 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
MACRPO: Multi-Agent Cooperative Recurrent Policy Optimization
Sep 02, 2021
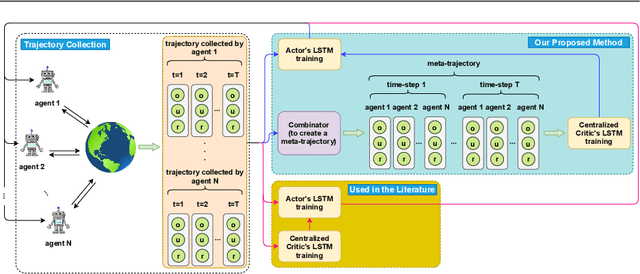
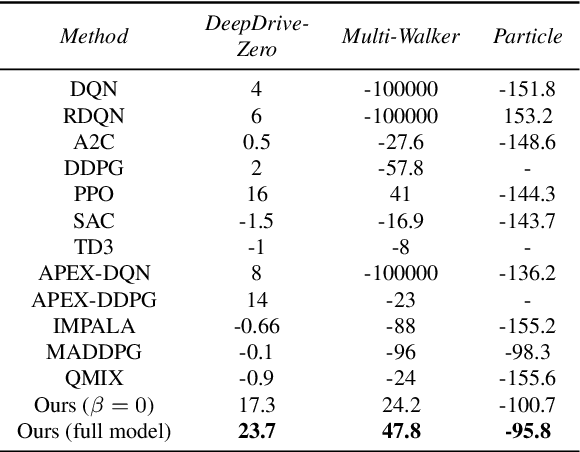
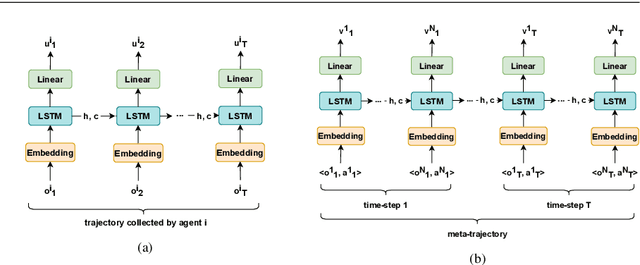
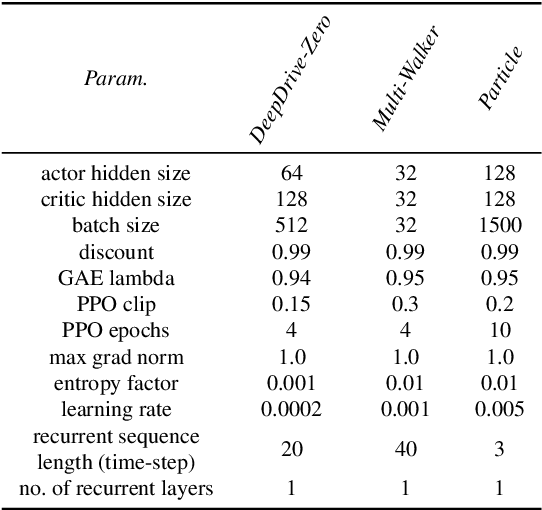
This work considers the problem of learning cooperative policies in multi-agent settings with partially observable and non-stationary environments without a communication channel. We focus on improving information sharing between agents and propose a new multi-agent actor-critic method called \textit{Multi-Agent Cooperative Recurrent Proximal Policy Optimization} (MACRPO). We propose two novel ways of integrating information across agents and time in MACRPO: First, we use a recurrent layer in critic's network architecture and propose a new framework to use a meta-trajectory to train the recurrent layer. This allows the network to learn the cooperation and dynamics of interactions between agents, and also handle partial observability. Second, we propose a new advantage function that incorporates other agents' rewards and value functions. We evaluate our algorithm on three challenging multi-agent environments with continuous and discrete action spaces, Deepdrive-Zero, Multi-Walker, and Particle environment. We compare the results with several ablations and state-of-the-art multi-agent algorithms such as QMIX and MADDPG and also single-agent methods with shared parameters between agents such as IMPALA and APEX. The results show superior performance against other algorithms. The code is available online at https://github.com/kargarisaac/macrpo.
