 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Warped-Linear Models for Time Series Classification
Nov 24, 2017
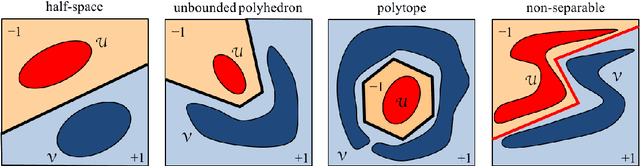

This article proposes and studies warped-linear models for time series classification. The proposed models are time-warp invariant analogues of linear models. Their construction is in line with time series averaging and extensions of k-means and learning vector quantization to dynamic time warping (DTW) spaces. The main theoretical result is that warped-linear models correspond to polyhedral classifiers in Euclidean spaces. This result simplifies the analysis of time-warp invariant models by reducing to max-linear functions. We exploit this relationship and derive solutions to the label-dependency problem and the problem of learning warped-linear models. Empirical results on time series classification suggest that warped-linear functions better trade solution quality against computation time than nearest-neighbor and prototype-based methods.
A semi-supervised self-training method to develop assistive intelligence for segmenting multiclass bridge elements from inspection videos
Sep 14, 2021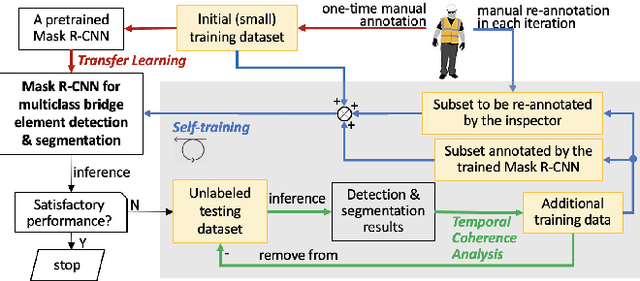
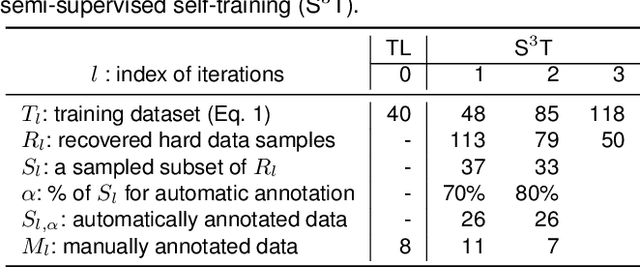
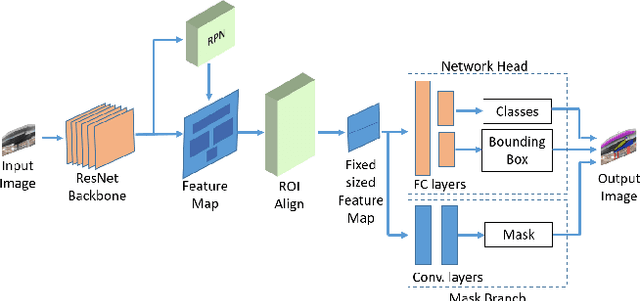
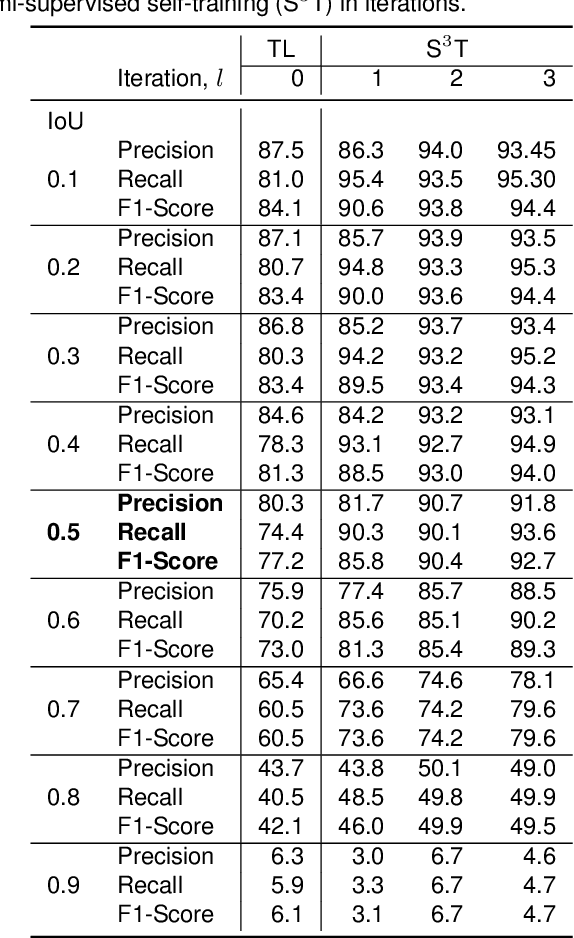
Bridge inspection is an important step in preserving and rehabilitating transportation infrastructure for extending their service lives. The advancement of mobile robotic technology allows the rapid collection of a large amount of inspection video data. However, the data are mainly images of complex scenes, wherein a bridge of various structural elements mix with a cluttered background. Assisting bridge inspectors in extracting structural elements of bridges from the big complex video data, and sorting them out by classes, will prepare inspectors for the element-wise inspection to determine the