 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Explainable Artificial Intelligence (XAI) on TimeSeries Data: A Survey
Apr 02, 2021
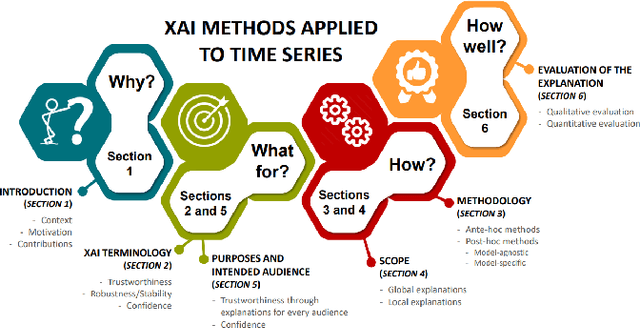
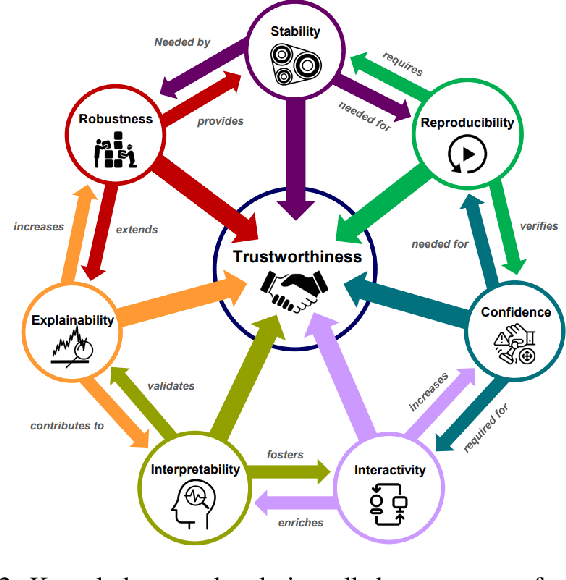
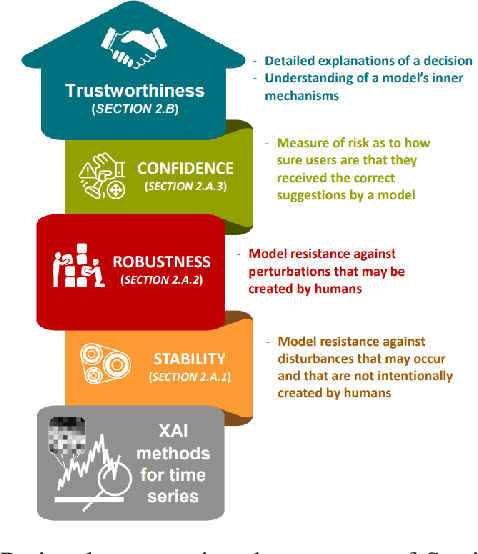
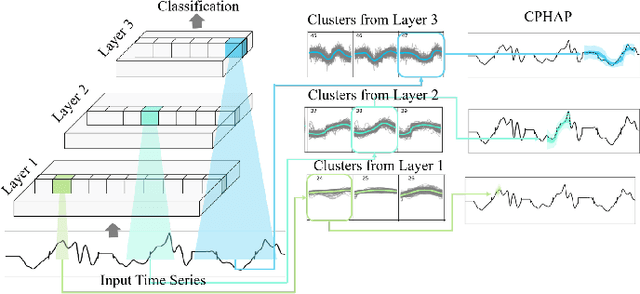
Most of state of the art methods applied on time series consist of deep learning methods that are too complex to be interpreted. This lack of interpretability is a major drawback, as several applications in the real world are critical tasks, such as the medical field or the autonomous driving field. The explainability of models applied on time series has not gather much attention compared to the computer vision or the natural language processing fields. In this paper, we present an overview of existing explainable AI (XAI) methods applied on time series and illustrate the type of explanations they produce. We also provide a reflection on the impact of these explanation methods to provide confidence and trust in the AI systems.
