 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
An Improved Single Step Non-autoregressive Transformer for Automatic Speech Recognition
Jun 18, 2021
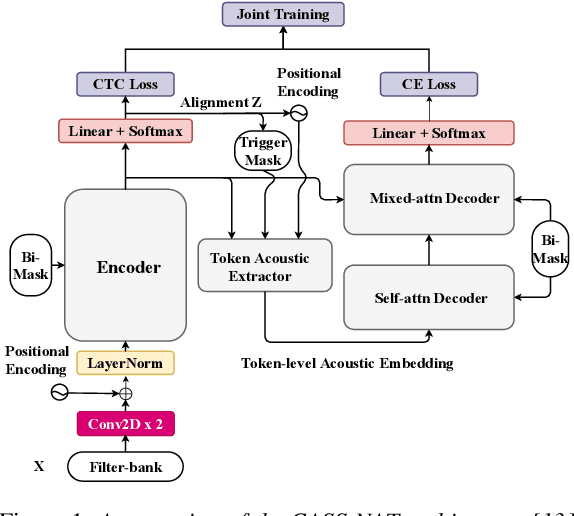
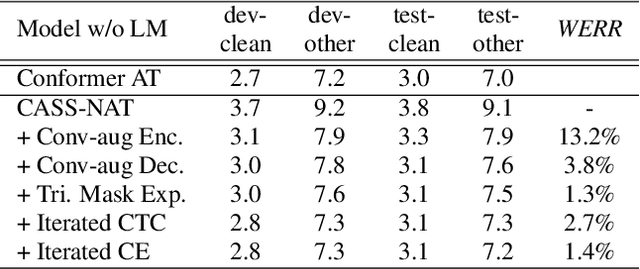
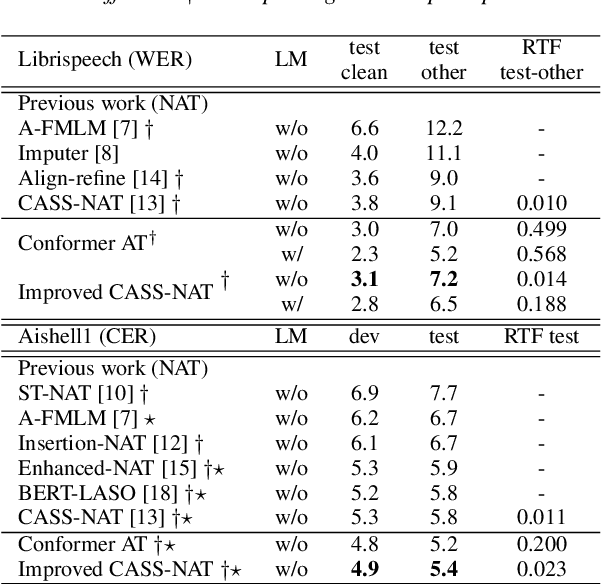
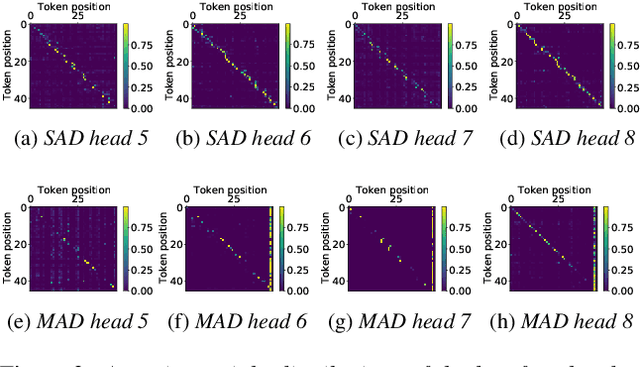
Non-autoregressive mechanisms can significantly decrease inference time for speech transformers, especially when the single step variant is applied. Previous work on CTC alignment-based single step non-autoregressive transformer (CASS-NAT) has shown a large real time factor (RTF) improvement over autoregressive transformers (AT). In this work, we propose several methods to improve the accuracy of the end-to-end CASS-NAT, followed by performance analyses. First, convolution augmented self-attention blocks are applied to both the encoder and decoder modules. Second, we propose to expand the trigger mask (acoustic boundary) for each token to increase the robustness of CTC alignments. In addition, iterated loss functions are used to enhance the gradient update of low-layer parameters. Without using an external language model, the WERs of the improved CASS-NAT, when using the three methods, are 3.1%/7.2% on Librispeech test clean/other sets and the CER is 5.4% on the Aishell1 test set, achieving a 7%~21% relative WER/CER improvement. For the analyses, we plot attention weight distributions in the decoders to visualize the relationships between token-level acoustic embeddings. When the acoustic embeddings are visualized, we find that they have a similar behavior to word embeddings, which explains why the improved CASS-NAT performs similarly to AT.
