 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Real-time Dynamic-Mode Scheduling Using Single-Integration Hybrid Optimization for Linear Time-Varying Systems
Aug 31, 2017
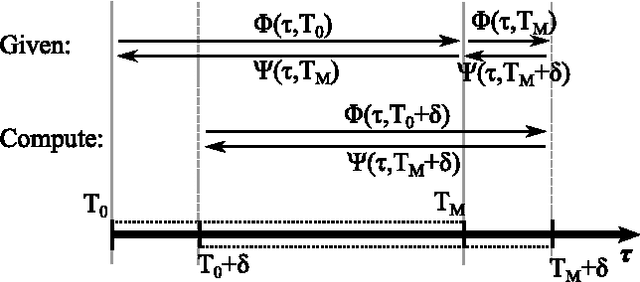
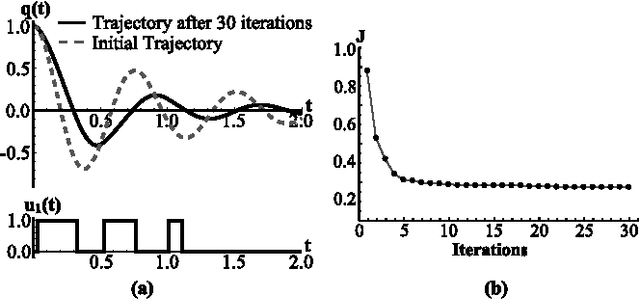
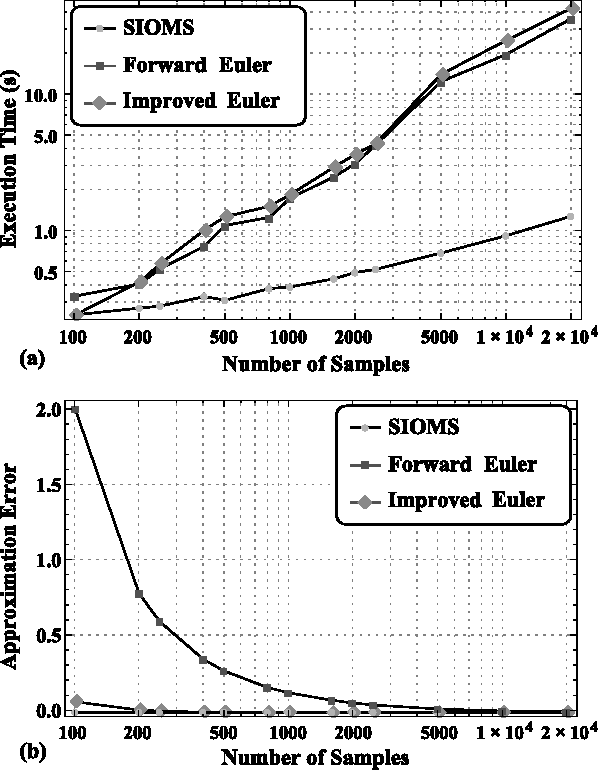
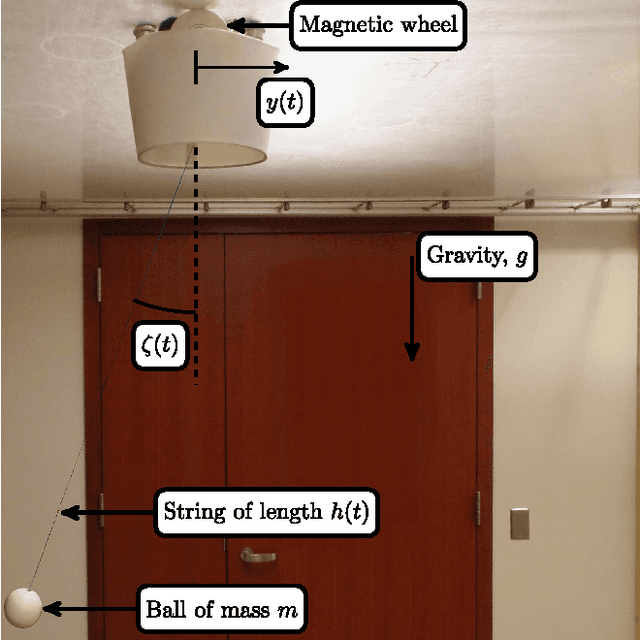
This paper considers the problem of real-time mode scheduling in linear time-varying switched systems subject to a quadratic cost functional. The execution time of hybrid control algorithms is often prohibitive for real-time applications and typically may only be reduced at the expense of approximation accuracy. We address this trade-off by taking advantage of system linearity to formulate a projection-based approach so that no simulation is required during open-loop optimization. A numerical example shows how the proposed open-loop algorithm outperforms methods employing common numerical integration techniques. Additionally, we follow a receding-horizon scheme to apply real-time closed-loop hybrid control to a customized experimental setup, using the Robot Operating System (ROS). In particular, we demonstrate---both in Monte-Carlo simulation and in experiment---that optimal hybrid control efficiently regulates a cart and suspended mass system in real time.