A survey of Monte Carlo methods for noisy and costly densities with application to reinforcement learning
Aug 01, 2021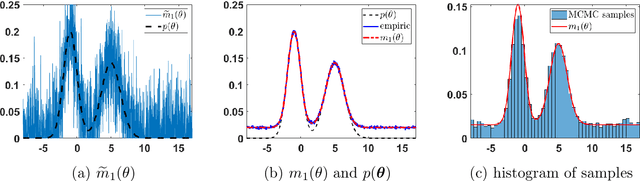
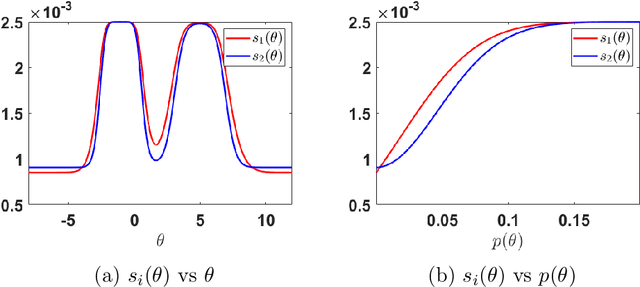
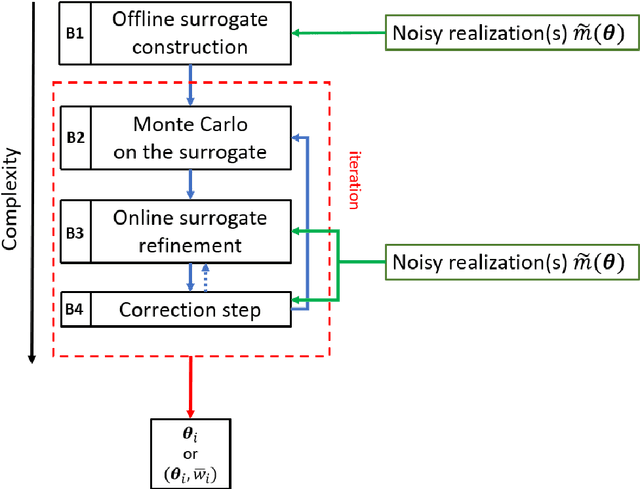

This survey gives an overview of Monte Carlo methodologies using surrogate models, for dealing with densities which are intractable, costly, and/or noisy. This type of problem can be found in numerous real-world scenarios, including stochastic optimization and reinforcement learning, where each evaluation of a density function may incur some computationally-expensive or even physical (real-world activity) cost, likely to give different results each time. The surrogate model does not incur this cost, but there are important trade-offs and considerations involved in the choice and design of such methodologies. We classify the different methodologies into three main classes and describe specific instances of algorithms under a unified notation. A modular scheme which encompasses the considered methods is also presented. A range of application scenarios is discussed, with special attention to the likelihood-free setting and reinforcement learning. Several numerical comparisons are also provided.