One-shot Key Information Extraction from Document with Deep Partial Graph Matching
Sep 26, 2021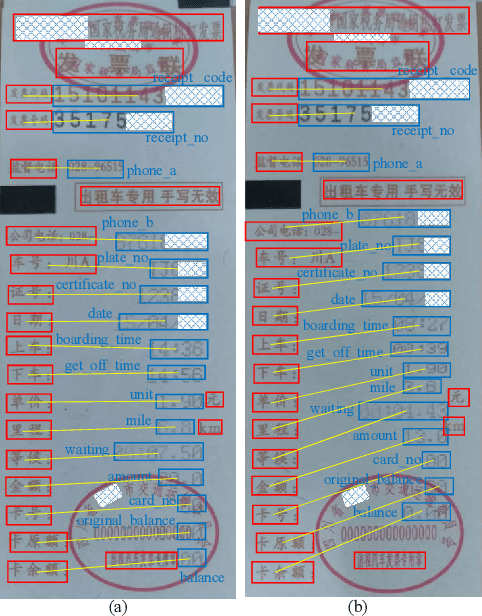
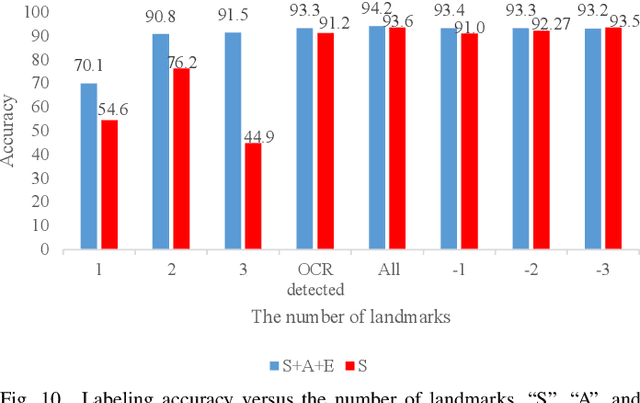
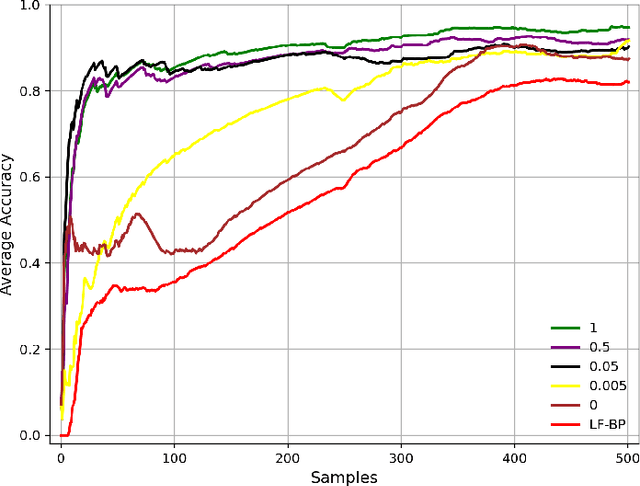
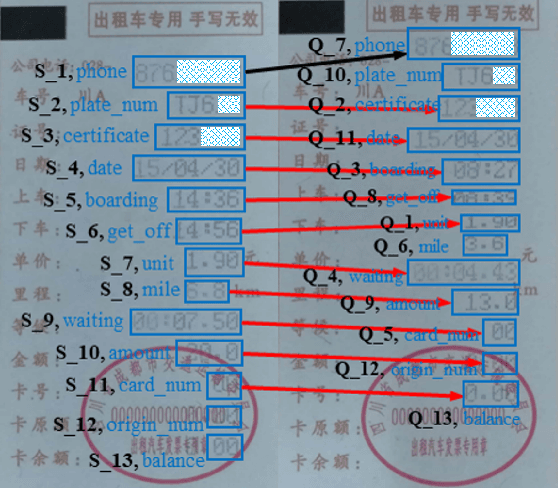
Automating the Key Information Extraction (KIE) from documents improves efficiency, productivity, and security in many industrial scenarios such as rapid indexing and archiving. Many existing supervised learning methods for the KIE task need to feed a large number of labeled samples and learn separate models for different types of documents. However, collecting and labeling a large dataset is time-consuming and is not a user-friendly requirement for many cloud platforms. To overcome these challenges, we propose a deep end-to-end trainable network for one-shot KIE using partial graph matching. Contrary to previous methods that the learning of similarity and solving are optimized separately, our method enables the learning of the two processes in an end-to-end framework. Existing one-shot KIE methods are either template or simple attention-based learning approach that struggle to handle texts that are shifted beyond their desired positions caused by printers, as illustrated in Fig.1. To solve this problem, we add one-to-(at most)-one constraint such that we will find the globally optimized solution even if some texts are drifted. Further, we design a multimodal context ensemble block to boost the performance through fusing features of spatial, textual, and aspect representations. To promote research of KIE, we collected and annotated a one-shot document KIE dataset named DKIE with diverse types of images. The DKIE dataset consists of 2.5K document images captured by mobile phones in natural scenes, and it is the largest available one-shot KIE dataset up to now. The results of experiments on DKIE show that our method achieved state-of-the-art performance compared with recent one-shot and supervised learning approaches. The dataset and proposed one-shot KIE model will be released soo