condition of bridges. This paper is motivated to develop an assistive intelligence model for segmenting multiclass bridge elements from inspection videos captured by an aerial inspection platform. With a small initial training dataset labeled by inspectors, a Mask Region-based Convolutional Neural Network (Mask R-CNN) pre-trained on a large public dataset was transferred to the new task of multiclass bridge element segmentation. Besides, the temporal coherence analysis attempts to recover false negatives and identify the weakness that the neural network can learn to improve. Furthermore, a semi-supervised self-training (S$^3$T) method was developed to engage experienced inspectors in refining the network iteratively. Quantitative and qualitative results from evaluating the developed deep neural network demonstrate that the proposed method can utilize a small amount of time and guidance from experienced inspectors (3.58 hours for labeling 66 images) to build the network of excellent performance (91.8% precision, 93.6% recall, and 92.7% f1-score). Importantly, the paper illustrates an approach to leveraging the domain knowledge and experiences of bridge professionals into computational intelligence models to efficiently adapt the models to varied bridges in the National Bridge Inventory.
* Published in Structural Health Monitoring
Impact of Data Normalization on Deep Neural Network for Time Series Forecasting
Jan 07, 2019
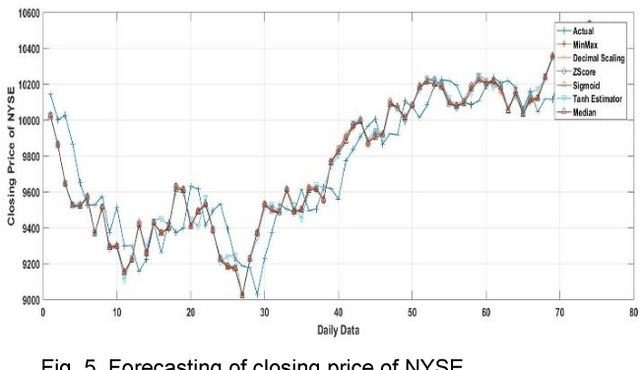
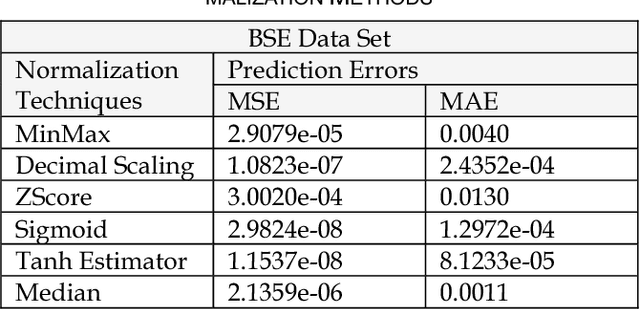
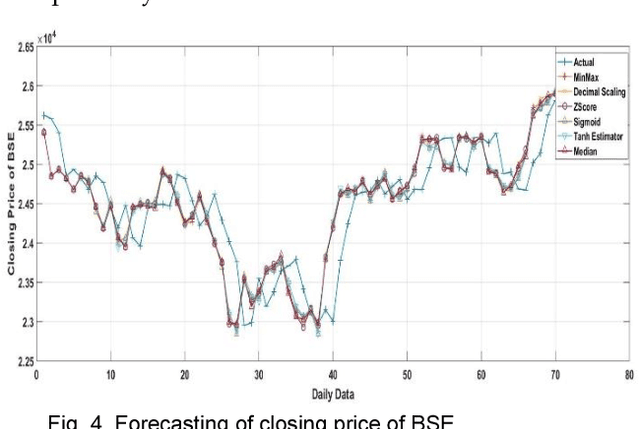
For the last few years it has been observed that the Deep Neural Networks (DNNs) has achieved an excellent success in image classification, speech recognition. But DNNs are suffer great deal of challenges for time series forecasting because most of the time series data are nonlinear in nature and highly dynamic in behaviour. The time series forecasting has a great