Performer Identification From Symbolic Representation of Music Using Statistical Models
Aug 05, 2021
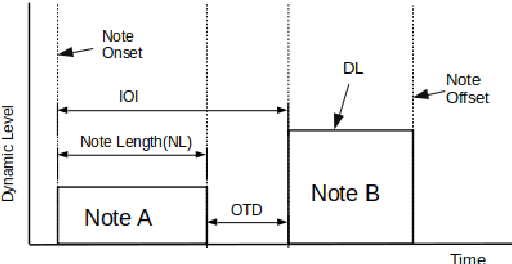
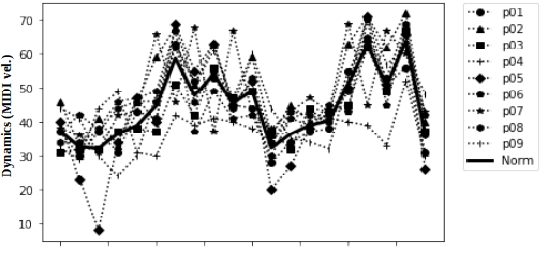
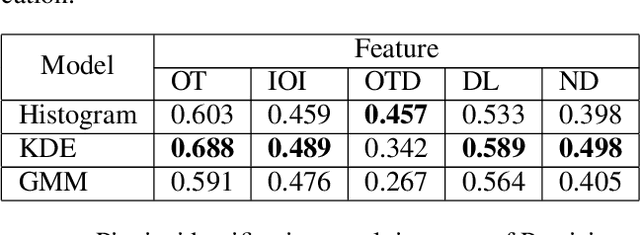
Music Performers have their own idiosyncratic way of interpreting a musical piece. A group of skilled performers playing the same piece of music would likely to inject their unique artistic styles in their performances. The variations of the tempo, timing, dynamics, articulation etc. from the actual notated music are what make the performers unique in their performances. This study presents a dataset consisting of four movements of Schubert's ``Sonata in B-flat major, D.960" performed by nine virtuoso pianists individually. We proposed and extracted a set of expressive features that are able to capture the characteristics of an individual performer's style. We then present a performer identification method based on the similarity of feature distribution, given a set of piano performances. The identification is done considering each feature individually as well as a fusion of the features. Results show that the proposed method achieved a precision of 0.903 using fusion features. Moreover, the onset time deviation feature shows promising result when considered individually.
Object-Augmented RGB-D SLAM for Wide-Disparity Relocalisation
Aug 05, 2021



We propose a novel object-augmented RGB-D SLAM system that is capable of constructing a consistent object map and performing relocalisation based on centroids of objects in the map. The approach aims to overcome the view dependence of appearance-based relocalisation methods using point features or images. During the map construction, we use a pre-trained neural network to detect objects and estimate 6D poses from RGB-D data. An incremental probabilistic model is used to aggregate estimates over time to create the object map. Then in relocalisation, we use the same network to extract objects-of-interest in the `lost' frames. Pairwise geometric matching finds correspondences between map and frame objects, and probabilistic absolute orientation followed by application of iterative closest point to dense depth maps and object centroids gives relocalisation. Results of experiments in desktop environments demonstrate very high success rates even for frames with widely different viewpoints from those used to construct the map, significantly outperforming two appearance-based methods.
Improving Deep Learning for HAR with shallow LSTMs
Aug 05, 2021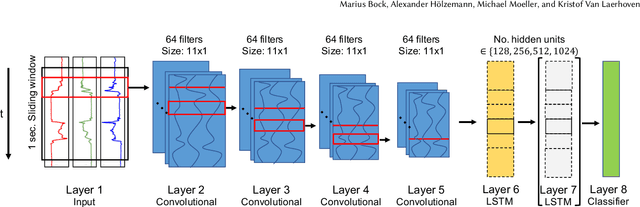
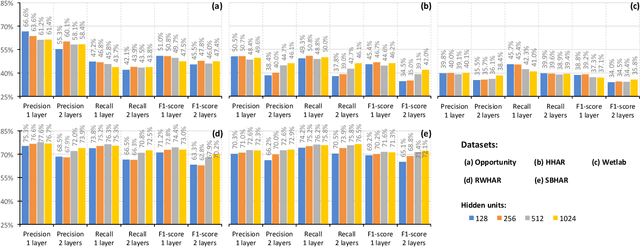
Recent studies in Human Activity Recognition (HAR) have shown that Deep Learning methods are able to outperform classical Machine Learning algorithms. One popular Deep Learning architecture in HAR is the DeepConvLSTM. In this paper we propose to alter the DeepConvLSTM architecture to employ a 1-layered instead of a 2-layered LSTM. We validate our architecture change on 5 publicly available HAR datasets by comparing the predictive performance with and without the change employing varying hidden units within the LSTM layer(s). Results show that across all datasets, our architecture consistently improves on the original one: Recognition performance increases up to 11.7% for the F1-score, and our architecture significantly decreases the amount of learnable parameters. This improvement over DeepConvLSTM decreases training time by as much as 48%. Our results stand in contrast to the belief that one needs at least a 2-layered LSTM when dealing with sequential data. Based on our results we argue that said claim might not be applicable to sensor-based HAR.