Prediction of Metacarpophalangeal joint angles and Classification of Hand configurations based on Ultrasound Imaging of the Forearm
Sep 26, 2021

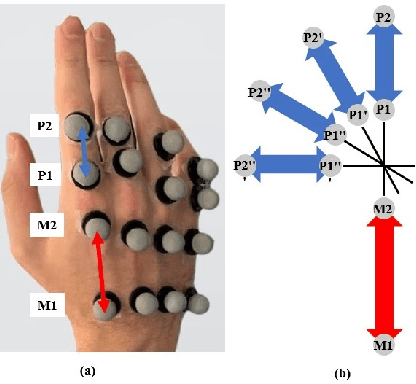
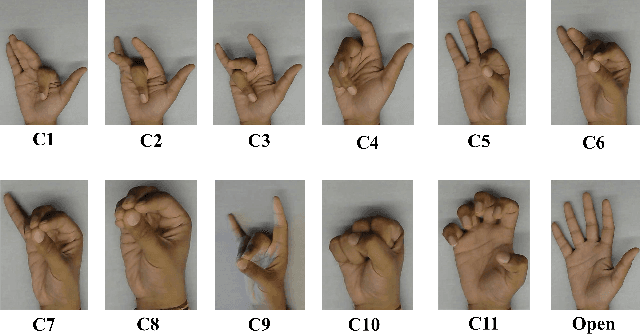
With the advancement in computing and robotics, it is necessary to develop fluent and intuitive methods for interacting with digital systems, AR/VR interfaces, and physical robotic systems. Hand movement recognition is widely used to enable this interaction. Hand configuration classification and Metacarpophalangeal (MCP) joint angle detection are important for a comprehensive reconstruction of the hand motion. Surface electromyography and other technologies have been used for the detection of hand motions. Ultrasound images of the forearm offer a way to visualize the internal physiology of the hand from a musculoskeletal perspective. Recent work has shown that these images can be classified using machine learning to predict various hand configurations. In this paper, we propose a Convolutional Neural Network (CNN) based deep learning pipeline for predicting the MCP joint angles. We supplement our results by using a Support Vector Classifier (SVC) to classify the ultrasound information into several predefined hand configurations based on activities of daily living (ADL). Ultrasound data from the forearm was obtained from 6 subjects who were instructed to move their hands according to predefined hand configurations relevant to ADLs. Motion capture data was acquired as the ground truth for hand movements at different speeds (0.5 Hz, 1 Hz, & 2 Hz) for the index, middle, ring, and pinky fingers. We were able to get promising SVC classification results on a subset of our collected data set. We demonstrated a correspondence between the predicted MCP joint angles and the actual MCP joint angles for the fingers, with an average root mean square error of 7.35 degrees. We implemented a low latency (6.25 - 9.1 Hz) pipeline for the prediction of both MCP joint angles and hand configuration estimation aimed at real-time control of digital devices, AR/VR interfaces, and physical robots.