Airborne Urban Microcells with Grasping End Effectors: A Game Changer for 6G Networks?
May 19, 2021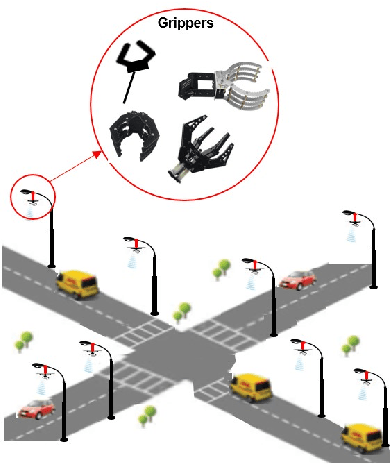
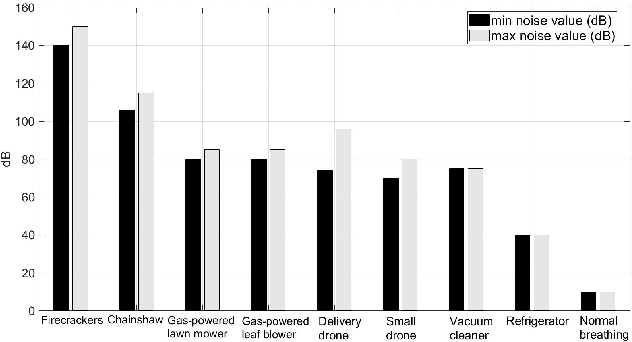
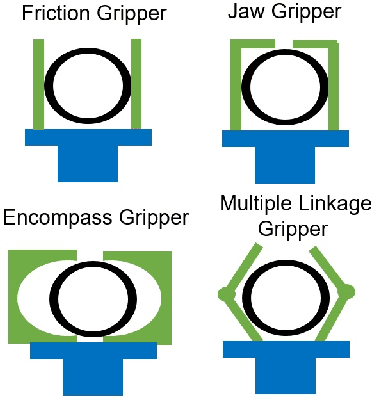
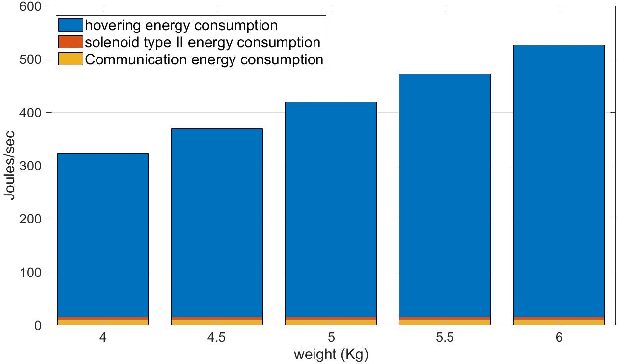
Airborne (or flying) base stations (ABSs) embedded on drones or unmanned aerial vehicles (UAVs) can be deemed as a central element of envisioned 6G cellular networks where significant cell densification with mmWave/Terahertz communications will be part of the ecosystem. Nonetheless, one of the key challenges facing the deployment of ABSs is the inherent limited available energy of the drone, which limits the hovering time for serving ground users to the orders of minutes. This impediment deteriorate the performance of the UAV-enabled cellular network and hinders wide adoption and use of the technology. In this paper, we propose robotic airborne base stations (RABSs) with grasping capabilities to increase the serving time of ground users by multiple orders of magnitude compared to nominal hovering based operation. More specifically, to perform the grasping task, the RABS is equipped with a versatile, albeit, general purpose gripper manipulator. Depending on the type of the gripper RABS can provide service in the range of hours, compared to minutes of hovering based ABSs. In theory it is possible that grasping can be energy neutral, hence the time of service can be bounded by the communications energy consumption. To illustrate the case, energy consumption comparison between hovering and grasping is performed in order to reveal the significant benefits of the proposed approach. Finally, overarching challenges, design considerations for RABS, and future avenues of research are outlined to realize the full potential of the proposed robotic aerial base stations.