HyperJump: Accelerating HyperBand via Risk Modelling
Aug 05, 2021
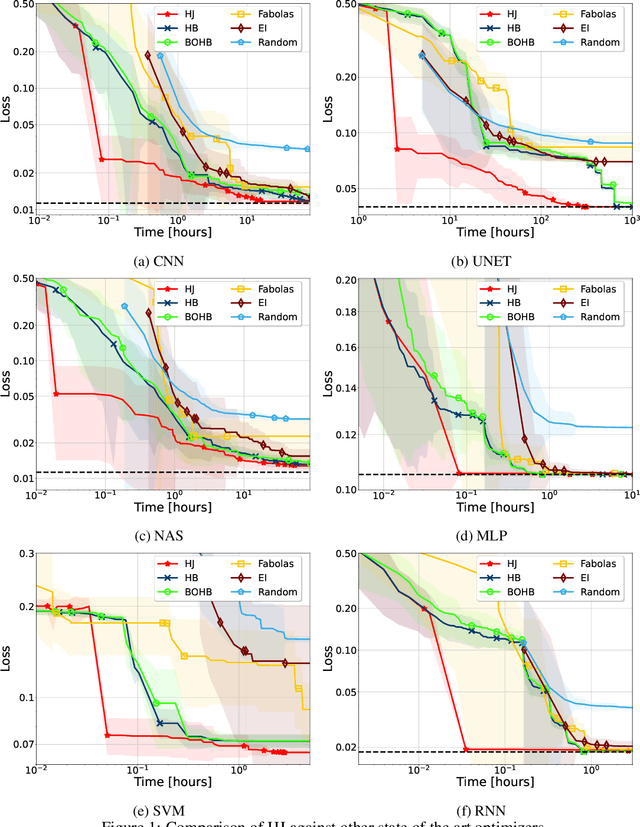
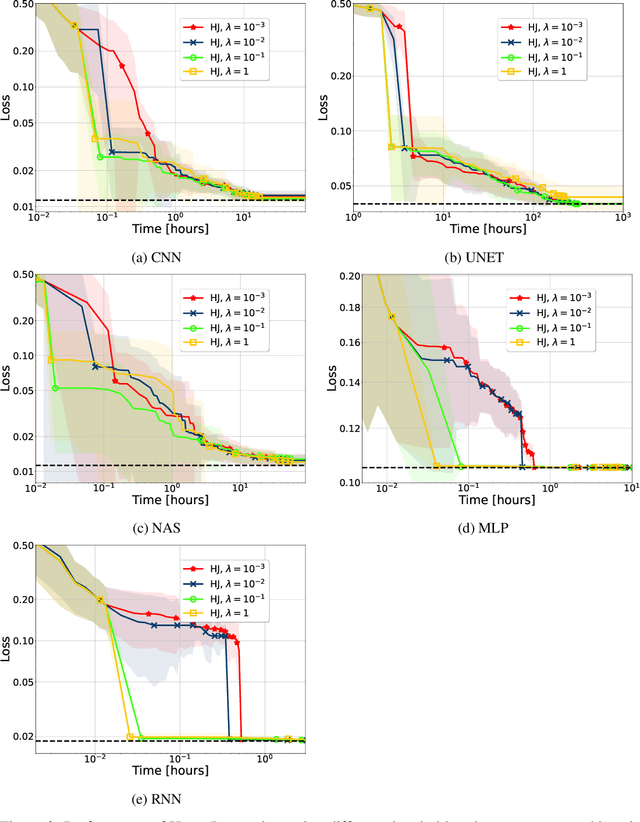
In the literature on hyper-parameter tuning, a number of recent solutions rely on low-fidelity observations (e.g., training with sub-sampled datasets or for short periods of time) to extrapolate good configurations to use when performing full training. Among these, HyperBand is arguably one of the most popular solutions, due to its efficiency and theoretically provable robustness. In this work, we introduce HyperJump, a new approach that builds on HyperBand's robust search strategy and complements it with novel model-based risk analysis techniques that accelerate the search by jumping the evaluation of low risk configurations, i.e., configurations that are likely to be discarded by HyperBand. We evaluate HyperJump on a suite of hyper-parameter optimization problems and show that it provides over one-order of magnitude speed-ups on a variety of deep-learning and kernel-based learning problems when compared to HyperBand as well as to a number of state of the art optimizers.