DISCO : efficient unsupervised decoding for discrete natural language problems via convex relaxation
Jul 13, 2021
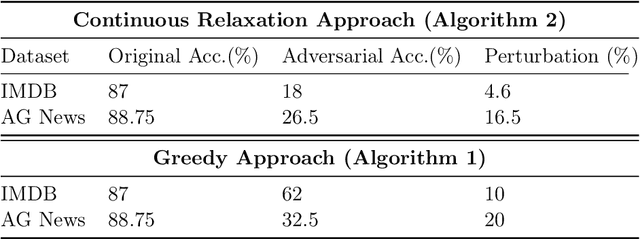
In this paper we study test time decoding; an ubiquitous step in almost all sequential text generation task spanning across a wide array of natural language processing (NLP) problems. Our main contribution is to develop a continuous relaxation framework for the combinatorial NP-hard decoding problem and propose Disco - an efficient algorithm based on standard first order gradient based. We provide tight analysis and show that our proposed algorithm linearly converges to within $\epsilon$ neighborhood of the optima. Finally, we perform preliminary experiments on the task of adversarial text generation and show superior performance of Disco over several popular decoding approaches.
A Spatial-Temporal Decomposition Based Deep Neural Network for Time Series Forecasting
Feb 02, 2019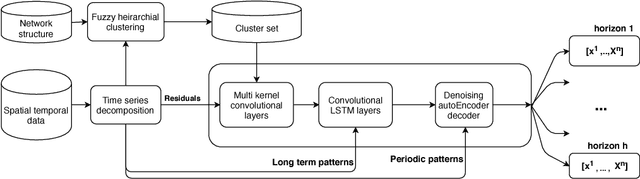
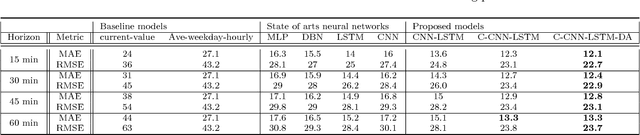
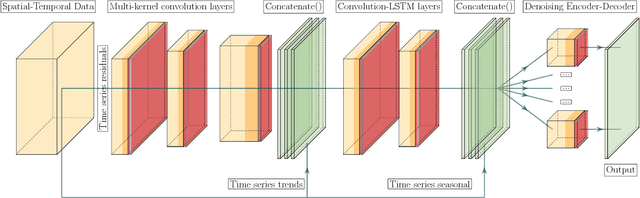

Spatial time series forecasting problems arise in a broad range of applications, such as environmental and transportation problems. These problems are challenging because of the existence of specific spatial, short-term and long-term patterns, and the curse of dimensionality. In this paper, we propose a deep neural network framework for large-scale spatial time series forecasting problems. We explicitly designed the neural network architecture for capturing various types of patterns. In preprocessing, a time series decomposition method is applied to separately feed short-term, long-term and spatial patterns into different components of a neural network. A fuzzy clustering method finds cluster of neighboring time series based on similarity of time series residuals; as they can be meaningful short-term patterns for spatial time series. In neural network architecture, each kernel of a multi-kernel convolution layer is applied to a cluster of time series to extract short-term features in neighboring areas. The output of convolution layer is concatenated by trends and followed by convolution-LSTM layer to capture long-term patterns in larger regional areas. To make a robust prediction when faced with missing data, an unsupervised pretrained denoising autoencoder reconstructs the output of the model in a fine-tuning step. The experimental results illustrate the model outperforms baseline and state of the art models in a traffic flow prediction dataset.