SDEdit: Image Synthesis and Editing with Stochastic Differential Equations
Aug 02, 2021
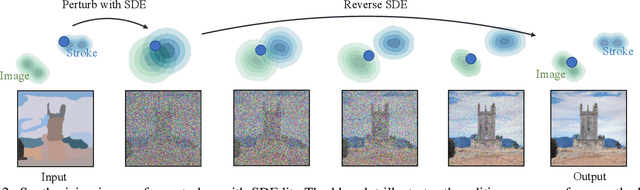
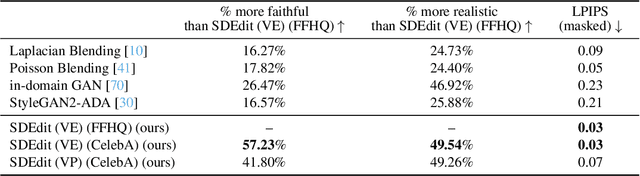

We introduce a new image editing and synthesis framework, Stochastic Differential Editing (SDEdit), based on a recent generative model using stochastic differential equations (SDEs). Given an input image with user edits (e.g., hand-drawn color strokes), we first add noise to the input according to an SDE, and subsequently denoise it by simulating the reverse SDE to gradually increase its likelihood under the prior. Our method does not require task-specific loss function designs, which are critical components for recent image editing methods based on GAN inversion. Compared to conditional GANs, we do not need to collect new datasets of original and edited images for new applications. Therefore, our method can quickly adapt to various editing tasks at test time without re-training models. Our approach achieves strong performance on a wide range of applications, including image synthesis and editing guided by stroke paintings and image compositing.
On the Feasibility of Modeling OFDM Communication Signals with Unsupervised Generative Adversarial Networks
Sep 10, 2021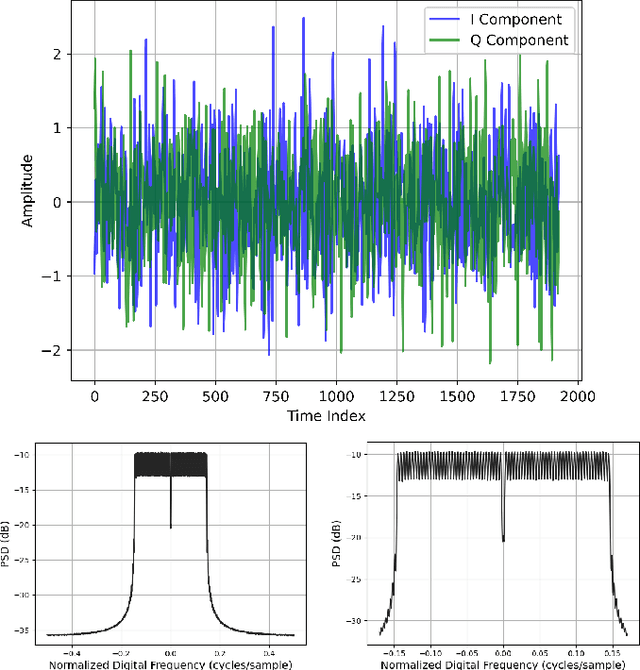
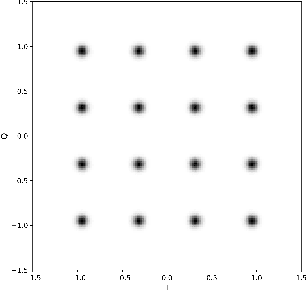
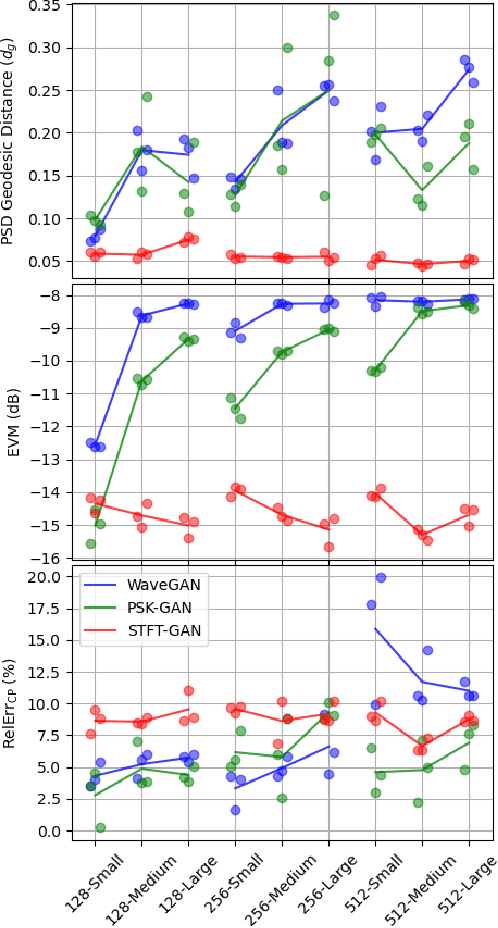
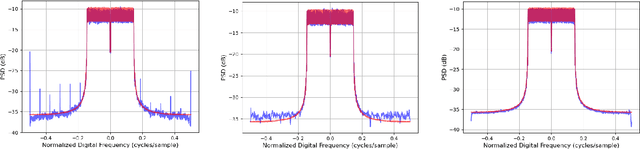