2.5D Thermometry Maps for MRI-guided Tumor Ablation
Aug 12, 2021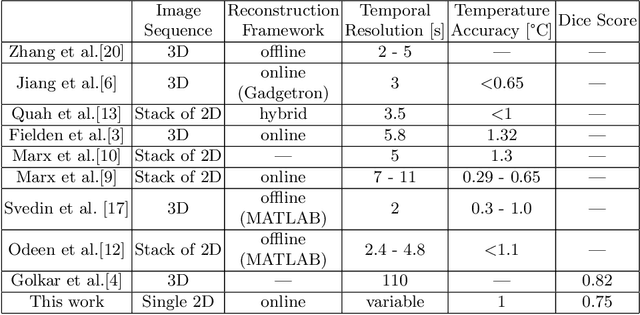
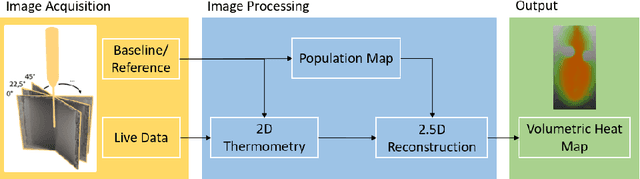
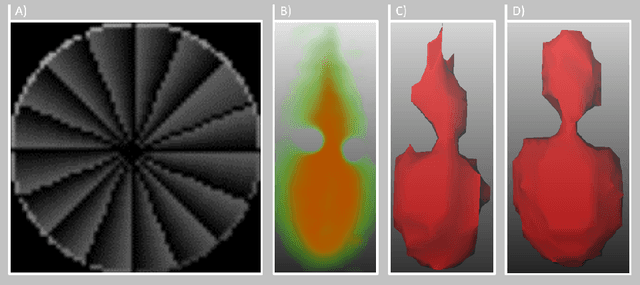
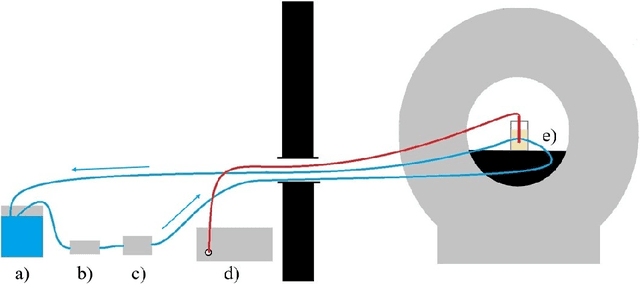
Fast and reliable monitoring of volumetric heat distribution during MRI-guided tumor ablation is an urgent clinical need. In this work, we introduce a method for generating 2.5D thermometry maps from uniformly distributed 2D MRI phase images rotated around the applicator's main axis. The images can be fetched directly from the MR device, reducing the delay between image acquisition and visualization. For reconstruction, we use a weighted interpolation on a cylindric coordinate representation to calculate the heat value of voxels in a region of interest. A pilot study on 13 ex vivo bio protein phantoms with flexible tubes to simulate a heat sink effect was conducted to evaluate our method. After thermal ablation, we compared the measured coagulation zone extracted from the post-treatment MR data set with the output of the 2.5D thermometry map. The results show a mean Dice score of 0.75+-0.07, a sensitivity of 0.77+-0.03, and a reconstruction time within 18.02ms+-5.91ms. Future steps should address improving temporal resolution and accuracy, e.g., incorporating advanced bioheat transfer simulations.