impact on our socio-economic environment. Hence, to deal with these challenges its need to be redefined the DNN model and keeping this in mind, data pre-processing, network architecture and network parameters are need to be consider before feeding the data into DNN models. Data normalization is the basic data pre-processing technique form which learning is to be done. The effectiveness of time series forecasting is heavily depend on the data normalization technique. In this paper, different normalization methods are used on time series data before feeding the data into the DNN model and we try to find out the impact of each normalization technique on DNN to forecast the time series. Here the Deep Recurrent Neural Network (DRNN) is used to predict the closing index of Bombay Stock Exchange (BSE) and New York Stock Exchange (NYSE) by using BSE and NYSE time series data.
Reinforcement Learning for Adaptive Optimal Stationary Control of Linear Stochastic Systems
Jul 20, 2021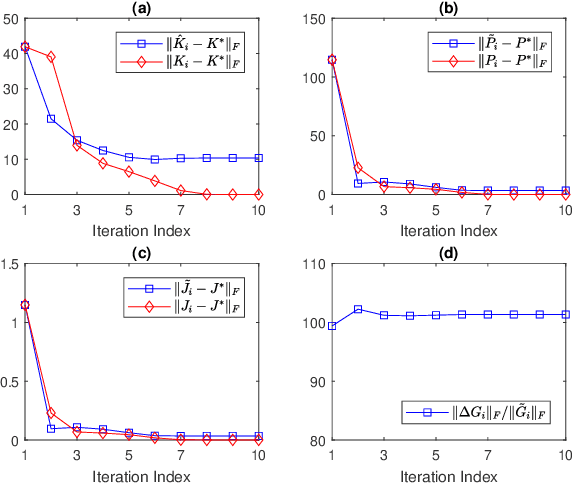
This paper studies the adaptive optimal stationary control of continuous-time linear stochastic systems with both additive and multiplicative noises, using reinforcement learning techniques. Based on policy iteration, a novel off-policy reinforcement learning algorithm, named optimistic least-squares-based policy iteration, is proposed which is able to iteratively find near-optimal policies of the adaptive optimal stationary control problem directly from input/state data without explicitly identifying any system matrices, starting from an initial admissible control policy. The solutions given by the proposed optimistic least-squares-based policy iteration are proved to converge to a small neighborhood of the optimal solution with probability one, under mild conditions. The application of the proposed algorithm to a triple inverted pendulum example validates its feasibility and effectiveness.