The Legislative Recipe: Syntax for Machine-Readable Legislation
Aug 19, 2021Legal interpretation is a linguistic venture. In judicial opinions, for example, courts are often asked to interpret the text of statutes and legislation. As time has shown, this is not always as easy as it sounds. Matters can hinge on vague or inconsistent language and, under the surface, human biases can impact the decision-making of judges. This raises an important question: what if there was a method of extracting the meaning of statutes consistently? That is, what if it were possible to use machines to encode legislation in a mathematically precise form that would permit clearer responses to legal questions? This article attempts to unpack the notion of machine-readability, providing an overview of both its historical and recent developments. The paper will reflect on logic syntax and symbolic language to assess the capacity and limits of representing legal knowledge. In doing so, the paper seeks to move beyond existing literature to discuss the implications of various approaches to machine-readable legislation. Importantly, this study hopes to highlight the challenges encountered in this burgeoning ecosystem of machine-readable legislation against existing human-readable counterparts.
Real-Time Monocular Object-Model Aware Sparse SLAM
Mar 06, 2019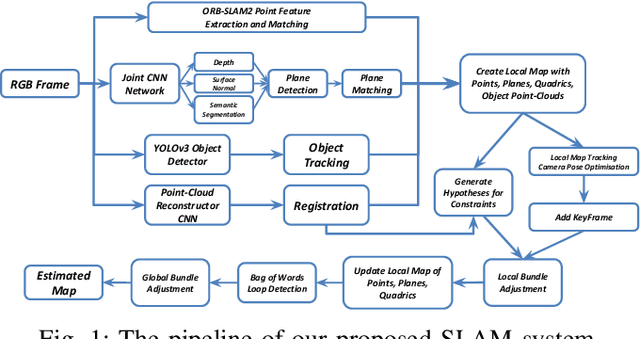
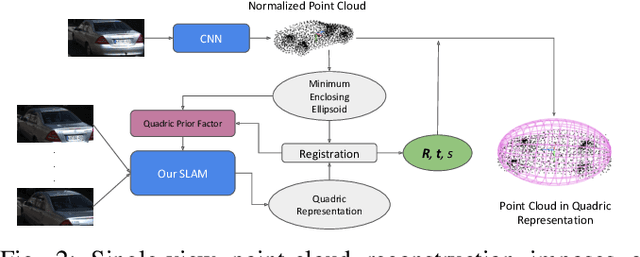
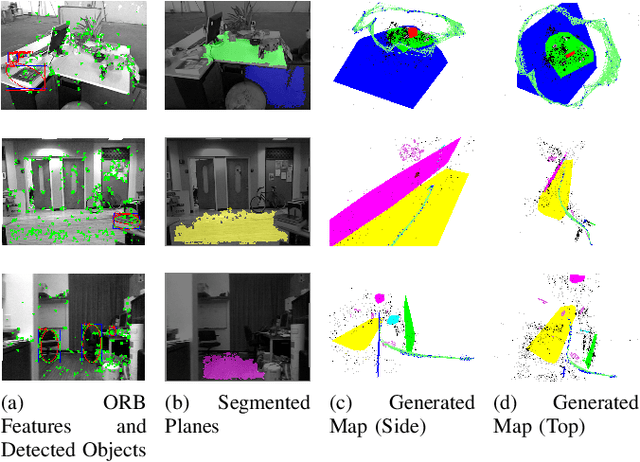
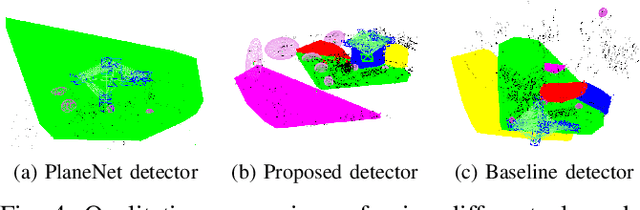
Simultaneous Localization And Mapping (SLAM) is a fundamental problem in mobile robotics. While sparse point-based SLAM methods provide accurate camera localization, the generated maps lack semantic information. On the other hand, state of the art object detection methods provide rich information about entities present in the scene from a single image. This work incorporates a real-time deep-learned object detector to the monocular SLAM framework for representing generic objects as quadrics that permit detections to be seamlessly integrated while allowing the real-time performance. Finer reconstruction of an object, learned by a CNN network, is