Kunster -- AR Art Video Maker -- Real time video neural style transfer on mobile devices
May 07, 2020
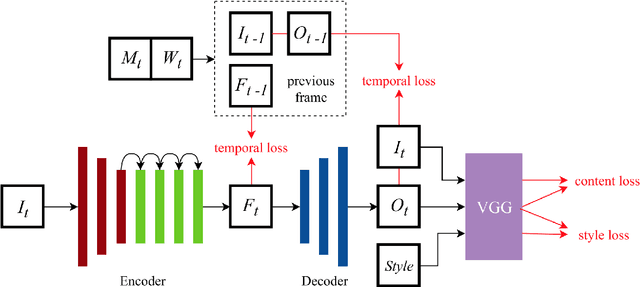


Neural style transfer is a well-known branch of deep learning research, with many interesting works and two major drawbacks. Most of the works in the field are hard to use by non-expert users and substantial hardware resources are required. In this work, we present a solution to both of these problems. We have applied neural style transfer to real-time video (over 25 frames per second), which is capable of running on mobile devices. We also investigate the works on achieving temporal coherence and present the idea of fine-tuning, already trained models, to achieve stable video. What is more, we also analyze the impact of the common deep neural network architecture on the performance of mobile devices with regard to number of layers and filters present. In the experiment section we present the results of our work with respect to the iOS devices and discuss the problems present in current Android devices as well as future possibilities. At the end we present the qualitative results of stylization and quantitative results of performance tested on the iPhone 11 Pro and iPhone 6s. The presented work is incorporated in Kunster - AR Art Video Maker application available in the Apple's App Store.
StreaMRAK a Streaming Multi-Resolution Adaptive Kernel Algorithm
Sep 07, 2021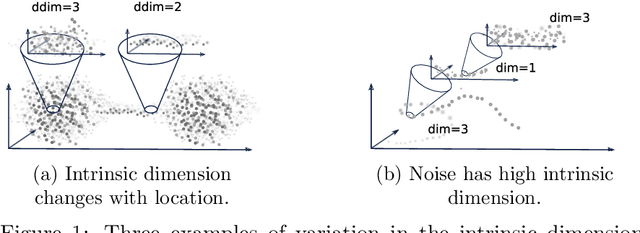
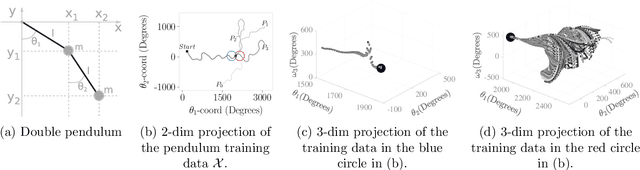
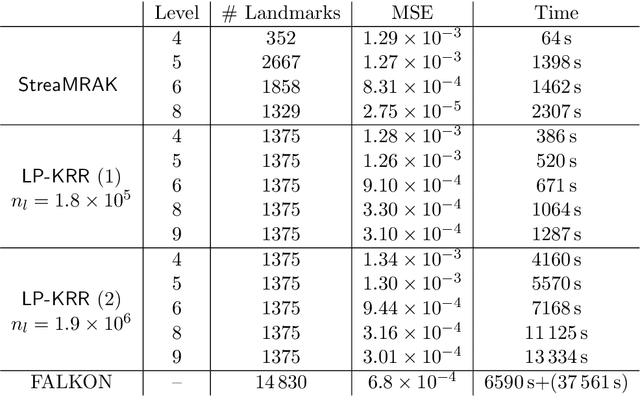
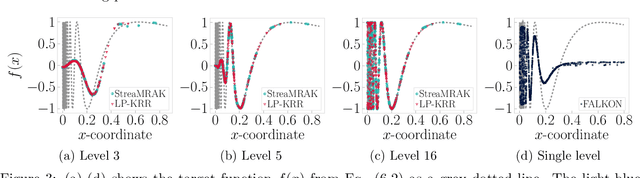
Kernel ridge regression (KRR) is a popular scheme for non-linear non-parametric learning. However, existing implementations of KRR require that all the data is stored in the main memory, which severely limits the use of KRR in contexts where data size far exceeds the memory size. Such applications are increasingly common in data mining, bioinformatics, and control. A powerful paradigm for computing on data sets that are too large for memory is the streaming model of computation, where we process one data sample at a time, discarding each sample before moving on to the next one. In this paper, we propose StreaMRAK - a streaming version of KRR. StreaMRAK improves on existing KRR schemes by dividing the problem into several levels of resolution, which allows continual refinement to the predictions. The algorithm reduces the memory requirement by continuously and efficiently integrating new samples into the training model. With a novel sub-sampling scheme, StreaMRAK reduces memory and computational complexities by creating a sketch of the original data, where the sub-sampling density is adapted to the bandwidth of the kernel and the local dimensionality of the data. We present a showcase study on two synthetic problems and the prediction of the trajectory of a double pendulum. The results show that the proposed algorithm is fast and accurate.