High-quality recordings of radio frequency (RF) emissions from commercial communication hardware in realistic environments are often needed to develop and assess spectrum-sharing technologies and practices, e.g., for training and testing spectrum sensing algorithms and for interference testing. Unfortunately, the time-consuming, expensive nature of such data collections together with data-sharing restrictions pose significant challenges that limit dataset availability. Furthermore, developing accurate models of real-world RF emissions from first principles is often very difficult because system parameters and implementation details are at best only partially known, and complex system dynamics are difficult to characterize. Hence, there is a need for flexible, data-driven methods that can leverage existing datasets to synthesize additional similar waveforms. One promising machine learning approach is unsupervised deep generative modeling with generative adversarial networks (GANs). To date, GANs for RF communication signals have not been studied thoroughly. In this paper, we present the first in-depth investigation of generated signal fidelity for GANs trained with baseband orthogonal frequency-division multiplexing (OFDM) signals, where each subcarrier is digitally modulated with quadrature amplitude modulation (QAM). Building on prior GAN methods, we propose two novel GAN models and evaluate their performance using simulated datasets with known ground truth. Specifically, we investigate model performance with respect to increasing dataset complexity over a range of OFDM parameters and conditions, including fading channels. The findings presented here inform the feasibility of use-cases and provide a foundation for further investigations into deep generative models for RF communication signals.