also incorporated and provides a shape prior for the quadric leading further refinement. To capture the dominant structure of the scene, additional planar landmarks are detected by a CNN-based plane detector and modeled as independent landmarks in the map. Extensive experiments support our proposed inclusion of semantic objects and planar structures directly in the bundle-adjustment of SLAM - Semantic SLAM - that enriches the reconstructed map semantically, while significantly improving the camera localization. The performance of our SLAM system is demonstrated in https://youtu.be/UMWXd4sHONw and https://youtu.be/QPQqVrvP0dE .
Adaptive Simultaneous Magnetic Actuation and Localization for WCE in a Tubular Environment
Aug 25, 2021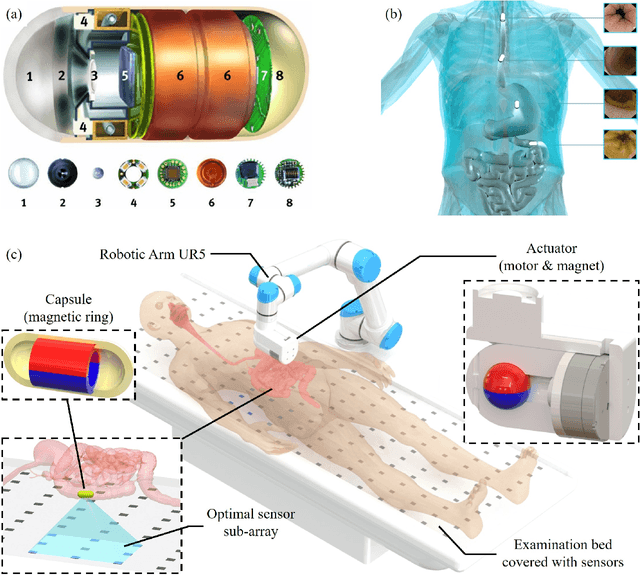


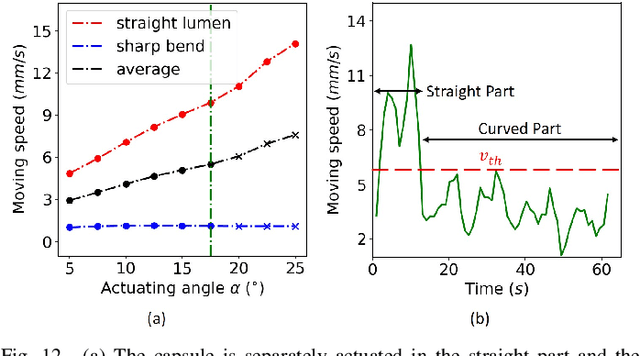
Simultaneous Magnetic Actuation and Localization (SMAL) is a promising technology for active wireless capsule endoscopy (WCE). In this paper, an adaptive SMAL system is presented to efficiently propel and precisely locate a capsule in a tubular environment with complex shapes. In order to track the capsule with high localization accuracy and update frequency in a large workspace, we propose a mechanism that can automatically activate a sub-array of sensors with the optimal layout during the capsule movement. The improved multiple objects tracking (IMOT) method is simplified and adapted to our system to estimate the 6-D pose of the capsule in real time. Also, we study the locomotion of a magnetically actuated capsule in a tubular environment, and formulate a method to adaptively adjust the pose of the actuator to improve the propulsion efficiency. Our presented methods are applicable to other permanent magnet-based SMAL systems, and help to improve the actuation efficiency of active WCE. We verify the effectiveness of our proposed system in extensive experiments on phantoms and ex-vivo animal organs. The results demonstrate that our system can achieve convincing performance compared with the state-of-the-art ones in terms of actuation efficiency, workspace size, robustness, localization accuracy and update frequency.