Machine Learning Framework for Sensing and Modeling Interference in IoT Frequency Bands
Jun 10, 2021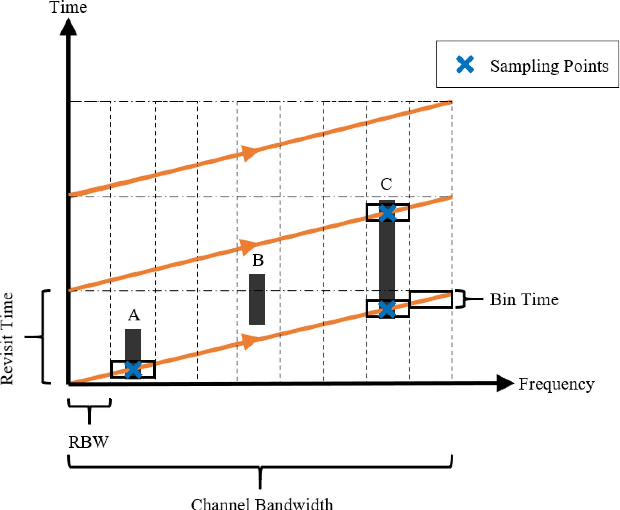
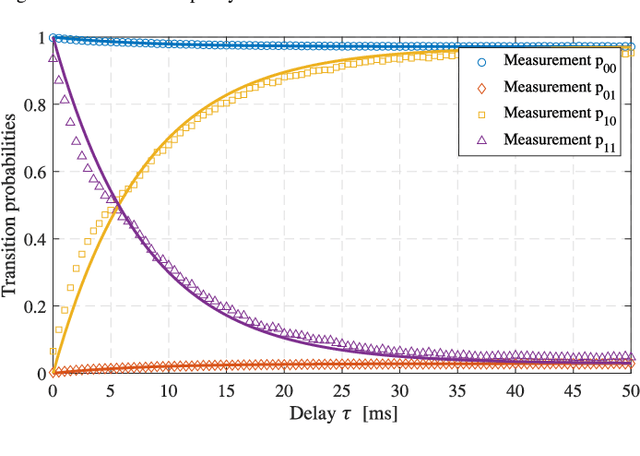
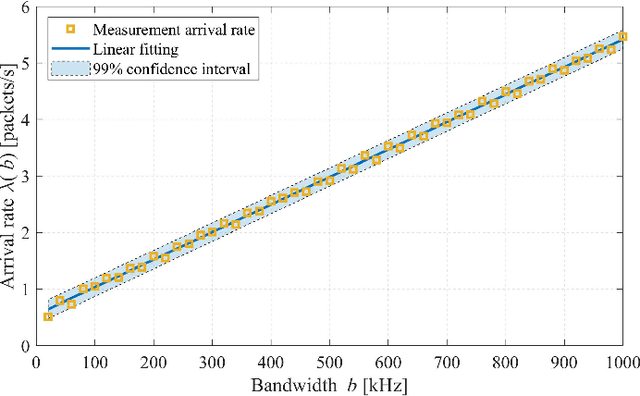
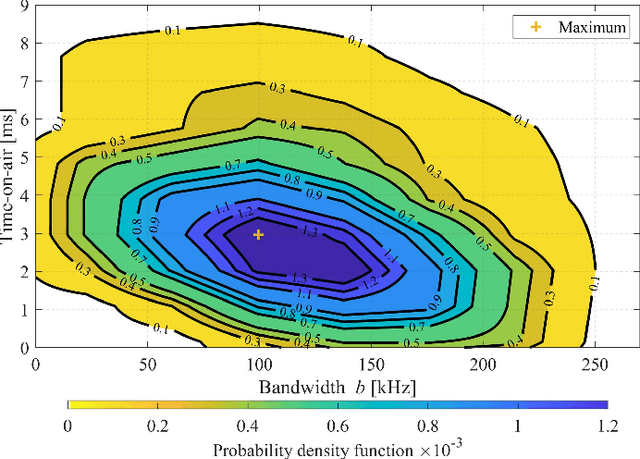
Spectrum scarcity has surfaced as a prominent concern in wireless radio communications with the emergence of new technologies over the past few years. As a result, there is growing need for better understanding of the spectrum occupancy with newly emerging access technologies supporting the Internet of Things. In this paper, we present a framework to capture and model the traffic behavior of short-time spectrum occupancy for IoT applications in the shared bands to determine the existing interference. The proposed capturing method utilizes a software defined radio to monitor the short bursts of IoT transmissions by capturing the time series data which is converted to power spectral density to extract the observed occupancy. Furthermore, we propose the use of an unsupervised machine learning technique to enhance conventionally implemented energy detection methods. Our experimental results show that the temporal and frequency behavior of the spectrum can be well-captured using the combination of two models, namely, semi-Markov chains and a Poisson-distribution arrival rate. We conduct an extensive measurement campaign in different urban environments and incorporate the spatial effect on the IoT shared spectrum.