Continual Backprop: Stochastic Gradient Descent with Persistent Randomness
Aug 13, 2021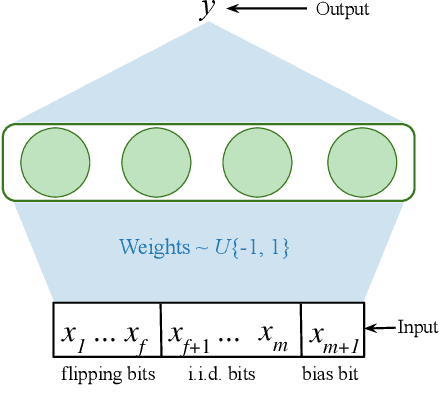
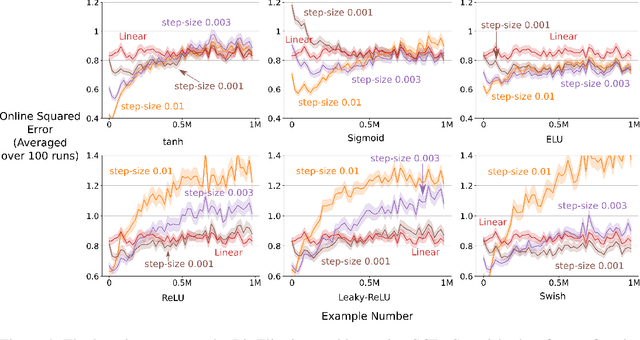
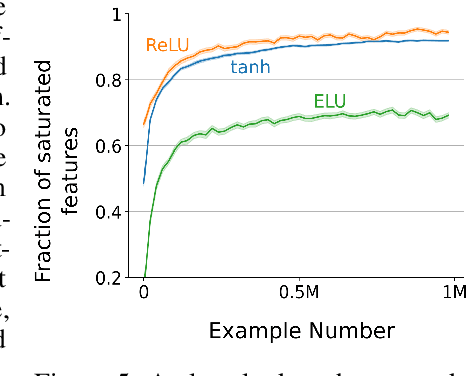
The Backprop algorithm for learning in neural networks utilizes two mechanisms: first, stochastic gradient descent and second, initialization with small random weights, where the latter is essential to the effectiveness of the former. We show that in continual learning setups, Backprop performs well initially, but over time its performance degrades. Stochastic gradient descent alone is insufficient to learn continually; the initial randomness enables only initial learning but not continual learning. To the best of our knowledge, ours is the first result showing this degradation in Backprop's ability to learn. To address this issue, we propose an algorithm that continually injects random features alongside gradient descent using a new generate-and-test process. We call this the Continual Backprop algorithm. We show that, unlike Backprop, Continual Backprop is able to continually adapt in both supervised and reinforcement learning problems. We expect that as continual learning becomes more common in future applications, a method like Continual Backprop will be essential where the advantages of random initialization are present throughout learning.
DeepPlastic: A Novel Approach to Detecting Epipelagic Bound Plastic Using Deep Visual Models
May 13, 2021

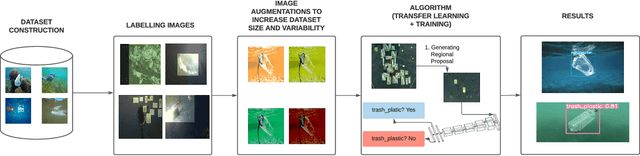

The quantification of positively buoyant marine plastic debris is critical to understanding how concentrations of trash from across the world's ocean and identifying high concentration garbage hotspots in dire need of trash removal. Currently, the most common monitoring method to quantify floating plastic requires the use of a manta trawl. Techniques requiring manta trawls (or similar surface collection devices) utilize physical removal of marine plastic debris as the first step and then analyze collected samples as a second step. The need for physical removal before analysis incurs high costs and requires intensive labor preventing scalable deployment of a real-time marine plastic monitoring service across the entirety of Earth's ocean bodies. Without better monitoring and sampling methods, the total impact of plastic pollution on the environment as a whole, and details of impact within specific oceanic regions, will remain unknown. This study presents a highly scalable workflow that utilizes images captured within the epipelagic layer of the ocean as an input. It produces real-time quantification of marine plastic debris for accurate quantification and physical removal. The workflow includes creating and preprocessing a domain-specific dataset, building an object detection model utilizing a deep neural network, and evaluating the model's performance. YOLOv5-S was the best performing model, which operates at a Mean Average Precision (mAP) of 0.851 and an F1-Score of 0.89 while maintaining near-real-time speed.