On Board Volcanic Eruption Detection through CNNs and Satellite Multispectral Imagery
Jul 28, 2021
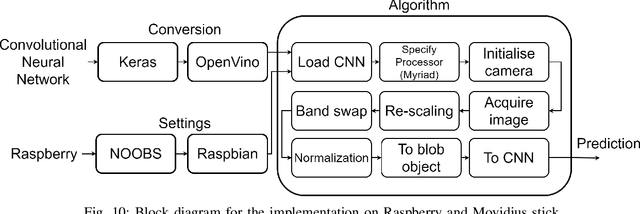


In recent years, the growth of Machine Learning (ML) algorithms has raised the number of studies including their applicability in a variety of different scenarios. Among all, one of the hardest ones is the aerospace, due to its peculiar physical requirements. In this context, a feasibility study and a first prototype for an Artificial Intelligence (AI) model to be deployed on board satellites are presented in this work. As a case study, the detection of volcanic eruptions has been investigated as a method to swiftly produce alerts and allow immediate interventions. Two Convolutional Neural Networks (CNNs) have been proposed and designed, showing how to efficiently implement them for identifying the eruptions and at the same time adapting their complexity in order to fit on board requirements.
Allocating Indivisible Goods to Strategic Agents: Pure Nash Equilibria and Fairness
Sep 17, 2021We consider the problem of fairly allocating a set of indivisible goods to a set of strategic agents with additive valuation functions. We assume no monetary transfers and, therefore, a mechanism in our setting is an algorithm that takes as input the reported -- rather than the true -- values of the agents. Our main goal is to explore whether there exist mechanisms that have pure Nash equilibria for every instance and, at the same time, provide fairness guarantees for the allocations that correspond to these equilibria. We focus on two relaxations of envy-freeness, namely envy-freeness up to one good (EF1), and envy-freeness up to any good (EFX), and we positively answer the above question. In particular, we study two algorithms that are known to produce such allocations in the non-strategic setting: Round-Robin (EF1 allocations for any number of agents) and a cut-and-choose algorithm of Plaut and Roughgarden [SIAM Journal of Discrete Mathematics, 2020] (EFX allocations for two agents). For Round-Robin we show that all of its pure Nash equilibria induce allocations that are EF1 with respect to the underlying true values, while for the algorithm of Plaut and Roughgarden we show that the corresponding allocations not only are EFX but also satisfy maximin share fairness, something that is not true for this algorithm in the non-strategic setting! Further, we show that a weaker version of the latter result holds for any mechanism for two agents that always has pure Nash equilibria which all induce EFX allocations.