Robust Interactive Semantic Segmentation of Pathology Images with Minimal User Input
Aug 30, 2021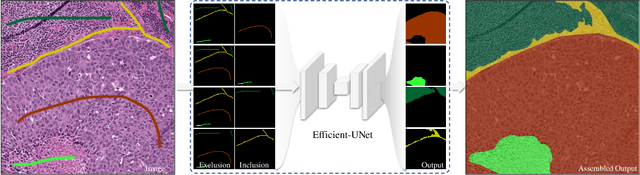

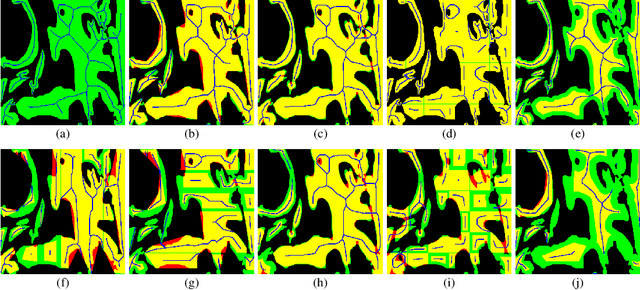
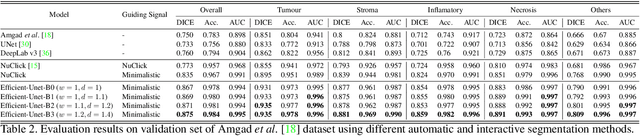
From the simple measurement of tissue attributes in pathology workflow to designing an explainable diagnostic/prognostic AI tool, access to accurate semantic segmentation of tissue regions in histology images is a prerequisite. However, delineating different tissue regions manually is a laborious, time-consuming and costly task that requires expert knowledge. On the other hand, the state-of-the-art automatic deep learning models for semantic segmentation require lots of annotated training data and there are only a limited number of tissue region annotated images publicly available. To obviate this issue in computational pathology projects and collect large-scale region annotations efficiently, we propose an efficient interactive segmentation network that requires minimum input from the user to accurately annotate different tissue types in the histology image. The user is only required to draw a simple squiggle inside each region of interest so it will be used as the guiding signal for the model. To deal with the complex appearance and amorph geometry of different tissue regions we introduce several automatic and minimalistic guiding signal generation techniques that help the model to become robust against the variation in the user input. By experimenting on a dataset of breast cancer images, we show that not only does our proposed method speed up the interactive annotation process, it can also outperform the existing automatic and interactive region segmentation models.