Through the Looking Glass: Diminishing Occlusions in Robot Vision Systems with Mirror Reflections
Aug 31, 2021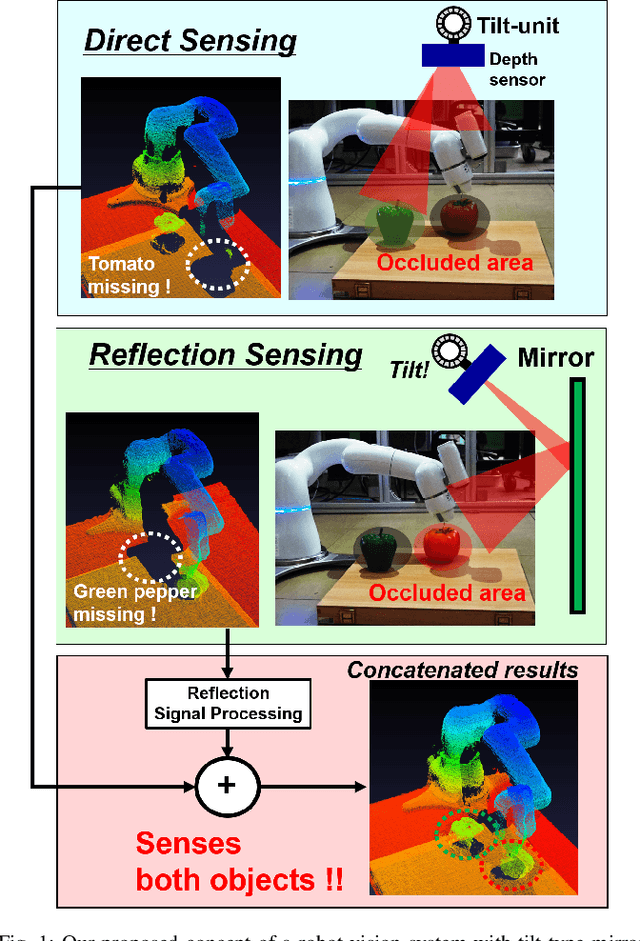
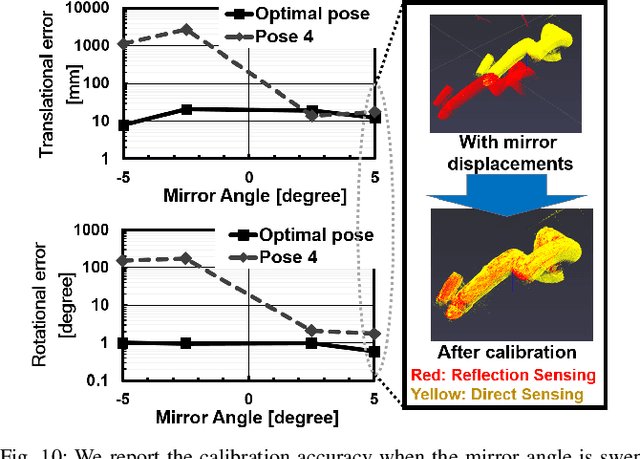
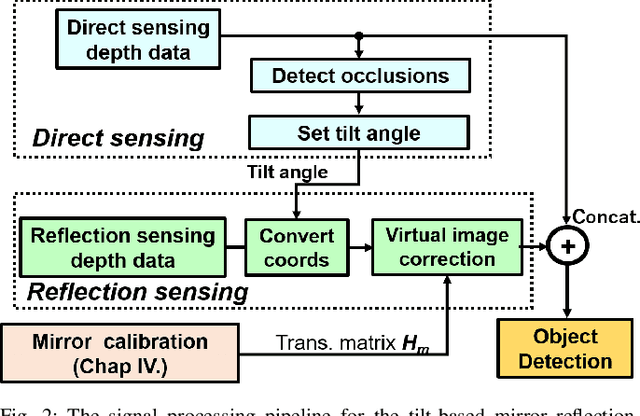
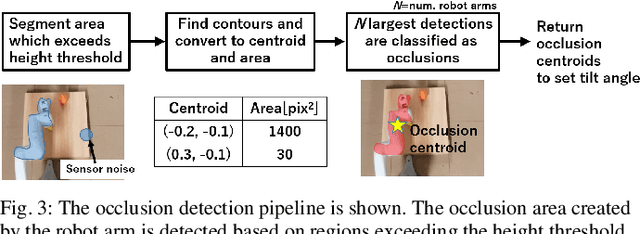
The quality of robot vision greatly affects the performance of automation systems, where occlusions stand as one of the biggest challenges. If the target is occluded from the sensor, detecting and grasping such objects become very challenging. For example, when multiple robot arms cooperate in a single workplace, occlusions will be created under the robot arm itself and hide objects underneath. While occlusions can be greatly reduced by installing multiple sensors, the increase in sensor costs cannot be ignored. Moreover, the sensor placements must be rearranged every time the robot operation routine and layout change. To diminish occlusions, we propose the first robot vision system with tilt-type mirror reflection sensing. By instantly tilting the sensor itself, we obtain two sensing results with different views: conventional direct line-of-sight sensing and non-line-of-sight sensing via mirror reflections. Our proposed system removes occlusions adaptively by detecting the occlusions in the scene and dynamically configuring the sensor tilt angle to sense the detected occluded area. Thus, sensor rearrangements are not required even after changes in robot operation or layout. Since the required hardware is the