Almost Tight Approximation Algorithms for Explainable Clustering
Jul 15, 2021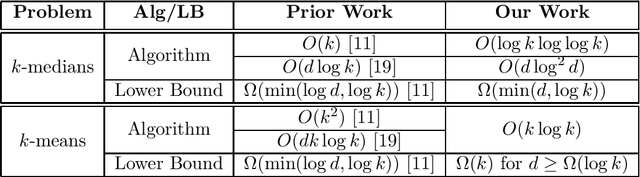



Recently, due to an increasing interest for transparency in artificial intelligence, several methods of explainable machine learning have been developed with the simultaneous goal of accuracy and interpretability by humans. In this paper, we study a recent framework of explainable clustering first suggested by Dasgupta et al.~\cite{dasgupta2020explainable}. Specifically, we focus on the $k$-means and $k$-medians problems and provide nearly tight upper and lower bounds. First, we provide an $O(\log k \log \log k)$-approximation algorithm for explainable $k$-medians, improving on the best known algorithm of $O(k)$~\cite{dasgupta2020explainable} and nearly matching the known $\Omega(\log k)$ lower bound~\cite{dasgupta2020explainable}. In addition, in low-dimensional spaces $d \ll \log k$, we show that our algorithm also provides an $O(d \log^2 d)$-approximate solution for explainable $k$-medians. This improves over the best known bound of $O(d \log k)$ for low dimensions~\cite{laber2021explainable}, and is a constant for constant dimensional spaces. To complement this, we show a nearly matching $\Omega(d)$ lower bound. Next, we study the $k$-means problem in this context and provide an $O(k \log k)$-approximation algorithm for explainable $k$-means, improving over the $O(k^2)$ bound of Dasgupta et al. and the $O(d k \log k)$ bound of \cite{laber2021explainable}. To complement this we provide an almost tight $\Omega(k)$ lower bound, improving over the $\Omega(\log k)$ lower bound of Dasgupta et al. Given an approximate solution to the classic $k$-means and $k$-medians, our algorithm for $k$-medians runs in time $O(kd \log^2 k )$ and our algorithm for $k$-means runs in time $ O(k^2 d)$.
Frequency Domain Convolutional Neural Network: Accelerated CNN for Large Diabetic Retinopathy Image Classification
Jun 24, 2021
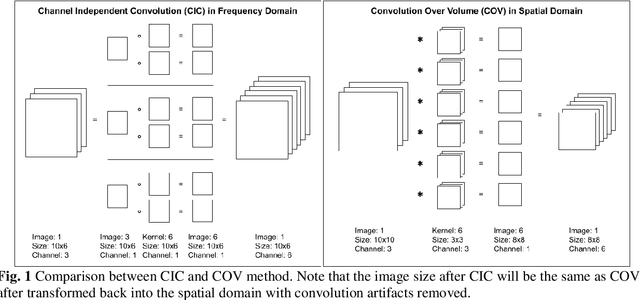


The conventional spatial convolution layers in the Convolutional Neural Networks (CNNs) are computationally expensive at the point where the training time could take days unless the number of layers, the number of training images or the size of the training images are reduced. The image size of 256x256 pixels is commonly used for most of the applications of CNN, but this image size is too small for applications like Diabetic Retinopathy (DR) classification where the image details are important for accurate classification. This research proposed Frequency Domain Convolution (FDC) and Frequency Domain Pooling (FDP) layers which were built with RFFT, kernel initialization strategy, convolution artifact removal and Channel Independent Convolution (CIC) to replace the conventional convolution and pooling layers. The FDC and FDP layers are used to build a Frequency Domain Convolutional Neural Network (FDCNN) to accelerate the training of large images for DR classification. The Full FDC layer is an extension of the FDC layer to allow direct use in conventional CNNs, it is also used to modify the VGG16 architecture. FDCNN is shown to be at least 54.21% faster and 70.74% more memory efficient compared to an equivalent CNN architecture. The modified VGG16 architecture with Full FDC layer is reported to achieve a shorter training time and a higher accuracy at 95.63% compared to the original VGG16 architecture for DR classification.