Performer Identification From Symbolic Representation of Music Using Statistical Models
Aug 05, 2021
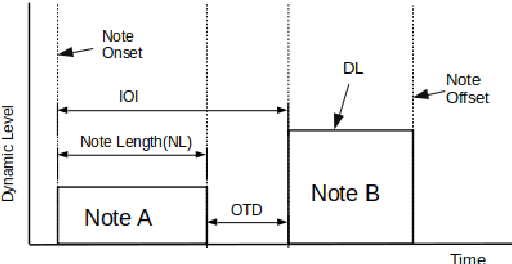
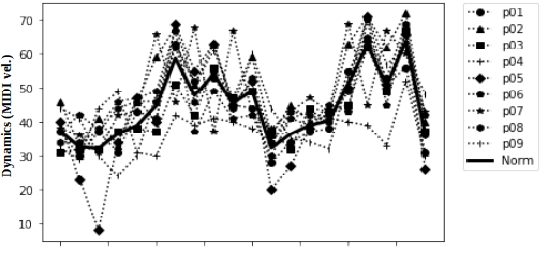
Music Performers have their own idiosyncratic way of interpreting a musical piece. A group of skilled performers playing the same piece of music would likely to inject their unique artistic styles in their performances. The variations of the tempo, timing, dynamics, articulation etc. from the actual notated music are what make the performers unique in their performances. This study presents a dataset consisting of four movements of Schubert's ``Sonata in B-flat major, D.960" performed by nine virtuoso pianists individually. We proposed and extracted a set of expressive features that are able to capture the characteristics of an individual performer's style. We then present a performer identification method based on the similarity of feature distribution, given a set of piano performances. The identification is done considering each feature individually as well as a fusion of the features. Results show that the proposed method achieved a precision of 0.903 using fusion features. Moreover, the onset time deviation feature shows promising result when considered individually.
A survey of Monte Carlo methods for noisy and costly densities with application to reinforcement learning
Aug 01, 2021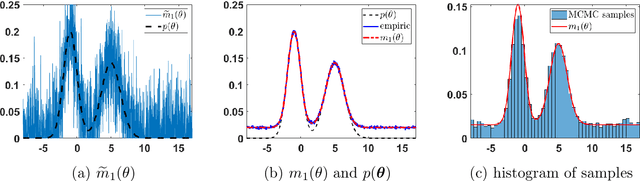
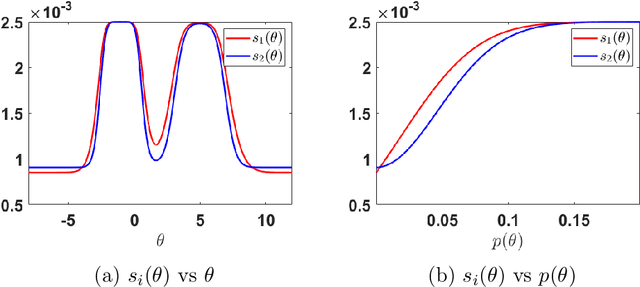
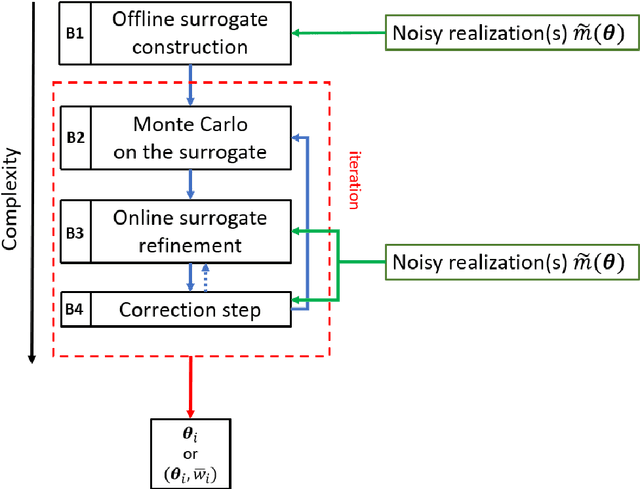

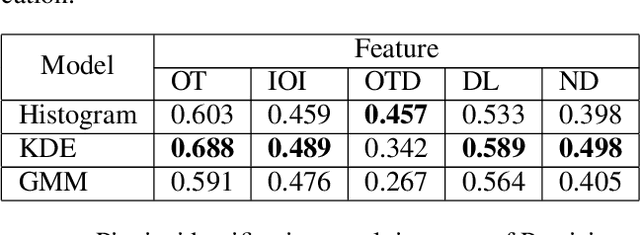
This survey gives an overview of Monte Carlo methodologies using surrogate models, for dealing with densities which are intractable, costly, and/or noisy. This type of problem can be found in numerous real-world scenarios, including stochastic optimization and reinforcement learning, where each evaluation of a density function may incur some computationally-expensive or even physical (real-world activity) cost, likely to give different results each time. The surrogate model does not incur this cost, but there are important trade-offs and considerations involved in the choice and design of such methodologies. We classify the different methodologies into three main classes and describe specific instances of algorithms under a unified notation. A modular scheme which encompasses the considered methods is also presented. A range of application scenarios is discussed, with special attention to the likelihood-free setting and reinforcement learning. Several numerical comparisons are also provided.