tilt-unit and a commercially available mirror, the cost increase is marginal. Through experiments, we show that our system can achieve a similar detection accuracy as systems with multiple sensors, regardless of the single-sensor implementation.
Machine learning models for DOTA 2 outcomes prediction
Jun 03, 2021
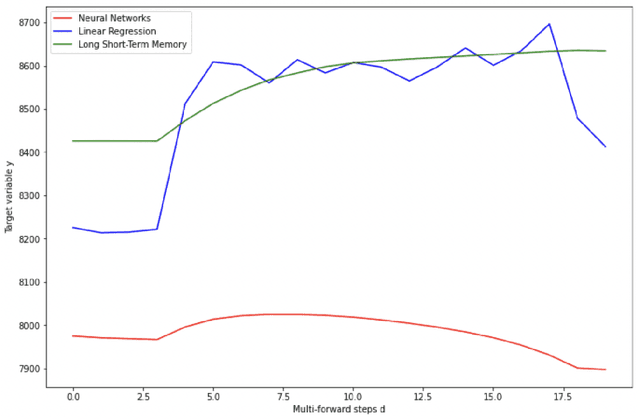

Prediction of the real-time multiplayer online battle arena (MOBA) games' match outcome is one of the most important and exciting tasks in Esports analytical research. This research paper predominantly focuses on building predictive machine and deep learning models to identify the outcome of the Dota 2 MOBA game using the new method of multi-forward steps predictions. Three models were investigated and compared: Linear Regression (LR), Neural Networks (NN), and a type of recurrent neural network Long Short-Term Memory (LSTM). In order to achieve the goals, we developed a data collecting python server using Game State Integration (GSI) to track the real-time data of the players. Once the exploratory feature analysis and tuning hyper-parameters were done, our models' experiments took place on different players with dissimilar backgrounds of playing experiences. The achieved accuracy scores depend on the multi-forward prediction parameters, which for the worse case in linear regression 69\% but on average 82\%, while in the deep learning models hit the utmost accuracy of prediction on average 88\% for NN, and 93\% for LSTM models.