Acoustic Scene Classification Using Bilinear Pooling on Time-liked and Frequency-liked Convolution Neural Network
Feb 14, 2020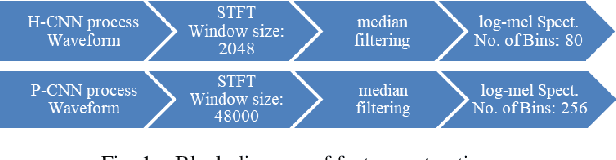
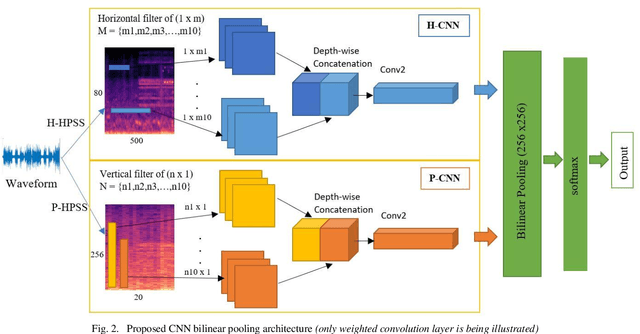
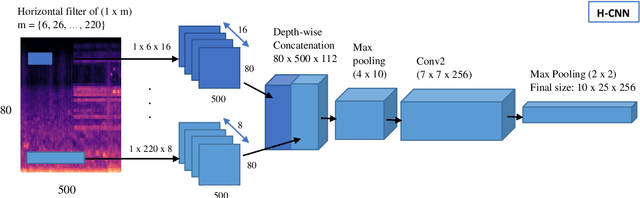

The current methodology in tackling Acoustic Scene Classification (ASC) task can be described in two steps, preprocessing of the audio waveform into log-mel spectrogram and then using it as the input representation for Convolutional Neural Network (CNN). This paradigm shift occurs after DCASE 2016 where this framework model achieves the state-of-the-art result in ASC tasks on the (ESC-50) dataset and achieved an accuracy of 64.5%, which constitute to 20.5% improvement over the baseline model, and DCASE 2016 dataset with an accuracy of 90.0% (development) and 86.2% (evaluation), which constitute a 6.4% and 9% improvements with respect to the baseline system. In this paper, we explored the use of harmonic and percussive source separation (HPSS) to split the audio into harmonic audio and percussive audio, which has received popularity in the field of music information retrieval (MIR). Although works have been done in using HPSS as input representation for CNN model in ASC task, this paper further investigate the possibility on leveraging the separated harmonic component and percussive component by curating 2 CNNs which tries to understand harmonic audio and percussive audio in their natural form, one specialized in extracting deep features in time biased domain and another specialized in extracting deep features in frequency biased domain, respectively. The deep features extracted from these 2 CNNs will then be combined using bilinear pooling. Hence, presenting a two-stream time and frequency CNN architecture approach in classifying acoustic scene. The model is being evaluated on DCASE 2019 sub task 1a dataset and scored an average of 65% on development dataset, Kaggle Leadership Private and Public board.