Q-Learning for Conflict Resolution in B5G Network Automation
Jul 28, 2021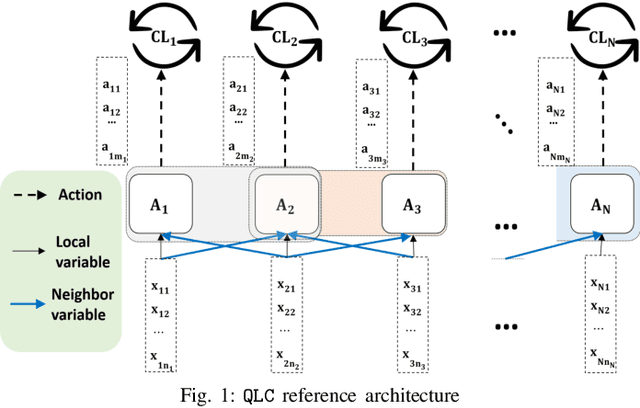
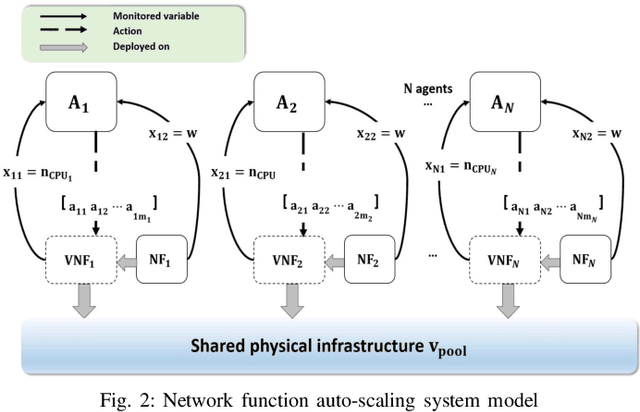
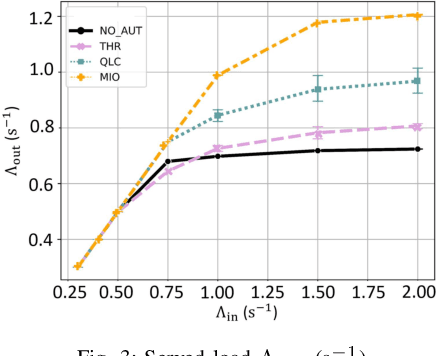
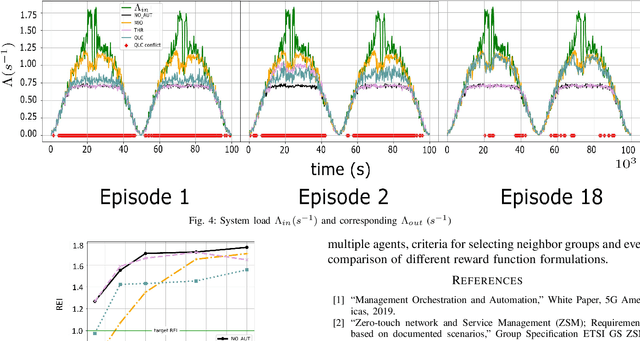
Network automation is gaining significant attention in the development of B5G networks, primarily for reducing operational complexity, expenditures and improving network efficiency. Concurrently operating closed loops aiming for individual optimization targets may cause conflicts which, left unresolved, would lead to significant degradation in network Key Performance Indicators (KPIs), thereby resulting in sub-optimal network performance. Centralized coordination, albeit optimal, is impractical in large scale networks and for time-critical applications. Decentralized approaches are therefore envisaged in the evolution to B5G and subsequently, 6G networks. This work explores pervasive intelligence for conflict resolution in network automation, as an alternative to centralized orchestration. A Q-Learning decentralized approach to network automation is proposed, and an application to network slice auto-scaling is designed and evaluated. Preliminary results highlight the potential of the proposed scheme and justify further research work in this direction.