Quant GANs: Deep Generation of Financial Time Series
Jul 15, 2019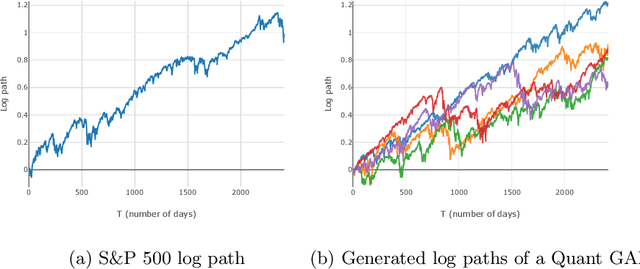

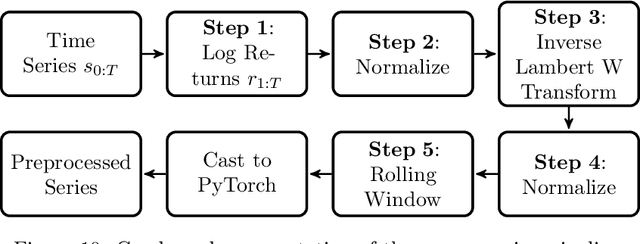
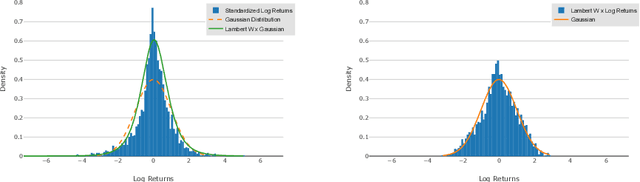
Modeling financial time series by stochastic processes is a challenging task and a central area of research in financial mathematics. In this paper, we break through this barrier and present Quant GANs, a data-driven model which is inspired by the recent success of generative adversarial networks (GANs). Quant GANs consist of a generator and discriminator function which utilize temporal convolutional networks (TCNs) and thereby achieve to capture longer-ranging dependencies such as the presence of volatility clusters. Furthermore, the generator function is explicitly constructed such that the induced stochastic process allows a transition to its risk-neutral distribution. Our numerical results highlight that distributional properties for small and large lags are in an excellent agreement and dependence properties such as volatility clusters, leverage effects, and serial autocorrelations can be generated by the generator function of Quant GANs, demonstrably in high fidelity.
Reinforcement Learning for Adaptive Optimal Stationary Control of Linear Stochastic Systems
Jul 20, 2021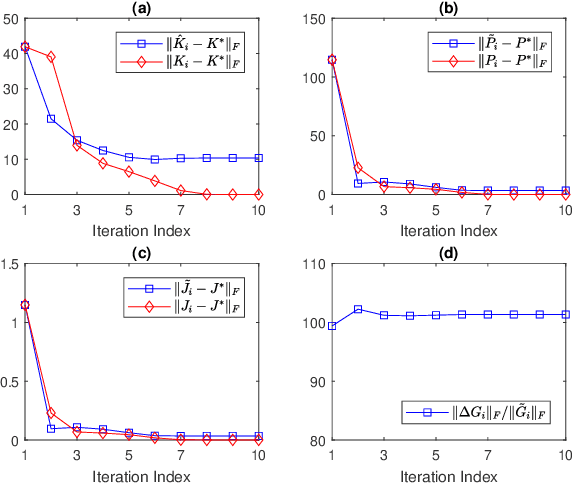
This paper studies the adaptive optimal stationary control of continuous-time linear stochastic systems with both additive and multiplicative noises, using reinforcement learning techniques. Based on policy iteration, a novel off-policy reinforcement learning algorithm, named optimistic least-squares-based policy iteration, is proposed which is able to iteratively find near-optimal policies of the adaptive optimal stationary control problem directly from input/state data without explicitly identifying any system matrices, starting from an initial admissible control policy. The solutions given by the proposed optimistic least-squares-based policy iteration are proved to converge to a small neighborhood of the optimal solution with probability one, under mild conditions. The application of the proposed algorithm to a triple inverted pendulum example validates its feasibility and effectiveness.