Effective and interpretable dispatching rules for dynamic job shops via guided empirical learning
Sep 07, 2021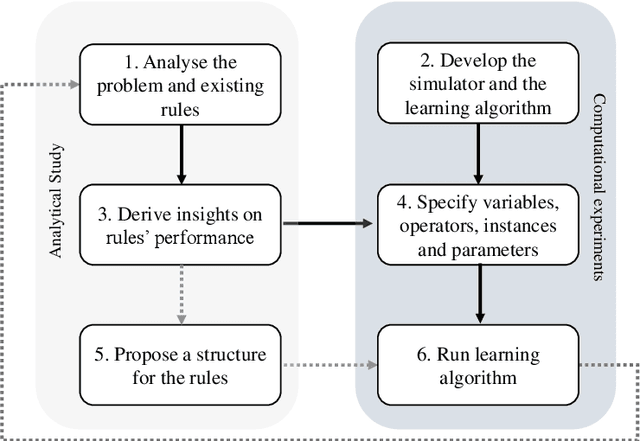
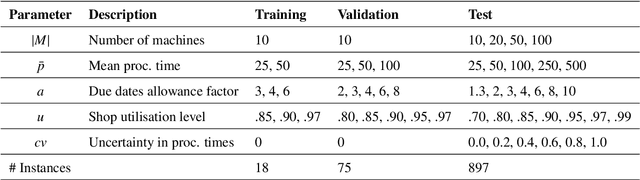
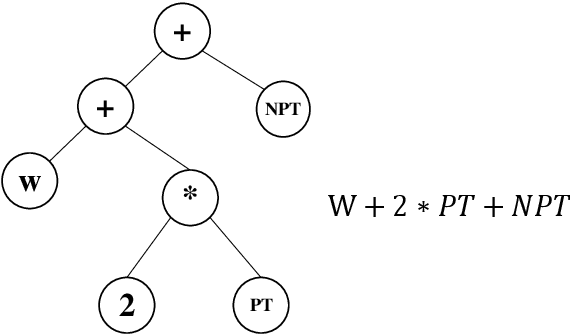
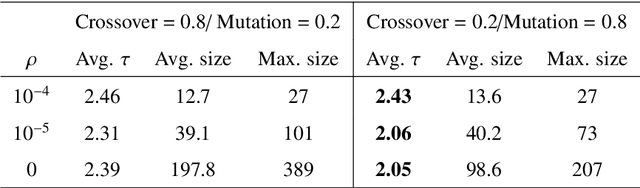
The emergence of Industry 4.0 is making production systems more flexible and also more dynamic. In these settings, schedules often need to be adapted in real-time by dispatching rules. Although substantial progress was made until the '90s, the performance of these rules is still rather limited. The machine learning literature is developing a variety of methods to improve them, but the resulting rules are difficult to interpret and do not generalise well for a wide range of settings. This paper is the first major attempt at combining machine learning with domain problem reasoning for scheduling. The idea consists of using the insights obtained with the latter to guide the empirical search of the former. Our hypothesis is that this guided empirical learning process should result in dispatching rules that are effective and interpretable and which generalise well to different instance classes. We test our approach in the classical dynamic job shop scheduling problem minimising tardiness, which is one of the most well-studied scheduling problems. Nonetheless, results suggest that our approach was able to find new state-of-the-art rules, which significantly outperform the existing literature in the vast majority of settings, from loose to tight due dates and from low utilisation conditions to congested shops. Overall, the average improvement is 19%. Moreover, the rules are compact, interpretable, and generalise well to extreme, unseen scenarios.