Object-Augmented RGB-D SLAM for Wide-Disparity Relocalisation
Aug 05, 2021



We propose a novel object-augmented RGB-D SLAM system that is capable of constructing a consistent object map and performing relocalisation based on centroids of objects in the map. The approach aims to overcome the view dependence of appearance-based relocalisation methods using point features or images. During the map construction, we use a pre-trained neural network to detect objects and estimate 6D poses from RGB-D data. An incremental probabilistic model is used to aggregate estimates over time to create the object map. Then in relocalisation, we use the same network to extract objects-of-interest in the `lost' frames. Pairwise geometric matching finds correspondences between map and frame objects, and probabilistic absolute orientation followed by application of iterative closest point to dense depth maps and object centroids gives relocalisation. Results of experiments in desktop environments demonstrate very high success rates even for frames with widely different viewpoints from those used to construct the map, significantly outperforming two appearance-based methods.
Improving Deep Learning for HAR with shallow LSTMs
Aug 05, 2021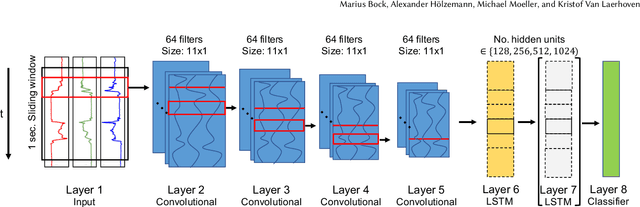
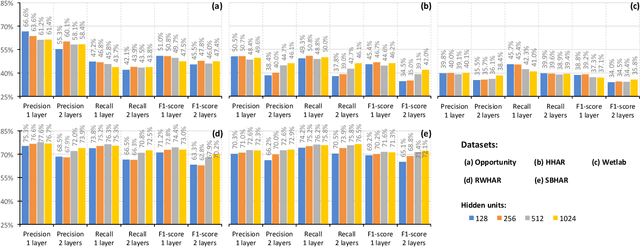
Recent studies in Human Activity Recognition (HAR) have shown that Deep Learning methods are able to outperform classical Machine Learning algorithms. One popular Deep Learning architecture in HAR is the DeepConvLSTM. In this paper we propose to alter the DeepConvLSTM architecture to employ a 1-layered instead of a 2-layered LSTM. We validate our architecture change on 5 publicly available HAR datasets by comparing the predictive performance with and without the change employing varying hidden units within the LSTM layer(s). Results show that across all datasets, our architecture consistently improves on the original one: Recognition performance increases up to 11.7% for the F1-score, and our architecture significantly decreases the amount of learnable parameters. This improvement over DeepConvLSTM decreases training time by as much as 48%. Our results stand in contrast to the belief that one needs at least a 2-layered LSTM when dealing with sequential data. Based on our results we argue that said claim might not be applicable to sensor-based HAR.