI2 and KITTI datasets demonstrate the effectiveness of our proposed joint learning framework and its superior performance compared to other state-of-the-art single-task networks. Our project webpage is accessible at mias.group/S3M-Net.
Enhancing Object Detection Performance for Small Objects through Synthetic Data Generation and Proportional Class-Balancing Technique: A Comparative Study in Industrial Scenarios
Jan 29, 2024Object Detection (OD) has proven to be a significant computer vision method in extracting localized class information and has multiple applications in the industry. Although many of the state-of-the-art (SOTA) OD models perform well on medium and large sized objects, they seem to under perform on small objects. In most of the industrial use cases, it is difficult to collect and annotate data for small objects, as it is time-consuming and prone to human errors. Additionally, those datasets are likely to be unbalanced and often result in an inefficient model convergence. To tackle this challenge, this study presents a novel approach that injects additional data points to improve the performance of the OD models. Using synthetic data generation, the difficulties in data collection and annotations for small object data points can be minimized and to create a dataset with balanced distribution. This paper discusses the effects of a simple proportional class-balancing technique, to enable better anchor matching of the OD models. A comparison was carried out on the performances of the SOTA OD models: YOLOv5, YOLOv7 and SSD, for combinations of real and synthetic datasets within an industrial use case.
Encoding Binary Events from Continuous Time Series in Rooted Trees using Contrastive Learning
Jan 02, 2024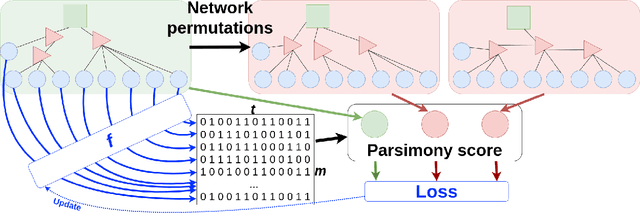
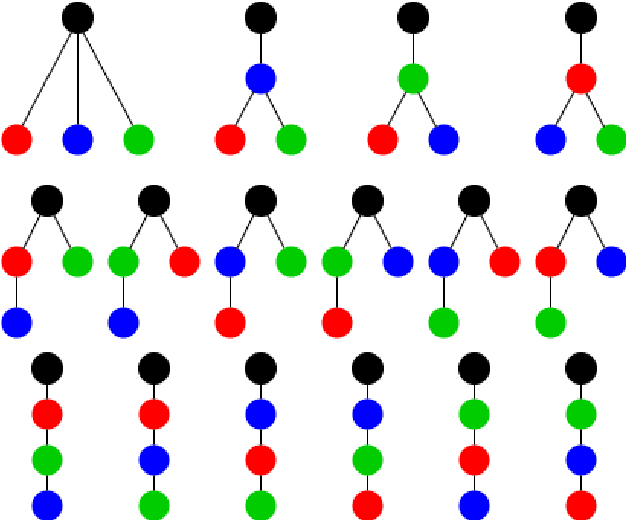
Broadband infrastructure owners do not always know how their customers are connected in the local networks, which are structured as rooted trees. A recent study is able to infer the topology of a local network using discrete time series data from the leaves of the tree (customers). In this study we propose a contrastive approach for learning a binary event encoder from continuous time series data. As a preliminary result, we show that our approach has some potential in learning a valuable encoder.
An Explicit Scheme for Pathwise XVA Computations
Jan 24, 2024Motivated by the equations of cross valuation adjustments (XVAs) in the realistic case where capital is deemed fungible as a source of funding for variation margin, we introduce a simulation/regression scheme for a class of anticipated BSDEs, where the coefficient entails a conditional expected shortfall of the martingale part of the solution. The scheme is explicit in time and uses neural network least-squares and quantile regressions for the embedded conditional expectations and expected shortfall computations. An a posteriori Monte Carlo validation procedure allows assessing the regression error of the scheme at each time step. The superiority of this scheme with respect to Picard iterations is illustrated in a high-dimensional and hybrid market/default risks XVA use-case.
An Embeddable Implicit IUVD Representation for Part-based 3D Human Surface Reconstruction
Jan 30, 2024To reconstruct a 3D human surface from a single image, it is important to consider human pose, shape and clothing details simultaneously. In recent years, a combination of parametric body models (such as SMPL) that capture body pose and shape prior, and neural implicit functions that learn flexible clothing details, has been used to integrate the advantages of both approaches. However, the combined representation introduces additional computation, e.g. signed distance calculation, in 3D body feature extraction, which exacerbates the redundancy of the implicit query-and-infer process and fails to preserve the underlying body shape prior. To address these issues, we propose a novel IUVD-Feedback representation, which consists of an IUVD occupancy function and a feedback query algorithm. With this representation, the time-consuming signed distance calculation is replaced by a simple linear transformation in the IUVD space, leveraging the SMPL UV maps. Additionally, the redundant query points in the query-and-infer process are reduced through a feedback mechanism. This leads to more reasonable 3D body features and more effective query points, successfully preserving the parametric body prior. Moreover, the IUVD-Feedback representation can be embedded into any existing implicit human reconstruction pipelines without modifying the trained neural networks. Experiments on THuman2.0 dataset demonstrate that the proposed IUVD-Feedback representation improves result robustness and achieves three times faster acceleration in the query-and-infer process. Furthermore, this representation has the potential to be used in generative applications by leveraging its inherited semantic information from the parametric body model.