Influence Estimation and Maximization via Neural Mean-Field Dynamics
Jun 03, 2021



We propose a novel learning framework using neural mean-field (NMF) dynamics for inference and estimation problems on heterogeneous diffusion networks. Our new framework leverages the Mori-Zwanzig formalism to obtain an exact evolution equation of the individual node infection probabilities, which renders a delay differential equation with memory integral approximated by learnable time convolution operators. Directly using information diffusion cascade data, our framework can simultaneously learn the structure of the diffusion network and the evolution of node infection probabilities. Connections between parameter learning and optimal control are also established, leading to a rigorous and implementable algorithm for training NMF. Moreover, we show that the projected gradient descent method can be employed to solve the challenging influence maximization problem, where the gradient is computed extremely fast by integrating NMF forward in time just once in each iteration. Extensive empirical studies show that our approach is versatile and robust to variations of the underlying diffusion network models, and significantly outperform existing approaches in accuracy and efficiency on both synthetic and real-world data.
NDPNet: A novel non-linear data projection network for few-shot fine-grained image classification
Jul 09, 2021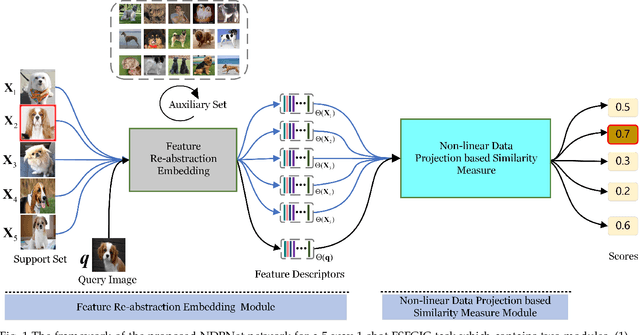
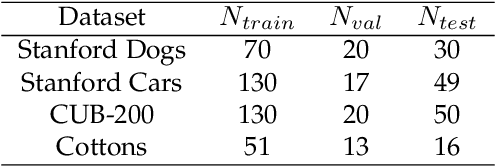
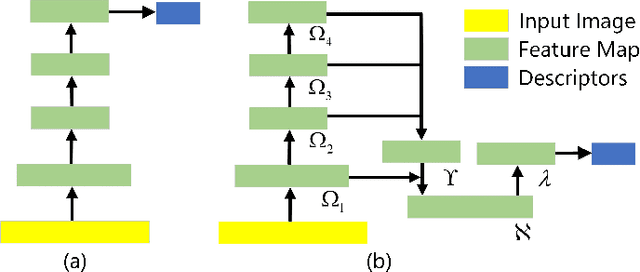
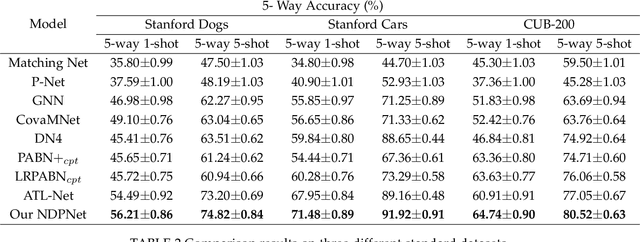
Metric-based few-shot fine-grained image classification (FSFGIC) aims to learn a transferable feature embedding network by estimating the similarities between query images and support classes from very few examples. In this work, we propose, for the first time, to introduce the non-linear data projection concept into the design of FSFGIC architecture in order to address the limited sample problem in few-shot learning and at the same time to increase the discriminability of the model for fine-grained image classification. Specifically, we first design a feature re-abstraction embedding network that has the ability to not only obtain the required semantic features for effective metric learning but also re-enhance such features with finer details from input images. Then the descriptors of the query images and the support classes are projected into different non-linear spaces in our proposed similarity metric learning network to learn discriminative projection factors. This design can effectively operate in the challenging and restricted condition of a FSFGIC task for making the distance between the samples within the same class smaller and the distance between samples from different classes larger and for reducing the coupling relationship between samples from different categories. Furthermore, a novel similarity measure based on the proposed non-linear data project is presented for evaluating the relationships of feature information between a query image and a support set. It is worth to note that our proposed architecture can be easily embedded into any episodic training mechanisms for end-to-end training from scratch. Extensive experiments on FSFGIC tasks demonstrate the superiority of the proposed methods over the state-of-the-art benchmarks.