A Reinforcement Learning Approach for GNSS Spoofing Attack Detection of Autonomous Vehicles
Aug 19, 2021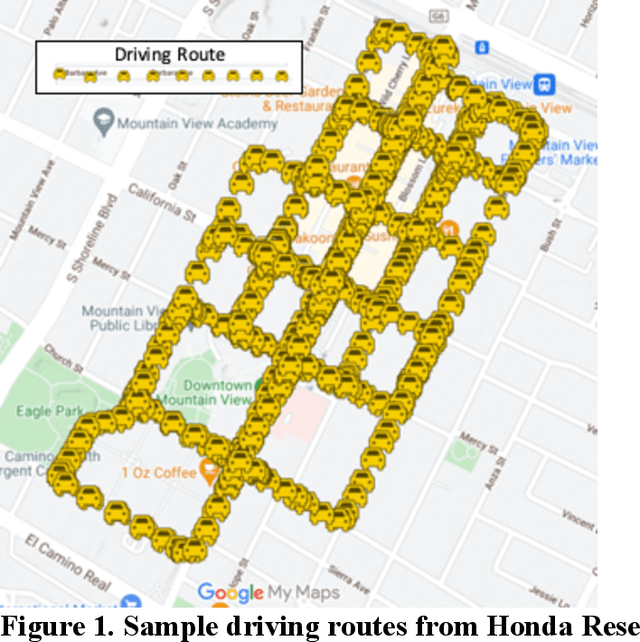
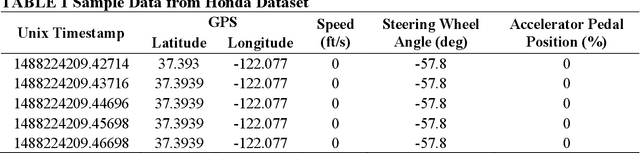
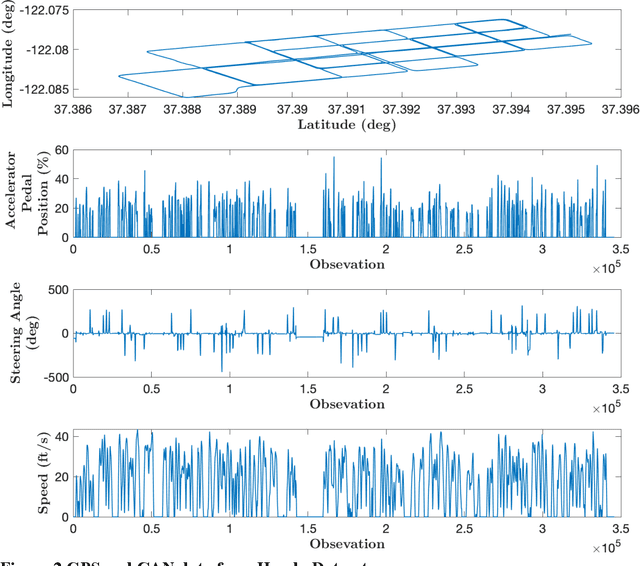
A resilient and robust positioning, navigation, and timing (PNT) system is a necessity for the navigation of autonomous vehicles (AVs). Global Navigation Satelite System (GNSS) provides satellite-based PNT services. However, a spoofer can temper an authentic GNSS signal and could transmit wrong position information to an AV. Therefore, a GNSS must have the capability of real-time detection and feedback-correction of spoofing attacks related to PNT receivers, whereby it will help the end-user (autonomous vehicle in this case) to navigate safely if it falls into any compromises. This paper aims to develop a deep reinforcement learning (RL)-based turn-by-turn spoofing attack detection using low-cost in-vehicle sensor data. We have utilized Honda Driving Dataset to create attack and non-attack datasets, develop a deep RL model, and evaluate the performance of the RL-based attack detection model. We find that the accuracy of the RL model ranges from 99.99% to 100%, and the recall value is 100%. However, the precision ranges from 93.44% to 100%, and the f1 score ranges from 96.61% to 100%. Overall, the analyses reveal that the RL model is effective in turn-by-turn spoofing attack detection.