Hardware Acceleration of Explainable Machine Learning using Tensor Processing Units
Mar 22, 2021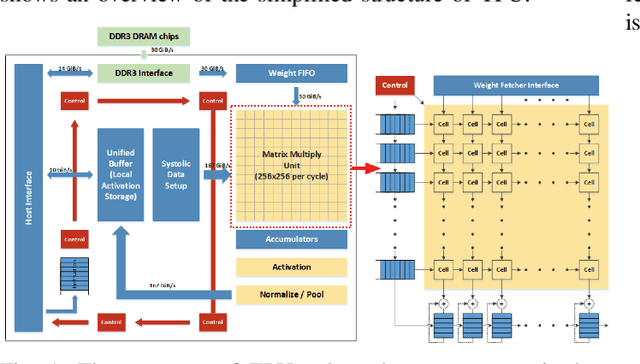
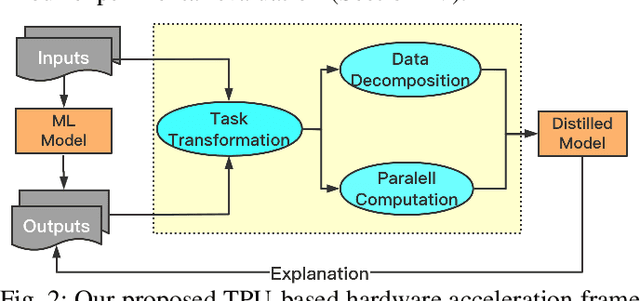
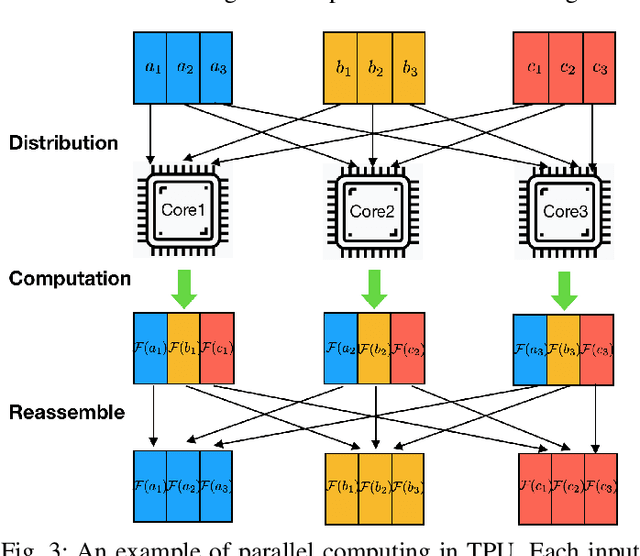
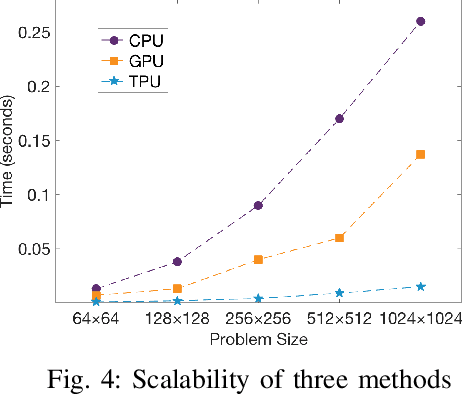
Machine learning (ML) is successful in achieving human-level performance in various fields. However, it lacks the ability to explain an outcome due to its black-box nature. While existing explainable ML is promising, almost all of these methods focus on formatting interpretability as an optimization problem. Such a mapping leads to numerous iterations of time-consuming complex computations, which limits their applicability in real-time applications. In this paper, we propose a novel framework for accelerating explainable ML using Tensor Processing Units (TPUs). The proposed framework exploits the synergy between matrix convolution and Fourier transform, and takes full advantage of TPU's natural ability in accelerating matrix computations. Specifically, this paper makes three important contributions. (1) To the best of our knowledge, our proposed work is the first attempt in enabling hardware acceleration of explainable ML using TPUs. (2) Our proposed approach is applicable across a wide variety of ML algorithms, and effective utilization of TPU-based acceleration can lead to real-time outcome interpretation. (3) Extensive experimental results demonstrate that our proposed approach can provide an order-of-magnitude speedup in both classification time (25x on average) and interpretation time (13x on average) compared to state-of-the-art techniques.