U2++: Unified Two-pass Bidirectional End-to-end Model for Speech Recognition
Jun 10, 2021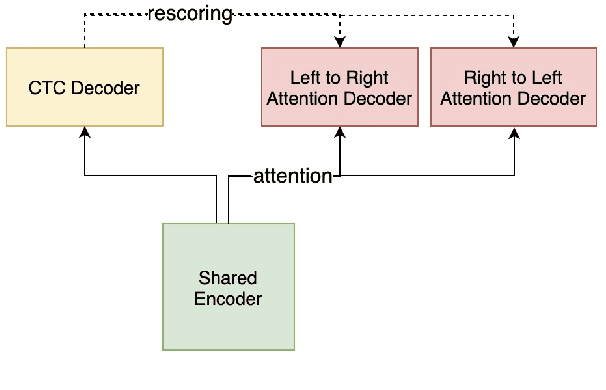
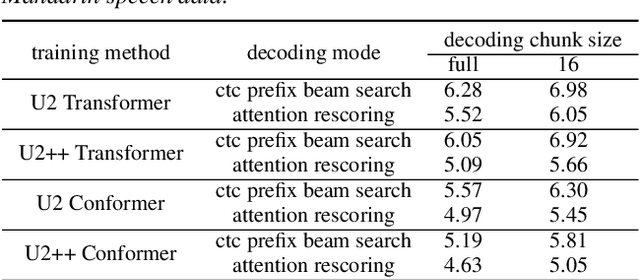
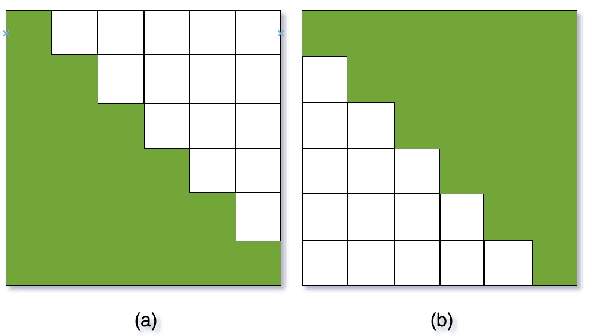
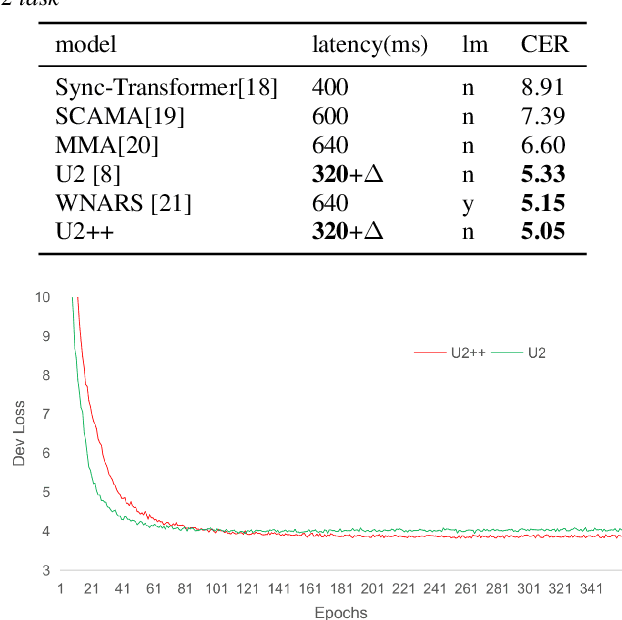
The unified streaming and non-streaming two-pass (U2) end-to-end model for speech recognition has shown great performance in terms of streaming capability, accuracy, real-time factor (RTF), and latency. In this paper, we present U2++, an enhanced version of U2 to further improve the accuracy. The core idea of U2++ is to use the forward and the backward information of the labeling sequences at the same time at training to learn richer information, and combine the forward and backward prediction at decoding to give more accurate recognition results. We also proposed a new data augmentation method called SpecSub to help the U2++ model to be more accurate and robust. Our experiments show that, compared with U2, U2++ shows faster convergence at training, better robustness to the decoding method, as well as consistent 5\% - 8\% word error rate reduction gain over U2. On the experiment of AISHELL-1, we achieve a 4.63\% character error rate (CER) with a non-streaming setup and 5.05\% with a streaming setup with 320ms latency by U2++. To the best of our knowledge, 5.05\% is the best-published streaming result on the AISHELL-1 test set.